
Enterprise Decision Framework for DeepSeek V4 and Frontier Models
June 03, 2026 / Bryan Reynolds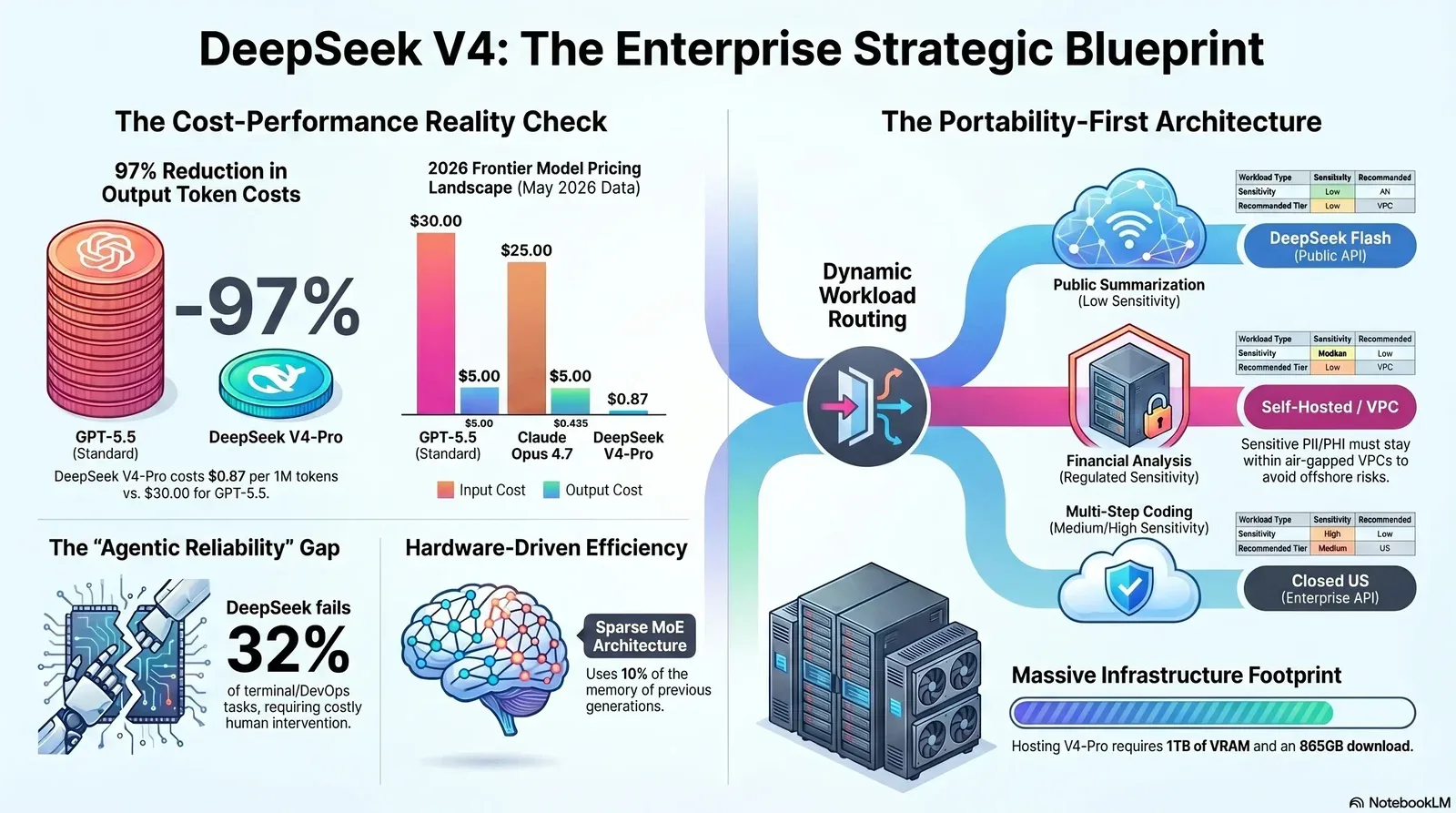
DeepSeek V4 in the Enterprise: A Cost-Performance Reality Check for CTOs Picking a Model Stack in 2026
The Chief Financial Officer has already reviewed the visualization demonstrating the dramatic cost reductions offered by recent artificial intelligence model releases. Enterprise adoption discussions regarding DeepSeek V4 invariably commence with the headline claim: the model is up to ten times cheaper than OpenAI and Anthropic per million tokens while achieving near-parity on major capabilities benchmarks. The strategic question that the Chief Information Security Officer is currently asking must now be answered: is a Chinese open-weight model appropriate to deploy alongside sensitive corporate intellectual property and protected customer data?

The cost gap between Chinese open-weight models—such as DeepSeek, Qwen, and GLM-5.1—and US frontier labs transitioned from an intriguing research anomaly in 2024 to an unavoidable procurement consideration by mid-2026. Most enterprise analysis either dismisses Chinese models entirely on geopolitical grounds without completing the mathematical analysis, or exclusively celebrates the cost savings while ignoring severe data-handling vulnerabilities.
The evidence indicates that a rigorous, workload-by-workload evaluation yields the most financially and technically secure outcome. Specific inference workloads, such as non-sensitive document summarization, code generation on open repositories, and high-volume content drafting, present a highly compelling case for self-hosted DeepSeek V4. Conversely, workloads touching Protected Health Information (PHI), Personally Identifiable Information (PII), trade secrets, or regulated automated decisions strictly do not. This framework necessitates a portability-first AI strategy—an architecture engineered to route workloads dynamically at runtime based on data classification, latency limits, and token economics, similar to the patterns described in portability-first AI strategy guidance for CTOs and CFOs.
The 2026 Frontier Model Landscape
Evaluating custom LLM development and enterprise model selection in 2026 requires understanding a tri-polar global market. The landscape is cleanly divided into three primary software architectures, each bearing distinct financial and operational profiles.
The first tier consists of the closed US frontier models. This includes OpenAI’s GPT-5.5, Anthropic’s Claude Opus 4.7, and Google’s Gemini 3.1 Pro. These models are strictly available via proprietary cloud APIs or managed cloud services such as Amazon Bedrock and Microsoft Foundry. They offer the absolute state-of-the-art in agentic reliability, complex tool orchestration, and multi-step reasoning, but they enforce a high cost per token and provide no option for air-gapped deployment.
The second tier encompasses open-weight Western models, dominated by Meta’s Llama 3 series and Mistral’s highly quantized releases. These models offer high utility for enterprise self-hosting but increasingly struggle to match the million-token context windows and raw parameter intelligence of the newest global releases without requiring vast computing clusters.
The third tier is the open-weight Chinese ecosystem, currently defined by DeepSeek V4, Alibaba’s Qwen 3.7-Max, and Zhipu AI’s GLM-5.1. DeepSeek V4 specifically targets the top-tier US frontier models while operating under a highly permissive MIT or provisional Apache 2.0 open-weight license.
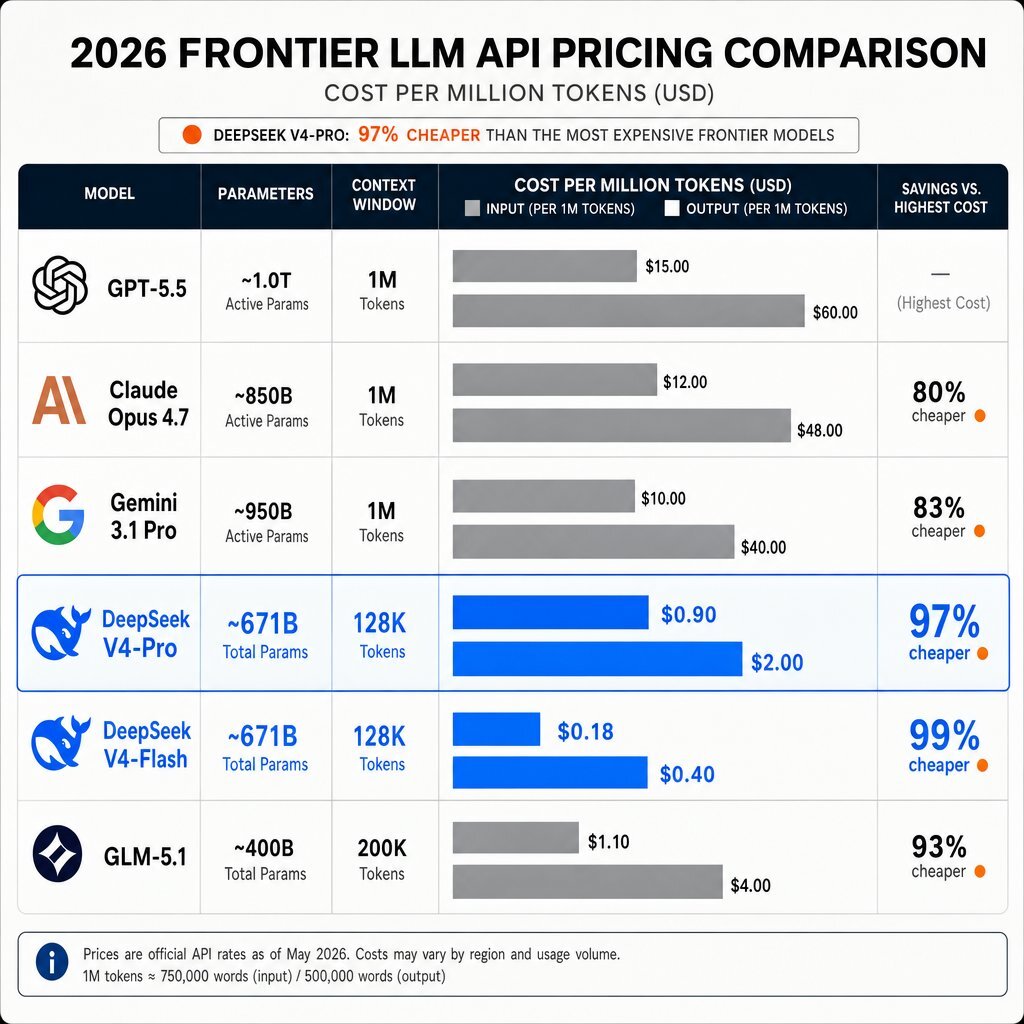
Table 1 outlines the technical specifications and pricing comparisons across the leading frontier models as of May 2026. Pricing reflects the standard API input and output costs per million (1M) tokens.
| Model | Classification | Total Parameters | Context Window | Input Cost (per 1M) | Output Cost (per 1M) |
|---|---|---|---|---|---|
| GPT-5.5 (Standard) | Closed US | Undisclosed | 1M tokens | $5.00 | $30.00 |
| Claude Opus 4.7 | Closed US | Undisclosed | 1M tokens | $5.00 | $25.00 |
| Gemini 3.1 Pro | Closed US | Undisclosed | 2M tokens | $2.50 | $10.00 |
| DeepSeek V4-Pro | Open Chinese | ~1.6 Trillion | 1M tokens | $0.435 | $0.87 |
| DeepSeek V4-Flash | Open Chinese | 284 Billion | 1M tokens | $0.14 | $0.28 |
| GLM-5.1 | Open Chinese | 754 Billion | 200K tokens | $1.20 | $1.20 |
Data accurately reflects standard configurations without volume caching discounts. DeepSeek V4 pricing reflects the permanent 75% price cut executed in May 2026.
The pricing differential alters the fundamental economics of high-volume inference applications. Generating one million output tokens on standard GPT-5.5 costs $30.00. The exact same volume on DeepSeek V4-Pro, utilizing the May 2026 permanent price adjustment, costs $0.87. This represents a near 97% reduction in output token expenditure, fundamentally changing the return on investment for long-horizon agentic workflows that consume massive autonomous token budgets and forcing leaders to rethink whether they should build or buy core AI capabilities.
The DeepSeek V4 Enterprise Cost-Performance Reality
To determine if the DeepSeek V4 enterprise cost advantages translate securely to production environments, the underlying architecture and independent benchmarking must be examined without the distortion of vendor marketing.
Architectural Innovations and Context Efficiency
DeepSeek V4 achieves its cost efficiency not through brute-force computation, but through severe architectural optimization forced by hardware constraints. The V4-Pro model features 1.6 trillion total parameters, but utilizes a sparse Mixture-of-Experts (MoE) architecture that activates only 49 billion parameters per token. This selective activation allows the model to possess immense latent knowledge without paying the computational inference penalty of a dense trillion-parameter network.
The critical innovation unlocking the 1-million-token context window is DeepSeek’s Hybrid Attention Architecture. By combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA), the model drastically reduces the memory footprint required to track extremely long documents. In a fully saturated 1-million-token context scenario, DeepSeek V4-Pro requires only 27% of the single-token inference floating-point operations (FLOPs) and a mere 10% of the Key-Value (KV) cache compared to its predecessor, V3.2. For an enterprise processing massive legal datasets, complete financial 10-K filings, or sprawling code repositories, this memory efficiency is what makes local deployment mathematically viable.
Furthermore, the model introduces Manifold-Constrained Hyper-Connections (mHC) to stabilize deep residual architectures and utilizes the Muon optimizer to accelerate convergence during the pre-training phase, which was conducted over 32 trillion diverse tokens. To offer developers granular latency control, DeepSeek V4 operates in distinct reasoning modes: "Non-think" for fast, intuitive responses; "Think High" for conscious logical analysis; and "Think Max" to push the reasoning budget to its absolute limit for complex planning.
Much of this architectural efficiency stems from a deeply constrained origin. Industry analysis frequently highlights a specific anomaly: DeepSeek reportedly trained its models for approximately $5.5 million, compared to the hundreds of millions expended by US laboratories on models like Gemini Ultra. The reality is far more nuanced. This low figure strictly covers the final pre-training run and excludes massive prior research expenditures, ablation experiments, and the foundational requirement of a 2,048-node H800 GPU cluster. However, because US export controls limited DeepSeek to the degraded NVIDIA H800 chip rather than the flagship H100, their engineers were forced to invent novel compression algorithms, directly resulting in the highly efficient inference profile the model exhibits today.
Where the 10x Advantage Holds
On specific benchmarks, DeepSeek V4-Pro matches the intelligence of the US frontier at a fraction of the cost. When evaluating standard academic and graduate-level reasoning, the V4-Pro-Max model scores 90.1% on the GPQA Diamond benchmark. While this trails GPT-5.5 (93.6%) and Claude Opus 4.7 (94.2%), the margin of error is narrow enough that for standard enterprise text synthesis, research summarization, and data extraction, the outputs are virtually indistinguishable in production.
In agentic web research, DeepSeek V4-Pro exhibits distinct leadership. On the BrowseComp benchmark, which measures an autonomous agent's ability to navigate the web and extract relevant unstructured data, DeepSeek V4-Pro scores 83.4%, successfully defeating Claude Opus 4.7’s score of 79.3%. For companies building high-volume web scraping or automated market research pipelines, routing this specific task to DeepSeek V4 yields superior accuracy while simultaneously capturing the output cost savings.
Where the Advantage Collapses: Agentic Reliability and Held-Out Evals
The headline cost savings collapse when workloads demand highly complex, terminal-heavy multi-step planning or novel problem-solving outside the model's training distribution.
On Terminal-Bench 2.0, an evaluation measuring how well an AI can automate complex command-line interfaces and execute DevOps server configurations, GPT-5.5 achieves a dominant 82.7%. DeepSeek V4-Pro manages only 67.9%. This 14.8-point gap is catastrophic in infrastructure environments; an autonomous coding agent that fails nearly a third of its terminal operations requires constant human intervention, instantly erasing any token-cost savings through lost engineering hours.
On SWE-bench Pro, which tests the ability to resolve real-world, repository-level GitHub issues across multiple files, Claude Opus 4.7 leads with 64.3%, GPT-5.5 achieves 58.6%, and DeepSeek V4-Pro trails closely at 55.4%.
The most revealing data regarding DeepSeek V4 emerges from the Center for AI Standards and Innovation (CAISI), a division of the US National Institute of Standards and Technology (NIST). In May 2026, CAISI published an independent evaluation comparing DeepSeek V4 Pro against US frontier models using uncontaminated, non-public benchmarks. Because open-weight models frequently suffer from data contamination—where public benchmark test questions inadvertently leak into the model's training data—CAISI utilized private evaluations like the internal software engineering test "PortBench" and the cybersecurity challenge "CTF-Archive-Diamond".
The CAISI evaluation concluded that DeepSeek V4 Pro’s true capability lags behind the leading US models by approximately eight months. Using an Item Response Theory (IRT) statistical model to assign Elo ratings, GPT-5.5 scored an Elo of 1260, Claude Opus 4.6 scored 999, and DeepSeek V4 Pro scored 800. On the private PortBench evaluation, DeepSeek V4 achieved only 44% accuracy, and on the highly complex CTF cybersecurity benchmark, it managed only 32%.
The technical reality for the Chief Technology Officer is evident: DeepSeek V4 is highly capable on known patterns and standardized reasoning, but struggles significantly with the extreme edge-case reliability required for unsupervised enterprise software engineering and cybersecurity remediation. This lines up with broader evidence that fully autonomous AI agents still fail in complex enterprise systems, and that human-led architecture remains essential.
The Enterprise Build-vs-Buy Calculus: DeepSeek V4 API vs. Self-Hosting
The decision to adopt a Chinese open-weight model immediately forces an infrastructure decision. Organizations must decide whether to consume the model via the public API hosted in China, or download the MIT-licensed weights and run the system on sovereign, self-hosted hardware.
Why the Public API Fails Regulated Data
For any enterprise managing PII, PHI, financial ledgers, or proprietary trade secrets, transmitting unencrypted plaintext payloads to the public DeepSeek API is an unequivocal violation of corporate security policy. The data residency risks associated with routing sensitive intelligence to offshore servers completely negate any token-cost benefits. State and federal compliance frameworks, alongside strict enterprise customer contracts, legally prevent third-party transmission of this data without rigorous auditing and localized data centers.

Consequently, the only credible path for DeepSeek V4 enterprise adoption involving secure data is self-hosting the open weights within the corporate perimeter or an isolated Virtual Private Cloud (VPC). This strategy, heavily utilized by healthcare and financial institutions, ensures that zero bytes of data ever leave the proprietary network, and aligns with the kind of hardened deployment patterns described in guidance on self-hosting AI developer agents in regulated enterprises.
The Hardware Footprint: Capacity Planning for H100s and Blackwell
Self-hosting open-weight LLM cost profiles depend entirely on the model size and the target inference speed. The 1.6-trillion-parameter DeepSeek V4-Pro is a massive software artifact. The weights alone require an 865-gigabyte download, necessitating dedicated infrastructure.
Loading the V4-Pro model in FP8 quantization requires approximately 1 terabyte of Video RAM (VRAM). Distributing this across modern hardware means an enterprise must provision either a single robust node containing eight NVIDIA H200 (141GB) GPUs or two linked nodes containing sixteen NVIDIA H100 (80GB) GPUs to serve the Pro model effectively.
The lighter DeepSeek V4-Flash model, containing 284 billion total parameters (with 13 billion active), is vastly more accessible. The Flash model requires roughly 158GB for weights, plus approximately 10GB to manage the full 1-million-token KV cache. This comfortably fits onto two NVIDIA H200s, two RTX Pro 6000 Blackwell GPUs, or a standard node of four A100 (80GB) GPUs.
The May 2026 performance data regarding the new NVIDIA Blackwell architecture demonstrates massive inference acceleration. Benchmarks from SemiAnalysis indicate that running DeepSeek V4-Pro on an NVIDIA GB200 NVL72 rack achieves over 150 tokens per second per user. This represents a 30x improvement in performance-per-watt compared to the previous H200 generation at similar interactivity levels. Furthermore, optimizations utilizing continuous batching via the vLLM engine allow enterprises to multiplex hundreds of concurrent internal users against a single deployment footprint.
For local, decentralized AI development—termed "CROPS AI" (Consequential, Recoverable, Open, Private, and Sovereign) by Ethereum co-founder Vitalik Buterin—extreme quantization proves highly effective. A 2-bit quantized version of DeepSeek V4 fits entirely within 90 GB of VRAM. While Apple Silicon devices achieve impressive speeds of 35 tokens per second under these constraints, AMD hardware trails significantly at roughly 7 tokens per second, exposing a critical fragmentation issue in consumer-grade hardware compatibility.
Total Cost of Ownership: The Breakeven Mathematics
A fundamental misunderstanding in enterprise AI strategy is the assumption that self-hosting open-weight models is inherently cheaper than consuming APIs. Mathematical analysis proves this false at low to medium volumes.
Consider a baseline self-hosted setup utilizing a single NVIDIA A100 GPU to run a smaller 70-billion parameter model. The raw hardware cost to rent an A100 in the cloud is roughly $1,440 per month. However, the Total Cost of Ownership (TCO) must include specialized DevOps labor, power, cooling, and infrastructure overhead. A conservative estimate places the true adjusted cost of running a single GPU at $3,240 per month.
When comparing this $3,240 monthly fixed cost against the premium GPT-5.5 API, the self-hosted setup breaks even at approximately 576 million tokens per month (or roughly 19 million tokens per day). If an enterprise processes more than 19 million tokens daily, self-hosting is mathematically cheaper than paying the GPT-5.5 invoice.
However, when comparing the cost of self-hosting against DeepSeek's extraordinarily cheap public API ($0.21 blended average per million tokens for Flash), the breakeven mathematics collapse entirely. To justify a $3,240 monthly server cost against an API that costs pennies, an enterprise would need to process nearly 4.7 billion tokens per month. A single A100 GPU maxes out its theoretical physical throughput at roughly 3.9 billion tokens per month.
Therefore, it is physically impossible to break even on a single GPU when competing against budget-tier APIs. The strategic conclusion is clear: an organization does not self-host DeepSeek V4 to save money compared to the public DeepSeek API. An organization self-hosts DeepSeek V4 to gain absolute data sovereignty, secure IP protection, and compliance certainty without paying the massive $30-per-million-token premium demanded by secure US frontier lab deployments. Finance leaders can plug these numbers directly into the kind of model outlined in our AI ROI framework for CFOs to understand real payback periods.
In real-world applications, this sovereign deployment provides immense value. A deployed hospital infrastructure case study utilizing a localized open-weight model demonstrated a reduction in physician review time from eight minutes to two minutes per clinical note. Because the deployment was 100% HIPAA compliant and air-gapped, the hospital incurred a $1,200 monthly infrastructure cost compared to a $6,500 monthly estimate for a compliant closed-source SaaS solution, proving the financial viability of local hosting in highly regulated verticals.
Geopolitics, Security, and Compliance Risk
Procuring and deploying an AI model built by a Shenzhen-based research laboratory introduces geopolitical and regulatory risk variables entirely absent when contracting with Microsoft or Amazon.
US Export Controls and the Huawei Ascend 950 Supply Chain
The aggressive pricing strategy deployed by DeepSeek is intimately linked to the ongoing semiconductor trade war. US export controls actively prevent NVIDIA from selling its most advanced logic chips, including the H100 and Blackwell series, to entities operating within the People's Republic of China. While these restrictions were engineered to constrain Chinese AI advancement, they inadvertently birthed a captive, highly optimized domestic supply chain.
DeepSeek circumvented these hardware bottlenecks by heavily optimizing the V4 architecture to run on domestic Chinese silicon, specifically the Huawei Ascend 950 processor. By completely decoupling from the expensive and restricted NVIDIA supply chain, DeepSeek structurally lowered its operational infrastructure costs, allowing for the 75% permanent price reduction that shocked western markets in May 2026.
This optimization triggered a massive scramble within the Chinese technology sector. Firms including ByteDance, Tencent, and Alibaba rushed to secure Ascend 950 orders, recognizing that localized hardware independence is now a proven, scalable reality Capacity Global. For western enterprise CTOs, this indicates that DeepSeek's pricing floor is sustainable and backed by state-championed hardware, not merely a temporary loss-leader strategy intended to capture market share.
The US Legal Landscape: Executive Order 14365
Domestically, the US federal government is actively reshaping the legal environment surrounding AI deployment. In December 2025, Executive Order 14365, titled "Ensuring a National Policy Framework for Artificial Intelligence," was issued to consolidate federal oversight and preempt fragmented state legislation.
The Executive Order establishes an AI Litigation Task Force within the Department of Justice, specifically tasked with challenging state AI laws that interfere with interstate commerce or conflict with the national policy framework. This mandate targets stringent state-level regulations, such as the California Transparency in Frontier Artificial Intelligence Act and the Colorado AI Act (effective June 2026), seeking to preempt them with a uniform federal standard.
For enterprises deploying self-hosted models, this creates a volatile compliance environment. The Federal Communications Commission (FCC) was directed to determine whether to adopt a federal reporting and disclosure standard for AI models, though specific compliance burdens remain in active rulemaking as of mid-2026. Systems engineering teams must design logging, tracking, and compliance frameworks that remain agile enough to pivot when federal preemption effectively overrides local state compliance mandates.
The EU AI Act: Systemic Risk and Open-Weight Exemptions
For multinational enterprises operating in Europe, the European Union AI Act provides strict, unavoidable obligations. Chapter V of the Act, which specifically targets providers of General-Purpose AI (GPAI) models, becomes fully enforceable under the supervision of the European Commission and the AI Office in August 2026.
The AI Act features specific language regarding open-source and open-weight foundation models. Providers releasing models under a free and open-source license are explicitly exempt from the heavy documentation requirements listed in Article 53, meaning they do not have to provide exhaustive technical documentation to downstream integrators or national competent authorities.
However, this exemption features a critical, non-negotiable exception: Systemic Risk. The AI Act defines any model trained using more than 10^{25} floating-point operations (FLOPs) as inherently possessing high-impact capabilities, triggering an automatic "Systemic Risk" classification. If an open-weight model crosses this massive compute threshold, all open-source exemptions are instantly voided.
Providers of systemic-risk models must conduct state-of-the-art model evaluations, carry out adversarial testing (red-teaming), track and report serious safety incidents to the European Commission, and ensure robust cybersecurity protections. DeepSeek V4-Pro, operating at the absolute frontier of computational scale, is scrutinized heavily under these systemic thresholds.
More critically for the enterprise: the EU AI Act dictates that if a downstream actor fine-tunes or modifies a model using compute that exceeds one-third of the original training compute, that downstream actor becomes the legal "provider" of the new model. If an enterprise uses massive internal clusters to heavily fine-tune a systemic-risk model like DeepSeek V4-Pro, they risk legally inheriting the exhaustive evaluation, red-teaming, and incident-reporting obligations demanded by the European Commission.
Architecting for Reality: The Portability-First Approach
Recognizing the cost disparities, hardware realities, and geopolitical risks, an organization cannot standardize its entire software stack on a single vendor. The modern infrastructure standard requires a portability-first AI strategy—an architecture engineered to avoid vendor lock-in by routing prompts dynamically based on runtime context, as described in our broader work on enterprise internal AI app stores and agent orchestration.
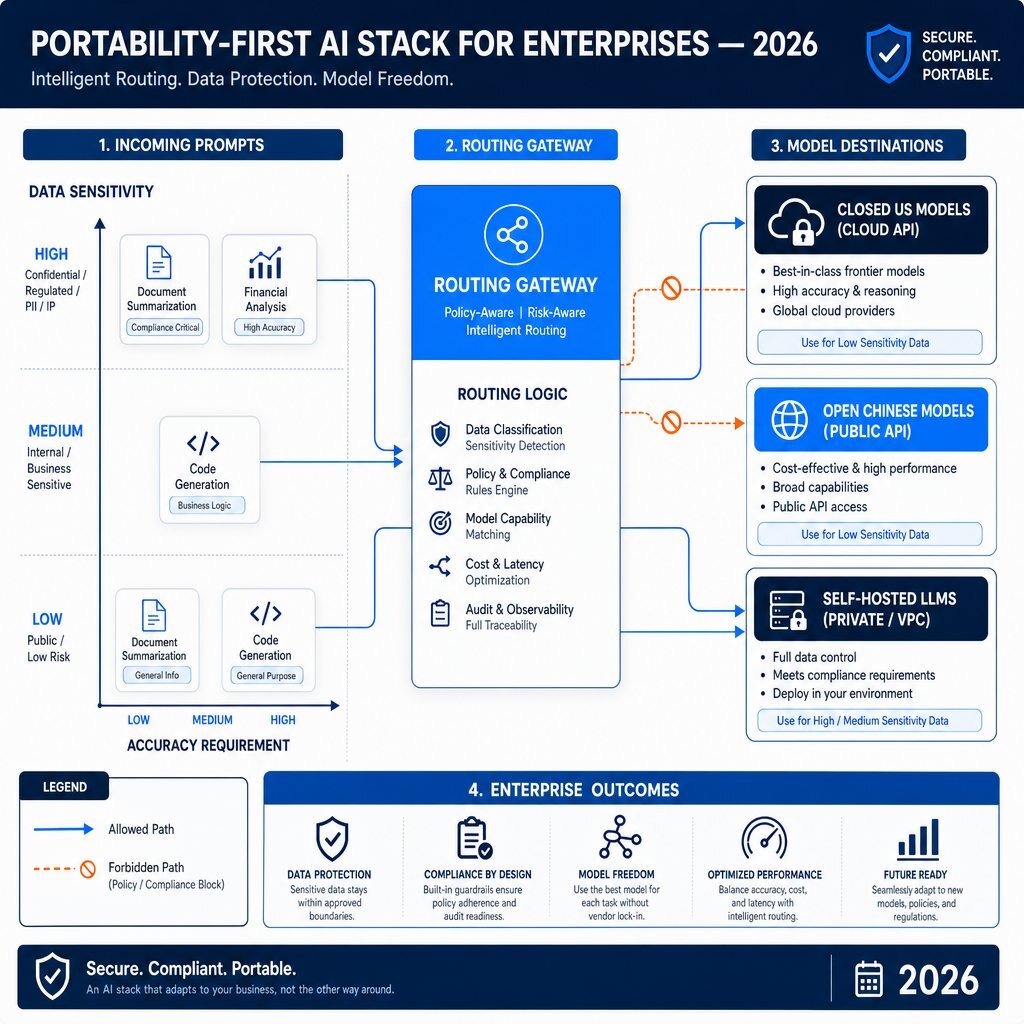
Engineering teams leveraging rapid agile deployment principles—such as the methodologies employed by Baytech Consulting—utilize an intermediary AI gateway or routing layer. This layer sits between the end-user application and the suite of LLMs, executing policy-based routing on reliable infrastructure such as Azure DevOps On-Prem, Kubernetes, and Docker containers.
The Workload Classification Matrix
To determine which model receives which prompt, workloads must be classified across two primary axes: Data Sensitivity and Capability/Accuracy Requirements.
| Workload Type | Data Sensitivity | Accuracy Need | Recommended Model Tier | Deployment Method |
|---|---|---|---|---|
| Document Summarization (Public Data) | Low | Medium | Open Chinese (DeepSeek Flash) | Public API |
| Complex Multi-Step Code Generation | Medium | High | Closed US (Opus 4.7 / GPT-5.5) | Enterprise Cloud API |
| Financial Analysis on PII/PHI | Regulated | High | Open Chinese / Western | Self-Hosted / VPC |
| Web Scraping & Open Data Extraction | Low | High | Open Chinese (DeepSeek Pro) | Public API |
| Customer-Facing Unsupervised Chatbots | Medium | High | Closed US (Gemini 3.1) | Enterprise Cloud API |
Under this matrix, if a marketing system needs to generate thousands of blog post outlines using public web data, the gateway routes the request to the DeepSeek V4 API. The business captures the 97% cost reduction on a massive volume of tokens because the data is entirely non-sensitive and the reasoning task is highly standardized.
Conversely, if a developer highlights a proprietary, unreleased algorithm in their VS Code IDE and requests a refactor, the gateway detects the internal source-code context. It then routes the prompt exclusively to the locally hosted instance of DeepSeek V4-Pro, or a zero-retention Enterprise API from Anthropic. The data never interacts with offshore infrastructure. This is also where solid DevOps practices and automation matter, because the routing, observability, and rollback need to be treated like any other critical production service.
Runtime Routing and Fallback Patterns
A portability-first architecture also ensures high availability. Cloud API endpoints frequently experience throttling, degradation, and complete outages during peak global loads. By decoupling the application logic from the specific LLM endpoint, a system can execute graceful fallback patterns. If the primary GPT-5.5 endpoint times out, the gateway automatically reroutes the prompt to a secondary Claude Opus 4.7 endpoint, or falls back to the self-hosted DeepSeek V4 cluster hosted on internal OVHcloud servers.
By designing the application to communicate via a standardized format (such as the OpenAI message schema, which the DeepSeek API natively mirrors), developers write the integration logic once and alter the model destinations via dynamic configuration files without touching the core application code.
Executing a 60-Day Enterprise Evaluation Plan
Transitioning from theoretical architecture to a production-ready stack requires a disciplined, methodical validation process. The organization must empirically verify that the open-weight model meets internal security and accuracy benchmarks.
Phase 1: Benchmark Selection and Security Review (Days 1-15)
The evaluation begins by establishing ground truth. Relying on vendor-published benchmark scores is highly insufficient, as demonstrated by the vast discrepancies exposed in the NIST CAISI evaluations. The engineering team must construct a private, internal evaluation dataset utilizing historical corporate data. This prevents data contamination and measures the model's actual utility on proprietary domains. Simultaneously, the security and compliance teams review the open-weight MIT license, confirm the lack of telemetry in the downloaded weights, and authorize a secure VPC environment for the test deployment.
Phase 2: Infrastructure Provisioning and Model Loading (Days 16-30)
The infrastructure team provisions the necessary hardware—such as a multi-node NVIDIA H100 cluster or the newer GB200 NVL72 architecture—within the air-gapped environment. The team downloads the 865-gigabyte DeepSeek V4-Pro weights and configures the vLLM serving engine, optimizing for continuous batching and FP8 quantization to maximize concurrent throughput. Network rules are strictly enforced at the pfSense firewall level to ensure the hosting nodes have zero outbound internet access, mathematically proving data sovereignty.
Phase 3: Pilot Workloads and Shadow Deployments (Days 31-45)
With the model active, the engineering team routes a duplicated shadow stream of production traffic to the self-hosted DeepSeek instance. The primary system continues to rely on the standard US closed models, but the local instance processes the exact same prompts silently in the background, logging outputs directly to a PostgreSQL database. The outputs are systematically compared for latency, logical accuracy, and instruction adherence. Cost metrics are calculated based on the active GPU amortization schedules compared to equivalent API expenditures. This mirrors the disciplined pilot approach we recommend in our 90‑day enterprise AI implementation roadmap, just tuned for model-stack decisions.
Phase 4: The Decision Gate (Days 46-60)
The executive leadership reviews the aggregated intelligence. The analysis must answer specific questions: Did the self-hosted DeepSeek V4-Pro model achieve acceptable accuracy on the internal dataset? Did the vLLM engine maintain necessary tokens-per-second throughput under concurrent user load? Does the adjusted total cost of ownership present a financially sound alternative to secure enterprise API contracts? If the answers are affirmative, the system is promoted from shadow deployment to active routing.
What This Means for the Broader Stack
Introducing an open-weight Chinese model into the enterprise stack enforces maturity across all adjacent systems. Observability tooling must be upgraded to track token usage, latency, and routing logic across entirely different backend architectures. If an autonomous agent utilizing tools like Claude Code or OpenClaw begins failing, the telemetry must clearly indicate whether the failure was caused by the routing layer, a context window overflow, or the specific reasoning limitations of DeepSeek V4 on terminal commands. This level of governance is especially important when you start orchestrating AI agent swarms that write and ship code into your CI/CD pipelines.
Compliance documentation must also dynamically adapt. To prepare for the European Union AI Act enforcement in August 2026, the legal team must meticulously track internal fine-tuning compute expenditures. If the engineering team pushes extensive training runs on the self-hosted model, systems must be in place to alert compliance officers before the compute threshold exceeds the one-third limit that legally designates the enterprise as a systemic-risk GPAI provider.
Conclusion
DeepSeek V4 has permanently altered the economics of enterprise artificial intelligence. By utilizing severe architectural efficiencies and leveraging hardware independence via the Huawei Ascend 950 processor, it delivers state-of-the-art text generation and data extraction at a near 97% discount compared to US frontier models.
However, deploying a Chinese open-weight model directly to sensitive enterprise data via a public API represents an unacceptable geopolitical and regulatory risk. The reality for the modern Chief Technology Officer is that realizing these cost savings safely requires highly robust infrastructure. An organization must either self-host the massive weights on expensive sovereign GPU clusters to ensure data privacy, or deploy a portability-first gateway that limits public API routing strictly to non-sensitive, high-volume tasks. By treating artificial intelligence not as a single vendor relationship, but as a dynamically routed commodity, enterprises can capture unprecedented financial efficiency without compromising security or regulatory compliance—and avoid the kinds of shadow AI risks that come from uncontrolled, ad hoc tool usage.
FAQ
How does DeepSeek V4 handle extremely long documents compared to US models?
DeepSeek V4 utilizes a Hybrid Attention Architecture featuring Compressed Sparse Attention (CSA), which allows it to process a 1-million-token context window (roughly 15 to 20 full-length novels) using only 27% of the compute required by previous models. While it excels at document retrieval and synthesis, independent benchmarks show it slightly trails top US models like GPT-5.5 in complex multi-step reasoning over those massive contexts.
Supporting Links
- https://www.nist.gov/news-events/news/2026/05/caisi-evaluation-deepseek-v4-pro
- https://www.datacamp.com/blog/deepseek-v4-vs-gpt-5-5
Enforcement of Chapter V under the EU AI Act
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.