
Minimize Risk and Maximize ROI with Sidecars
March 11, 2026 / Bryan Reynolds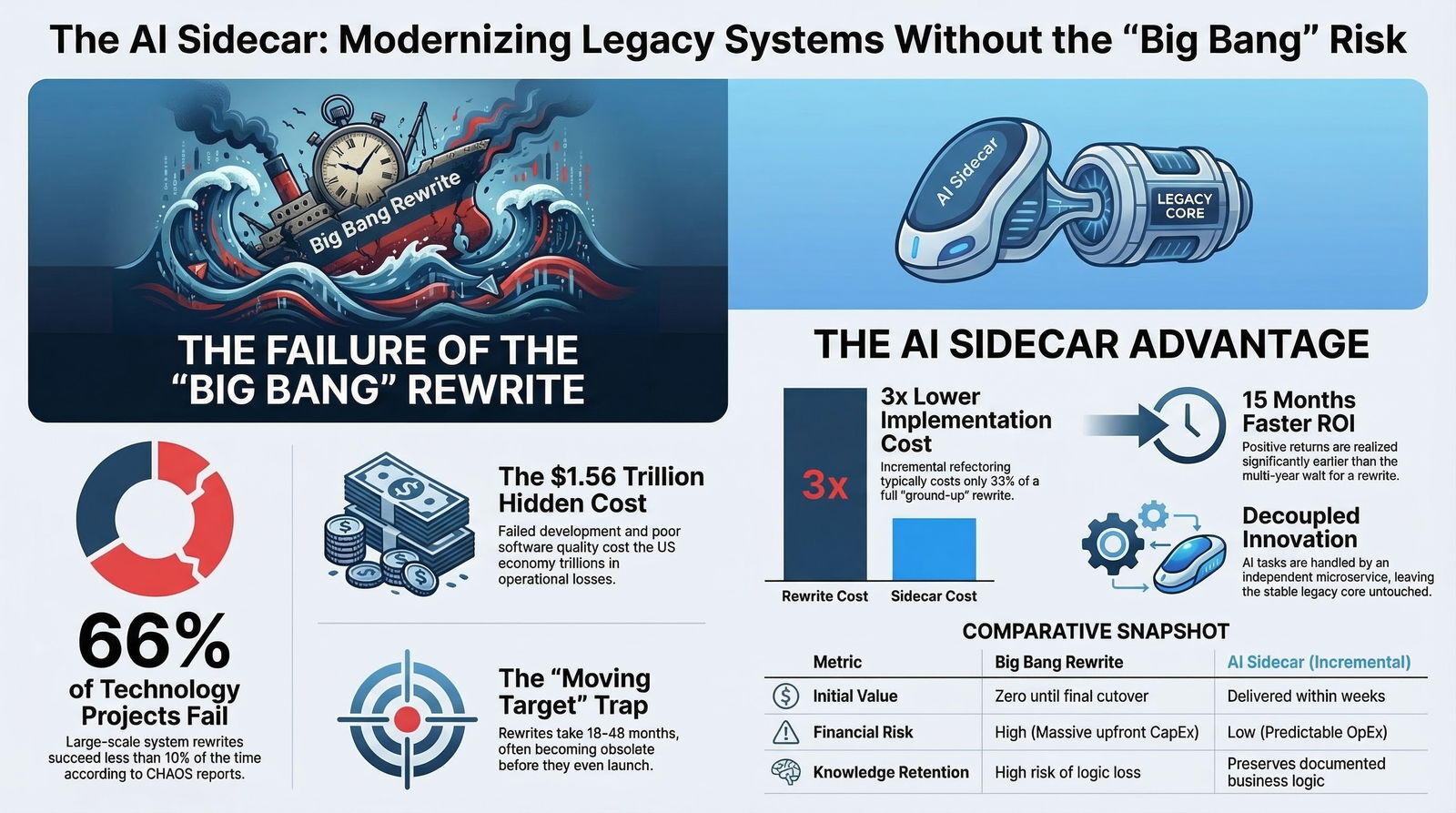
The AI Sidecar Strategy: Incremental Modernization vs. Full Rewrite
The question echoing through corporate boardrooms and daily engineering stand-ups is universally pressing: "Does an entire application need to be rewritten to add artificial intelligence?"
This inquiry arises as organizations face mounting, existential pressure to deploy artificial intelligence capabilities. Enterprises across the globe rely on battle-tested legacy applications to process millions in revenue, manage complex global supply chains, and secure decades of proprietary, highly sensitive data. Yet, these same applications are frequently rigid, monolithic, and technologically isolated from the rapidly expanding modern AI ecosystem. When business executives demand cutting-edge capabilities—such as the ability to "Chat with Data" or deploy predictive analytics—the traditional software development response is often a catastrophic recommendation: the complete, ground-up system rewrite.
This exhaustive analysis dissects the technical, financial, and operational realities of software modernization. By examining decades of project data, this report explores why the "big bang" rewrite is statistically doomed to fail and how a hybrid architectural approach—specifically the AI Sidecar Pattern—provides a low-risk, high-reward pathway to incremental updates. Through the integration of large language models (LLMs) with legacy databases via retrieval-augmented generation (RAG), organizations can deploy modern intelligence without disrupting their operational core. For a deeper dive into why most AI rebuild projects struggle, see our research on software development security, technical debt, and AI governance.

The State of Legacy Systems in the Modern Enterprise
To understand the necessity of an incremental approach, one must first examine the entrenched nature of legacy systems within the global economy. A legacy system is not merely "old" software; it is business-critical software that resists rapid modification. As much as 70% of the software utilized by Fortune 500 companies was developed two or more decades ago.
The "If It Ain't Broke" Dilemma
Survey data from 2025 indicates that 62% of organizations still rely heavily on legacy systems for their daily operations. When IT professionals are asked why these systems have not been upgraded, 50% state that the primary reason is simply because "the current system still works". These systems successfully process transactions, manage inventory, and maintain compliance. They are the digital bedrock of the enterprise.
However, this stability masks a growing crisis of technical debt. This technical debt acts as a massive anchor, slowing down business agility and innovation. While the systems function for their original purpose, they lack the flexibility required for rapid change, making it nearly impossible to integrate generative AI, real-time analytics, or modern mobile interfaces. Furthermore, 43% of organizations cite security vulnerabilities in these aging platforms as a major, ongoing concern, while 68% must rely entirely on internal IT teams for maintenance due to a severe shortage of external developers skilled in outdated languages.
The Market Imperative for Modernization
The pressure to resolve this tension has created a massive economic sector. The global application modernization services market is valued at approximately $24.98 billion in 2025 and is projected to skyrocket to $56.87 billion by 2030, representing a robust Compound Annual Growth Rate (CAGR) of 17.92%.
Other analyses place the ceiling even higher, projecting the market to reach $72.5 billion by 2033.
This explosive financial growth is driven by enterprise recognition that modernization cannot wait. Approximately 87% of business leaders now state that modernization is absolutely essential to grow and succeed, and in 2025, modernizing existing applications remains among the top ten priorities for Chief Information Officers (CIOs) globally. Around 91% of CIOs expect their budgets to increase specifically to boost business agility through modernization. Many of these leaders are now prioritizing enterprise application architecture that can support AI sidecars and gradual refactoring.
The mandate is clear: organizations must modernize to survive. However, the methodology chosen to execute this modernization dictates whether the enterprise thrives or faces catastrophic operational failure.
The Trap of the "Big Bang" Rewrite
When tasked with modernizing a legacy platform, enthusiastic developers and external agencies frequently push for a "Big Bang" approach. This strategy involves discarding the existing legacy system in its entirety and building a completely new application from scratch. The plan typically culminates in a predefined cutover date—a singular moment where the old system is permanently switched off, and the new system takes over all business processes.
Advocates argue this is the only way to achieve technical purity, eliminate decades of technical debt, and seamlessly integrate modern, cloud-native frameworks. They present executives with a vision of a pristine architecture, free from the constraints of the past. However, empirical data gathered over the last three decades paints a remarkably grim picture of this high-stakes strategy.
The Statistical Reality of Software Project Failure
The assertion that complete software rewrites are highly risky is not a matter of opinion; it is a heavily documented statistical fact. The Standish Group's CHAOS Report, a foundational and ongoing study analyzing global software project outcomes, reveals that a staggering 66% of technology projects end in partial or total failure.
When analyzing large-scale rewrites specifically, the numbers become even more alarming. Large projects are successful less than 10% of the time, while an estimated 31% of US IT projects are canceled outright before ever delivering a single feature to production. Government initiatives fare no better, with only 13% of major US state and local IT projects achieving success.
The broader landscape of business transformation research corroborates the Standish Group's findings. A synthesis of analyses from top-tier consulting firms highlights a pervasive crisis in digital transformation efforts.
| Research Organization | Year | Finding Regarding Transformation and IT Project Failure |
|---|---|---|
| Bain & Company | 2024 | 88% of business transformations fail to achieve their original ambitions. |
| Gartner | 2023 | 85% of AI projects fail, and 87% of R&D projects never reach production. |
| Ernst & Young (EY) | 2023 | Two-thirds of senior leaders experienced an underperforming digital transformation in the prior 5 years. |
| McKinsey & Company | 2020 | 17% of large IT projects go so badly they threaten the very existence of the company. |
| Boston Consulting Group (BCG) | 2020 | 70% of digital transformation efforts fall short of meeting targets. |
The financial consequences of these failures are catastrophic. The total cost of unsuccessful development projects among US firms alone is estimated to be $260 billion. Furthermore, the operational failures caused by poor quality software resulting from rushed or botched rewrites cost the economy an estimated $1.56 trillion. These numbers mirror what we see when organizations chase quick, AI-generated code without a plan, leading to what we call the AI technical debt problem.
The Hidden Risks of Total Replacement
The failure of the big bang rewrite is rarely due to a simple lack of coding ability among the engineering team. Rather, these projects fail because they become organizational and operational minefields. The complexity multiplies beyond human comprehension, leading to unforeseen roadblocks that derail budgets and timelines.
Loss of Organizational Knowledge: Legacy applications contain years, sometimes decades, of essential data and highly specific business processes. Critical business logic, boundary cases, unique regulatory tolerance rules, and specialized pricing algorithms are often embedded directly into the codebase without proper or updated documentation. A complete rewrite relies on developers attempting to reverse-engineer this logic. This process is time-intensive, mentally draining, and highly prone to errors. By rewriting, the organization risks abandoning undocumented robustness that took years of painful patches, bug fixes, and client feedback to achieve.
SEO Suicide and Market Presence Disruption: For consumer-facing platforms or B2B software systems, re-platforming often alters underlying URL structures, content delivery networks, and HTML footprints. Changing these foundational elements often tanks organic search engine rankings for three to six months, leading to a devastating drop in inbound lead generation and online revenue.
Data Integrity and Migration Hazards: Migrating ten to twenty years of complex order history, user permissions, and nested customer attributes from a legacy relational database to a new cloud-native architecture is rarely a seamless process. Data corruption during a big bang cutover can halt operations entirely.
The Feature Parity Trap: During a multi-year rewrite, business users expect the new system to possess every single feature the old system had—a concept known as "feature parity." However, organizations often forget about custom logic hacked into the system years ago to satisfy a specific, high-value client. This missing logic is inevitably discovered on launch day when a major client attempts a critical workflow and is blocked, leading to immediate crisis management and loss of trust.
The Moving Target Problem: A total rewrite typically spans 18 to 48 months, with some ambitious projects dragging on for up to five years. During this lengthy period, the business must continue to operate, the market evolves, and competitors release new features. By the time the massive new system is finally ready for launch, the original market requirements have shifted, rendering the supposedly "new" system functionally obsolete upon arrival.
Change Overload and Adoption Friction: Attempting a co-existence between a legacy application and a new one during a transition, or forcing a massive cutover, introduces monumental change overload. Introducing a new architecture, new UI paradigms, new workflows, and new environments all at once overwhelms employees and external users, severely hampering productivity and driving fierce resistance to adoption.
The Economics of Incremental Modernization
Recognizing the existential threats posed by the big bang rewrite, leading technology strategists advocate heavily for incremental modernization. This approach—often referred to as refactoring or phased upgrading—focuses on improving specific areas of a system while keeping the legacy core fully operational. It also aligns naturally with Agile methodology, where change is delivered in small, testable pieces instead of one risky leap.
The business case for incremental modernization is economically unassailable. Modernization extends the life and value of existing software with drastically lower risk profiles than total replacements.
Refactoring vs. Rewriting: A Financial Comparison
The financial metrics strongly favor the incremental approach. Refactoring and incrementally updating a system typically costs three to four times less than a complete rewrite. Because incremental modernization focuses on delivering small, observable releases that compound value, organizations achieve a positive Return on Investment (ROI) rapidly.
| Economic Metric | Incremental Modernization / Refactoring | Big Bang Rewrite |
|---|---|---|
| Relative Cost | ~33% of the cost of a full rewrite, preserving capital. | Massive upfront capital expenditure; frequently exceeds planned budgets. |
| ROI Timeline | Positive ROI realized 15 months earlier than rewrites. | ROI typically delayed 24 to 48 months, if realized at all. |
| Initial Value Delivery | Measurable improvements visible within weeks. | Zero business value realized until the final, distant cutover. |
| Financial Risk | Low; implementation is phased, maintaining existing revenue streams. | High; teams must maintain dual systems, draining operational expenditure. |
| Knowledge Retention | Preserves decades of documented and undocumented business logic. | High risk of losing critical institutional knowledge during transition. |
Incremental modernization provides organizations with agility. Each improvement is visible, measurable, and easily justified to stakeholders without requiring downtime or ballooning overhead. If market priorities shift mid-year, the engineering team has the flexibility to pause, accelerate, or redirect focus—a luxury entirely absent when locked into a multi-year rewrite contract. Costs remain clear, predictable, and justified at every step, turning system maintenance from a financial sinkhole into a foundation for ongoing resilience.
Enter the AI Sidecar Pattern
With 62% of organizations still relying on legacy systems, and the market fiercely demanding advanced AI capabilities to remain competitive, a bridge is required. The organization cannot afford to rewrite, but it also cannot afford to ignore the AI revolution.
The optimal solution to this paradox lies in Hybrid Modernization, specifically utilizing an architectural framework known as the AI Sidecar Pattern. This is the same pattern that underpins modern multi-agent solutions described in our work on the rise of action agents.
Defining the "Sidecar" Architecture
In modern software architecture, a sidecar is an independent, specialized software component that runs alongside a primary application, operating much like a physical sidecar attached to a motorcycle.
The primary application (the motorcycle) handles the core journey. In an enterprise context, this means the legacy monolith continues to process business transactions, manage shopping carts, calculate complex payroll taxes, or store logistics inventory. The sidecar handles auxiliary, highly modern tasks. While sidecars are traditionally used for network proxying or logging in Kubernetes environments, they are now the premier vehicle for introducing advanced artificial intelligence and natural language processing to older systems.
The AI Sidecar is built as a lightweight, highly modern microservice—frequently developed using contemporary languages and frameworks such as Python and FastAPI. It sits directly adjacent to the legacy monolith on the server or in the cloud cluster. It communicates with the old system via secure Application Programming Interfaces (APIs) or direct, read-only database connections. The sidecar extracts necessary data and processes it through modern intelligence engines, such as Large Language Models (LLMs) from OpenAI, Anthropic, or Google.
The Core Philosophy: Decoupling Innovation from Maintenance
The genius and safety of the AI Sidecar Pattern lie in its profound respect for the legacy monolith. Instead of attempting the impossible task of forcing a 15-year-old PHP, Visual Basic, or AS/400 application to natively execute complex machine learning algorithms and vector mathematics, the architecture leaves the legacy system completely alone.
The monolith is permitted to continue doing exactly what it was designed to do. It is stable, it is battle-tested, and its development costs have been fully amortized. The sidecar assumes 100% of the cognitive load associated with AI integration. It interacts by observing data, monitoring changes, and providing real-time insights to the user interface, without ever physically altering the underlying legacy codebase.
This architectural decoupling provides an ultimate safety net. If the AI module experiences an error, hallucinates, or requires a rapid update to integrate a newer generation of LLM, the core business engine is entirely unaffected. It continues processing orders, managing customer records, and handling transactions without a single millisecond of interruption.

Building the "Chat with Data" Experience
One of the most highly sought-after features by business executives and operational managers today is the ability to converse seamlessly with proprietary enterprise data. Users desire the capability to query financial histories, summarize complex legal contracts, analyze logistics pipelines, or generate ad-hoc reports utilizing simple natural language rather than complex SQL syntax. This transformative capability, universally referred to as "Chat with Data," is the primary, high-value use case for the AI Sidecar.
To achieve this capability without rewriting the underlying application, the sidecar leverages a sophisticated architectural framework known as Retrieval-Augmented Generation (RAG). RAG effectively bridges the gap between the static, generalized knowledge of a pre-trained LLM and the dynamic, highly specific, and private data living inside an organization's legacy SQL Server, PostgreSQL database, or mainframe.
The RAG Pipeline for Legacy Integration
Implementing RAG on top of legacy architecture is not a plug-and-play endeavor; it involves a precise sequence of data engineering steps managed entirely by the sidecar microservice.
1. Data Auditing and Secure Connectors: Before any AI implementation begins, data engineering experts must audit the legacy data sources to understand the existing data debt. Once mapped, the sidecar establishes secure data connectors to the legacy database. Crucially, this is architected as a "one-way mirror." The AI sidecar is granted strictly read-only access. This air-gap prevents any possibility of an AI hallucination or a rogue generated query from accidentally overwriting, dropping, or corrupting the core transactional database tables.
2. Data Extraction and AI Adapters: Legacy systems frequently store vast amounts of critical business knowledge in unstructured formats, such as TEXT or LONGTEXT columns, which were originally designed merely for storage rather than semantic search. To make this usable, AI adapters are deployed within the sidecar to convert legacy outputs—including flat files, messy database dumps, and PDFs—into structured, machine-readable formats. For example, in the logistics industry, these adapters can read unstructured shipping manifests and automatically extract key details like container ID, cargo type, port of origin, and delivery timelines.
3. The Embedding Pipeline (Chunking): Large enterprise datasets cannot be fed entirely into an LLM's limited context window. The sidecar executes a critical processing step called "chunking." This involves breaking large documents and massive data rows into smaller, semantically coherent sections, typically ranging from 500 to 1,000 tokens. This ensures the AI model retains focus and processes information accurately without losing contextual threads.
4. Vectorization and Semantic Search: These newly created chunks are then processed through an embedding model, which translates human text into high-dimensional mathematical vectors. These vectors are stored in an independent, highly optimized Vector Database, such as FAISS, Pinecone, ChromaDB, or Milvus. This Vector Database acts as the dedicated memory bank for the sidecar application, enabling hyper-fast semantic search based on the actual meaning of the data, rather than relying on brittle, exact keyword matching.
5. Intelligent Retrieval and Generation: When a user interacts with the modernized interface—typing a prompt such as, "Summarize the major trends in technology contracts over the last 6 months"—the sidecar converts this natural language query into a vector. It searches the Vector Database for the most mathematically and semantically similar data chunks. Finally, the sidecar packages the user's original query alongside the retrieved legacy data (acting as ground-truth context) and sends this combined package to the LLM. The LLM then generates a natural, highly accurate response based exclusively on the provided enterprise data, effectively eliminating hallucinations.
Text-to-SQL: Direct Database Interaction
While semantic search handles unstructured text exceptionally well, business operations frequently demand structured computational answers. Queries like "How many projects over $1M were approved from 2023 to 2025?" require hard mathematics, not semantic summaries.
For these scenarios, advanced sidecar applications deploy sophisticated Text-to-SQL agents. Instead of retrieving text chunks, the LLM agent is provided with the schema (the structural blueprint) of the legacy database. When a user asks a question, the agent analyzes the natural language request, cross-references the legacy schema, and autonomously generates a standard, highly optimized SQL query.
The sidecar then safely executes this generated SQL query against the read-only replica of the legacy database, retrieves the hard numerical data, and translates the structured output back into a natural language summary for the user. This allows non-technical stakeholders to query twenty-year-old relational databases as easily as texting a colleague, completely bypassing complex query builders, outdated reporting interfaces, or the need to wait weeks for the data analytics team to build a custom dashboard. This is also where an SQL-first AI reporting strategy becomes critical, rather than relying on vector search alone for numeric accuracy.
Orchestration Frameworks: LangChain vs. LlamaIndex
Engineers building these complex AI sidecars do not build the pipelines from scratch; they rely on specialized, open-source orchestration frameworks. The two dominant frameworks in the AI engineering landscape are LangChain and LlamaIndex, each serving distinct architectural patterns and use cases. Understanding the difference is critical for successful sidecar deployment.
| Feature / Capability | LangChain Focus | LlamaIndex Focus |
|---|---|---|
| Primary Architectural Strength | Agent orchestration, complex workflows, and flexible control flow. | Fast, highly accurate data retrieval over massive datasets with structured indexing. |
| Core Design Philosophy | Workflow-driven; designed to chain multiple steps and tools together. | Retrieval-first; optimized deeply for search and data ingestion. |
| Ideal Sidecar Use Case | Multi-agent AI systems where the AI must take actions, such as querying a database, parsing results, and calling a third-party CRM API. | Sidecars focused strictly on "Chat with Data" across vast repositories of enterprise documents and unstructured text. |
| Data Handling Approach | Generalist; integrates retrieval algorithms alongside memory management and tool calling. | Specialist; provides advanced, specialized index structures to make unstructured data highly accessible to LLMs. |
If the legacy application is a massive repository of unstructured data—such as a legacy legal contract management system or a sprawling enterprise intranet—LlamaIndex provides superior, out-of-the-box tools for connecting to that data, chunking it efficiently, and executing rapid semantic searches. Conversely, if the sidecar needs to perform multi-step actions and complex logic—such as a customer service bot that must read a legacy database, check inventory levels, and then update a ticketing system—LangChain's robust agent orchestration is the required framework. In practice, these orchestration tools sit inside a broader AI-native SDLC that governs how prompts, agents, and code move safely into production.
The Strangler Fig Pattern: The Long-Term Vision
The AI Sidecar Pattern is highly effective for immediate feature augmentation, providing rapid ROI. However, it also serves as the critical first step in a broader, highly strategic, long-term modernization methodology known in software engineering as the Strangler Fig Pattern.
Named after the biological strangler fig vine that gradually envelops, utilizes, and eventually replaces its host tree, the Strangler Fig Pattern is a proven strategy for incrementally refactoring a monolithic application into a modern microservices architecture over time. Rather than rebuilding everything simultaneously, engineering teams carve out specific pieces of functionality one by one.
The Mechanics of Gradual Replacement
To execute this, a facade or proxy layer is introduced between the user interface and the backend systems. When a user or client application requests a feature, the proxy intercepts and routes the request.
If the requested feature has not yet been modernized, the proxy routes the traffic directly to the legacy system. However, if the feature has been rebuilt—such as a new AI-powered search sidecar—the proxy routes the traffic to the new microservice.
Over a multi-year horizon, as more sidecars and modern microservices are built to handle core functionality (e.g., a modern billing sidecar, a new inventory sidecar), the legacy monolith handles fewer and fewer requests. The legacy system is gradually "strangled" out of existence. Eventually, it handles no traffic at all and is safely decommissioned.
This methodology achieves a full, modern system rewrite without the organization ever experiencing a dangerous, unified cutover event.
Ensuring Regulatory and Compliance Continuity
For organizations operating in highly regulated industries, the Strangler Fig approach is not just a technical preference; it is a compliance necessity. Healthcare systems managing strict HIPAA requirements, or financial services institutions required to maintain unbroken audit trails, view system downtime as unacceptable. The technical challenge of migration is often eclipsed by the challenge of maintaining availability during the modernization process.
Because the Strangler Fig pattern allows the legacy application to continue functioning perfectly while the modernization effort occurs in parallel, it guarantees 100% operational continuity and compliance throughout the entire transformation lifecycle. Teams develop expertise gradually, learning modern technologies through hands-on experience with manageable, isolated scopes, building lasting organizational capability without risking the core business. Over time, these teams can also introduce proactive AI agents that monitor systems and flag issues before they become outages.
Executive Impact: The View from the C-Suite
The decision to adopt an AI Sidecar via incremental modernization resonates differently across the corporate leadership team, solving highly distinct pain points for each executive persona.
The Visionary CTO
For the Chief Technology Officer, the primary directive is integrating emerging technology while strictly mitigating systemic risk. The big bang rewrite is perceived accurately as an architectural minefield characterized by undocumented legacy dependencies.
The sidecar pattern allows the CTO to adopt cutting-edge infrastructure—such as vector databases, LLM orchestration (LangChain/LlamaIndex), and intelligent agentic workflows—without threatening the stability of the core transactional engine. It establishes a clear, phased maturity model, paving the way for a methodical Strangler Fig migration. This approach prevents developer burnout, protects delivery schedules, and perfectly aligns with modern, DevOps efficiency practices.
The Strategic CFO
Financial leaders abhor the unpredictable capital expenditure associated with multi-year IT overhauls. Large-scale rewrites routinely run wildly over budget, draining resources with no immediate return. Incremental modernization is a financial revelation; it transforms unpredictable capital expenses into clear, predictable operational expenditures.
By delivering functional AI features in a matter of weeks rather than years, the business dramatically accelerates its time-to-value. The organization achieves positive ROI 15 months faster than with a rewrite, all while preserving the millions of dollars already invested in the legacy system's core business logic. This mindset mirrors the CFO shift toward building, not buying, with AI-augmented development.
The Driven Head of Sales
Sales leadership operates on aggressive quarterly timelines and demands immediate competitive advantages to win deals. Waiting three to five years for a new CRM or inventory management system to support AI capabilities is entirely unacceptable.
The AI Sidecar can rapidly wrap intelligence around legacy architecture. By implementing a Text-to-SQL agent via a sidecar, the sales team can immediately begin querying legacy inventory or customer databases using natural language from their mobile devices. This drastically reduces the friction in retrieving client data, eliminates reliance on slow reporting teams, and directly improves deal velocity.
The Innovative Marketing Director
Marketing teams require ultimate agility to adapt to shifting digital landscapes and consumer expectations. When core systems are frozen due to a pending, multi-year rewrite, the deployment of new marketing features is entirely blocked.
An AI sidecar allows for the rapid deployment of advanced, revenue-generating customer features entirely independent of the monolithic release cycle. Marketing can launch intelligent product recommendations, semantic catalog searches that understand deep context and user typos, and dynamic content generation tools, drastically improving user experience and conversion rates while the IT team continues to manage the legacy backend.
Industry Applications of AI Sidecars
The versatility of the AI Sidecar pattern allows it to solve specific, highly complex legacy challenges across a multitude of B2B industries.
- Financial Services: Banks and mortgage lenders sit on decades of unstructured loan applications and risk assessments. Sidecars enable compliance officers to query decades of PDF documents using natural language to ensure adherence to new regulatory frameworks instantly, without altering the core AS/400 banking systems.
- Healthcare: Hospitals utilizing aging electronic health record (EHR) systems can deploy sidecars to summarize patient histories or cross-reference symptoms with medical journals via RAG, providing doctors with instant, secure insights while maintaining HIPAA compliance on the legacy database.
- Education (LMS): Legacy Learning Management Systems can be augmented with sidecar-driven AI tutors. The sidecar reads the specific curriculum and student performance data from the old LMS database and provides personalized, real-time feedback to students without requiring a massive LMS platform migration.
- Real Estate & Mortgage: Brokers can utilize text-to-SQL sidecars to query complex, aging Multiple Listing Service (MLS) databases. Instead of building complex filtering queries, a broker can simply ask, "Find all commercial properties in the downtown sector zoned for mixed-use that dropped in price over the last six months," receiving instant, structured data.
- Logistics & Telecom: Massive, rigid databases tracking global supply chains or network nodes can be analyzed for anomalies. AI adapters ingest flat files and complex manifests, converting them to structured data to drive automated insights regarding network outages or shipping delays.
Partnering for Incremental Success
Executing an incremental modernization strategy utilizing AI sidecars requires a highly sophisticated blend of legacy system comprehension and cutting-edge cloud-native expertise. The architecture demands precise API construction, secure data proxying, advanced RAG pipeline tuning, and expert-level containerization.
For organizations seeking to execute this hybrid modernization, specialized engineering partners become critical. Baytech Consulting specializes in custom software development and enterprise application management, providing organizations with a Tailored Tech Advantage. Rather than forcing clients into generic, off-the-shelf SaaS platforms that necessitate highly disruptive, massive data migrations, engineering teams custom-craft solutions that wrap cutting-edge intelligence tightly around existing, proven business assets.
Operating with a philosophy of Rapid Agile Deployment, complex modernization challenges are broken down into adaptable, transparent, and timely sprint cycles. Utilizing enterprise-grade infrastructure and a robust tech stack—including Kubernetes and Docker for perfectly isolating sidecar microservices from the monolith, Harvester HCI and Rancher for advanced cluster management, alongside deep, historical expertise in managing relational databases like Postgres and SQL Server—organizations can safely run legacy and modern systems in parallel. Leveraging secure environments like Azure DevOps On-Prem and OVHCloud servers, this methodology ensures on-time delivery, pristine communication, and the ultimate transformation of legacy technical debt into a highly strategic, AI-powered asset. This is the essence of our AI-powered and integrating AI service offerings: designed to bolt intelligence onto what already works.
Conclusion
The statistical and economic evidence surrounding software transformation is incontrovertible: attempting to rewrite a legacy software system from scratch to add modern capabilities is an exercise fraught with excessive cost, severe operational delay, and an unacceptably high probability of outright failure. Technology moves far too rapidly, and daily business operations are far too critical, to ground an enterprise's digital fleet for a multi-year rebuild.
The AI Sidecar pattern represents the optimal strategic path forward for the modern enterprise. By strictly decoupling innovation from maintenance, businesses can preserve the battle-tested reliability, historical data, and complex business logic of their core systems. Simultaneously, they can deploy the transformative power of Large Language Models and Retrieval-Augmented Generation to users and internal teams.
This incremental, sidecar-driven approach delivers immediate Return on Investment, strictly minimizes operational risk, and provides the organization with modern, intelligent features exactly where they are needed most. The executive question is no longer whether to adopt AI, but how to deploy it intelligently and safely. By surrounding the legacy core with smart, specialized microservices, an organization secures its digital future without sacrificing its operational present. As you architect this future, it is also vital to deploy an AI firewall layer to guard against prompt injection and data leakage between sidecars and core systems.
Frequently Asked Questions
Do I need to rewrite my entire app to add AI? Absolutely not. Statistical data shows that complete system rewrites fail or face severe challenges up to 74% of the time. Instead of taking on the massive risk, cost, and delay of rewriting, you can leave your core application completely intact. By using an API-led approach to connect your existing systems to modern AI tools, you save significant time, preserve your capital, and eliminate operational risk.
What is a "Sidecar" application? A sidecar is a lightweight, independent piece of modern software (a microservice) that runs right next to your main legacy application. Think of it as a highly intelligent digital assistant. While your old software continues handling the heavy, traditional tasks like processing transactions and storing records, the sidecar handles the new, complex tasks—like understanding natural language and communicating with AI models—without ever modifying or breaking your original code.
How can I add AI features quickly to an old app? By leveraging a combination of the Sidecar Pattern and Retrieval-Augmented Generation (RAG). You extract specific, necessary data from your old database, process it within the sidecar, and store it in a modern Vector Database. This architecture allows you to deploy advanced features like "Chat with Data" in a matter of weeks, providing modern search and conversational querying capabilities over decades-old infrastructure safely and efficiently. For many teams, pairing this with a 90/10 human-in-the-loop trust architecture is the best way to keep quality and compliance high as AI usage grows.
Further Reading
- https://medium.com/dhiwise/why-do-70-of-projects-fail-in-it-6f1991637835
- https://wearenotch.com/blog/refactoring-vs-rewriting-legacy-applications/
- Application Modernization Patterns
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.