
Securing SaaS from Ransomware: Insights from Canvas Attack
May 22, 2026 / Bryan Reynolds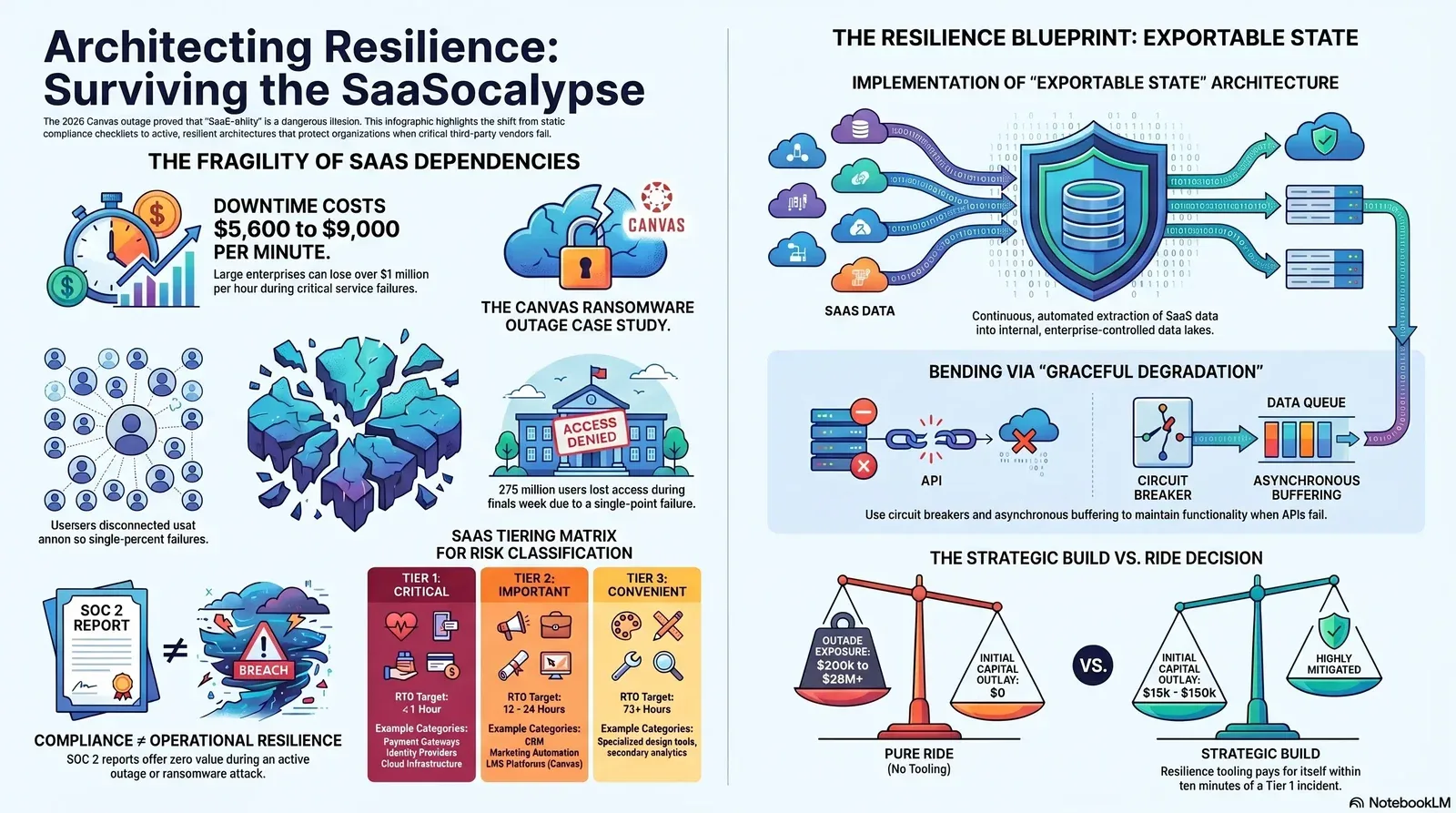
Canvas Went Down During Finals Week. Your SaaS Dependencies Are a Roadmap of Your Risk.
The modern enterprise operates under a dangerous, unspoken illusion: the assumption that software-as-a-service (SaaS) providers are inherently resilient, continuously available, and fundamentally secure. The architecture of contemporary business is built upon an interconnected web of third-party platforms handling everything from customer relationship management to financial ledger reconciliation. When these systems function properly, they provide unprecedented operational velocity. When they fail, they reveal the fragile, silently load-bearing dependencies that organizations have constructed without adequate contingency planning.
The May 2026 ransomware attack on Instructure’s Canvas learning management system demonstrated exactly how catastrophic these failures can be when they strike at the worst possible moment. ShinyHunters, a notorious extortion-as-a-service group, claimed responsibility for the breach, institutions scrambled, and exams ran on paper—because almost nobody had architected for the possibility that the gradebook itself could simply vanish.

This outage is not merely a story about a single learning management system or a specific cybercriminal syndicate. It serves as a defining case study illustrating how organizations across every sector—finance, healthcare, logistics, software, and real estate—have quietly outsourced their core operational stability to vendors they cannot control and cannot rapidly replace. The most critical executive question regarding third-party risk management is no longer a compliance-driven “Is the vendor secure?”—a state that is practically impossible to verify with absolute certainty. The critical question is: “What happens to the business in the 48 hours after a critical vendor goes dark, and what infrastructure would be built differently if that scenario were taken seriously?”
The answer invariably involves a strategic allocation of custom adjacent tooling—exportable state pipelines, graceful degradation architectures, and tested incident response playbooks. This infrastructure costs a fraction of the downtime it prevents. This comprehensive analysis will explore the mechanics of the Canvas outage, define methodologies for mapping SaaS dependency risk, provide decision frameworks for custom tooling, and outline the technical architecture required to ensure business continuity when cloud dependencies fail.
1. The Canvas Outage: Anatomy of a Worst-Case Scenario
To understand the systemic operational risk embedded in SaaS dependencies, the May 2026 Instructure incident provides a clear timeline of cascading failure, extortion, and organizational paralysis. Threat actors understand that the leverage required for extortion scales linearly with the victim's operational dependency, making the timing of this attack a masterclass in exploiting concentration risk.
The Attack Vector and Timeline
Instructure, the parent company of the widely utilized Canvas platform, experienced unauthorized activity beginning on April 29, 2026. ShinyHunters successfully exploited a vulnerability associated with the platform's “Free-For-Teacher” account program. This exploit granted the attackers direct access to the Canvas platform, initiating an exposure window that lasted from April 30 to May 7, 2026.
The disruption peaked on the afternoon of Thursday, May 7. Students and faculty across thousands of institutions logged into Canvas only to find a defaced login page containing a ransom demand. ShinyHunters claimed to have exfiltrated 3.6 terabytes of data covering approximately 275 million users across 9,000 schools. While Instructure did not publicly verify the total data volume, the company confirmed the exposure of names, email addresses, student IDs, and private platform messages. The hackers issued a strict ultimatum: the targeted institutions and Instructure had until the end of the day on May 12, 2026, to negotiate a settlement, or the stolen data would be publicly leaked.
Operational Paralysis During Finals Week
The timing of the attack amplified the blast radius exponentially. The disruption coincided directly with the final examination period for the spring semester across North American higher education institutions. Universities found themselves entirely dependent on a compromised platform for administering exams, processing grades, and communicating with students.
The responses from affected institutions highlighted a total lack of localized, exportable state architectures:
- University of Pennsylvania: Students lost access on Thursday afternoon as finals began. The hackers explicitly targeted Penn, claiming to have compromised data for 306,000 affiliates, including internal messages between faculty and students. The university had to scramble to provide instructors with specific “continuity measures” to salvage the exam period.
- Boise State University: The attack forced the university to cancel all exams scheduled for Friday, May 8. Instructors were directed to finalize grades based entirely on prior coursework because the assessment mechanism had completely disappeared.
- Idaho State University: The university was forced to cancel all mid-Thursday assignments and exams.
- Cornell University: The platform went dark for approximately six hours on Thursday afternoon and evening, severely disrupting the crucial study period immediately preceding Saturday exams.
The Resolution and the Illusion of Control
On May 11, 2026, Instructure announced it had reached an agreement with ShinyHunters. Instructure CEO Steve Daly issued a statement confirming that the stolen data was returned, copies were purportedly destroyed by the hackers, and assurances were given that customers would not be extorted. The system was restored to maintenance mode and eventually brought back online safely.
While the immediate crisis was resolved—likely through a substantial ransom payment, typical for such resolutions—the incident exposed a fundamental flaw in enterprise risk architecture. Educational institutions had treated Canvas as an infallible utility rather than a third-party dependency carrying severe concentration risk. When the gradebook disappeared, there was no local cache, no read-only fallback, and no alternate routing. They were flying entirely blind.
2. Your SaaS Dependency Map is Your Real Risk Register
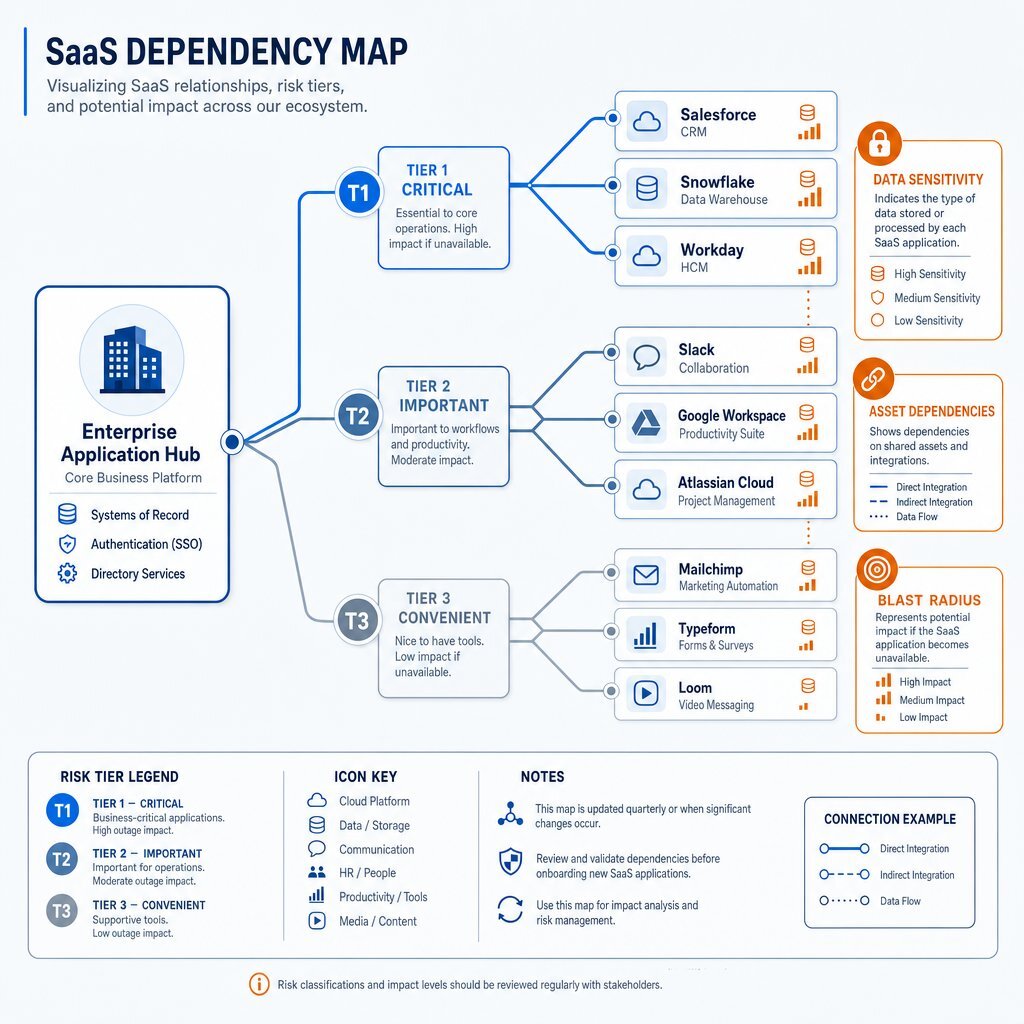
The traditional approach to third-party risk management relies heavily on compliance checklists, such as the Standardized Information Gathering (SIG) questionnaire, Consensus Assessments Initiative Questionnaire (CAIQ), or SOC 2 Type II reports. These documents provide a static, point-in-time snapshot of a vendor's theoretical security controls, but they offer zero operational value during an active outage. A clean SOC 2 report cannot process a transaction when a payment gateway is down, nor can a completed compliance questionnaire retrieve customer data from a locked cloud environment.
To accurately assess risk, the enterprise must transition from static compliance tracking to dynamic application dependency mapping (ADM). A SaaS dependency map serves as the true risk register, visually and structurally documenting the exact business processes tied to specific external services, similar to the way a CTO readiness checklist for enterprise AI surfaces hidden dependencies before you scale.
Moving from Questionnaire Fatigue to Contextual Assurance
A vendor can be categorized as low risk in one environment and mission-critical in another. A marketing analytics tool storing anonymized behavioral data carries a vastly different risk profile than the exact same platform housing regulated personally identifiable information (PII) to feed executive reporting. Broad security questionnaires prioritize compliance checkboxes over tailored risk analysis, leading to incomplete visibility into dynamic threats.
A rigorous dependency map must move beyond surface-level generic checkboxes to provide real-time clarity regarding the impact of a vendor's failure. A functional contextual risk model must categorize and weigh risk based on dynamic factors. The following fields are non-negotiable for an executive-level SaaS dependency map:
- Business Function Support: The specific department or operational unit the vendor supports, clarifying who owns the operational fallout.
- Asset Dependencies: Real-time clarity into the exact internal data pipelines, systems, and microservices that rely on the vendor.
- Data Sensitivity: The classification of data (e.g., PII, PHI, intellectual property) processed by the SaaS application, determining regulatory exposure.
- Blast Radius: The immediate operational and financial consequences if the vendor fails for 1 hour, 24 hours, and 72 hours.
- Replaceability and Recovery Time Objective (RTO): The estimated time, capital, and engineering effort required to swap the vendor for a competitor or an internal alternative.
- Supply Chain Depth (Fourth- and Fifth-Party Visibility): Identification of layered dependencies. If a primary SaaS vendor relies exclusively on a single cloud provider region, the enterprise indirectly inherits that specific geographic concentration risk.
Automating the Discovery Process to Combat SaaS Sprawl
Manual mapping frequently falls behind continuous deployment cycles. In highly dynamic ecosystems, infrastructure is elastic, new features deploy continuously, and downstream data flows evolve in weeks rather than years. Furthermore, the ease of modern software procurement creates rampant SaaS sprawl. Teams adopt new software in minutes—often without centralized oversight—creating visibility gaps and hidden continuity risks.
Effective dependency mapping requires automation integrated directly into the CI/CD pipeline. Tools that analyze source code repositories identify hardcoded software dependencies, while network traffic analysis and IT Service Management (ITSM) integrations map dynamic API calls and service interactions. This automation ensures that when an incident occurs, the incident response team immediately knows which internal systems will experience cascading failures and can act with the same discipline you’d apply when rolling out an enterprise AI implementation plan over 90 days.
Categorizing the Blast Radius: The SaaS Tiering Matrix
Organizations must classify SaaS dependencies into distinct tiers to allocate engineering resources and budget appropriately. Attempting to build resilience around every vendor is financially unviable; treating all vendors equally leaves the core business exposed.
| Vendor Category | Defining Characteristic | Blast Radius Impact | RTO Target | Example SaaS Categories |
|---|---|---|---|---|
| Tier 1: Critical | Single point of failure for revenue generation, core operations, or safety. | Immediate financial hemorrhage, regulatory breach, or total business halt. | < 1 Hour | Payment gateways, Identity Providers (Okta), Cloud Infrastructure, Core ERP. |
| Tier 2: Important | Essential for daily productivity, but manual workarounds exist for short durations. | Severe operational drag, delayed reporting, intense internal friction. | 12 - 24 Hours | CRM (Salesforce), ITSM tools, Marketing Automation, LMS platforms (Canvas). |
| Tier 3: Convenient | Point solutions optimizing specific workflows or departmental tasks. | Minor inconvenience; business proceeds normally without immediate financial loss. | 72+ Hours | Specialized design tools, secondary analytics, HR pulse-survey applications. |
The Canvas incident revealed that institutions fundamentally misunderstood their own dependency maps. They treated a Tier 1 system (the core mechanism for delivering and grading final exams) with Tier 3 architectural resilience. They possessed no mechanisms to extract raw student data to administer offline tests, highlighting a profound disconnect between business criticality and technical architecture.
3. The Build-vs-Ride Decision Framework
When a Tier 1 or Tier 2 SaaS dependency is identified, executives face a crucial architectural decision: accept the vendor's uptime at face value and absorb the risk (the “ride” strategy), or invest in custom adjacent tooling to insulate the business from outages (the “build” strategy).
The modern build-vs-buy software debate has fundamentally evolved. The question is no longer whether to buy a SaaS product or build an entire platform from scratch. SaaS is here to stay. The actual question is when to invest in custom middleware, data caches, and fallback workflows around the purchased SaaS product to guarantee resilience. This is the same logic that now drives many enterprises to stop renting intelligence and build AI where it really matters.
Calculating the True Cost of Downtime
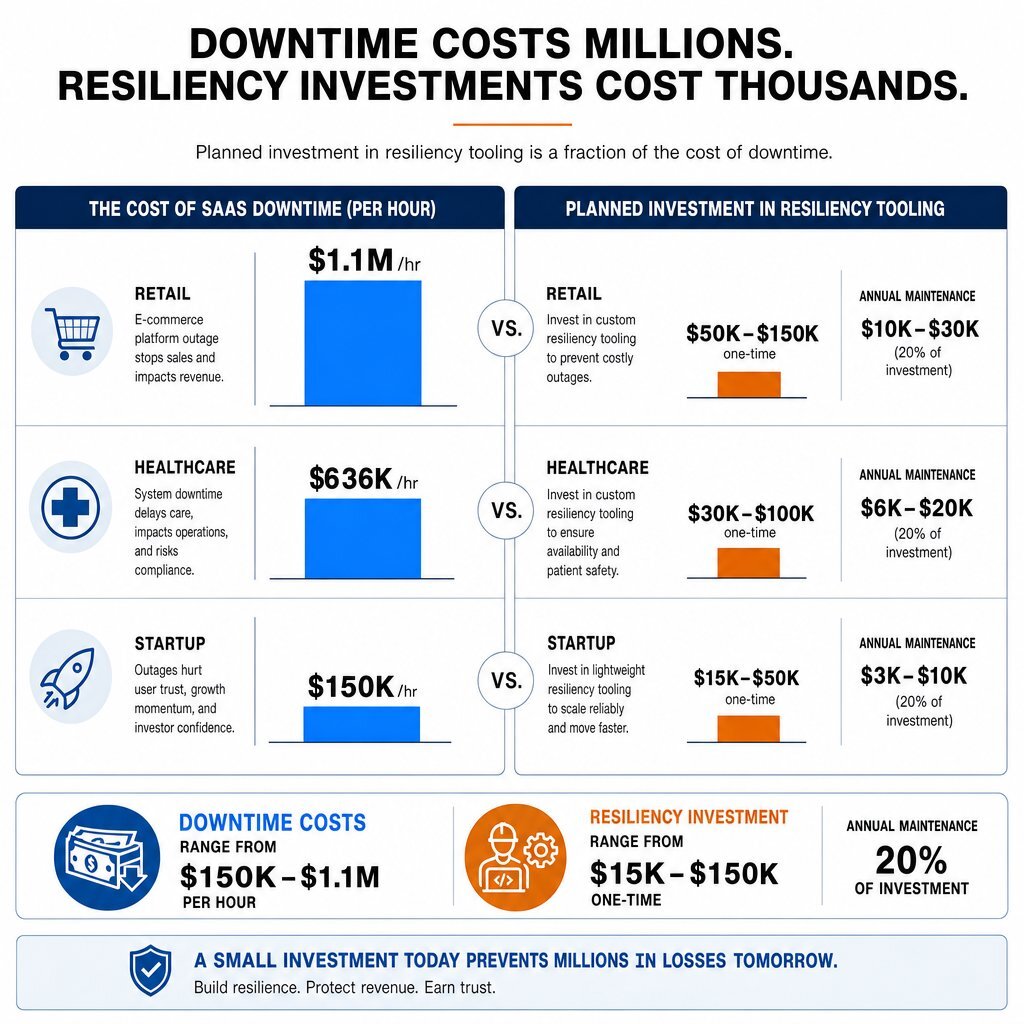
The justification for building custom resilience tooling relies entirely on accurate downtime cost modeling. Relying on a vendor's “99.9% high-availability” marketing promise is insufficient when the financial mathematics of an actual outage are calculated.
Industry benchmarks indicate that the average cost of IT downtime ranges broadly from 5,600 to 9,000 per minute, depending heavily on the organization's size, industry vertical, and business model.
- Retail and E-commerce: Outages average $1,100,000 per hour due to immediate transaction abandonment, failed point-of-sale systems, and rapid reputation erosion.
- Healthcare: Downtime costs average $636,000 per hour. Failures in electronic health records or adjacent systems lead directly to delayed patient care, diverted ambulances, and severe compliance penalties.
- Startups and Mid-Market Businesses: Even for smaller firms, the cost ranges from 137 to 427 per minute (8,220 to 25,620 per hour). Furthermore, extended incidents severely impact startup cash runways; data indicates that nearly 29% of startups that fail do so because they run out of cash, making them highly vulnerable to the financial shock of a major incident.
Beyond the immediate financial loss, organizations face long-term indirect costs: eroded customer trust, missed business opportunities, and compliance violations. This is why CFOs increasingly look at downtime and resilience through the same lens they use to reframe AI ROI and justify technology investments.
The Economics of Custom Adjacent Tooling
Contrast the financial hemorrhage of downtime with the cost of building custom resilience architecture. AI-assisted development, modular cloud-native frameworks, and specialized custom software development have significantly compressed the cost and timeline of bespoke engineering.
To construct a robust data extraction pipeline—effectively creating a local, queryable cache of critical SaaS data—the upfront engineering investment typically ranges from 4,000 to 15,000 for standard mid-market integrations, requiring 40 to 120 hours of DevOps and engineering time. For highly complex, enterprise-grade, event-driven architectures built to exacting security standards, development costs scale higher, often requiring 3 to 6 months of foundational work. Comprehensive custom software projects can require $150,000 to $400,000 upfront, with an additional 15% to 25% allocated annually for maintenance.
While these figures appear substantial to a CFO scrutinizing a budget, they represent a predictable Capital Expenditure (CapEx) or planned Operational Expenditure (OpEx) that pales in comparison to the unmitigated cost of a multi-day vendor outage.
| Investment Strategy | Initial Capital Outlay | Annual Maintenance | Outage Financial Exposure (24 Hours) |
|---|---|---|---|
| Pure Ride (No Custom Tooling) | $0 | $0 | 200,000 to 26,000,000+ |
| Strategic Build (Adjacent Tooling) | 15,000 - 150,000 | 20% of Build Cost | Highly Mitigated (Graceful Degradation) |
If an enterprise loses $1.1 million per hour during a payment gateway or inventory management collapse, a $150,000 investment in a gracefully degrading fallback architecture pays for itself within the first ten minutes of an incident.
Paying the Integration Tax
Relying solely on native SaaS integrations frequently results in the “integration tax”—brittle, point-to-point scripts that break during vendor updates, resulting in mismatched reporting across CRM, ERP, and finance systems, leading to silent failures that are discovered far too late.
When these symptoms appear, it signals that the organization must move from ad-hoc scripts to mature data engineering. Custom adjacent tooling centralizes data governance. By leveraging expert partners like Baytech Consulting—who utilize robust tech stacks including Azure DevOps On-Prem, PostgreSQL, Kubernetes, and Docker—businesses can pull critical state information into highly controlled environments. This ensures the organization retains ultimate data sovereignty and operational control, regardless of what happens to the external vendor, and aligns with a broader move away from fragile, generic SaaS toward post‑SaaSocalypse architectures.
4. Exportable State Architecture: Controlling Your Data Destiny
To survive a third-party vendor outage, an organization must retain possession of its operational state. If the SaaS provider's servers vanish from the internet, the business must still be capable of knowing who its customers are, what they purchased, what inventory is available, and what services are owed. This requires the implementation of an “exportable state architecture.”
Exportable state refers to the continuous, automated extraction of critical data from a SaaS platform into an internal data warehouse, data lake, or relational database controlled exclusively by the enterprise. This architectural pattern ensures data portability, prevents vendor lock-in, and provides the absolute necessary foundation for read-only fallback systems during active incidents. It also lays the groundwork for safer AI on top of that data, similar to how AI data infrastructure reduces hallucinations and makes intelligent agents more reliable.
Data Extraction Patterns
The success of an exportable state architecture relies entirely on the reliability of the data extraction pipeline. Extraction is the “E” in ETL (Extract, Transform, Load) and is frequently the most challenging phase due to wildly varying SaaS APIs, strict availability windows, and aggressive rate limits.
Engineering teams must select the appropriate extraction strategy based on the characteristics of the source SaaS system:
1. Full Extraction This pattern pulls the entire dataset from the API on a scheduled basis. It is simple, consistent, and automatically catches deleted records. However, it is exceedingly slow for large datasets and consumes vast amounts of compute resources and API quotas, making it suitable only for small datasets or legacy systems lacking reliable change-tracking features.
2. Incremental Extraction This pattern pulls only records that have been modified since the last successful pipeline execution, typically relying on timestamp columns (e.g., updated_at). This method is highly efficient and enables faster data refreshes. However, it requires tracking state continuously, and it frequently fails to detect hard deletes in the source system unless the vendor provides a specific “deleted records” endpoint.
3. Change Data Capture (CDC) For Tier 1 systems requiring real-time consistency, CDC is the gold standard. Instead of polling an API, the system subscribes to real-time event streams or webhooks provided by the SaaS vendor. Every mutation (insert, update, delete) is captured instantly. While it provides near real-time synchronization, it requires high infrastructure overhead, including message brokers and event-driven processing layers, to prevent dropped events.
Overcoming Extraction Complexities
Modern SaaS platforms are fundamentally data systems characterized by multi-tenancy and high cardinality events generating millions of records daily. A robust pipeline must decouple producers from consumers to ensure fault tolerance.
This architecture requires careful handling of API rate limiting and backpressure. If the SaaS vendor enforces strict throttling (e.g., 100 requests per minute), the extraction workers must implement exponential backoff and retry logic. Furthermore, the internal pipeline must handle checkpointing—saving its progress so that if the extraction pipeline crashes, it can resume precisely where it left off upon recovery without duplicating data.
Implementing Fallback Operations
In enterprise environments, extracted data is often funneled into data lakes (such as Snowflake) or relational databases (like PostgreSQL) to support analytics and operational reporting. However, simply hoarding data is insufficient for continuity. The data must be structured for immediate use during an outage.
Systems must be designed to initiate “fallback operations.” For instance, if a primary application utilizes an external analytics SaaS endpoint, and that endpoint fails, the system can gracefully switch to querying the internal data lake. While these fallback queries might suffer from higher latency or rely on data that is slightly stale (representing the state of the system at the time of the last successful extraction framing operation), they allow the business to continue functioning. The critical imperative is that the local data store is entirely isolated from the vendor's failure domain.
5. Graceful Degradation in Practice: Bending Without Breaking
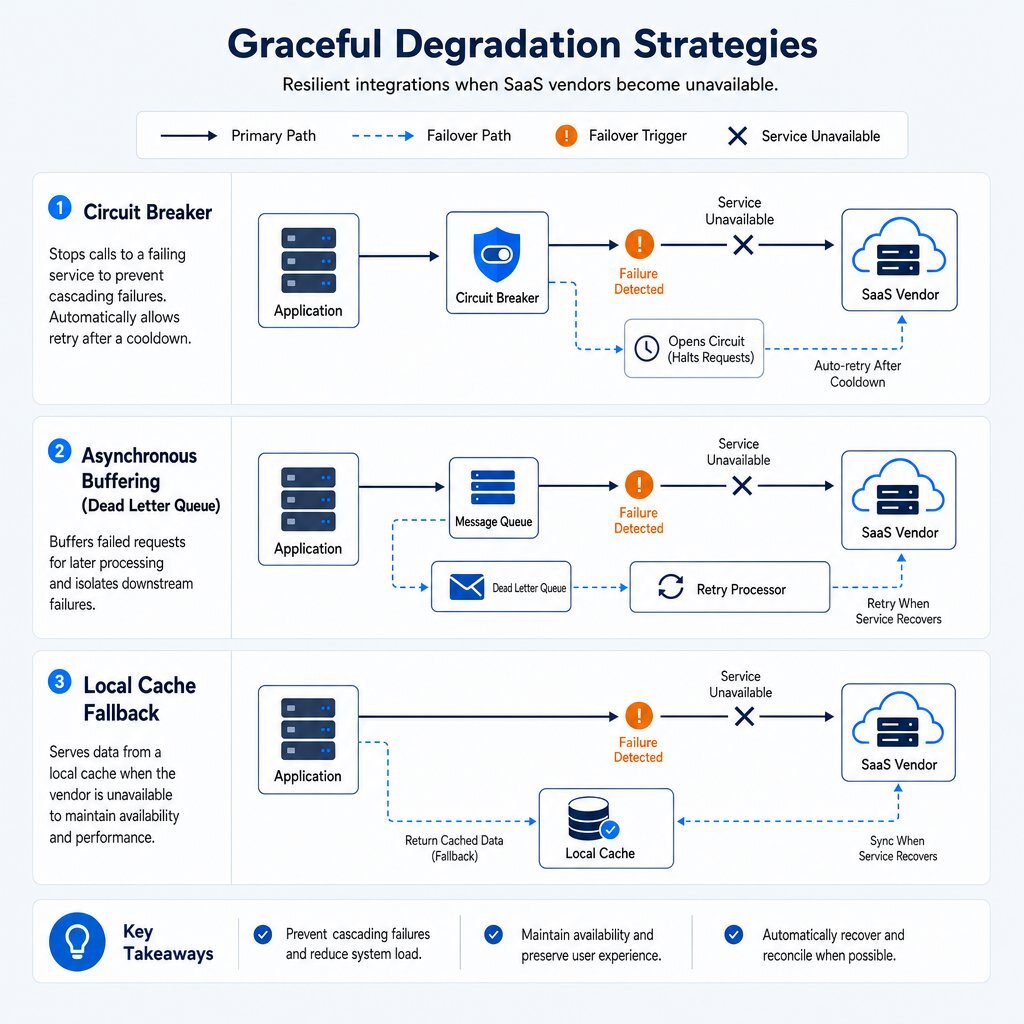
Possessing a local copy of SaaS data is only the first step. The application architecture must be explicitly designed to utilize that data when the primary SaaS dependency fails. This is the essence of graceful degradation: the ability of a system to maintain at least partial functionality, perhaps with reduced performance or accuracy, rather than suffering a catastrophic collapse.
Graceful degradation transforms hard architectural dependencies into soft dependencies. If a payment provider slows down, an inventory API times out, or an LMS gradebook vanishes, the system must bend without breaking. Instead of failing catastrophically, the system falls back to a reduced but functional experience, keeping users moving, protecting the brand, and buying the engineering team time to react instead of firefighting in a panic.
Core Patterns for Resilience
Engineering teams must proactively implement established resilience patterns to handle predictable failure modes:
1. The Circuit Breaker Pattern When a downstream SaaS dependency becomes unresponsive, continuing to send requests guarantees application thread exhaustion and cascading internal failures. The circuit breaker pattern monitors failing API calls for time-critical systems. If the error rate crosses a predefined threshold, the circuit “opens,” instantly blocking further outbound requests. Instead of waiting for network timeouts, the application immediately returns a predefined fallback response or serves locally cached data. After a specified cooldown period, the circuit enters a “half-open” state, allowing a trickle of test requests to determine if the vendor has recovered before fully restoring traffic.
2. Asynchronous Buffering and Dead Letter Queues To handle the unavailability of a primary SaaS database or processing engine, write requests must be buffered asynchronously. For example, if an inventory synchronization API is down, updates can be published to an internal message queue (such as an Amazon SQS queue). The application returns a “success” message to the user, acknowledging receipt of the action, even though the backend process is delayed. Once the vendor service is restored, queue workers process the backlog. Messages that consistently fail input validation (poison pills) are isolated into a Dead Letter Queue (DLQ) for manual inspection, preventing them from perpetually crashing the queue processors and contributing to system overload.
3. Load Shedding and Sidelining Traffic During an incident, traffic patterns often become erratic. To protect internal fallback systems from being overwhelmed by a “thundering herd” of retries, applications must implement load shedding. This involves dropping excess or low-priority requests at the frontend layer to protect backend stability. If a specific workload exceeds a configured rate, the consumer service can sideline those excess messages into a separate “spillover” queue. This allows the system to process primary, high-priority traffic (like customer checkouts) while draining the old backlog separately as resources become available.
Managing Cache Addiction and Modal Behavior
A common anti-pattern in resilience architecture is “cache addiction”. A cache implemented to speed up reads can inadvertently become a critical dependency itself. If the cache fleet fails or goes cold, the sudden surge of traffic sent directly to the downstream SaaS API can cause a secondary outage. This introduces dangerous “modal behavior,” where the service performs wildly differently depending on whether an object is cached.
To counter this, systems must implement Soft and Hard Time-To-Live (TTL) values. Under normal operations, an application attempts to refresh a cached item based on its soft TTL. If the downstream SaaS is unavailable or signals backpressure, the application gracefully suppresses the error and continues serving the stale data until the hard TTL is reached.
Additionally, Negative Caching is critical during outages. If a SaaS provider returns a 500 Internal Server Error or a 429 Too Many Requests response, the internal application should cache that failure state for a short duration using a distinct TTL. This prevents the internal application from aggressively retrying a known-down service, discarding error responses, and inadvertently acting as a denial-of-service attacker against its own vendor, which would only amplify the ongoing outage.
6. The Vendor Incident Playbook: Beyond Disaster Recovery
When chaos engineering uncovers a vulnerability, or when a real-world event like the Canvas ransomware attack strikes, technical architecture must be supported by procedural rigor. A generic Disaster Recovery Plan (DRP) designed for internal data center failures is woefully inadequate for handling the compromise of a cloud-based third party.
Internal hardware failures require spinning up backup servers; SaaS compromises require legal notifications, data forensics coordination across corporate boundaries, and immediate containment of API access. Therefore, every organization must develop a specific Vendor Incident Playbook.
Aligning with Supply Chain Frameworks
A comprehensive vendor playbook should align with federal and industry standards, specifically the National Institute of Standards and Technology (NIST) Special Publication 800-161, which governs Cybersecurity Supply Chain Risk Management (C-SCRM).
NIST SP 800-161 emphasizes that organizations must establish processes to identify supply chain risks, monitor supplier posture, and—crucially—solicit supplier participation in contingency planning and incident response before an event occurs. The framework mandates establishing an incident response management program that explicitly addresses incidents originating from the supply chain, ensuring that internal checks and balances validate that service providers are actively disclosing vulnerabilities.
Critical Playbook Components
A modern Vendor Incident Playbook bridges the gap between technical operations and legal compliance. It must contain the following actionable tracks:
1. Triage and Access Containment The immediate priority is preventing the vendor's compromise from pivoting into the enterprise network. The playbook must include explicit, step-by-step instructions for revoking API keys, rotating OAuth tokens, suspending Single Sign-On (SSO) federations, and nullifying webhook endpoints associated with the compromised vendor. In the Instructure incident, rotating API credentials and monitoring for personalized phishing campaigns were immediate, non-negotiable post-breach necessities.
2. Contractual and Regulatory Activation Unlike internal incidents, third-party breaches are governed by Master Services Agreements (MSAs) and Data Processing Agreements (DPAs). The playbook must detail exactly how to activate the vendor's contractual notification obligations. Furthermore, if the SaaS provider processes Personally Identifiable Information (PII) or Protected Health Information (PHI), the playbook must immediately trigger the organization's own regulatory notification timelines under frameworks like GDPR, HIPAA, or CCPA. As the data controller, the enterprise remains legally liable for the breach, regardless of the vendor's failures.
3. Fallback Operations Deployment The playbook must document the precise procedures for shifting operations to the exportable state architecture discussed earlier. This includes instructions on how to activate read-only UIs, redirect traffic to internal data lakes, and instruct customer support teams on manual workarounds while the primary system remains degraded.
4. Forensic Coordination and Evidence Preservation The internal Incident Response Team (IRT) must gather and preserve local evidence—such as API request logs, firewall telemetry, and database commit histories—to determine if the vendor's attackers managed to exfiltrate data from the enterprise side. Coordination with the vendor's external IR firm is essential to establish the exact timeline of the exposure window.
5. Post-Incident Review and Vendor Reassessment Once the incident is resolved, the playbook mandates a formal review of the vendor's response quality. Did the vendor communicate transparently? Did they meet their Service Level Agreements (SLAs)? This data must be documented and fed directly into the vendor risk management lifecycle, potentially triggering contract renegotiation or a migration to a competitor.
7. Chaos Engineering for Third-Party Dependencies
Theoretical architecture is entirely meaningless until it survives contact with a real failure. Traditional unit tests and staging environments cannot replicate the sheer unpredictability of distributed network partitions, cloud provider transient errors, or a ransomware attack wiping out a vendor's API.
To guarantee that exportable state pipelines and graceful degradation mechanisms actually function, organizations must adopt Chaos Engineering. Pioneered by Netflix in 2010 to test AWS cloud resilience with their “Chaos Monkey” tooling, Chaos Engineering is the discipline of proactively injecting controlled failures into systems to uncover weaknesses before they manifest as customer-facing outages. Today, similar thinking is being applied to AI and automation platforms, from simple copilots to complex AI agent swarms that write your code.
The Principles of Chaos
Chaos engineering is not random, careless destruction; it is a systematic, scientific method. According to the core principles of the discipline, experiments must follow a structured approach:
- Define the Steady State: Establish baseline metrics for normal operational behavior. Focus on measurable outputs that correlate to customer success (e.g., checkout completion rate, API latency percentiles, stream starts per second) rather than internal implementation details.
- Formulate a Hypothesis: Predict how the system will react to a specific fault. For example: “If the third-party payment API latency increases by 500ms, the circuit breaker will open, the UI will display a ‘processing delay’ message, and no orders will be dropped from the asynchronous queue.”
- Inject the Fault (Contain the Blast Radius): Introduce the failure. Start with the smallest possible scope—perhaps affecting only 1% of traffic or a specific staging environment—before expanding to build confidence.
- Observe and Measure: Monitor the steady-state metrics using established probes. If the metrics deviate unacceptably and severely impact customers, abort the experiment immediately using an automated halt mechanism.
- Learn and Improve: Analyze the gaps in observability and architectural response, fix the bugs (e.g., implementing request-coalescing locks or randomized TTL back-offs), and automate the test to prevent future regression.
Simulating SaaS Outages Safely
Testing the failure of internal microservices is straightforward; testing the failure of an external SaaS vendor presents unique challenges. Organizations cannot launch denial-of-service attacks against a vendor's public API to test their own fallback systems without violating Terms of Service and inviting legal repercussions.
Instead, engineering teams must simulate the dependency loss internally. There are two primary mechanisms for achieving this without breaking vendor relationships:
1. Layer 7 Proxy Interception By routing all outbound API requests through a Layer 7 (Application Layer) proxy, teams can modify the proxy's middleware to arbitrarily drop requests, inject HTTP 503 errors, or artificially inflate latency. This effectively “blackholes” the vendor exclusively from the perspective of the internal application, perfectly mimicking a network partition or a total vendor collapse without generating a single byte of external traffic.
2. Feature Flags and Mock Services Feature flags (or toggles) offer a highly controlled mechanism for chaos testing. By wrapping the code that calls the external SaaS dependency in a feature flag, engineers can dynamically route traffic to a mock service or forcefully trigger the fallback logic without redeploying any code.
This allows for precision targeting. A team can scope the simulated failure to a specific geographic region, a beta-testing user segment, or even a single internal test account. If the system responds poorly to the simulated failure, the flag is simply toggled off, providing an instant, risk-free rollback mechanism that is far faster and less stressful than reverting a software deployment.
Executing Game Days
The culmination of chaos engineering is the “Game Day”—a planned, cross-functional rehearsal where engineering, operations, and security teams gather to simulate a major incident in real-time.
During a Game Day focused on third-party SaaS dependency, the facilitator might use a tool like Gremlin or Litmus to artificially inject network latency into the connection pool reserved for a critical vendor. As the latency spikes, the team observes the application's telemetry. Does the circuit breaker trip? Does the local data cache take over seamlessly? Do the monitoring alarms fire correctly, or are the Site Reliability Engineers (SREs) flying blind because the alerting thresholds are misconfigured?
These exercises transform theoretical resilience into proven operational muscle memory, shifting the engineering culture from reactive firefighting to proactive assurance.
8. What to Do This Quarter: A Concrete Starting Checklist
Recognizing the existential threat of SaaS dependency failure is insufficient without a concrete timeline for remediation. Executives must mandate a structural review of third-party architecture immediately. Many organizations bundle this with broader digital modernization work or even with project rescue efforts when existing systems are already under stress.
Days 1–30: Visibility and Mapping
- Execute an automated discovery scan utilizing ITSM integrations to document all SaaS applications currently interacting with corporate data.
- Classify the inventory into Tier 1 (Critical), Tier 2 (Important), and Tier 3 (Convenient) based strictly on the operational blast radius and true cost of downtime.
- Demand documentation detailing the fourth and fifth-party infrastructure underpinning Tier 1 vendors to identify hidden geographic or cloud provider concentration risks.
Days 31–60: Architectural Assessment
- Evaluate the extraction pipelines for all Tier 1 SaaS dependencies. Ensure that mission-critical state data is continuously synchronized to a localized, controlled data store using CDC or reliable incremental extraction.
- Audit the application codebase for hard dependencies. Implement circuit breakers, dead letter queues, and load shedding mechanisms around external API calls, and make sure these patterns fit cleanly into your existing DevOps practices and CI/CD pipelines.
Days 61–90: Resilience Testing and Procedural Alignment
- Draft the Vendor Incident Playbook, ensuring tight alignment with NIST SP 800-161 supply chain guidelines for legal, forensic, and operational procedures.
- Schedule a localized Game Day. Use an L7 proxy or feature flags to safely simulate the total loss of a Tier 2 dependency in a staging environment to observe the degradation mechanisms in action and validate alerting thresholds.
Conclusion
The ransomware attack that crippled Canvas during finals week serves as a stark reminder that the cloud does not insulate an organization from risk; it merely transfers the physical infrastructure to an external entity while amplifying systemic interdependencies. Vendor risk management can no longer be relegated to the compliance department as an annual paperwork exercise. It is a fundamental engineering and architectural imperative.
By dynamically mapping the true operational blast radius of SaaS dependencies, calculating the unforgiving economics of downtime, and investing strategically in custom adjacent tooling—such as exportable state pipelines and graceful degradation patterns—the enterprise reclaims its sovereignty. Firms leveraging modern engineering practices, supported by custom software development partners proficient in architectures utilizing robust environments like PostgreSQL, Kubernetes, and Azure DevOps On-Prem, can transform catastrophic vendor outages into minor operational inconveniences. Resilience is not purchased through a vendor SLA; it is architected intentionally before the crisis arrives, just as future-focused enterprises are now architecting internal AI app stores to keep critical workflows under their direct control.
FAQ
What is the difference between a generic Disaster Recovery Plan (DRP) and a Vendor Incident Playbook? A traditional DRP focuses on restoring internal infrastructure, such as spinning up backup servers after a hardware failure or natural disaster. A Vendor Incident Playbook is specifically designed to manage external compromises, focusing on revoking API access, coordinating cross-organizational forensics, triggering contractual legal notifications under strict MSAs and DPAs, and shifting operations to localized data caches while the third party remains offline.
Why is reliance on a vendor's SOC 2 report insufficient for risk management? A SOC 2 report provides a point-in-time snapshot of a vendor's theoretical security controls and policies, designed primarily for compliance checklists. It offers no operational value during an active outage, does not address the dynamic nature of rapid cloud deployments, and cannot restore business continuity if the vendor experiences a catastrophic failure or ransomware attack.
How can an organization test for vendor outages without violating SaaS Terms of Service? Organizations can utilize Chaos Engineering techniques internally by employing Layer 7 proxies to artificially drop outbound requests, or by using feature flags to reroute traffic to mock services. This safely simulates a total vendor outage from the perspective of the internal application without generating aggressive or malicious traffic against the actual vendor's public API. The same disciplined approach you’d use to compare competing AI copilots for developers should apply when you evaluate and harden every critical dependency in your stack.
Supporting Links
- https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-161r1.pdf
- https://www.isaca.org/resources/news-and-trends/industry-news/2026/enhancing-third-party-risk-management-moving-from-questionnaire-fatigue-to-contextual-assurance
https://www.gremlin.com/chaos-engineering
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.