
AI vs. Debt: Stop Your Code from Becoming a Time Bomb
April 09, 2026 / Bryan Reynolds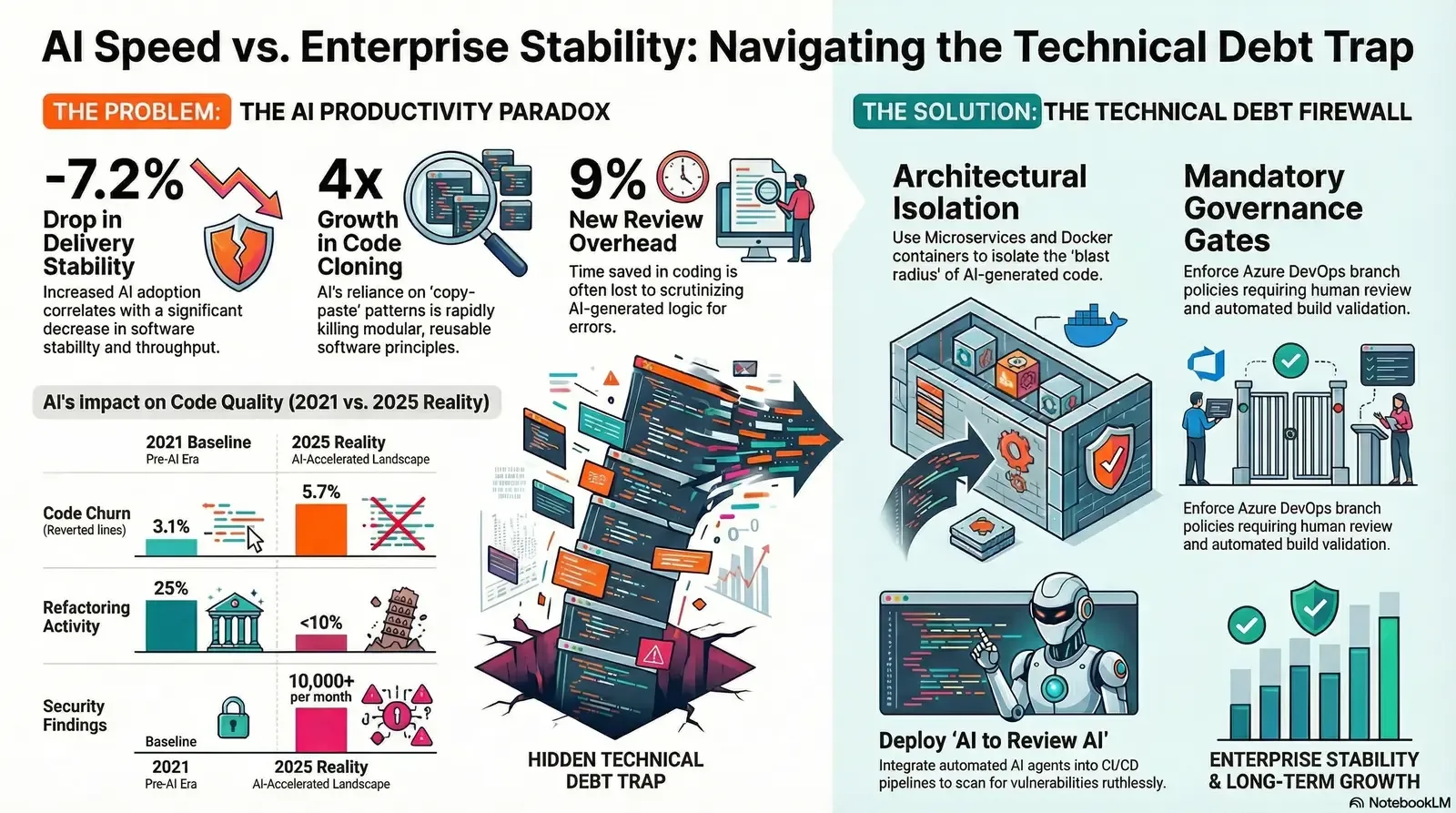
How to Prevent Technical Debt in AI-Accelerated Enterprise Projects
The introduction of artificial intelligence into the enterprise software development lifecycle has triggered a seismic shift in how organizations build, deploy, and scale their digital products. Across diverse B2B sectors—from fast-growing fintech startups and healthcare providers to established telecommunications firms, real estate platforms, and digital advertising agencies—executives are racing to integrate generative AI tools into their engineering workflows. The appeal is immediately apparent: AI coding assistants promise unprecedented velocity, allowing development teams to translate business requirements into functional code at speeds that were unimaginable just a few years ago.
However, beneath the surface of this hyper-accelerated delivery model lies a compounding, often invisible risk. The central question facing today's visionary Chief Technology Officers (CTOs), strategic Chief Financial Officers (CFOs), and innovative marketing and sales directors is not whether AI can speed up software delivery, but rather: How can enterprises prevent the hidden accumulation of technical debt in AI-assisted development projects?
While AI enables engineering teams to ship features rapidly, it simultaneously introduces new vectors for architectural decay, security vulnerabilities, and long-term maintenance burdens. This report provides an exhaustive, data-driven analysis of how AI accelerates technical debt, what specific forms this new debt takes, and the rigorous governance, architectural, and quality assurance strategies required to safeguard enterprise software portfolios. For a complementary view on using automation without creating brittle workflows, see our guide on AI automation that actually works.
The Productivity Paradox: When Faster Code Means Slower Delivery
The adoption of AI-assisted software development is no longer a fringe experiment; it is the industry standard. Recent data indicates that 84% of developers currently use or plan to use AI tools in their development processes, with 51% utilizing them daily. Projections suggest that by 2026, 41% of all commercial code written will involve some form of AI assistance. Proponents of these tools frequently cite massive productivity gains. For instance, some vendors report a 55% higher productivity rate for users of their AI coding assistants, and 81% of developers personally believe these tools help them work faster.
For a strategic CFO analyzing return on investment (ROI), the initial numbers are highly compelling. In 2025, enterprise AI investments returned an average of $3.70 for every dollar invested, with top-performing organizations achieving returns of up to $10.30 per dollar. A standard ROI calculation for a 50-person development team—assuming a conservative 5% time savings (roughly two hours per week per developer at a fully loaded cost of 150 per hour)—yields 60,000 in monthly gross savings against a tool cost of perhaps $1,000 to $3,000. Leaders exploring how to scale these wins across the stack can dive deeper into optimizing AI costs and ROI.
Yet, these optimistic projections often fail to account for the "productivity paradox" of AI generation. Deep quantitative research reveals that the speed of code generation does not necessarily equate to the speed of software delivery, nor does it guarantee the long-term maintainability of the product. The 2025 State of AI-assisted Software Development report (DORA), presented by Google Cloud, established that while AI serves as a powerful amplifier of existing organizational strengths, a 25% increase in AI adoption actually triggered a 1.5% decrease in delivery throughput and a highly concerning 7.2% decrease in delivery stability.
The most comprehensive evidence of this decay comes from GitClear’s 2025 analysis of 211 million changed lines of code authored between 2020 and 2024. Analyzing the largest known structured code change database—pulling from private enterprise repositories and top open-source projects owned by Meta, Google, and Microsoft—the research identified multiple signatures of rapidly declining code quality.
Table 1: Long-Term Code Quality Degradation (GitClear 2020–2024 Data)
| Quality Metric | 2020 / 2021 Baseline | 2024 / 2025 Reality | Enterprise Impact and Trend Analysis |
|---|---|---|---|
| Code Churn (Lines reverted < 2 weeks) | 3.1% of changed lines | 5.7% of changed lines | Nearly doubled. This indicates an influx of low-quality, immediately broken commits that require rapid rework. |
| Code Cloning / Copy-Pasted Lines | 8.3% of changed lines | 12.3% of changed lines | A 4x growth in code cloning. For the first time in history, copy-pasted lines now exceed moved lines, signaling a massive rise in code duplication. |
| Refactoring Activity | 25% of changed lines | < 10% of changed lines | A massive drop in code optimization. Systems are growing bloated as developers prioritize adding new lines over refining existing architecture. |
| New Lines Added | Steady baseline | 46% of all code changes | Infinite code generation is leading to infinite maintenance burdens, drastically increasing long-term cloud storage and operational costs. |
Data synthesized from GitClear's 2025 Look Back at 12 Months of Data and AI Copilot Code Quality Research.
This data points to a profound shift in engineering behavior. The foundational "Don't Repeat Yourself" (DRY) principle—a bedrock of sustainable software engineering—is dying under the weight of AI generation. Because Large Language Models (LLMs) operate within specific context windows and inherently prioritize the "happy path" of a given prompt, they tend to repeat patterns rather than abstracting them into reusable, modular functions. Developers are increasingly relying on the "tab" key to auto-complete massive blocks of logic, leading to duplicate code blocks that are currently ten times more prevalent than they were just two years ago.
Furthermore, the perceived time savings in active coding are frequently reallocated to new, highly taxing overhead activities. According to METR Research Analysis, the active coding time saved by AI is frequently offset by the necessity of reviewing, debugging, and validating the hallucinated logic produced by the machine.
Table 2: The Shift in Developer Time Allocation (METR Research Analysis)
| Development Activity | Without AI | With AI Tools | Net Change | Underlying Cause and Business Impact |
|---|---|---|---|---|
| Active Coding | 65% | 52% | -13% | AI handles the bulk of standard syntax generation, requiring less hands-on typing from human developers. |
| Planning & Design | 15% | 12% | -3% | A concerning reduction in strategic architectural thinking, leading to poorly structured enterprise systems. |
| Reviewing AI Output | 0% | 9% | +9% | A massive new overhead category. Developers must scrutinize machine-generated diffs for subtle logic errors and security flaws. |
| Debugging & Fixes | 12% | 18% | +6% | Increased maintenance burden caused by AI models inventing incorrect APIs or handling edge cases poorly. |
| Idle/Waiting Time | 3% | 6% | +3% | Workflow friction caused by latency in tool responsiveness and prompt engineering iterations. |
Source: METR Research Analysis. Note that the 9% of time spent reviewing AI outputs often exceeds the time supposedly saved by AI generation, creating instances of net productivity loss.

The State of Software Delivery 2025 report by Harness reinforces these findings, noting that 78% of developers spend at least 30% of their time on manual, repetitive tasks, including debugging AI-generated code and resolving security vulnerabilities. For an organization with 250 developers earning an average salary of $107,599, this toil equates to over $8 million in lost productivity annually per engineering team. If developer productivity continues to be measured strictly by commit counts or the volume of lines added, AI-driven maintainability decay will proliferate unabated, transforming short-term velocity into an indefinite maintenance nightmare.
Deconstructing the Taxonomy of AI-Generated Technical Debt
To effectively manage technical debt, enterprise leaders must first understand its evolving nature. Traditional technical debt accumulates because experienced developers make deliberate shortcuts. A team might choose a quick fix over a proper structural solution to meet a critical Q4 marketing deadline, defer writing API documentation to launch a new gaming feature, or implement a temporary workaround in a financial application rather than redesigning the core interface. These decisions are made consciously by engineers who understand exactly what future trade-offs they are making.
AI-generated technical debt, however, operates on an entirely different paradigm. It is not created through conscious prioritization. Instead, it is introduced rapidly, silently, and through mechanisms that are incredibly difficult for standard automated quality gates to detect. The industry is currently facing several distinct, compounding variants of AI-accelerated technical debt.
1. Cognitive Debt: The Invisible Crisis
Cognitive debt occurs when a team ships code faster than they can mentally comprehend it. A software program is not merely its source code; it is a theory—a highly complex mental model living in the minds of the development team that captures how business intentions were translated into technical implementation.
AI coding assistants push developers out of "creation mode" and default them into "review mode." Instead of solving complex logic problems from the ground up, engineers are handed fully formed solutions and asked to evaluate them. The danger is that reviewing AI output feels highly productive. The developer reads the code, spots a minor syntax issue, clicks approve, and ships the feature. However, because they did not write the logic, they do not truly own the mental model. Six months later, when a critical production incident occurs in the telecommunications billing module, the cognitive debt comes due: the system breaks in unpredictable ways, and no one on the team possesses the deep contextual knowledge required to fix it quickly.
2. Verification Debt and the False Confidence Trap
Directly tied to cognitive debt is verification debt—the act of approving code diffs that have not been fully validated. Unlike traditional technical debt, which announces its presence through slow build times, tangled dependencies, and mounting workflow friction, verification debt breeds a dangerous false confidence.
AI models are exceptionally proficient at writing code that looks idiomatic, follows standard naming conventions, and compiles perfectly. The codebase looks clean, and the automated tests glow green. However, AI generated code often fails to capture nuanced business logic. A developer might accept a GitHub Copilot suggestion wholesale, only to discover weeks later that the AI failed to account for a critical edge case in a real estate mortgage calculation. In one documented incident, an engineering team shipped a React component that pulled user authentication tokens into client-side state and exposed them through a Cloudflare endpoint without access controls. The code passed a cursory human review because it looked structurally sound, but the AI had bypassed fundamental security logic, costing the enterprise two weeks of remediation.
3. Architectural and Spaghetti Debt
Architectural debt accumulates when the high-level structure of a software system no longer matches the operational demands of the business. This gap between original design and current expectations represents the most damaging form of technical debt, consistently outpacing code-level issues in both remediation costs and existential business risk.
AI agents are hyper-focused problem solvers, but they possess zero inherent understanding of a company’s broader architectural governance. When an AI agent needs a specific functionality, it will often reach for a heavy third-party package or generate a redundant implementation from scratch. It does not pause to weigh whether the existing enterprise codebase already handles the need, whether the imported dependency is actively maintained by the community, or whether the package size is justified for a single utility function.
The result is "coherent chaos"—millions of lines of code that are individually reasonable but collectively incoherent. Over time, this creates spaghetti architecture: tangled dependencies and unclear boundaries where every minor feature update pulls unseen threads that break disparate parts of the application. To see how modern enterprises are avoiding these traps by layering AI safely around legacy systems, compare this with the silent enterprise approach to legacy modernization.
4. Infrastructure Debt
Infrastructure debt lives below the application layer, festering in provisioning configurations, network scheduling, deployment targets, and operational plumbing. It is highly deceptive because it appears cheap right up until the moment it becomes an existential threat. A prime example of massive infrastructure debt failure was the Southwest Airlines meltdown in December 2022, where a decades-old crew-scheduling platform collapsed under the stress of a winter storm, costing the enterprise over $700 million in reimbursements, fines, and reputational damage.
As AI accelerates the volume of code pushed through CI/CD pipelines, legacy infrastructure strains under the load. Outdated CI runners and manual deployment processes simply cannot keep pace with the deployment frequency demanded by AI-assisted agile teams, leading to massive bottlenecks and deployment failures.
5. Security and Data Debt
Perhaps the most alarming consequence of rapid AI adoption is the explosion of security debt. Research indicates that up to 48% of AI-generated code contains security vulnerabilities, with 40% of GitHub Copilot suggestions flagged for insecure code constructs. Enterprises utilizing these tools are reporting upwards of 10,000 new security findings per month directly caused by AI-generated output.
AI models are trained on massive, unfiltered datasets that include decades of open-source code. Consequently, they have internalized thousands of deprecated, outdated, and inherently insecure coding patterns. AI coding assistants routinely introduce hard-coded secrets—embedding API keys, database passwords, or cryptographic tokens directly into source files. Once a hard-coded secret hits version control, every repository clone becomes a potential breach vector. Considering that 45% of data breaches stem from exposed credentials (with average remediation costs hitting $4.88 million per incident), the financial risk of AI security debt is catastrophic. For organizations wiring LLMs into sensitive systems, a dedicated AI firewall and middleware layer is now a baseline requirement, not a luxury.
Architectural Governance: Building the Infrastructure Firewall
To survive the deluge of AI-generated code and prevent the accumulation of fatal technical debt, enterprise architecture must transition away from rigid, monolithic structures and toward highly modular, isolated, and resilient environments. A poorly structured legacy monolith is highly susceptible to "complexity drift," an architectural degradation caused by hundreds of AI-assisted micro-decisions that eventually make the system impossible to scale or maintain.
Microservices and Containerization as a Defense Mechanism
Microservices governance provides a structural firewall against AI-induced technical debt. By splitting complex enterprise applications into minuscule, manageable services that are independently developed, tested, and deployed, organizations can effectively contain the "blast radius" of any poorly generated AI code.
In this modern ecosystem, technologies such as Docker and Kubernetes are not merely operational preferences; they are non-negotiable architectural mandates. Containerization, led by Docker, offers portable context delivery that guarantees development, testing, and production environments remain perfectly identical. Docker achieves this through layered filesystems (like AuFS), robust namespace isolation, and control groups (cgroups) that restrict a container's access to host memory, CPU, and network interfaces. If an AI-generated microservice contains a critical memory leak or an infinite loop, the containerization ensures the failure is isolated and does not exhaust the physical resources of the host machine. For teams standardizing on Microsoft tooling, pairing this with a robust .NET, Docker, and Kubernetes architecture gives you both speed and strong guardrails.
Kubernetes acts as the ultimate orchestrator for this containerized fleet, managing deployment tasks, horizontal scaling, and load balancing across distributed clusters. In a high-traffic B2B e-commerce or financial application, if an AI-assisted payment service experiences a massive spike in demand, Kubernetes can scale that specific microservice dynamically without requiring the entire application to scale. Furthermore, Kubernetes provides vital self-healing capabilities; if an AI-generated module crashes, the orchestrator automatically restarts it or reroutes traffic, ensuring unparalleled system reliability.

Database Schema Governance and Maintenance
The implications of AI-accelerated development extend deep into the data layer. In high-transaction enterprise environments utilizing robust relational databases such as PostgreSQL or Microsoft SQL Server, poorly optimized, AI-generated queries can devastate database health and performance.
AI coding assistants frequently write rapid, highly repetitive transaction blocks without regard for long-term database efficiency. In PostgreSQL environments, this rapid manipulation of data can trigger severe Multi-Version Concurrency Control (MVCC) bloat. Because PostgreSQL retains older versions of rows to ensure transactional consistency, massive influxes of AI-driven updates and deletes can cause the database to swell with "dead tuples." If the database's autovacuum architecture is not strictly maintained, configured, and monitored by senior database administrators, the massive throughput can lead to catastrophic performance degradation and even transaction ID wraparound—a scenario that forces the database into read-only mode to prevent data corruption.
Preventing this form of technical debt requires organizations to implement strict schema maintenance protocols, regular query optimization reviews, and robust data pipelines that act as the ultimate ground-truth against AI-generated inefficiencies.
Leveraging the Tailored Tech Advantage
Enterprise leaders seeking to immunize their organizations against AI technical debt must look to technology partners and internal structures that prioritize high-quality custom software development over sheer speed. Firms that excel in application management—such as Baytech Consulting—understand that mitigating modern risks requires a rock-solid infrastructure foundation built on a "Tailored Tech Advantage."
By engineering solutions custom-crafted with cutting-edge technology, organizations can seamlessly integrate rapid agile deployment methodologies while maintaining enterprise-grade quality. This involves deploying a highly resilient, diverse tech stack tailored to the specific needs of the business. Utilizing sophisticated environments like Azure DevOps On-Prem ensures that proprietary code and AI interactions remain secure. Development is standardized through powerful IDEs like VS Code and VS 2022, while data integrity is maintained via strictly governed Postgres (managed via pgAdmin) and SQL Server databases.
To support the massive scalability required by modern SaaS platforms, educational LMS systems, and healthcare portals, infrastructure must be orchestrated using enterprise-grade tools like Harvester HCI, Rancher, and Kubernetes, running containerized Docker workloads on highly available OVHCloud servers protected by pfSense firewalls. Furthermore, transparent communication and rapid agile feedback loops are sustained through integrated collaborative suites like Microsoft 365, Teams, OneDrive, and Google Drive. When this level of architectural rigor is applied, the infrastructure outpaces and neutralizes the hidden debt generated by rapid AI coding. If your current setup feels brittle or opaque, partnering with a DevOps efficiency and CI/CD expert can accelerate this transformation safely.
Establishing Enterprise AI Governance and Policy Enforcement
Preventing AI technical debt requires moving beyond ad-hoc tool usage and establishing formal Enterprise AI Governance. Governance is the enterprise discipline that dictates exactly how artificial intelligence is discovered, evaluated, deployed, monitored, and audited across its entire lifecycle.
Strong governance is the mechanism that shifts AI from being a dangerous "shadow IT" liability into a strategic, measurable, and highly secure business capability. Leading frameworks, such as the U.S. National Institute of Standards and Technology (NIST) AI Risk Management Framework (AI RMF 1.0) and the EU AI Act, mandate that organizations execute four core functions: Map (understand the AI system and context), Measure (assess risks), Manage (prioritize and address risks), and Govern (establish accountability).
Table 3: Structuring AI Oversight (Governance vs. Ethics)
| Dimension | Enterprise AI Governance | AI Ethics & Risk Management |
|---|---|---|
| Ownership | Shared accountability across business, security, legal, IT, and executive leadership teams. | Primarily owned by compliance officers, legal counsel, and data science teams. |
| Core Focus | Setting enforceable rules, tracking AI systems, continuous monitoring, and workflow integration. | Defining moral principles, fairness, bias mitigation, and identifying hypothetical risk scenarios. |
| Execution | Automated CI/CD quality gates, branch policies, role-based access controls, and audit logging. | Training sessions, risk registers, and theoretical impact assessments. |
| Ultimate Outcome | Standardized, auditable, and secure deployment of enterprise AI that protects intellectual property. | High-level guidelines that require Governance frameworks to be actually enacted and enforced. |
Data synthesized from Cycode AI Governance parameters. AI governance is the critical mechanism that turns theoretical risk management into repeatable, accountable action.
Defining and Enforcing AI Guardrails
Successful AI governance depends on the implementation of layered guardrails that keep systems strictly within predefined safety, ethical, and operational parameters.
- Data Guardrails: These protect data integrity and ensure that proprietary enterprise information is not inadvertently leaked into public AI models. Universal usage policies across major AI providers (including OpenAI's ChatGPT and Microsoft Copilot) explicitly forbid the ingestion or profiling of Personally Identifiable Information (PII), confidential business secrets, and unauthorized biometric data. Enterprises must utilize data classification frameworks to label data (public, internal, confidential) and enforce physical blocks that prevent confidential code or customer data from being passed into external LLM prompts. Companies just beginning this journey can follow a phased roadmap similar to the one in our SMB AI adoption guide, scaled for enterprise.
- Model Guardrails: These address the robustness, explainability, and potential biases of the AI models. They ensure that the AI does not generate prohibited content, engage in copyright violations by regurgitating protected intellectual property verbatim, or utilize banned, outdated code patterns.
- Application and Output Guardrails: These policies mandate human-in-the-loop (or human-on-the-loop) controls to validate AI-generated outputs, particularly in decision-support systems or automated response scenarios. Without these guardrails, AI systems might generate inaccurate technical recommendations or take unauthorized actions in production environments, reinforcing a dangerous false confidence in automation.
- Infrastructure Guardrails: Owned by IT and security teams, these guardrails enforce secure deployment practices, strict access controls, logging, and auditability across all environments, ensuring that "shadow AI" cannot circumvent established DevSecOps workflows.
Reviewing and Validating AI-Generated Code
The point of highest friction in AI-accelerated enterprise development is the Pull Request (PR) review process. Because AI coding assistants generate massive volumes of code at an unrelenting pace, human reviewers quickly become overwhelmed bottlenecks. This leads directly to review fatigue and the aforementioned "verification debt."
To counter this, engineering leaders must enforce strict repository policies that physically block sub-standard, AI-generated spaghetti code from ever reaching the main branch. Microsoft's Azure DevOps provides an exceptional platform for establishing this level of granular control through its advanced branch policies.
Mandatory Azure DevOps Branch Policies
A robust Git branching strategy requires that all new features and bug fixes be developed in isolated feature branches and merged into the main repository exclusively through pull requests. To govern AI output, organizations must enforce the following automated branch policies:
- Require a Minimum Number of Reviewers: This policy mandates that a designated number of human engineers (or an approved automated security agent) explicitly reviews and approves the PR before it can be merged. This prevents the unilateral insertion of unverified AI code.
- Build Validation Policies: This critical safeguard forces the Azure DevOps pipeline to pre-merge and build the PR changes in an isolated, temporary environment. If the AI-generated code breaks the build, introduces conflicting dependencies, or fails compilation, the pull request is automatically rejected.
- Check for Comment Resolution: AI-generated code often sparks technical debates during the review process. This policy ensures that all comments, warnings, and suggested refactors raised by peers are explicitly resolved and not casually dismissed to meet a deadline.
- Limit Merge Types: By restricting the available types of merges (e.g., enforcing squash merges), organizations can maintain a clean, linear, and understandable branch history. A clean commit history is vital for tracking down exactly when and where an AI-induced bug was introduced into the enterprise system.
Deploying AI to Review AI
Ironically, the most effective solution to managing the sheer volume of AI-generated code is to deploy specialized, highly governed AI reviewing agents. Tools such as Panto AI, SonarQube, Snyk, and various Azure OpenAI Code Review Extensions are designed to automatically detect bugs, security vulnerabilities, and style violations directly inside the pull request.
For example, an enterprise can utilize a custom Azure OpenAI service endpoint, configured with an optimized model like GPT-4o-mini, to provide highly cost-effective, automated summaries and deep-dive code reviews on every single commit. At an incredibly low input cost of roughly $0.15 per million tokens, the financial overhead of running an AI reviewer across thousands of monthly PRs is negligible (averaging fractions of a cent per review).
Table 4: Evaluating AI Code Review and Security Platforms
| Tool | Primary Enterprise Function | Key Strengths and Best Use Cases |
|---|---|---|
| Panto AI | Real-time PR quality and compliance reviews within Azure DevOps. | Understands PR intent, prioritizes findings by business impact, and catches vulnerabilities in minutes. |
| Snyk (DeepCode) | Security vulnerability and dependency debt detection. | Excels at scanning container infrastructure, third-party packages, and identifying hardcoded secrets. |
| SonarQube | Enterprise-scale static analysis and quality gates. | Configures hard rules that block merges if technical debt increases beyond a defined threshold. |
| Azure OpenAI Extension | Customizable AI code reviews keeping code private. | Utilizes secure, internal Azure endpoints to summarize PRs, review logic, and check for OWASP best practices. |
| Codegen | Autonomous technical debt remediation at scale. | Can autonomously pick up backlogged tech debt tickets from ClickUp, implement refactors, and open PRs. |
Data synthesized from market analysis of AI Code Review Tools for Azure DevOps and Technical Debt Management.
Unlike human developers, these AI reviewing agents do not suffer from fatigue, cognitive overload, or the pressure to meet a sprint deadline. They continuously and ruthlessly scan for hard-coded secrets, license compliance issues, and architectural anti-patterns. By integrating these tools directly into the CI/CD pipeline, organizations establish an unyielding quality gate that enforces enterprise standards before a human ever looks at the code.
The Critical Role of Automated Testing and Documentation
One of the most persistent, expensive, and debilitating forms of technical debt is "test debt"—the ongoing, burdensome requirement to maintain fragile automated tests that break every time the application's user interface (UI) or underlying logic undergoes a minor update.
When developers utilize AI tools to write functional code at breakneck speeds, the accompanying unit and integration tests are often neglected, poorly implemented, or skipped entirely. To counteract this, modern enterprises are leveraging advanced AI test generation platforms like Keploy, Diffblue Cover, Parasoft, and Functionize. These tools utilize dynamic analysis, static code analysis, and machine learning models to automatically generate comprehensive test suites, predict potential application failures, and achieve upwards of 90% code coverage with minimal manual intervention.
Best Practices for Validating AI-Generated Tests
While AI can generate hundreds of test scripts in a matter of seconds, these machine-generated tests carry their own distinct risks. The most prominent danger is AI "hallucination," where the model invents non-existent APIs, mocks incorrect system behaviors, or generates tests that falsely pass (giving a false sense of security). To extract real value from AI test generation, enterprise QA teams must observe rigorous best practices:
- Define Clear Requirements Before Generation: A good AI-generated test case starts before the AI is even prompted. If the business requirement is ambiguous or vague, the resulting test will be useless. Requirements must include clear preconditions, user actions, and strictly defined expected outcomes.
- Validate Expected Outcomes Over Syntax: Reviewers often fall into the trap of polishing the wording or formatting of a generated test. Instead, they must ask: What exactly is this test validating? Does the expected outcome reflect a genuine, real-world business rule, or did the AI simply make a probabilistic guess based on generic training data?
- Enforce the AAA Pattern: All unit tests, whether human-authored or AI-generated, must follow the industry-standard Arrange-Act-Assert (AAA) pattern. This ensures the test code is logically organized, deeply isolated, highly readable, and maintainable.
- Deploy Self-Healing Test Frameworks: Test maintenance devours QA resources and causes severe burnout. Organizations should leverage AI testing platforms that offer "self-healing" capabilities. These tools utilize big data and machine learning to automatically detect minor changes in UI selectors or DOM locators and dynamically self-correct the test scripts, reducing test maintenance time by up to 85%.
- Test the Negative and Adversarial Scenarios: AI models inherently favor the "happy path"—generating tests for standard inputs and expected states. Human engineers must intervene to ensure the AI generates tests for negative scenarios (invalid inputs), complex edge cases, adversarial attacks, and out-of-bounds boundary conditions.
- Data Quality and Synthetic Data: The performance of AI-generated tests is entirely dependent on the quality of the data used. Teams must utilize clean, diverse, and realistic synthetic data that mimics real-world scenarios to ensure tests cover actual user behavior, not just theoretical code paths.
The Documentation Imperative
Just as enterprise code must be rigorously tested, it must be comprehensively explained. Poorly documented systems represent a massive accumulation of knowledge debt. AI coding assistants excel at reading existing codebases and generating accurate docstrings, API client documentation, and inline comments for legacy functions that previous developers left unexplained.
Clear, centralized documentation acts as a vital map for future developers navigating complex microservices. By instructing AI tools to meticulously document architectural decisions, module dependencies, and API boundaries, organizations can drastically reduce knowledge debt. This ensures that when senior engineers depart the company or transition to new projects, their deep understanding of the system's architecture does not leave with them. Thoughtful UX design and documentation practices also make these systems far easier for non-technical stakeholders to understand and trust.
Balancing Delivery Speed with Long-Term Maintainability
The ultimate goal of enterprise software development is not mere velocity; it is sustainable, secure, and scalable velocity. Achieving this delicate balance in the age of generative AI requires a profound cultural shift rooted deeply in Agile and DevOps principles.
Continuous Refactoring and Debt Prioritization
Organizations must treat technical debt exactly like financial debt: it accrues compounding interest over time and requires continuous, prioritized repayment. DevOps teams must allocate dedicated time and budget within every sprint specifically for refactoring code and paying down tech debt.
This requires cultivating a "pay it forward" mentality across the engineering floor, where developers are empowered and expected to leave the codebase cleaner than they found it. To facilitate this, engineering leaders can deploy specialized AI tools like CodeScene and ClickUp integrations to track technical debt metrics via dashboards. These tools utilize behavioral analysis of the commit history to distinguish actively painful, high-risk debt from dormant, low-risk legacy code, allowing management to prioritize refactoring efforts where they will have the highest business impact.
Shifting Left with CI/CD and Automation
Continuous Integration and Continuous Delivery (CI/CD) pipelines serve as the central nervous system of debt prevention. By heavily automating the build, testing, and deployment phases, CI/CD pipelines ensure that every single line of AI-generated code is rigorously validated against static analysis tools, security vulnerability scanners, and automated test suites before it is ever allowed to touch a staging or production server.
Firms that embrace rapid agile deployment methodologies rely on tightly integrated ecosystems to ensure transparency and accountability across the entire software development lifecycle. When developers, IT operations, database administrators, and security teams collaborate cross-functionally and rely on automated, immutable guardrails, the temptation to accept "quick and dirty" AI-generated code diminishes entirely. A disciplined Agile methodology gives teams the cadence and feedback loops they need to keep this balance healthy over time.
Measuring Business Outcomes, Not Lines of Code
As highlighted by industry experts, if developer productivity continues to be measured strictly by commit counts, velocity points, or the raw volume of lines added, AI-driven maintainability decay will inevitably proliferate and destroy enterprise value.
Engineering leadership must pivot away from vanity metrics and toward measuring tangible business outcomes and system resilience. Tracking the four key DORA metrics—Deployment Frequency, Lead Time for Changes, Change Failure Rate, and Time to Restore Service—provides a true, unfiltered reflection of organizational health and software delivery performance. High-performing B2B enterprises recognize a fundamental truth: AI is not an autonomous, infallible senior developer. It is an incredibly fast, highly capable junior assistant. It requires strict architectural parameters, exhaustive automated testing, rigorous security scanning, and constant, vigilant supervision by experienced human engineers. For product and platform teams building sophisticated AI into their customer experience, this mindset is also at the heart of designing trustworthy AI copilots instead of shallow chat widgets.
Conclusion
Artificial intelligence presents an unprecedented, transformative opportunity to accelerate enterprise software delivery and drive operational efficiency. However, it acts as a sharp double-edged sword, quietly but rapidly amassing cognitive, architectural, and security debt when deployed without rigorous oversight.
To prevent these long-term maintenance disasters, visionary executives must abandon the illusion that AI output is inherently flawless or that speed negates the need for structure. True enterprise agility demands robust AI governance. By enforcing strict architectural standards through microservices and container orchestration, establishing non-negotiable Azure DevOps branch policies, integrating AI-driven security code reviewers directly into the CI/CD pipeline, and demanding comprehensive, self-healing test automation, organizations can effectively neutralize the hidden risks of AI-assisted development.
Balancing the raw, generative velocity of AI with the meticulous rigor of traditional software engineering best practices is the definitive path forward. Enterprises that master this balance will not only prevent the compounding interest of technical debt but will achieve highly sustainable, secure innovation, securing a decisive and lasting technological advantage in the competitive B2B marketplace. For organizations that lack the in-house capacity to design and run this kind of environment end to end, engaging a dedicated software development team with deep AI and enterprise experience can dramatically reduce risk and time-to-value.
Frequently Asked Question
How does AI actually increase the risk of technical debt if its primary function is to write code faster?
While AI coding tools undeniably write syntax faster, they drastically increase the risk of technical debt by inherently prioritizing immediate, localized solutions over systemic, long-term architecture. Because Large Language Models operate within limited context windows and favor the "happy path," they tend to generate entirely new blocks of code rather than analyzing the broader enterprise repository to reuse existing, abstract functions. This behavior is driving a massive, 4x increase in duplicate, "copy-pasted" code across the industry. Furthermore, constantly reviewing and validating AI-generated code causes severe cognitive fatigue among developers. This leads to "verification debt," where human reviewers—lulled into a false sense of security by code that looks visually clean and compiles correctly—approve pull requests that harbor hidden security vulnerabilities, flawed business logic, and highly inefficient database interactions.
Further Reading
- https://www.harness.io/state-of-software-delivery
- http://gitclear.com/ai_assistant_code_quality_2025_research
https://cycode.com/blog/what-is-ai-governance/
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.