
The Token Tax: Stop Paying More Than You Should for LLMs
March 02, 2026 / Bryan Reynolds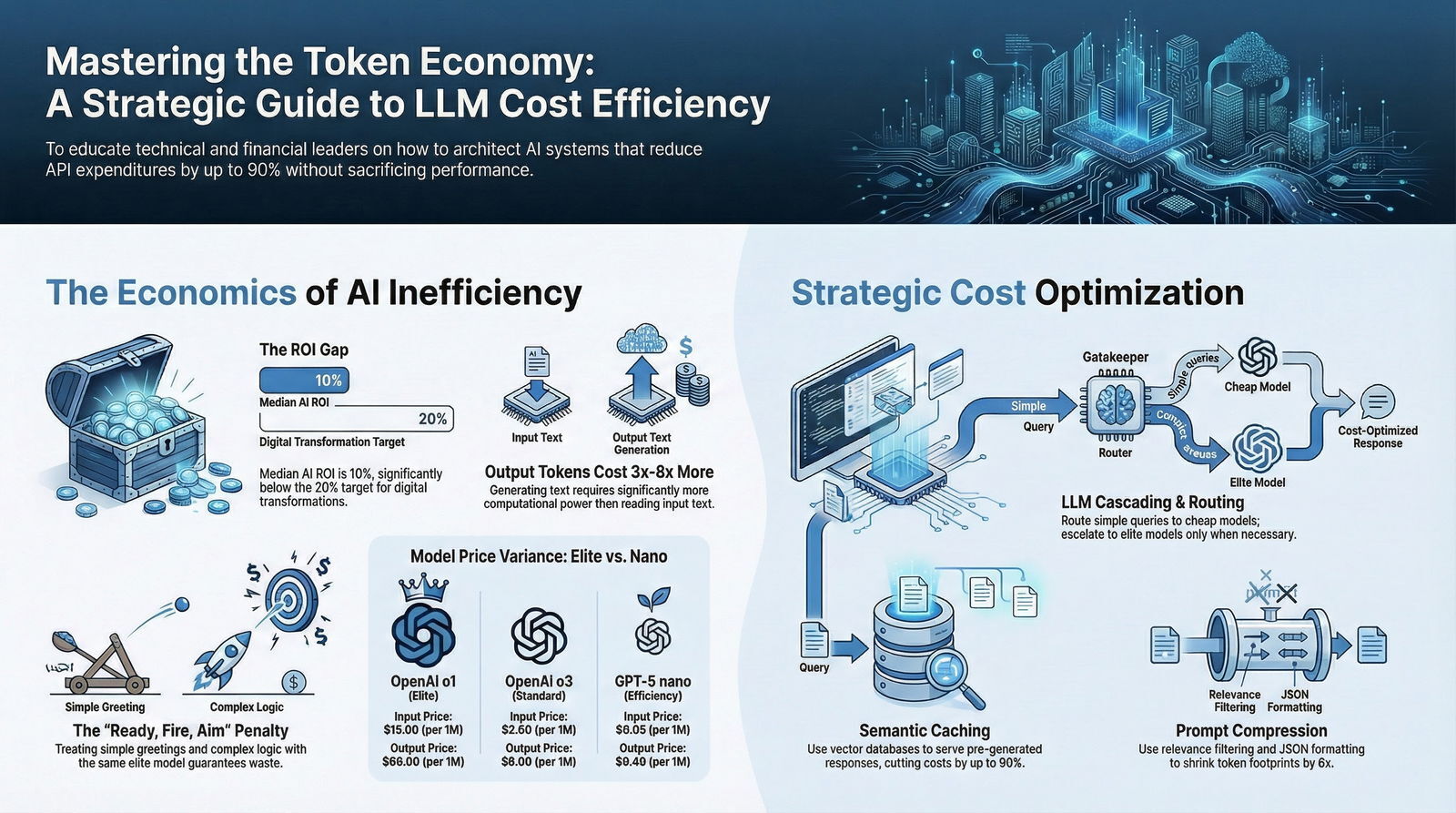
Why Is My AI API Bill So High? A Strategic Guide to LLM Cost Efficiency and Engineering
The integration of artificial intelligence into enterprise operations has transitioned from a phase of speculative experimentation to a period of mandatory, mission-critical infrastructure deployment. However, as organizations rapidly scale generative AI capabilities from isolated proof-of-concept sandboxes into live production environments, executive leadership teams are running headfirst into an unexpected and often staggering operational challenge: the exponential, seemingly uncontrollable growth of Application Programming Interface (API) costs. The underlying economics of Large Language Models (LLMs) operate on consumption-based, metered models that charge per computation unit. In high-volume B2B environments, every user interaction, automated agentic workflow, and background data processing task generates a continuous, real-time stream of financial liabilities.
For the Strategic Chief Financial Officer (CFO) and the Visionary Chief Technology Officer (CTO), the growing disconnect between anticipated operational efficiency gains and the actual, compounding month-over-month expenditures has triggered a critical reevaluation of AI deployment strategies. Technical leaders are now increasingly tasked with demonstrating rigorous financial stewardship. They must architect and engineer software systems that actively optimize and suppress token consumption without degrading the fundamental quality, accuracy, or speed of the model's output.
This comprehensive industry analysis explores the multifaceted landscape of LLM cost optimization. It details the intricate pricing structures that act as the primary drivers of these expenses and outlines exhaustive technical strategies—ranging from intelligent model routing and semantic caching to prompt compression and hyperconverged infrastructure—that elite engineering firms use to reduce clients' monthly AI expenditures by more than 50%. To better understand where these tactics fit in a broader AI roadmap, it can be helpful to view them through the lens of an AI-native SDLC strategic blueprint for CTOs, where architecture, governance, and cost control are baked in from day one.
The Economics of Generative AI: Understanding the Core Cost Drivers
To effectively diagnose the root causes of escalating AI API bills, it is essential to first dismantle the pricing architecture of modern Large Language Models. The financial model of generative AI is fundamentally different from traditional Software-as-a-Service (SaaS) licensing agreements, which typically rely on highly predictable, per-seat, or flat-tier monthly subscriptions. Instead, LLM providers such as OpenAI, Anthropic, and Google utilize a utility-based pricing model that is strictly metered by “token” usage.
The Token Economy and the Context Window Explosion
In the realm of natural language processing, a token represents a fragment of a word, typically corresponding to about four characters of text in the English language. Models process incoming text by reading “input tokens” (the prompt and contextual data provided to the model by the user or application) and generating “output tokens” (the response created by the model). Because the act of probabilistically generating new text requires significantly more computational power and memory bandwidth than simply reading and processing provided text, output tokens are consistently priced higher than input tokens, often by a factor of three, four, or even eight to one.
The recent introduction of massive context windows—with some advanced models now supporting up to 2,000,000 tokens of input—has inadvertently exacerbated enterprise cost issues.
When applications leverage Retrieval-Augmented Generation (RAG) architectures to provide foundational models with highly specific, proprietary enterprise data, they frequently inject tens of thousands of input tokens into a single prompt.
If an application queries a dense, 100-page operational document for every single user interaction, the cost of processing those highly redundant input tokens scales linearly with application usage, quickly overwhelming initial operational budgets and eroding profit margins.
The Evolution of LLM Pricing Models (2024–2026)
The global LLM market has experienced rapid technological commoditization, characterized by a continuous, sharp downward trend in the base cost of token processing for standard tasks, simultaneously offset by the introduction of increasingly complex and wildly expensive “reasoning” models designed for advanced logic.
A historical analysis of OpenAI's pricing reveals a product strategy distinctly bifurcated between high-efficiency, lightweight models and computationally intensive, elite reasoning engines.
For context, the legacy GPT-4o model established an industry benchmark at $2.50 per million input tokens and $10.00 per million output tokens.
However, subsequent iterations and competitive market pressures have introduced drastic price stratifications across the ecosystem:
| Provider & Model Classification | Specific Model Release | Input Price (per 1M Tokens) | Output Price (per 1M Tokens) | Cached Input Price (per 1M) | Target Enterprise Workload |
|---|---|---|---|---|---|
| OpenAI - Elite Reasoning | o1 (Global 2024) | $15.00 | $60.00 | $7.50 | Complex logic, advanced mathematics, multi-step agentic planning |
| OpenAI - Pro Reasoning | GPT-5.2 Pro | $21.00 | N/A | N/A | Highly specialized domain tasks and deep research synthesis |
| OpenAI - Standard Reasoning | o3 (Global 2025) | $2.00 | $8.00 | $0.50 | General multi-faceted analysis, broad visual tasks |
| OpenAI - Standard Logic | GPT-5.2 | $1.75 | $14.00 | N/A | General enterprise workflows, conversational agents |
| OpenAI - Compact Logic | o4-mini (Global 2025) | $1.10 | $4.40 | $0.28 | High-volume conversational tasks, coding assistance |
| OpenAI - Nano Efficiency | GPT-5 nano | $0.05 | $0.40 | $0.0025 | Basic categorization, rapid semantic sorting, simple routing |
| Anthropic - Core Logic | Claude 3 Sonnet | $3.00 | $15.00 | N/A | Enterprise workflows, advanced coding, long-document parsing |
| Google - Core Integration | Gemini 3.1 Pro | 2.00 - 4.00 | $5.00 | N/A | Broad ecosystem integration, multimodal processing |
The financial variance illustrated in this data is stark. Executing a task on the elite o1 reasoning model is exponentially more expensive than executing the identical task on the ultra-efficient GPT-5 nano model.
When organizations apply a single, top-tier model universally across all user queries—treating a simple conversational greeting and a highly complex financial calculation with the exact same computational weight—massive financial inefficiency is not just likely; it is guaranteed.
Furthermore, cloud providers have introduced nuanced architectural pricing mechanisms to reward efficient engineering. For example, Azure OpenAI offers “Cached Input” pricing, where previously processed tokens within a continuous session are charged at a significantly reduced rate (e.g., 0.50 per 1M tokens for o3 cached input versus 2.00 for raw, uncached input).
The utilization of Batch APIs, which allow asynchronous processing over a 24-hour window, can also reduce token costs by exactly 50% for non-latency-sensitive workloads, presenting a massive opportunity for background data processing tasks.
The ROI Crisis in B2B Artificial Intelligence
The escalating costs of AI consumption are occurring against a tense backdrop of increasing organizational scrutiny regarding Return on Investment (ROI). Recent empirical data gathered from financial and technological sectors highlights a growing frustration among executive leadership regarding the tangible business value generated by these expensive systems.
According to a comprehensive survey of finance executives conducted by the BCG Center for CFO Excellence, while corporate ambition is clear and investment in generative AI is at an all-time high, the median reported ROI sits at merely 10%—significantly below the 20% benchmark target expected for enterprise-grade digital transformations.
More alarmingly, nearly a third of business leaders report seeing only limited, or entirely negligible, financial gains from their AI initiatives.
This systemic underperformance is frequently attributed to the pervasive “ready, fire, aim” approach to AI adoption.
Driven Heads of Sales and Innovative Marketing Directors often aggressively push to integrate the latest, most powerful LLMs to capture high-intent buyers—noting that LLM-driven search traffic can convert at rates up to 9x better than traditional channels.
However, without a cohesive technical strategy, organizations deploy these models across broad, low-impact transactional areas, such as basic policy drafting or simple email generation, without establishing rigorous success metrics or technical cost constraints. As CapTech Consulting research reveals, technology-first strategies that lack alignment with core business transformations consistently undermine AI ROI. This is where a disciplined AI governance and technical debt strategy becomes essential to keep experiments from quietly turning into expensive liabilities.
In highly regulated sectors such as healthcare, pharmaceutical life sciences, and financial services, this operational challenge is heavily compounded by stringent, non-negotiable requirements for data privacy, compliance, and auditability.
Enterprises simply cannot expose raw operational data or Personally Identifiable Information (PII) to public, multi-tenant models. They must build secure, isolated pipelines. These pipelines involve complex orchestration layers, proprietary vector databases, and real-time monitoring to avoid hallucination, bias, and security risks.
All of these necessary components add heavily to the Total Cost of Ownership (TCO), which is why many enterprises are now investing in a private “AI fortress” or walled garden architecture for corporate AI to keep data sovereign while still capturing value from generative models.
The mandate for technical leadership, therefore, is not merely to build impressive AI applications, but to architect them in a manner that enforces rigorous financial stewardship from the ground up.
Engineering efficiency is no longer a downstream optimization; it is a fundamental prerequisite for enterprise AI viability.
Technical Strategy 1: LLM Cascading and Dynamic Routing
The most immediate, mathematically sound, and impactful architectural pattern for controlling AI expenditures is LLM cascading, frequently referred to in academic literature and advanced engineering circles by frameworks such as FrugalGPT.
This strategy directly addresses the fundamental economic inefficiency of processing simple, low-level queries through computationally expensive, elite reasoning models.
The Mechanics of the Complexity Router
LLM cascading operates on a sophisticated sequential routing logic. Instead of exposing a single, monolithic API endpoint to the user interface, the application employs an intelligent traffic controller or “router” that intercepts and evaluates the inherent complexity of an incoming prompt.
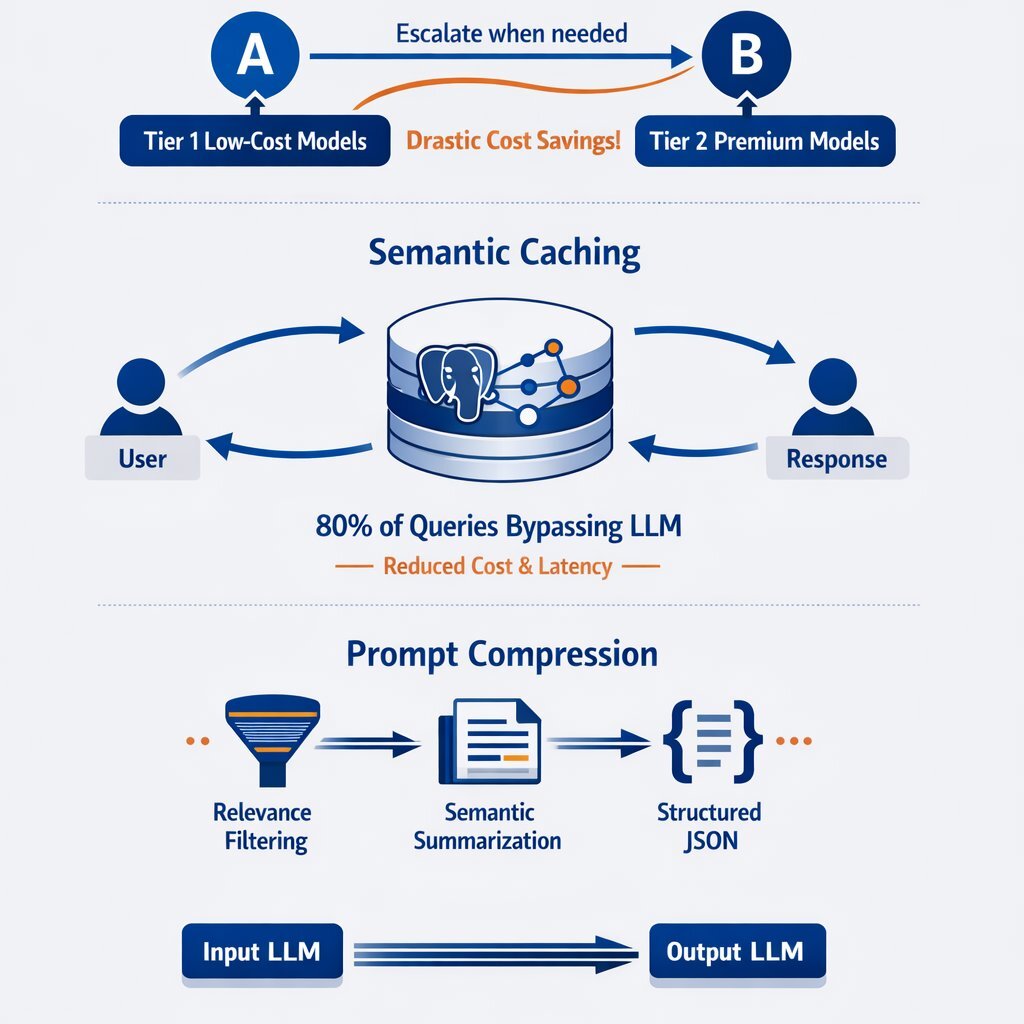
The architecture of an LLM cascade operates as a sophisticated decision tree. An incoming user query is first intercepted by a Complexity Router. This router evaluates the prompt and directs it down a primary path to Tier 1—a high-efficiency, low-cost model such as GPT-5 nano or a locally hosted open-source model. The system then evaluates the output using a decision diamond: is the confidence score of the generated response greater than 95%? If the answer is yes, the system proceeds directly to the final output, incurring negligible fractions of a cent in costs. If the answer is no, the query is diverted down an escalation path to Tier 2—a premium reasoning model like o1 or Claude 3 Opus—before delivering the final output. This targeted escalation guarantees that the heavy computational cost is only paid when the task genuinely demands it, drastically reducing the average cost per interaction across the application.
Performance and Cost Benchmarks of Cascading
The financial impact of this architecture is profound and well-documented. Research on the FrugalGPT framework indicates that by algorithmically learning which combinations of LLMs to use for varying queries, organizations can effectively match the performance of top-tier models while achieving up to a 98% reduction in inference costs.
In rigorous benchmark datasets evaluating reading comprehension, scientific question answering, and news classification, cascading not only reduced the overall operational cost by 80%, but it actually improved overall accuracy by 1.5% compared to relying exclusively on GPT-4.
This counterintuitive improvement occurs because smaller, highly specialized models can sometimes outperform generalized giant models on narrow, specific tasks, successfully bypassing the complex hallucinations that occasionally plague larger models attempting to over-analyze simple inputs.
Advanced iterations of this concept employ a technique known as “LLM Shepherding.” This approach utilizes a two-stage predictor model that jointly determines whether a smaller model requires a targeted “hint” from a larger model to complete a task, and exactly how many tokens to request for that hint.
By exploiting this token-level budget control, Shepherding incurs only the Small Language Model (SLM) cost when no hint is needed; otherwise, it selectively incurs the LLM input cost for processing the query and generating a precise hint. On widely-used mathematical reasoning and code generation benchmarks, Shepherding has been proven to reduce costs by 42% to 94% relative to standard LLM-only inference, delivering up to a 2.8x cost reduction over baseline routing while perfectly matching accuracy. This same idea shows up in modern multi-agent AI architectures, where specialized “manager” and “worker” agents coordinate to keep expensive reasoning focused only where it matters.
However, implementing cascade routing requires deep engineering expertise. Existing model selection strategies rely heavily on precise estimates of quality and computational cost for each model. In practical scenarios, these estimates can be noisy. Furthermore, cascade routing involves tuning multiple hyperparameters to balance the cost-quality tradeoff, making it challenging to optimize without extensive data and enterprise-grade application management.
Technical Strategy 2: Semantic Caching and Vector Infrastructure
While dynamic model routing minimizes the cost of generating new responses, semantic caching attacks inefficiency from an entirely different angle: eliminating the need to generate a response in the first place. Large-scale enterprise applications, particularly customer service chatbots, Learning Management Systems (LMS), and internal corporate knowledge bases, are frequently subjected to a massive volume of redundant queries. Having an LLM compute a novel response to a question it has already answered thousands of times is a primary driver of wasted capital and computing resources. As recent work on the limits of naïve vector search for enterprise data shows, you need to pair caching and embeddings with the right retrieval and verification patterns to keep both costs and errors under control.
The Mechanics of Semantic Search and Vector Embeddings
Traditional database caching relies on exact keyword matching. This approach is highly effective for strict data lookups but almost entirely ineffective in natural language applications where users phrase the exact same intent in dozens of different ways (e.g., “Reset my password,” “I forgot my login credentials,” and “Help me access my locked account” all require the same response). Semantic caching solves this linguistic variance by utilizing vector embeddings.
When a user submits a query, the application first generates an embedding—a dense mathematical array representing the query's underlying semantic meaning.
The system then queries a vector database to find historically cached prompts that share a high cosine similarity or inner product with the new query.
If a semantically equivalent match is identified above a strict confidence threshold, the system retrieves the pre-generated response and serves it to the user directly, entirely bypassing the expensive LLM inference engine.
Transformative Cost and Latency Reductions
The performance metrics associated with semantic caching are transformative for the bottom line. Smart caching strategies provide immediate relief from expensive API calls, effectively reducing model serving costs by up to 90% in highly repetitive environments.
For typical chatbot deployments experiencing a modest cache hit rate of 10% to 15%, the baseline savings are noticeable but moderate.
However, in high-traffic enterprise systems where queries converge heavily around specific operational topics or seasonal events, cache hit rates regularly reach between 80% and 95%.
In such optimal, high-traffic scenarios, empirical data demonstrates a 35% to 80% reduction in total daily LLM API costs.
| Operational Metric | Standard LLM Call (No Cache) | Semantic Cache Retrieval (60% Hit Rate) | Net Improvement |
|---|---|---|---|
| Response Latency | ~6,800 milliseconds | ~25 milliseconds | 250x Faster |
| Daily API Cost (Example) | $41.00 | $16.40 | 60% Savings |
| Annualized Cost (Example) | $14,760 | $5,904 | $8,856 Saved |
Beyond pure financial savings, the latency improvements are equally critical for the end-user experience. Standard LLM API calls frequently require multiple seconds to generate a complete response, creating friction.
A semantically cached answer, delivered from a high-performance in-memory database, can be returned in as little as 25 milliseconds (with 22 milliseconds of that time spent simply generating the input embedding).
This sub-millisecond retrieval creates a dramatically better user experience where most repeated queries feel instantaneous.
Architecting the Vector Database Layer
The success of semantic caching relies heavily on the stability, speed, and design of the underlying vector storage infrastructure. The technology ecosystem offers various approaches, ranging from native vector databases like ScaNN, Chroma, and Qdrant, to in-memory stores like Amazon MemoryDB.
However, many enterprises prefer to consolidate their infrastructure and reduce vendor sprawl by utilizing powerful extensions like pgvector for PostgreSQL.
pgvector allows database engineers to store high-dimensional vectors directly within familiar relational database columns and execute similarity queries using standard SQL syntax.
It supports various distance metrics, including L2 (Euclidean), inner product, and cosine similarity.
While earlier versions of pgvector faced performance bottlenecks regarding indexing strategies (limited to HNSW and IVF_FLAT) and high-dimensional limits, recent releases (0.6.0 and 0.8.0) have introduced massive improvements. The introduction of parallel HNSW index builds, scalar and binary quantization, and SIMD optimizations offer 10x to 150x speedups without requiring any query rewrites.
In AWS benchmarks on a 10 million product dataset, updated pgvector configurations delivered up to a 9.4x faster query performance, dropping filtered query latency from 120ms to 70ms.
This makes PostgreSQL a highly viable, enterprise-grade solution for unified data management and caching without the overhead of maintaining a separate standalone vector database.
Enterprises must also implement rigorous cache management protocols to ensure reliability. This includes establishing Time-to-Live (TTL) expiration policies with randomized “jitter” to prevent mass cache invalidations from simultaneously overwhelming the backend LLM, and ensuring strict context segregation (using distinct namespaces) to avoid cross-domain data contamination and prevent PII leakage.
Technical Strategy 3: Prompt Compression and Token Management
Even with intelligent routing and robust semantic caching firmly in place, a percentage of queries will inevitably reach the LLM. For these net-new requests, the queries must be rigorously optimized to consume the absolute minimum number of tokens required to successfully complete the task. Because the physical size of the prompt directly dictates the input cost, prompt compression is a mandatory discipline for financial stewardship.
Prompt compression leverages the inherent redundancy of human language. Linguistic research demonstrates that English text, particularly at the paragraph or chapter length, contains approximately 75% redundancy—meaning most words can be accurately predicted from the context of the words preceding them.
Advanced prompt engineering teams utilize several distinct techniques to shrink context windows and accelerate generation without sacrificing task quality:
1. Relevance Filtering and Selective Context
When building context for a prompt through RAG processes, naive systems frequently retrieve entire, multi-page documents to ensure the model has adequate background information. Relevance filtering algorithmically scores the distinct sections of a retrieved text against the user's prompt, dynamically extracting and passing only the highly pertinent paragraphs.
Techniques like Selective Context measure the self-information of the text to identify and prune redundant input.
This vastly improves LLM reasoning efficiency by reducing memory costs and generation latency while maintaining task performance on long-context operations.
2. Semantic Summarization
Rather than feeding raw, verbose meeting transcripts, lengthy code bases, or historical conversation logs into the model iteratively, systems can execute a low-cost, preliminary summarization step. A fast, highly efficient nano-model digests the lengthy text and produces a highly condensed digest that retains essential semantics.
This summarized context is then passed to the primary reasoning model, drastically reducing the token footprint the expensive model must “read.”
3. Structured JSON Prompting
Natural human language is inherently inefficient for programmatic instructions. By transposing lengthy textual instructions into compact, semi-structured formats like JSON key-value pairs or concise bulleted lists, engineers can communicate complex constraints to the model using significantly fewer tokens.
Structured prompting also minimizes linguistic ambiguity, reducing the likelihood of model hallucinations and forcing a highly deterministic, consistent output.
4. Instruction and Template Referencing
Enterprise applications frequently utilize extensive system prompts that dictate the model's persona, required output format, brand style guide, and ethical guardrails. Rather than repeating these multi-paragraph instructions in every single API call, systems can utilize instruction referencing.
In advanced cloud environments, such as Amazon Bedrock, prompt caching allows the system to cache these static prompt prefixes in memory. This strategy can reduce input token costs by up to 90% and lower inference response latency by up to 85% for repeated interactions.
5. Output Compression Constraints
Token management extends beyond the input prompt. Because generating output tokens is mathematically the most expensive operation an LLM performs, output compression is vital.
Output compression is a semi-controllable process that involves applying strict deterministic modifiers within the prompt to restrict the model's natural verbosity.
Directives such as “Respond strictly in three bullet points,” “Be exclusively concise,” or defining strict maximum character limits prevent the model from generating unnecessary preamble, conversational filler, or overly exhaustive explanations that drive up the final bill. These same constraints are a core part of modern agentic engineering practices, which aim to keep AI helpful but tightly scoped so it doesn’t quietly inflate costs or complexity.
Methods such as LongLLMLingua have proven to be exceptionally promising for prompt compression in RAG applications, capable of compressing prompts by 6x to 7x while still retaining the key information needed for the LLM to generate highly accurate, context-aware responses.
The Infrastructure Layer: Taking Control with Kubernetes and Harvester HCI
Implementing intelligent routing, highly available vector caching, and complex prompt compression algorithms requires a robust, scalable, and meticulously orchestrated backend infrastructure. Relying solely on fragmented, external cloud-based microservices to handle every step of the AI pipeline can introduce unacceptable latency, severe security vulnerabilities regarding data privacy, and unpredictable network egress costs.
Organizations focused on rigorous cost management and maximum operational control are increasingly adopting unified, on-premise, or hybrid enterprise architectures. Technology partners like Baytech Consulting leverage a distinct Tailored Tech Advantage by deploying sophisticated, custom-crafted software environments built on cutting-edge stacks, ensuring rapid agile deployment that remains adaptive and transparent.

The Strategic Value of Harvester HCI and Rancher
For enterprises managing highly secure AI workloads, or those looking to eliminate API costs entirely for the first tier of their LLM cascade, utilizing modern open-source infrastructure solutions is a strategic imperative. The foundation of this approach relies on technologies like Harvester—a modern, open, interoperable Hyperconverged Infrastructure (HCI) solution built natively on Kubernetes.
Harvester is designed for operators seeking a cloud-native HCI solution that runs directly on bare-metal servers. It provides integrated virtualization and distributed block storage capabilities via Longhorn.
What makes Harvester particularly powerful for AI engineering is that it unifies legacy virtualized infrastructure (managed via KubeVirt) while automatically supporting containerized environments through seamless integration with Rancher.
By leveraging an enterprise-grade stack—incorporating Azure DevOps On-Prem, Docker, Kubernetes, Rancher, and Harvester HCI hosted on powerful OVHCloud servers—engineering teams can deploy localized, lightweight LLMs directly within their own data centers.
This means the “Tier 1” model in the FrugalGPT cascade is hosted internally. When the Complexity Router directs a basic query to this local model, the interaction incurs strictly zero external API token costs. The enterprise pays only for the fixed cost of their own hardware electricity and maintenance, effectively neutralizing the variable token pricing model for a vast majority of traffic.
The system utilizes the Kubernetes API as a unified automation language to scale these containerized AI inference workloads dynamically across the cluster based on real-time traffic spikes, ensuring hardware is utilized efficiently.
Furthermore, maintaining the semantic cache layer—such as a clustered PostgreSQL and pgAdmin environment augmented with pgvector—within the exact same hyperconverged infrastructure ensures that vector similarity searches execute with microsecond latency, completely unaffected by external internet routing delays.
This architectural synthesis of routing algorithms, rapid database retrieval, and scalable container orchestration, all secured behind robust pfSense firewalls, forms the absolute foundation of truly cost-effective, enterprise-grade AI operations. For many teams, this is the natural evolution from cloud-only prototypes toward a more strategic full-stack engineering and infrastructure stack that balances speed with long-term control.
Optimizing for High-Volume Applications: Industry Perspectives
The theoretical cost savings of AI engineering strategies become highly tangible when applied to high-throughput, mission-critical enterprise applications across distinct B2B sectors. The challenges—and the engineering solutions—vary depending on the industry persona.
Education and Healthcare: Learning Management Systems (LMS)
In the digital education and healthcare training sectors, Learning Management Systems face uniquely variable, high-volume workloads. Platforms supporting medical and allied health professionals—similar to the comprehensive solutions developed for American Allied Health and Petra Medical College—serve thousands of students simultaneously, managing portals, online exams, and certification generation.
Students interacting with AI-driven tutors or automated curriculum assessment systems generate a massive volume of highly repetitive queries regarding curriculum specifics, exam schedules, and basic conceptual clarifications. Applying semantic caching in an LMS environment yields extraordinary ROI. Because the core curriculum is highly standardized, the statistical probability of multiple students asking semantically identical questions is exceptionally high. Caching these responses locally in Postgres ensures that the heavy API costs of a premium LLM are incurred only when a student asks a novel, highly complex question requiring personalized pedagogical reasoning.
Financial Services, Real Estate, and Mortgage Tech
In the fast-paced financial services, real estate, and mortgage sectors, AI is increasingly utilized for rapid lead scoring, predictive pipeline analysis, and high-volume document extraction.
Companies handling SaaS CRM for mortgage lead management or high-volume loan processing (akin to systems utilized by LeadStack, CashCall Mortgage, and InterCap Lending) must evaluate vast amounts of historical data, client dossiers, and complex regulatory documents.
In these environments, utilizing LLM Shepherding and structured JSON prompting is vital. When an agentic workflow evaluates a 50-page financial disclosure to extract five key risk factors, returning the output as raw, conversational text consumes excess tokens and requires secondary processing to integrate into the CRM dashboard.
Forcing the model to output strict JSON not only compresses the output token count but enables seamless, programmatic ingestion directly into SQL Server databases, streamlining the entire automation pipeline and dramatically lowering per-document processing costs. As teams mature, many also move beyond simple chatbots toward action-oriented AI agents that can execute these workflows end to end instead of just summarizing documents.
Advertising, Gaming, and Telecom
For Innovative Marketing Directors in advertising and Heads of Sales in telecom, generative AI is used to craft highly personalized outreach, adjust site content dynamically, and generate varied ad copy.
In gaming, LLMs are increasingly used to generate non-player character (NPC) dialogue. These applications require massive output generation. Here, output compression techniques and instruction referencing are paramount. By caching the complex “persona” and “brand voice” system prompts using Amazon Bedrock or local memory stores, the application avoids re-sending the massive instructional payload for every single ad variation or line of dialogue, resulting in up to 90% savings on input tokens alone.
AI Governance, Compliance, and Future-Proofing
As these high-volume systems scale, the overarching governance framework dictates long-term cost viability. B2B organizations must establish clear maturity models for their AI stacks, moving from basic “Automation 1.0” rules to a predictive layer, and finally to “Actionable Intelligence”.
Technical leaders must continuously monitor auto-scaling GPU utilization, track token usage per user or feature for strict cost attribution, and enforce non-negotiable data privacy standards (such as GDPR, SOC 2, and HIPAA) to ensure that the drive for cost efficiency does not inadvertently compromise security or compliance. In practice, this often means adopting a 90/10 human-in-the-loop model, where automation does the bulk of the work but humans still review high-risk output—a pattern explored in depth in Baytech’s research on 90% automation, 10% humanity as the winning AI trust architecture.
Conclusion: The Mandate for Financial Stewardship in AI
The rapid proliferation of Generative AI represents a fundamental paradigm shift in software capabilities, but it brings an equally disruptive and often painful shift in software economics. Exorbitant API bills are rarely the result of inherently overpriced models; rather, they are the direct symptom of brute-force, unoptimized engineering. Treating every single user interaction as an opportunity to invoke the most complex, expensive reasoning engine on the market is architecturally lazy and financially unsustainable.
To achieve meaningful ROI and demonstrate true financial stewardship to the executive board, technical leaders must transition from treating LLMs as infallible magic boxes to managing them as highly measurable, rigorously optimizable computing resources. By implementing sophisticated LLM cascading protocols, organizations can route traffic intelligently, reserving premium token expenditures strictly for high-value, complex reasoning tasks. The deployment of robust semantic caching frameworks, backed by highly performant vector databases like pgvector on hyperconverged infrastructure such as Harvester, further truncates costs by completely eliminating redundant computation. Finally, applying strict prompt compression techniques ensures that every payload delivered to an LLM operates at maximum information density. For CFOs and CTOs weighing build versus buy decisions, this is exactly the kind of disciplined engineering that turns AI from a cost center into a strategic asset, echoing the findings in Baytech’s analysis of the Vibe Coding trap and hidden AI costs.
Ultimately, cost-effective AI is not achieved merely by waiting for cloud providers to lower their prices or by choosing inferior models. It is achieved by engineering smarter, leaner, and more adaptive systems.
Frequently Asked Question
How do we optimize AI for high-volume applications?
Optimizing AI for high-volume enterprise applications requires a multi-layered architectural approach that minimizes redundant processing and heavily restricts unnecessary token consumption.
First, implement Semantic Caching utilizing a highly performant vector database (such as the pgvector extension natively within PostgreSQL) to store and instantly retrieve responses to previously answered questions. This strategy can successfully handle 60% to 80% of repetitive application traffic, returning answers in milliseconds without incurring any external API costs.
Second, utilize LLM Cascading (Dynamic Routing) to build a decision-tree system that automatically directs simple, low-complexity tasks to highly efficient, low-cost models (such as GPT-5 nano or a locally hosted open-source model). The system should only escalate the prompt to a premium reasoning model if the smaller model's confidence threshold drops below an acceptable level.
Third, employ rigorous Prompt Compression techniques, including relevance filtering, semantic summarization, and structured JSON formatting, to drastically reduce the number of redundant input tokens and restrict the verbosity of output tokens processed during every interaction.
Finally, deploying these robust systems on highly orchestrated, on-premise or hybrid hyperconverged infrastructure—like Harvester, Rancher, and Kubernetes—ensures that local, low-cost inference operations scale seamlessly with traffic spikes while maintaining strict data privacy and security.
Supporting Articles for Further Exploration
- https://medium.com/@agrawalss17.it/how-semantic-caching-cuts-llm-costs-by-70-a-practical-guide-469f19cfb5d2
- Optimize LLM response costs and latency with effective caching
- https://machinelearningmastery.com/prompt-compression-for-llm-generation-optimization-and-cost-reduction/
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.