
Stop Trusting Vector Search With Your Numbers
February 27, 2026 / Bryan Reynolds
Why Vector Search Fails at Math: Building SQL Agents for Accurate AI Reporting
The modern corporate boardroom is increasingly defined by a desire to converse seamlessly with enterprise data. Executives across industries—from visionary Chief Technology Officers and strategic Chief Financial Officers to driven Heads of Sales and innovative Marketing Directors—share a common operational dream: the ability to ask a conversational artificial intelligence a simple question and receive an immediate, mathematically exact answer. When a business leader asks, "What were our total sales last Q3 segmented by region?", they expect the AI to operate with the precision of a seasoned financial analyst. Instead, they are frequently met with confident, eloquently phrased hallucinations that completely misrepresent the company's financial reality.
This pervasive disconnect between executive expectations and AI output represents one of the most significant hurdles in enterprise technology today. The underlying cause of this failure is not a lack of intelligence within modern Large Language Models (LLMs), but rather a fundamental misapplication of data retrieval architectures. The prevailing methodology for grounding artificial intelligence in proprietary corporate data is Retrieval-Augmented Generation (RAG).
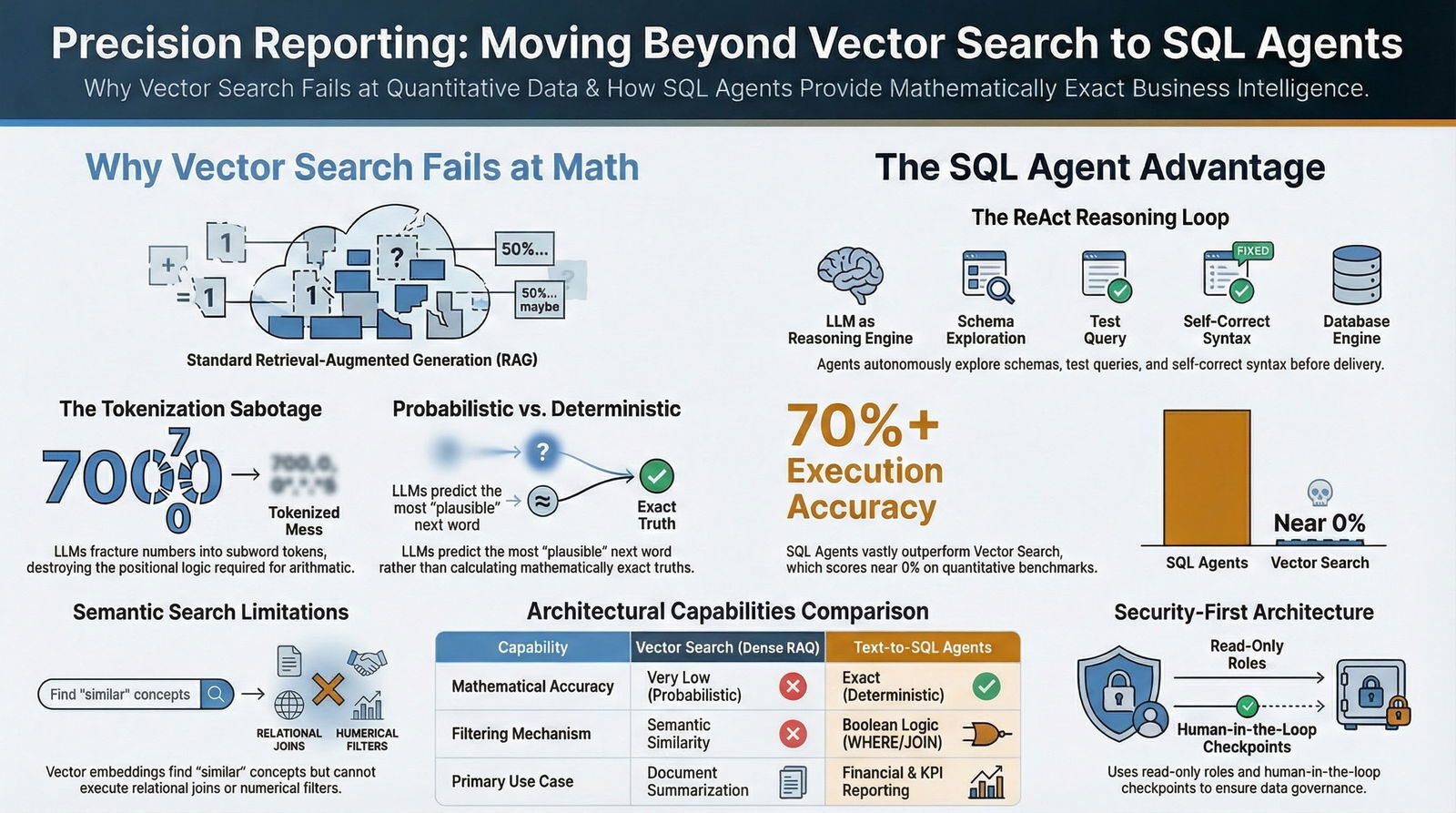
Standard RAG pipelines rely almost exclusively on vector databases to perform semantic, unstructured searches. While vector search is nothing short of revolutionary for summarizing fifty-page legal contracts, extracting policies from human resources handbooks, or navigating complex software documentation, it is structurally incapable of performing reliable mathematics, executing relational data joins, or computing multi-dimensional tabular aggregations.
For organizations specializing in custom software development and application management, navigating this architectural divide is a daily reality. Engineering teams—such as those at Baytech Consulting, where custom-crafted solutions are built on a foundation of a Tailored Tech Advantage and Rapid Agile Deployment—recognize that deploying a rudimentary vector database is wholly insufficient for accurate, enterprise-grade business intelligence. Delivering on-time, high-quality applications across robust infrastructures that utilize PostgreSQL, SQL Server, Kubernetes, and Azure DevOps On-Prem requires a paradigm shift. To achieve true database querying accuracy, developers must abandon the idea of forcing language models to guess numerical sums based on semantic text chunks and instead move toward an AI-native SDLC that treats LLMs as governed components in a larger system.
The industry is rapidly pivoting toward a highly orchestrated, deterministic approach: the deployment of "SQL Agents." By architecting autonomous systems that translate natural language directly into precise SQL queries, organizations can empower AI to bypass semantic guesswork, interact directly with relational databases, compute exact aggregations using the database engine, and return verifiable, mathematically flawless truths. This exhaustive report details the structural limitations of standard RAG pipelines for quantitative analysis, explores the deep technical roots of LLM mathematical failures, and provides a comprehensive, step-by-step blueprint for building, securing, and deploying enterprise-grade SQL Agents.
The Mathematical Limitations of Large Language Models
To fully comprehend why a multi-billion-parameter language model cannot reliably calculate a quarterly revenue report, one must examine the underlying mechanics of neural network text processing. Large language models, such as GPT-4, Claude 3.5 Sonnet, and open-source variants like LLaMA 3, are probabilistically optimized for linguistic fluency and next-token prediction, not for rule-based, deterministic precision.
They fundamentally lack an internal Arithmetic Logic Unit (ALU)—the core component of a traditional computer processor responsible for executing mathematical operations. Furthermore, LLMs do not possess an internal notion of variables, axioms, or mathematical operators with guaranteed semantics. These limitations echo the broader AI productivity paradox in software engineering, where raw speed does not always translate into reliable outcomes.
The Tokenization Problem
The most critical and technical root cause of the LLM mathematics problem lies in the pre-processing stage known as tokenization.
Before an LLM can analyze or generate any text, the input string must be broken down into smaller, numerical units called tokens. This is typically achieved using algorithms like Byte Pair Encoding (BPE), which are heavily optimized for the statistical frequency of human language, syllables, and common word fragments.
Tokenizers are explicitly not designed to respect the logical, positional structure of numerical digits.
While humans process numbers structurally by place value—instantly recognizing the distinct roles of thousands, hundreds, tens, and units—LLMs fracture digits into statistically determined subword tokens, effectively destroying the positional logic required for accurate arithmetic. This architectural design choice quietly sabotages mathematical operations in several distinct and compounding ways:
Inconsistent Splitting and Contextual Fracturing: LLMs lack a consistent, semantically meaningful tokenization strategy for arbitrary numerical strings. The exact same mathematical quantity can be fractured differently depending on the surrounding text. For example, the number "87439" might be encoded as two separate tokens (e.g., "874" and "39") in one specific context, but as entirely different tokens (e.g., "87" and "439") in another.
In some rare cases, it might be preserved as a single token. This inconsistency means the model has no stable internal representation of the number's magnitude.
Statistical Distortions from Formatting: Human conventions dictate that 12,345, 12345, and 12.345 (in European locales) represent the exact same integer value. However, to an LLM tokenizer, the inclusion of a comma, a space, or a decimal point fundamentally alters the statistical pattern.
Each distinct format produces a completely different token sequence, triggering different next-token probabilistic priors within the neural network.
- The Breakdown of Scientific Notation: The absolute mathematical equality between numerical variants like 0.007, 7.0e-3, and 7x10^-3 is not inherently encoded into the model's token embeddings. The model treats these as distinct linguistic phrases rather than equivalent mathematical values.
- The Erasure of Carry Chains: Arithmetic algorithms—such as addition or multiplication—rely heavily on long carry chains (e.g., carrying the "1" over to the tens column). Because tokenization strips away strict positional alignment, and because long carry chains are statistically rare in standard training text, the LLM cannot reliably execute multi-step mental math across disparate tokens.
Probability Versus Precision in Financial Data
When a generative AI model attempts to answer a mathematical question, it is not running a calculation; it is generating a sequence of tokens that looks statistically plausible based on the vast corpus of internet data it ingested during training.
However, the discipline of mathematics does not reward mere plausibility; it demands rigorous exactness.
Consider the task of computing compound interest on a revolving credit balance or converting basis points to percentage changes across multiple financial quarters. The unique, correct sequence of digits required to answer this query is an incredibly rare pattern in ordinary, conversational text.
Faced with the choice of generating a mathematically correct but statistically rare sequence, versus generating a highly common but mathematically incorrect sequence, the model will frequently default to the latter. The model will choose a pattern that reads correctly to a human observer, rather than the singular correct sequence required by an accounting ledger.
This probabilistic nature is precisely why highly confident, articulate paragraphs generated by a language model can still hide a single incorrect digit. In regulated settings—such as enterprise finance, real estate mortgage processing, healthcare administration, or compliance auditing—this failure mode is entirely unacceptable.
A single hallucinated number can fail a reconciliation process, trigger a severe compliance exception, or lead to disastrous strategic misallocations. Enterprise systems must compute exactly and must be able to transparently explain how they arrived at a specific figure, a theme that mirrors broader concerns around software development security, technical debt, and AI governance.
The Limitations of Vector Search (RAG) for Structured Data
To bridge the knowledge gap between a pre-trained LLM and a company's proprietary data, developers employ Retrieval-Augmented Generation (RAG).
Standard RAG pipelines are heavily dependent on vector databases. In this architecture, raw corporate data is ingested, chopped into smaller chunks, converted into dense numerical arrays called vector embeddings, and stored.
When an executive asks a question, the natural language query is similarly converted into a vector embedding. The system then utilizes K-Nearest Neighbors (KNN) or Approximate Nearest Neighbors (ANN) algorithms to calculate the numerical distance between the query vector and the stored data vectors, retrieving the chunks of text that are most "semantically similar" to the question.
This approach is highly robust for fuzzy, conceptual meaning. If an employee asks, "What is our policy on remote work?", the vector database will effortlessly retrieve paragraphs discussing telecommuting, working from home, and flexible schedules, even if the exact phrase "remote work" does not appear in the text.
However, this dense semantic mapping paradigm fails spectacularly when strict precision, relational mapping, or structured logic is required.
The Illusion of Semantic Aggregation
Consider a user querying a highly structured clinical trials database: "Show me all risks with severity > 5 for active oncology trials."
This query is fundamentally not about semantic similarity; it is about strict structural constraints, exact Boolean matches, and numerical filtering.
Dense vector embeddings do not inherently understand the mathematical operator "greater than 5," nor do they possess the relational logic required to perform a data join between an "Oncology" department table and a specific "Risk" tracking table.
If an enterprise system attempts to answer this query using a pure vector search approach, the vector database will simply retrieve random chunks of text that happen to mention the words "oncology," "risk," and "severity."
It will then feed these disconnected, unstructured paragraphs into the context window of the LLM. The LLM is then forced to read through the text and guess the aggregate count.
Because the LLM lacks an ALU, and because the retrieved chunks likely do not contain the entirety of the database rows, the model is guaranteed to make aggregation mistakes.
Furthermore, to mask its inability to calculate the answer, the LLM will often hallucinate entirely non-existent fields, invent relationships that do not exist, and fabricate customized code to justify its output.
Modern AI applications require a far more layered, sophisticated approach to address the inherent limitations of embedding models. When querying structured, transactional data where consistency and precision are paramount—such as financial records, inventory supply chains, or patient health records—the data is best organized into tables consisting of rows and columns, with relationships strictly defined by primary and foreign keys.
This is the domain of SQL databases, not vector databases, and it is also where disciplined Agentic Engineering practices become essential to keep speed from undermining long-term reliability.
When to Use Vector Search vs. SQL Queries
To build accurate, enterprise-grade AI reporting systems, technical leaders must architect intelligent routing layers that direct user queries to the appropriate analytical engine. Recognizing the hard boundary between unstructured semantic search and structured deterministic querying is the foundational principle of modern data architecture.
The Domain of Vector Search (Unstructured Data)
Vector search engines and semantic retrieval pipelines thrive in environments where data is messy, unstructured, narrative-driven, and highly qualitative. Vector search remains the optimal and superior choice for:
- Document Intelligence: Searching through massive repositories of unstructured text, such as employee handbooks, multi-page legal contracts, research whitepapers, or PDF reports.
- Fuzzy Concept Matching: Retrieving information based on conceptual alignment rather than exact keyword matches (e.g., finding documents related to "environmental sustainability initiatives" even if the exact terms are omitted).
- Conversational Knowledge Bases: Building chatbots that can explain corporate policies, summarize meeting transcripts, or provide qualitative insights from historical text data.
The Domain of Text-to-SQL (Structured Data)
SQL generation is the strictly required, non-negotiable approach when dealing with tabular datasets, strict database schemas, and definitive mathematical operations.
Text-to-SQL workflows are the optimal choice for:
- Time-Based Filtering: Extracting operational metrics constrained by specific, chronological periods (e.g., "Calculate revenue for the last month," "Show me Q3 2023 performance"). Relational databases utilizing time-series extensions, such as Timescale on PostgreSQL, excel at these exact chronological queries using functions like
time_bucket. - Aggregations and Mathematics: Calculating absolute sums, statistical averages, minimums, maximums, and standard deviations across tens of thousands or millions of structured rows.
- Relational Joins: Connecting disparate datasets accurately, such as cross-referencing a customer's demographic data in one table with their transactional history in a completely separate table.
The Tri-Hybrid and Graph Architectures
In practical, high-stakes enterprise deployments, executive questions rarely fall neatly into a single category; they frequently span both structured and unstructured domains simultaneously.
Consider the query: "What were the top five most discussed GitHub issues last month related to performance optimization?".
This complex query requires the deterministic power of SQL to handle the time filter ("last month") and the strict mathematical aggregation ("top five most discussed"), while simultaneously requiring the semantic nuance of vector search to identify topics related to the fuzzy concept of ("performance optimization").
Embedding search alone will fail to rank the top five accurately, while SQL alone will fail to identify the nuance of "performance optimization" if the exact string is not used.
To solve this, advanced engineering teams deploy Tri-Hybrid architectures that seamlessly blend multiple retrieval signals:
- Stage 1: SQL Filtering (The Literal Pass): The system first utilizes deterministic SQL to massively narrow down the dataset from millions of rows to thousands using exact literal matches (e.g., executing
WHERE department = 'oncology' AND status = 'active' AND date >= '2023-01-01'). - Stage 2: Vector Search (The Semantic Pass): The system then takes the strictly filtered, smaller dataset and performs a dense vector search to find semantically relevant unstructured chunks within that specific boundary.
- Stage 3: Sparse Reranking (The Precision Pass): Finally, the system utilizes sparse search algorithms (such as BM25, SPLADE, or ColBERT-style signals) to prioritize exact keyword matches, domain-specific terminology, product SKUs, and version numbers that dense vectors notoriously overlook. The final results are combined using Reciprocal Rank Fusion (RRF) or weighted scoring to dramatically improve both quality and recall.
Alternatively, some enterprises are exploring Graph-based RAG architectures (Knowledge Graphs). Tools like the WRITER Knowledge Graph or integrations within Elasticsearch use specialized LLMs to process data and build semantic relationships (nodes and edges) between disparate data points.
While Graph databases are ideal for modeling highly connected networks and complex relationships, SQL remains the gold standard for pure transactional consistency and mathematical aggregation.
The following table synthesizes the optimal applications for each technological approach across varying enterprise requirements:
| Architectural Capability | Vector Search (Dense RAG) | Text-to-SQL Agents | Hybrid / Knowledge Graph Systems |
|---|---|---|---|
| Primary Data Source Format | Unstructured text (PDFs, Word Docs, Emails) | Highly Structured (Relational DBs, Data Warehouses) | Multi-modal, Highly Connected & Relational |
| Mathematical Accuracy | Very Low (Highly prone to hallucination and estimation) | Exact (Relies deterministically on DB engine) | Variable depending on the underlying execution engine |
| Core Filtering Mechanism | Semantic Similarity (KNN/ANN distance metrics) | Deterministic Boolean logic (WHERE clauses, Joins) | Combined literal rules and semantic traversal |
| Handling of Complex Relationships | Poor (Often retrieves disconnected, out-of-context chunks) | High (Enforced via strict Primary/Foreign Keys) | Excellent (Native representation via Nodes and Edges) |
| Primary Enterprise Use Case | HR Policy lookup, legal text summarization, Q&A | Financial reporting, tracking KPIs, sales aggregations | Complex investigative research, fraud detection networks |
The Solution: Building Production-Ready SQL Agents
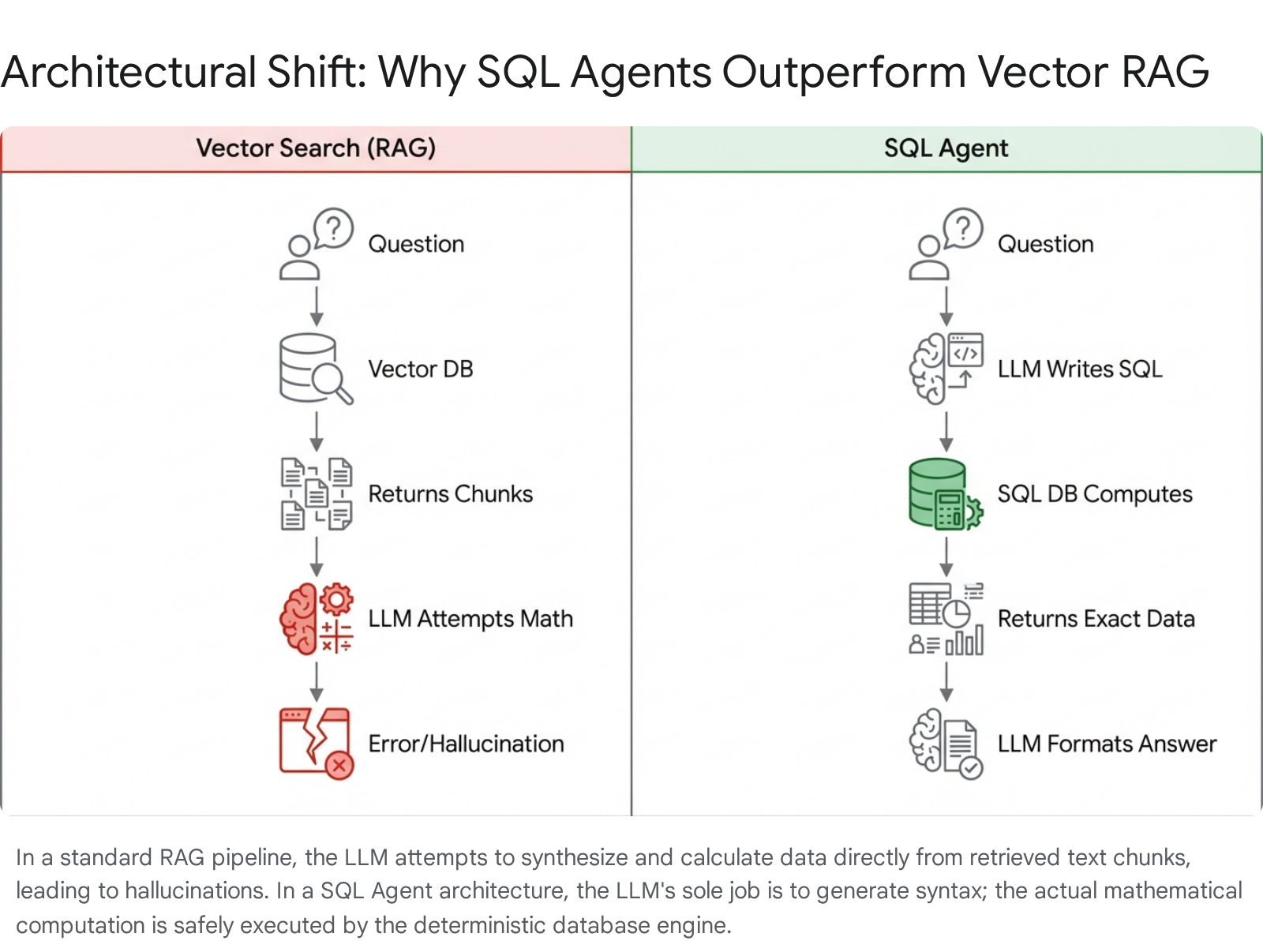
When enterprise business intelligence requires absolute deterministic accuracy rather than probabilistic text generation, the architectural solution is to completely remove the language model from the mathematical calculation process. Instead of asking the AI to compute the numerical answer, the system asks the AI to write the code that will compute the answer.
This is the foundational premise of a SQL Agent. A SQL Agent is a sophisticated orchestrator built on advanced AI frameworks like LangChain, LangGraph, or LlamaIndex.
It leverages a large language model not as a static repository of knowledge, but as a dynamic reasoning engine capable of interacting directly with a SQL database. Instead of relying on a fragile, single text-in, text-out API call, the agent operates utilizing a ReAct (Reason + Act) loop.
This iterative loop allows the agent to autonomously select predefined tools, explore the database schema, formulate and test queries, and self-correct syntax errors before ever presenting an answer to the human user.
By leveraging highly mature database technologies—whether standard relational systems like PostgreSQL and SQL Server, lightweight instances like SQLite, or advanced setups deployed across Kubernetes clusters—the SQL Agent offloads all the mathematical heavy lifting to the database engine where it belongs. The AI simply acts as a highly intelligent translator, converting the user's messy natural language intent into a structured, executable SQL dialect.
Core Architecture of a Production-Ready SQL Agent Workflow
Building a production-ready SQL agent involves moving far beyond simple, fragile "demo" scripts into a highly robust, multi-stage architecture. As frequently noted by industry data practitioners, most AI SQL agents fail in the real world for one simple reason: they are built like fragile demonstrations rather than careful orchestrations of reasoning, security, and tooling.
A truly production-ready SQL agent is a carefully orchestrated system that balances reasoning, memory, tooling, and delivery while operating on live enterprise data.
A robust implementation, particularly those utilizing the LangChain and LangGraph frameworks, relies heavily on providing the agent with highly specific, modular "hands" or tools. Each tool represents a single, well-scoped capability. Clear boundaries are critical because the model must autonomously decide when to use each tool based on its descriptive prompt.
The core workflow encompasses the following critical phases:
Phase 1: Tool Definition, Schema Extraction, and Grounding
An LLM cannot reliably query a database if it does not possess a flawless understanding of its underlying structure. A Text-to-SQL agent can only be as accurate as its understanding of the database schema.
The agent must begin its reasoning loop by fetching the available landscape programmatically.
Interaction with the database is managed via toolkits (such as the SQLDatabaseToolkit in LangChain).
- Listing Tables (
sql_db_list_tables): The agent initiates its investigation by utilizing a tool to extract a comprehensive list of all usable table names within the connected database. - Deciding Relevance: Based on the user's natural language question, the LLM's reasoning engine evaluates the fetched table list and deterministically decides which specific tables are relevant to formulate the answer. This prevents the model from attempting cross-joins on unrelated datasets.
- Schema and Sample Row Retrieval (
sql_db_schema): Once the relevant tables are identified, the agent uses a second tool to fetch the exact Data Definition Language (DDL) schemas, detailed column names, data types, and primary/foreign key relationships. Crucially, the agent also retrieves a small set of sample rows (e.g.,LIMIT 3). Providing sample rows is an essential industry best practice; it helps the model definitively understand the formatting of categorical variables (e.g., understanding whether aStatuscolumn uses the string "Active", the integer "1", or the character "A").
Phase 2: System Prompt Governance and Query Generation
Equipped with the highly specific schema context, the agent proceeds to write the SQL query.
This step is heavily governed by a meticulously engineered System Prompt. In production environments, the system prompt is not merely a polite persona description; it acts as strict operational policy and unbreakable governance.
A production-grade system prompt enforces critical operational rules:
- Data Limitation: Instructions to explicitly limit result sets (e.g., mandating the inclusion of
LIMIT 100clauses) to prevent massive memory overloads that could crash the application. - Strict Security Guardrails: Absolute prohibitions against generating any Data Manipulation Language (DML) statements. The prompt must dictate that the agent never attempts to execute
INSERT,UPDATE,DELETE, orDROPcommands. - Dialect Specificity: Directives to strictly utilize the specific SQL dialect natively supported by the connected system, whether the backend is a lightweight SQLite database, an enterprise SQL Server, a PostgreSQL instance, or a specialized data warehouse like Snowflake.
- Failure Recovery Instructions: Explicit guidance on how the agent should recover from failure (e.g., "If a query fails, fetch the schema again to verify column names and retry execution once").
Phase 3: Execution, LLM Self-Correction, and Response Synthesis
The primary differentiator of an intelligent "Agent" over a static script is its profound ability to recover gracefully from failure.
- Pre-Execution Syntax Checking (
sql_db_query_checker): Before execution, the agent can optionally route the drafted query through a checker tool, utilizing the LLM to double-check its own work for common syntax errors, faulty join logic, missing filters, or non-optimal subqueries. - Execution and Iteration (
sql_db_query): The finalized query is executed against the database via the execution tool. If the database engine returns an error (for instance, a "column does not exist" error because the model hallucinated a field), the agent does not immediately fail and return an error to the user. Instead, it captures the raw error string, reasons about why the query failed, reviews the provided schema context again, rewrites the SQL to correct the mistake, and attempts execution a second time. - Synthesis and Formatting: Once the database engine processes the calculation and returns a successful, mathematically exact data payload, the agent transitions to its final step. It formulates a natural language response, weaving the precisely calculated figures into a highly conversational, easy-to-understand answer for the end-user.
Safely Integrating AI with a SQL Database: Security and Governance
The prospect of granting an autonomous, non-deterministic artificial intelligence direct querying access to a live enterprise SQL database rightfully triggers severe security, privacy, and compliance concerns among Chief Information Security Officers. Relying solely on a system prompt that explicitly tells an LLM to "never delete data" is dangerously insufficient; prompt injection attacks or unexpected model hallucinations can easily bypass such semantic instructions.
In a production AI SQL agent, every LLM-generated query must be treated as an untrusted input. Hard security boundaries must be enforced at the architectural and database engine levels.
The Principle of Least Privilege and Read-Only Enforcement
The foundational, non-negotiable rule of Text-to-SQL architecture is that the application must never supply the agent with administrative or superuser credentials. The agent must connect to the database utilizing dedicated, highly restricted roles.
- Read-Only Roles at the Gateway: The connection string configured in the application layer must utilize a specifically tailored role (e.g.,
rag-reader) that has been explicitly and irrevocably denied access toINSERT,UPDATE,DELETE,ALTER, andDROPcommands at the core database engine level. Starting with advanced, modern enterprise systems like Oracle AI Database 26ai or hardened PostgreSQL configurations, administrators can definitively control read-write session states at the infrastructure layer, completely overriding any rogue commands attempting to alter the database irrespective of the connected user's higher-level privileges. - Strict Role-Based Access Control (RBAC): Access should be rigorously governed by the principle of least privilege. The AI must only be granted permission to view the exact tables, views, and schemas strictly necessary for its intended business function.
Schema Curation and Context Exposure Best Practices
Exposing an entire raw enterprise data warehouse schema to an LLM is a guaranteed recipe for catastrophic context overload, degraded performance, and severe hallucinations. If a database contains 2,000 highly complex tables, feeding the entire data definition into the model's prompt exceeds token limits and deeply confuses the model's relational join logic.
The lack of context can lead to incorrect assumptions when the AI faces an abundance of raw data.
- View Creation for Simplification: Instead of exposing raw, messy base tables, skilled data engineering teams must create highly curated SQL Views. Views encode complex business filters, pre-calculate frequently used specific metrics, and abstract away irrelevant backend system columns (like internal database IDs or timestamps). This presents a pristine, heavily simplified interface for the LLM to query, acting as an essential data curation layer and echoing the same disciplined approach used when designing scalable headless CMS architectures for content.
- Quarantining Private Schemas: Highly sensitive organizational data must remain strictly quarantined in isolated "private" schemas. These schemas should be entirely inaccessible to the agent's broad querying tools, ensuring that sensitive information can only be retrieved through heavily monitored, secure server-side functions that the AI cannot directly manipulate.
- Vectorized Schema Retrieval for Massive Databases: For massive, enterprise-scale databases, the table schemas and data definitions themselves should be embedded into an intermediary vector database (such as ChromaDB). When an executive asks a question, the system first performs a rapid semantic search over the schema metadata to retrieve only the 3 to 5 most relevant table structures. It then passes only those strictly limited definitions into the Text-to-SQL prompt, preserving the token window and drastically focusing the model's attention.
PII Redaction, Compliance, and Multi-Agent Collaboration
In heavily regulated industries governed by strict compliance frameworks (such as healthcare HIPAA regulations or financial data privacy laws), Personally Identifiable Information (PII) must be rigorously protected throughout the AI workflow.
- Server-Side Masking: Redaction must occur securely at the database level before the payload ever reaches the LLM application layer. Data engineers can encode data masking functions and business filters directly into the curated SQL views.
- Multi-Agent Redaction Architectures: Highly advanced enterprise architectures leverage secondary, specialized AI agents to handle compliance. Before any generated query is executed, a dedicated "Compliance Checker Agent" evaluates the raw SQL string for potential PII exposure vectors and submits a formal compliance verdict. Additionally, an automated "PII Redaction Agent" can seamlessly scan and sanitize the final result sets, automatically replacing names or sensitive IDs before the data is formulated into the final natural language response.
Human-in-the-Loop (HITL) Validation Workflows
For high-stakes operational decision-making, fully autonomous execution of AI-generated queries is often an unnecessary and unacceptable risk. The most robust enterprise deployments prioritize human oversight. Modern agentic frameworks like LangGraph natively support HumanInTheLoopMiddleware integrations.
This sophisticated architecture allows the SQL agent to formulate the database query and then immediately pause its internal execution loop, entering an "interrupted" or holding state.
The raw, proposed SQL query is then surfaced to a human data analyst or business stakeholder via an integrated dashboard or messaging interface (such as Microsoft Teams). The human reviewer can meticulously inspect the exact query, modify the logic if necessary to correct subtle domain-specific errors, and manually approve the execution command to resume the flow.
This human-centric checkpoint provides total operational transparency, effectively eliminating the "black box" anxiety commonly associated with AI reporting systems.
By logging every interaction and maintaining a human validation loop, enterprises ensure correctness while tracking performance to identify persistent errors.
Real-World Benchmarks: The State of Text-to-SQL Accuracy in 2026
The transition of AI from theoretical, sandbox architecture to mission-critical production deployment requires rigorous, empirical evaluation. Technical leaders must ask: How accurately can modern, frontier Large Language Models actually generate complex SQL from messy, natural language queries?
Measuring Accuracy: Spider versus the BIRD Benchmark
Historically, researchers and developers relied on the "Spider" dataset to evaluate text-to-SQL capabilities. While useful in the early days of AI, Spider's relatively simplistic schemas no longer accurately reflect the immense complexity of real-world enterprise databases.
The new, universally accepted gold standard for evaluating these systems is the BIRD benchmark (BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation).
BIRD is a pioneering, cross-domain dataset that rigorously examines the impact of extensive database contents on parsing capabilities.
BIRD encompasses over 12,751 unique question-SQL pairs mapped across 95 massively large databases totaling 33.4 GB in size.
Crucially, it covers more than 37 highly complex professional domains, including blockchain, healthcare, hockey statistics, and education.
The benchmark fundamentally measures "Execution Accuracy" (EX)—whether the AI-generated SQL query, when executed against the database, returns the exact same mathematical data payload as the human-written, ground-truth SQL query.
Current state-of-the-art benchmark results underscore the profound complexity of the Text-to-SQL challenge. While human analysts can achieve extremely high accuracy given sufficient time and domain context, leading frontier AI models currently hover around 70% execution accuracy on the complex BIRD benchmark when utilized out-of-the-box.
| AI Model / System Approach | BIRD Execution Accuracy (Approximate) | SPIDER Execution Accuracy (Approximate) |
|---|---|---|
| GPT-4o (Zero-shot baseline) | ~60% | ~85% |
| Claude 3.5 Sonnet | ~65% | ~86% |
| SOTA Text-to-SQL Agentic Systems (e.g., Qwen-Coder integrations) | ~68% - 72% | ~88% |
| Pure Vector Search (RAG) on quantitative queries | 0% - 10% | N/A |
Table Note: Execution accuracy is highly dependent on schema complexity, the presence of multi-table joins, and whether domain-specific few-shot examples are provided within the prompt context. Data is synthesized from recent, state-of-the-art BIRD leaderboard reports and published benchmark analyses.
Addressing the Accuracy Gap
The benchmark data clearly illustrates a critical industry reality: while Text-to-SQL generation is not yet perfectly flawless, it is functionally highly viable and astronomically superior to the near-zero quantitative accuracy of pure Vector Search models when processing mathematical or relational queries.
When analyzing LLM-generated SQL, models frequently make four primary types of errors: faulty join logic (misidentifying necessary JOIN operations), aggregation mistakes, missing conditional filters, and general syntax errors.
However, execution accuracy can be driven significantly higher—approaching 90% or more in tightly controlled, real-world enterprise environments—through meticulous architectural engineering.
Organizations achieve these superior results by implementing comprehensive data curation strategies, utilizing customized contextual LLMs, providing the model with highly specific corporate dictionaries, and establishing strict operational guardrails. This is the same discipline that separates quick "vibe coding" experiments from sustainable systems, as explored in depth in the Vibe Coding Trap analysis of long-term total cost of ownership.
By fine-tuning smaller, off-the-shelf models or initializing Reinforcement Learning on specifically curated datasets, developers can turn noisy data into highly meaningful training signals, vastly improving query precision.
Real-World Enterprise Applications and Case Studies
Organizations across the globe are rapidly migrating these intelligent agents from experimental data science sandboxes into critical, daily operational workflows, achieving measurable improvements in efficiency and insight discovery.
Finance and Investment Analysis: In the fast-paced world of investment finance, Chief Financial Officers and financial analysts are utilizing highly secure SQL agents to rapidly interrogate complex financial histories. Specialized multi-agent architectures are deployed to parse unstructured 10-Q regulatory reports alongside highly structured historical fund performance metrics stored in SQL databases.
These systems instantly combine narrative context with exact financial aggregates to produce cohesive, mathematically accurate due diligence reports, mitigating disruptions and maximizing operational value. For CFOs wrestling with how AI-generated code impacts balance sheets and audit risk, this ties directly into the guidance laid out in the CFO’s playbook for AI code governance.
Sales and Marketing Optimization: Innovative Marketing Directors and driven Heads of Sales leverage SQL agents to track campaign performance dynamically, entirely bypassing the bottleneck of waiting on busy data engineering pipelines. Queries such as, "Calculate the exact ROI and distinct conversion rates for the Q4 promotional campaign, segmented by geographical region," are effortlessly translated into complex SQL aggregations across multiple Customer Relationship Management (CRM) tables instantly.
This allows businesses to seamlessly track website traffic by campaign, segment high-value customers based on spending patterns, and quickly calculate precise ROI metrics for ad promotions, especially when combined with predictive AI models that forecast revenue impact.
Retail and E-commerce Customer Retention: In highly competitive retail markets, understanding customer behavior is paramount.
Businesses deploy SQL agents to analyze purchasing patterns dynamically. A Sales Director can ask an agent to "Identify high-value customers who have spent more than $500 but have churned in the last six months, and segment them by previous purchase frequency".
The agent retrieves exact customer IDs and total spending aggregates, enabling highly targeted, personalized retention campaigns and maximizing customer lifetime value without requiring a data scientist to write complex
GROUP BYclauses.Operations and Back-Office Automation: Beyond customer-facing metrics, SQL agents are revolutionizing back-office operations.
From automating complex invoice matching against historical supply chain data to parsing receipt processing and validating multi-dimensional data consistency, AI agents drastically reduce manual employee workloads.
In customer service environments, providing immediate, accurate access to critical, structured customer records through agentic AI has proven to significantly increase response quality and boost overall customer experience. Pairing these agents with modern DevOps efficiency practices ensures that new capabilities can be deployed, monitored, and iterated on quickly without sacrificing stability.
Strategic Conclusion and Next Steps
The promise of conversational artificial intelligence in the enterprise is unequivocally real, yet it has been severely hindered over the past several years by a fundamental, architectural misapplication of technology. Forcing a language model—a system built on probabilistic word prediction—to perform strict mathematical calculations using fuzzy semantic search is an architectural dead-end. Generative models are brilliant engines of reasoning, translation, and text synthesis; they are not reliable calculators.
By deploying sophisticated SQL Agents, organizations correctly align the technology with its inherent strengths. The LLM handles the complex task of translating messy human intent into structured syntax, while the underlying, hardened SQL database engine performs the exact mathematical filtering, aggregation, and relational joining it was built to execute.
This profound paradigm shift—when supported by robust security protocols, read-only database roles, human-in-the-loop checkpoints, and highly curated data schemas—transforms AI from a creative novelty prone to hallucination into a highly accurate, trustworthy, and deterministic reporting tool.
For strategic business leaders across the B2B landscape—whether visionary CTOs managing infrastructure, strategic CFOs requiring precise revenue figures, or driven marketing directors seeking instant ROI analysis—the operational next steps are definitive:
- Audit Current AI Implementations Immediately: Evaluate all existing internal chat tools and AI pilots. If your organization relies purely on Vector Search (RAG) to answer financial, performance, or numerical questions, you are actively exposing the business to severe hallucination risks and compliance violations.
- Curate the Enterprise Data Layer: Before adopting any text-to-SQL tooling, internal data engineering teams must rigorously prepare the database backend. Build pristine, simplified SQL Views, implement strict Role-Based Access Controls, and isolate PII into secure schemas. AI agents are fundamentally only as intelligent and accurate as the database schema they are allowed to read. This data-first discipline also underpins modern AI “walled garden” strategies for corporate data sovereignty.
Deploy a Controlled Proof of Concept: Begin by deploying a LangChain or LangGraph-based SQL Agent against a low-risk, non-sensitive dataset. Start small and incrementally expand.
Implement human-in-the-loop middleware to rigorously monitor how accurately the LLM interprets your specific business jargon into complex SQL joins, logging every interaction to identify errors.
The competitive advantage in the next decade will no longer belong solely to the firm that possesses the largest data warehouse; it will belong decisively to the firm that empowers its workforce to converse with that massive data asset instantly, accurately, and safely—and does so with clear, governed engineering patterns instead of ad‑hoc "vibe coding." As many CFOs are already discovering in the vibe coding revolution and renewed build‑vs‑buy debate, the organizations that treat AI as an engineered capability, not a toy, will pull ahead fastest.
Frequently Asked Questions
Why does ChatGPT get math questions wrong? ChatGPT and similar Large Language Models (LLMs) are architecturally built to predict the next logical word in a sentence based on statistical probabilities, not to perform rigid mathematical arithmetic. The way these models process raw text—a process known as tokenization—breaks numerical digits into arbitrary, unpredictable subword chunks. This fracturing actively destroys the strict positional logic (like place values and carry chains) required for accurate arithmetic calculations. Consequently, while they excel at generating text that sounds highly plausible, they fundamentally lack an internal calculator, leading them to confidently guess incorrect numbers.
How do you safely let AI query a SQL database? Safety requires implementing strict, uncompromising boundaries at the database infrastructure level, not merely writing instructions in the AI's prompt. Best practices mandate using a dedicated, read-only database user role (e.g., rag-reader) that is explicitly denied the ability to insert, update, delete, or alter any data at the engine level. Furthermore, database administrators should never expose the raw, complex database structure to the AI; instead, they must create simplified, curated "Views" that hide sensitive Personally Identifiable Information (PII) and pre-calculate complex business logic. Finally, utilizing Human-in-the-Loop (HITL) middleware allows a human analyst to review and manually approve the AI's generated SQL query before it is ever executed against the live data. This is similar in spirit to how disciplined teams approach Agile methodology with built-in review and feedback loops.
When should I use Vector Search vs. SQL queries? Use Vector Search (RAG) when querying massive collections of unstructured text documents—such as employee manuals, legal contracts, and PDF reports—where the primary goal is to find thematic, qualitative, or semantic similarities without requiring exact keyword matches. Conversely, you must use SQL queries (via AI SQL Agents) when dealing with structured, tabular data that requires absolute mathematical precision. SQL is the definitive choice for calculating total sales, performing time-based filtering ("last Q3"), executing multi-table joins, or counting specific operational occurrences. When a complex user question spans both domains, advanced systems use hybrid architectures to combine initial SQL filtering with subsequent vector context.
Supporting Articles
- https://docs.langchain.com/oss/python/langchain/sql-agent
- https://www.tigerdata.com/blog/rag-is-more-than-just-vector-search
- https://moveo.ai/blog/why-llm-struggle
- https://www.baytechconsulting.com/blog/unlocking-ai-software-development-2026
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.