
Garbage In, Gold Out: How Data Readiness Unlocks Enterprise AI
March 13, 2026 / Bryan Reynolds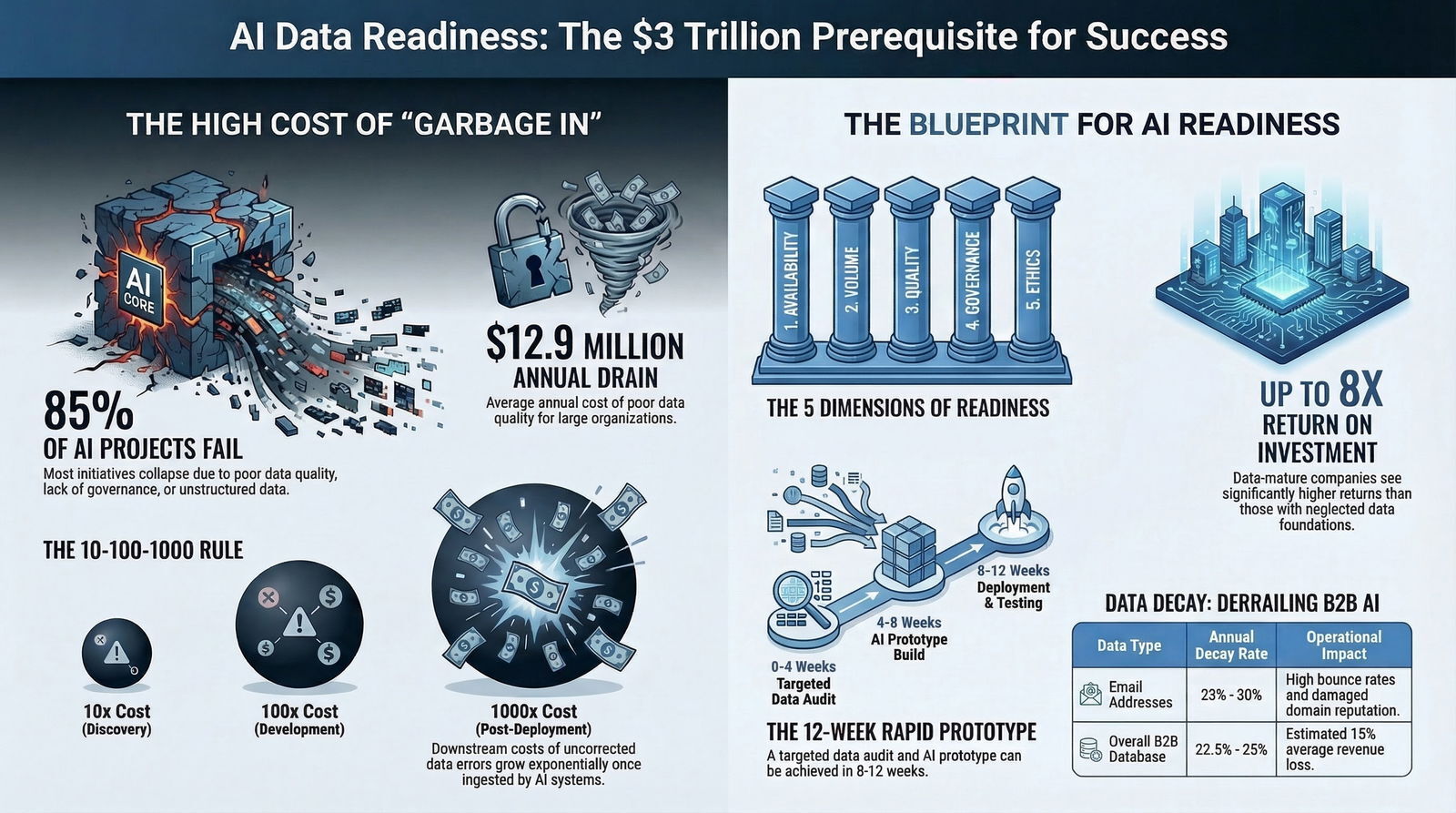
Data Readiness Consulting: The Fundamental Prerequisite for Enterprise AI
The enterprise pursuit of artificial intelligence has reached a fever pitch across the global business landscape. Organizations are aggressively integrating generative models, predictive analytics, natural language processing algorithms, and autonomous AI agents into their core operational workflows. Yet, despite massive capital expenditures and strategic prioritization from the highest levels of corporate leadership, a significant portion of these high-profile initiatives fail to deliver their anticipated return on investment. Advanced predictive models hallucinate facts, automated customer service workflows break down under complex queries, and algorithmic strategic insights frequently prove demonstrably false.
The root cause of these systemic failures rarely lies in the underlying sophistication of the neural networks or the mathematical architecture of the algorithms themselves. Rather, the failure stems almost entirely from the foundational quality, structure, and integrity of the information feeding these systems. The universal, uncompromising computing principle of "Garbage In, Garbage Out" (GIGO) has never been more relevant, nor has it ever carried such profound financial consequences.
Before any meaningful automation can occur, corporate data must be painstakingly structured, rigorously cleaned, and meticulously governed. This uncompromising reality check has given rise to the critical discipline of data readiness consulting—a specialized, highly technical field dedicated to auditing, restructuring, and optimizing disparate corporate data to make it definitively AI-ready. This exhaustive research report explores the mechanics of AI data readiness, the cascading and exponential costs of poor data hygiene, the architectural imperatives of modern data integration pipelines, and the highly structured phases of the enterprise data audit. For a deeper dive into how to weave this discipline into a modern development lifecycle, see our companion guide on the AI-native SDLC, which shows how data readiness underpins every stage of AI-enabled software delivery.
The AI Reality Check: Why Algorithms Produce Flawed Outputs
A persistent, urgent question echoing through corporate boardrooms and executive steering committees is why multi-million-dollar AI deployments consistently generate inaccurate, biased, or entirely nonsensical answers. The answer requires a fundamental understanding of machine learning architecture. Artificial intelligence models do not possess innate knowledge, contextual awareness, or human-like reasoning. They are highly sophisticated mathematical engines designed to recognize complex patterns, calculate probabilities, and synthesize outputs based entirely on the corpus of data upon which they were trained, fine-tuned, and prompted. When an organization feeds an AI engine incomplete, outdated, highly siloed, or unstructured data, the system dutifully treats those underlying flaws as ground truth.
The Anatomy of AI Failure
Research across the B2B technology sector indicates a staggering failure rate for AI implementations that lack rigorous foundational data architecture. According to comprehensive industry analysis, up to 85% of all AI models and automated projects fail primarily due to poor data quality, a lack of data governance, or an absolute absence of relevant, structured data.
A recent, expansive study analyzing thousands of queries directed at highly sophisticated AI systems found that 45% of those queries produced erroneous, misleading, or factually incorrect answers.
This demonstrates a critical vulnerability: even a marginal error rate in input data—sometimes as low as 2%—can exponentially degrade the reliability of downstream analytical outputs, rendering the system effectively useless for strategic decision-making.
Poor data quality manifests in several distinct, highly destructive ways within AI systems, each carrying severe operational, financial, and reputational consequences for the enterprise:
- Incomplete Datasets and Informative Missingness: When critical variables, historical records, or contextual markers are missing from a dataset, predictive models are forced to form distorted, skewed predictions. For example, a financial forecasting tool lacking comprehensive historical expense data or detailed seasonal variations will inevitably generate overly optimistic margin projections, leading to catastrophic capital misallocation.
- Inaccurate, Redundant, and Outdated Records: Data decay is a relentless, entropic force within any organization. AI systems relying on outdated CRM records, redundant vendor files, or legacy supply chain logs make autonomous decisions based on past, irrelevant circumstances. This results in misallocated marketing resources, operational bottlenecks, and fundamentally flawed customer interactions.
- Statistical Artifacts and Physical Inconsistencies: In computer vision, simulation models, and spatial computing, low-quality synthetic data or poorly labeled real-world sources introduce dangerous statistical artifacts. While AI-generated images or synthetic training environments might appear highly realistic to a human observer, they often lack physical consistency (e.g., incorrect lighting physics, flawed depth perception), which actively misleads machine learning algorithms in critical, high-stakes applications such as autonomous navigation, advanced manufacturing robotics, or medical imaging diagnostics.
- Algorithmic Bias and Discrimination: AI systems act as objective mirrors, flawlessly reflecting and mathematically amplifying the human biases and historical prejudices present in their training data. Notable, highly publicized industry failures—such as algorithmic recruitment tools that systematically penalized female candidates because they were trained on historically male-dominated enterprise resumes—underscore the severe reputational, ethical, and legal risks of deploying autonomous models on unvetted, un-audited historical data. For a broader look at how these risks connect to long-term technical debt and trust, review our analysis of AI technical debt and total cost of ownership.
- Security Risks and Adversarial Vulnerabilities: Inaccurate or poorly structured data can be actively exploited by malicious actors to manipulate AI systems. If an AI agent relies on unverified external data feeds, it becomes susceptible to data poisoning attacks, leading to severe security breaches, the autonomous spread of misinformation, and the compromise of proprietary enterprise intellectual property. These same weaknesses are often exploited through prompt injection and unsafe integrations, which is why many enterprises now pair data readiness with an AI firewall to protect models at the boundary.
Without high-quality, deeply cleansed, and universally standardized data, even the most advanced, capital-intensive AI technologies fail to deliver meaningful business value. Furthermore, they actively introduce enterprise risk. AI data readiness, therefore, is not an IT administrative task to be delegated; it is the fundamental, non-negotiable bedrock of enterprise AI viability and modern corporate strategy.
The Escalating Financial Toll: The 1-10-100 Rule
The operational impact of poor data quality is not merely an inconvenience for data scientists; it translates directly into severe, systemic financial hemorrhage for the enterprise. Broad industry estimates, backed by leading advisory firms, suggest that poor data quality costs the average large organization approximately $12.9 million annually in wasted resources, endless remediation efforts, reduced productivity, and lost strategic opportunities.
On a macroeconomic scale, the impact is staggering, with bad data silently draining an estimated $3 trillion annually from the U.S. economy alone.
To conceptualize the hidden financial mechanics of data hygiene and the urgent need for comprehensive data audits, enterprise data architects and strategic CFOs frequently rely on the 1-10-100 Rule of Data Quality. Originally formulated in 1992 in the context of total quality management, this paradigm flawlessly illustrates the compounding, exponential costs of deferred data maintenance, a reality that has only grown more severe in the age of hyperscale computing.
| Intervention Phase | Financial Ratio | Operational Description | Enterprise Impact |
|---|---|---|---|
| Prevention (Point of Entry) | $1 | Verifying, cleansing, and ensuring accuracy as data is ingested into the system. | Highly efficient. Requires automated validation rules, structured ingestion pipelines, and rigorous upfront data governance. |
| Remediation (Data Warehouse) | $10 | Locating, extracting, and correcting flawed data after it has bypassed initial validation and entered the corporate data ecosystem. | Resource-intensive. Data engineering teams spend vital hours querying databases, reconciling silos, and running batch updates, distracting from strategic work. |
| Failure (Downstream Impact) | $100+ | Uncorrected data is ingested by an AI model, utilized in a financial report to stakeholders, or acted upon by a sales team. | Catastrophic. Represents the cost of lost enterprise value: a botched marketing campaign, a flawed supply chain decision, compliance violations, and damaged brand equity. |

Modern data professionals argue that in the current era of generative AI, high-frequency algorithmic trading, and automated decision engines, this paradigm has shifted significantly. It is now more accurately modeled as a 10:100:1000 ratio.
Because AI systems ingest and process data at machine speed, they rapidly amplify underlying data flaws. The downstream cost of failure—ranging from algorithmic bias lawsuits, regulatory fines under the GDPR or CCPA, to the outright abandonment of $10 million AI initiatives—has grown exponentially, far surpassing the original estimates of the 1990s.
Amplification Through Automation
A critical misunderstanding among executive leadership is the belief that automation can streamline messy operations. In reality, automation does not correct bad data; it merely operationalizes it at unprecedented speed. When poor-quality data enters machine learning workflows, its inherent inaccuracies, biases, and structural inconsistencies propagate across all downstream systems.
This creates a cycle of operational degradation. Data engineering teams, rather than building advanced predictive models, ultimately spend up to 50% of their expensive, highly specialized time on reactive remediation efforts.
By the time a systemic data quality issue surfaces on a boardroom executive dashboard as a missed revenue target or a failed compliance audit, the cost to trace the error back through complex AI pipelines and fix it at the source is astronomically higher than implementing a data readiness strategy prior to deployment. Repeated exposure to these automated, inaccurate insights rapidly erodes stakeholder trust; business users begin to question the validity of the AI, adoption stalls, and the entire digital transformation initiative is jeopardized. This is exactly why we recommend pairing data readiness with a proactive AI strategy instead of relying on passive dashboards; see our perspective in “Kill the Dashboard: The Rise of Proactive AI” for how clean data fuels continuous, trustworthy insights.
Industry-Specific Vulnerabilities: How Bad Data Derails B2B Operations
The necessity of rigorous data readiness consulting becomes acutely apparent when examining sector-specific use cases. Across the diverse B2B landscape, disparate industries face highly unique data structure challenges, regulatory environments, and legacy system architectures that actively prevent effective automation. A bespoke approach to data auditing is required for each.
Advertising and Marketing Technology (AdTech & MarTech)
In the hyper-competitive B2B marketing sector, data is the absolute, undisputed fuel for revenue operations, predictive lead scoring, programmatic advertising, and account-based marketing (ABM). Yet, research indicates that 45% of the data used by marketers to make critical business decisions is fundamentally incomplete, wildly inaccurate, or totally obsolete.
Consequently, 43% of Chief Marketing Officers (CMOs) actively distrust the majority of their own marketing intelligence.
The core challenge in B2B marketing is the rapid velocity of data decay. Contact data, firmographic details, and behavioral signals degrade at an alarming rate of 22.5% to 25% annually as professionals change roles, companies merge, and corporate email architectures shift.
This continuous deterioration results in futile marketing efforts, fundamentally flawed buyer personas, wasted advertising spend, and severely damaged email sender reputations.
| Data Type | Annual Decay Rate | Operational Impact on B2B Marketing & Sales |
|---|---|---|
| Email Addresses | 23% - 30% | High bounce rates, damaged domain reputation, increased risk of permanent spam filter blocks, inability to nurture leads. |
| Phone Numbers | 18% | Unsuccessful cold calling campaigns, ineffective SMS outreach, severe disruptions in sales development representative (SDR) workflows. |
| Overall B2B Database | 22.5% - 25% | Estimated 15% average revenue loss; wasted digital advertising spend targeting defunct accounts. |
If an enterprise feeds its generative AI marketing models or automated bidding algorithms with this unverified, rotting data, the algorithmic targeting will misfire up to 86% of the time, squandering an estimated 10-25% of the total marketing and advertising budget. Data readiness in this specific sector demands rigorous, continuous hygiene protocols, real-time API enrichment integrations, and strict deduplication processes before any predictive lead scoring or automated personalized outreach can be safely deployed.
Real Estate, Mortgage, and PropTech
The mortgage lending and commercial real estate institutions process some of the most complex, highly unstructured, and heavily regulated data in the entire financial sector. Mortgage applications and commercial acquisitions require the ingestion and meticulous verification of vast amounts of heterogeneous documentation: complex tax records, variable income statements, physical property appraisals, and dense legal agreements.
Industry surveys reveal that the primary, overriding barrier to AI adoption in commercial real estate is data quality and data availability.
Most critical intelligence is trapped in static, unstructured PDFs, poorly scanned images, or siloed core management systems that lack modern API connectivity.
Advanced AI technologies—such as Natural Language Processing (NLP) and sophisticated Computer Vision models—are theoretically capable of automating tedious document processing, verifying compliance, and performing instant credit risk analysis.
However, these models cannot read physical paper or interpret chaotic data lakes; they require perfectly extracted, normalized, indexed, and analyzed digital data.
Data readiness consulting in the real estate and PropTech sectors focuses heavily on deploying optical character recognition (OCR) and intelligent document processing to transform unstructured, legacy documents into machine-readable, tabular data suitable for centralized data warehousing and subsequent machine learning applications.
Financial Services and FinTech
In the financial sector, where reporting accuracy is not just a business goal but a strict regulatory mandate, AI governance and absolute data integrity are non-negotiable prerequisites.
Flawed data in finance leads directly to inaccurate revenue projections, misallocated capital, heightened credit risk exposure, and severe regulatory penalties.
For instance, if an AI agent is deployed for real-time anomaly detection in credit card transactions, or for building predictive models for loan defaulting, it must draw upon flawless, bias-free historical data.
Financial institutions must undertake exhaustive data audits to map intricate systemic dependencies, validate external data sources, and eliminate their historic reliance on manual, error-prone IT reporting. The transition to an AI-ready financial posture requires the aggressive discontinuation of rigid legacy systems, the full implementation of paperless, cloud-based bookkeeping, and the rigid standardization of workflows to ensure the absolute consistency needed for autonomous, agentic AI to operate safely.
Healthcare and MedTech
The stakes of data readiness are arguably highest in the healthcare and MedTech sectors, where data quality directly and tangibly impacts clinical outcomes, patient safety, and complex operational logistics.
Poor data quality in healthcare ecosystems leads to misaligned medical benefits, dangerously delayed care, severe administrative burnout among clinicians, and massive financial waste.
A prime, quantifiable example of this crisis is the proliferation of duplicate medical records. In a typical healthcare organization, nearly 20% of all patient records are duplicates, creating fragmented, contradictory views of patient medical history.
These duplicates not only delay critical surgical treatments and emergency department response times, but they also increase operational costs by an average of $1,100 per affected patient, representing tens of millions of dollars in entirely preventable losses for a single hospital network.
Achieving AI readiness in healthcare requires building a sophisticated, HIPAA-compliant enterprise data fabric that seamlessly harmonizes clinical data across disparate electronic health record (EHR) systems. This fabric must resolve duplications with extreme precision and expertly handle the "informative missingness" prevalent in medical datasets, ensuring that AI-driven diagnostic tools and predictive resource allocation models operate on a foundation of absolute clinical truth.
Telecommunications, Software, and High-Tech
For B2B software-as-a-service (SaaS) providers and telecommunications giants, survival depends on subscription renewals, network reliability, and the precise prediction of customer churn. These industries generate petabytes of data daily, primarily in the form of network telemetry, software usage logs, and customer support interactions.
AI readiness in these sectors hinges on the ability to process high-velocity, real-time data streams. If telemetry data is dropped, mislabeled, or delayed, predictive AI models designed to anticipate server outages or identify at-risk enterprise software accounts will fail to trigger automated interventions. The data audit phase here focuses heavily on latency reduction, stream processing architectures, and the unification of product usage data with financial billing records to create a holistic, real-time view of account health. In practice, that often means moving beyond simple vector search and investing in production-grade SQL agents for accurate reporting, especially when revenue and SLAs are on the line.
Education Technology (EdTech) and Gaming
While seemingly disparate, the EdTech (Learning Management Systems) and Gaming sectors share a profound reliance on real-time behavioral data to drive AI personalization. In EdTech, predictive models are deployed to identify struggling learners, recommend personalized coursework, and automate grading. In B2B gaming infrastructure, AI governs matchmaking algorithms, dynamic difficulty adjustment, and real-time fraud detection.
For both industries, data must be structured as high-fidelity time-series event logs. If an LMS fails to accurately capture the sequence and duration of a student's interactions with a module, the resulting AI intervention will be mistimed and irrelevant. Data readiness consulting ensures that event-tracking architectures are robust, scalable, and standardized, allowing machine learning models to ingest behavioral data seamlessly and output highly accurate, personalized dynamic responses.
Engineering AI Readiness: Data Structures and Pipelines
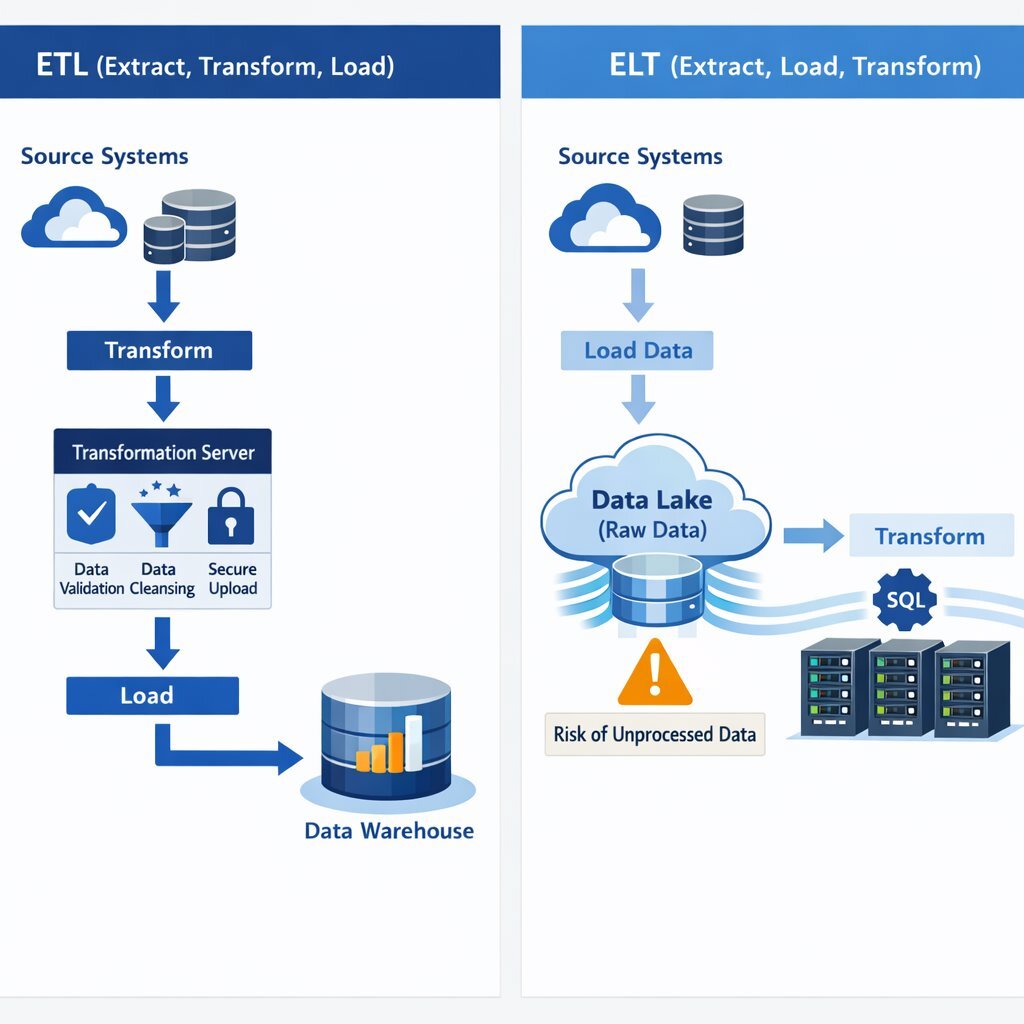
Achieving the clean, highly structured data required to prevent the catastrophic failures outlined across these industries necessitates sophisticated, enterprise-grade infrastructure. Before an organization can deploy an advanced AI model or a generative language agent, it must structurally architect and deploy robust data integration pipelines. The two dominant paradigms for moving, preparing, and structuring data are ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). Choosing the correct architecture is a critical outcome of the data readiness consulting process.
The Foundational Role of ETL in AI Preparation
ETL is a legacy data integration process that has been extensively modernized for the cloud computing era. In an ETL pipeline, the system extracts raw data from disparate SaaS applications, legacy databases, and on-premises systems. Crucially, it then transforms this data (cleansing, filtering, normalizing, and structuring it) on a dedicated, intermediate processing server before finally loading it into a target data warehouse.
ETL remains foundational and highly preferred for delivering high-quality, rigidly structured data to traditional machine learning models and business intelligence dashboards.
By enforcing strict schema transformations and data quality rules before the data ever lands in the central warehouse, ETL pipelines actively remove errors, deduplicate overlapping records, and resolve structural inconsistencies, ensuring that only verified, trusted data reaches the AI layer.
This specific pipeline architecture is highly recommended when dealing with sensitive, heavily regulated compliance data—such as Personally Identifiable Information (PII) in healthcare or protected financial records. Because the data is cleansed, masked, and secured in a staging area before it enters the central repository, the risk of exposing sensitive data to broad analytical queries is significantly mitigated.
Furthermore, debugging ETL failures is straightforward, as the logs are tied directly to the transformation layer before the data lands.
The Shift to ELT for Hyperscale AI and RAG Models
Conversely, the ELT architecture prioritizes speed and raw data availability. ELT extracts data from sources and loads it directly into a highly scalable cloud data warehouse or data lake in its raw, unaltered state. It then utilizes the immense, elastic processing power of the destination system itself to transform the data on demand (a paradigm known as schema-on-read).
ELT has become increasingly popular and frequently necessary in the modern AI landscape due to its unparalleled speed and flexibility. It is uniquely capable of handling massive, continuous volumes of unstructured data (such as raw text documents, audio files, images, and raw telemetry streams) which are absolutely essential for training complex neural networks, Large Language Models (LLMs), and feeding Retrieval-Augmented Generation (RAG) architectures.
Because raw data is stored indefinitely in the data lake, data scientists and machine learning engineers can iteratively run different transformation models, test new feature engineering techniques, and pivot their AI strategies without needing to initiate costly and time-consuming re-extractions from the original source systems.
However, ELT requires highly disciplined, sophisticated data governance. Because raw, unverified data lands in the warehouse immediately, there is a severe risk of downstream AI models inadvertently ingesting "garbage" if role-based access controls and logical staging areas are not meticulously managed. If consumers or autonomous agents query raw tables directly, the resulting insights will be fundamentally flawed.
The Emergence of Hybrid Pipelines and TEL
To balance the strict governance of ETL with the flexible power of ELT, data readiness consultants often architect hybrid patterns. One such pattern is TEL (Transform, Extract, Load), which introduces a pre-transformation step at the source to act as a lightweight filter, stripping out obvious errors or masking critical PII before the heavier extraction even begins.
A common enterprise hybrid pattern utilizes ETL for sensitive data cleansing and strict compliance enforcement, followed by ELT for complex analytical modeling and AI feature engineering on top of that cleansed foundational layer.
AI-Driven Pipeline Orchestration
The data integration landscape is rapidly evolving beyond static, manually coded pipelines. Modern data integration now utilizes AI to automate the pipelines themselves. AI-driven ETL tools can auto-detect schema changes at the source, suggest complex transformation logic based on historical data patterns, and dynamically adjust pipelines without requiring constant manual intervention from data engineers.
This predictive ETL acts as a self-healing network, preventing costly unplanned downtime by detecting anomalies and statistical drifts in data streams long before they can pollute the central data warehouse and degrade downstream AI performance.
The Custom Infrastructure Advantage: Architectural Best Practices
Building, deploying, securely managing, and continuously maintaining these AI-ready pipelines requires robust, enterprise-grade infrastructure. Organizations cannot rely on rigid, off-the-shelf software to map their highly specific, proprietary corporate logic. Enterprise data readiness requires a custom architectural approach. This is where organizations benefit from a Tailored Tech Advantage—a methodology championed by firms specializing in custom software development and application management, such as Baytech Consulting.
Instead of forcing a company's unique data flows into an inflexible external SaaS platform, specialized engineering teams build resilient, secure, and fully containerized environments tailored to the specific AI use case. Deploying an AI-ready backend that guarantees both high availability and strict data sovereignty relies on a sophisticated, interlocking technology stack:
- Containerization & Orchestration for Resilience: Utilizing Docker to containerize ETL and ELT workloads ensures that extraction and transformation processes run with absolute consistency across any computing environment, eliminating the "it works on my machine" vulnerability. Kubernetes, expertly managed via platforms like Rancher and Harvester HCI, orchestrates these containers at scale. If an ETL pod crashes during a massive, compute-heavy data transformation, the Kubernetes control plane automatically detects the failure and restarts the pod, ensuring zero operational downtime and a continuous, unbroken flow of high-quality data to the AI models. You can see how this ties into our broader .NET, Docker & Kubernetes engineering practice, which underpins many of our AI data platforms.
- Database Foundations for Transactional and AI Workloads: A highly performant, rock-solid relational database is the critical backbone of any data strategy. PostgreSQL (managed and optimized via pgAdmin) and Microsoft SQL Server provide the ACID-compliant transactional certainty required for enterprise operations. Modern iterations of this infrastructure, such as deploying Postgres integrated with vector embedding extensions (e.g.,
pgvector), are transformative. These extensions allow the core database to handle both traditional tabular business data and the complex, high-dimensional vector data required by Generative AI and advanced Retrieval-Augmented Generation (RAG) models, unifying the data ecosystem. - Secure Deployment Environments and Data Sovereignty: Managing proprietary data privacy and ensuring regulatory compliance requires strict, unyielding control over exactly where the data resides and where the compute occurs. Leveraging Azure DevOps On-Prem alongside dedicated, highly secure OVHCloud servers protected by robust pfSense firewalls ensures that sensitive corporate data—whether patient records or financial algorithms—never leaks into the public domain or multitenant cloud environments during the crucial training, transformation, or inferencing phases.
- Rapid Agile Deployment and Collaborative Workflows: The data landscape shifts constantly. Utilizing unified, modern development environments like VS Code / VS 2022 enables Rapid Agile Deployment, allowing software engineering teams to adapt data schemas, modify transformation logic, and deploy updates on the fly as business requirements evolve. This technical agility is supported by seamless collaborative communication across platforms like Microsoft 365, Teams, OneDrive, and Google Drive, ensuring that the business stakeholders and the technical data engineers remain in total alignment throughout the readiness process. Underneath that, we rely on Agile methodology to keep data workstreams iterative, transparent, and closely tied to business outcomes.
This custom, infrastructure-as-code approach ensures enterprise-grade high availability, unbreakable security, and limitless scalability. It is the definitive mechanism by which isolated, chaotic data silos are transformed into unified, potent, and strictly AI-ready assets.
The Data Audit Phase: Defining and Executing AI Readiness
Before a single line of production code is written, before a cloud warehouse is provisioned, and certainly before an AI model is deployed, an organization must undergo a comprehensive Data Readiness Consulting engagement. This process culminates in the foundational "Data Audit" phase. The data audit is the ultimate reality check—a highly systematic, deeply technical, and unvarnished evaluation of a company’s entire data landscape.
An AI readiness assessment rigorously measures organizational capabilities across strategy, data infrastructure, people, and governance to identify critical gaps and vulnerabilities.
The statistical correlation between this preparation and ultimate success is clear: companies that conduct formal, exhaustive readiness assessments are 47% more likely to implement their AI initiatives successfully and achieve their desired ROI.
The Five Dimensions of AI Data Readiness (AIDR)
Expert technology auditors do not simply look at databases; they evaluate an enterprise's entire data ecosystem across five critical, interlocking dimensions:
| Readiness Dimension | Evaluation Focus | Enterprise Imperative |
|---|---|---|
| 1. Data Availability | Can the proposed AI system actually access the required data? | Auditors map data flows between legacy systems and modern cloud environments, assessing whether vital data is trapped in isolated content management systems, inaccessible mainframes, or static PDF reports. |
| 2. Data Volume and Diversity | Is there enough data, and does it represent reality? | Machine learning requires massive datasets to train effectively. Auditors quantify the historical data available and ensure it encompasses sufficient diversity to capture statistical edge cases, seasonal trends, and varied demographic patterns without overfitting. |
| 3. Data Quality and Integrity | Is the data accurate, complete, and reliable? | This is the core technical focus of the audit. Analysts rigorously inspect datasets for completeness, accuracy, consistency, and timeliness. They evaluate the handling of duplicates, the frequency of manual data entry errors, and the protocols for resolving conflicting records across different departments. |
| 4. Data Governance | Who controls the data, and how is it secured? | Auditors verify that crystal-clear policies govern data ownership, role-based access control, and metadata management. Strict governance ensures that powerful language models do not inadvertently ingest and later expose restricted executive communications or confidential HR compensation records. |
| 5. Data Ethics and Responsibility | Does the data harbor historical prejudice or violate privacy? | The final dimension assesses the severe risk of algorithmic bias. Auditors test the training data for historical prejudices and rigorously verify compliance with global regulatory frameworks like GDPR, CCPA, HIPAA, and emerging international AI legislative acts. |
The Strategic Execution of a Data Audit
From an executive perspective, a professional data audit is not a chaotic expedition into the IT department; it moves through five pragmatic, highly structured phases to ensure maximum visibility and minimal operational disruption:
- Phase 1: Define Objectives, Scoping, and Use Cases. The audit must begin with strategic alignment. What specific business problem must the AI solve? (e.g., predictive lead scoring, automated claims processing, real-time supply chain routing). Auditors define the precise scope of the audit based exclusively on the data required for these specific, high-priority use cases, avoiding the trap of trying to audit the entire enterprise simultaneously.
- Phase 2: Assemble a Cross-Functional Task Force. Data does not exist in a vacuum; it represents real business processes. The audit requires deep collaboration between IT data engineers (who know where the data is), specialized data scientists (who know what the AI needs), and departmental Subject Matter Experts (SMEs) (who understand the actual business context and quirks of the data).
- Phase 3: Deep Data Collection and Technical Assessment. Auditors dive directly into the infrastructure. They review data inventories, meticulously inspect Entity Relationship Diagrams (ERDs), evaluate the efficiency of existing ETL/ELT tools, and run advanced statistical profiling algorithms to map the actual, quantifiable error rate and missingness within the core databases.
- Phase 4: Analysis, Stress Testing, and Gap Identification. The audit team compares current data practices and quality metrics against the stringent mathematical requirements of the target machine learning models. They identify specific, critical vulnerabilities—such as biased logic paths in historical data, missing integration APIs that break real-time automation, or uncontrolled legacy silos that contradict the central data warehouse.
- Phase 5: Reporting and the Strategic Remediation Roadmap. The culmination of the data audit is not merely a depressing list of IT errors. It is a highly strategic, actionable roadmap. It outlines the exact data cleansing protocols, the necessary infrastructure investments (e.g., upgrading from a legacy database to a Kubernetes-orchestrated Postgres environment), and the governance frameworks required to achieve absolute AI readiness.
Timelines, Investment, and Measuring ROI
Executives evaluating data readiness consulting and the subsequent infrastructure upgrades must understand that restructuring enterprise data is a significant, complex, yet ultimately highly profitable undertaking. The mathematical justification is robust: implementing AI on a solid foundation of clean, architecturally sound data delivers an average return on investment of 3.5X, with top-performing, data-mature companies seeing returns as high as 8X their initial investment.
Realistic Benchmarks for Timeline and Capital Investment
The cost and duration of a comprehensive data readiness transformation vary heavily driven by industry complexity, the volume of legacy technical debt, and external regulatory pressures. Developing a comprehensive, enterprise-wide AI-ready data platform requires sustained, strategic investment:
| Industry Sector | Data Complexity Drivers | Estimated Investment Range | Estimated Timeline |
|---|---|---|---|
| Healthcare & MedTech | HIPAA compliance, complex clinical record deduplication, highly unstructured physician notes. | 450,000 – 1,200,000 | 10 – 18 months |
| Logistics & Supply Chain | Vast real-time IoT sensor integrations, global telemetry data, disparate vendor systems. | 300,000 – 750,000 | 7 – 13 months |
| Manufacturing & Industry 4.0 | Factory floor sensor data, legacy SCADA systems, predictive maintenance modeling. | 400,000 – 1,000,000 | 8 – 14 months |
| Real Estate & PropTech | Unstructured legal documents, PDF appraisals, disparate local MLS data integration. | 200,000 – 500,000 | 6 – 12 months |
| Retail & eCommerce | High-volume transactional data, unified customer profile creation across fragmented channels. | 220,000 – 600,000 | 6 – 12 months |
However, it is crucial to note that the initial Data Audit and Prototyping phase is substantially faster and less capital-intensive. If a specific business problem is well-defined and appropriately scoped, expert consultants can conduct the audit, clean a targeted subset of data, and deliver a functional predictive AI prototype in 8 to 12 weeks. Scaling that prototype into a highly reliable, enterprise-wide production system that business units actually trust generally takes 4 to 6 months.
Measuring Success in the First 90 Days
The return on a data readiness investment should be demonstrably measurable within the first 90 days of an AI deployment. Success is not measured by vanity metrics such as the sheer volume of data processed or the number of models deployed, but by concrete, unarguable operational improvements:
- Time Saved: A quantifiable reduction in hours spent by highly paid analysts on manual reporting, data hygiene, and tedious process completion.
- Cost Reduction: Decreased operational expenses in AI-assisted workflows and structurally lower costs of customer acquisition due to better targeting.
- Error Rates: Statistically significant improvements in the accuracy of automated decisions, financial forecasts, and inventory predictions.
- Pipeline Velocity: Faster movement of deals through B2B sales stages due to accurate targeting, enriched context, and the elimination of outreach to dead accounts. Many organizations combine these metrics with a broader Agentic Engineering approach, using specialized AI agents on top of clean data to increase speed without sacrificing control.
Conclusion
The aggressive pursuit of artificial intelligence without a mandatory, prerequisite investment in data readiness is an exercise in profound corporate futility. As the evolved 10:100:1000 rule unequivocally demonstrates, ignoring data hygiene at the foundational ingestion level inevitably leads to exponential downstream costs, dangerous algorithmic hallucinations, and total operational paralysis. Artificial intelligence is not a magical panacea capable of untangling chaotic, neglected corporate data; rather, it is an exceptionally powerful, mathematically precise engine that mercilessly accelerates and amplifies whatever fuel it is given.
A comprehensive, brutally honest data audit is the vital, unavoidable first step. By meticulously assessing data availability, governing ethical use, breaking down legacy silos, and deploying robust, containerized ETL and ELT pipelines through expert custom engineering, organizations can transform unstructured operational noise into a proprietary, infinitely scalable AI-ready asset. The fundamental difference between an enterprise that successfully leverages AI for absolute market dominance and one that abandons its costly initiatives entirely lies solely, and irreversibly, in the quality of its underlying data. If you are wondering how to turn that foundation into real autonomous execution instead of isolated experiments, explore our playbook on building your AI team of autonomous bots.
Frequently Asked Questions (FAQ)
Why is my AI model giving me bad, inaccurate, or biased answers? AI models operate entirely and exclusively based on the data they ingest during training and prompting. If a model generates flawed outputs, it is experiencing the reality of "Garbage In, Garbage Out." Incomplete datasets, outdated CRM records, statistical anomalies, and historical human biases embedded in the training data are treated as indisputable facts by the algorithm. This fundamentally flawed foundation results directly in hallucinations, biased targeting, and incorrect autonomous operational decisions. To protect yourself from these issues in production, pair clean data with strong software development security and AI governance practices.
What exactly is evaluated during the "Data Audit" phase? A professional data audit assesses your corporate data ecosystem across five critical dimensions: Availability (can the system access it via modern APIs?), Volume (is there enough history to establish statistical significance?), Quality (is it accurate, clean, and deduplicated?), Governance (is access controlled securely with clear ownership?), and Ethics (is it free from regulatory violations and demographic bias?). The audit identifies these gaps and provides a highly specific technical roadmap for architectural remediation.
How do I prepare my company data for automation and advanced AI? Preparation requires migrating data from static PDF reports, complex spreadsheets, and siloed legacy systems into a centralized, highly structured, and governed environment. This is achieved by engineering and deploying robust data integration pipelines (ETL or ELT) that extract raw data, clean and format it to remove all duplicates and formatting errors, and securely load it into a cloud data warehouse or data lake that is instantly accessible by machine learning algorithms. In many cases, the fastest path is to partner with a team that already has hardened patterns for integrating AI into existing applications and data platforms.
How long does it actually take to get enterprise data "AI-ready"? While building a comprehensive, enterprise-wide, AI-ready data platform can take anywhere from 6 to 18 months depending on industry complexity and strict regulatory compliance requirements (such as HIPAA in healthcare), an initial data audit and the development of a cleansed data prototype for a specific, targeted business use case (like predictive lead scoring) can typically be completed rapidly, usually within 8 to 12 weeks.
Supporting Articles
- https://www.demandgenreport.com/demanding-views/how-poor-data-quality-is-undermining-modern-b2b-operations/51724/
- https://www.matillion.com/blog/the-1-10-100-rule-of-data-quality-a-critical-review-for-data-professionals
- https://assets.kpmg.com/content/dam/kpmg/xx/pdf/2024/04/ai-in-financial-reporting-and-audit-web.pdf
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.