
Shadow AI Risks in 2026 and Strategies for Secure Adoption
April 16, 2026 / Bryan Reynolds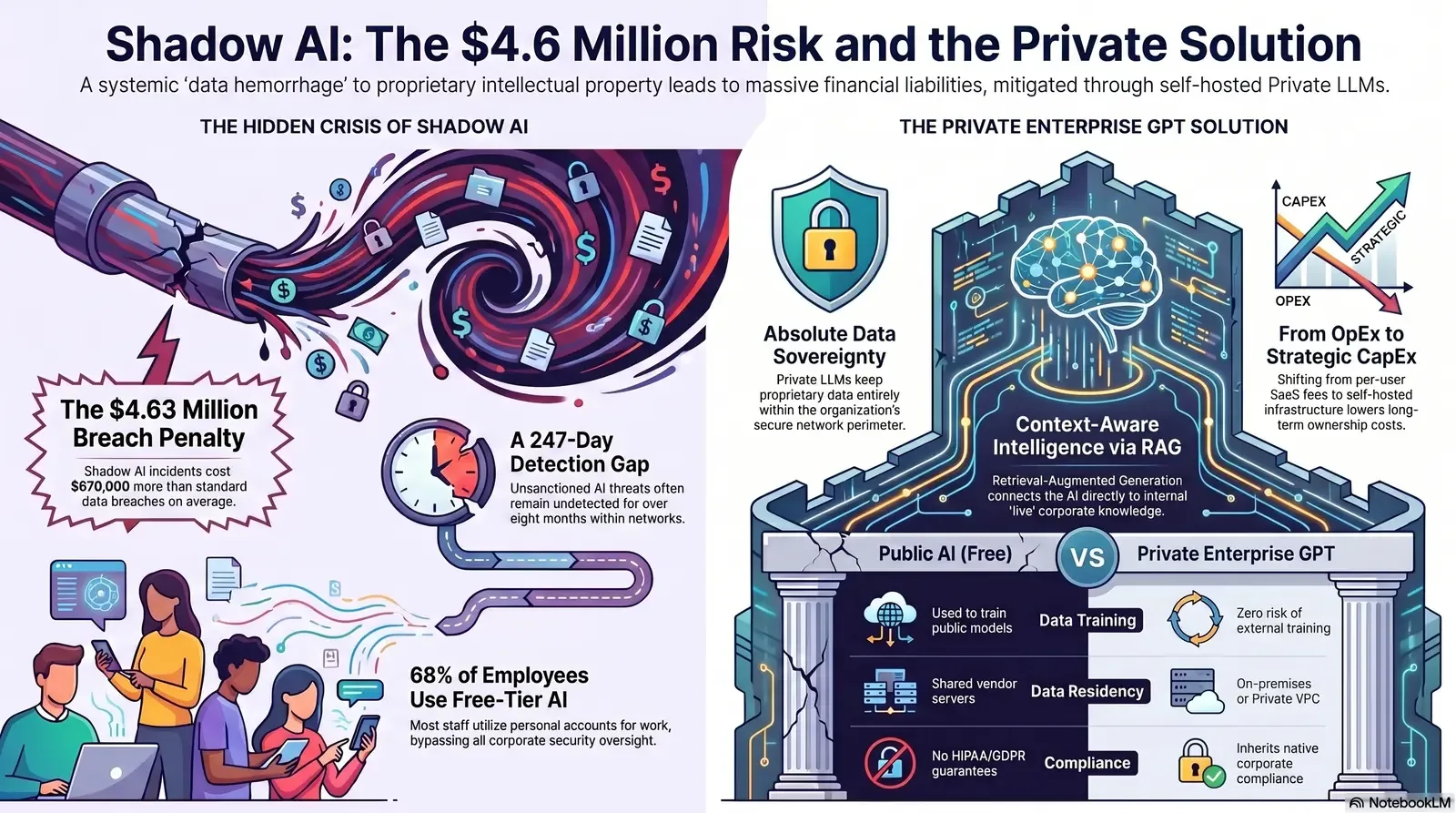
The Hidden Cost of Shadow AI: Navigating Security, Data Privacy, and the Shift to Private Enterprise GPTs
The rapid democratization of generative artificial intelligence has fundamentally altered the operational velocity of the modern business landscape. Employees across every organizational department—from software engineering and digital marketing to financial analytics and human resources—are leveraging advanced large language models (LLMs) to accelerate workflows, synthesize complex datasets, and generate novel insights. However, this decentralized, grassroots adoption has vastly outpaced formal corporate information technology (IT) governance, giving rise to a pervasive, insidious, and immensely costly security vulnerability known as "Shadow AI."
As digital transformation initiatives accelerate into 2026, corporate executives—specifically visionary Chief Technology Officers (CTOs), strategic Chief Financial Officers (CFOs), driven Heads of Sales, and innovative Marketing Directors—face an urgent, high-stakes dilemma. The mandate to drive workforce productivity and maintain competitive parity demands the deployment of advanced artificial intelligence capabilities. Conversely, the unrestricted use of public AI platforms exposes organizations to catastrophic data leaks, intellectual property theft, and severe regulatory penalties.
The core questions dominating boardroom discussions across the globe are stark and unambiguous: Is it inherently safe for employees to utilize consumer-grade public applications like ChatGPT? What precise mechanisms make Shadow AI such a critical threat to enterprise data security? Most importantly, how can modern B2B organizations provide their workforce with state-of-the-art AI tools without compromising their proprietary data and intellectual property?
This comprehensive research report explores the escalating risks associated with unsanctioned generative AI usage, quantifies the severe financial and reputational impacts of corporate data leakage, and details the strategic shift toward self-hosted, Private Enterprise GPT solutions. By examining the underlying architectures that secure these private models, the following analysis provides a definitive roadmap for safely integrating artificial intelligence into the corporate environment.
The Anatomy of Shadow AI: A Crisis of Convenience
The phenomenon of Shadow IT—where employees adopt unapproved software applications to bypass perceived bureaucratic bottlenecks—is a well-documented challenge for cybersecurity professionals. However, the emergence of Shadow AI introduces a vastly more complex, dynamic threat vector.
Shadow AI refers to the unauthorized, unmonitored use of generative artificial intelligence tools within a corporate network or by employees handling corporate data.
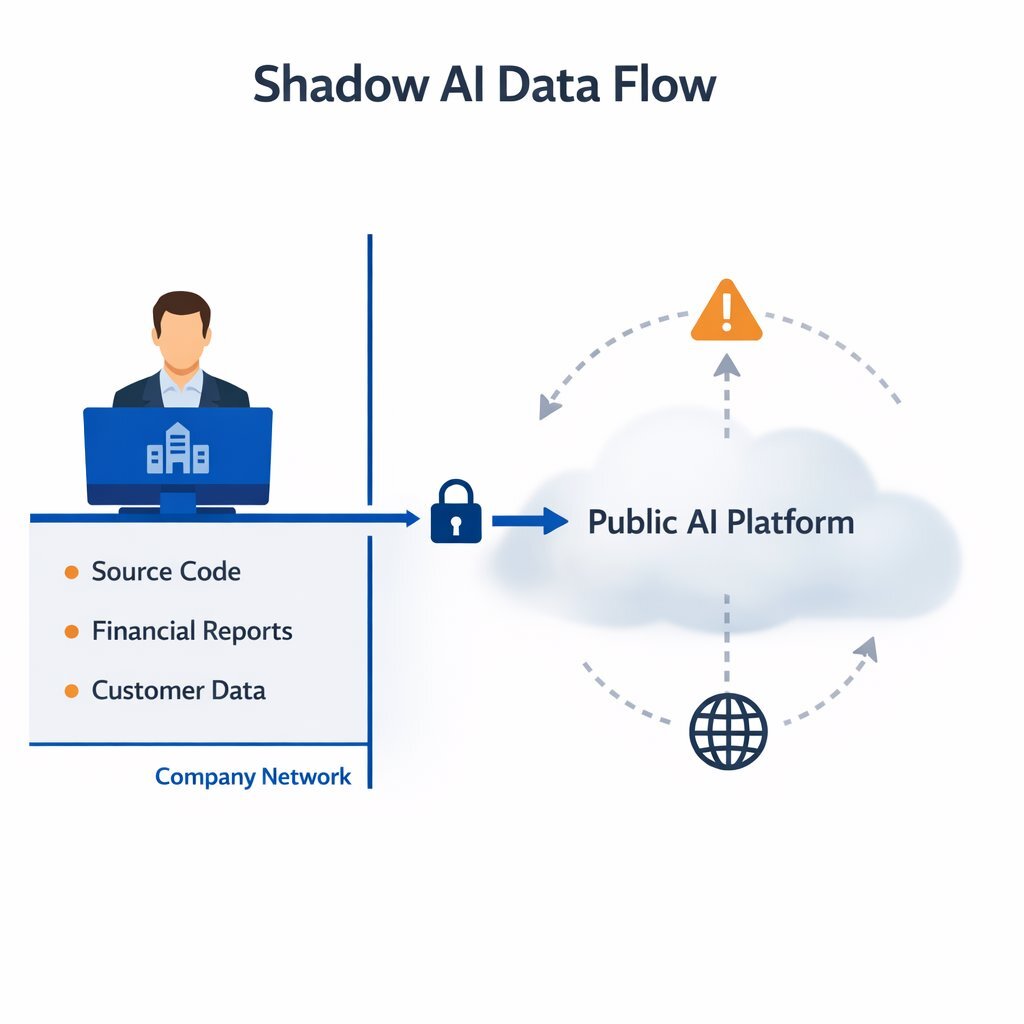
Unlike traditional unsanctioned applications, which might simply store a calendar event or a note, generative AI models are fundamentally designed to ingest, analyze, and mathematically learn from the data they process. When an employee pastes a block of proprietary code to find a software bug, uploads a client spreadsheet for rapid financial analysis, or drafts a highly sensitive marketing press release using a public AI model, that corporate data leaves the organization's secure perimeter. It enters the infrastructure of a third-party technology vendor, outside the reach of the company's data loss prevention (DLP) tools.
The Staggering Scale of Unauthorized Adoption
The scale of Shadow AI adoption is staggering, driven entirely by the human desire for increased workplace efficiency and productivity. The Menlo Security 2025 Report: How AI is Shaping the Modern Workspace recorded an astonishing 10.53 billion visits to generative AI sites in January 2025 alone, representing a massive 50% surge from the 7 billion visits recorded in February of the previous year.
This data reveals a critical, systemic disconnect between official corporate security policies and daily employee behavior. Quantitative research indicates that 68% of employees actively use free-tier AI tools—such as the standard, public versions of ChatGPT, Claude, or Gemini—via their personal accounts, operating completely outside the purview of corporate IT oversight. Furthermore, a separate survey found that 44% of employees openly admit to using artificial intelligence at work in ways that explicitly violate established company policies.
This widespread behavioral shift translates into massive, continuous data exfiltration. In a single month, security platforms logged 155,005 copy attempts and 313,120 paste attempts into unapproved generative AI interfaces across monitored networks. This volume demonstrates how users—often entirely unaware of the underlying technical risks—are inadvertently exposing sensitive company information while simply attempting to complete their routine tasks more efficiently. The normalization of this behavior means that data leakage is no longer an isolated incident but a continuous, systemic hemorrhage of intellectual property.
The Financial Premium of AI-Driven Data Breaches
The consequences of Shadow AI extend far beyond hypothetical privacy concerns or abstract risk models; they represent a severe, quantifiable financial liability. According to the IBM 2025 Cost of a Data Breach Report, incidents involving Shadow AI significantly inflate the financial impact of a security failure.
Data breaches involving unsanctioned artificial intelligence cost organizations an average of $4.63 million per incident. These specific incidents carry a staggering $670,000 cost premium compared to standard data breaches, which average $3.96 million. The frequency of these events is also rising dramatically, with Shadow AI incidents now accounting for 20% of all recorded data breaches—surpassing the 13% attributed to sanctioned, albeit poorly configured, internal AI systems.
The inflated cost of Shadow AI breaches is driven by several compounding operational factors. Foremost is the extended timeline required to identify and contain the threat. Shadow AI incidents take an average of 247 days to detect, leaving sensitive data exposed for over eight months. Furthermore, credential exposure through AI assistants—such as usernames, API keys, and passwords shared to "streamline workflows"—creates a median remediation time of 94 days. Because employees use these tools indiscriminately across various devices and networks, 62% of Shadow AI incidents affect data stored across multiple environments and public clouds, dramatically complicating forensic and remediation efforts.
The Unintentional Threat Actor
It is crucial for corporate leadership to understand that the employees driving Shadow AI are rarely malicious insiders or corporate saboteurs. They are highly motivated professionals seeking to optimize their output in an increasingly demanding business environment.
Consider the reality of the modern digital workflow: A developer at a fast-growing tech startup pastes proprietary source code into a public chatbot to expedite the debugging process. A healthcare administrator queries a free-tier language model to rapidly format and summarize de-identified (but still highly sensitive) patient records. A financial analyst uploads a quarterly projections spreadsheet containing client account numbers to quickly generate an executive summary report.
In every single instance, the employee views the artificial intelligence simply as a utility—a highly sophisticated calculator. However, the reality of public generative AI architecture dictates that the moment proprietary information is typed into a free or standard AI platform, that data effectively leaves the organization's control. It is transmitted to third-party servers, where it may be retained indefinitely and utilized to train future iterations of the vendor's commercial models. Consequently, a company's closely guarded trade secrets, unreleased financial data, and sensitive client information become part of a public algorithmic knowledge base, permanently compromising the organization's intellectual property.
Industry-Specific Vulnerabilities: The Ripple Effects of AI Data Exposures
The ramifications of Shadow AI are not distributed equally across the economy; different sectors face unique, catastrophic risks based entirely on the nature of the data they process and the regulatory frameworks governing their operations. For B2B enterprises operating in heavily regulated or highly competitive markets, the unauthorized use of generative AI represents an existential threat to client trust, market valuation, and regulatory compliance.
Advertising, Marketing, and Media: The IP Hemorrhage
In the hyper-competitive sectors of advertising, marketing, and digital media, intellectual property and timing are the primary currencies. Agencies and marketing departments handle pre-release product specifications, confidential rebranding strategies, highly targeted consumer demographic data, and sensitive corporate communications. Innovative Marketing Directors are under constant pressure to generate content faster and more efficiently, often turning to AI-powered automation to keep up with demand. That makes it essential to distinguish between brittle, one-off hacks and well-architected AI automation that actually works safely inside enterprise guardrails.
Analysis of network traffic indicates that employees in the media and entertainment sectors copy 261.2% more data from AI tools than they put into them, utilizing these platforms heavily for mass content generation, ideation, and strategy formulation. However, a broader analysis of generative AI usage reveals a darker reality: 8.5% of all employee prompts submitted to LLMs include highly sensitive corporate data. Within those sensitive prompts, an alarming 46% involve confidential customer information, and 15% contain legal or financial details.
If a marketing executive uploads a draft of an unannounced product launch into a public AI to generate ad copy variations, that product information is ingested by the model. Unintentional exposure of this data not only breaches strict non-disclosure agreements (NDAs) with high-value clients but can also ruin multi-million-dollar product launches if the model inadvertently leaks the concepts, branding, or pricing strategies to a competitor querying the same system.
Software Development, High-Tech, and Gaming: The Source Code Crisis
For technology firms, SaaS providers, and video game development studios, proprietary source code is the ultimate, foundational asset. The integration of AI coding assistants has skyrocketed among engineering teams, promising massive gains in developer velocity. Visionary CTOs are eager to capitalize on this efficiency and to measure its impact using modern engineering metrics rather than vanity activity stats. That shift requires a thoughtful framework for developer productivity metrics that actually matter, especially when AI is writing or reviewing large portions of the codebase.
Rigorous research demonstrates that 62% of AI-generated code solutions contain design flaws or known security vulnerabilities, even when developers utilize the latest, most advanced foundational models. AI coding assistants lack an inherent understanding of an organization's specific risk model, internal security standards, architectural patterns, or custom threat landscape. When developers rely on public AI, they risk introducing systemic logic flaws, missing access controls, and inconsistent patterns that erode trust and security over time.
More alarmingly, when developers paste proprietary game engine architecture, advanced algorithmic trading logic, or core SaaS application code into a public LLM to seek optimization advice, that source code is exfiltrated. Source code leaks via public AI are highly damaging; they expose hardcoded secrets, database schemas, cryptographic keys, and proprietary logic that malicious actors can easily exploit, bypassing the need to search for complex zero-day vulnerabilities in compiled programs. Left unchecked, this kind of careless usage turns AI into a factory for hidden bugs and long-term technical risk, creating exactly the kind of AI-driven technical debt described in AI vs. Debt: Stop Your Code from Becoming a Time Bomb.
Real Estate, Finance, and Mortgage Lending: Compliance and Hallucinations
The housing finance, real estate, and broader financial services industries manage vast repositories of personally identifiable information (PII), financial assets, loan amounts, and transactional records. The regulatory environment governing this data—including the Gramm-Leach-Bliley Act (GLBA) in the United States, the California Consumer Privacy Act (CCPA), and various international standards—imposes strict financial penalties and operational sanctions for unauthorized data disclosure.
The history of data breaches in this sector highlights the severity of the risk. For instance, the American Financial Corporation breach exposed 885 million mortgage-related records due to severe database misconfigurations. The introduction of Shadow AI multiplies this data exposure risk exponentially. Financial employees utilizing unapproved AI tools to underwrite loans, draft client communications, process applications, or analyze market trends frequently input sensitive PII into public chats.
If a mortgage broker pastes a client's comprehensive financial history into a public chatbot to generate a personalized loan summary or risk profile, they have committed a severe compliance violation. Unauthorized disclosure of PII to third-party AI servers can lead to massive regulatory fines, mandated consumer notifications, legal action, and catastrophic reputational damage that destroys consumer trust.
Furthermore, Strategic CFOs face the unique, high-consequence threat of AI "hallucinations." This occurs when an AI generates plausible but entirely incorrect financial advice, numerical computations, or market analyses. If a finance team relies on hallucinated data generated by an unvetted model to make investment decisions, set pricing, or report earnings, the resulting highly visible financial errors can lead to severe reputational damage and loss of investor trust. It also amplifies the hidden “token tax” of AI—where poor prompt design and unmanaged usage drive up API bills without delivering reliable value, a challenge explored in The Token Tax: Stop Paying More Than You Should for LLMs.
Education (LMS), Telecom, and Healthcare: Privacy Imperatives
Industries bound by strict confidentiality mandates—such as healthcare (HIPAA), education (FERPA), and telecommunications—cannot tolerate the data leakage inherent in public AI models. Healthcare administrators attempting to summarize patient diagnostics, or education professionals using AI to analyze student performance data within a Learning Management System (LMS), are inadvertently violating federal privacy laws if they utilize consumer-tier tools. Public LLMs are not HIPAA-compliant, and OpenAI explicitly warns against sharing sensitive data in their free or Plus versions. Entrusting Protected Health Information (PHI) to a system without a Business Associate Agreement (BAA) is a profound failure of corporate governance.
The ChatGPT Conundrum: Comparing Public, SaaS Enterprise, and Private AI
To successfully mitigate the severe risks of Shadow AI, organizations must provide a compelling, highly secure alternative that satisfies the workforce's insatiable demand for intelligent automation. Banning AI entirely is a futile strategy that merely drives the behavior further underground. The marketplace currently offers several tiers of generative AI access, ranging from consumer-grade public models to highly secure, bespoke private deployments. Understanding the profound architectural and legal distinctions between these tiers is critical for enterprise leadership.
The Consumer Tier: Free, Plus, and Pro Models
The standard, consumer-facing versions of large language models (such as ChatGPT Free, ChatGPT Plus, and ChatGPT Pro) are designed specifically for individual users and hobbyists. They provide standard security features sufficient for casual inquiries but fundamentally lack the rigorous compliance guarantees, data privacy frameworks, and administrative controls required by B2B enterprises.
The critical, unresolvable vulnerability in the consumer tier is data usage and retention. By default, these platforms frequently retain user prompts, uploaded files, and generated outputs to continuously train and refine their underlying models. While advanced users can sometimes navigate complex account settings to opt out of data training, the baseline architecture is simply not designed for corporate data sovereignty. In a corporate environment, a staggering 73.8% of standard ChatGPT accounts are non-corporate, completely lacking security oversight or enterprise administration. Entrusting intellectual property, unreleased financial data, or PII to a consumer-grade platform is functionally equivalent to publishing that data on the open internet.
The SaaS Enterprise Tier: ChatGPT Enterprise and Copilot
Recognizing the immense enterprise demand for secure generative AI, providers offer commercial Software-as-a-Service (SaaS) tiers, such as ChatGPT Enterprise, Microsoft Copilot, and Google Gemini for Business. These enterprise solutions elevate security significantly above the consumer models, addressing many fundamental corporate concerns.
From a data privacy perspective, solutions like ChatGPT Enterprise enforce full privacy by default; user prompts and model outputs are never used to train OpenAI's foundational models. The enterprise tier provides critical administrative controls necessary for IT governance, including SAML Single Sign-On (SSO), Role-Based Access Control (RBAC), domain verification, and centralized admin dashboards to manage user provisioning and monitor usage analytics. Furthermore, organizations can configure strict data retention policies, dictating exactly how long prompts are stored on the provider's servers, or opting for zero retention.
Despite these robust, enterprise-grade protections, the SaaS Enterprise tier remains a multi-tenant cloud solution. The organization must still place implicit trust in the third-party provider's infrastructure, security practices, and personnel. Corporate data must still leave the corporate perimeter to be processed on external servers. For highly regulated industries dealing with strict data residency laws, defense contracts, or extreme intellectual property sensitivities, the SaaS Enterprise model may still present unacceptable compliance hurdles. These protections still rely entirely on trusting the vendor's Data Processing Agreements (DPAs) and Business Associate Agreements (BAAs).
Furthermore, SaaS AI models are inherently generalized. While they offer high performance across broad natural language tasks, they are not deeply integrated into an organization's proprietary databases or live operational data without significant, complex API engineering. Their knowledge remains largely static, limited to their pre-training data and whatever limited files a user manually uploads.
Detailed Feature Comparison
To clarify the operational differences, the following table outlines the capabilities and security postures of the primary AI deployment models available to modern enterprises.
| Feature Category | Public AI (Free/Plus) | Enterprise SaaS AI | Private Enterprise GPT (Self-Hosted) |
|---|---|---|---|
| Data Training Risk | Prompts are used to train public models by default. | Prompts are explicitly excluded from model training. | Total control; zero technical risk of external training. |
| Data Residency | Hosted on public, shared vendor servers. | Hosted on the vendor's secure enterprise cloud. | Hosted securely on-premises or within a private VPC. |
| Compliance Posture | No guarantees; explicit warnings against PII/HIPAA use. | SOC 2, DPAs, and BAAs are generally available. | Inherits the organization's native compliance (HIPAA, GDPR). |
| Access Control | Individual, unmanaged personal accounts. | SAML SSO, RBAC, and Centralized Admin Console. | Deep, native integration with internal Active Directory/IAM. |
| Contextual Customization | General knowledge; highly limited file upload capacity. | Custom GPTs with shared workspace access. | Fine-tuned and directly connected to proprietary corporate workflows. |
The Strategic Imperative of the Private Enterprise GPT
For B2B organizations seeking the absolute highest tier of security, guaranteed data sovereignty, and deeply customized artificial intelligence, the optimal strategic solution is the deployment of a Private Enterprise GPT (often referred to as a Private LLM).
A Private Enterprise GPT is a powerful large language model deployed entirely within infrastructure wholly controlled by the organization—whether that is a secure on-premises data center, dedicated bare-metal servers, or an isolated, highly restricted cloud environment (VPC). In this architecture, the corporate data never, under any circumstances, leaves the defined trust boundaries established by the organization's IT security team.
Uncompromising Intellectual Property Protection
The primary, non-negotiable driver for adopting a Private Enterprise GPT is competitive intellectual property protection. Knowledge-intensive industries—such as algorithmic trading firms, pharmaceutical research laboratories, and advanced software engineering organizations—cannot risk exposing their core IP to external cloud providers, regardless of the contractual assurances provided.
With a private deployment, the organization retains total, end-to-end ownership and control over the inference process. Because the AI model operates entirely within an air-gapped or highly restricted network perimeter, it inherently satisfies the most stringent regulatory requirements, including HIPAA for healthcare, GDPR for European data residency, and defense-grade compliance standards. Private deployments empower organizations to enforce custom compliance rules, strict data minimization protocols, and regional access controls exactly on their own terms, completely bypassing the need to trust a third-party vendor's infrastructure or evolving privacy policies.
Deep Customization and Contextual Relevance via RAG
A significant limitation of general SaaS AI models is their reliance on publicly available pre-training data, which is often months or years out of date and completely ignorant of internal company policies, highly specific product specifications, or legacy systems. For an AI to be genuinely useful in a complex business environment, it must be plugged into the organization's live sources of truth.
Private Enterprise GPTs overcome this limitation through advanced customization techniques, most notably Retrieval-Augmented Generation (RAG) and domain-specific fine-tuning. By connecting the private LLM directly to internal data repositories, the model acts as an intelligent, context-aware synthesis engine.
When a Driven Head of Sales queries a Private Enterprise GPT about a specific client's history or a complex pricing matrix, the model retrieves the exact, real-time data from the internal Customer Relationship Management (CRM) system, synthesizes it securely, and generates an accurate, highly relevant response without hallucinating or exposing the query to the outside world. This level of continuous contextual memory and complex conversational capability is absolutely essential for high-stakes enterprise support, dynamic marketing ideation, and strategic advisory scenarios. For many organizations that still rely on aging, hard-to-change platforms, the fastest path to this kind of intelligence is an incremental AI sidecar pattern that adds “chat with data” capabilities without risking a full legacy rewrite.
Total Cost of Ownership (TCO) and ROI at Scale
The financial calculus between licensing a SaaS Enterprise AI and building a Private LLM requires a long-term, strategic view from the CFO. SaaS AI solutions operate on a perpetual per-user, monthly subscription model. At approximately $60 per user per month for premium enterprise tiers, outfitting a 1,000-person organization results in an ongoing operational expense (OpEx) of $720,000 annually. As enterprise usage inevitably scales and API token consumption increases, variable costs can become highly unpredictable, straining IT budgets.
Conversely, deploying a Private Enterprise GPT shifts the financial model toward an initial capital expenditure (CapEx) for hardware infrastructure and setup, followed by highly predictable, significantly lower ongoing maintenance costs.
While the initial investment in dedicated infrastructure and specialized engineering talent is higher, private LLMs provide superior return on investment (ROI) over time. Inference costs become fixed and entirely predictable, shielding the organization from unexpected billing spikes driven by heavy usage. Furthermore, the compounding business value of owning an AI model that deeply understands proprietary operational procedures, internal coding standards, and specific client histories—rather than continuously renting generalized intelligence—frequently exceeds the initial expenditure, establishing a durable, long-term competitive advantage.
Architecting the Secure Private LLM: The Tailored Tech Advantage
Building and deploying a production-grade Private Enterprise GPT requires sophisticated infrastructure architecture and highly specialized engineering expertise. Organizations that attempt to build these complex systems internally often struggle with the steep learning curve of GPU orchestration, intricate security configurations, and the establishment of reliable Machine Learning Operations (MLOps) pipelines.
Firms leveraging elite partners specializing in custom software development and application management, such as Baytech Consulting, benefit immensely from a "Tailored Tech Advantage." By utilizing a highly skilled engineering workforce and a methodology focused on Agile methodology and Rapid Agile Deployment, these complex AI systems can be architected for enterprise-grade quality, timely delivery, and transparent communication. The foundation of a robust Private LLM rests on a modern, highly secure, and meticulously integrated technology stack.
Bare-Metal Performance and Zero-Trust Network Security
The computational compute requirements for processing Large Language Models are exceptionally intensive. Virtualized, multi-tenant cloud environments often introduce unacceptable latency and hidden security risks for highly sensitive, real-time AI workloads. The optimal foundational architecture utilizes dedicated, bare-metal GPU servers, such as those provided by OVHCloud.
Bare-metal servers supply the physically isolated, dedicated resources necessary to power complex AI computations, ensuring maximum performance, low latency, and high throughput for both model fine-tuning and real-time inference. This physical isolation is the absolute bedrock of a zero-trust security posture. Furthermore, utilizing platforms like OVHCloud ensures predictable billing models and grants the organization total control over data residency requirements.
To aggressively secure the perimeter of this bare-metal environment, advanced firewall and routing solutions like pfSense are deployed to strictly regulate all ingress and egress network traffic. This ensures that no unauthorized API calls can reach the model and continuously monitors for any suspicious data exfiltration attempts.
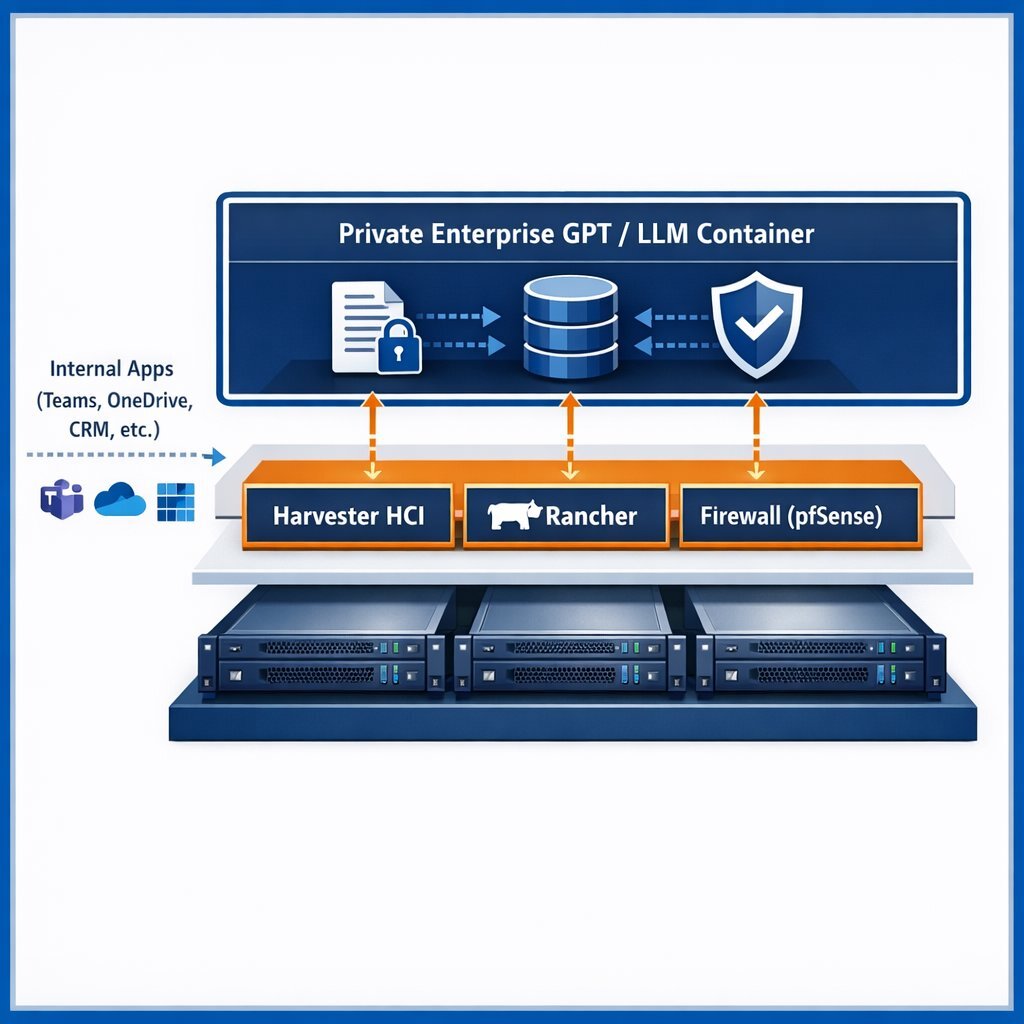
Deploying a Private LLM requires a robust, layered architecture. At the foundational layer, bare-metal GPU servers provide isolated compute power, secured by robust firewalls. Above this hardware, hyperconverged infrastructure tools and cluster managers orchestrate the containerized environments. Finally, the application layer houses the Private LLM and its associated databases, ensuring that data processing remains entirely within the secure organizational perimeter.
Virtualization and Orchestration: Harvester HCI and Rancher Synergy
Managing fleets of bare-metal servers and optimizing the utilization of highly expensive GPU compute requires advanced virtualization techniques. The modern standard for this is Hyperconverged Infrastructure (HCI) built entirely on cloud-native principles.
Harvester HCI is a modern, open-source hyperconverged infrastructure solution designed specifically for bare-metal servers. Unlike legacy, proprietary virtualization platforms that suffer from high licensing costs and rigid architectures, Harvester uses Kubernetes under the hood as a unified automation language across both containerized and virtual machine (VM) workloads. It deeply integrates KubeVirt for virtualization management and Longhorn for highly available, distributed block storage.
For highly scalable Private LLM deployments, the tight integration of Harvester HCI with Rancher is critical. Rancher acts as the centralized, intuitive management pane, streamlining the complex provisioning of Kubernetes clusters across the Harvester-managed nodes. Rancher enforces consistent governance, deploying strict Role-Based Access Control (RBAC) tied directly to corporate identity providers (such as Active Directory).
This specific architectural combination solves a massive cost-efficiency problem for enterprise AI: GPU underutilization. Standard Kubernetes deployments often lock an entire expensive physical GPU to a single, lightweight support model, wasting up to 90% of the compute capacity. Through advanced Kubernetes scheduling and infrastructure management on Harvester, engineering teams can implement sophisticated GPU partitioning (such as NVIDIA MIG or time-slicing). This allows multiple containerized AI models to safely share the same physical hardware, drastically improving cluster density and ROI without sacrificing inference speed.
Containerization, Data Integration, and Secure MLOps Pipelines
At the application layer, the Private LLM and all its critical dependencies are packaged into Docker containers. Containerization provides an immutable infrastructure, ensuring the AI application behaves consistently regardless of the underlying hardware, and securely isolating the AI processes from the host operating system.
The true power of the Private Enterprise GPT is unlocked at the data integration layer. To fuel the Retrieval-Augmented Generation (RAG) process, the system must ingest unstructured and structured data. Highly skilled engineers securely integrate the LLM with corporate knowledge bases, pulling context safely from Microsoft 365, Teams, OneDrive, and Google Drive environments. Relational data generated by the applications, user session logs, and complex system metrics are securely managed using robust databases like Postgres, administered securely via pgAdmin, alongside SQL Server for enterprise structured data.
To manage the lifecycle of the AI application—including model weight updates, fine-tuning processes, and regular security patching—organizations leverage robust CI/CD pipelines. Using deployment platforms like Azure DevOps On-Prem ensures that all code, infrastructure-as-code (IaC), and AI model updates are subjected to automated security scanning and drift detection before they ever reach the production environment. Development and refinement of these systems rely on industry-standard environments like VS Code and VS 2022, enabling rapid, agile deployment.
This meticulously engineered, closed-loop architecture guarantees that sensitive corporate data, client PII, and proprietary source code are processed with high throughput and low latency, entirely isolated from the public internet. For CTOs who want additional guardrails, adding an AI firewall layer to stop prompt injection and enforce governance between user interfaces and the model itself further reduces the attack surface.
Establishing a Corporate AI Policy and Governance Framework
Deploying a highly secure Private Enterprise GPT solves the technological risk, but technology alone cannot eradicate the cultural phenomenon of Shadow AI. Employees will always default to the path of least resistance to achieve their goals. Therefore, executive leadership must establish a comprehensive, enforceable AI governance framework that aligns technological capabilities with strict corporate policy.
As AI adoption accelerates, corporate boards and investors are demanding that executives safely manage these tools to drive innovation while mitigating systemic risk. The widespread, daily use of generative AI necessitates preemptive policies to protect businesses from open-ended legal liability, copyright infringement claims, and regulatory non-compliance.
Key Pillars of an Effective AI Governance Strategy
- Define Clear Boundaries and Mandate Sanctioned Tools: The single most effective way to eliminate Shadow AI is to provide a superior, authorized alternative. Once a Private LLM is deployed, corporate policy must explicitly and forcefully prohibit the use of unapproved, public-tier generative AI tools for any company business. Policies must clearly dictate what constitutes sensitive data (PII, source code, financial projections, client communications) and establish strict disciplinary consequences for exposing this data to external models.
- Implement Comprehensive Network Visibility: A security team cannot secure what it cannot see. IT administrators must utilize integrated network monitoring tools to detect and automatically block unauthorized API calls or web traffic to known public generative AI domains. Tracking network activity and analyzing dynamic SaaS logs allows administrators to identify pockets of Shadow AI usage rapidly and redirect those employees to the sanctioned, secure internal platforms.
- Establish Cross-Functional Governance Committees: AI governance cannot be solely an IT mandate; it affects the entire enterprise. Organizations must build effective oversight teams comprising technical professionals, legal counsel, risk and compliance officers, and end-user representatives from departments like marketing and sales. This committee must evaluate new AI use cases, audit system performance, and ensure alignment with evolving legal frameworks and internal ethics standards.
- Mandate Continuous AI Literacy Training: A corporate policy is only effective if the workforce understands both the rules and the reasoning behind them. Employees generally do not cause data breaches maliciously; they cause them due to a profound lack of awareness regarding how public LLMs ingest and utilize data. Organizations must build out comprehensive training programs that educate all employees on basic AI literacy, the precise mechanics of data leakage, the dangers of AI hallucinations, and the secure operation of the company's approved Private LLM. For smaller teams that need a practical place to start, following a structured SMB AI adoption roadmap can help phase in capabilities and policies over a manageable 90-day period.
Conclusion: Securing the Future of Enterprise AI
The integration of generative artificial intelligence into the modern corporate workflow is not a passing trend; it is an inevitable, fundamental shift in how business is conducted. Attempting to ban AI entirely is a draconian strategy that will only drive adoption further underground, exacerbating the severe risks of Shadow AI and stifling organizational productivity. Conversely, allowing unrestricted workforce access to public, consumer-grade language models is an abdication of fiduciary duty, virtually guaranteeing the exposure of proprietary intellectual property, client PII, and sensitive corporate strategy to the public domain.
The path forward requires a balanced, highly strategic approach. Organizations must firmly close the door on Shadow AI by implementing rigorous network monitoring, establishing comprehensive corporate usage policies, and continuously educating their workforce. Simultaneously, they must open a secure, officially sanctioned avenue for innovation by deploying a Private Enterprise GPT.
By leveraging advanced, cloud-native infrastructure—including high-performance OVHCloud bare-metal servers, Harvester HCI, Rancher, secure Kubernetes orchestration, and Docker containerization—organizations can construct self-hosted AI environments. These environments offer the immense analytical power of large language models while maintaining an impenetrable, zero-trust boundary around their data.
For executives seeking to navigate this complex technological transition, partnering with highly skilled software development and application management experts is highly recommended. Firms that specialize in custom solutions, agile deployment, and enterprise-grade quality can architect the precise, tailored infrastructure required to turn artificial intelligence from a severe security liability into a secure, compounding competitive advantage. For many enterprises, that partnership includes end-to-end support for integrating AI safely into existing applications and establishing the long-term practices needed to keep those systems compliant and resilient.
Frequently Asked Questions
Is it safe for my employees to use ChatGPT? The safety of using ChatGPT depends entirely on the tier of service and the nature of the data being processed. Standard, free-tier or consumer "Plus" versions of ChatGPT are highly unsafe for corporate use. The platform may ingest employee prompts and uploaded data to train future public models, leading to severe data privacy risks and IP leakage. Conversely, Enterprise-tier solutions (like ChatGPT Enterprise) or self-hosted Private LLMs are significantly safer, as they incorporate strict data retention policies, encrypt data, and explicitly prohibit the use of corporate data for model training.
What is "Shadow AI" and why is it dangerous? Shadow AI refers to the unauthorized, unmonitored use of artificial intelligence tools by employees without official IT approval or corporate oversight. It is profoundly dangerous because employees frequently input sensitive corporate data—such as financial records, proprietary source code, or client personally identifiable information (PII)—into public models to complete tasks faster. Because IT lacks visibility into these unvetted tools, the organization cannot control where the data goes, leading to catastrophic compliance violations, intellectual property theft, and massive financial penalties for data breaches.
How can we give employees AI tools without risking our IP? To safely harness artificial intelligence without risking intellectual property, organizations should deploy a Private Enterprise GPT (Private LLM). By utilizing custom architecture involving secure bare-metal servers, hyperconverged infrastructure (like Harvester HCI), and container orchestration (Kubernetes and Docker), the AI model is hosted entirely within the company's secure network perimeter. In a Private LLM setup, corporate data never leaves the organization's control, ensuring absolute protection of intellectual property while still providing employees with powerful, deeply customized AI capabilities. For regulated teams or those handling sensitive code, layering in a 7-stage AI code approval framework helps standardize reviews, satisfy auditors, and keep AI-generated changes aligned with security policies.
Recommended Reading on AI Security and Governance
- https://www.reco.ai/blog/popular-doesnt-mean-secure-the-2025-state-of-shadow-ai-report-findings
- https://www.menlosecurity.com/press-releases/menlo-securitys-2025-report-uncovers-68-surge-in-shadow-generative-ai-usage-in-the-modern-enterprise
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.