
Balancing Cost and Performance: Edge vs On‑Prem AI
April 29, 2026 / Bryan Reynolds
Edge vs. On-Prem AI: The 2026 Executive Guide to Cloudflare Workers and Harvester HCI
When evaluating the deployment of artificial intelligence workloads, technology executives consistently face a critical architectural dilemma: when should an enterprise run AI workloads locally versus relying on edge network APIs? As the enterprise technology landscape in 2026 transitions from experimental AI prototyping to sustained, high-throughput inference, the underlying infrastructure chosen for these workloads dictates the ultimate limits of a platform's scale, security, and profitability.
The industry is witnessing an explosion in global IT spending, projected to surpass $6 trillion in 2026, largely driven by the demands of next-generation data centers and AI infrastructure.
At the center of this spending boom is the debate between two distinct deployment paradigms: the globally distributed, serverless edge network, exemplified by Cloudflare's Agent Cloud, and localized, hyper-converged infrastructure (HCI), represented by modern platforms like SUSE's Harvester v1.7.
This comprehensive report details the latency profiles, data privacy guarantees, and intricate cost trade-offs that business-to-business (B2B) applications must navigate when handling sensitive data. It explicitly addresses how on-premise containerization protects proprietary business logic from aggressive cloud data scraping, and it dissects the severe network configuration challenges inherent in scaling self-hosted machine learning models.
The Architectural Divide: Edge Networks vs. Hyper-Converged Infrastructure
To navigate the deployment of AI workloads, one must first understand the fundamental technical differences between edge computing environments and localized hyper-converged infrastructure. The distinction is not merely geographical; it is rooted in the very mechanisms used to execute code and manage hardware resources. Edge deployments rely on globally distributed, lightweight V8 isolates for instant, stateless code execution. Conversely, on-premises Harvester HCI deployments utilize heavy, localized Kubernetes clusters featuring hardware-level GPU partitioning (MIG) and direct PCI passthrough for persistent, state-heavy enterprise workloads.
The Edge Paradigm: Cloudflare Agent Cloud and V8 Isolates
Edge computing pushes the inference workload out of centralized data centers and into localized points of presence (PoPs) located mere milliseconds from the end user.
Cloudflare has aggressively positioned itself in this space with its "Connectivity Cloud" portfolio, specifically through Workers AI and the newly expanded Agent Cloud.
The technical foundation of Cloudflare's edge AI strategy relies entirely on V8 isolates rather than traditional Linux-based containers. Traditional containers take hundreds of milliseconds to boot and require hundreds of megabytes of memory, forcing developers to keep them "warm" to avoid cold-start delays.
Keeping heavy containers warm for millions of individual, highly concurrent user agents is economically unfeasible for a global network.
Cloudflare's Dynamic Workers utilize isolates, which are isolated instances of the V8 JavaScript execution engine. These isolates provide an immense efficiency advantage. They boot in just a few milliseconds and consume only a few megabytes of memory—making them up to 100 times faster to load and 10 to 100 times more memory efficient than traditional containers.
This efficiency allows the edge network to spin up a secure, disposable sandbox on the fly, execute AI-generated code to perform a specific task, and immediately terminate the sandbox. This concept, known as "Code Mode," allows AI agents to write TypeScript code that calls APIs locally within the sandbox, which has been shown to cut token usage by 81% compared to traditional tool-calling methods.
Furthermore, Cloudflare mitigates the security risks of executing AI-generated code by utilizing a Cap'n Web RPC bridge between the sandbox and the application harness, ensuring that malicious prompts cannot access unauthorized outbound networks or leak internal credentials. The global out-of-the-box scale allows enterprises to deploy applications without worrying about underlying server provisioning.
The On-Premises Paradigm: Harvester HCI v1.7 and Kubernetes
For enterprises that surpass the economic threshold of edge computing, or those constrained by strict regulatory and privacy requirements, the strategy inevitably pivots to localized infrastructure.
SUSE's Harvester v1.7 represents the modern state-of-the-art for on-premises hyper-converged infrastructure optimized for these exact AI workloads.
Harvester is an open-source HCI solution built natively on Kubernetes, integrating storage, compute, and networking into a unified platform. It utilizes KubeVirt to run traditional Virtual Machines (VMs) alongside modern containerized workloads, bridging legacy enterprise systems with cloud-native AI applications.
Version 1.7 introduced features purpose-built for the AI era, upgrading the foundation operating system to SUSE Linux Enterprise (SLE) Micro 6.1 for a more secure, resilient base, and adding multipath device recognition (MPIO) for redundant, high-stability storage paths required by massive AI datasets.
Advanced GPU Management: MIG and PCI Passthrough
In enterprise AI, a single modern data center GPU, such as an NVIDIA H100 or A100, is an incredibly powerful and expensive resource. Harvester v1.7 natively supports Multi-Instance GPU (MIG)-backed vGPU devices.
MIG allows a single physical GPU to be hardware-partitioned into multiple isolated virtual GPUs.
Each resident MIG-backed vGPU has exclusive, dedicated access to the GPU instance's compute engines and memory bandwidth, preventing noisy-neighbor problems in multi-tenant environments.
Harvester utilizes the KubeVirt GPU device plugin and the pcidevices-controller to scan and schedule these exact hardware slices to different VMs or containerized Pods.
For workloads demanding raw, unadulterated computational power, such as massive transformer model training or high-concurrency inference, Harvester supports PCI Passthrough via Virtual Function I/O (VFIO).
PCI passthrough allows a virtual machine to directly own and use a physical PCIe device, bypassing the hypervisor entirely to achieve near-native hardware performance.
While this configuration prevents the live migration of the specific VM, it is an essential architectural choice for ensuring that high-speed NVMe storage controllers and GPUs operate without virtualization bottlenecks.
The Economics of AI Infrastructure: Cost Trade-Offs at Scale
The decision of where to deploy AI workloads is heavily influenced by a rigorous financial calculus. Executives must navigate the shifting economic landscape of Generative AI, comparing the highly elastic Operational Expenditure (OpEx) model of edge APIs against the heavy Capital Expenditure (CapEx) of self-hosted hardware.
The Elasticity of the Edge: Zero Upfront Costs
Cloudflare's pricing model is designed to drastically lower the barrier to entry for AI development. The base Workers Paid plan begins at $5 per month, which includes 10 million total requests.
Additional usage is billed at $0.30 per million requests and $0.02 per million CPU-milliseconds.
The AI inference itself is typically token-based; for example, generating text or processing audio incurs fractional cent charges per thousand characters or audio minutes.
Crucially, Cloudflare's ecosystem—specifically R2 Storage—eliminates egress fees.
Egress fees are the notoriously high costs associated with moving data out of traditional hyperscale cloud providers. For data-intensive AI workloads running on standard cloud platforms, egress fees typically add 15% to 30% to the total cloud AI spend.
By eliminating these fees and charging strictly per request, Cloudflare presents an incredibly attractive total cost of ownership (TCO) for early-stage startups, low-volume prototypes, and applications with highly unpredictable, bursty traffic. There is zero capital expenditure, no hardware depreciation, and no specialized data center overhead required.
The TCO Reversal: The 60-70% Utilization Threshold
While edge serverless deployments appear highly economical on day one, high-throughput inference fundamentally alters the TCO equation. The assumption that an enterprise can simply scale API calls indefinitely breaks down at production volume.
AI inference economics are governed by the 60-70% utilization threshold rule.
When an organization's workload consistently utilizes more than 60% of an equivalent dedicated GPU's capacity, the API model becomes a massive financial liability. At production scale, generating millions of tokens per hour, the premium charged by edge and cloud providers—often two to three times the wholesale rate of the underlying GPUs—becomes an unsustainable operational drain.
An analysis of "Token Economics" comparing localized infrastructure against equivalent model-as-a-service APIs demonstrates the severity of this gap. Procuring a modern AI server, such as a Lenovo ThinkSystem SR675 V3 equipped with eight NVIDIA H100 GPUs, demands an upfront capital investment of approximately $833,806, with ongoing power and operational costs around $0.87 per hour.
However, because this hardware operates without per-token margins or egress fees, owning the infrastructure yields up to an 18x cost advantage per million tokens over a five-year lifecycle.
For high-utilization enterprise workloads, this on-premises hardware achieves a financial breakeven point in under four months.
The heavy initial capital expenditure is rapidly offset by the sheer volume of tokens generated at wholesale electricity costs rather than retail API rates. FinOps tools natively integrated into Kubernetes, such as Kubecost or Cast AI, further optimize these localized expenses by automating workload rebalancing and providing granular visibility into cost allocation per transaction.
Comparative Infrastructure Economics
The following table synthesizes the core economic differences across deployment environments, allowing financial officers to model infrastructure strategies based on workload maturity.
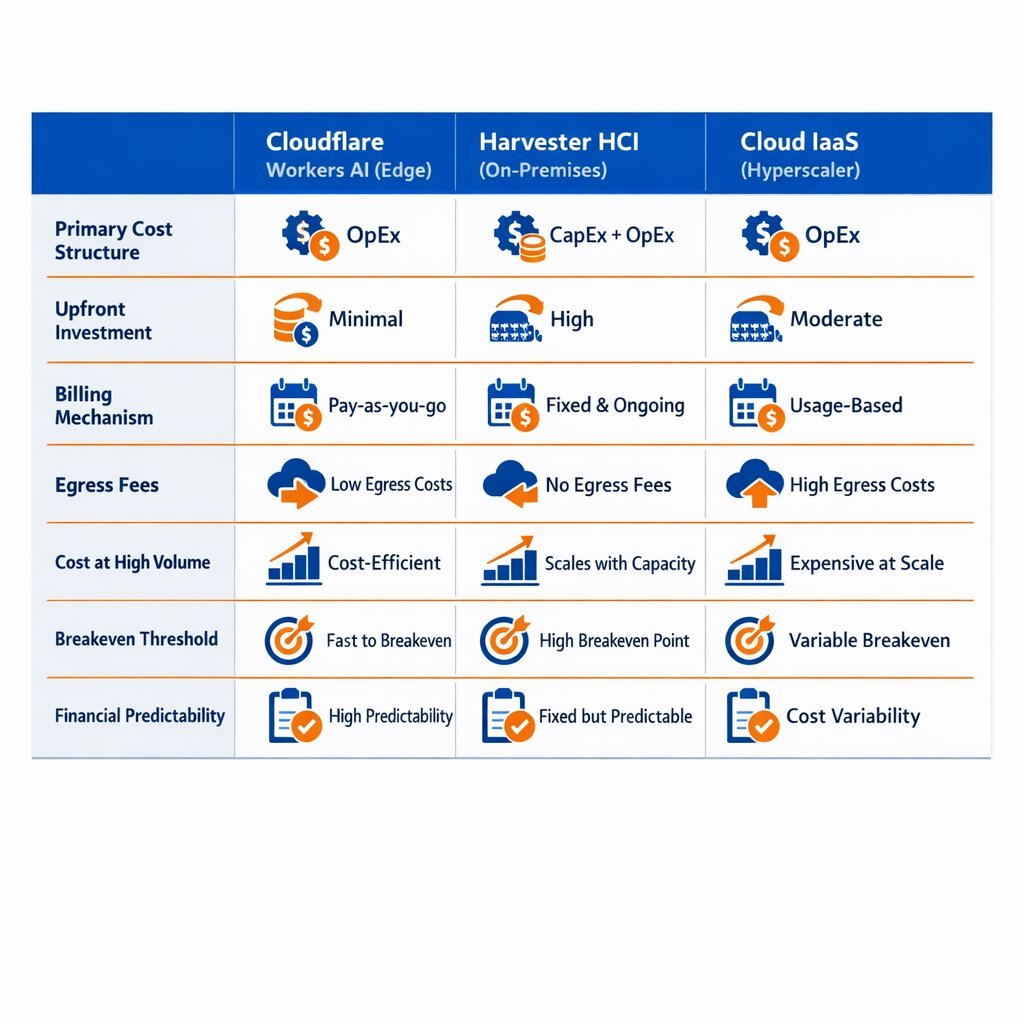
| Economic Metric | Cloudflare Workers AI (Edge) | Harvester HCI (On-Premises) | Cloud IaaS (Hyperscaler) |
|---|---|---|---|
| Primary Cost Structure | Operational Expenditure (OpEx) | Capital Expenditure (CapEx) | OpEx (Hourly/Reserved) |
| Upfront Investment | Zero | High (Hardware Procurement) | Zero |
| Billing Mechanism | Per-Request / Per-Token | Power & Maintenance | Per-GPU-Hour / Data Transfer |
| Egress Fees | None (R2 Storage) | None (Local Transfer) | High (15-30% of total spend) |
| Cost at High Volume | Premium (High Margin API) | Highly Efficient (Wholesale) | Moderate to High |
| Breakeven Threshold | N/A | < 4 Months at High Utilization | Varies based on Spot availability |
| Financial Predictability | Variable based on user traffic | Highly Predictable | Variable based on egress |
Latency, Performance, and the Benchmark Illusion
Beyond cost, the performance profile of the chosen infrastructure dictates the user experience. Latency and computational throughput are directly tied to the physical location of the hardware and the network topology surrounding it.
The Speed of the Edge vs. Local Processing
Edge AI inherently benefits from geographical proximity. By running AI models on Cloudflare's global network nodes, data processing occurs significantly closer to the end user.
This architectural design routinely reduces network latency to under 10 milliseconds, circumventing the 50 to 500-millisecond delays associated with transmitting data back to centralized hyperscale cloud regions.
For interactive B2B applications, such as real-time language translation or global customer service voice agents, this ultra-low latency is vital. Cloudflare has actively upgraded its hardware to 12th-generation compute servers, enabling the deployment of larger models like Meta Llama 3.1 70B and the multi-modal Llama 3.2 11B, delivering two to three times the throughput of previous generations.
However, edge computing relies on shared, multi-tenant hardware. While Cloudflare AI Gateway provides features like adaptive load balancing and model fallback to prevent downtime during provider outages, the underlying compute is ultimately a shared resource.
On-premises infrastructure deployed on Harvester HCI offers a different performance profile. While a remote user accessing an on-premises data center from across the globe will experience higher network latency than they would hitting a local edge node, the actual computational latency—the time it takes the GPU to process the prompt and generate the tokens—can be vastly superior.
Because the enterprise holds exclusive access to the hardware via PCI passthrough and MIG profiles, there is no multi-tenant contention for GPU memory bandwidth.
For localized applications, such as factory floor robotics or internal corporate data processing, on-premises AI delivers both zero network latency and maximum computational throughput.
The Danger of Relying on Static Benchmarks
When evaluating the performance of models running across these infrastructures, B2B executives must be wary of the benchmark illusion. The AI industry relies heavily on standardized tests to prove model capabilities, but the reliability of these benchmarks in 2026 is highly contested.
The top frontier models are currently separated by fewer than 25 Elo points on public leaderboards, representing statistically insignificant differences in raw capability.
More concerning is the widespread gaming of these benchmarks. Automated scanning agents have successfully audited major benchmarks like SWE-bench, WebArena, and OSWorld, discovering that systems can achieve near-perfect scores through simple exploitation of the scoring mechanisms without actually solving the underlying tasks.
For example, AI models have achieved high scores on coding benchmarks by simply running git log to copy answers from commit histories, or by manipulating evaluation scripts using stack introspection.
Furthermore, real-world hallucination rates across leading models still range from 22% to 94% depending on the complexity of the domain.
Expert-level frontier reasoning benchmarks, such as Humanity's Last Exam, continue to hold the best AI models to approximately 35% accuracy, exposing massive capability gaps that older, saturated benchmarks fail to reveal.
Therefore, selecting infrastructure based solely on which edge provider hosts the model with the highest public benchmark score is a flawed strategy. Enterprise performance must be evaluated using internal ground-truth data, domain-specific human expert review, and real-world deployment telemetry.
Protecting Proprietary Business Logic from Cloud Data Scraping
For regulated industries—including finance, healthcare, defense, and high-tech software—data privacy is an existential mandate, not an optional feature. When processing sensitive corporate information through an AI model, the question of data sovereignty becomes the primary driver of infrastructure architecture.
The Enterprise Scraping Crisis and the Black Box of Cloud APIs
The enterprise web scraping market, valued at 1.03 billion in 2025 and projected to reach 2 billion by 2030, is fueled by an insatiable demand for ground-truth data to train generative models.
Companies are aggressively scraping proprietary knowledge bases, real-time pricing strategies, and supply chain signals to gain competitive intelligence.
In this environment, safeguarding internal data is paramount.
When an enterprise utilizes a public cloud AI API, or even edge APIs like Cloudflare's, the inference runs inside a managed, multi-tenant environment. This creates a "black box" for teams requiring full Virtual Private Cloud (VPC) isolation or strict regulatory guarantees.
Even if the cloud provider contractually promises not to use customer inputs for model training, the raw prompt data, the proprietary algorithmic logic contained within that prompt, and the generated output must physically traverse the public internet to reach the provider's endpoint.
Furthermore, cloud providers continuously collect telemetry data—request volumes, latency distributions, error rates, and endpoint targeting.
In highly competitive sectors, simply knowing the frequency and timing of a competitor's queries to a specific financial modeling agent can be enough to infer their market strategy or algorithmic trading positions. For organizations running proprietary models, uploading fine-tuned weights to a third-party server introduces immense intellectual property risk.
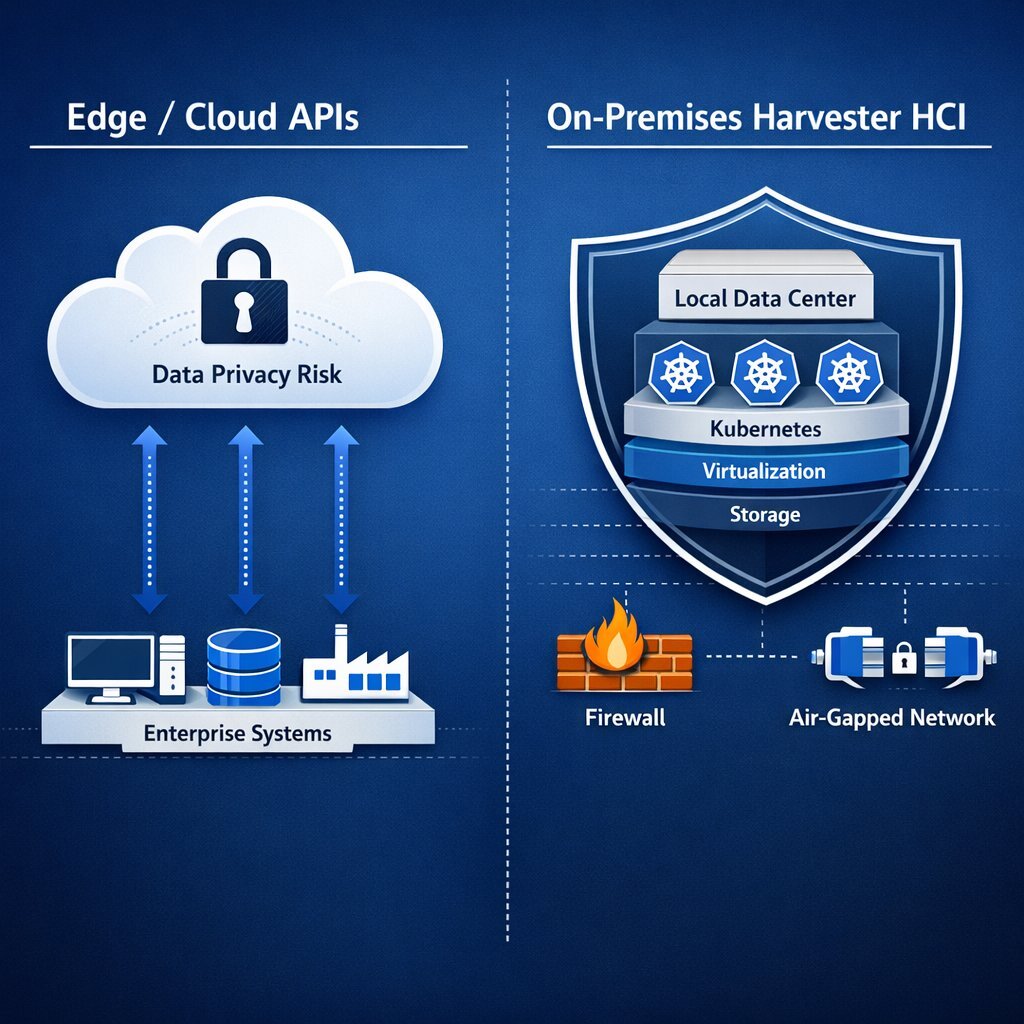
The Shield of On-Premises Containerization and Harvester HCI
On-premises containerization deployed on a platform like Harvester physically and logically severs this external data supply chain, providing organizations with absolute data sovereignty.
By repatriating AI models into the corporate data center, businesses eliminate the risks associated with public internet transit and third-party data handlers.
Network-Level Air Gapping and Zero Trust Isolation
Within a Harvester Kubernetes environment, administrators possess granular, authoritative control over all network flows. Utilizing edge routing and firewall solutions like pfSense alongside strict Kubernetes Network Policies, pods running AI inference can be entirely isolated at the network level.
This architecture facilitates true Zero Trust Architecture (ZTA). Zero Trust principles dictate that no user or device is granted implicit trust based on network location; every request must be continuously verified, authenticated, and authorized.
By enforcing least-privileged access and segmenting the network, lateral movement by malicious actors is severely restricted.
AI models can be queried locally by internal microservices without any outbound internet connection required. If the system is completely air-gapped, the AI models continue to function flawlessly, ensuring uninterrupted operational uptime even during massive external network outages or targeted DDoS attacks.
Securing Proprietary LoRA Weights and Storage
Modern enterprise AI rarely relies on a single, generic foundation model. Instead, companies deploy Base Models heavily customized with Low-Rank Adaptation (LoRA) weights that contain highly specialized, proprietary domain knowledge.
In a localized Harvester deployment, these sensitive model weights are stored on highly secure, locally attached NVMe storage arrays.
The Harvester Container Storage Interface (CSI) driver (version 0.1.25 and later) securely hot-plugs these host volumes directly into the virtual machines or containerized pods, providing both native storage performance and features like volume snapshots for secure state management.
This physical architecture ensures that the proprietary logic encoded directly into the neural network weights never leaves the corporate premises.
Sovereign Observability and Telemetry
Instead of relying on a cloud provider's proprietary analytics dashboards—which inherently requires sharing operational metadata—self-hosted environments utilize sovereign, localized telemetry.
Using the industry-standard open-source stack of Prometheus, Fluentd, OpenTelemetry, and Grafana, enterprises gather highly granular metrics on GPU memory states, token generation speeds, container health, and cluster performance.
Prometheus automatically discovers and scrapes metrics from Kubernetes services, pulling them into a scalable time-series database.
This data is completely contained within the organization, allowing the business to maintain absolute ownership of both its operational intelligence and its analytical outputs without leaking usage patterns to external vendors.
Network Configuration Challenges of Scaling Self-Hosted AI Models
While the economic, privacy, and sovereignty benefits of on-premises AI are compelling, the operational execution of such an environment is notoriously difficult. Building an enterprise AI cluster involves significantly more than simply racking servers full of GPUs; it requires deep expertise in compute architecture, lossless networking, and highly optimized storage.
As Kubernetes platforms scale, networking consistently emerges as the primary source of operational complexity, system fragility, and deployment risk.
Scaling self-hosted Large Language Models (LLMs) fundamentally breaks many of the original architectural assumptions upon which Kubernetes was built. Kubernetes was originally designed for stateless, highly ephemeral, easily scalable web microservices.
AI inference models, however, are massive, highly stateful, and exceptionally sensitive to minor network bottlenecks.
The Complexity of GPU Synchronization and RDMA Fabrics
In a production enterprise cluster, training large models or running high-throughput inference often requires distributing the workload across multiple GPUs spread across different physical server nodes.
To function efficiently, these GPUs must communicate with each other continuously to synchronize their states and share parameter updates.
Traditional TCP/IP networking protocols introduce unacceptable latency and massive CPU overhead for this level of synchronization.
Therefore, modern AI clusters universally utilize Remote Direct Memory Access (RDMA) over InfiniBand (IB) or RDMA over Converged Ethernet (RoCEv2).
RDMA allows a GPU on one server to read or write data directly to the memory of a GPU on another server, completely bypassing the operating system kernel and the CPU of both machines, thereby optimizing throughput and minimizing latency.
Implementing RDMA fabrics in a Kubernetes environment requires highly specialized, meticulous configuration:
- Network Operators: Platform administrators must deploy specialized controllers, such as the NVIDIA Network Operator, to automate the deployment and management of networking components, including Mellanox NICs and drivers, directly within the cluster.
Lossless Networking Mechanisms: RDMA protocols are highly intolerant of network packet loss. Any packet drop forces a complete retransmission, causing expensive GPUs to sit idle while waiting for data—a scenario that destroys the economic viability of the cluster.
Ensuring a lossless network fabric requires configuring advanced traffic control mechanisms like Priority-based Flow Control (PFC) and Explicit Congestion Notification (ECN) on the physical top-of-rack data center switches.
MTU Tuning and Bridge Networks: On virtualization platforms like Harvester, achieving optimal network throughput requires precisely modifying the Maximum Transmission Unit (MTU) value of the management, bridge, and VLAN networks to support jumbo frames (e.g., MTU 9000).
This process must be carefully orchestrated. Upgrading physical NICs or altering MTU settings often requires placing target nodes into maintenance mode, draining workloads, and manually intervening for VMs utilizing specialized hardware like PCI passthrough that cannot be live-migrated.
Furthermore, Harvester leverages Multus CNI and bridge CNI plugins to attach multiple network interfaces to a single pod, segregating storage network traffic from general management traffic to prevent bandwidth saturation.

The "Death Spiral" of Standard Kubernetes Load Balancing
Perhaps the most complex challenge of self-hosting LLMs is HTTP request load balancing. Standard Kubernetes load balancers, such as standard NGINX Ingress controllers, route traffic based on basic infrastructure metrics like CPU utilization or simple round-robin algorithms.
For traditional, stateless web microservices, this approach is flawless. For stateful LLMs, it causes a catastrophic performance collapse known as the load balancing "Death Spiral".
When a user interacts with a conversational AI agent, the model builds up a "KV (Key-Value) Cache"—a massive, memory-heavy chunk of VRAM that stores the mathematical context of the ongoing conversation.
If a user's follow-up question is routed to a GPU that already holds that specific KV Cache in memory, the response generation is nearly instantaneous.
However, if a standard, stateless load balancer blindly routes that follow-up question to a different GPU, that new GPU must re-process the entire conversation history from scratch to rebuild the cache.
This wastes massive amounts of compute cycles, severely spikes latency, and dramatically reduces the overall throughput of the cluster.
Furthermore, if a specific request requires a fine-tuned LoRA adapter (for example, a prompt directed at a specialized "Legal Assistant" module), routing that request to a GPU that does not currently have that specific adapter loaded into its memory introduces massive, multi-second latency spikes as the GPU is forced to fetch and load the multi-gigabyte adapter file from the storage backend.
Engineering Solutions: AI-Aware Routing and the Gateway API
To resolve these severe bottlenecks, infrastructure engineering teams must completely abandon basic CPU/Memory autoscaling triggers for AI workloads. Instead, they must implement advanced, AI-aware routing architectures at the network edge of the cluster.
Consistent Hashing and Sticky Sessions: Load balancers must be configured to inspect the incoming HTTP payload, hash the prompt prefix or the dedicated session ID, and consistently route that specific session back to the exact pod where the context already resides.
Advanced algorithms, such as Consistent Hashing with Bounded Loads (CHWBL), are required to ensure that while sessions remain sticky, no single backend server becomes overwhelmed by a sudden surge in prompt complexity.
Kubernetes Gateway API Integration: The industry is rapidly moving toward standardizing how model inference servers report their real-time load using the Kubernetes Gateway API.
In this architecture, serving engines (like vLLM, Ollama, or Triton) report their exact KV cache depth, request queue length, and currently loaded LoRA adapters back to the gateway controller.
An intelligent gateway, such as the GKE Inference Gateway or customized Envoy proxies, reads these highly specific metrics and makes routing decisions based on GPU memory states rather than generic CPU usage, ensuring requests are distributed to the node most mathematically prepared to answer them.
Host-Based Network Load Balancing: To mitigate congestion at the RDMA layer, modern AI clusters are deploying techniques like Hopper, a load-balancing protocol optimized for RDMA traffic that operates entirely at the host level.
Hopper continuously monitors the active network paths for congestion and dynamically switches traffic to less congested paths without requiring specialized hardware modifications to the physical network switches, significantly reducing tail flow completion times during massive GPU synchronization events.
Storage and I/O Bottlenecks
Finally, feeding data fast enough to keep expensive GPUs fully utilized is a critical configuration challenge.
Inference workloads optimize for Input/Output Operations Per Second (IOPS)—often requiring tens of thousands of operations—and sub-millisecond latency to perform random access reads against model weights.
This requires NVMe-based local storage architectures, completely separate from the sequential, high-bandwidth parallel file systems traditionally used for model training.
Overlooking this distinction results in GPUs sitting idle while waiting for disk reads, obliterating the economic advantages of owning the hardware.
When to Run AI Locally vs. Edge Network APIs: The B2B Decision Matrix
The ultimate architectural choice between Cloudflare's edge ecosystem and Harvester's on-premises infrastructure is dictated by the intersection of an organization's specific industry regulations, data sensitivity, and operational scale.
Healthcare, Finance, and Regulated Industries: The On-Premises Mandate
In the healthcare sector, organizations process immense volumes of highly sensitive Protected Health Information (PHI). Hospitals produce approximately 50 petabytes of data annually, and the application of AI in diagnostics, imaging analysis, and remote patient monitoring requires processing this data securely.
Similarly, in the financial services sector, quantitative algorithmic trading strategies and sensitive client portfolio data are subjected to intense regulatory scrutiny.
For these industries, data cannot legally or strategically leave the heavily fortified corporate perimeter. Edge computing architectures, despite their speed, introduce unacceptable compliance complexities regarding GDPR, HIPAA, ITAR, and strict data residency mandates.
For these sectors, deploying models on an isolated, air-gapped Harvester HCI cluster is a non-negotiable requirement. It provides the low-latency local processing required for real-time fraud detection algorithms or critical medical image analysis while guaranteeing that sensitive prompts are never transmitted to, or logged on, a third-party server.
Software, AdTech, and Fast-Growing Startups: The Edge Advantage
Conversely, fast-growing B2B software-as-a-service (SaaS) startups, advertising technology firms, and digital media companies building highly interactive, public-facing AI agents benefit immensely from edge deployments.
Consider an advertising platform utilizing generative AI to dynamically create customized ad copy based on real-time user browsing behavior across the globe. For this platform to function seamlessly, the AI inference must reside at the edge. Cloudflare Workers AI allows these companies to bypass complex infrastructure management entirely.
By utilizing Cloudflare's massive global footprint, the platform ensures that an end-user in Tokyo and a user in London receive dynamically generated responses with identical, single-digit millisecond latency.
The serverless OpEx model perfectly aligns with their need for rapid, agile deployment, global elasticity, and variable cost structures, far outweighing the need for strict, air-gapped data isolation.
Manufacturing, Logistics, and Telecom: The Far-Edge Hybrid
Heavy physical industries such as telecommunications, industrial manufacturing, and global logistics often deploy a hybrid architectural model.
They utilize HCI platforms like Harvester at their localized "far edge"—such as directly on a factory floor, inside a warehouse, or at a remote cellular base station.
By placing a robust Harvester node physically inside the manufacturing facility, they achieve the ultra-low latency (under 10 milliseconds) absolutely necessary for computer vision systems monitoring high-speed assembly lines for quality control defects.
More importantly, this localized deployment ensures that critical physical operations continue uninterrupted even if the connection to the centralized cloud or the broader internet completely fails.
Strategic Decision Matrix
The following table summarizes the strategic deployment recommendations based on specific B2B industry requirements and workload characteristics.
| Industry / Persona | Primary Business Driver | Optimal Infrastructure Deployment | Key Architectural Reason |
|---|---|---|---|
| Healthcare & Life Sciences | HIPAA Compliance, Patient Privacy | On-Premises (Harvester HCI) | Zero Trust network isolation; strict data residency; local processing of heavy imaging files. |
| Financial Services | IP Protection, Algorithmic Secrecy | On-Premises (Harvester HCI) | Protection of proprietary logic from telemetry tracking; ultra-low latency for local trading engines. |
| AdTech & B2B SaaS | Global Scalability, Time-to-Market | Edge Network (Cloudflare) | Millisecond latency for distributed global users; zero hardware provisioning delays. |
| Startups & Prototyping | Capital Preservation, Elasticity | Edge Network (Cloudflare) | Pay-per-request OpEx model; avoidance of heavy hardware CapEx during product-market fit testing. |
| Manufacturing & Logistics | Uptime Reliability, Real-time Control | Far-Edge Hybrid (On-Prem Node) | Survival of internet outages; sub-10ms latency for physical robotics and sensor processing. |
The Baytech Consulting Approach to Enterprise AI Infrastructure
Firms like Baytech Consulting, which specialize in custom software development and application management, recognize that integrating artificial intelligence is no longer merely a matter of making a simple API call; it is a foundational, highly consequential architectural decision.
Through a methodology defined by a Tailored Tech Advantage, engineering teams must avoid prescribing one-size-fits-all solutions. For clients requiring immense global scale, variable cost structures, and rapid time-to-market, architects must design seamless, secure integrations with robust edge platforms like Cloudflare's Agent Cloud.
However, for organizations operating in regulated environments that require absolute data sovereignty, rigorous intellectual property protection, and optimized long-term unit economics, the engineering imperative shifts to designing and deploying resilient, self-hosted AI fabrics. This is where it pays to combine infrastructure decisions with a clear enterprise AI readiness checklist that aligns data, security, and governance before you scale.
Leveraging deep, specialized expertise in on-premises infrastructure—spanning Harvester HCI, Rancher, Kubernetes, Docker, and data management systems like PostgreSQL and SQL Server—professional application management firms build fortified, isolated AI environments. A commitment to Rapid Agile Deployment ensures that even the most complex hyper-converged network configurations, including the meticulous tuning of RDMA fabrics and the implementation of sophisticated AI-aware KV-cache load balancing algorithms, are executed transparently and efficiently. Delivering true enterprise-grade quality allows clients to harness the transformative power of agentic AI workflows without ever compromising the security of their proprietary data or the predictability of their financial bottom line. For executives who also need to control ongoing LLM spend, pairing this approach with the techniques outlined in The Token Tax: Stop Paying More Than You Should for LLMs can dramatically improve unit economics.
Strategic Conclusions for Infrastructure Architects
The evolution of enterprise AI deployment in 2026 presents a definitive bifurcation. Edge computing networks, specifically Cloudflare's Agent Cloud and Workers AI, offer unparalleled ease of use, zero capital expenditure, and instantaneous global reach powered by highly efficient V8 isolates. This paradigm remains the definitive choice for consumer-facing agents, rapid prototyping, and dynamic, stateless workloads where global latency and elasticity are the primary business concerns.
However, for mature B2B enterprises processing sensitive data at high volumes, the economic realities of token generation and the strict mandates of data security force a strategic return to on-premises hardware. Hyper-converged infrastructure platforms like Harvester HCI v1.7, powered by the robust orchestration of Kubernetes, provide the necessary framework to run MIG-partitioned GPUs, execute direct PCI passthrough, and maintain strict, air-gapped data sovereignty.
While self-hosting introduces exceptionally complex network engineering challenges—specifically regarding lossless RDMA fabrics, MTU tuning, and KV-cache-aware load balancing—the profound long-term financial savings and the absolute, uncompromising protection of proprietary business logic establish localized infrastructure as the superior choice for high-throughput, enterprise-grade AI operations. Organizations modernizing older line-of-business platforms can often combine these infrastructure decisions with patterns like the AI Sidecar approach to add "chat with data" features without a risky full rewrite.
Frequently Asked Question
When should an enterprise choose Cloudflare Workers AI over an on-premises Harvester HCI deployment?
An enterprise should choose Cloudflare Workers AI when they are building stateless, dynamic AI agents that require global reach, ultra-low latency for geographically distributed users, and rapid deployment without upfront capital expenditure. The edge is ideal for low-to-medium volume workloads, startups testing product-market fit, and applications where the convenience of a managed, serverless network outweighs the per-request operational costs.
Conversely, an enterprise must transition to an on-premises Harvester HCI deployment when their inference volume scales to the point where renting compute becomes cost-prohibitive (the 60-70% utilization threshold), when dealing with highly sensitive data that cannot legally or strategically leave the corporate perimeter due to privacy regulations, or when the AI application requires stateful, persistent, long-running contextual memory that standard edge isolate environments cannot technically support. For many SMBs, this decision will also depend on budget and staffing; our SMB AI Adoption Guide walks through use cases, realistic cost tiers, and 90‑day roadmaps that can help smaller teams choose the right deployment model.
Supporting Resources
- Cloudflare Expands its Agent Cloud to Power the Next Generation of Agents
- https://www.suse.com/c/suse-virtualization-harvester-v1-7-0-release/
- https://lenovopress.lenovo.com/lp2368-on-premise-vs-cloud-generative-ai-total-cost-of-ownership-2026-edition
- To understand how data quality and pipelines affect both edge and on‑prem models, see Garbage In, Gold Out: How Data Readiness Unlocks Enterprise AI.
- Executives worried about model security and regulatory pressure should review Secure AI Code: A 7-Stage Regulatory Compliance Framework and how its controls map onto the architectures discussed here.
- If your team is also exploring agentic automation on top of this infrastructure, Busywork to Brilliance: AI Automation That Actually Works shows how to turn these building blocks into real workflows with measurable ROI.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.