
From Copilots to Swarms: Taming the AI Agents That Write Your Code
May 11, 2026 / Bryan Reynolds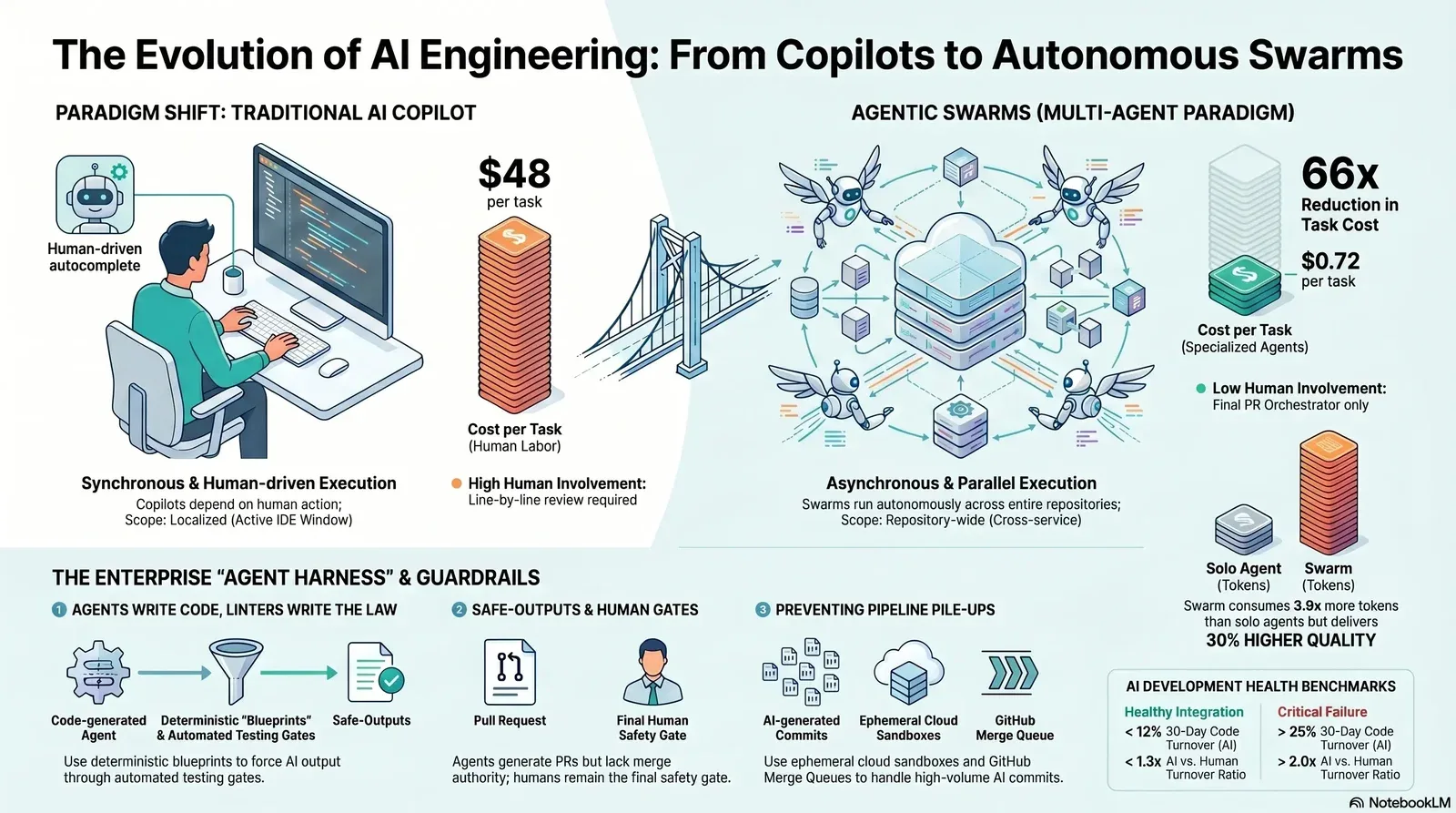
GitHub Enterprise "Minions": Managing AI Agent Swarms Without Pipeline Pile-Ups
The software engineering landscape has crossed a critical threshold, moving rapidly from an era of manual keystrokes to one of automated orchestration. Industry data indicates that in highly mature deployments, up to 41% of all code written by active developers is now generated by artificial intelligence.
However, the mechanisms driving this code generation are undergoing a radical architectural transformation. Organizations are migrating away from the interactive, autocomplete-driven world of AI pair programmers and entering the era of agentic swarms. High-performing engineering teams are no longer simply typing faster; they are deploying fleets of autonomous, specialized AI agents capable of taking a plain-text intent, navigating millions of lines of enterprise code, running tests, and submitting production-ready pull requests without human intervention.
Technology executives, engineering leaders, and platform architects face a complex set of challenges. The core inquiry driving modern platform engineering is precisely this: How do top-tier engineering teams deploy swarms of autonomous agents to handle thousands of pull requests and system refactors, and what infrastructure is required to orchestrate these agents securely within a GitHub Enterprise environment without causing pipeline pile-ups?
This comprehensive report provides an exhaustive analysis of how leading organizations manage AI agent swarms. It explores the architectural divergence between traditional copilots and agentic swarms, dissects the orchestration frameworks required to prevent codebase collisions, and details the infrastructure necessary to secure agent operations within an enterprise ecosystem. For leaders thinking beyond narrow tools and toward platform strategy, resources like enterprise AI readiness checklists for CTOs can help frame the broader change management effort.
The Paradigm Shift: Copilots Versus Agentic Swarms
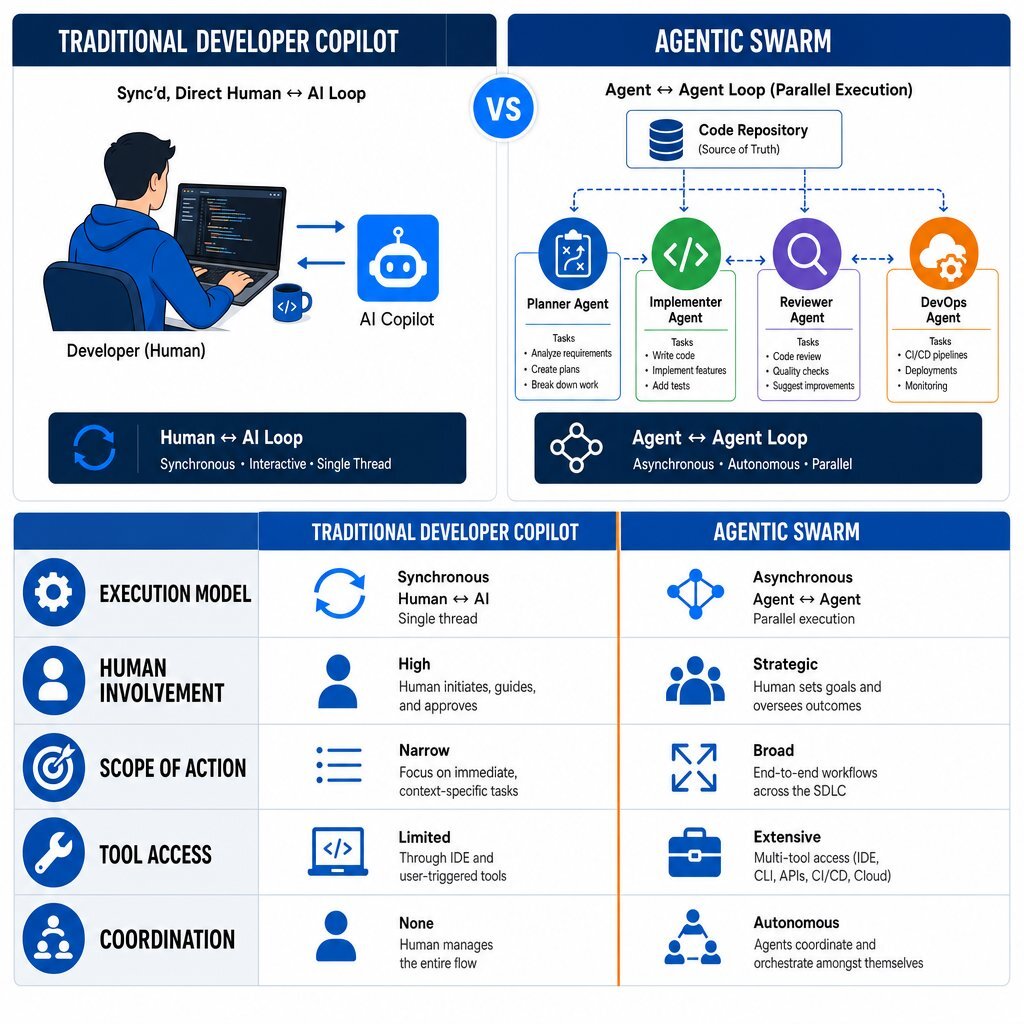
To understand the infrastructure required for agentic software development, it is necessary to delineate the boundary between an AI copilot and an AI agent swarm. While the terminology is often conflated in software marketing, the operational mechanics, autonomy levels, and organizational impacts of these two paradigms are fundamentally distinct.
The Synchronous Nature of Developer Copilots
A traditional developer copilot operates as a synchronous, linear assistant embedded directly within an Integrated Development Environment (IDE). The operational loop is highly dependent on human action: the developer types, the copilot suggests an autocomplete snippet or answers a contextual chat query, and the developer manually accepts, rejects, or refines the output.
In this model, the human developer acts as the primary orchestrator and the sole execution engine. The AI model is constrained by the specific file the developer has open and the immediate context window provided by the IDE. While this significantly accelerates routine tasks, reduces boilerplate coding, and improves flow state, it inherently limits productivity to the typing speed and cognitive load capacity of a single human engineer. The copilot possesses no autonomy to execute background tasks, trigger external test suites, or proactively navigate across disparate microservices to implement sweeping architectural changes.
The Asynchronous Power of Agentic Swarms
An AI agent swarm, conversely, operates asynchronously and autonomously at the repository level. Instead of assisting with individual keystrokes, an agentic swarm is assigned a complete, end-to-end task—such as migrating a legacy API endpoint, applying a security patch across multiple microservices, or generating comprehensive documentation for an undocumented module.
A swarm consists of multiple specialized agents, each possessing distinct roles, predefined tools, and customized system prompts. For example, a "Planner Agent" decomposes a high-level goal into a Directed Acyclic Graph (DAG) of sub-tasks. "Implementer Agents" execute the code changes in isolated environments. A "Reviewer Agent" validates the output against architectural guidelines, and a "DevOps Agent" triggers the build pipeline.
This architecture allows for massive, unprecedented parallelization. An engineer can dispatch a request via a Slack message, an issue tracker, or a CLI command, and immediately shift focus to complex, high-value architectural work. Concurrently, the swarm provisions its own infrastructure, researches the codebase, writes the implementation, validates the logic, and opens a pull request. For teams moving from simple chat widgets to embedded copilots and agents inside their products, patterns from the SaaS AI copilot revolution are directly applicable.
Comparative Analysis of Development Paradigms
The following table illustrates the core differences between these development paradigms, highlighting the transition from human-driven execution to human-supervised orchestration.
| Architectural Dimension | Traditional Developer Copilot | Agentic Swarm (Multi-Agent System) |
|---|---|---|
| Execution Model | Synchronous and blocking (Human ↔ Agent loop). | Asynchronous and parallel (Agent ↔ Agent loop). |
| Human Involvement | High. Developer authors code and reviews suggestions line-by-line. | Low during execution. Human acts as an orchestrator and final reviewer at the PR stage. |
| Scope of Action | Localized to the active IDE window and specific functions. | Repository-wide. Capable of multi-file refactoring and cross-service modifications. |
| Tool Access | Limited to IDE context and basic code search. | Expansive. Uses Model Context Protocol (MCP) to access APIs, databases, shell commands, and CI runners. |
| Coordination | Single agent interacting with a single human. | Multiple specialized agents coordinating via decentralized handoffs or central orchestrators. |
Table 1: Operational distinctions between Developer Copilots and AI Agent Swarms.
The transition to agentic swarms represents a fundamental redefinition of the software engineering discipline. The core skill of the modern developer is shifting from raw code generation to the architectural design, specification drafting, and supervision of automated, interacting systems. Forward-looking teams are already pairing this shift with modern developer productivity metrics that emphasize outcomes over keystrokes.
The Economics and ROI of Swarm Engineering
The economic implications of deploying AI agent swarms are profound, driving rapid adoption across enterprise environments. Evaluating an autonomous system utilizing traditional developer metrics—such as lines of code written or commits per day—is fundamentally flawed. AI can generate massive volumes of syntax instantly; measuring success by volume alone merely incentivizes the accumulation of technical debt.
Instead, leading organizations measure the success of agentic swarms through the lens of complexity-adjusted velocity, cost-per-task reduction, and time-to-value.
Dramatic Reductions in Cost-Per-Task
In 2026, enterprise telemetry data reveals that the deployment of production AI agents recovers a median of 6.4 hours per week per knowledge worker, with senior engineering practitioners saving upwards of 10 to 12 hours weekly. The most striking impact is observed in the cost-per-task economics.
According to recent enterprise studies and telemetry from leading AI providers, the financial efficiency of agentic workflows heavily outperforms human execution for routine maintenance and review tasks. While a routine pull request review performed by a senior human engineer costs an organization approximately $48 in labor time, a specialized code-review agent completes the identical task for just $0.72—a 66x cost reduction. Finance leaders looking to justify this kind of shift can adapt the methodology in practical AI ROI frameworks for CFOs.
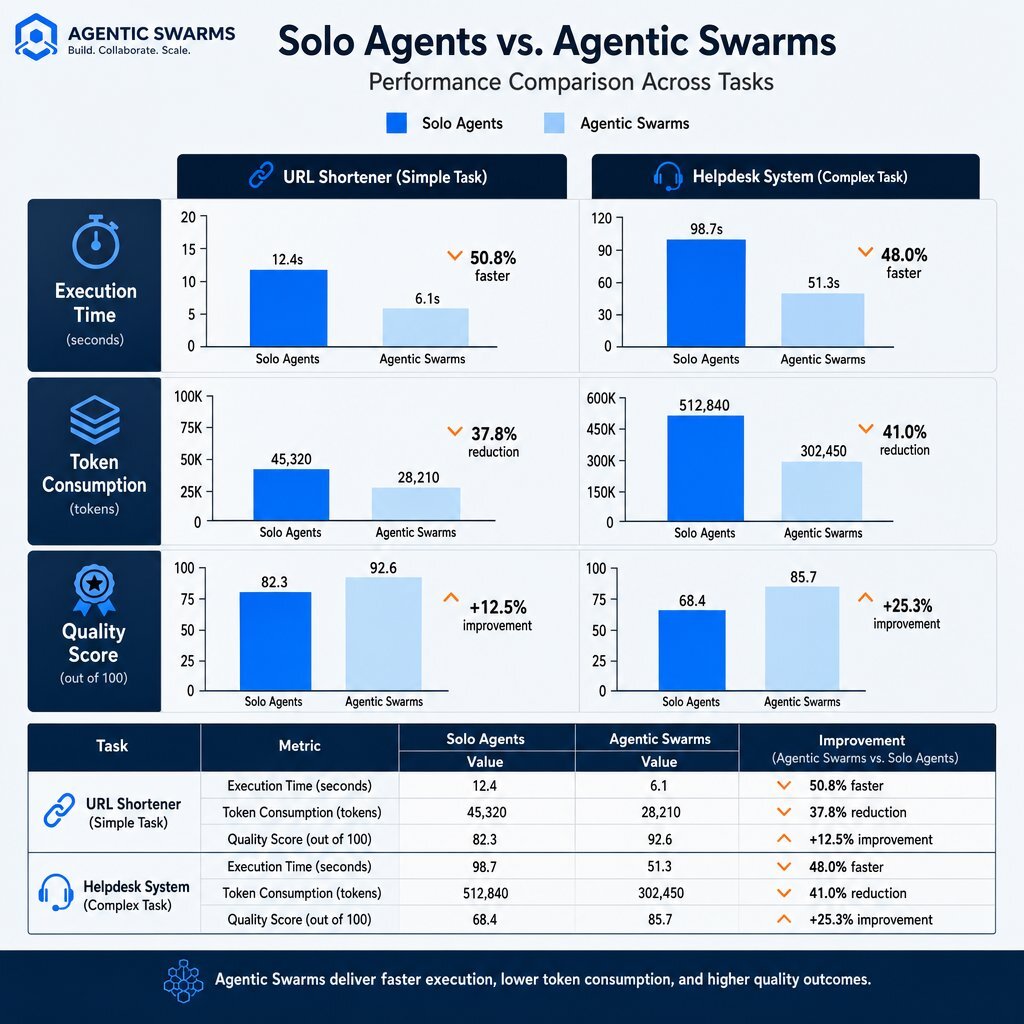
Performance Benchmarks: Solo Agents vs. Swarms
While single autonomous agents provide value, swarms deliver superior quality by dividing labor among specialized components. The following data visualization illustrates the performance benchmarks of single agents compared to multi-agent swarms operating on the Azure Durable Task Scheduler framework.
| Task Complexity | Execution Model | Execution Time | Token Consumption | Quality Score (out of 5) |
|---|---|---|---|---|
| Simple (URL Shortener) | Solo Agent | 2.5 minutes | 7.7K tokens | 1.90 |
| Simple (URL Shortener) | Swarm (Parallel) | 5.5 minutes | 30.0K tokens | 2.50 (+32% improvement) |
| Complex (Helpdesk System) | Solo Agent | 1.75 minutes | 11.0K tokens | 2.30 |
| Complex (Helpdesk System) | Swarm (Parallel) | ~8.0 minutes | 39.0K tokens | 2.95 (+28% improvement) |
Table 2: Performance benchmarks demonstrating the quality vs. cost/time tradeoffs of Solo Agents versus Agent Swarms.
The data indicates that while swarms consume up to 3.9x more tokens and require longer execution times due to orchestration overhead, the output quality is significantly higher. Specialized swarm agents successfully implement security best practices, parameterize queries, and generate comprehensive test suites—critical engineering steps that single, generalized agents consistently skip in their rush to completion.
Anatomy of an Enterprise Swarm: Dissecting Stripe's "Minions"
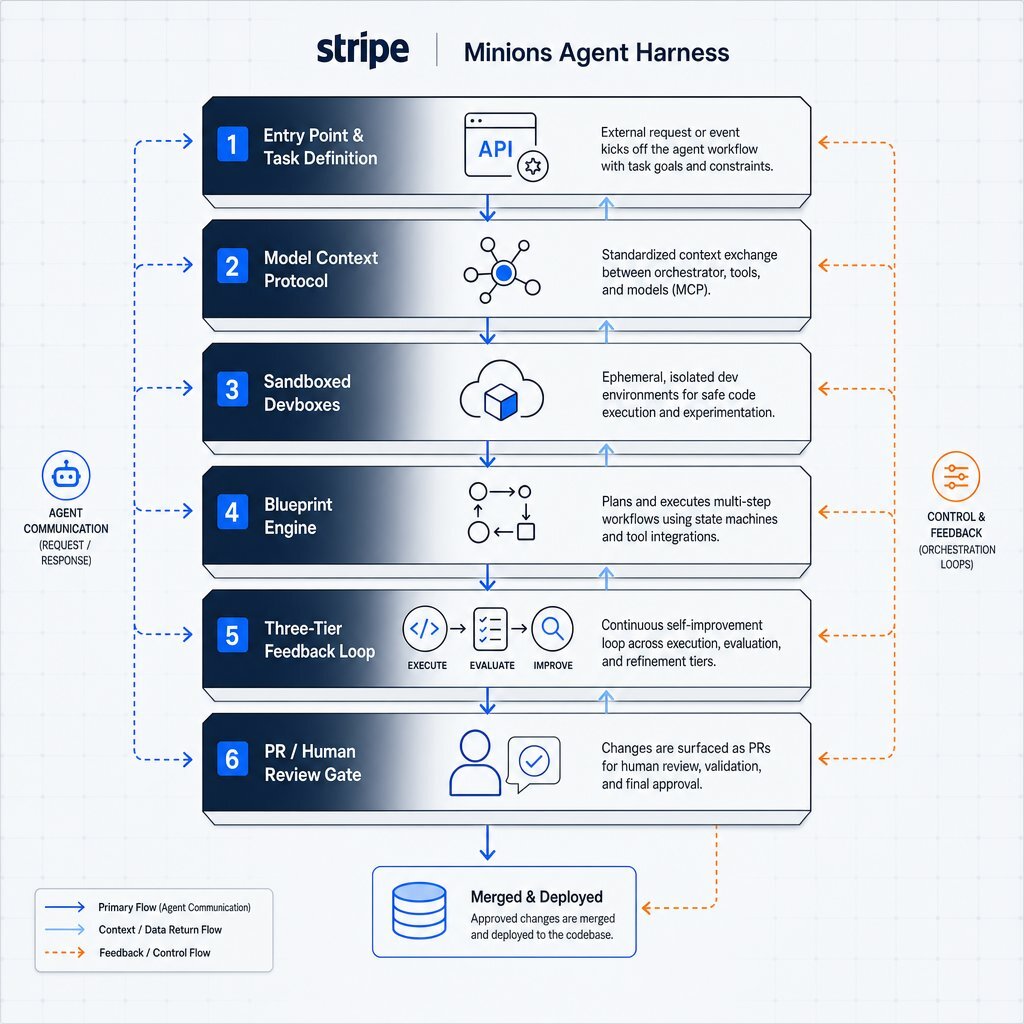
The theoretical benefits of multi-agent systems are vast, but realizing these benefits in a production environment requires a highly disciplined infrastructure. The benchmark for enterprise-scale autonomous coding is currently set by Stripe, an organization processing over $1 trillion in annual payment volume. Stripe's internal agent swarm, known as "Minions," successfully generates and merges over 1,300 pull requests every week, completely unattended during the execution phase.
The success of the Minions ecosystem is not derived from a proprietary, hyper-advanced Large Language Model. The core agent logic evolved from an internal fork of "Goose," an open-source coding agent originally developed by Block. The true competitive differentiator, and the reason the system scales reliably across millions of lines of complex Ruby code, is the sophisticated, six-layer agent harness built around the model.
The Six-Layer Agent Harness Architecture
An AI model requires an operating system to function autonomously in the real world. This operating system is the "agent harness." Stripe engineered a heavily constrained environment that prevents the probabilistic nature of LLMs from introducing chaos into the codebase.
- The Entry Point and Task Definition Layer: Agents receive structured intent via standardized API entry points—such as Slack commands, CLI inputs, or CI triggers—rather than open-ended chat prompts. This ensures the agent begins with a clearly scoped directive.
- Context Hydration via the Model Context Protocol (MCP): Stripe utilizes MCP to connect agents to an internal "Toolshed" containing over 500 enterprise-specific tools. Rather than overwhelming the LLM's context window by dumping the entire codebase into the prompt, a deterministic orchestrator pre-fetches only the exact documentation, API schemas, and historical context required for the specific task.
- Sandboxed Execution Environments (Devboxes): Unattended agents cannot run safely on a developer's local machine, nor should they execute directly in production. Every Minion is assigned a pre-warmed, ephemeral AWS EC2 "devbox" that spins up in ten seconds. These devboxes are completely isolated, ensuring that a hallucinating agent cannot execute destructive commands against production databases, leak credentials, or corrupt shared testing environments. Organizations that prefer on-prem control can adopt similar isolation using hyper-converged platforms like Harvester, as outlined in edge versus on‑prem AI deployment guides.
- The Blueprint Engine (Deterministic vs. Agentic Nodes): This is the most critical architectural component of the Minions system. Rather than giving the AI full autonomy to decide how to complete a task, the workflow is governed by a state machine called a "blueprint." Blueprints interleave creative, agentic nodes (where the LLM reasons, plans, and writes code) with strict, deterministic nodes (where hardcoded scripts run linters, type checkers, and test suites).
- The Three-Tier Feedback Loop: The system features a "shift-left" strategy for error correction. If an agent writes syntactically incorrect code, the deterministic linter catches the error locally within seconds, feeding the error log back to the agent for immediate correction. This prevents the agent from pushing broken code to a remote CI server, saving immense amounts of time and compute resources.
- PR Creation and the Human Review Gate: The automated workflow strictly concludes with the creation of a pull request. The agent holds submission authority, but it explicitly lacks merge authority. A human engineer must always review and approve the final code before it enters the main branch, maintaining absolute control over the production environment.
The Imperative of Deterministic Guardrails
The blueprint methodology illustrates a profound principle of enterprise AI: LLMs are highly effective at generating code, but they are uniquely unqualified to evaluate it. By enforcing a pipeline where "agents write the code, but linters write the law," organizations ensure that the creative capabilities of generative AI are strictly bounded by deterministic reliability.
The AI cannot bypass the linter; if the code fails the deterministic check, the agent is forced to rewrite it. Stripe caps this cycle at two full CI retry loops. If the agent cannot satisfy the deterministic gates after two attempts, the workflow suspends and hands the branch over to a human engineer. This "self-healing cap" prevents runaway compute consumption and infinite hallucination loops. Teams that want a broader governance blueprint for AI code can draw on frameworks such as a seven-stage AI code approval process.
Orchestrating the Swarm: Preventing Codebase Collisions
Scaling from a single autonomous agent to a coordinated swarm introduces a massive distributed systems problem. When multiple agents are unleashed on the same repository simultaneously, the probability of collisions increases exponentially. If Agent A is refactoring a database schema while Agent B is writing API endpoints that depend on the original schema, the resulting output will be fundamentally broken, despite both agents executing their individual instructions flawlessly.
The Merge Conflict Bottleneck
Early experiments in multi-agent orchestration frequently resulted in spectacular failures. In one documented architectural test, an engineering team deployed a swarm of five specialized agents operating on five parallel Git branches. Because the agents lacked real-time awareness of each other's actions, the integration step resulted in massive merge conflicts. When an LLM was tasked with resolving the conflict autonomously, it silently hallucinated and deleted critical implementation logic, rendering the entire application useless.
To successfully coordinate swarms, engineering teams must implement strict state management, data contracts, and isolated workspaces. The orchestration layer, not the AI models themselves, is the true differentiator in enterprise deployments.
Worktree Isolation and Parallelization
To prevent agents from overwriting shared files or becoming confused by each other's incomplete edits, advanced orchestration tools abandon traditional localized branching in favor of Git worktrees. Frameworks like Claude Squad and Gitgrip generate entirely isolated working directories for every concurrent agent.
Because each agent operates within a dedicated worktree, it possesses isolated file handles. Agent A cannot read Agent B's half-finished refactor, preventing context bleed and "politeness loops." The orchestration layer acts as the synchronization engine, ensuring that changes are integrated sequentially and deterministically. A dedicated integration script is often deployed to resolve minor syntactic conflicts during the merge phase, while major architectural discrepancies are flagged immediately for human intervention.
The "Boss Repository" and Spec-Driven Orchestration
For complex cross-repository operations, enterprise architectures utilize the "Boss Repository" pattern (as implemented in frameworks like AllBeads). This acts as a centralized control plane that federates issue tracking and synchronizes state across multiple microservices, providing agents with a unified dependency graph.
Furthermore, leading multi-agent platforms utilize a "Contract-First" or specification-driven approach to maintain alignment. Before any implementer agent is allowed to write a single line of code, a designated "Planner Agent" generates explicit API contracts, function signatures, and data models. These contracts serve as the unchangeable source of truth. All subsequent agents must develop against these defined contracts, neutralizing the risk of incompatible implementations.
In this model, human developers transition into the role of "Architects." They review and approve the initial specification drafted by the Planner Agent. Once approved, the swarm executes the implementation in parallel, drastically reducing development latency while maintaining architectural coherence.
Comparing Orchestration Frameworks
The market has rapidly consolidated around several premier orchestration frameworks designed to handle these complex coordination tasks. Understanding the architectural differences between these frameworks is critical for selecting the right tool for an enterprise environment.
| Framework | Architecture Pattern | State Management | Production Readiness | Best Use Case |
|---|---|---|---|---|
| Swarms (Python/Rust) | Highly modular (Hierarchical, Graph, Concurrent). | Extensive telemetry and persistent state. | Enterprise-grade (ISO 27001 compliant infrastructure). | High-frequency trading, massive scale enterprise automation. |
| LangGraph | Cyclical graph-based workflows. | Built-in stateful workflows via LangSmith. | High. | Complex workflows requiring deep observability and custom routing. |
| CrewAI | Role-based multi-agent teams. | Comprehensive built-in file caching. | High. | Fast deployment of specialized teams (e.g., Researcher + Writer + Reviewer). |
| Microsoft Agent Framework | Unified SDK (formerly AutoGen + Semantic Kernel). | Azure-native state integration. | Enterprise-grade. | Workflows requiring deep integration with Microsoft 365 or Azure ecosystems. |
Table 3: Comparison of leading Multi-Agent Orchestration Frameworks.
Securing the Swarm: Guardrails in GitHub Enterprise
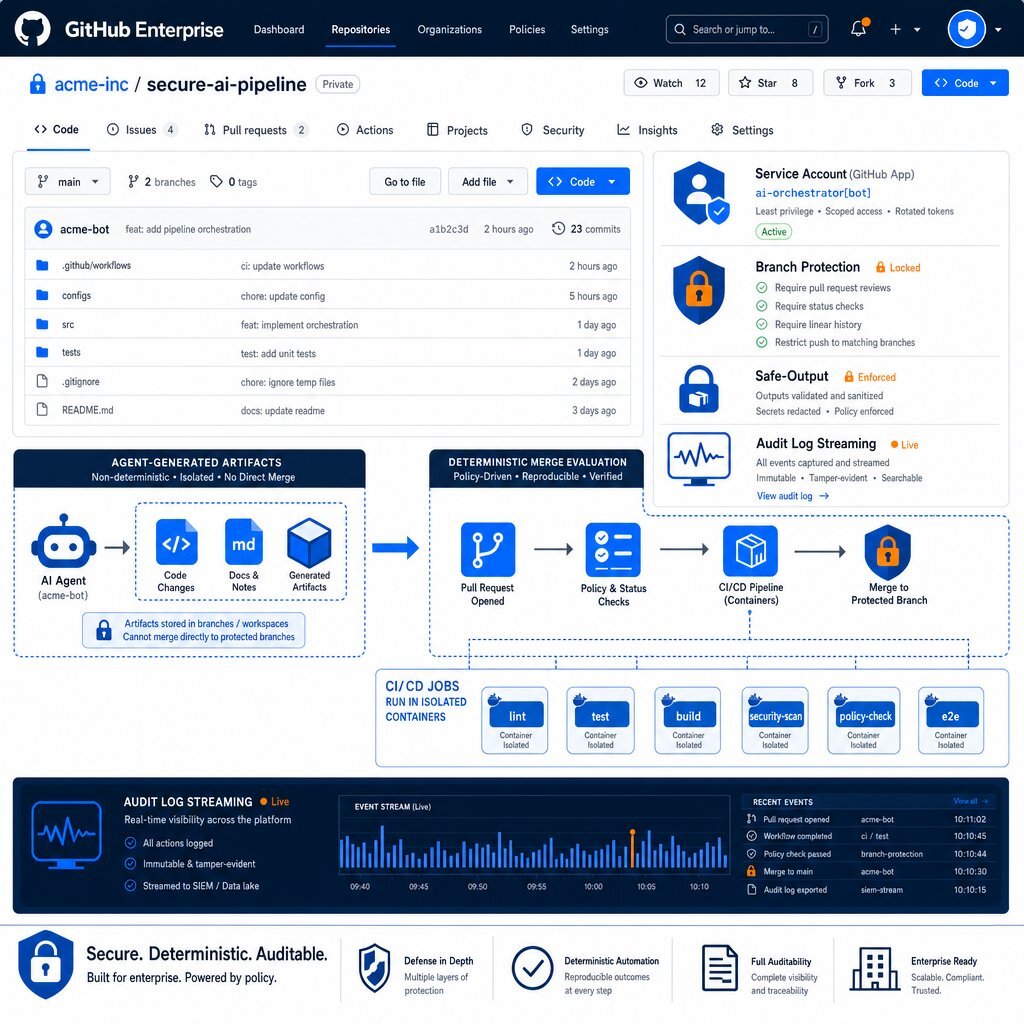
Granting autonomous software entities commit access to enterprise repositories fundamentally alters the corporate threat model. A compromised, hallucinating, or prompt-injected agent with unrestricted access can inadvertently leak proprietary algorithms, introduce insecure dependencies, or inject malicious code directly into the software supply chain.
For organizations utilizing GitHub Enterprise, securing an AI agent swarm requires moving beyond traditional developer security training and embedding zero-trust guardrails directly into the platform architecture. The objective is to enforce security via immutable infrastructure, rather than relying on the LLM to self-regulate its behavior.
Identity, Access, and Enterprise Managed Users (EMU)
Security begins with strict identity management. Agents must never operate using the personal access tokens of human developers. Doing so destroys forensic traceability, violates the principle of non-repudiation, and creates massive credential exposure risks.
Within GitHub Enterprise, organizations must deploy Enterprise Managed Users (EMU) to maintain a clean separation between personal and corporate identities. Every automated agent or swarm orchestrator must be assigned a dedicated Service Account with granular, role-based access control (RBAC). This ensures that an agent’s blast radius is cryptographically restricted to the specific repositories, branches, and environments required for its assigned task.
Leveraging GitHub Agentic Workflows and Safe-Outputs
GitHub has introduced native capabilities, such as Agentic Workflows, designed specifically to secure autonomous operations within continuous integration pipelines. When an agent operates within a GitHub Action, it runs within the same trust domain as the CI/CD pipeline, creating significant risk if the agent attempts to modify workflow files, rotate API keys, or access underlying deployment secrets.
To mitigate this, GitHub Agentic Workflows utilize a compiled security model based on strict compartmentalization:
- Read-Only Defaults: Agents are granted
contents: readpermissions by default. They can explore the repository, analyze issues, and review pull requests, but they lack the authorization to alter the codebase directly. - Safe-Outputs Configuration: Instead of executing Git commit commands directly, the agent generates a structured artifact detailing its intended changes (e.g., "create a PR with this specific diff"). A separate, deterministic workflow job—which the agent cannot modify—evaluates this artifact against a strict
safe-outputsconfiguration. If the artifact requests the creation of a pull request, and the policy permits it, the deterministic job applies the change. This creates a hard boundary between AI reasoning and repository modification. - Threat Detection Scanning: Before any agent-generated artifact is executed, a dedicated security job scans the proposed payload for prompt injections, leaked credentials, and known malware signatures, blocking the execution if anomalies are detected.
Enforcing Repository Rulesets and Auditability
Agent-authored code must be treated with the highest degree of skepticism. Organizations must configure GitHub branch protection rules and repository rulesets to ensure that no agent can bypass mandatory human review. The CODEOWNERS file must be strictly enforced, guaranteeing that modifications to sensitive infrastructure configurations, deployment scripts, or agent instruction files (.github/copilot-instructions.md) require explicit approval from designated security personnel.
Furthermore, comprehensive observability is non-negotiable. GitHub Enterprise administrators must enable audit log streaming to an external Security Information and Event Management (SIEM) platform (e.g., Splunk or Datadog). By tracking the agent_session_id and actor_is_agent fields, security teams can correlate anomalous behaviors across long-running swarm sessions and trigger automated alerts if an agent attempts to access restricted network domains or bypass established rulesets.
Beating the Validation Bottleneck: CI/CD and Pipeline Pile-ups
The widespread adoption of agentic swarms exposes a severe bottleneck in modern software delivery: CI/CD congestion. Traditional pipelines were engineered to accommodate the commit cadence of human development teams. When an AI swarm is capable of generating hundreds of pull requests in a matter of hours, the validation infrastructure collapses under the load. Staging environments crash due to concurrent deployments, test queues stretch into days, and human reviewers experience profound alert fatigue.
The bottleneck has fundamentally shifted. Generating code is no longer the rate-limiting step in software development; proving that the generated code works safely in a distributed, production-like system is the new critical path.
Elastic Ephemeral Environments
To prevent pipeline pile-ups, organizations must decouple integration testing from shared staging environments. The solution is the implementation of elastic, ephemeral cloud sandboxes.
When a swarm agent submits a pull request, the CI/CD orchestrator must automatically spin up a lightweight, isolated replica of the application architecture. This requires a robust containerization and orchestration strategy. Utilizing technologies such as Kubernetes and Docker—frequently managed via platforms like Rancher on Harvester HCI, and integrated deeply with Azure DevOps On-Prem—organizations can provision complete microservice ecosystems dynamically. Firms like Baytech Consulting specialize in engineering these custom application management environments, ensuring that the underlying infrastructure is scalable, secure, and resilient enough to support high-velocity automated testing, much like the environments described in their .NET, Docker & Kubernetes services.
The agent's code is tested comprehensively within this isolated namespace. Once the automated test suite concludes, the environment is destroyed. This methodology prevents concurrent agent PRs from corrupting shared databases, eliminates environmental drift, and allows for limitless parallel validation of swarm outputs.
Defensive CI/CD Pipeline Configuration
AI agents introduce novel attack vectors directly into the CI/CD pipeline. The "PromptPwnd" vulnerability demonstrated how malicious actors could inject prompt-overriding instructions into issue tickets, causing an AI agent running in a GitHub Action to exfiltrate repository secrets or execute arbitrary code.
To harden the CI/CD pipeline against swarm-induced vulnerabilities, engineering teams must enforce rigorous Infrastructure-as-Code (IaC) security practices:
- Pin Actions to Commits: All third-party GitHub Actions must be pinned to full cryptographic commit SHAs rather than mutable tags (e.g.,
@v2or@latest). This prevents supply chain poisoning where a compromised tag executes malicious code during an agent's run. - OIDC Integration: Long-lived cloud credentials must be eliminated in favor of short-lived OpenID Connect (OIDC) workload identities, minimizing the blast radius if an agent's execution environment is compromised.
- Input Sanitization: User-controlled input (such as pull request titles, issue bodies, or commit messages) must never be interpolated directly into shell execution blocks, as this creates a direct vector for prompt injection.
Orchestrating Concurrency with GitHub Merge Queues
Even with ephemeral testing, merging hundreds of PRs into the main branch sequentially creates severe race conditions. Agent A's passing PR might break Agent B's passing PR when both are merged into the main line simultaneously.
GitHub Enterprise addresses this critical concurrency issue via the Merge Queue feature. When a human reviewer approves an agent's PR, it is not merged immediately. Instead, it enters a queue where GitHub Actions automatically builds and tests the PR against the latest version of the target branch and any previously queued PRs. If the combined integration fails, the PR is ejected from the queue for rework. This ensures that the main branch remains perpetually stable, orchestrating high-volume concurrency without requiring human engineers to manually rebase and retest every automated change.
Metrics, Quality, and the Truth About AI Code
Adopting a transparent approach requires confronting the uncomfortable realities of AI-generated software. While the speed and volume of code generation are unprecedented, the quality metrics tell a more nuanced story.
The Surge in Defect Density and Code Churn
Extensive analysis of millions of pull requests reveals a troubling pattern: AI-generated code introduces approximately 1.7x more logic and correctness defects per pull request than human-authored code. Furthermore, because AI models tend to copy and paste established patterns rather than refactor thoughtfully, code duplication has surged dramatically, violating core principles of software maintainability.
To monitor the health of an agent-assisted codebase, engineering leaders must move beyond DORA metrics—which can be artificially inflated by high-speed, low-quality automated commits—and track the "AI vs. Human Turnover Ratio." This metric measures the rate at which AI-generated code is deleted, revised, or rewritten within 30 days, compared to human-written code.
| Metric Dimension | Healthy AI Integration | Caution Required | Critical Failure |
|---|---|---|---|
| 30-Day Code Turnover (Human-Only) | < 8% | 8 - 12% | > 18% |
| 30-Day Code Turnover (AI-Assisted) | < 12% | 12 - 18% | > 25% |
| AI vs. Human Turnover Ratio | < 1.3x | 1.3x - 1.5x | > 2.0x |
Table 4: 2026 Developer Productivity Benchmarks for Code Turnover and Churn.
An AI turnover ratio exceeding 1.5x indicates that the agent swarm is generating code faster than the human review process can adequately validate it, resulting in the rapid deployment of flawed logic that requires immediate remediation. Maintaining a healthy ratio demands strict adherence to the deterministic guardrails, blueprint methodologies, and layered CI/CD testing frameworks outlined previously. It also means pairing swarm tooling with a clear strategy to prevent AI-driven technical debt.
If an organization's pull request count doubles, but their bug count also doubles, velocity has not increased; the organization has merely automated the generation of technical debt. True velocity is achieved only when rigorous orchestration ensures that AI output is structurally sound before it reaches the main branch.
Frequently Asked Question
Q: How does the memory management of an AI agent swarm differ from a standard developer copilot, and where is that context stored securely?
Unlike a traditional copilot that relies primarily on the active files currently open in an IDE, an agentic swarm requires persistent, shared memory to coordinate complex architectural changes across multiple asynchronous sessions. A copilot's memory dies when the chat window is closed; a swarm's memory must survive across deployments, agent handoffs, and system reboots.
In advanced enterprise deployments, this shared memory architecture is achieved through a combination of the Model Context Protocol (MCP) and highly scalable databases. The industry is currently witnessing a trend where enterprises are abandoning expensive, standalone vector databases in favor of unified storage systems. Many organizations are successfully utilizing robust, relational databases like PostgreSQL combined with the pgvector extension to handle agent memory, embeddings, and semantic search. This allows agents to store their vector embeddings alongside primary application data, ensuring transactional consistency and significantly reducing architectural complexity.
Furthermore, swarm frameworks maintain specialized project-wide context files—such as an AGENTS.md or a MEMORY.md ledger located in the repository root. After every major session, the orchestrator agent documents architectural decisions, learned conventions, and completed sub-tasks into these files. Subsequent agents read these files upon initialization, ensuring the swarm maintains absolute operational continuity and adheres to evolving project standards without relying on fragmented or ephemeral chat histories.
Conclusion and Strategic Next Steps
The evolution from interactive AI copilots to fully autonomous agent swarms marks a pivotal turning point in enterprise software development. By leveraging orchestration frameworks that interleave agentic reasoning with strict deterministic gates, isolated cloud environments, and rigorous GitHub Enterprise security protocols, engineering teams can unlock unprecedented levels of throughput and code management efficiency.
However, this transition dictates that organizations stop treating AI as a mere coding accessory and start managing it as a highly volatile distributed computing system. Success requires deep, foundational investments in CI/CD elasticity, Identity and Access Management, and proactive threat mitigation. It also demands clarity on where to rent commodity tools and where to build AI that protects your competitive edge.
Strategic Next Steps for Engineering Leaders:
- Audit CI/CD Infrastructure: Ensure all automated pipelines enforce OIDC, pin actions to specific cryptographic SHAs, and utilize ephemeral sandboxes to prevent agent-driven supply chain attacks or staging environment collapses.
- Implement Agent Governance: Transition all autonomous agent deployments to dedicated Enterprise Managed User (EMU) service accounts with strictly defined, read-only default tokens and
safe-outputlimits within GitHub. - Establish Baseline Metrics: Move beyond tracking lines of code. Begin tracking AI-touched PR cycle times and the AI-to-Human turnover ratio to monitor the true impact of agentic code generation on long-term technical debt.
Organizations seeking to modernize their application delivery infrastructure and seamlessly integrate these autonomous architectures can engage with Baytech Consulting. Specializing in custom software development and application management, Baytech delivers a Tailored Tech Advantage. By leveraging deep expertise in modern tech stacks—including Azure DevOps On-Prem, Postgres, Kubernetes, and Docker—Baytech ensures that the underlying infrastructure is robust enough to support advanced AI orchestration, executing complex transformations with Rapid Agile Deployment, enterprise-grade quality, and on-time delivery. If your current partner or internal team is struggling with this leap, a dedicated project rescue engagement can stabilize today’s pipelines while you design tomorrow’s swarm architecture.
Supporting Resources:
https://stripe.dev/blog/minions-stripes-one-shot-end-to-end-coding-agents) (https://www.datadoghq.com/blog/github-actions-iac-security/) (https://wellarchitected.github.com/library/governance/recommendations/governing-agents/
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.