
Mastering the AI Code Revolution in 2026: Unlock Faster, Smarter Software Development
January 14, 2026 / Bryan ReynoldsExecutive Summary: The AI Productivity Paradox

The software engineering industry stands at a critical juncture in 2025/2026. We have moved past the initial phase of novelty and experimentation with Artificial Intelligence coding assistants into a period of mass adoption and, paradoxically, growing disillusionment. The narrative that dominated the early 2020s—that Generative AI would serve as a friction-free accelerant for software delivery, democratizing coding and exponentially increasing velocity—is colliding with a more nuanced, rigorous, and often contradictory reality. This report, prepared specifically for Baytech Consulting, aims to dissect this "AI Productivity Paradox" through an exhaustive analysis of the latest empirical data, including the landmark METR 2025 randomized controlled trial, telemetry data from millions of Pull Requests (PRs) via Jellyfish, and wide-ranging industry surveys from Stack Overflow and GitHub.
The overarching finding of this investigation is that AI coding assistants are not a monolithic accelerator. Instead, they function as a highly variable lever that amplifies velocity in specific contexts while actively degrading performance in others. The data reveals a bifurcation in outcomes driven by task complexity, developer seniority, and the inherent limitations of probabilistic models in handling deterministic logic.
On one side of the ledger, we observe undeniable gains in specific metrics. Data from Jellyfish indicates that organizations achieving high adoption rates of tools like GitHub Copilot and Cursor have seen median PR cycle times drop by as much as 24%. 1 For routine tasks, boilerplate generation, and syntax discovery, these tools effectively eliminate the "blank page problem," allowing developers to maintain flow and ship code faster. For teams optimizing DevOps efficiency, these cycle time improvements can make or break release schedules.
However, a darker narrative emerges when we examine the performance of experienced developers working on complex, real-world systems. The METR 2025 study provides the most rigorous evidence to date of an "efficiency illusion." In a randomized controlled trial involving seasoned open-source contributors working on their own mature repositories, the use of AI tools resulted in a 19% net slowdown compared to unassisted work. 2 This slowdown was masked by a profound psychological effect: despite taking longer, participants believed they were working 20% faster, highlighting a dangerous disconnect between perceived effort and objective reality. 4
This report explores the mechanisms behind this slowdown, identifying the "hidden taxes" of AI adoption: the cognitive load of context switching between coding and prompting, the "reviewer's burden" of verifying plausible-but-incorrect code, and the introduction of subtle, high-severity defects such as race conditions and security vulnerabilities that traditional testing frameworks struggle to catch. We also examine the cultural impact, including the degradation of trust—dropping to just 29% in 2025 5 —and the perverse incentives created by leadership teams tracking "commit volume" rather than business outcomes.
Ultimately, the goal of this report is to provide Baytech Consulting with a strategic framework. We argue that the winning organizations of the next decade will not be those that simply "turn on" AI, but those that implement a bimodal strategy: aggressively leveraging automation for low-risk, high-volume tasks while enforcing strict human oversight and "slow thinking" protocols for the architectural core.
Part I: The State of the Ecosystem (2025-2026)
1.1 The Ubiquity of Usage vs. The Crisis of Trust
By late 2025, the debate over whether developers would use AI had effectively ended, replaced by a complex reality of ubiquitous but skeptical adoption. The 2025 Stack Overflow Developer Survey and GitHub's Octoverse report provide definitive proof that AI coding assistants have graduated from experimental novelties to essential infrastructure. The data indicates that 84% of developers are now utilizing AI tools in their workflows, with over half (51%) relying on them daily. 6 This level of saturation places AI coding assistants in the same category of ubiquity as the Integrated Development Environment (IDE) or Version Control Systems (VCS)—tools that are no longer optional for modern software delivery.
However, a granular examination of developer sentiment reveals deep structural cracks in this foundation of usage. While adoption metrics have climbed, the enthusiasm that characterized the 2023-2024 "boom" years has significantly dampened. Positive sentiment toward AI tools decreased in 2025, dropping from over 70% in previous years to roughly 60%. 8 Even more alarmingly, the core metric of engineering reliance—trust in the accuracy of the output—has plummeted. In 2025, only 29% of developers reported trusting the accuracy of AI-generated code, a sharp and concerning decline from the 40% levels seen in prior years. 5
This phenomenon, which we might term the "Trust Gap," is not merely an emotional or luddite reaction to new technology. It is an empirical response to the changing nature of developer work. As AI models have become more sophisticated and confident in their tone, they have arguably become harder to verify. The Stack Overflow survey highlights that the number-one frustration for 45% of respondents is dealing with "AI solutions that are almost right, but not quite". 5 This creates a scenario often described as the "Uncanny Valley of Code." In this valley, the code looks syntactically perfect and architecturally plausible, yet contains subtle, functional defects that require deep expertise to uncover. The developer is thus forced to transition from a "creator" mindset to a "forensic auditor" mindset—a shift that many find both exhausting and inefficient. For teams intent on optimizing developer happiness and productivity, acknowledging and addressing these trust gaps is now non-negotiable.
1.2 The Feedback Loop: Python's Ascension and AI's Influence
The rise of AI has also begun to exert a gravitational pull on the very languages and ecosystems developers choose to employ. The 2025 data shows that Python's adoption accelerated by a remarkable 7 percentage points year-over-year. 8 While Python has long been on a growth trajectory due to data science, this sudden acceleration in general-purpose development suggests a feedback loop: AI models, having been heavily trained on Python-rich repositories, perform best when generating Python code. Developers, seeking to maximize the utility of their AI tools, are subconsciously or consciously migrating toward the languages where the "AI friction" is lowest, as detailed in recent research into AI-native IDEs like Google Antigravity.
This homogenization of the tech stack has implications for the diversity of the software ecosystem. As developers coalesce around "AI-friendly" languages, we risk a stagnation in languages that are less represented in the training data, potentially stalling innovation in niche or emerging paradigms that the AI models do not "understand" well.
Furthermore, the nature of "contribution" itself is changing. GitHub reports a 29% year-over-year increase in merged pull requests. 9 On the surface, this looks like a productivity boom. However, when viewed alongside the "trust gap" data, it raises the specter of "commit inflation"—a scenario where the ease of generating code leads to larger, more frequent PRs that may lack the rigorous thought process of manually crafted solutions. We are seeing a surge in volume, but the density of value per commit remains an open question.
Part II: The Efficiency Illusion – Deconstructing the METR Study
In an industry often driven by hype cycles and vendor-sponsored case studies claiming "55% speed improvements," the randomized controlled trial (RCT) conducted by METR (Model Evaluation & Threat Research) in 2025 stands as a watershed moment for empirical software engineering research. It provided a sober, scientific counter-weight that has forced engineering leaders to recalibrate their expectations regarding AI and developer velocity.
2.1 Study Methodology: A rigorous Test of Reality
The METR study was designed to rigorously test the impact of early-2025 frontier AI tools—specifically Cursor Pro powered by Claude 3.5 and 3.7 Sonnet—on experienced developers working on real-world tasks. 3 The methodology distinguishes itself from typical benchmarks in several critical ways:
- Participants: The study recruited 16 highly experienced developers, each with an average of 5 years of tenure on the specific open-source repositories they were modifying. 3 These were not junior developers or students; they were "very serious professionals at a high skill level" working on projects with an average of 1.1 million lines of code and over 22,000 stars. 3
- Tasks: Instead of synthetic, isolated algorithmic puzzles (like LeetCode), the developers worked on 246 real-world issues—bug fixes, feature additions, and refactors—drawn directly from their project's backlog. 3 These tasks averaged two hours to complete and required navigating complex dependency trees, adhering to strict style guides, and satisfying the high quality standards of mature open-source projects.
- Design: The study utilized a randomized controlled trial design. Each task was randomly assigned to either an "AI Allowed" or "AI Disallowed" condition. In the allowed condition, developers had full access to state-of-the-art tools; in the disallowed condition, they worked manually. Screen recordings were captured and analyzed to decompose time usage. 3
2.2 The 19% Slowdown: Data vs. Perception
The results of the study were counter-intuitive to the prevailing narrative and shocked even the researchers.
- The Reality: Developers using AI tools took 19% longer to complete tasks than those working without them. 2 This was not a margin-of-error finding; it was a statistically significant drag on productivity for this demographic.
- The Perception: Despite being objectively slower, these same developers believed they were faster. In post-task surveys, developers estimated that the AI tools had provided a roughly 20% speedup. 4
- The Prediction: Prior to the study, participants had forecasted a massive 24% speedup. 4
This discrepancy—a 43-point gap between the predicted speedup (+24%) and the actual result (-19%)—constitutes one of the largest "Expectations Gaps" recorded in modern software engineering research. 2 It suggests a profound psychological disconnect: the AI tools made the work feel easier and faster, likely by reducing the tedious mechanics of typing, but they introduced invisible inefficiencies that ultimately extended the time-to-completion.
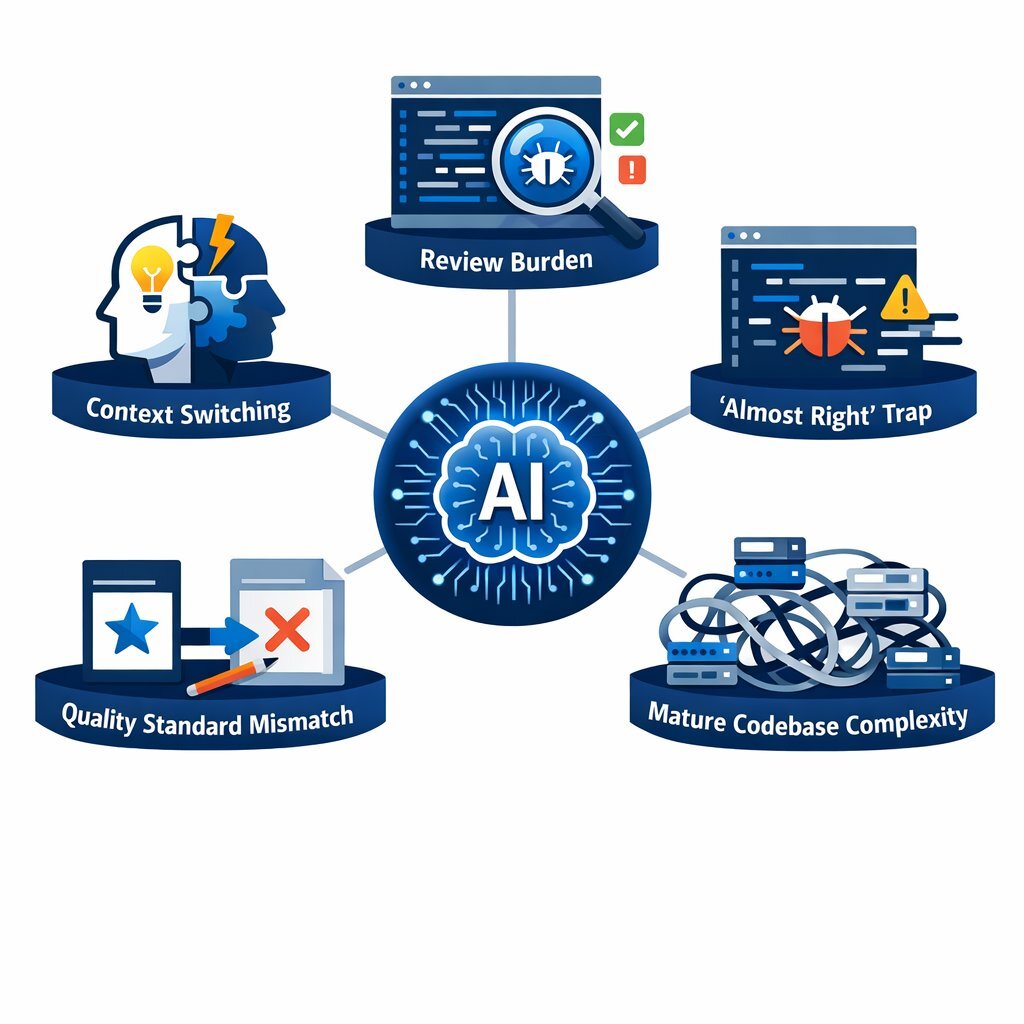
2.3 Deconstructing the Slowdown: The Five Factors of Friction
The study and subsequent analysis identified five primary factors driving this slowdown, which collectively describe the "friction of integration" inherent in AI-assisted workflows for complex tasks. 2
- The Context-Switching Tax: The most pervasive factor is the cognitive cost of switching between "coding mode" and "prompting mode." Flow state research indicates that context switching incurs measurable time penalties. When a developer stops to craft a prompt, waits for generation, reviews the output, and then integrates it, they are breaking their mental model of the code. 2 Screen analysis showed developers spending significant time "waiting" and "reviewing" rather than "doing". 3
- The Reviewer's Burden: In a manual workflow, the developer constructs the logic line-by-line, maintaining a continuous mental map of the state. In an AI workflow, the developer receives a block of code and must reverse-engineer the logic to verify its correctness. This "review" phase often takes longer than the "creation" phase, especially for experienced developers who type fast but read code critically. 3
- The "Almost Right" Trap: As noted in the Stack Overflow data, AI often produces code that is 95% correct. Finding the 5% error—a hallucinated library method, a subtle off-by-one error, or a security flaw—requires deep debugging. This is often more time-consuming than writing the code from scratch because the developer must first find the bug in code they didn't write. 5
- High-Quality Standards: The METR study focused on repositories with high standards for documentation, testing, and style. AI tools frequently struggle with implicit requirements (e.g., "we use this specific internal utility for logging, not the standard library"). Correcting the AI's stylistic and architectural deviations added significant overhead. The study noted that AI capabilities appeared "lower in settings with very high quality standards". 3
- Mature Codebase Complexity: On large, established codebases (averaging 1M+ lines of code), the AI lacks the "global context" that a senior developer has built over years. It suggests solutions that are locally valid but architecturally incoherent, forcing the developer to heavily refactor the suggestion. 12
These factors suggest that for senior developers, the bottleneck is rarely typing speed—it is decision-making, context gathering, and verification. AI tools, in their current state, accelerate typing but often obstruct the other, more critical processes. This reality is especially evident for organizations striving to evaluate software solutions and technology proposals for technical excellence.
Part III: The Velocity Reality (The Jellyfish Metrics)
It would be intellectually dishonest to present the METR findings as the total truth of the AI experience. While the RCT highlights the risks for experts on complex tasks, broader market telemetry offers a counter-narrative of acceleration. Data from Jellyfish, which analyzes engineering signals across millions of PRs, paints a picture of substantial gains when the lens is widened to include different types of work and teams.

3.1 Cycle Time Reductions in High-Adoption Teams
Jellyfish's analysis of data from July 2024 to June 2025 shows a clear, positive correlation between high AI adoption and reduced Pull Request (PR) cycle times. The data indicates that PRs tagged with "high AI use" (defined as authors utilizing AI 3+ times a week) had cycle times that were 16% faster than tasks performed without AI. 13
This acceleration effect appears to compound at the organizational level. Companies that successfully managed a transition from 0% to 100% adoption of coding assistants saw their median cycle time drop by 24% (from 16.7 to 12.7 hours). 1 This suggests that once a team overcomes the initial learning curve and integrates the tools into their CI/CD and review processes, a systemic lift in velocity is achievable, as explored in recent risk strategies for software investments.
3.2 The Paradox of "More Bugs, Faster Fixes"
An interesting nuance in the Jellyfish data is the relationship between velocity and quality. Companies with higher AI use were found to "merge more PRs" and push more bug fixes. Specifically, 9.5% of PRs at high-adoption companies were bug fixes, compared to only 7.5% at low-adoption companies. 1
This statistic can be interpreted in two ways:
- The Optimistic View: AI helps teams identify and fix bugs faster, leading to a more robust product.
- The Pessimistic View: AI generates more buggy code, necessitating a higher volume of "fix" PRs to clean up the mess.
Given the METR findings on the "almost right" nature of AI code, it is plausible that the increased velocity is partially offset by an increased rate of rework—a classic case of "moving fast and breaking things."
3.3 Reconciling METR and Jellyfish: The Complexity Variable
How do we reconcile a 19% slowdown in the METR study with a 16-24% speedup in the Jellyfish data? The answer lies in the variables of task complexity and developer seniority .
- The Junior/Boilerplate Boost: Studies indicate that junior developers and those new to a language see the highest gains (21% - 40% productivity boost). 14 For these developers, the bottleneck is often syntax knowledge and API discovery—areas where AI excels. They are also more likely to be working on isolated, lower-complexity tasks (e.g., "create a new API endpoint") where context requirements are lower.
- The Senior/Complexity Drag: The METR study focused exclusively on experienced developers working on complex tasks. For seniors, the bottleneck is system architecture and requirements gathering. AI does not help with these constraints and adds the "review burden."
Therefore, the "average" speedup reported in broad market surveys is likely driven by the massive volume of low-complexity, boilerplate tasks where AI is a force multiplier. The slowdowns are concentrated in the "critical path" engineering—the deep logic that defines the system's reliability.
Part IV: The Hidden Costs – When AI Quietly Slows You Down
While the "time-to-complete" metric is the most visible indicator of slowdown, there are deeper, more insidious costs that accumulate over time. These are the factors that "quietly" slow down an organization by introducing technical debt, security vulnerabilities, and fragile logic that requires future rework. The "productivity" gained today is often borrowed from the "stability" of tomorrow, a lesson that's also central to profitable quality assurance practices in software development.
4.1 The Hallucination of Logic: Recursive Failures
One of the most persistent failure modes for AI coding assistants is complex algorithmic logic , particularly recursion. Large Language Models (LLMs) are probabilistic token predictors; they do not "understand" the halting problem, stack depth, or the mathematical guarantees required for a recursive function to terminate correctly.
Consider the case of generating a maze-solving algorithm or a file system traversal. Users report that while AI can generate the structure of a recursive function (base case + recursive step), it frequently fails on edge cases or termination logic, leading to infinite loops or stack overflow errors. 16
Case Study: The Recursive Trap
A developer attempting to use AI for an Advent of Code challenge noted that while the AI generated a recursive solution instantly, it failed to account for the specific performance constraints of the problem. The developer spent significantly more time debugging the stack overflow and optimizing the AI's "naive" recursion than it would have taken to implement a dynamic programming approach from the start.16 The AI's solution was "textbook correct" for a small example but "contextually wrong" for the actual dataset—a distinction that costs hours of debugging time. This exemplifies the "Verification Tax": the time spent proving the AI wrong often exceeds the time required to write the code right.
4.2 The "Race Condition" Blind Spot
Concurrency is arguably the most difficult aspect of software engineering, and it is here that AI tools show their most dangerous weakness. Race conditions—where the outcome of a process depends on the non-deterministic timing of other events—are often invisible to LLMs because they require understanding the temporal state of a system, not just the static text of a file. An LLM sees code as a sequence of characters; a developer must see it as a sequence of events in time.
Technical Example: The Bank Account Vulnerability
A classic example involves a "check-then-act" sequence in banking logic. Consider a function designed to process a withdrawal:
# AI Generated Concept
if account.balance >= withdrawal_amount: account.balance -= withdrawal_amount process_withdrawal() An AI tool might generate this code snippet as a valid solution for a withdrawal function. It is syntactically correct and logically sound in a single-threaded context. However, in a multi-threaded environment (like a web server handling multiple requests), two requests could pass the if check simultaneously before the deduction occurs. Both threads would "see" sufficient funds, and both would deduct the amount, leading to a double withdrawal and a negative balance. 17
While a senior developer knows to wrap this in a database transaction or use a mutex lock, the AI, training on vast amounts of unsecured tutorial code or simple scripts, often defaults to the simplest, non-thread-safe implementation. The cost of this slowdown is not paid during the coding phase—it is paid during the production outage, the emergency rollback, or the security audit weeks later.
4.3 Security Vulnerabilities: The Injection Protocol
Despite improvements, AI models continue to suggest insecure coding patterns. A 2025 analysis of AI-generated code found persistent issues with SQL Injection and Insecure File Handling .
- SQL Injection: AI tools frequently concatenate user strings directly into queries (e.g.,
"SELECT * FROM users WHERE name = '" + user_input + "'"), bypassing the parameterized queries that are standard security practice. 19 The model optimizes for "completing the string" rather than "securing the query." - Insecure File Uploads: Code generated for handling file uploads often contains multiple risks. It may blindly trust user-supplied filenames, exposing the server to path traversal attacks (such as accessing
/etc/passwd). Additionally, these snippets often lack validation for file types or extensions, which could allow for the upload of malicious executables. 19 - Hardcoded Secrets: Because LLMs are trained on public repositories, they have a tendency to hallucinate "placeholder" API keys or, worse, suggest patterns that encourage hardcoding credentials rather than using environment variables.
The "Quiet Slowdown" here is the Security Remediation Cycle . Code that is generated in seconds may require days of penetration testing and remediation to be made production-ready.
Part V: The Metrics Trap – Gaming the System
As organizations rush to measure the impact of their AI investment, they often fall into the trap of "Goodhart's Law"—when a measure becomes a target, it ceases to be a good measure. The ease of generating code has distorted traditional productivity metrics, leading to perverse incentives.
5.1 The Commit Volume Fallacy
With management pressing for "efficiency," some organizations have begun tracking "commits per developer per month" or "lines of code (LOC) generated." This is catastrophic in an AI era. AI allows developers to generate infinite lines of code with zero effort. We are seeing reports of developers "gaming" these metrics by committing verbose, AI-generated boilerplate that adds complexity without value. 20
One anecdotal report describes a developer who created an automated pipeline to commit minor changes to a repo every other day, purely to satisfy the "activity" metrics demanded by leadership. 20 This behavior, incentivized by poor metrics, creates a "Busywork Slowdown"—the codebase grows, the CI/CD pipelines slow down, and the review queues clog up, all while actual feature delivery stagnates. Teams seeking reliable agile software delivery should beware of these false incentives.
5.2 The True Metric: Cycle Time and DORA
The only reliable way to measure AI impact is through outcome-based metrics , specifically the DORA (DevOps Research and Assessment) framework:
- Deployment Frequency: Does AI help us ship smaller batches faster?
- Lead Time for Changes: Does the time from "commit" to "production" decrease?
- Change Failure Rate: This is the critical counter-balance. If AI makes us faster but breaks production more often (due to the verification gap), we are not actually productive.
Jellyfish data supports this approach, showing that while "commits" might spike, the meaningful metric is the 24% reduction in median cycle time observed in mature AI-native teams. 1 This suggests that "speed" should be measured in delivery , not typing .
Part VI: The Psychology of AI Coding
Beyond the metrics and technical flaws, there is a profound psychological shift occurring in the developer workforce. The concepts of "Vibe Coding" and the "Dopamine Trap" are becoming central to understanding why developers feel productive even when they are slowing down.
6.1 Vibe Coding and the Dopamine Trap
"Vibe Coding" refers to a workflow where the developer acts as a "director" rather than a "writer," loosely guiding the AI through prompts and accepting the output based on a general "vibe" of correctness rather than rigorous verification. 15 This process is highly addictive because it triggers the brain's reward system. Seeing a complex function appear instantly on the screen releases dopamine, creating a feeling of achievement.
However, as the METR study showed, this feeling is illusory. The "Vibe Coder" avoids the hard cognitive work of structuring logic, but pays for it later in the "debugging tax." The danger is that this mode of working becomes habitual. Developers may lose the "muscle memory" of deep problem-solving, becoming dependent on the tool for even basic logic. Companies that prioritize selecting the right software partner also look closely at sustainable developer practices to avoid falling into this productivity trap.
6.2 The Loss of Flow and Deep Work
Traditional programming relies on "Flow"—a state of deep, uninterrupted concentration where the developer holds the entire mental model of the problem in working memory. AI tools, by their nature, interrupt this flow. The cycle of "Prompt -> Wait -> Review -> Debug" forces a constant context switch. The developer is no longer "in the code"; they are "managing the assistant." This shift from Deep Work to Management may explain why experienced developers, who rely heavily on Flow for complex tasks, experience the greatest slowdowns.
Part VII: Strategic Recommendations for Engineering Leaders
Based on the divergence in the data—where AI accelerates the simple but obstructs the complex—Baytech Consulting recommends a nuanced "Bimodal Strategy" for AI adoption. This echoes the greater industry movement toward strategic product development and process flexibility.

7.1 The "Green Zone": Where to Automate
Encourage aggressive AI use for tasks where the "Verification Tax" is low and the "Generation Value" is high:
- Boilerplate & Scaffolding: Generating DTOs, API clients, and standard UI components.
- Unit Tests: AI excels at generating test cases for pure functions (though humans must verify the assertions).
- Documentation: Using AI to explain legacy code or generate docstrings (shifting left on documentation). 22
- Junior Enablement: Using AI as a "tutor" to explain error messages or suggest library usage, reducing the mentorship load on seniors. 23
7.2 The "Red Zone": Where to Restrict
Enforce strict human oversight (or discourage AI use) for:
- Core Business Logic: The critical "money-handling" code where edge cases matter more than syntax.
- Concurrency & Security: Threading models, authentication flows, and cryptography.
- Large-Scale Refactoring: AI lacks the context to understand the ripple effects of changing a core dependency across 50 files.
7.3 The "Reviewer-First" Mindset
Organizations must retrain their engineering teams to shift from "Writers" to "Reviewers." The skill of 2026 is not writing a QuickSort algorithm; it is looking at an AI-generated QuickSort and instantly spotting that it uses an unstable pivot. This requires higher expertise, not lower. We recommend instituting "AI Code Reviews" where the specific prompt used to generate the code is included in the PR description, allowing reviewers to understand the intent alongside the implementation . 24
Conclusion: The Era of the "AI Architect"
The narrative that "AI makes you faster" is true, but dangerously incomplete. AI makes typing faster. It makes syntax generation instantaneous. But software engineering is not typing; it is thinking.
The data from 2025 demonstrates that when we apply this "typing accelerator" to complex, thought-intensive tasks, we inadvertently create a "thinking decelerator"—a friction layer of debugging, verifying, and context-switching that can cost experienced teams 19% of their velocity.
For Baytech Consulting's clients, the path forward is not to ban these tools, nor to blindly mandate them. It is to recognize the AI Productivity Paradox and manage it actively. The winning organizations of the next decade will be those that treat AI not as a magic wand for speed, but as a high-powered engine that requires a skilled driver, a detailed map, and—most importantly—a set of reliable brakes.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.