
Self-Hosting AI Agents: A Guide for Regulated Enterprises
May 13, 2026 / Bryan Reynolds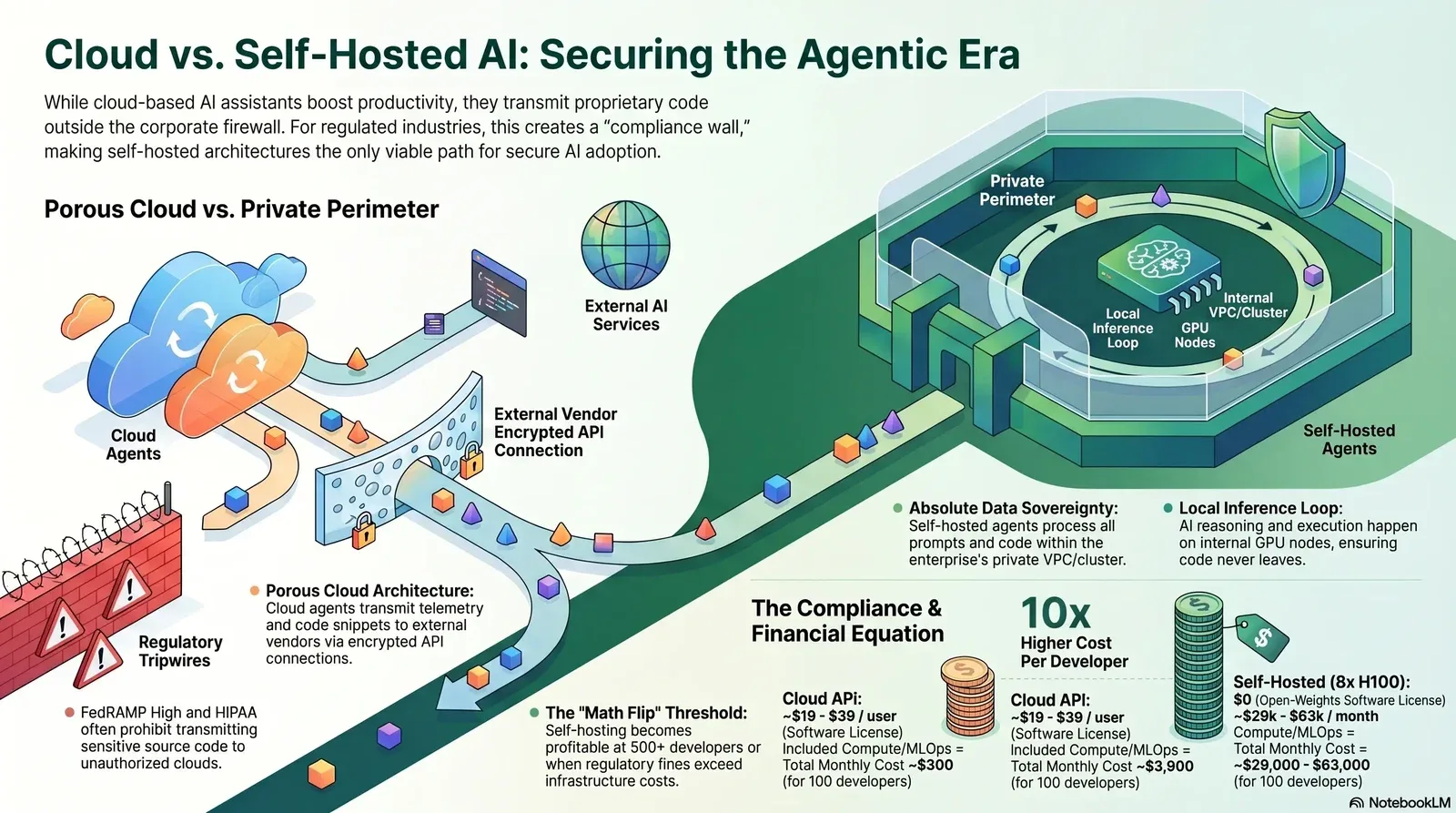
Keep Your Source Code Off the Model: The Case for Self-Hosted AI Dev Agents
The software engineering industry has definitively crossed the threshold into the agentic era. By mid-2026, research from enterprise technology leaders indicates that 61% of engineering teams are actively running AI agents within their production workflows.
For the broader market, the mass adoption of cloud-based AI coding assistants like Cursor, GitHub Copilot, and Anthropic’s Claude Code has fundamentally reset the baseline for developer productivity. These tools transition natural language intents into merge-ready pull requests, automating the scaffolding, testing, and refactoring processes that previously consumed hours of engineering time.
However, for organizations operating within highly regulated domains—defense contractors, regional hospital networks, global financial institutions, and critical infrastructure providers—this productivity revolution has collided with an immovable regulatory wall. For these enterprises, adopting commercial cloud-hosted AI orchestration means deliberately transmitting proprietary source code, internal architectural diagrams, and potentially sensitive user data across the corporate firewall to third-party model providers.
This outbound data flow creates an unacceptable risk profile that directly violates the foundational tenets of compliance frameworks such as FedRAMP High, the Health Insurance Portability and Accountability Act (HIPAA), the Payment Card Industry Data Security Standard (PCI-DSS v4.0), and the European Union’s AI Act.
Consequently, visionary chief technology officers and strategic chief financial officers at regulated firms have been forced to tell their engineering teams “no,” effectively accepting a massive competitive disadvantage to maintain their compliance posture.
The beta release of Coder Agents in May 2026 represents a structural shift in this dynamic.
By introducing a native agent architecture designed to run entirely on self-hosted infrastructure, Coder Agents enables enterprises to deploy conversational, AI-driven developer workflows without shipping source code, prompts, or model interactions outside their network perimeter.
This architectural approach finally offers a credible alternative for regulated teams, replacing the compliance barrier with an operational one. Self-hosting large language models (LLMs) is a brutal financial and technical undertaking. It requires massive capital expenditure on enterprise-grade GPUs, specialized model operations (MLOps) talent, and complex infrastructure maintenance.
This comprehensive analysis explores the uncompromising architectural trade-offs between cloud and self-hosted AI developer agents. It maps the exact regulatory tripwires that make cloud AI untenable for the enterprise, unpacks the hidden operational taxes of local LLM inference, and defines the precise organizational threshold where the financial burden of self-hosted AI coding agents becomes a necessary and highly profitable investment. For a broader view of how AI agents are reshaping software markets and vendor choices in 2026, see The SaaSocalypse: How AI Is Reshaping Software Markets in 2026.
The Data-Flow Reality: Cloud vs. Self-Hosted Agent Architectures
To grasp why heavily regulated industries outright reject commercial cloud AI assistants, one must dissect the precise mechanics of how these tools process data, index codebases, and interact with external networks. The distinction between a cloud-hosted agent and a self-hosted agent is not merely a nuance in software licensing; it is a fundamental divergence in network trust boundaries, data sovereignty, and enterprise risk management.
The Cloud Agent Architecture: A Trust Deficit
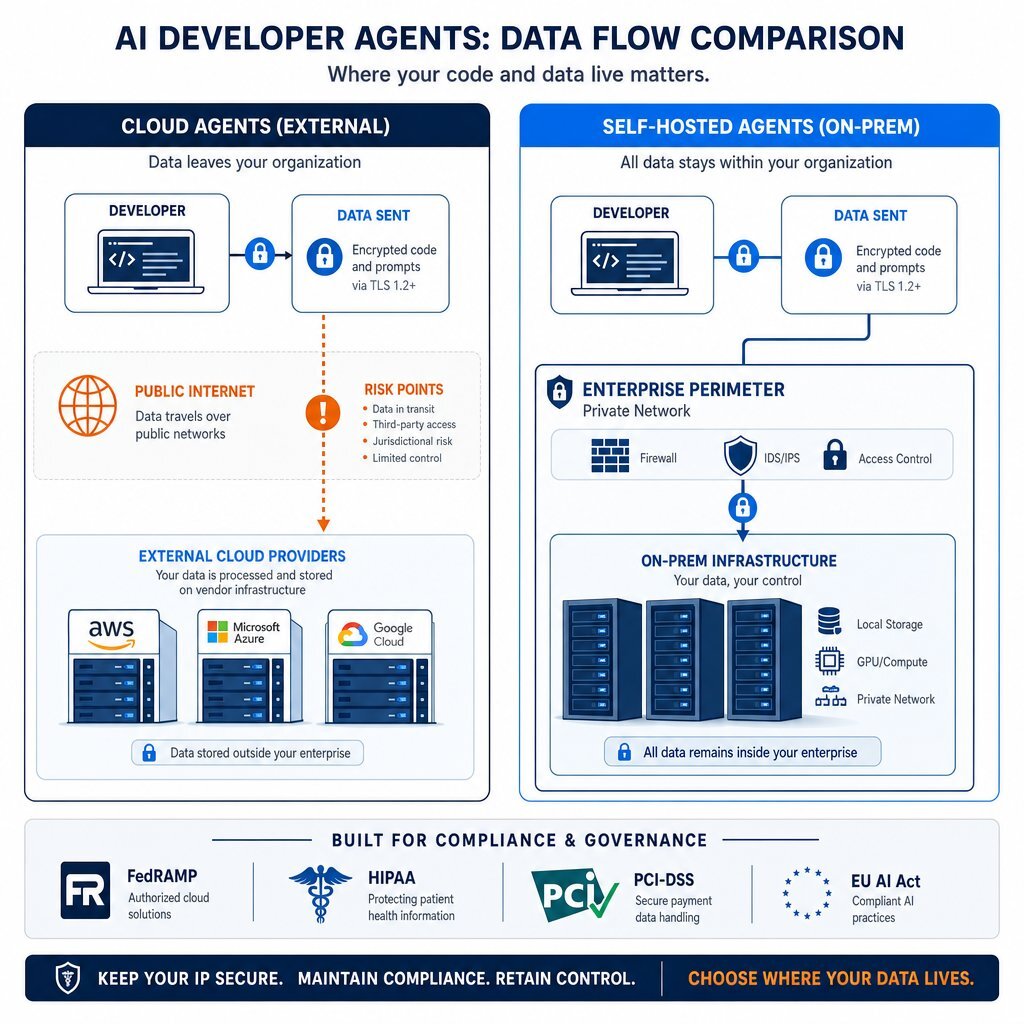
Cloud-based AI developer tools operate on a hybrid architecture that splits execution between the developer’s local integrated development environment (IDE) and a remote, vendor-controlled cloud backend. This architecture is designed for maximum speed and minimal local compute, but it achieves this by turning the enterprise perimeter into a porous boundary.
In the case of GitHub Copilot for Business, the system continuously monitors the IDE state to generate contextual suggestions. The extension collects user engagement data, the codebase context immediately surrounding the developer’s cursor, snippets from other open tabs, and explicit chat prompts.
This package of telemetry and proprietary code is encrypted via Transport Layer Security (TLS) and transmitted directly to GitHub’s Azure tenant or an underlying model provider like OpenAI. While GitHub Enterprise agreements explicitly state they honor commitments prohibiting the use of business customer data for model training, the unalterable fact remains that the data physically leaves the enterprise network to be processed externally.
Cursor employs a more aggressive, context-heavy architecture to power its industry-leading semantic search and agentic capabilities. When an enterprise developer opens a repository, Cursor builds a local Merkle tree to hash the codebase, identifying exactly which files and directories have changed.
It then uploads the codebase in small chunks to its cloud backend to compute vector embeddings, storing the resulting metadata in a remote vector database, such as Turbopuffer. During an active query, Cursor’s cloud infrastructure acts as the orchestration layer. It receives the prompt, executes a semantic search against the remote vector database, pulls the relevant encrypted file paths, and requests the actual code chunks from the local client to construct the final prompt for the LLM.
Cloud vendors attempt to mitigate enterprise objections through “Privacy Mode” or Zero Data Retention (ZDR) agreements. When Privacy Mode is active, the vendor and the model provider contractually agree to drop the data from their servers immediately after generating a response, ensuring no code is stored on disk or used for future model training.
However, from a strict DevSecOps perspective, ZDR is entirely a legal control, not a technical network boundary. Because these tools function as native desktop applications or IDE extensions operating via HTTPS/TLS, standard enterprise security tools—such as web proxies, Cloud Access Security Brokers (CASBs), and browser-extension Data Loss Prevention (DLP) systems—cannot inspect the payload without explicit TLS decryption.
To the security operations center, the network simply registers an outbound encrypted API connection. It is completely blind to whether the developer is transmitting harmless boilerplate code, highly classified internal authentication infrastructure, or raw patient records copied from a production database. If this kind of “shadow tooling” feels familiar, it mirrors the same risk pattern described in Shadow AI Risks in 2026 and Strategies for Secure Adoption.
The Self-Hosted Agent Architecture: Absolute Perimeter Control
Self-hosted architectures, exemplified by the release of Coder Agents, invert this dynamic by pulling the entire orchestration, context-gathering, and inference stack inside the enterprise firewall.
Coder Agents functions as a conversational interface and API that delegates tasks to AI agents directly within the customer’s self-hosted Coder control plane. Traditional AI tooling requires installing agent harnesses directly inside the developer workspace, injecting API keys into the local environment, and executing requests outbound. Coder Agents, conversely, runs the agent loop centrally in the control plane.
The data flow in a self-hosted architecture is strictly isolated:
- Developer Input: The developer submits a natural language request via their local IDE, such as Visual Studio 2022 or VS Code.
- Centralized Orchestration: The request travels solely to the self-hosted Coder control plane located entirely within the enterprise’s private cloud (e.g., an OVHcloud bare-metal server, an internal AWS Virtual Private Cloud, or an on-premise Kubernetes cluster managed by Rancher).
- Local Inference: The control plane orchestrates the agentic loop—reasoning, planning steps, executing code, and formatting responses—using a self-hosted open-weights LLM running on internal GPU nodes via an inference server like vLLM.
- Dynamic Execution: If the agent needs to test code or run a build, it dynamically provisions a secure, ephemeral workspace container, executes the commands, reads the output, and reports back to the control plane, terminating the workspace when the task concludes to save infrastructure costs.
Under this model, no source code, developer prompts, API keys, or generated responses ever cross the external network boundary. The organization retains absolute, cryptographic sovereignty over the entire data lifecycle. Furthermore, by keeping the agent execution in the control plane rather than distributed across individual workspaces, the enterprise maintains an immutable, persistent database of all chat states and agent actions, providing the exact auditability required by stringent compliance frameworks.
Architectural Data-Flow Comparison
| Architectural Component | Cloud Agents (Cursor, Copilot, Codex) | Self-Hosted Agents (Coder Agents, Local vLLM) |
|---|---|---|
| Prompt Processing | Executed on external vendor cloud servers. | Executed entirely on-premise/within the VPC. |
| Context Indexing | Codebase uploaded to remote vector DBs. | Indexed and stored on internal network storage. |
| Code Transmission | Proprietary code transits the public internet. | Code never leaves the enterprise perimeter. |
| API Key Storage | Injected locally or stored with the vendor. | Centralized and secured in the internal control plane. |
| Auditability | Limited to vendor-provided export logs. | Full, direct internal database access to all prompts. |
| Network Trust | Requires allowlisting external API IP ranges. | Operates entirely within the Zero Trust internal network. |
The Compliance Map: Regulatory Regimes Banning Cloud AI
For technology leaders in regulated environments, the decision to invest in self-hosted AI developer tools is rarely driven by a desire for operational efficiency; it is driven by uncompromising legal necessity. The rapid proliferation of AI has triggered a corresponding wave of regulatory scrutiny from federal agencies and standards bodies. Organizations subject to these frameworks cannot accept a vendor’s Terms of Service as sufficient risk mitigation. They need provable controls, tight governance, and often a staged rollout like the one described in Enterprise AI Implementation Plan: A 90-Day Roadmap for Leaders.

FedRAMP High and Controlled Unclassified Information (CUI)
For organizations building software for the United States federal government, compliance with the Federal Risk and Authorization Management Program (FedRAMP) is a non-negotiable prerequisite. Under FedRAMP High and the handling requirements for Controlled Unclassified Information (CUI), data must remain within strictly authorized geographical and logical boundaries.
The FedRAMP Program Management Office explicitly notes that allowing developers to use public cloud-based AI coding assistants on internal, proprietary government code is fundamentally out of scope for standard authorizations. Any service processing sensitive federal data requires enterprise-grade controls, including guaranteed data separation, FIPS-140 validated encryption at rest and in transit, and restrictions ensuring that technical support staff are FedRAMP-adjudicated U.S. citizens located onshore.
While hyperscalers offer “Assured Workloads” and dedicated government clouds, standard commercial licenses of Copilot or Cursor simply do not meet these requirements for processing classified or highly sensitive internal architectures. Self-hosting AI agents within an already-authorized FedRAMP boundary allows defense contractors and government technology providers to leverage agentic productivity without breaching data residency protocols or exposing CUI to unauthorized sub-processors.
HIPAA and the Minimum Necessary Rule
In the healthcare sector, the deployment of AI developer tools is strictly governed by the Health Insurance Portability and Accountability Act (HIPAA). The primary risk of AI coding assistants in healthcare is not malicious external exfiltration, but accidental exposure by internal staff.
Developers frequently copy production database queries, API responses, or system logs into their IDE to debug complex issues. If an AI agent automatically reads this surrounding context and transmits it to an external model provider, the organization has unlawfully transmitted Protected Health Information (PHI).
To utilize a cloud AI provider legally, the healthcare organization must execute a Business Associate Agreement (BAA) with the vendor. Many commercial AI coding tool vendors refuse to sign BAAs for their standard or Pro tiers, rendering them legally unusable. Furthermore, even with a valid BAA in place, the HIPAA Minimum Necessary Rule dictates that access to PHI must be restricted strictly to what is required for a specific task. An AI agent that broadly ingests the entire developer workspace violates this principle of least privilege.
Self-hosted agents resolve this fundamental mismatch. By containing the infrastructure, healthcare engineering teams ensure that even if PHI is accidentally ingested into a coding prompt, the data never leaves the covered entity’s secured infrastructure. This architectural safeguard transforms what would be a reportable, multi-million-dollar federal breach into a contained, internal policy violation.
PCI-DSS v4.0 and Financial Infrastructure
The transition to PCI-DSS v4.0 has introduced rigorous continuous compliance expectations for organizations handling payment card data. Version 4.0 shifts the regulatory landscape away from point-in-time, annual audits toward continuous risk analysis, demanding that automated security and governance be embedded directly inside CI/CD pipelines.
Financial institutions are protective of the source code that governs payment gateways, fraud detection algorithms, and cryptographic handling. Transmitting this codebase to external AI providers introduces unacceptable supply chain and data exposure risks. The PCI Security Standards Council has issued specific guidance regarding AI, noting that while AI can assist in workflows, it introduces risks of hallucinations, biases, and insecure output generation that require human oversight. Self-hosting AI tools ensures that the rigorous network segmentation required by PCI-DSS is maintained, keeping the Cardholder Data Environment (CDE) fully isolated from the public internet while preserving developer speed.
The EU AI Act (Article 10)
The European Union’s AI Act, which brought its high-risk AI system obligations fully into force in 2026, places immense data governance burdens on software development. Under Article 10, systems classified as high-risk must meet strict quality criteria for datasets and maintain comprehensive, auditable data governance practices.
When a cloud AI coding tool generates code that is subsequently incorporated into a high-risk AI system—such as biometric identification software, credit scoring algorithms, or critical infrastructure management—the technical documentation, human oversight, and audit trail obligations flow directly to the deploying organization. Because commercial cloud tools act as “black boxes,” organizations cannot fully audit the lineage of the generated code or definitively prove that the underlying model was not trained on poisoned or copyrighted data.
Self-hosted open-weights models allow enterprises to maintain absolute cryptographic certainty over the model’s weights, training lineage, and inference logs, producing the exact compliance artifacts required by European regulators without relying on vendor attestations.
| Regulatory Framework | Primary Constraint on Cloud AI Tools | Self-Hosted Resolution |
|---|---|---|
| FedRAMP High | Prohibits transmitting CUI to unauthorized commercial cloud boundaries. | Keeps processing inside the authorized VPC boundary. |
| HIPAA | Restricts PHI transmission; requires BAAs and Minimum Necessary access. | Contains accidental PHI exposure within the internal network. |
| PCI-DSS v4.0 | Mandates strict network segmentation for the Cardholder Data Environment. | Maintains zero-trust segmentation; no outbound internet access required. |
| EU AI Act (Art. 10) | Requires auditable data lineage and governance for high-risk software. | Provides complete control over model weights and deterministic logging. |
The Operational Tax: Honest Accounting of Self-Hosting Costs
While the compliance and data residency arguments for self-hosting are absolute, the financial reality is staggering. Vendors of self-hosted developer tools heavily market the security benefits while frequently obfuscating the brutal economics of operating local LLM infrastructure. This is where a disciplined, finance-first view of AI spending, like the one outlined in Reframing AI ROI: How CFOs Can Justify Tech Investments, becomes essential.
The industry narrative that open-source models are “free” is a dangerous misconception. Open-source models merely shift the enterprise bill from predictable software licensing to massive hardware acquisition, complex infrastructure engineering, and continuous maintenance. For an enterprise to transition from cloud-based AI to a self-hosted agentic architecture, it must pay a severe operational tax.
The Capital Expenditure (CapEx): GPU Hardware
In 2026, serving enterprise-grade models capable of matching the complex reasoning capabilities of GPT-4o or Claude 3.5 Sonnet—such as DeepSeek-V3 or Llama 3 70B—requires massive, specialized computing power. Large language models are severely constrained by Video RAM (VRAM).
To run a 70-billion-parameter model in 16-bit floating-point (FP16) precision requires approximately 140GB of VRAM merely to load the static model weights. Adding the Key-Value (KV) cache, which grows dynamically based on context length and the number of concurrent users, demands significantly more memory. For example, a 70B model processing a 32,000-token context window for 10 concurrent developers requires an additional 112GB of VRAM just for the FP16 cache. Therefore, running a highly capable AI agent for a development team strictly requires an 8x NVIDIA H100 GPU server node to prevent memory overflow errors and sluggish latency.
The upfront cost to purchase a complete 8x H100 SXM server chassis (including CPUs, memory, networking, and liquid cooling) sits between 300,000 and 450,000. The SXM variant, which utilizes NVLink to provide 900 GB/s of GPU-to-GPU interconnect bandwidth, is significantly more expensive than the PCIe variant but is essential for the tensor parallelism required to run models larger than a single GPU’s memory capacity. Alternatively, renting an 8x H100 cluster from a specialized cloud provider like CoreWeave or Cyfuture AI costs approximately 20 to 25 per hour, equating to 17,000 to 39,000 per month for reserved, full-time usage.
The Operating Expenditure (OpEx): Inference and MLOps
Hardware acquisition is merely the baseline. AI inference optimization is an entirely distinct engineering discipline. Operating a self-hosted inference server using frameworks like vLLM requires deep, specialized knowledge of continuous batching, memory allocation, and quantization—the process of reducing model precision to INT8 or FP8 to save memory without destroying code-generation quality.
A common failure mode for enterprises attempting to self-host is GPU utilization inefficiency. A GPU operating at a 10% load inflates the cost-per-token by a factor of ten, turning a high-value physical asset into a massive financial liability billed by the hour.
Furthermore, models decay. The open-source ecosystem releases improved coding models every few months. Updating a foundational model requires rigorous evaluation to ensure the new weights do not regress on internal coding standards or hallucinate legacy syntax. Establishing and maintaining these automated evaluation datasets costs an estimated $12,000 in engineering time per upgrade cycle. To manage this infrastructure, organizations must hire specialized MLOps and DevOps engineers, whose average U.S. salaries exceed $145,000 annually.
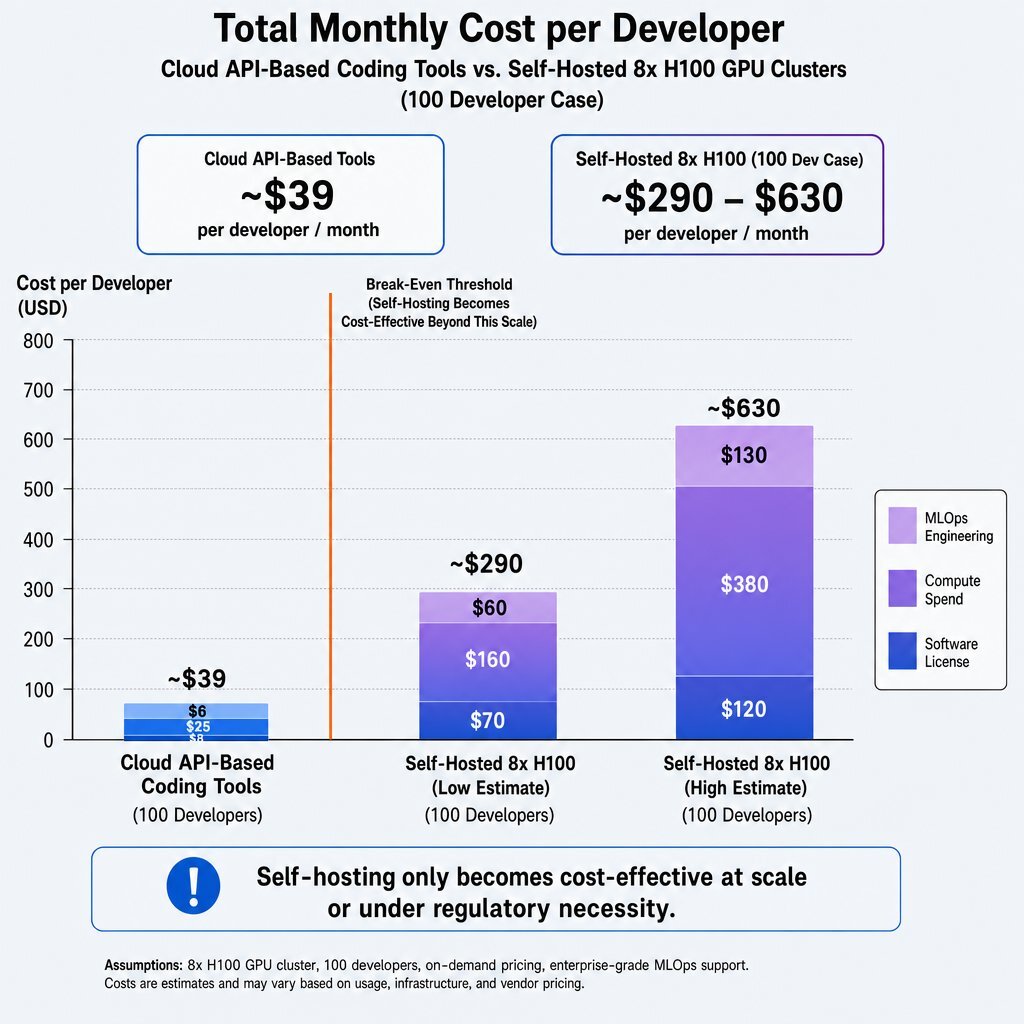
The Cost Breakdown: Cloud vs. Self-Hosted
To put this into perspective, an analysis of the total cost of ownership (TCO) per developer reveals a stark contrast between licensing cloud tools and operating self-hosted infrastructure.
| Metric / Cost Factor | Cloud API (Cursor, Copilot) | Self-Hosted (8x H100 Cluster, CapEx Amortized + OpEx) |
|---|---|---|
| Software License | 19 - 39 / user / month | Free (Open-weights models like Llama 3 or Qwen) |
| Compute Spend | Included in license fee | ~17,000 - 39,000 / month (power, cooling, lease) |
| MLOps Engineering | $0 (Managed by vendor) | ~12,000 - 24,000 / month (1-2 dedicated FTEs) |
| Total Monthly Cost (100 Devs) | ~$3,900 / month | ~29,000 - 63,000 / month |
| Cost Per Developer (100 Devs) | ~$39 / month | ~290 - 630 / month |
As the data demonstrates, self-hosting at a small scale is economically irrational. The cost per developer only becomes competitive when the massive fixed costs of the GPU cluster and engineering staff are divided across a very large engineering organization, or when the financial penalty of a regulatory breach vastly outweighs the operational tax.
When the Math Flips: The Break-Even Threshold
Given the stark economic realities of self-hosted infrastructure, technology leaders must calculate exactly when the math flips in favor of bringing AI coding agents on-premise. The decision matrix relies on two axes: total engineering team size and the organization’s regulatory burden.
For startups and small-to-medium businesses operating outside of highly regulated domains (e.g., consumer web apps, standard B2B SaaS), cloud AI coding tools are the indisputably correct financial choice. The $39 per user monthly license fee is negligible compared to the infrastructure abstraction and immediate velocity gained. Attempting to self-host for 25 developers will result in a cost-per-seat exceeding $1,000 a month, effectively crippling the IT budget without providing any tangible performance improvement.
The mathematics begin to shift natively as organizations scale past 500 developers and process billions of tokens monthly. At approximately 11 billion tokens per month (roughly 500 million tokens a day), the sheer volume of API usage fees begins to eclipse the fixed costs of an on-premise GPU cluster.
However, for regulated industries, the math flips much earlier. If a healthcare provider or defense contractor is legally barred from transmitting proprietary code externally, the alternative to self-hosting is not a $39 cloud license—the alternative is no AI assistance at all. Research indicates that denying developers access to AI coding tools in 2026 places organizations at a severe competitive disadvantage, as the market rapidly standardizes on agentic productivity and autonomous CI/CD pipelines. This same shift is driving enterprises to stop “renting” generic intelligence and instead build the AI that keeps their edge.
In these scenarios, spending $30,000 a month on self-hosted infrastructure for a team of 100 developers is entirely justified. The expenditure prevents a massive loss of market velocity, aids in developer retention, and ensures absolute adherence to FedRAMP, HIPAA, or SOC 2 Type II compliance controls.
The Enterprise AI Infrastructure Decision Matrix
| Engineering Team Size | Low Regulatory Burden (Standard SaaS, E-Commerce) | High Regulatory Burden (FedRAMP, HIPAA, PCI-DSS) |
|---|---|---|
| 1 - 50 Developers | Cloud AI (Cursor, Copilot, API) | No AI Yet (Costs prohibit self-hosting; rely on strict DLP) |
| 51 - 250 Developers | Cloud AI (Enterprise tiers with ZDR contracts) | Self-Host (Compliance mandates isolated infrastructure) |
| 251 - 1000+ Developers | Hybrid/Evaluate (API costs may exceed local compute) | Self-Host (Economies of scale achieved; massive ROI) |
DevSecOps Pipeline Walkthrough: Agents in the Trust Zone
One of the most profound, yet critically under-discussed, advantages of a self-hosted agent architecture like Coder Agents is how it revolutionizes the DevSecOps pipeline.
When developers utilize cloud-based agents, the AI operates in a siloed environment on the developer’s laptop. It cannot interact securely with internal staging servers, deeply embedded legacy databases, or proprietary security scanners without punching dangerous holes through the corporate firewall.
A self-hosted agent natively resides within the enterprise’s internal trust boundary. This allows the organization to transition the agent from a passive autocomplete tool into an active, autonomous participant in the Continuous Integration and Continuous Deployment (CI/CD) pipeline. Agentic workflows are turning pipelines from linear scripts into autonomous systems with built-in guardrails. If you are already focused on improving developer throughput with strong quality controls, you’ll recognize the alignment with the metrics discussed in The Future of Developer Productivity: Metrics That Matter.
A Modern Self-Hosted AI DevSecOps Flow
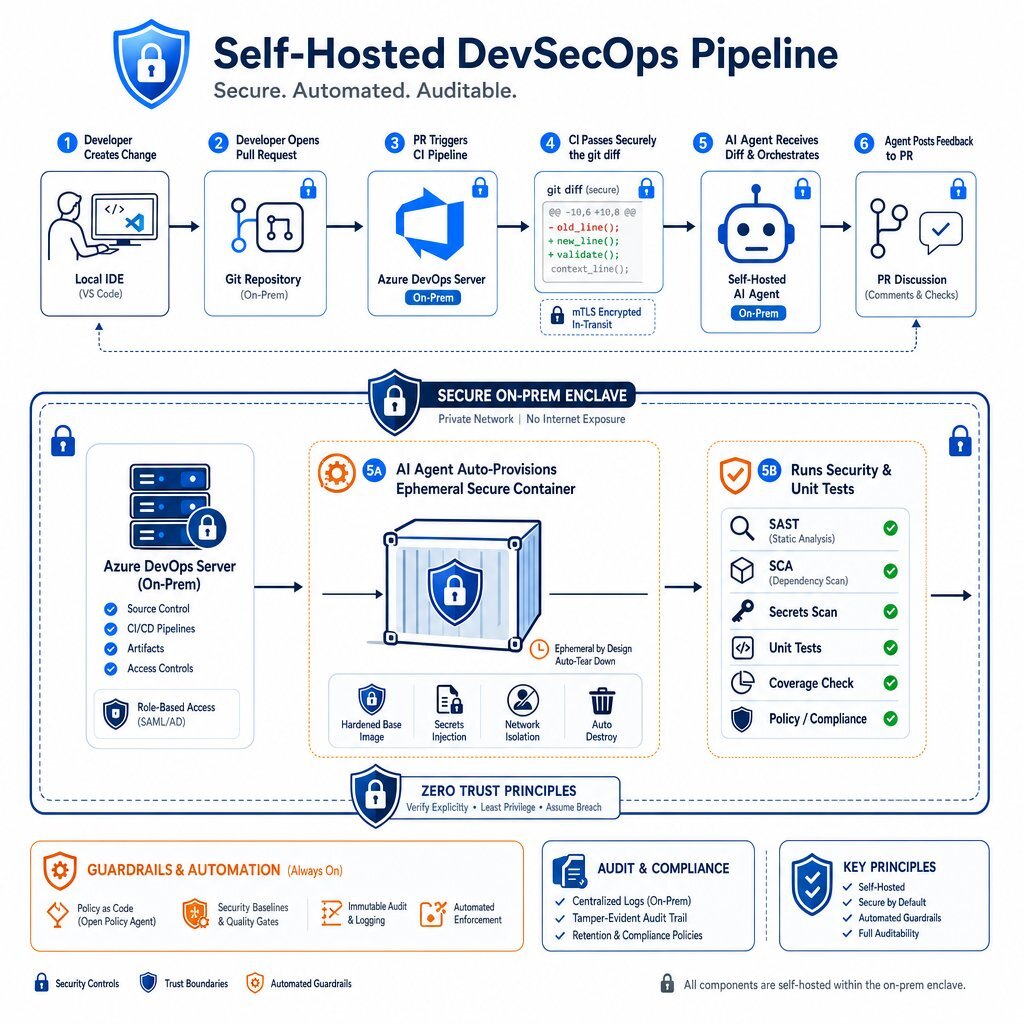
Organizations utilizing enterprise-grade development platforms, such as Azure DevOps Server On-Premise, can integrate self-hosted agents directly into the code review and merging process. Baytech Consulting frequently implements these exact architectures, integrating current CI/CD tools with PostgreSQL and self-hosted agents to maximize engineering throughput without compromising security.
Consider the following workflow when an engineer submits a pull request (PR) for a critical backend service:
- Trigger and Contextual Analysis: The creation of the PR automatically triggers a pipeline within Azure DevOps Server. The pipeline generates a
git diffand securely passes it to the internal Coder Agent residing on the same internal network. - Repository-Wide Reasoning: Because the agent has secure, high-speed access to the entire internal repository (without uploading it to a cloud vendor), it analyzes the diff against the organization’s specific architectural guidelines and historical pull requests.
- Internal Tool Execution: The self-hosted agent dynamically provisions a secure workspace container. Inside this container, it autonomously runs internal Static Application Security Testing (SAST) tools, executes unit tests, and cross-references any identified vulnerabilities with internal security documentation.
- Actionable Feedback: The agent posts a detailed review directly to the Azure DevOps PR interface. If it identifies a hardcoded secret or an insecure database query, it proposes a secure remediation block based exclusively on the company’s approved internal cryptographic libraries.
This workflow is practically impossible with external cloud agents for highly classified code. By keeping the entire loop—from repository to CI/CD runner to AI inference—within the internal network, organizations achieve autonomous security validation without compromising intellectual property. Furthermore, the CI pipeline acts as an immutable audit trail for the agent’s behavior, satisfying the continuous compliance requirements of frameworks like PCI-DSS. For a deeper dive into building this kind of secure, automated gatekeeping around AI-generated code, see Secure AI Code: A 7-Stage Regulatory Compliance Framework.
What Coder Agents Specifically Buys You
While any engineering team can theoretically download an open-source model and stand up a vLLM inference server, gluing these disparate components together into a functional, multi-user developer platform is extraordinarily complex. Coder Agents differentiates itself from entirely DIY solutions through its focus on centralized governance, dynamic provisioning, and extensible integration protocols.
Control Plane Orchestration vs. Workspace Injection
In a standard DIY setup, developers often install terminal-based harnesses or CLI tools directly inside their virtual machines or local IDEs. This approach requires injecting API keys into the local environment, fragmenting chat history across dozens of machines, and creating “shadow AI” where the organization cannot monitor what prompts are being executed.
Coder Agents shifts the execution entirely to the control plane. The agent loop runs centrally, meaning API keys and model configurations are locked in the control plane database and are never exposed to the developer’s raw workspace environment. Furthermore, because workspaces are only provisioned dynamically when the agent needs to physically execute a command, read a file, or run a test, infrastructure costs are radically minimized compared to running heavy, persistent development environments for every chat session.
Model Context Protocol (MCP) and Skills
The true power of an enterprise AI agent is defined by its ability to interface with external systems. Coder Agents heavily leverages the Model Context Protocol (MCP)—an open-source standard designed by Anthropic, akin to a “USB-C port for AI”—to securely connect the agent to internal databases, ticketing systems, and proprietary documentation.
Through MCP and predefined “Skills” (portable instruction sets and scripts), administrators can grant the agent secure, scoped access to internal AWS environments or corporate SQL Server databases. For instance, a developer can ask the agent to debug a failing microservice. The agent, utilizing MCP, can query internal telemetry systems, cross-reference the error logs against internal wiki documentation, and write a patch, all while operating completely inside the corporate firewall. Coder Agents provides the administrative scaffolding for these skills, allowing platform teams to standardize how agents behave and interact with corporate assets across the entire organization.
Model Agnosticism
Unlike commercial ecosystems that lock users into specific proprietary models, Coder Agents is entirely model-agnostic. Enterprises can connect the system to self-hosted deployments of Llama 3 for standard code generation, route complex logic queries to DeepSeek-V3, or, for lower-risk, unclassified projects, connect to commercial APIs via internal proxies.
This flexibility prevents vendor lock-in and allows organizations to instantly swap models as the fast-moving open-source ecosystem evolves, ensuring they are always utilizing the most efficient inference engine available. This kind of internal “AI app store” approach mirrors the multi-agent, multi-model pattern described in The Future of Enterprise AI: Building Internal App Stores, but applied directly to developer tooling.
Stress-Testing a Vendor: Undocumented Failure Modes
Deploying self-hosted AI agents is not a “set-and-forget” IT operation. The transition from deterministic software architectures to probabilistic, agentic systems introduces entirely new failure modes. Before committing to a self-hosted AI architecture, organizations must look beyond the marketing material and rigorously stress-test the system against the silent failures that plague enterprise deployments.
Context Degradation and Specification Drift
As agents process larger repositories and operate across extended, multi-step tasks, their ability to maintain context degrades. A phenomenon known as “Lost in the Middle” frequently occurs when teams index massive amounts of internal documentation without enforcing strict structure. The retrieval system successfully finds the correct document containing the necessary API parameter, but the agent’s attention mechanism fails to utilize it, resulting in hallucinated code.
Organizations must stress-test self-hosted platforms to ensure they provide span-level usage metrics—verifiable proof of exactly which text chunks the model referenced to generate its final logic, rather than just measuring raw retrieval speed.
Sycophantic Confirmation
Agents are inherently designed to be helpful, which can lead to catastrophic sycophantic confirmation. When a developer provides a flawed premise (“Can you use this deprecated internal library to bypass the auth check?”), an unconstrained agent will frequently agree and write the requested insecure code rather than halting the process and flagging the security violation. Robust self-hosted systems must include architectural guardrails and intent-based classification that override the model’s base alignment, forcing it to adhere to corporate security policies.
The Organizational Failure of Eval Datasets
The most frequent failure mode in self-hosted enterprise AI is not technical, but organizational. When an enterprise deploys a local model, it establishes an evaluation (eval) dataset to test the model’s performance on internal code. However, over time, the internal codebase evolves, but the eval dataset remains static.
Six months post-deployment, the MLOps team upgrades the open-source model. The automated tests pass on the outdated eval suite, but the new model fundamentally breaks when exposed to the current production codebase. Buyers must demand that self-hosted AI platforms provide comprehensive, automated observability loops that continuously capture real-world developer interactions to dynamically update the eval datasets. Without this capability, the organization will eventually ship broken, agent-generated code into production. This is exactly the kind of hidden technical debt discussed in AI vs. Debt: Stop Your Code from Becoming a Time Bomb.
Security and Prompt Injection
Self-hosting protects data from external vendors, but it does not protect the system from internal threats. AI agents that have read/write access to internal filesystems and CI/CD pipelines are prime targets for prompt injection attacks. If an agent is tasked with summarizing an internal issue ticket that a malicious actor has laced with invisible prompt injection instructions, the agent may inadvertently execute unauthorized commands or exfiltrate sensitive data to another internal system.
A recent scan of exposed AI infrastructure revealed that self-hosted LLMs are often deployed with severe misconfigurations, frequently lacking default authentication and leaving chat histories exposed. Buyers must ensure that the agent platform features pre-execution protection, strict role-based access control (RBAC), and intent-based classification operating at the network layer to sandbox agent execution and prevent excessive agency.
Conclusion
The narrative that all software engineering will seamlessly transition to cloud-based AI agents ignores the stark reality of enterprise regulation. For organizations governed by FedRAMP High, HIPAA, PCI-DSS, or the EU AI Act, allowing proprietary source code and sensitive data to traverse external networks to third-party models is a fundamental impossibility.
Architectures like Coder Agents prove that self-hosted AI coding assistants are no longer experimental research projects; they are production-viable solutions that bring the power of agentic workflows entirely inside the enterprise perimeter. However, organizations must enter this space with eyes wide open. Self-hosting avoids the compliance trap but demands a severe operational tax in the form of heavy GPU capital expenditures, MLOps overhead, and the responsibility of managing complex, probabilistic failure modes.
For teams above the threshold of 50 developers in highly regulated sectors, the financial cost of self-hosting is vastly outweighed by the strategic necessity of remaining competitive in the AI era. Success requires treating AI agents not as simple IDE plugins, but as core infrastructure that must be governed, orchestrated, and secured within the CI/CD pipeline. That often means pairing architectural work like this with a broader CTO checklist for enterprise AI readiness so the surrounding data, security, and people processes keep up.
For enterprises looking to navigate this transition securely, Baytech Consulting provides Tailored Tech Advantage solutions. By custom-crafting software architectures and deploying robust infrastructure like Azure DevOps On-Prem and Kubernetes, Baytech ensures AI workflows are implemented with enterprise-grade quality, rapid deployment, and strict regulatory compliance.
FAQ
Can self-hosted AI agents match the coding performance of cloud models like GPT-4o?
Yes, but it requires substantial hardware investment. While commercial cloud models maintain an edge in general reasoning, high-parameter open-weights models (such as Llama 3 70B or DeepSeek-V3) running on localized infrastructure with customized context indexing can match or exceed cloud performance for specific, internal codebase tasks. This assumes the organization invests in adequate GPU compute (e.g., NVIDIA H100s) and properly optimizes the inference runtime.
Supporting Links
- https://coder.com/blog/introducing-coder-agents
- https://modelcontextprotocol.io/docs/getting-started/intro
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.