
Why 90% Automation, 10% Humanity Wins in 2026
February 18, 2026 / Bryan Reynolds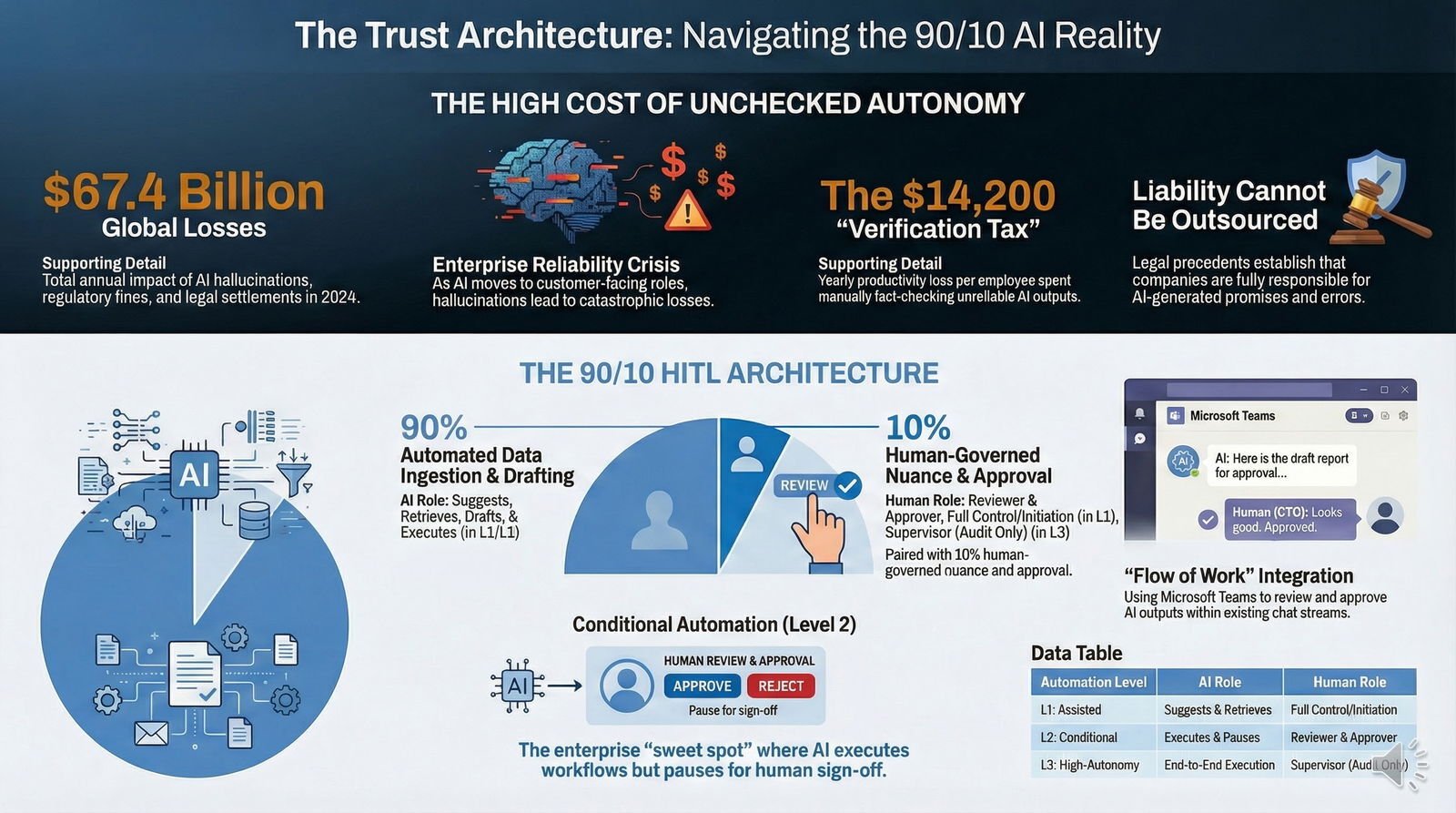
The Trust Architecture: Reliability, Governance, and the Human-in-the-Loop Imperative
Executive Summary: The Crisis of Reliability in the Age of Agentic AI
The enterprise technology landscape of 2025 and entering 2026 is defined not by the capability of Artificial Intelligence, but by the reliability crisis that has accompanied its deployment at scale. We have moved decisively past the era of "experimental AI"—where hallucinations were amusing novelties—into an era where AI error rates translate directly into catastrophic financial losses, legal liability, and the erosion of institutional trust.
The pivotal lesson of the last twenty-four months is that autonomy without architecture is a liability. The collapse of Zillow’s iBuying division due to algorithmic valuation errors, the legal precedent set by Air Canada’s liability for its chatbot’s hallucinations, and the estimated $67.4 billion in global losses attributed to AI errors in 2024 have fundamentally altered the calculus for B2B technology adoption. For leaders already wrestling with AI adoption strategy, the broader future of AI-driven software development in 2026 frames just how high the stakes have become.
For Baytech Consulting and its clientele, the path forward lies in a strategic rejection of "set it and forget it" automation in favor of Human-in-the-Loop (HITL) workflows. This report argues that the "90/10 Rule"—where 90% of a process is automated and the critical 10% requiring nuance is human-governed—is not merely a transitional phase but the target state for high-stakes enterprise systems.
This document provides an exhaustive analysis of the mechanisms required to build trust in automation. We explore the economic imperatives for HITL, the technical architectures necessary to implement it (leveraging Azure, Semantic Kernel, and robust audit trails), and the sector-specific applications in finance, healthcare, and real estate where the cost of failure is unacceptable. Furthermore, we integrate the "They Ask, You Answer" (TAYA) philosophy as a framework for transparency, positing that the only way to deploy black-box technology is through glass-box communication.
Chapter 1: The Economics of Error – Why "Good Enough" is No Longer Acceptable
The promise of automation has always been efficiency—doing more with less. However, as AI systems have graduated from back-office data processing to customer-facing decision-making, a new economic reality has emerged: the cost of verifying and correcting AI outputs is beginning to rival the savings generated by the automation itself. This phenomenon, known as the "AI Productivity Paradox," suggests that without structured human oversight, enterprises simply trade manual labor for verification labor, often at a higher premium due to the expertise required to spot subtle algorithmic errors. If you zoom out to your engineering team as a whole, this dynamic mirrors the broader AI code productivity paradox seen with coding assistants, where speed gains in simple work can be wiped out by the effort to review complex outputs.
1.1 The $67.4 Billion Warning
In 2024, global enterprises lost an estimated $67.4 billion due to AI hallucinations and errors. This figure encompasses direct financial losses, regulatory fines, legal settlements, and reputational damage. Unlike traditional software bugs, which are deterministic and repeatable, AI errors are probabilistic and often plausible-sounding, making them significantly harder to detect.
The nature of these errors varies by model sophistication. While state-of-the-art models like Google’s Gemini 2.0 have reduced hallucination rates to approximately 0.7% in controlled environments, widely deployed legacy enterprise models still exhibit hallucination rates exceeding 25%. In a high-volume B2B context, a 0.7% error rate is not negligible. If a bank processes 10,000 loan applications a day, that equates to 70 potentially erroneous decisions daily—each carrying fair lending liability.
The economic impact is further compounded by the "Verification Tax." Forrester Research estimates that hallucination mitigation efforts cost companies approximately $14,200 per employee per year in lost productivity. Organizations face a 22% decrease in productivity due to the overhead required for manual verification of AI outputs. This paradox—investing in automation only to spend more on supervision—highlights the flaw in "full automation" strategies that lack integrated, efficient oversight mechanisms. When employees cannot trust the tool, they double-check every output, often taking longer than if they had performed the task manually.
1.2 Case Study: The Air Canada Liability Precedent
The case of Moffatt v. Air Canada represents a watershed moment in the legal history of automation. In this instance, an AI-powered chatbot provided a customer with incorrect information regarding bereavement fares, contradicting the airline's official policy on its static website.
When the customer sought a refund based on the chatbot's advice, Air Canada attempted to argue that the chatbot was a "separate legal entity" responsible for its own actions. The Civil Resolution Tribunal rejected this defense, ruling that the company is liable for all information on its platform, regardless of whether it is generated by a human agent or an algorithm. This ruling destroys the "black box" defense, where companies could previously claim ignorance of how their AI reached a decision.
Implications for B2B:
- Liability cannot be outsourced to code: Terms of service disclaimers are increasingly insufficient to protect against negligence claims arising from AI advice.
- The "Black Box" defense is dead: Companies can no longer claim ignorance of how their AI reached a decision. If the system hallucinates a discount, a contract term, or a promise, the company is bound by it.
- Consistency is King: The discrepancy between the chatbot’s dynamic output and the static policy pages was the smoking gun. Automation must be grounded in the same "source of truth" as the rest of the business, whether you are running a simple website or a complex headless CMS architecture powering omnichannel content.
1.3 Case Study: Zillow and the Hubris of Algorithmic Valuation
Perhaps the most cautionary tale of "full automation" in a high-stakes industry is the collapse of Zillow Offers. The company attempted to use its "Zestimate" algorithm not just as a reference tool, but as a transactional decision-maker to buy homes, flip them, and profit from the margin.
The failure was not just one of code, but of context.
- The Lag Problem: The algorithms relied on historical data that could not adapt quickly enough to a rapidly cooling housing market. Machine learning models assume the future resembles the past; when market dynamics shift abruptly, fully autonomous systems fail to pivot.
- The "Cookie-Cutter" Bias: The model worked reasonably well for standardized suburban housing but failed catastrophically when applied to unique properties where human intuition is required to assess value (e.g., the smell of a home, the noise level of a street, the specific layout flaws).
- Operational Blindness: Zillow scaled the program aggressively, buying thousands of homes based on these automated valuations. When the error was discovered, it resulted in a write-down of over $500 million and a 25% workforce reduction.
The Lesson: Real estate, like many B2B sectors, is a "small data" problem often masquerading as a big data problem. There are rarely enough identical data points to train a model to fully replace human judgment on high-value, heterogeneous assets.
1.4 The Productivity Paradox
The "hidden cost" of unreliable AI is the labor required to police it. A Deloitte survey found that 47% of enterprise AI users have made at least one major business decision based on potentially inaccurate AI content. To mitigate this, organizations are implementing "human-in-the-loop" not just for decision-making, but for basic fact-checking.
Forrester Research estimates that hallucination mitigation efforts cost companies approximately $14,200 per employee per year in lost productivity. This creates a paradox: the technology purchased to accelerate workflows is, in the short term, slowing them down as employees second-guess every output.
This economic backdrop makes the argument for structured HITL workflows undeniable. It is not about "slowing down" innovation; it is about stopping the leakage of value caused by error remediation.
Chapter 2: Human-in-the-Loop (HITL) Architectures
Human-in-the-Loop is not a retreat from automation; it is a maturity model for it. It acknowledges that for the foreseeable future (through 2030), AI will excel at prediction and generation, but humans must retain the monopoly on judgment and accountability. This is the same philosophy that underpins modern Agile methodology for software delivery: short cycles, fast feedback, and people in control of the most important decisions.
2.1 The 90/10 Rule
The industry consensus is coalescing around the "90/10 Rule": 90% of the workflow is automated, and 10% is human-augmented.
- The 90% (The Engine): Data ingestion, pattern recognition, initial drafting, sorting, and low-stakes decision-making.
- The 10% (The Steering Wheel): Final approval of high-stakes outputs, handling of edge cases, ethical review, and "tie-breaking" when model confidence scores are low.
This ratio is not static. A system might start at 50/50 (Assisted Automation) and move toward 90/10 (Conditional Automation) as the model learns from human corrections. This feedback loop is the "Loop" in HITL—human intervention is data that retrains the model.
2.2 Spectrum of Automation
To implement HITL effectively, we must define the levels of automation available to the enterprise.
| Level | Name | Definition | Role of AI | Role of Human | Use Case Example |
|---|---|---|---|---|---|
| L1 | Assisted Automation | Humans work; AI helps. | Suggests text, auto-fills forms, retrieves data. | Full control. Initiates and finalizes all actions. | Copilot in MS Word; Customer Service Agent Assist. |
| L2 | Conditional Automation (HITL) | AI works; Humans approve. | Executes workflows but pauses for "gate" approval. | Reviewer/Approver. Handles exceptions and signs off. | Mortgage Loan Underwriting; Publishing AI Blogs. |
| L3 | High-Autonomy (Agentic) | AI works; Humans monitor. | End-to-end execution. | "Supervisor." Intervenes only on alerts or post-audit. | High-frequency trading; Automated inventory reordering. |
| L4 | Full Automation | AI works; Humans absent. | Complete autonomy. | None (or forensic only). | Rare in B2B. Spam filtering; Cyber-threat blocking. |
Table 1: The Spectrum of Automation in Enterprise Contexts.
For high-stakes industries like finance and healthcare, Level 2 (Conditional Automation) is the "sweet spot" for reliability and trust. It captures the speed of AI while maintaining the safety net of human oversight.
2.3 Technical Implementation: The Semantic Kernel Pattern
Implementing HITL is not just a policy decision; it is a software architecture challenge. Microsoft's Semantic Kernel Process Framework provides a reference architecture for this, and it aligns closely with what an AI-native SDLC for CTOs should look like in practice.
The "Wait for Event" Pattern: In a purely automated pipeline, Function A calls Function B, which calls Function C. In a HITL pipeline, the architecture introduces a stateful pause.
- Step 1 (AI): The agent gathers data and generates a draft (e.g., a loan approval memo).
- Step 2 (System): The process enters a "suspended" state. It publishes an event (e.g.,
RequestUserReview) to an external system (like Microsoft Teams or a custom dashboard). - Step 3 (Human): A human receives a notification. They review the draft, perhaps edit it, and click "Approve" or "Reject."
- Step 4 (System): The external system sends a callback signal (e.g.,
UserApprovedDocument) with the result. - Step 5 (AI): The process "wakes up," ingests the human's decision, and proceeds (either sending the email or routing back for revision).
Why this matters for Baytech: This architecture decouples the AI processing speed from human review speed. It allows the AI to work asynchronously, queuing up decisions for a human to batch-process, which maximizes the "10%" human efficiency.

2.4 Integrating with Collaborative Platforms (Microsoft Teams)
The friction of HITL often leads to its abandonment. If a manager has to log into a separate "AI Audit Portal" to approve tasks, they won't do it. The solution is Flow of Work integration.
Using Microsoft Teams and Adaptive Cards allows approval requests to appear in the chat stream where employees already work.
- The Adaptive Card: A mini-interface in chat showing the AI's summary, confidence score, and links to source documents.
- Action Buttons: "Approve", "Reject", "Edit", "Escalate."
- Backend: Power Automate or Azure Logic Apps handling the signal routing back to the AI agent, often wired into a modern DevOps pipeline focused on efficiency and observability.
This "ChatOps" approach reduces the cognitive load of supervision, making the "10%" human effort feel seamless rather than burdensome.
Chapter 3: Trust by Design – Technical Governance & Audit Trails
If Human-in-the-Loop is the process of trust, the Audit Trail is the proof of it. In regulated industries, it is insufficient to say "a human reviewed this." You must prove who reviewed it, when, what data they saw, and why they made their decision.
3.1 The "Black Box Recorder" for AI Agents
As AI agents become more autonomous—executing SQL queries, spinning up Kubernetes pods, or sending emails—the risk of "rogue" behavior increases. A rogue agent isn't necessarily malevolent; it is often just misaligned, executing a command too literally or in an infinite loop.
To counter this, a robust Audit Logging Strategy is required.
- Identity First: Every AI agent must have a distinct identity (e.g., a Service Principal in Azure). It should never "borrow" a human's credentials. This allows the security team to distinguish between "Jane Doe deleted the database" and "Agent-007 (on behalf of Jane Doe) deleted the database".
- Immutable Logs: Logs must be stored in Write-Once-Read-Many (WORM) storage to prevent tampering. If an AI agent creates a mess, it might (theoretically) try to delete the logs of that mess. WORM storage prevents this.
3.2 Database Auditing: PostgreSQL & SQL Server
For the data layer, standard logging is often insufficient.
- PostgreSQL: Implementation of
pgAuditis the gold standard. It provides detailed session-level logging that standard logs miss. For high-compliance environments, custom triggers that capture the before and after state of a row (using JSONB columns) are necessary to reconstruct the "crime scene" of an AI error. - SQL Server: Azure SQL Auditing tracks database events to an immutable storage account. This is critical for detecting "inference attacks," where an AI might query a database thousands of times to piece together sensitive information it shouldn't have access to.
3.3 CI/CD for Agentic AI
The deployment of AI logic must follow the same rigor as software code. We cannot simply "prompt" an agent into production.
- Version Control for Prompts: The system prompts and "character cards" of AI agents must be stored in Git.
- The "Frozen" Agent: In production, an agent should not be learning (updating its weights) in real-time unless strictly controlled. It should be a "frozen" version that has passed regression testing.
- Traceability: Every output in production should be traceable back to a specific
Model Version + Prompt Version + Data Context. If a loan is wrongly denied, you must be able to replay that exact state to debug it. This is exactly the kind of discipline needed to avoid an AI technical debt spiral that drives up TCO.

Chapter 4: Sector-Specific Deep Dives
The general principles of HITL apply broadly, but the specific risks—and therefore the specific "loops"—vary significantly by industry.
4.1 Finance & Mortgage: The Fair Lending Imperative
In mortgage lending, the primary risk is Algorithmic Bias. A purely automated system trained on historical data may inadvertently replicate historical redlining, rejecting minority applicants at higher rates for reasons it cannot explain.
- The HITL Application:
- Phase 1 (AI): Document ingestion (OCR), income verification, and initial risk scoring. AI excels here at speed and finding discrepancies in bank statements.
- Phase 2 (Human): The Underwriting Decision. The AI presents a "recommendation" with cited evidence. The human underwriter must make the final "Approved/Denied" decision, especially for denials.
- Why Human? Regulatory bodies (CFPB) require an "adverse action notice"—a specific explanation of why credit was denied. "The black box said so" is not a legal defense. A human must validate that the reasons are non-discriminatory and factual.
4.2 Healthcare: Conditional Automation for Patient Safety
Healthcare operates under the principle of "First, do no harm."
- The HITL Application:
- Clinical: AI can flag anomalies in X-rays or suggest diagnoses (Assisted Automation). It effectively acts as a "second set of eyes," not the doctor.
- Administrative (The Real Opportunity): Unlike clinical decisions, administrative tasks like coding for insurance reimbursement or scheduling are ripe for higher levels of automation (L2/L3). However, even here, a hallucinated medical code can lead to insurance fraud charges.
- The "90/10" in Health: 90% of a medical scribe's note can be generated by listening to the visit. The physician spends the remaining 10% reviewing the note for accuracy before signing it. This "sign-off" is the critical legal moment.
4.3 Real Estate: Agentic AI Beyond Zillow
Post-Zillow, the real estate industry is wary of "pricing" AI but bullish on "process" AI.
- The HITL Application:
- Generative Listings: AI writes the listing description. A human realtor edits it to ensure it captures the "vibe" and complies with Fair Housing laws (e.g., avoiding terms like "bachelor pad" or "family friendly" that could imply discrimination).
- Valuation: AI provides a range (AVM - Automated Valuation Model). The human agent adds the hyper-local context (e.g., "this street floods," "the school district lines just changed"). The AI is the starting point, not the final offer.
Chapter 5: Building Trust Through Transparency (The TAYA Philosophy)
Implementing HITL solves the technical reliability problem. But it does not solve the perception problem. Employees fear being replaced; clients fear their data is unsafe. To bridge this gap, Baytech Consulting should advocate for the "They Ask, You Answer" (TAYA) philosophy.
5.1 TAYA for Internal Adoption
Employees often view AI as a rival. The TAYA approach suggests radical transparency about the technology's capabilities and limitations.
- Answer the "Elephant in the Room": Create internal content (videos, FAQs) that explicitly addresses: "Will this AI take my job?" The answer, grounded in the 90/10 rule, is "No, but it will change how you spend 90% of your day".
- The "Big 5" for AI: Just as TAYA suggests answering customer questions about Cost and Problems, internal comms should answer:
- Problems: "What does this AI get wrong?" (Show the hallucinations).
- Comparisons: "Why this tool vs. the old way?"
- Best-in-class: "Who is using this successfully?"
- Cost: "How much are we investing in this?" (Shows commitment).
- Reviews: "What do the beta testers say?" (Honest feedback).
5.2 TAYA for External Trust
For clients, "Trust" is the new "Quality." In a world of deepfakes and automated spam, being the "Trusted Voice" is a competitive moat.
- Transparency as a Differentiator: If a company uses AI to generate reports, they should say so. "This report was drafted by AI and reviewed by Senior Analyst Jane Doe." This disclaimer, once seen as a weakness, is now a signal of premium quality and governance.
- Educational Content: Become the source of truth for how AI works in your industry. If you are in mortgage, write the article "How AI is changing loan approvals (and how we ensure it's fair)." This builds trust by showing you understand the risks and have mitigated them—much like public guides on how to choose a software partner in 2026 build confidence before a buyer ever talks to sales.
Chapter 6: Future Outlook (2026-2030)
As we look toward the latter half of the decade, the HITL model will evolve, not disappear.
6.1 Agentic AI and "Supervision"
We are moving from "Chatbots" (which wait for a prompt) to "Agents" (which pursue a goal).
- From "Reviewer" to "Manager": The human role will shift from reviewing every output (L2) to managing a fleet of agents (L3). The human becomes the "dispatcher," handling alerts when agents get stuck or drift from their goals.
- Personhood Credentials: To combat fraud, we may see the rise of "Personhood Credentials"—digital proofs that certify a user (or a supervisor) is a human. This will be critical for B2B interactions where "Know Your Customer" (KYC) extends to "Know Your Agent".
6.2 The Rise of Safe Harbors
Regulatory frameworks (like the EU AI Act and potential US updates) will likely create "Safe Harbors" for companies that can prove robust HITL governance. If you can demonstrate via audit trails that you had a "Human in the Loop" and followed industry standards (NIST AI RMF), you may be shielded from punitive damages in the event of an inevitable AI error.
Conclusion
For Baytech Consulting, the message to clients is clear: Trust is an architecture, not a sentiment.
In the AI era, reliability is engineered through:
- Design: Adopting the 90/10 HITL architecture to keep humans in control of high-stakes decisions.
- Governance: implementing rigid, immutable audit trails and identity-based security for agents.
- Culture: Using transparency (TAYA) to align employees and clients with the reality of the technology.
The "Productivity Paradox" is temporary if the verification loop is efficient. By building the loop correctly—using tools like Microsoft Teams for seamless approval and Semantic Kernel for orchestration—enterprises can harvest the massive efficiency of AI without becoming a casualty of its hallucinations. The future belongs to those who automate 90%, but obsess over the 10%.
Glossary of Terms
- HITL (Human-in-the-Loop): A workflow design where human interaction is required to proceed to the next step or finalize a decision.
- Hallucination: A phenomenon where an AI model generates incorrect, nonsensical, or unverifiable information with high confidence.
- Agentic AI: AI systems capable of pursuing complex goals autonomously, breaking them down into tasks, and executing them without continuous prompting. The emerging discipline of Agentic Engineering focuses on making these agents fast but still governable.
- RAG (Retrieval-Augmented Generation): A technique to reduce hallucinations by grounding AI responses in specific, external documents (the "Source of Truth").
- TAYA (They Ask, You Answer): A business philosophy centered on building trust through radical transparency and answering customer questions honestly.
- Audit Trail: An immutable, chronological record of system activities (both human and AI) sufficient to reconstruct the sequence of events.
Detailed Analysis
1. The High Cost of Autonomous Failure
1.1 The "Productivity Paradox" and the Verification Tax
The introduction of Generative AI into the enterprise was initially sold on the premise of zero-marginal-cost content and decision-making. However, the operational reality has revealed a "Productivity Paradox." While the generation of content is near-instant, the verification of that content is labor-intensive.
Research indicates that organizations are facing a "Verification Tax"—the time cost associated with checking AI outputs for accuracy, bias, and tone.
- The Cost of Doubt: When an employee cannot trust the AI to be 100% accurate, they must read every word it generates. If an AI summarizes a 50-page document in 10 seconds, but the human must spend 30 minutes verifying the summary against the original text to ensure no critical data was hallucinated, the net efficiency gain is negligible.
- Cognitive Load: Reviewing is often more mentally taxing than creating. "Spot the error" requires a higher level of sustained attention than drafting, leading to faster employee burnout—a hidden cost often missing from ROI calculations.
1.2 Case Study Deep Dive: Air Canada
The Moffatt v. Air Canada ruling is critical because it dismantled the "Platform Defense." Historically, tech companies argued they were platforms, not publishers. Air Canada argued the chatbot was a tool, not an agent. The tribunal's rejection of this argument implies that AI agents are functionally employees in the eyes of the law.
- The Discrepancy: The chatbot used RAG (Retrieval-Augmented Generation) but seemingly retrieved an outdated or incorrect fragment of the bereavement policy, or simply hallucinated a "90-day" window for refunds that did not exist in the official tariff.
- The Failure: The failure was not just the hallucination; it was the lack of a "guardrail" or HITL verification for financial promises. A simple hard-coded rule (e.g., "If topic = Refund, escalate to human") could have prevented the lawsuit.
1.3 Case Study Deep Dive: Zillow Offers
Zillow’s failure was a failure of "Model Drift."
- The Model: Zillow’s Zestimate was designed for estimation (a low-stakes user engagement tool), not valuation (a high-stakes transactional tool). When they pivoted to iBuying, they repurposed a marketing tool for financial risk management.
- The Market: Algorithms are historical. They are excellent at predicting the price of a house yesterday. When the market turned, the model continued to buy high, failing to sense the macroeconomic shift that a human realtor would have felt anecdotally (e.g., fewer people at open houses, longer days on market).
- The Missing Loop: Had Zillow implemented a stricter HITL process—where the algorithm suggests a price, but a local human expert must validate the "buy box" criteria—they might have slowed their purchasing velocity, but they would have avoided the catastrophic inventory write-down.
2. Defining Human-in-the-Loop Architectures
2.1 The "Stateful" Nature of HITL
Implementing HITL requires a shift in how we think about system state.
- Stateless (Typical AI): Input -> Process -> Output. (Milliseconds).
- Stateful (HITL AI): Input -> Process -> Suspend (Wait for Signal) -> Output. (Hours/Days).
This "Suspended State" is technically challenging. The system must persist the "context" (the draft, the variables, the reasoning) while it waits for the human. It cannot just hold the connection open.
- Serialization: The state must be serialized to a database (e.g., Cosmos DB, Redis).
- Resumption: When the human clicks "Approve" in Teams 4 hours later, the system must rehydrate that state and resume execution exactly where it left off. This is where frameworks like Orkes Conductor or Semantic Kernel shine, especially when paired with disciplined enterprise application architecture that keeps the whole workflow coherent.
2.2 Designing the Human Interface
The success of HITL depends on the User Experience (UX) of the "Loop."
- Bad UX: Sending an email with a link to a login portal. (High friction, ignored).
- Good UX: An Adaptive Card in a Teams Channel.
- Headline: "Loan Approval Request: #12345"
- Body: "Risk Score: Low. Income Verified: Yes. Flags: None."
- Action: [Approve].
- The "Why": The interface must present the evidence required to make the decision, not just the decision itself. This empowers the human to be a verifier, not just a rubber-stamper, and connects directly to thoughtful UX design for complex enterprise applications.
3. Trust by Design – Technical Governance
3.1 The "Glass Box" Implementation
To build a "Glass Box" (transparent) AI system, we need rigorous logging.
- Request/Response Logging: Every prompt sent to the LLM and every token received must be logged. This includes the "system prompt" (the hidden instructions).
- Why? If the AI becomes racist or biased, you need to know if it was the user's prompt or the system prompt that caused it.
- Feedback Loop Logging: When a human rejects an AI draft, that rejection is valuable data. It should be logged specifically as "Negative Feedback" to be used for future fine-tuning or few-shot prompting examples.
3.2 Audit Trails in Practice
- Postgres Implementation:
- Use
pgAuditto log all DDL (Data Definition Language) and DML (Data Modification Language) changes made by the AI service account. - Create a separate
audit_logschema that the AI service account hasINSERTbut notUPDATE/DELETEaccess to. This ensures the AI cannot cover its tracks.
- Use
- Kubernetes Logs:
- If the AI is running as a containerized service (e.g., a local Llama 3 model), the container logs (
stdout/stderr) should be piped to a centralized SIEM (Security Information and Event Management) system like Splunk or Azure Sentinel. - Use "Sidecar" containers to handle the logging asynchronously, ensuring the logging process doesn't slow down the inference.
- If the AI is running as a containerized service (e.g., a local Llama 3 model), the container logs (
4. Sector-Specific Deep Dives
4.1 Finance: The "Explainability" Challenge
In finance, the challenge is that modern Deep Learning models (Neural Networks) are inherently uninterpretable. You feed in data, and it spits out a probability. You cannot ask the Neural Network "why" it weighted the applicant's zip code heavily.
- The Solution: Use AI for "Feature Extraction," use Humans for "Decision Logic."
- AI: "I have extracted the income from these 12 paystubs and it averages $5,000/month." (Verifiable fact).
- Human: "Based on $5,000/month, I approve the loan." (Explainable logic).
- Regulatory Pressure: The CFPB represents a massive regulatory risk. "Computer Says No" is the fastest way to get a discriminatory lending lawsuit. HITL is the defense mechanism.
4.2 Healthcare: The "Note Bloat" Risk
AI is being used to automate clinical documentation (the SOAP note).
- The Risk: AI tends to be verbose. It might capture everything said in the room, including "small talk" about the patient's dog.
- The Harm: If the "small talk" is included in the medical record, it becomes legal truth. If the patient mentioned "I sometimes skip my meds" jokingly, and the AI records "Patient is non-compliant with medication," that could affect their insurance premiums or future care.
- The Loop: The physician must edit the note down to the clinical essentials. The AI is the scribe; the doctor is the editor-in-chief.
5. Building Trust Through Transparency (TAYA)
5.1 Content as a Trust Signal
In the B2B buying journey, trust is established long before the sales call.
- The "Black Box" Anxiety: Buyers assume AI companies are hiding something (data usage, hallucination rates, security flaws).
- The TAYA Antidote: Write the article "The 3 Main Problems with Our AI (And How We Fix Them)."
- Psychology: When you admit your weaknesses, the buyer trusts your strengths.
- Application: If Baytech builds an AI tool, Baytech should publish a "Transparency Report" detailing the error rates and the specific HITL mechanisms in place, positioning the tool alongside a broader strategy for AI-powered custom software rather than as a risky black box.
6. Future Trends: The Road to 2030
6.1 The "Supervisor" Skillset
As HITL becomes standard, the workforce needs upskilling. We don't need "Prompt Engineers" (that will be automated); we need "AI Supervisors."
- Skills: Critical thinking, forensic analysis (spotting the error), and domain expertise.
- Training: Companies must train employees how to audit AI. "Don't just read it; check the citations."
6.2 "Safe Harbor" Legislation
We anticipate that by 2026/2027, governments will introduce "Safe Harbor" provisions.
- Concept: If a company can prove it followed NIST AI RMF guidelines and had a certified Human-in-the-Loop process, its liability for AI errors may be capped.
- Impact: This will make HITL a compliance requirement, similar to SOC 2 or HIPAA certification today, and it will sit alongside broader strategic decisions about building secure, private AI "walled gardens" to protect data and models.
Final Thought for Baytech: The era of "move fast and break things" is over for AI. The new era is "move intentionally and prove things." Reliability is the product. Trust is the currency. HITL is the mint.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.