
Portability-First AI Strategy for Mid-Market CTOs and CFOs
May 23, 2026 / Bryan Reynolds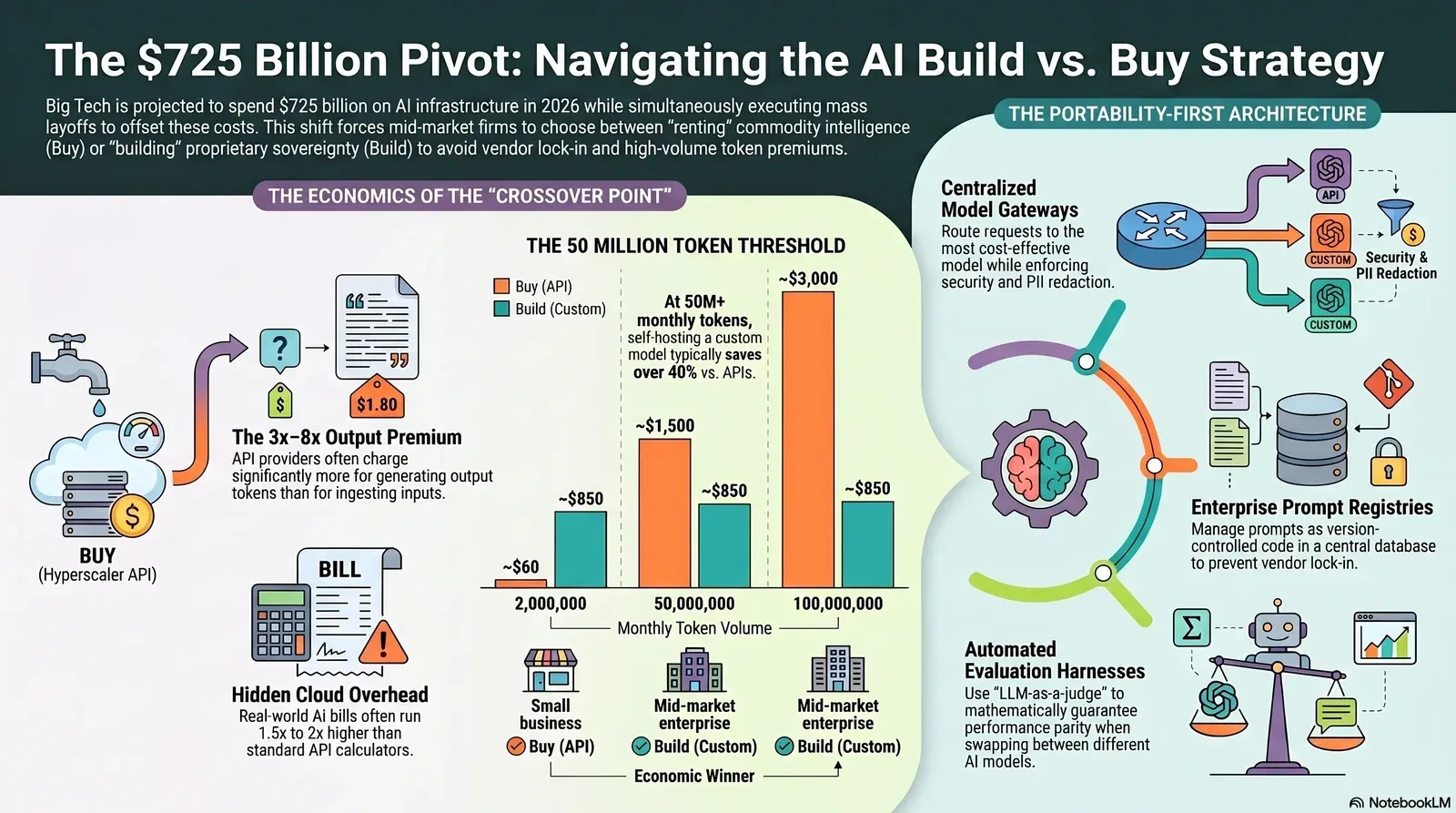
$725 Billion in AI Capex, Plus Layoffs: What Big Tech's 2026 Spending Means for Build-vs-Buy
Four technology conglomerates are projected to spend roughly $725 billion on artificial intelligence infrastructure in 2026, an amount exceeding the gross domestic product of all but twenty nations. Simultaneously, these same organizations are eliminating their own engineering and corporate jobs by the tens of thousands. This severe macroeconomic contradiction between record capital expenditure and aggressive workforce reduction serves as the most critical signal for mid-market technology leaders evaluating the AI build vs buy decision this year.
The conventional interpretation of these market mechanics suggests that "buying" commodity AI services is the sole logical path forward. If hyperscale providers are committing tens of billions of dollars to construct data centers, secure specialized memory components, and train frontier models, mid-market organizations seemingly have no rationale for building competing infrastructure. However, a sharper analysis of the underlying cloud economics reveals a more complex reality. When highly concentrated capital expenditure collides with structural labor reallocations, three market forces activate concurrently: the per-token cost of commodity inference compresses, the risk of vendor lock-in intensifies, and highly specialized engineering talent exits Big Tech, becoming available to mid-market firms.
For mid-market Chief Technology Officers (CTOs) and Chief Financial Officers (CFOs), the optimal strategy is neither pure-build nor pure-buy. The sustainable approach relies on a portability-first architecture that treats foundation model selection as a runtime configuration rather than a permanent code commitment. This structural flexibility allows specific workloads to seamlessly alternate between custom, self-hosted models and commodity application programming interfaces (APIs) as unit economics and regulatory frameworks dictate quarter to quarter. If you are weighing how far to lean into custom development versus SaaS, it pairs well with our guide on why you should stop renting generic intelligence and build the AI that keeps your edge.
The $725 Billion Picture: Capital Over Human Resources
The scale of Big Tech's 2026 infrastructure commitment represents the most aggressive capital expenditure (capex) cycle the industry has ever recorded. An analysis of corporate guidance and earnings data reveals a combined infrastructure spend across Alphabet, Amazon, Meta, and Microsoft that ranges between $650 billion and $755 billion for the year, representing an 83% year-over-year jump according to Morningstar. This capital is driven almost entirely by the acquisition of specialized artificial intelligence hardware, data center facility expansion, power procurement, and memory components.
The distribution of this capital highlights the operational priorities of each hyperscale provider. Alphabet reported a blistering $35.7 billion in first-quarter capex alone and raised its 2026 capital expenditure guidance to between $180 billion and $190 billion, signaling clearly that expenditures will continue to rise significantly into 2027 from Marketwise report. Amazon expects its total capital expenditure to reach $200 billion for the year, a posture CEO Andy Jassy defended by stating the company refuses to be conservative in its AI infrastructure play.
Microsoft's CFO explicitly attributed $25 billion of its record budget solely to the rising costs of memory chips and components required to assemble graphics processing unit (GPU) clusters, noting the company will remain capacity-constrained through 2026. Meta similarly increased its outlook to a range of $125 billion to 145 billion, while concurrently disclosing a staggering 107 billion step-up in contractual commitments for network and cloud infrastructure executed in a single quarter Fast Company.
This unprecedented spending carries severe financial implications for the hyperscalers themselves. The combined free cash flow of these four entities is projected to plummet to roughly $4 billion in the third quarter of 2026, down from a post-pandemic historical average of $45 billion per quarter. To finance these hardware ambitions while attempting to protect shareholder returns, these organizations are executing severe structural reorganizations.
The Mechanics of the 2026 Technology Layoffs
The narrative that hyperscalers are reducing headcount due to macroeconomic weakness is demonstrably incorrect. The reductions are a deliberate mechanism to offset the soaring costs of AI infrastructure. Big Tech's view of margin generation has fundamentally shifted: future revenue will be decoupled from human headcount and tethered directly to compute capacity.
Meta provides the clearest articulation of this strategy. In May 2026, the company eliminated approximately 8,000 positions. Meta's Chief Financial Officer directly linked these reductions to the company's $145 billion infrastructure budget, framing the workforce reduction as necessary to offset the substantial investments required to remain competitive in AI model training. The financial disparity is stark: Meta's AI capital expenditure is currently estimated at four to five times the company's total human compensation budget. Even if the company replaced its entire workforce with automation, the resulting payroll savings of roughly $27 billion would only represent a fraction of the required infrastructure spend. The limiting constraint on enterprise growth is no longer engineering talent; it is access to compute power and the electricity required to operate it.
Similar reallocations are visible across the sector. Amazon eliminated roughly 30,000 corporate roles over a five-month period spanning late 2025 and early 2026, primarily targeting divisions like Alexa AI, Prime Video, and Amazon Pharmacy. Concurrently, Amazon announced plans to hire 11,000 software developers and engineers to support its Amazon Web Services (AWS) operations, demonstrating a targeted skill recalibration rather than a general reduction People Matters. Microsoft executed the first voluntary buyout program in its 51-year history, making approximately 125,000 U.S. employees eligible for early retirement packages, yet explicitly excluded teams working directly on AI and Copilot integration from the offer Computerworld.
For mid-market enterprises, this dynamic generates two immediate benefits. First, the displacement of specialized talent—including machine learning operations (MLOps) engineers, infrastructure architects, and data platform builders previously hoarded by Big Tech—floods the labor market with candidates capable of building custom, self-hosted infrastructure Kore1. Second, the hundreds of billions of dollars poured into hyperscaler data centers drastically accelerates the commoditization of base-level AI capabilities. For leaders thinking about where to redeploy that talent, our overview of AI automation that turns busywork into durable enterprise workflows offers concrete use cases.
What This Means for Commodity AI Pricing and Lock-In
The most direct consequence of a $725 billion AI capex cycle is a rapid deflation in the raw cost of standard intelligence. As hyperscalers bring massive GPU clusters online, they offset their capital costs by aggressively discounting the APIs required to access their hosted models. Mid-market organizations evaluating an AI build vs buy decision must understand that the baseline cost of "buying" commodity inference is compressing, but the pricing structures are increasingly weaponized to encourage platform lock-in. This is also reshaping entire software markets, a trend we explored in more depth in our analysis of how AI is driving the 2026 “SaaSocalypse” and forcing new pricing models.
By mid-2026, the pricing structures across AWS Bedrock, Azure AI Foundry, Google Vertex AI, and standalone providers like Anthropic and OpenAI have fractured into highly tiered ecosystems. The market no longer prices general intelligence at a single rate; instead, pricing is dictated by context length, latency requirements, and the ratio of input parameters to generated outputs Go-Cloud.
The Input-to-Output Pricing Asymmetry
The prevailing billing mechanism across all major providers relies on a per-token system that routinely masks the true cost of production applications. Organizations commonly calculate expected costs based on advertised input token rates while failing to account for the massive premium applied to output generation.
Across nearly all frontier and mid-tier models, output tokens cost between three and eight times more than input tokens. For example, Anthropic's Claude 3.5 Sonnet on AWS Bedrock charges $3.00 per million input tokens but $15.00 per million output tokens Medium. OpenAI's GPT-4o Mini, frequently marketed at a highly attractive $0.15 per million input tokens, charges $0.60 per million output tokens Cloudidr. For premium configurations, the disparity is even wider; specialized models like OpenAI's GPT-5.2 Pro can demand up to $168 per million output tokens, making verbose text generation or complex code synthesis exceptionally expensive at scale.
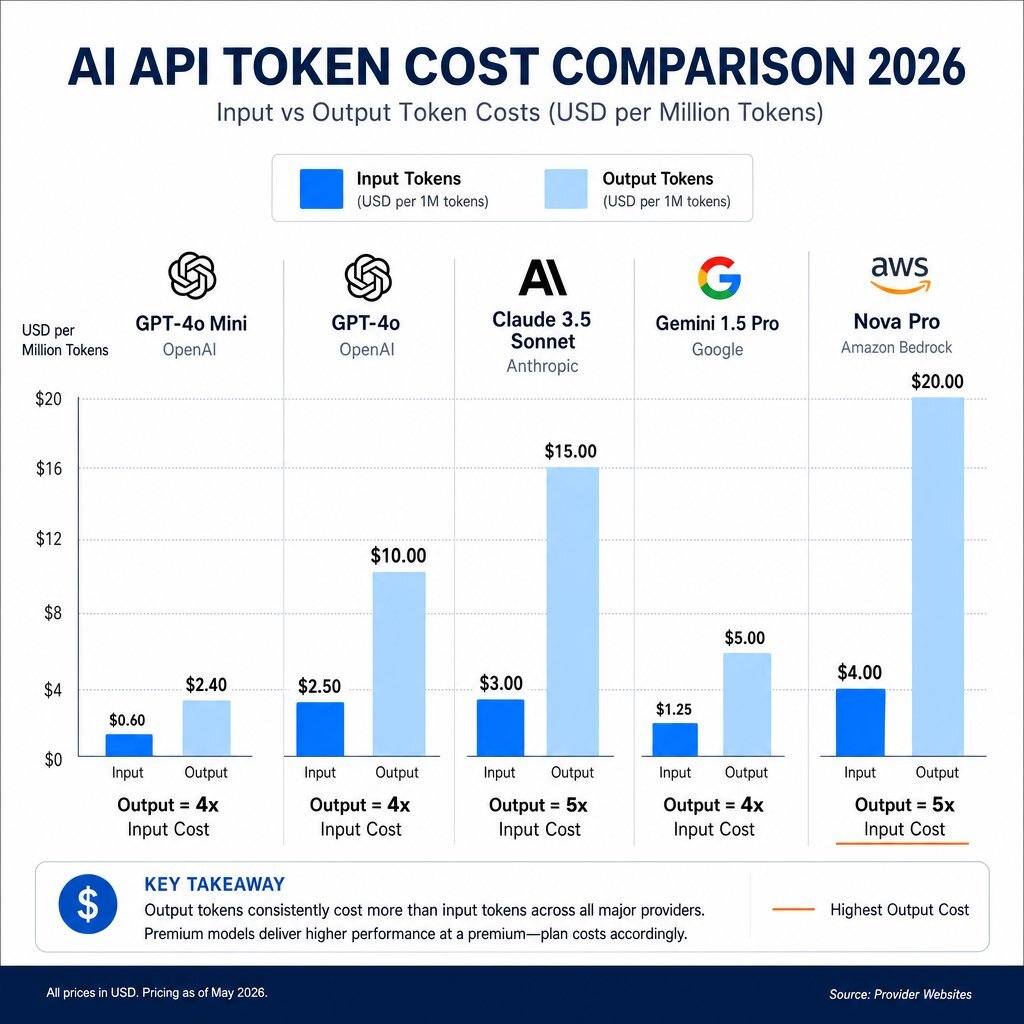
A conversational agent or analytical pipeline that ingests small prompts but generates extensive responses will immediately deviate from standard financial models. A mid-market firm processing 20 million tokens per month might model costs assuming a balanced input-to-output ratio, only to discover that 80% of their volume consists of high-margin output generation, driving actual expenditures exponentially higher than forecasted. For CFOs who need to make this math concrete, our finance-first framework on reframing AI ROI and justifying tech investments walks through payback and TCO step by step.
The Hidden Costs of Cloud AI Integration
Analyzing raw token pricing ignores the structural overhead required to operate a production-grade AI application. Industry data indicates that real-world cloud AI bills run 1.5 to 2 times higher than the figures generated by standard API calculators Medium. A mid-market organization budgeting $50,000 annually for AWS Bedrock or Google Vertex usage will frequently incur closer to $85,000 to $100,000.
These overruns stem from seven specific operational realities inherent to the "buy" strategy:
- Iterative Testing and Experimentation: Prompt engineering and pipeline validation require thousands of trial executions. Development environments consume substantial token volumes before an application ever reaches production.
- Failure Rates and Automated Retries: Network latency, timeouts, and API rate limits result in a baseline failure rate of approximately 6%. Because failed requests still incur charges, and automated retry logic amplifies the request volume, operational friction directly inflates billing.
- Continuous Optimization: Conducting A/B testing to compare model performance—such as evaluating Anthropic's Haiku against Sonnet—requires duplicating inference workloads.
- Surrounding Infrastructure: Cloud platforms do not operate APIs in a vacuum. Routing requests through services like AWS API Gateway, preparing payloads via serverless functions, and logging transactions in cloud storage all generate ancillary charges.
- Observability Overhead: Storing detailed execution traces and telemetry data to monitor for hallucinations or model drift requires high-volume database reads and writes.
- Capacity Provisioning for Peaks: Organizations relying on on-demand pricing face severe latency during peak traffic periods. Securing guaranteed throughput requires transitioning to provisioned capacity models, which demand rigid financial commitments regardless of actual utilization.
- Multi-Region Failover: Ensuring high availability often mandates duplicating provisioned throughput across distinct geographic zones (e.g., US East and EU Central) to protect against localized data center outages, immediately increasing costs by roughly 30%.
While the $725 billion AI capex environment drives raw token prices downward, the complexity of integrating these tokens into an enterprise architecture ensures that hyperscalers extract substantial revenue through auxiliary cloud services. Consequently, the decision to purchase AI capabilities off-the-shelf remains viable for many use cases, but it is not inherently cost-effective at high volumes without aggressive architectural management.
The AI Build vs Buy Decision Tree: Four Scenarios for Custom Ownership
The historical dichotomy between building custom software and purchasing commercial off-the-shelf products has evolved. In 2026, acquiring artificial intelligence capability is an architectural decision involving foundation models, retrieval pipelines, specialized fine-tuning, and complex agent orchestration Forbes. If you are weighing this for a broader modernization push, it dovetails with our comparison of top enterprise software development partners that help de-risk IT modernization.
Because hyperscaler capex drives the price of basic reasoning toward zero, utilizing embedded AI within existing software-as-a-service platforms or making standard API calls to OpenAI and Anthropic is the correct default action for undifferentiated tasks. An organization requiring document summarization, basic sentiment analysis, or standard drafting assistance should reliably default to "buy."
However, delegating intelligence to a hyperscaler introduces distinct vulnerabilities: vendor lock-in, unannounced model deprecation, and exposure to data processing agreements that may violate regional compliance standards. To determine when to bypass commodity APIs in favor of a self-hosted or fully custom-built foundation model, technology executives should evaluate workloads against four strict criteria.
1. The Regulatory and Data Residency Mandate
If an organization operates in a highly regulated sector—such as healthcare, defense, financial services, or European public administration—sending unredacted payloads to a third-party API is frequently prohibited. Regulations governing data minimization, purpose limitation, transparency, and cross-border data transfers actively constrain how enterprise data interacts with external endpoints HP. Self-hosting an open-weights model, such as Meta's Llama 3 or Mistral's Mixtral architecture, allows an organization to keep every byte of sensitive data within infrastructure it directly controls. This architectural separation simplifies compliance audits, avoids protracted negotiations over data processing agreements, and entirely eliminates the risk of an external provider utilizing proprietary data for future model training Alibaba Cloud. It also aligns with our guidance on containing Shadow AI risks with private, governed enterprise AI.
2. Latency-Bound Operational Workloads
Standard API endpoints are subject to network variability and "noisy neighbor" effects resulting from shared multi-tenant infrastructure. For use cases demanding strict real-time execution—such as high-frequency automated trading algorithms, autonomous robotics control, or instantaneous voice-to-voice customer service routing—the unpredictable latency of a cloud API is unacceptable. Building a custom inference stack on dedicated graphics processing units ensures deterministic response times. While dedicated infrastructure requires a higher baseline expenditure, it guarantees that critical operational paths are not delayed by a hyperscaler's capacity constraints during peak usage hours.
3. Highly Differentiated Intellectual Property
Relying exclusively on off-the-shelf APIs traps organizations in what industry analysts term the "Wrapper Trap." Companies that merely build thin interfaces over OpenAI or Google models pay premium prices for generic capabilities while offering zero defensive moats against competitors with access to the exact same models Forbes. If a specific business process represents a core competitive advantage, the intelligence driving it must be proprietary. Organizations achieve this by conducting supervised fine-tuning on open-source foundation models, utilizing proprietary operational data to adjust model weights. This creates an asset that no competitor can purchase via an API subscription, securing the firm's intellectual property and market differentiation. To keep that differentiation from eroding, it helps to pair this with the right developer productivity and quality metrics in an AI-heavy world.
4. Sustained High-Volume Inference Economies
The pay-per-token model functions as a retail markup on raw compute power. The provider prices the token to cover server depreciation, power usage, physical cooling, and corporate profit margins. For workloads experiencing unpredictable, bursty traffic, absorbing this markup is economically preferable to maintaining idle hardware. However, for organizations running continuous, high-volume extraction pipelines or orchestrating automated agent networks, token billing rapidly becomes the organization's largest singular operational expense. When token volume crosses a specific mathematical threshold, the unit economics decisively favor transitioning from rented APIs to self-hosted infrastructure.
Unit Economics: Locating the Hardware-to-API Crossover Point
Transitioning from hyperscaler API credits to sustainable internal infrastructure requires mathematical precision. The specific crossover point at which building and hosting a custom model becomes cheaper than paying a per-token API fee depends entirely on the efficiency of the organization's inference architecture and the physical cost of GPU instances in 2026.
The 2026 GPU Hardware Baseline
The baseline hardware for localized inference heavily relies on NVIDIA's advanced accelerator ecosystems. Procuring these resources via specialized cloud providers reveals massive price variance. As of mid-2026, renting an NVIDIA H200 instance on demand costs between $3.50 per hour on specialized platforms like Nebius and $13.78 per hour on major hyperscalers like Azure. More advanced NVIDIA B200 infrastructure displays a similar spread, with prices ranging from $2.25 per hour for heavily reserved, multi-year contracts, up to $14.24 per hour for on-demand access.
Furthermore, hyperscalers typically restrict access to these high-end accelerators by requiring customers to rent entire 8-GPU servers, pushing the hourly commitment beyond 80 to 113 per node Jarvislabs. An organization choosing to build and self-host its AI must ensure its workload can fully saturate the utilization of these highly expensive clusters. A GPU operating at 15% utilization generates catastrophic financial waste compared to standard API usage.
The Mathematical Break-Even Point
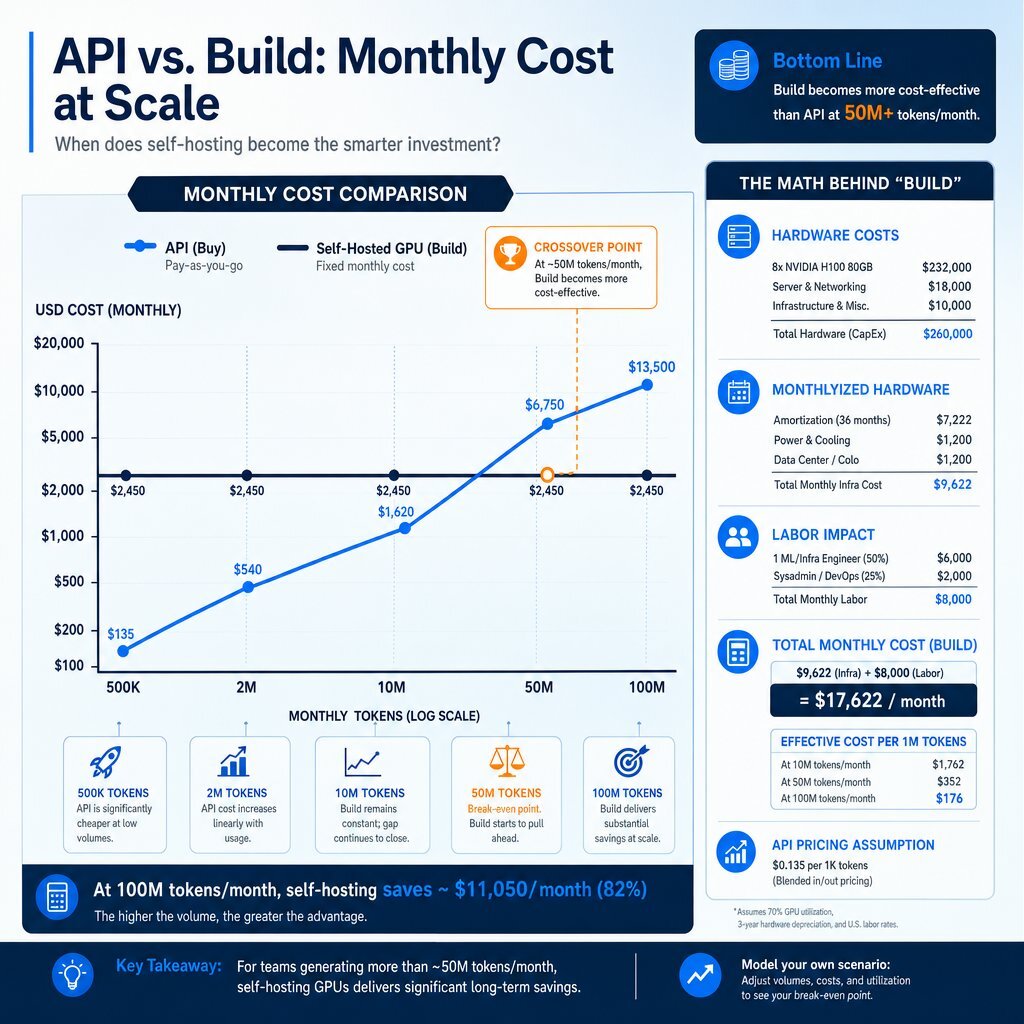
Assuming competent infrastructure orchestration that maintains a GPU cluster at approximately 70% utilization, the mathematical crossover point sits significantly lower than many mid-market organizations realize. Industry analysis points to a threshold of approximately 10 million to 50 million tokens per month Prem AI.
Consider a high-volume data classification workload comparing the cost of OpenAI's GPT-4o Mini against a self-hosted, 7-billion parameter open-weights model deployed on a single NVIDIA H100 spot instance (costing roughly 1.65 per hour, or 1,200 per month).
| Monthly Token Volume | Hyperscaler API (e.g., GPT-4o Mini) | Self-Hosted Open-Weights (e.g., 7B Model) | Economic Winner |
|---|---|---|---|
| 500,000 Tokens | ~$15 | ~$850 (baseline hardware cost) | Buy (API significantly cheaper) |
| 2,000,000 Tokens | ~$60 | ~$850 | Buy (API dominates) |
| 10,000,000 Tokens | ~$300 | ~$850 | Buy (API slightly cheaper, hardware underutilized) |
| 50,000,000 Tokens | ~$1,500 | ~$850 | Build Custom (Self-hosted saves over 40%) |
| 100,000,000 Tokens | ~$3,000 | ~$850 | Build Custom (Self-hosted saves over 70%) |
At 50 million tokens per month, the physical hardware costs of the self-hosted solution dramatically undercut the retail markup of the API. One fintech enterprise effectively reduced its monthly inference spend from 47,000 on API calls to 8,000 by transitioning to a hybrid self-hosted approach, achieving an 83% cost reduction Prem AI.
However, hardware is only one component of the total cost of ownership. Maintaining a self-hosted environment requires dedicated infrastructure engineering, model patching, and pipeline monitoring. When factoring in the labor overhead of a dedicated MLOps engineer, the true financial break-even point often shifts closer to 100 million to 500 million tokens per month ClankerCloud. If an organization chooses to self-host below this absolute volume threshold, the decision must be justified by data sovereignty requirements or latency advantages, rather than raw financial savings. For teams planning that journey, our 90-day enterprise AI implementation roadmap breaks down how to move from pilots to durable, cost-aware production.
Architecting for Portability: The 2026 Design Pattern
For mid-market enterprises navigating these shifting economics, committing entirely to a single path represents a critical strategic failure. The optimal enterprise AI strategy relies on "composability" and hybrid design. Because Big Tech is pouring $725 billion into capability expansion, new models will launch continuously, and API prices will fluctuate violently. Codebases hardwired to specific model endpoints will become legacy technical debt within six months.
The architectural solution is an explicit portability-first design. This involves decoupling the application logic from the underlying cognitive reasoning engine. To achieve this, organizations must implement three distinct abstraction layers: Model Gateways, Prompt Registries, and Evaluation Harnesses. This blueprint fits neatly into the broader shift toward internal AI platforms and private app stores that we outlined in our report on building internal enterprise AI app stores.
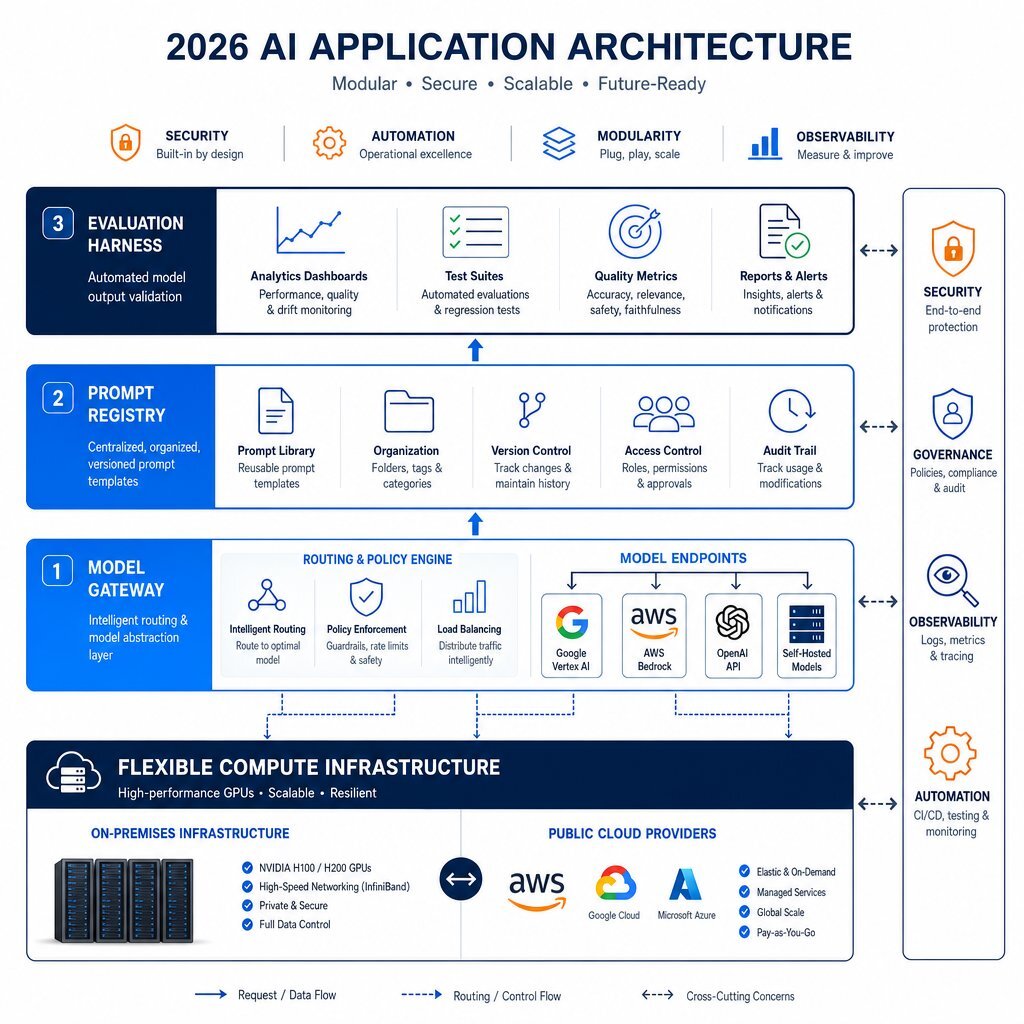
The Centralized Model Gateway
An AI Gateway functions as a reverse proxy sitting directly between the enterprise application and the vast array of available LLM providers. Rather than configuring individual applications to call Google Vertex, AWS Bedrock, or a local self-hosted container, the applications call the internal gateway. The gateway then automatically routes the request to the most cost-effective, fastest, or most accurate model available based on predefined administrative rules.
Beyond simple routing, gateways enforce security policies at the protocol level. They manage rate limiting, execute automatic retries when a hyperscaler API fails, perform semantic caching to prevent paying for identical queries multiple times, and aggressively redact Personally Identifiable Information (PII) before data crosses the enterprise boundary.
The 2026 market presents several robust gateway options:
- Kong AI Gateway: Engineered for massive enterprise scale, capable of processing up to 28,000 requests per second. It is highly suited for organizations already leveraging Kong's broader API management ecosystem.
- Portkey: Focuses heavily on application-level reliability, governance guardrails, and detailed observability, claiming 99.9999% uptime for production traffic AgentOverflow.
- LiteLLM: A highly flexible, developer-first open-source proxy supporting over 100 providers, though independent tests indicate performance degradation when pushed beyond 1,000 concurrent requests per second without proper infrastructure tuning Kong.
Organizations partnering with experienced engineering firms, such as Baytech Consulting, frequently utilize Rapid Agile Deployment frameworks to stand up these gateways. By deploying these proxies inside containerized environments using Kubernetes, Docker, and localized PostgreSQL databases for logging, companies ensure their control plane remains completely sovereign and cloud-agnostic.
The Enterprise Prompt Registry
The industry has rapidly transitioned through distinct development eras: from basic "Prompt Engineering" in 2022 to "Context Engineering" in 2025, and finally to "Harness Engineering" in 2026. The fundamental truth established by this evolution is that prompts are essentially application programming interfaces; they are source code that dictates system behavior.
Managing prompts in scattered text documents or hidden within individual code repositories creates catastrophic operational bottlenecks. A Prompt Registry solves this by version-controlling all organizational prompts in a centralized, auditable database Medium. Registries built on templating languages like Jinja2 allow developers to separate the dynamic application data from the static instruction sets Agenta. This enforces strict lifecycle management, enables rapid rollbacks if a prompt regression causes application failures, and provides a clear audit trail for compliance officers investigating how specific AI behaviors were triggered.
The Automated Evaluation Harness
Because the portability-first architecture relies on swapping models in and out of production as economics shift, organizations must possess a mathematical mechanism to guarantee that a new, cheaper model performs at parity with the previous baseline. Manual output reviews do not scale.
An Evaluation Harness systematically tests model outputs against standardized criteria. Platforms like MLflow, DeepEval, and Arize Phoenix capture entire execution traces—monitoring the exact reasoning loop, tool invocation, and hierarchical memory interactions of an AI agent MLflow. Utilizing "LLM-as-a-judge" algorithms grounded in empirical research, these harnesses automatically score responses for logical consistency, tone adherence, and absence of hallucinations before any code change reaches production.
By unifying the gateway, the registry, and the evaluation harness, a mid-market firm constructs an environment where moving from a $15-per-million-token commercial API to a self-hosted, $2-per-million-token open-source model requires changing a single configuration file rather than rewriting thousands of lines of application code.
Governance, Vendor Risk, and CFO CapEx Strategy
The reliance on external AI infrastructure forces organizations to address critical third-party risks. The rapid restructuring occurring inside hyperscaler organizations—evidenced by massive layoffs and strategic realignments—proves that vendor roadmaps are volatile.
Mitigating Hyperscaler Vendor Risk
The 2024 global IT outage caused by a routine CrowdStrike software update vividly demonstrated the danger of highly concentrated supply chain dependencies. In the AI context, this risk is magnified. Geopolitics, energy constraints, and shifting national policies surrounding AI capability directly impact a cloud provider's ability to offer consistent service.
When evaluating enterprise AI platforms like AWS Bedrock, Google Vertex AI, or Azure AI Foundry, technology executives must demand transparency. Critical governance evaluations must define exact data access permissions, verify that integration protocols do not allow training on enterprise intellectual property, and guarantee data residency within specific geographic borders Glean. Furthermore, executives must audit the vendor's internal safeguards against prompt injection and cross-tenant data leakage. If an AI provider cannot present explicit documentation outlining their data isolation boundaries and bias testing results across demographic groups, the platform fails the baseline security requirement for enterprise adoption.
CapEx vs. OpEx: The Tokenomics of AI Infrastructure
From a financial perspective, the AI build vs buy decision fundamentally alters the corporate balance sheet. Historically, CFOs preferred capital expenditures (CapEx) for technology investments to leverage depreciation and amortization over long periods Mitel. However, the unpredictable hardware requirements and rapid obsolescence cycles of AI technology make hardware procurement exceptionally risky.
The API-driven "buy" strategy transitions this investment into an operating expense (OpEx) model. By paying per token, organizations shift the massive physical hardware depreciation risk entirely onto the hyperscalers—letting Amazon, Alphabet, Microsoft, and Meta absorb the $725 billion burden.
Yet, when sustained high-volume inference pushes an organization toward self-hosting, the CFO must re-engage with CapEx realities. Procuring private clusters of NVIDIA H200 or B200 GPUs represents a significant capital outlay. The strategic compromise for the mid-market CFO lies in maintaining extreme infrastructural flexibility. By funding the development of a cloud-agnostic, containerized software architecture, the CFO retains the leverage to negotiate aggressively with managed infrastructure providers or switch rapidly to dedicated GPU cloud providers as tariff signals, energy costs, or compute prices fluctuate.
A 12-Month Roadmap for Mid-Market Flexibility
Deploying a resilient AI strategy requires structured sequencing. Attempting to build production-scale intelligent agents without foundational data readiness and governance protocols guarantees failure. A standard 12-month timeline ensures that an enterprise avoids "pilot purgatory" and successfully transitions from initial discovery to scalable operation Alice Labs. For CTOs who want to sanity-check their current posture before committing, our enterprise AI readiness checklist offers a pragmatic companion.
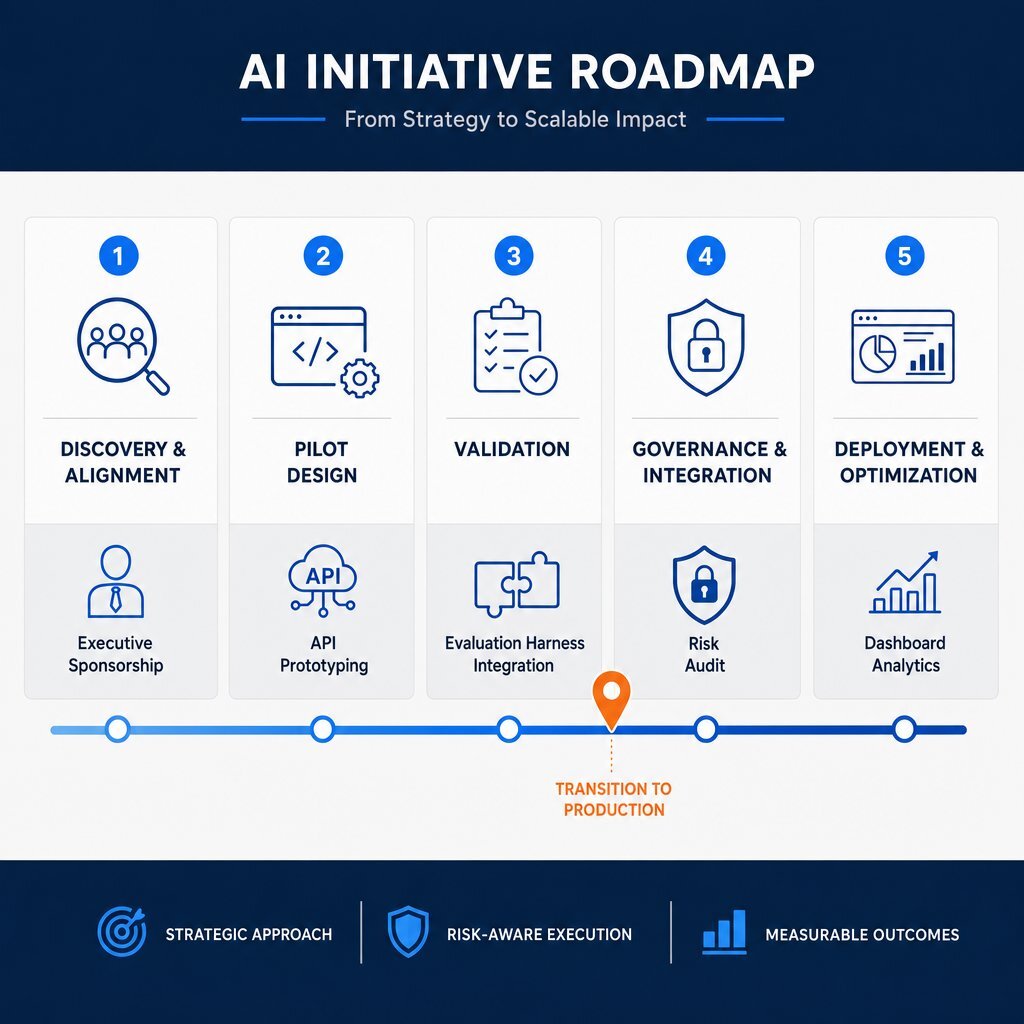
Phase 1: Discovery and Alignment (Months 1–2)
The initiative begins with a comprehensive readiness assessment. Executives must define the strategic vision, audit the current state of organizational data, and identify highly specific, measurable use cases. Success in this phase is defined by establishing a concrete budget allocation and securing cross-departmental executive sponsorship, moving past generalized AI ambitions toward specific workflow enhancements GrowExx.
Phase 2: Pilot Design and Execution (Months 2–4)
Organizations transition into active experimentation, utilizing commodity APIs to prototype capabilities rapidly. Engineering teams construct the preliminary abstractions—implementing open-source gateways and prompt registries to manage the testing phase. The objective is to evaluate model efficacy against internal data without committing to permanent infrastructure.
Phase 3: Validation and Business Case Modeling (Months 4–6)
Pilots undergo rigorous evaluation against baseline performance metrics. Evaluation harnesses capture execution traces to monitor accuracy, drift, and latency. Critically, this phase demands precise unit economic forecasting. Teams calculate projected token volumes to determine if the workload justifies transitioning from the hyperscaler API to a fine-tuned, self-hosted deployment.
Phase 4: Governance and Infrastructure Integration (Months 5–7)
Prior to scaling, organizations embed rigid security and compliance controls. This involves configuring role-based access, implementing automated PII redaction at the gateway level, and finalizing data processing agreements for any external endpoints. Concurrently, development teams integrate the chosen AI capabilities seamlessly into existing operational technology (OT) and enterprise resource planning (ERP) systems, avoiding isolated, siloed applications.
Phase 5: Deployment, Scale, and Continuous Optimization (Months 6–12)
Models enter full production. The focus shifts entirely to operational monitoring, automated retraining schedules, and cost observability. Dashboards actively track the financial burn rate of inference costs against projected business value, ensuring that the return on investment remains positive. The architecture’s portability is continuously tested by routing non-critical traffic to newer, more cost-effective models as they become available in the market. For many organizations, this is where a structured DevOps efficiency and observability practice becomes the backbone of sustainable AI operations.
Conclusion
The convergence of $725 billion in hyperscaler infrastructure spending and widespread technical layoffs fundamentally resets the economics of artificial intelligence for the mid-market. While the sheer scale of Big Tech's data center expansion continually drives down the raw cost of commodity reasoning, the hidden operational overhead and strategic risks of absolute vendor dependency make a pure "buy" strategy dangerously fragile. Conversely, the capital constraints and maintenance burdens of pure custom development make an absolute "build" strategy economically unviable for all but the highest-volume tasks.
To survive the turbulent innovation cycles of 2026, technology executives must adopt a composable, portability-first architecture. By isolating business logic from external dependencies through the strict use of model gateways, prompt registries, and continuous evaluation harnesses, organizations preserve the agility to route low-risk workloads to heavily subsidized APIs while retaining the power to pull sensitive, high-volume intelligence back into sovereign infrastructure. The winners of the current AI cycle will not be those who build the best models, but those who design systems capable of seamlessly consuming whatever models the market makes most efficient.
Organizations requiring expert orchestration of these localized, containerized architectures can leverage Baytech Consulting's Custom Software Development and Rapid Agile Deployment methodologies. By utilizing enterprise-grade technologies such as Docker, Kubernetes, and PostgreSQL, mid-market firms can construct the unassailable, cloud-agnostic AI infrastructure required to remain competitive. If you are ready to move beyond theory and launch real AI copilots inside your products, our playbook on building true SaaS-grade AI copilots instead of simple chat widgets is a practical next read.
FAQ
How do cloud AI hidden costs alter the build vs buy calculation?
Advertised token prices primarily reflect input costs, whereas generated output tokens generally cost three to eight times more. Additionally, operational friction—such as continuous pipeline testing, network retries, and surrounding cloud data routing—adds an average of 30% to 100% to baseline API estimates. Organizations must calculate the total cost of observability and capacity provisioning before finalizing their AI infrastructure budgets to determine the true crossover point for self-hosting. For enterprises with strict on-premise or latency needs, it is also worth comparing these costs against modern hyperconverged Harvester HCI deployments for AI workloads.
Supporting Links
https://www.tomshardware.com/tech-industry/big-tech/big-techs-ai-spending-plans-reach-725-billion)
- https://medium.com/@aiengineeringonaws/aws-bedrock-pricing-explained-what-youll-actually-pay-in-2026-39377a27cdbd
AI Gateway Comparison 2026: LiteLLM vs Portkey vs Kong vs 5 More
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.