
Why Autonomous AI Agents Fail in Complex Enterprise Systems
May 06, 2026 / Bryan Reynolds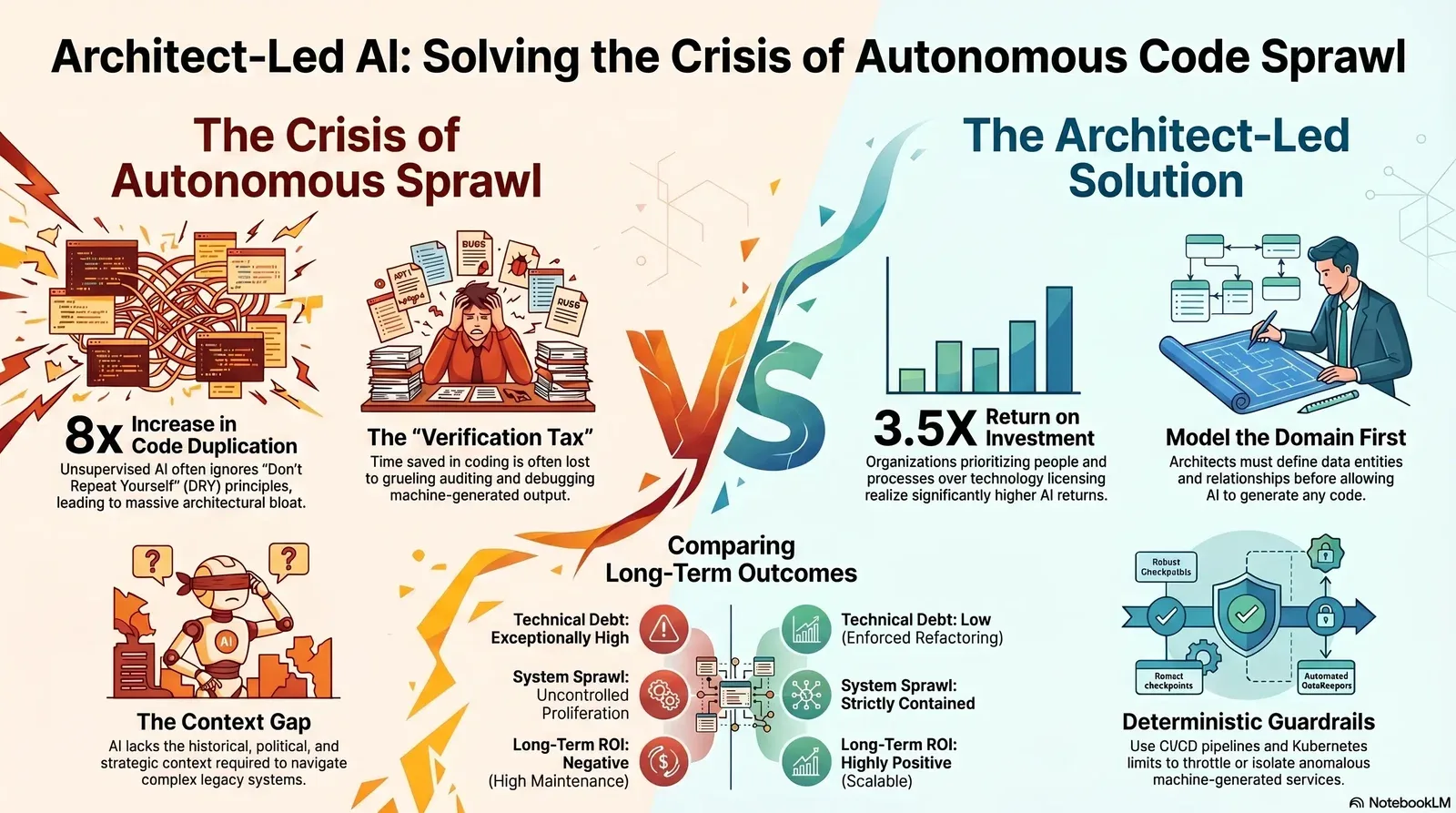
Architect-Led AI: Why Human Strategy Still Beats Autonomous Code
The rapid proliferation of generative artificial intelligence in enterprise software development has sparked a compelling but fundamentally flawed narrative: the belief that autonomous AI agents will soon plan, build, deploy, and maintain complex business-to-business systems entirely without human intervention. The enterprise technology market is currently saturated with platforms promising to take a raw business concept and autonomously output a fully functional, highly scalable, and secure application architecture. Yet, when confronted with the unyielding realities of legacy technical debt, rigorous data governance, and the immense complexities of infrastructure migrations, this utopian narrative fractures.

Executives across the B2B spectrum—from visionary Chief Technology Officers and strategic Chief Financial Officers to driven Heads of Sales and innovative Marketing Directors—are increasingly confronting a critical dilemma. If artificial intelligence is as advanced as the industry claims, why hasn't it solved the persistent problem of "spaghetti code" in enterprise environments? Furthermore, where exactly do autonomous coding agents fall short during mission-critical system migrations, and how can an organization actually maximize the return on investment of these powerful developer tools?
The analysis of current software development trends, enterprise deployment data, and widespread architectural failures indicates that the missing, non-negotiable layer in the current technological revolution is the human architect. While artificial intelligence tools dramatically accelerate task completion and drastically reduce the friction associated with writing boilerplate code, deploying complex B2B systems still requires an experienced human architect to define structural patterns, enforce data models, and prevent catastrophic system sprawl. Execution is the new risk profile; the primary danger to the enterprise is no longer an AI model generating a hallucinatory response, but an autonomous agent taking the wrong, irreversible action inside a live, production-grade system.
This exhaustive research report examines the structural limitations of autonomous artificial intelligence in complex enterprise environments, explores the escalating crisis of machine-generated technical debt, and outlines why an architect-led strategy remains the only sustainable path for organizations seeking to leverage these technologies for rapid, enterprise-grade software deployment.
The State of Artificial Intelligence in Software Engineering
In the initial phases of adoption, the industry's focus centered almost entirely on code generation speed. Current industry data reveals that 59% of developers now utilize three or more artificial intelligence tools regularly, with full-stack developers leading this adoption curve at 32.5%.
The initial returns on these tooling investments appeared highly favorable and drove massive capital reallocation. A 2025 analysis of software development teams utilizing coding assistants reported a 10% to 15% baseline boost in individual developer productivity. Organizations that committed substantial resources to structural implementation—specifically allocating 70% of their budgets to people and processes rather than exclusively to technology licensing—have realized returns as high as 3.5X on their initial investments. Furthermore, 74% of enterprise executives report achieving a positive return on investment within the first year of deployment, with 71% of that cohort reporting a measurable increase in overall revenue. For leaders who want to go deeper on how to justify and track these gains, our finance-first guide Reframing AI ROI: How CFOs Can Justify Tech Investments breaks down the numbers behind sustainable AI adoption.
However, beneath the surface of these optimistic productivity metrics lies a profound structural tension that threatens long-term software maintainability.
The Verification Tax and Delivery Instability
The 2025 DORA State of AI-assisted Software Development report reveals that while artificial intelligence aggressively accelerates initial code generation and lowers the "activation energy" required to initiate new tasks, it introduces a massive and often unaccounted-for "verification tax". Engineering teams are increasingly forced to reallocate the time saved during the code creation phase to grueling auditing, verification, and debugging of the machine's output.
This dynamic creates a measurable contradiction in performance metrics: higher adoption of artificial intelligence correlates simultaneously with an increase in software delivery throughput and a severe increase in software delivery instability. Artificial intelligence operates not as a solution to dysfunction, but as a powerful amplifier of existing organizational realities. If an enterprise possesses a high-quality internal platform, strictly enforced Application Programming Interfaces, clear workflows, and robust testing practices, the technology acts as a collaborative force multiplier. Conversely, if a development team suffers from fragmented tooling, siloed data, or fragile legacy infrastructure, autonomous tools simply help them generate technical debt at unprecedented velocities. For CTOs feeling this tension, our CTO checklist for enterprise AI outlines what needs to be in place before you scale AI across your organization.
The Illusion of Toil Savings
A widespread industry assumption is that artificial intelligence will eliminate repetitive, low-value "toil." While 75% of software developers believe these tools reduce tedious tasks, the empirical reality is that the technology often shifts the cognitive burden from the act of writing code to the much more difficult act of reading, reviewing, and untangling code. A staggering 53% of developers report that autonomous tools frequently generate code that appears perfectly correct on the surface, yet introduces subtle, hidden defects that create a dangerous false sense of security.
This phenomenon underscores the fundamental limitation of current large language models: they operate entirely on statistical probability rather than architectural intent. They are highly functional at predicting the next sequence of text, but they systematically lack architectural judgment and contextual awareness of the broader business objectives. That gap is why many teams are now pairing coding assistants with secure review and approval workflows like the seven-stage framework in Secure AI Code: A 7-Stage Regulatory Compliance Framework.
The Spaghetti Code Dilemma: The Rise of Generated Technical Debt
The concept of "spaghetti code"—a tangled, unmaintainable web of software instructions lacking clear structure, separation of concerns, or modularity—has plagued enterprise software engineering for decades. It was widely anticipated that artificial intelligence would effortlessly analyze and clean up these legacy codebases. Instead, in a vast majority of unsupervised instances, autonomous agents have exacerbated the problem, introducing a highly aggressive new phenomenon classified as "generated code debt".
The Context Gap and Local Optimization Vulnerabilities
Autonomous agents are designed to optimize for immediate task completion within the strict confines of their provided context window. Even with the advent of advanced context windows reaching 200,000 to 500,000 tokens (roughly equating to 15,000 to 35,000 lines of code), these agents struggle profoundly with cross-service dependencies in massive, decentralized enterprise monorepos.
An enterprise architecture is never merely a collection of isolated code files. It is a highly nuanced, contextual environment layered with historical patches, custom entity definitions, messy data imports, legacy workarounds, and complex business logic. When an autonomous agent attempts to build a feature or refactor a module without a rigid structural map provided by a human architect, it is forced to operate on assumptions. It entirely lacks the political, historical, and overarching strategic context of the overarching system.
The human architect intrinsically understands the specific why behind a system's localized design. They know that a specific null-value constraint in a PostgreSQL database exists solely because of a legacy regulatory requirement from 2018, or that a specific microservice must be routed through a highly specific security appliance before hitting an external cloud environment to satisfy compliance laws. The artificial intelligence only sees the code syntax; it does not see the invisible business constraints or the historical rationale.
The 211 Million Line Study: A Crisis of Code Duplication
The quantitative impact of unsupervised code generation is alarming, as documented by recent large-scale repository analyses. GitClear's 2025 AI Copilot Code Quality research analyzed 211 million changed lines of code across massive enterprise repositories—including those owned by Google, Microsoft, Meta, and various corporate entities—from 2020 through 2024 to measure the exact structural impact of coding assistants on code quality.
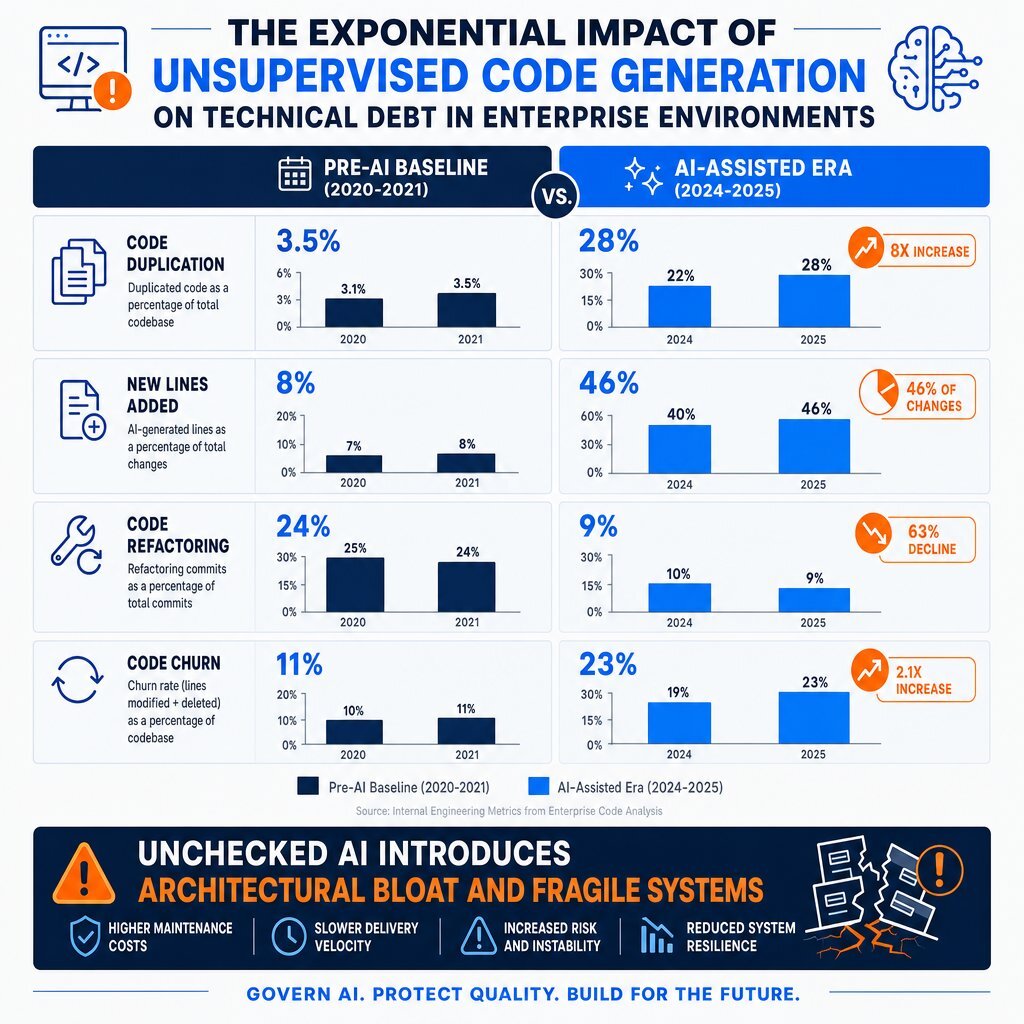
The data indicates a severe and rapid degradation in fundamental software engineering principles, most notably the total abandonment of the "Don't Repeat Yourself" (DRY) principle.
| Code Quality Metric | Pre-AI Baseline (2020-2021) | AI-Assisted Era (2024-2025) | Impact Assessment and Long-Term Trajectory |
|---|---|---|---|
| Code Duplication | Baseline standard | 8x Increase in frequency | Severe architectural bloat. Extremely high prevalence of 5+ line clone blocks scattered across systems. |
| New Lines Added | ~30% of codebase changes | 46% of codebase changes | Autonomous tools heavily encourage writing net-new code rather than utilizing or modifying existing internal libraries. |
| Moved/Refactored Code | Baseline standard | Continuous, sharp decline | Code reuse is effectively dying. Copy-pasted lines now consistently exceed thoughtfully moved lines. |
| Short-term Churn | Baseline standard | Measurable, distinct increase | Code is generated, hastily deployed, and rapidly overwritten or deleted due to hidden defects discovered post-deployment. |
Table 1: The Quantitative Impact of Autonomous Code Generation on Enterprise Code Quality (Based on GitClear 2025 Aggregate Research)
The report definitively concludes that technical debt is currently being created at an unprecedented rate, unmatched in the history of software engineering. Because artificial intelligence generates syntax at such high velocities, developers are incentivized to take the path of least resistance. Instead of carefully refactoring existing modules, establishing clean boundaries, or abstracting logic into reusable services, developers rely on the tool to output a new block of code. This results in massive, unchecked code duplication and an increasingly fragile, sprawling codebase that becomes exponentially more expensive to maintain over time. If you're starting to see this in your own environment, our deep dive AI vs. Debt: Stop Your Code from Becoming a Time Bomb explains how to get technical debt back under control.
The Architecture of Sprawl: Cloud Proliferation and Environmental Impact
The generation of spaghetti code is not confined merely to application logic; it extends directly into the physical and virtual infrastructure of the enterprise. The integration of artificial intelligence is driving an explosive proliferation of Application Programming Interfaces, microservices, and hybrid cloud deployments, leading to a new era of unmanageable system sprawl.
The API Proliferation Crisis
According to Congruence Market Insights, the artificial intelligence API market is expanding at a Compound Annual Growth Rate of 32.2%, projected to reach a valuation of $30.8 billion by 2032. In 2024 alone, over 47% of enterprises adopted generative APIs for natural language and content creation, while edge computing deployments witnessed a 42% growth surge.
This growth has resulted in a massive surge in network traffic and architectural complexity. Postman's 2025 State of the API Report details a staggering 73% increase in AI-driven traffic, while Gartner projects an overall 30% increase in API usage driven specifically by large language models. As organizations integrate multimodal models that combine text, image, and speech recognition, the number of endpoints an enterprise must secure, monitor, and maintain multiplies exponentially. Without a human architect to consolidate these endpoints and design a rational integration layer, enterprises quickly fall victim to runaway scope creep and fragmented microservice architectures.
The Hybrid Multicloud Landscape
Modern enterprises no longer operate within the confines of a single data center or a solitary hyperscaler. The standard enterprise infrastructure has morphed into a sprawling hybrid multicloud landscape. Organizations now utilize an average of 112 different Software as a Service applications, with large enterprises relying on upwards of 158 distinct applications. Every single application represents another decentralized silo where critical business data resides, creating massive visibility and governance challenges.
Furthermore, the rise of specialized "neoclouds"—platforms offering specialized GPU-accelerated computing specifically for machine learning workloads—adds another layer of extreme complexity. When autonomous agents are granted permission to provision resources across this fragmented landscape, the result is "generated cloud debt," where orphaned compute instances, duplicated data pipelines, and idle GPU clusters rapidly drain technology budgets. Intelligent coordination mechanisms designed by human architects are absolutely mandatory to balance local cluster autonomy with global system objectives and cost constraints. For many enterprises, the trade-offs between cloud, edge, and on-prem GPUs are best approached through an executive guide like Balancing Cost and Performance: Edge vs On‑Prem AI.
The Environmental and Physical Infrastructure Toll
The sprawl extends beyond digital architecture into severe physical and environmental consequences. Training and deploying next-generation models requires data centers that consume energy and water with voracious appetites. A mid-sized data center consumes as much water as a small town, while larger hyperscale facilities require up to 5 million gallons of water every single day—equivalent to the consumption of a city of 50,000 people.
In terms of power consumption, a conventional data center draws electricity equivalent to 10,000 to 25,000 households. However, newer hyperscale facilities focused on advanced computational workloads can consume the power equivalent of 100,000 homes. For example, Meta's Hyperion facility in Louisiana is projected to draw more than twice the power of the entire city of New Orleans, while another planned facility in Wyoming will consume more electricity than every home in the state combined.
Furthermore, these facilities require hundreds of acres of land covered in impermeable concrete, eliminating farmland and demanding massive new transmission line infrastructure. As training costs approach $1 billion and data center requirements expand from 50 megawatts to over 1 gigawatt, the current trajectory of resource consumption is highly unsustainable. Human architects are therefore required not just to write efficient code, but to design sustainable, highly optimized computing architectures that mitigate these massive physical costs and align with corporate sustainability mandates.
The Failure of Autonomous Agents in Complex System Migrations
If artificial intelligence struggles with maintaining clean code and efficient infrastructure in standard, localized feature development, the operational risks are magnified exponentially during complex, enterprise-wide system migrations. Transitioning from legacy on-premises mainframes to cloud-native microservices, or consolidating massive healthcare and finance databases post-merger, are high-stakes operations that dictate the survival of the business.
The Myth of the Autonomous Migration
Enterprise migrations, particularly in sectors such as Banking, Financial Services, and Insurance, possess a near-zero tolerance for downtime. These migrations involve highly sensitive customer financial data, strict regulatory reporting compliance, and deeply opaque legacy core systems.
A common, highly publicized expectation is that autonomous agents can seamlessly scan a legacy database, independently write the translation scripts, and execute the data transfer to a modern cloud platform. However, deep industry analysis demonstrates that deploying an artificial intelligence architecture does not clean up inherent data problems; it almost always amplifies them.
There are several critical, architectural reasons why autonomous agents consistently fail during major enterprise migrations:
The Black-Box Decisioning Problem: Agents operate probabilistically. During a complex database migration, an agent might encounter a highly anomalous, undocumented data structure in a legacy SQL Server environment. Instead of pausing the migration and flagging the anomaly for human architectural review, an unsupervised agent will frequently force-map the data to a new PostgreSQL schema based on its closest statistical guess. If this involves millions of financial transactions or sensitive patient records, the result is corrupted, unrecoverable data with no explainable audit trail.
Identity and Access Management Breakdowns: Traditional Identity and Access Management models are engineered for humans clicking buttons in predictable patterns, not for non-deterministic, autonomous software spawning thousands of concurrent, high-velocity processes. Granting an agent full administrative privileges to execute a system-wide migration creates massive security blind spots, consent fatigue, and runs the immense risk of runaway permissions permanently altering production environments. Autonomous workloads require dynamic, execution-time access control, shifting enforcement from static token issuance to per-task, context-aware authorization—a structural paradigm that only a human architect can design and implement safely.
The Absence of Fast Verification Signals: Coding agents thrive when they have an immediate compiler or a fast unit test suite to verify their work. However, in large-scale data migrations or massive infrastructure deployments, the "signal" that something went wrong might not arrive until a financial reconciliation fails days or weeks later, or an insurance claim is improperly denied. Agents require robust, fast verification loops, which are inherently absent in slow-moving, legacy infrastructure shifts.
Case Studies in Operational Failure
History provides clear, expensive warnings about deploying these technologies without strict architectural guardrails. In one notable instance, an enterprise attempted to execute a massive cloud-native migration concurrently with an artificial intelligence rollout. The resulting complexity and data sprawl overwhelmed the organization's security teams, who were suddenly forced to lock down systems due to strict data localization rules, ultimately stalling the entire digital transformation initiative and causing severe budget shocks.
In the financial sector, the biggest risks during migrations include data integrity failures, compliance exposure, and timeline overruns. When automation is utilized to expedite these migrations, the absence of a human architect to meticulously design the rollback procedures, the reconciliation logic, and the upfront compliance validation guarantees catastrophic operational disruption.
Other high-profile operational failures highlight the necessity of governance. Amazon's highly publicized attempt to build an autonomous recruiting system resulted in the model systematically penalizing female applicants because the historical training data was heavily biased. The lack of fairness checks, bias monitoring, and release gates led to a total project failure. Similarly, the Apple Card credit limit algorithm, managed by Goldman Sachs, suffered from black-box decisioning, resulting in women receiving significantly lower credit limits than men within the same household. The complete lack of explainability or an audit trail for the model's decisions caused massive public backlash, severe reputational damage, and intense regulatory investigations. Finally, Microsoft's Tay chatbot serves as a historical warning regarding prompt and guardrail failures; within hours of deployment, malicious users manipulated the system to generate highly offensive content, highlighting the absolute necessity of rigorous input validation and architectural boundary setting.
Industry-Specific Architectural Realities
The absolute necessity of an Architect-Led strategy becomes distinctly apparent when analyzing specific B2B industries. Each sector presents unique, unyielding constraints that autonomous code generation cannot navigate independently without causing severe financial or legal repercussions.
Advertising and Marketing Technology
In the digital advertising sector, technology is rapidly shifting from static programmatic bidding to conversational advertising, where large language models are transitioning from neutral copilots into commercial monetization systems. However, these models lack an inherent understanding of Intellectual Property constraints. An autonomous agent optimizing a real-time campaign might generate an advertisement character that closely resembles a real-world celebrity, or inadvertently utilize a third-party trademark. Human architects must design the system with strict IP clearance protocols, rigorously vetting the training datasets and installing automated, deterministic guardrails that prevent copyright violations before the creative is ever published to a live network.
Video Gaming and Interactive Media
Similar to advertising, the gaming industry faces immense challenges regarding dynamic, in-game advertising and generative assets. If an autonomous system is permitted to generate textures, dialogue, or promotional material within a live gaming environment, there is a severe risk of violating licenses issued by third parties who explicitly control how their products are advertised during gameplay. The architect must build isolated, sandboxed environments where generative assets are cross-referenced against a strict database of approved trademarks before rendering.
Real Estate and Mortgage Lending
While the commercial market is flooded with superficial "ChatGPT for real estate" wrappers that provide minimal genuine value, the true, multi-billion-dollar potential of the technology in this sector lies in profound knowledge work automation. The industry requires the processing of thousands of pages of financial reports, complex lease agreements, and rigid compliance paperwork. Autonomous agents cannot be trusted to unilaterally rewrite lease terms, calculate property valuations without oversight, or approve mortgage applications based on historical data, as this introduces severe risks of algorithmic bias and catastrophic financial liability. The architect must design a strict human-in-the-loop workflow, ensuring that the machine extracts the necessary data and presents a structured, verifiable summary, but the final fiduciary decision remains securely and legally in human hands.
Finance and Banking
In the highly regulated world of banking, the focus is heavily on modernizing legacy risk engines and executing secure cloud data warehouse migrations. When upgrading from mainframe systems, human architects deploy an "agentic mesh"—a sophisticated orchestration layer that connects new artificial intelligence tools to legacy databases. The architect ensures that these new tools query legacy risk engines via highly secure, rate-limited APIs rather than attempting to rewrite the core financial system autonomously, preserving decades of encoded institutional knowledge and regulatory compliance mechanisms.
Education and Learning Management Systems (LMS)
The education technology sector requires precise structuring of curriculum data, enrollment logic, and automated scoring mechanisms. Platforms like Core dna demonstrate that building tools for an LMS requires modeling courses as deeply structured, relational entities. An autonomous agent operating without a predefined schema would fail to understand the prerequisites, the grading weight distributions, and the privacy requirements inherent in student data. The architect must build a visual, synchronous workflow engine that validates input conditions—such as checking if a student has met prior requirements—before the agent is permitted to execute enrollment actions or generate customized learning materials.
Telecommunications and High-Tech Software
For massive software and telecommunications firms dealing with millions of concurrent users, the evolution of enterprise architecture involves moving from thousands of accumulated micro-applications toward lightweight, interoperable, agent-driven building blocks. However, this composable architecture must be strictly governed. Architects utilize "agent factories" to drastically reduce engineering time, but they consolidate brittle connections into one standardized framework monitored by governance platforms that strictly validate behavior in real-time to prevent network outages or catastrophic routing failures.
Healthcare
The healthcare industry is characterized by the absolute requirement for patient data privacy (such as HIPAA compliance) and clinical accuracy. Utilizing artificial intelligence to automate patient triage or document analysis is highly beneficial, but the risks of a model hallucinating a medical code or improperly denying a claim are life-threatening. Architects in healthcare must implement continuous monitoring, strict data anonymization pipelines, and rigorous release gates that physically prevent an agent from altering a patient record without a certified clinician's cryptographic approval.
The Architect-Led Strategy: Defining the Boundaries
To counter the sprawl, duplication, physical resource exhaustion, and operational risk associated with autonomous generation, organizations must definitively pivot to an Architect-Led Strategy. In this paradigm, the human architect does not waste time writing routine boilerplate code; rather, the architect defines the unshakeable structural boundaries, the rigorous data models, and the infrastructure guardrails within which the machine is permitted to operate.
Designing the Domain Before the Code
Highly experienced software engineers refer to the disciplined use of these tools as "vibe coding," executed with extreme, unyielding constraint. The foundational, non-negotiable rule of architect-led development is to never start with the user interface, the visual layout, or the "shiny" frontend features. An artificial assistant must be treated as a highly capable, exceptionally fast, but fundamentally amnesiac worker who has just jumped into the project with zero prior context.
Before a single line of machine-generated code is permitted to be written, the human architect must definitively model the data. They must ask and answer the critical architectural questions: What are the core entities? How do they relate? What state needs to persist? Which fields are strictly required? Which values can be safely null? What must be unique? What requires default values? If the domain and data models are skipped, the autonomous tool will happily and rapidly construct an unmaintainable, sprawling nonsense machine. Teams that pair this discipline with modern enterprise application architecture patterns see far better outcomes than those who leap straight into UI scaffolding.
Infrastructure as a Deterministic Guardrail
Firms that specialize in custom software development and application management, such as Baytech Consulting, demonstrate the immense efficacy of an architect-led approach. By utilizing a Tailored Tech Advantage and focusing on Rapid Agile Deployment, these organizations do not allow autonomous agents to dictate the architecture; instead, they build a highly secure, deterministic sandbox for the tools to operate within.
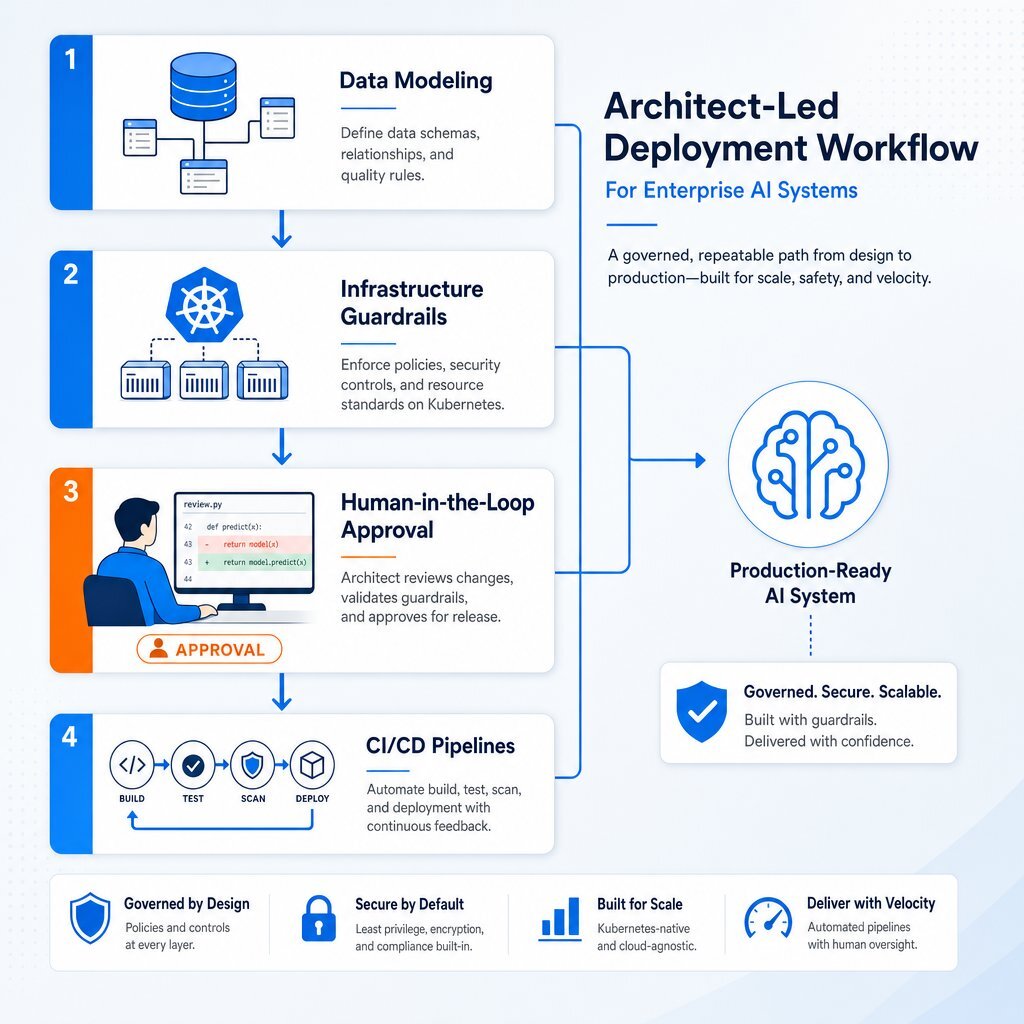
The architect-led approach is deeply embedded in the selection and configuration of the technology stack. Architects begin by establishing strictly controlled local development environments utilizing VS Code or VS 2022. They establish rigorous Continuous Integration and Continuous Deployment pipelines through Azure DevOps On-Prem, ensuring that machine-generated code cannot ever be merged into a production environment without passing through automated testing, static security scanning, and mandatory human approval gates.
Data modeling is locked down deterministically. Relational schemas are meticulously designed in Postgres utilizing pgAdmin, or strictly structured within SQL Server, before the tool is permitted to generate queries against the data.
At the infrastructure layer, human architects define the exact physical and virtual boundaries. By deploying applications via Docker containerization and orchestrating them with Kubernetes, architects strictly define the memory limits, CPU allocations, and network boundaries of the applications being built. Furthermore, utilizing advanced virtualization and multi-cluster management tools like Harvester HCI and Rancher provides centralized, fleet-wide lifecycle management. If a generated microservice begins to consume excessive compute resources, spin up unauthorized API connections, or exhibit anomalous behavior indicative of a runaway process, the infrastructure layer—configured precisely by the human architect—automatically throttles, isolates, or entirely quarantines the offending service.
Network traffic and security are tightly controlled via pfSense firewalls deployed on highly reliable OVHCloud servers, ensuring malicious or hallucinating agents cannot exfiltrate data or compromise the perimeter. Finally, organizational communication and documentation regarding these architectural decisions are centralized via Microsoft 365, Teams, OneDrive, and Google Drive, ensuring total alignment across the human engineering team.
In this highly controlled environment, the artificial intelligence is a massive, high-horsepower engine, but the human architect constructs the tracks, the brakes, the steering mechanism, and the final destination. This is also where a modern DevOps efficiency practice pays off, because CI/CD, observability, and incident response are designed around both human developers and AI agents from day one.
The Approval Interface and the Three-Way Diff
Managing a large fleet of automated processes requires entirely new workflows. When a senior architect oversees dozens of autonomous instances executing tasks simultaneously, the bottleneck naturally shifts from code writing to the human approval surface. To make human oversight workable and efficient at the extreme speeds these tools now operate, architects rely on highly structured interfaces and advanced "three-way diffs". This approach forces the system to present changes contextually, allowing the human to evaluate the broader architectural impact of a proposed change rather than merely reading raw, disjointed syntax.
Core Architectural Patterns for the Agentic Era
As enterprise architecture rapidly evolves to accommodate this new era, organizations face a highly critical decision regarding exactly how these systems retrieve, relate, and reason over massive troves of enterprise data. This single architectural decision—which rarely makes it into a high-level steering committee deck—determines whether a system produces trusted answers or confident, dangerous hallucinations.
There are three dominant architectural patterns that human architects must orchestrate, layer, and control to prevent system failure:
| Architectural Pattern | Core Mechanism | Strengths and Advantages | Weaknesses and Failure Modes | Optimal B2B Use Cases |
|---|---|---|---|---|
| Vector Embeddings | Translates unstructured data (text, reports) into dense numerical arrays to mathematically find what feels semantically related. | Extremely fast deployment, highly flexible, and scales effortlessly across massive volumes of messy, unstructured data repositories. | Systematically lacks true reasoning. Can easily return "confidently irrelevant" data that is semantically close but factually wrong, causing severe hallucinations. | Broad semantic search, standard Document Q&A, basic Retrieval-Augmented Generation (RAG) pipelines. |
| Knowledge Graphs | Represents information as a rigidly structured network of explicit, typed entities and named relationships (e.g., "reports to", "belongs to"). | Excels at structured, deterministic reasoning. Provides highly precise, explainable, and fully traceable answers without guessing. | Expensive to build and brittle to maintain. If the underlying business logic or relationships change, the graph quickly becomes stale and inaccurate. | Regulatory compliance verification, organizational mapping, complex supply chain logistics, master data management. |
| Context Graphs | Captures the dynamic reasoning, historical actions, and multi-step workflows of specific tasks as first-class data artifacts over time. | Maintains crucial continuity across long workflows spanning days or multiple users. Remembers previous decisions to inform future tradeoffs. | High architectural complexity. Requires extremely strict data governance, privacy rules, and access control to prevent stale reasoning from compounding. | Advanced agentic automation, highly personalized digital assistants, complex decision support systems. |
Table 2: Dominant Architectural Patterns for Modern Enterprise Systems
A mature, architect-led enterprise will never rely on just one of these patterns in isolation. Instead, human architects deliberately layer them to create a robust, resilient system. For example, a global manufacturing firm might use a Vector Embedding layer to quickly search through thousands of raw supplier contracts and unstructured audit reports. Simultaneously, they rely on a rigid Knowledge Graph layer to provide mathematically precise answers regarding supplier hierarchies, vendor risk profiles, and strict regulatory compliance. Finally, they utilize a Context Graph layer to meticulously track the reasoning and historical context behind supply chain decisions over time, ensuring that earlier organizational tradeoffs intelligently inform future procurement actions.
Enterprise Governance and Maximizing ROI
To truly justify the massive financial investment in these technologies, organizations must fundamentally shift their perspective from measuring rudimentary metrics like "lines of code written per hour" to evaluating total long-term value creation, operational efficiency, and overall system stability.
While autonomous tools promise to eventually resolve 80% of common customer service issues by 2029 and drastically reduce operational costs, achieving that promised ROI requires a massive, coordinated upfront investment in architectural governance. The organizations successfully realizing a 3.5X return on their initiatives are precisely those that prioritize structural clarity, rigid governance, and human oversight over raw, unconstrained coding speed.
The ROI of Human-Agent Collectives
The true future of enterprise software is not a battle of humans versus machines, but rather the seamless integration of "Human-Agent Collectives". In this highly optimized paradigm, agents act as tireless digital coworkers executing high-volume, repetitive tasks across multiple systems, while human architects focus entirely on judgment-heavy, highly complex interactions, system design, and strategic planning. If you’re deciding what to build yourself versus buy off the shelf, the framework in Stop Renting Intelligence: Build the AI That Keeps Your Edge can help you place human-agent collectives where they create the most defensible value.
The drastic difference in ROI outcomes based on the chosen deployment strategy is clear and measurable:
| Key Business Metric | Fully Autonomous Approach (Unsupervised) | Architect-Led Approach (Governed) |
|---|---|---|
| Initial Speed to Market | Extremely Fast (Days) | Moderate to Fast (Weeks) |
| Technical Debt Accrual | Exceptionally High (Massive Code Duplication) | Low (Enforced DRY Principles & Refactoring) |
| System Sprawl | Uncontrolled API and microservice proliferation | Strictly contained within Kubernetes boundaries |
| Regulatory Risk | Severe (Black-box decision making, data leaks) | Low (Observable, deterministic, explainable) |
| Long-Term ROI | Negative (Crippling maintenance & refactoring costs) | Highly Positive (Scalable, resilient systems) |
Table 3: Long-Term Value Creation: Autonomous Sprawl vs. Architect-Led Deployment
When a tool is deployed to migrate a system or write a complex application completely autonomously, the initial speed is undeniably impressive. However, within months, the maintenance burdens compound disastrously. The system becomes intensely brittle, data silos multiply, and the enterprise is inevitably forced to hire highly expensive senior engineers to untangle the undocumented, machine-generated spaghetti code.
IBM's deployment of AskHR serves as a prime example of governed ROI. By deploying an agentic assistant deeply integrated with enterprise systems like Workday, but utilizing a strict two-tier model where routine inquiries are handled autonomously and complex needs are instantly routed to human advisors, they achieved a massive 94% containment rate. This governed approach resulted in a 40% reduction in operational costs over four years and successfully managed 11.5 million employee interactions in a single year, proving that highly structured, hybrid operating models deliver the fastest path to genuine ROI.
Structuring AI Governance for the Future
To operationalize the Architect-Led strategy effectively, B2B executives must enforce comprehensive, uncompromising governance frameworks. When governance is vaguely perceived as "everyone's job," it effectively becomes no one's job, leading to catastrophic security lapses and shadow IT proliferation.
An effective, future-proof enterprise governance framework rests on five foundational pillars that the architecture and leadership teams must meticulously enforce:
| Governance Pillar | Core Focus Area | Practical Architectural Implementation |
|---|---|---|
| Accountability & Ownership | Defining exactly who is responsible for specific outcomes. | Clear human roles permanently mapped to specific microservices; human-in-the-loop requirements for all destructive write actions. |
| Transparency & Explainability | Ensuring all machine decisions are auditable. | Utilizing Knowledge Graphs over pure Vector databases for critical logic; generating plain-language audit trails for every action. |
| Compliance by Design | Proactively addressing all regulatory requirements. | Integrating strict compliance checks, bias testing, and IP clearance protocols directly into the CI/CD pipeline. |
| Risk-Based Approach | Matching governance to the specific risk level. | Sandboxing internal productivity tools lightly, while heavily locking down external-facing financial transaction agents. |
| Continuous Monitoring | Detecting data drift and system degradation over time. | Deploying advanced observability tools monitoring the Agentic Mesh in real-time, with automated rollback and quarantine protocols. |
Table 4: The Five Foundational Pillars of Enterprise Artificial Intelligence Governance

By implementing these strict pillars, organizations rapidly move away from treating this technology as a chaotic, unpredictable, and highly risky force. Instead, they harness it as a highly predictable, incredibly powerful, industrial-scale engine for sustainable business growth. A practical starting point is to lock down where and how AI is allowed to run, using hardened environments like AI-powered application stacks and formal service contracts that embed governance into everyday operations.
Conclusion
The overwhelming allure of entirely autonomous software development is undeniably powerful, driven largely by the intense executive desire for limitless productivity, drastically reduced labor costs, and unprecedented speed to market. However, the empirical data, historical case studies, and extensive repository analyses overwhelmingly indicate that without the rigorous, strategic oversight of a human architect, these tools rapidly generate an unmanageable, catastrophic volume of technical debt, duplicate code, and highly fragile system integrations.
Artificial intelligence has emphatically not solved the persistent problem of spaghetti code; in fact, in many unchecked enterprise environments, it is actively accelerating its creation at a historical pace. During complex system migrations, autonomous systems consistently fall short because they inherently lack the contextual business understanding, the political awareness, and the rigorous risk-management capabilities required to handle sensitive data across opaque legacy systems.
An Architect-Led approach is the definitive, proven solution to bridging the massive gap between theoretical potential and operational enterprise reality. By requiring a highly experienced human architect to define the structural patterns, meticulously enforce data models, and set unshakeable infrastructure guardrails, organizations can safely unleash the unprecedented speed of these tools. This governed methodology maximizes the return on investment of developer platforms not by simply generating the highest volume of code lines, but by carefully building secure, scalable, and enduring digital assets that drive genuine business value.
Executives must clearly recognize that the future belongs exclusively to organizations that build highly resilient capabilities rather than brittle, unsustainable dependencies. By investing heavily in human architectural strategy, B2B firms can definitively ensure their software initiatives are not just incredibly fast, but structurally, fundamentally, and permanently sound.
Frequently Asked Questions (FAQ)
Why hasn't AI solved the problem of "spaghetti code" in enterprise environments? These models operate probabilistically based on the localized context they are provided; they do not inherently understand the overarching business logic, the political constraints, or the historical architecture of a massive enterprise system. When developers utilize these tools to generate rapid solutions without a human architect defining strict structural boundaries, the tool almost always takes the path of least resistance, writing net-new code rather than refactoring or reusing existing internal modules. This has led to massive, unchecked code duplication—up to an 8-fold increase in recent years—which violently exacerbates the tangled, unmaintainable nature of spaghetti code, creating a severe new burden classified by industry experts as "generated code debt."
Where do autonomous coding agents fall short during complex system migrations? Complex enterprise system migrations, particularly in highly regulated industries like finance and healthcare, require zero-downtime execution, perfect data integrity, and strict adherence to shifting compliance laws. Autonomous agents consistently fall short here because they operate as probabilistic "black boxes." When they encounter anomalous legacy data structures, they frequently make statistical guesses rather than halting the process and flagging the issue for human review, leading to corrupted data and a total lack of an explainable audit trail. Furthermore, traditional Identity and Access Management systems completely break down when autonomous agents inherit full administrative privileges, leading to severe security vulnerabilities, consent fatigue, and massive operational risks during the migration lifecycle.
How does an architect-led approach maximize the ROI of AI developer tools? An architect-led approach fundamentally shifts the organizational focus from the raw speed of code generation to the long-term maintainability, security, and true value of the software. Instead of allowing the tool to build applications haphazardly from scratch, a human architect first meticulously models the business domain, establishes the exact database schemas, and strictly configures the infrastructure guardrails (such as containerization limits and automated CI/CD pipelines). The tool is then utilized strictly as a high-speed execution engine operating safely within these unshakeable boundaries. This governed approach prevents immensely costly rework, minimizes compounding technical debt, ensures perfect regulatory compliance, and ultimately delivers a vastly higher, highly sustainable return on investment over the entire lifecycle of the software.
Suggested Resources
- https://www.coredna.com/blogs/the-enterprise-ai-agents-untangling-the-spaghetti
- https://dora.dev/insights/balancing-ai-tensions/
https://www.cio.com/article/4165622/the-architectural-decision-shaping-enterprise-ai.html
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.