
Stop Burning Tokens: Why Browser AI Costs 45× More
May 20, 2026 / Bryan Reynolds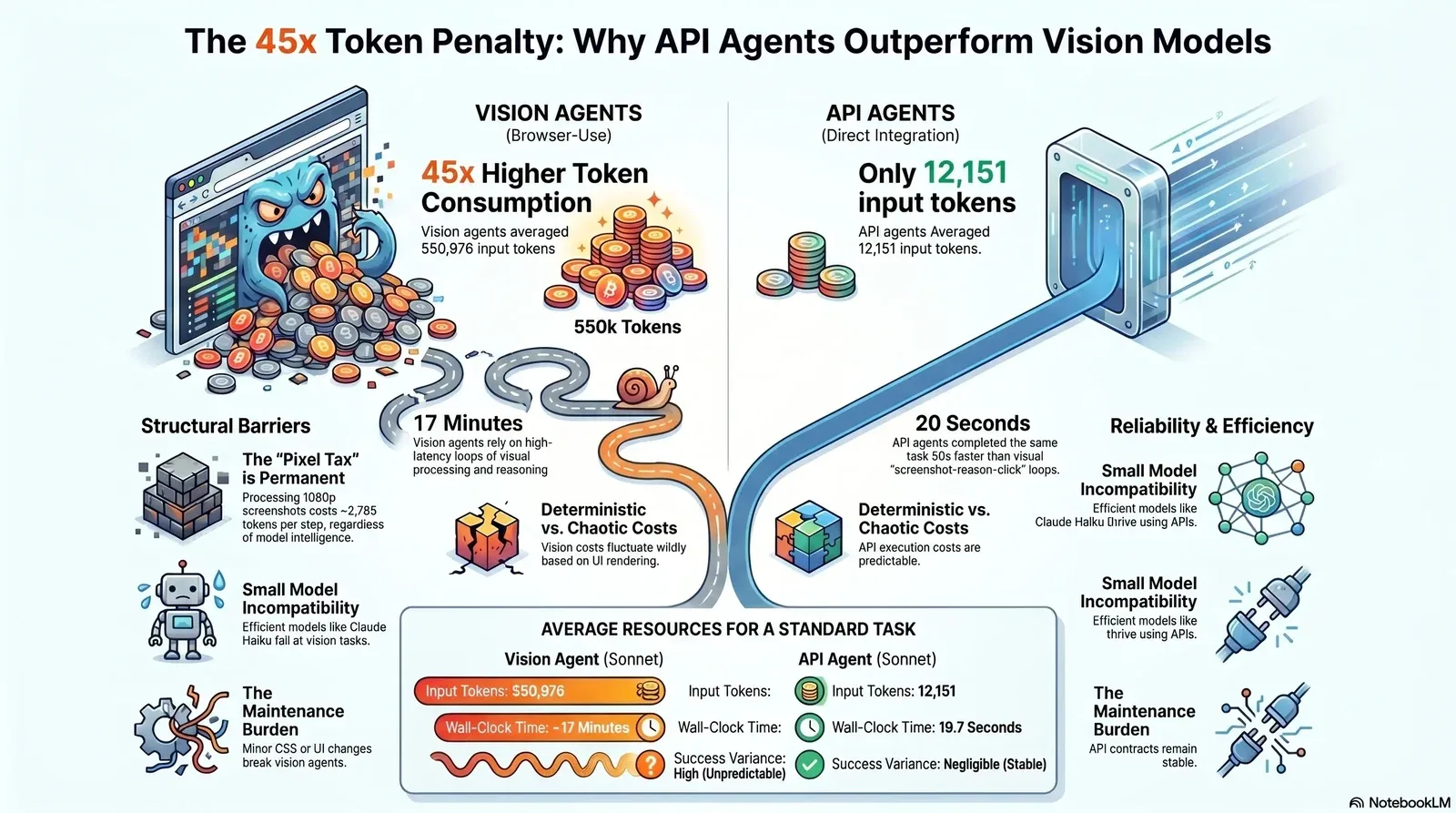
Why Your AI Agent's Browser Is Burning 45× More Tokens Than It Needs To
A new Reflex benchmark found AI agents using visual web interaction can consume 45 times more tokens than agents using APIs, suggesting that “human-like” browser automation may be far more expensive than structured software integration. The enterprise rush toward agentic application architecture has largely centered on an intuitive but fundamentally flawed default: deploying Large Language Models (LLMs) to navigate software exactly as human operators do. Driven by the commercial appeal of zero-integration deployments, engineering teams frequently configure AI agents to read pixels on a screen, interpret graphical user interfaces (GUIs), and issue simulated mouse clicks.
This visual emulation requires no backend integration and allows teams to bypass the difficult work of designing structured API surfaces. However, replacing an application programming interface with an optical character recognition (OCR) and screenshot loop introduces a massive, often unmodeled financial penalty. The assumption that visual operation is a scalable default has been systematically dismantled by recent empirical testing, revealing that vision agents are an expensive fallback for systems you do not control, not a default architecture.
For any system you can put an API surface on—yours, a customer's, or a partner's—the API path wins on cost, speed, and reliability by an embarrassing margin. Most teams reach for computer-use because it feels easier. The data puts a dollar figure on that decision, exposing a reality where runtime is measured in minutes rather than seconds, and where the economic viability of small, hyper-efficient models is entirely erased. This report translates the underlying benchmark data, tokenization mathematics, and compounding failure rates of visual automation into a practical architectural decision framework for executives building agentic features and thinking about their broader enterprise AI readiness.
The Reflex Benchmark: Defining the Structural Cost Gap
To quantify the economic disparity between visual emulation and structured integration, the enterprise application platform Reflex designed an experiment utilizing their 0.9 platform release. Reflex 0.9 includes a plugin that auto-generates HTTP endpoints from an application's event handlers, making it possible to run an API path alongside a GUI path without writing a second codebase. The core objective was to put a definitive price tag on vision agents by isolating the interface as the sole variable.
The test deployed Anthropic's Claude Sonnet model against the same administrative web panel to complete a highly specific, fixed dataset task. The prompt directed the agent to find a customer named Smith who had complained about a recent order, identify the Smith with the most orders, accept all their pending reviews, and mark their most recent order as delivered.
Two distinct architectural approaches were evaluated:
- The Vision Agent (Browser-Use): Claude Sonnet was equipped with
browser-useversion 0.12, an open-source tool for automated web browser operation that relies on image processing to operate an application. - The API Agent: The exact same Claude Sonnet model interacted with the web application through HTTP endpoints. It invoked the identical processing mechanisms as the UI and received structured JSON data in response, rather than analyzing a web page screenshot.
The results exposed a fundamental, structural inefficiency in the vision-based approach.
| Metric | Vision Agent (Sonnet) | API Agent (Sonnet) | API Agent (Haiku) |
|---|---|---|---|
| Steps / Calls | 53 ± 13 | 8 ± 0 | 8 ± 0 |
| Wall-Clock Time | 1003s ± 254s (~17 min) | 19.7s ± 2.8s | 7.7s ± 0.5s |
| Input Tokens | 550,976 ± 178,849 | 12,151 ± 27 | 9,478 ± 809 |
| Output Tokens | 37,962 ± 10,850 | 934 ± 41 | 819 ± 52 |
Data sourced from the May 2026 Reflex benchmark. Values represent mean ± sample standard deviation. Vision path capped at 3 trials; API path run 5 times.

Analyzing the Token Multiplier and Operational Variance
The vision agent consumed an average of 550,976 input tokens, representing roughly a 45× increase over the API agent's 12,151 input tokens. This extraordinary consumption is driven by the screenshot-reason-click loop. The engineering team noted that with an abstract prompt, the vision agent found a single review, accepted it, and moved on without ever paginating to find the rest. To force the agent to complete the task, the engineers had to rewrite the prompt into a rigid 14-step walkthrough. Even with this intense level of prompt engineering, the vision agent averaged 53 round-trips to the server per run. Each step carried a full-page screenshot worth thousands of tokens, the vast majority of which were expended merely looking at static table rows and dropdown menus.
Conversely, the API agent required only a six-sentence prompt and zero iteration. It instantly identified the correct parameters and executed 8 identical HTTP calls across every single trial. For example, it called GET /reviews?customer_id=421&status=pending, which returned the necessary data directly. There was nothing to infer from pixels, nothing to retry, and no need to paginate visually.
Variance also serves as a critical differentiator between the two architectures. The visual approach exhibited severe non-determinism. Across the three trials, the vision agent's input token consumption fluctuated wildly between 407,000 and 751,000 tokens, with the cycle count ranging from 43 to 68 steps. The wall-clock time spanned from 749 seconds to 1,257 seconds. The screenshot-reason-click loop inherently contains so much instability that a single run cannot serve as a reliable cost estimate. The API path had no such variance. Sonnet hit identical tool calls on every trial, with input token counts varying by an almost negligible ±27 tokens across all five runs. When structured responses give an LLM no reason to deviate, execution becomes deterministic, and cloud spend becomes predictable.
Why Screenshots Are Architecturally Expensive
The financial chasm between API and vision agents is not a temporary anomaly that will be resolved by the next generation of models. The cost gap is structural. An agent that must see in order to act will continually pay for the privilege of sight, regardless of how efficient the underlying reasoning engine becomes. Better vision models do not reduce the number of screenshots required to navigate a multi-step workflow; they simply process those screenshots with higher fidelity.
To fully understand the 45× multiplier, engineering leaders must examine the underlying tokenization mathematics utilized by frontier multimodal models and how that impacts overall AI ROI modeling.
The Pixel-to-Token Conversion Formula
When a screenshot is passed to an Anthropic Claude model, the image is segmented into token representations based on its resolution and area. The base formula dictates that an image utilizes approximately (width × height) / 750 tokens.
Historically, Claude 4.6 and its predecessors capped the maximal native image resolution at 1,568 pixels on the long edge. Any screenshot larger than this was automatically downscaled to fit a maximum budget of roughly 1,568 tokens per image, preserving the aspect ratio but losing fine visual detail. However, the release of Claude Opus 4.7 shifted this dynamic significantly. Opus 4.7 supports higher visual fidelity, allowing images up to 2,576 pixels on the long edge before downscaling, which pushes the theoretical maximum token cost per image to 4,784 tokens. Furthermore, Opus 4.7 utilizes a new tokenizer that produces 1.0x to 1.35x more tokens for the exact same input compared to version 4.6.
| Image Size & Resolution | Input Tokens (Claude Sonnet 4.6) | Input Tokens (Claude Opus 4.7) | Cost per 1,000 Images (Opus 4.7 at $5/M) |
|---|---|---|---|
| 1000x1000 px (1 MP) | ~1,334 | ~1,334 | ~$6.70 |
| 1092x1092 px (1.19 MP) | ~1,568 | ~1,590 | ~$8.00 |
| 1920x1080 px (2.07 MP) | ~1,568 (downscaled) | ~2,765 | ~$14.00 |
| 2000x1500 px (3 MP) | ~1,568 (downscaled) | ~4,000 | ~$20.00 |
Token estimations and cost calculations based on standard input token rates. Claude Opus 4.7 charges $5.00 per million input tokens, while Sonnet 4.6 charges $3.00 per million.
When a computer-use agent attempts to navigate a dense enterprise GUI, it requires high fidelity to accurately identify small interactive elements like dropdown arrows, pagination buttons, and fine text. Therefore, feeding a standard 1080p desktop screenshot into Opus 4.7 to determine a single mouse click costs roughly 2,765 input tokens. At 53 steps, the baseline visual processing alone accounts for over 146,000 tokens, before accounting for the text prompt, the history of previous actions, or the tool definitions.
The Compounding Costs of Tool Overhead and Context
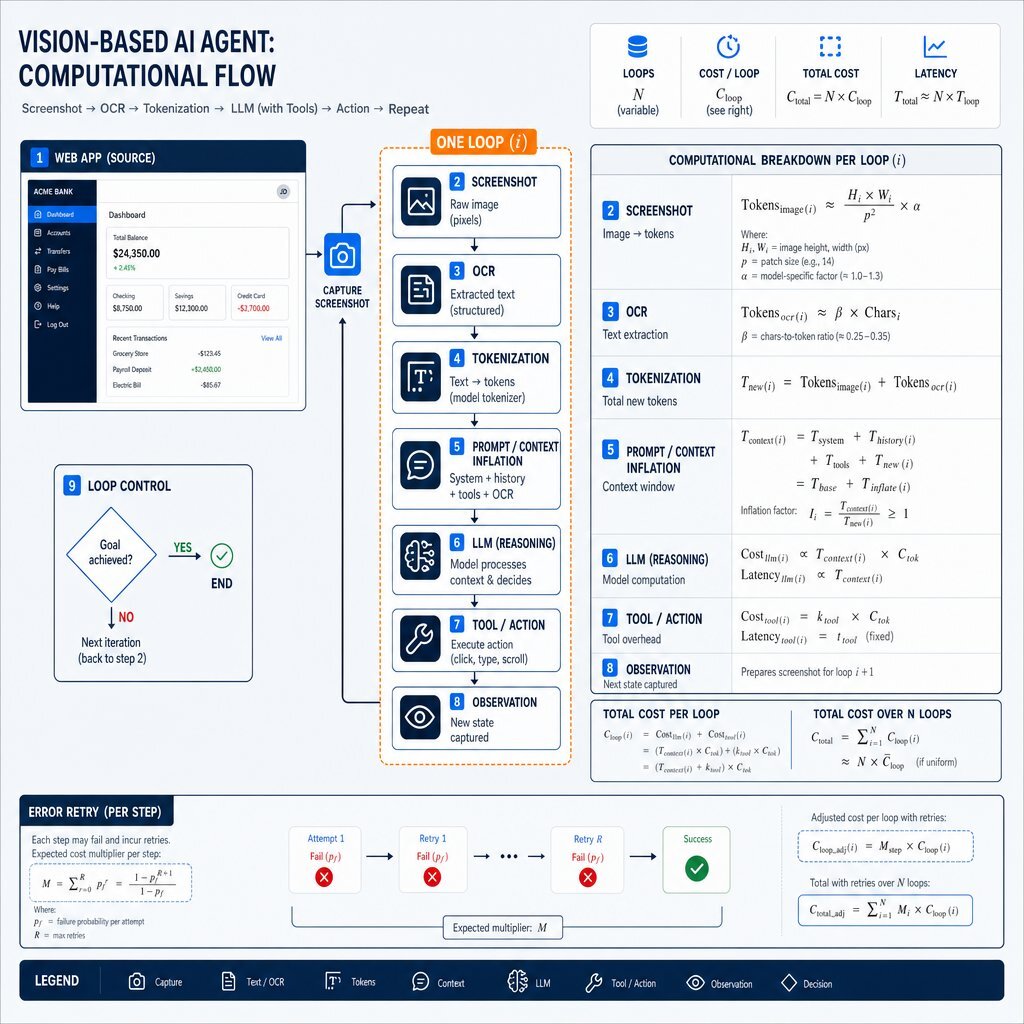
The raw image tokenization is only the starting point. Computer-use architectures require heavy system prompts and complex tool definitions to function. According to Anthropic's pricing documentation, deploying the computer-use beta inherently adds 466 to 499 tokens to the system prompt immediately. The computer-use tool definition itself requires an additional 735 tokens per cycle for Claude 4.x models.
In a multi-step workflow, the LLM must maintain the context of its previous actions to plan its next move. While prompt caching can mitigate the cost of historical context, it introduces its own pricing modifiers. If screenshots and text are cached, they are billed at 1.25x the base input price for a 5-minute write. Subsequent cache reads are charged at 0.1x (10%) of the base input price. However, prompt caching is highly ineffective for the visual component of browser automation. Every new screenshot generated after a click or scroll represents a fundamentally novel state that must be tokenized and written to the cache at the full premium price.
Further compounding the cost is data residency routing. If an enterprise requires US-only inference to satisfy compliance mandates, models like Claude 4.6+ incur a 1.1x multiplier on all token pricing, applying directly to the massive visual payloads. When a vision agent requires dozens of distinct state observations to complete a workflow, the compounding cost of capturing, tokenizing, caching, and evaluating those high-resolution screenshots overwhelms the economic viability of the feature.
The Small-Model Viability Floor
Perhaps the most restrictive finding of the Reflex benchmark was the complete failure of the smaller, highly efficient Claude Haiku model on the vision path. The takeaway is clear: small models can use APIs, but they often cannot use vision.
The failure was not inherently due to a lack of logical reasoning capacity, but rather an inability to reliably produce the complex structured-output schema required by the browser-use 0.12 tool in vision mode. End-to-end visual operation is an intensely demanding multimodal task. It requires a model to simultaneously process dense pixel grids, map those pixels to absolute coordinate geometries, and format the requested action into a strict JSON schema without hallucinating key-value pairs. Haiku's attention mechanisms collapsed under this concurrent payload constraint, failing to output the schema reliably in either vision or text-only mode during the visual execution path.
This fragility persists even as tooling attempts to optimize the interaction. The browser-use 0.12 release introduced significant optimizations, including an Agent-Optimized State that returns a structured list of clickable elements via indices (e.g., browser-use click 0) rather than forcing the agent to output complex CSS or XPath selectors. The 0.12.6 patch also utilized a SchemaOptimizer to flatten schemas for Bedrock structured output and removed oneOf properties to prevent breaking API clients. Despite these extensive engineering efforts to simplify the interaction surface, the multimodal overhead remained too heavy for small models to carry.
However, when shifted to the API path, the narrative reversed entirely. Relieved of the burden of visual processing, Haiku finished the identical administrative task in under 8 seconds, utilizing fewer than 10,000 input tokens. This was the cheapest and fastest configuration tested in the entire benchmark.
This dynamic fundamentally alters agent deployment economics. Claude Haiku 4.5 is priced at $1.00 per million input tokens, compared to Sonnet 4.6 at $3.00 and Opus 4.7 at $5.00. Haiku 3 is even cheaper at $0.25 per million. Visual architectures artificially constrain the deployment environment to frontier-class, high-cost models. By relying on computer-use, engineering teams lock themselves out of the economic advantages of tier-3 models and increase the risk of hidden AI-driven technical debt.
The Second-Order Costs of Browser Automation
Beyond the easily quantifiable token bill, visual AI agents carry severe second-order architectural penalties. Extensive benchmarking across thousands of automated tasks reveals that vision-based interaction frameworks suffer from chronic reliability deficits, high latency, and massive maintenance burdens.
The Vulnerability of Grounding and Composed Architectures
Computer-use agents typically rely on one of two architectural patterns: End-to-End (E2E) models, which map pixels directly to action predictions, and Composed Agents, which divide the workflow into distinct perception, reasoning, and acting phases.
Composed agents rely heavily on “grounding models” to translate a screenshot into a structured UI description containing bounding boxes, spatial locations, and semantic labels. Grounding remains the weakest link in these systems. In a specialized UI grounding benchmark evaluating how well models identify exact pixel locations from natural-language instructions on 2560×1440 desktop screenshots, specialized models like UI-TARS achieved only a ~37.8% accuracy rate. While leading models like Qwen3-VL reached ~90% accuracy, they still exhibited pixel errors. When a grounding model misinterprets the location of a UI element by even a few pixels, the subsequent planning model issues a failed click. This triggers a cascade of retries, generates new screenshots, and exponentially increases token consumption.
Real-World Reliability and Latency Metrics
The theoretical fragility of computer-use agents is validated by operational data. An exhaustive review of 12 AIMultiple benchmarks, encompassing nearly 70 AI agents across over 1,000 tasks, highlights the current limitations of these tools.
When deployed against a business workflow benchmark requiring the extraction and manipulation of interactive graph data on an external website (observablehq.com), visual agents demonstrated significant fail rates:
- ChatGPT Agent: Scored 80%, successfully handling complex navigation but failing to correctly update button configurations.
- Browser-Use (Open Source): Scored only 30%. While it successfully signed in, it deleted the original template, failed to preserve styling cells, and wrote data code into the wrong areas.
- Anthropic Computer Use: Scored 0%. The agent completely refused to sign into the target account due to internal safety guardrails regarding credential usage.
In a web search and scraping benchmark tasked with finding B2B tech funding data, performance was similarly poor. Phidata hallucinated links and pricing information that did not exist, Perplexity provided companies with incorrect fundraising dates, and Anthropic Computer Use failed to provide any valid answers.
Latency is equally problematic. Remote browser infrastructure providers (such as Bright Data, Browserbase, and BrowserAI) offer underlying execution environments for these agents. Load testing 250 concurrent AI agents against them reveals a harsh reality: there is a direct, negative correlation between speed and success. Unblocking technologies required to bypass anti-scraping firewalls inherently degrade execution times. Bright Data achieved a 95% success rate but required robust anti-bot features, whereas faster tools like Airtop failed 60% of the time. In Model Context Protocol (MCP) server tests for web access, the fastest provider (Firecrawl) took 7 seconds per task, while others like Hyperbrowser took over 90 seconds to handle browser automation. This extends the wall-clock latency of agent workflows far beyond acceptable limits for real-time B2B user experiences.
The Maintenance Burden and Mobile Instability
UI-driven agents generate immense technical debt. Engineering teams intentionally redesign web interfaces, shuffle button locations, and alter CSS hierarchies to improve user experience. Every aesthetic update to the GUI threatens to break the brittle visual and DOM-parsing logic of a computer-use agent.
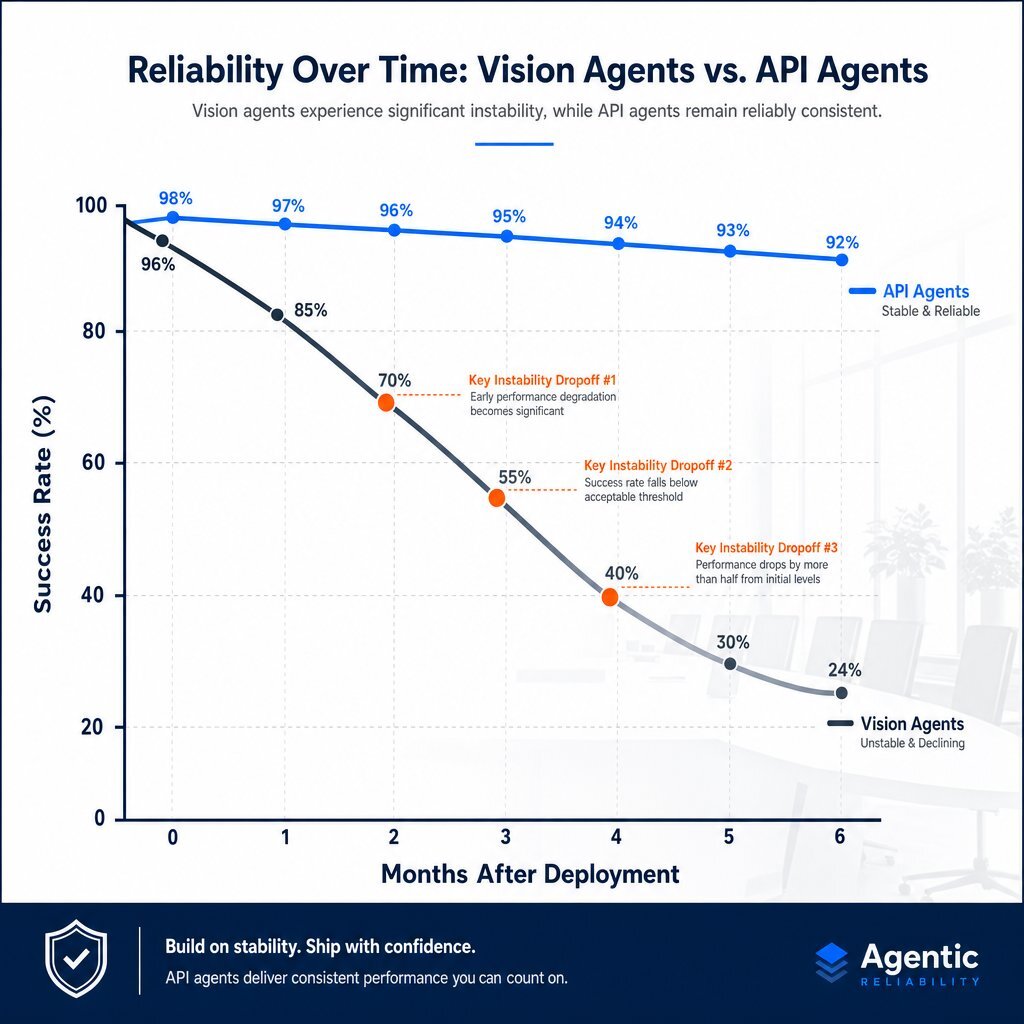
This is highly evident in open-source web agent benchmarks utilizing the WebVoyager test suite (643 tasks across 15 sites). The Agent-E framework, which relies entirely on DOM parsing without vision models, scored 73.1% overall. However, while it achieved 95.7% accuracy on static pages, its success rate plummeted to 27.3% on dynamic sites like Booking.com, where DOM structures aggressively mutate based on user interaction.
The instability extends to mobile environments. In a benchmark of 65 real-world tasks using an Android emulator, the best-performing mobile agent (DroidRun) achieved only a 43% success rate, costing $0.075 and 3,225 tokens per successful task. AppAgent, which relies heavily on processing labeled screenshots through multimodal LLMs, achieved a dismal 7% success rate and cost $0.90 per task. The high vision processing overhead failed to translate into task completion, proving that emulating human phone usage is not yet a viable business strategy.
When Computer-Use Actually Earns Its Cost
The takeaway for teams building agentic products is not to universally ban computer-use. Vision agents are an incredibly powerful tool for a specific, narrow category of problems. The cost is justifiable only when an organization faces an absolute lack of control over the target environment and has no programmatic alternative.
Third-Party SaaS Without APIs
If a critical enterprise workflow depends on scraping data from or inputting data into a proprietary external vendor that actively restricts API access, remote browser agents and vision capabilities are the only viable solutions. In these scenarios, the 45× token penalty is the cost of doing business with a closed ecosystem, and should be weighed against options like rebuilding the workflow in-house or following a post-SaaSocalypse custom platform strategy.
Legacy Desktop Systems and Mainframes
Mainframe terminals, local file systems, and legacy monolithic desktop applications that lack programmatic endpoints require OS-level computer-use agents to bridge the automation gap. Tools like Open Interpreter or Anthropic's Claude Cowork (which operates a local visual workspace on macOS) are designed precisely for this. In the OSWorld benchmark, which tests agents across 369 real-world tasks involving OS file operations and multi-app workflows, top-ranked agentic frameworks like Simular Agent S3 achieved a 72.6% success rate by acting directly on the desktop.
End-to-End UI Testing and Accessibility
Vision agents excel in Quality Assurance (QA) environments where the specific objective is to evaluate the graphical rendering and visual accessibility of an application across various viewports. Evaluating generated applications through user-visible browser interactions, rather than internal unit tests, accurately reflects whether real users can complete required workflows. In these controlled CI/CD pipeline tests, the token cost is absorbed as a necessary QA expense.
Designing for API-First Agents: The MCP Alternative
For any greenfield application, internal tool, or modernized microservice environment where the enterprise controls the codebase, the API path is non-negotiable. The excuse that “we don't have time to build APIs” is rarely accurate; the engineering effort required to prompt-engineer a vision agent through 14 steps of UI navigation far exceeds the effort to expose a basic REST endpoint.
The antidote to the inefficiency of visual scraping is the Model Context Protocol (MCP). Positioned by its architects as the “USB-C port for AI applications,” MCP is an open-source standard designed to connect AI agents directly to external data sources, tools, and workflows. It fits naturally into a broader strategy of building internal AI app ecosystems, such as an enterprise AI app store of specialized agents.
Structured Integration and Certified Tools
MCP shifts the agentic paradigm from UI interaction to capability discovery. Instead of reading an HTML document or analyzing a screenshot, an API-first agent communicates with an MCP Server that exposes specific “Agent Skills.” This programmatic foundation ensures that AI agents and backend systems interact using a universal, structured language.
In practice, an API-first architecture relies on co-designing the agent's tool surface alongside the application. When an operation requires reading data, the agent dynamically queries the API specification to discover relevant operations, bypassing the GUI entirely. For operations that modify state, move money, or cross compliance boundaries, the agent does not navigate a web form. Instead, it calls a “Certified Tool”—a hardened, audited wrapper that enforces sequencing rules, permission checks, and audit trails before executing the API call. The LLM outputs a strictly formatted JSON payload defining the parameters, and the backend returns structured data directly to the context window.
This approach has been heavily validated in agentic CLI (Command Line Interface) tool benchmarks. When assessing AI coding agents—where the environment is strictly text and API-based—models demonstrate significantly higher utility. In an evaluation of 10 complex software development scenarios involving over 5,000 automated test executions, tools operating via API integrations achieved robust success. Codex scored 67.7% overall, and Junie scored 63.5%. When agents operate in structured environments with clear code contracts, their ability to reason and execute scales predictably.
Furthermore, relying on structured agentic search APIs yields dramatically better results than visual web scraping. In benchmarks evaluating search APIs for agents, native structured endpoints like Brave Search delivered an Agent Score of 14.89 with an incredibly low latency of 669 milliseconds. Firecrawl, a data extraction API that converts live pages into clean Markdown for LLMs, achieved a score of 14.58 with 1.3 seconds of latency. Compared to the 17 minutes required for the vision agent to navigate the Reflex benchmark, native API retrieval is functionally instantaneous and strengthens the kind of data infrastructure that reduces AI hallucinations.
Modeling the Spend Before You Commit
Before committing to an architecture, engineering leaders must accurately model the projected spend. Relying on basic unit costs (e.g., “$3.00 per million tokens”) is insufficient when dealing with autonomous agents. Financial modeling must account for the stochastic nature of the systems.
To calculate the True Cost per Task (TCPT) for an agentic feature, teams must account for four primary variables:
- Base Context Overhead: The initial cost of the system prompt. For computer-use agents, this immediately adds ~1,200 input tokens (system instructions plus tool definitions). For API agents, this includes the schema definitions of the available endpoints.
- Payload Tokenization: For vision agents, this requires estimating the number of interactions (clicks, scrolls, typing) multiplied by the screenshot token cost (e.g., 2,765 tokens per 1080p image for Opus 4.7). For API agents, this is the token length of the expected JSON response.
- The Retry Multiplier: Vision agents frequently misclick or misinterpret grounding coordinates. A conservative multiplier of 1.4x to 1.6x should be applied to the vision path to account for error recovery cycles and hallucinated logic paths. API agents executing single-shot commands generally carry a multiplier of 1.0x.
- The Half-Life of Agent Reliability: To generate true ROI, organizations must account for the “half-life” of AI success. Because external UI structures mutate, a vision agent that succeeds 90% of the time in month one may degrade to a 50% success rate by month six as unannounced changes to DOMs cause workflows to fracture. This necessitates modeling a continuous maintenance budget for prompt engineering and workflow repair.
By mapping these inputs, the cost disparity becomes undeniable. A single successful API execution utilizing a model like Claude Haiku will cost fractions of a cent and execute in under ten seconds. The equivalent visual execution utilizing Claude Sonnet will cost significantly more per run, require minutes of wall-clock time, and demand ongoing maintenance as interfaces evolve. Thinking about these dynamics early is exactly what a disciplined 90-day enterprise AI implementation plan should cover.
A Decision Framework for B2B Product Teams
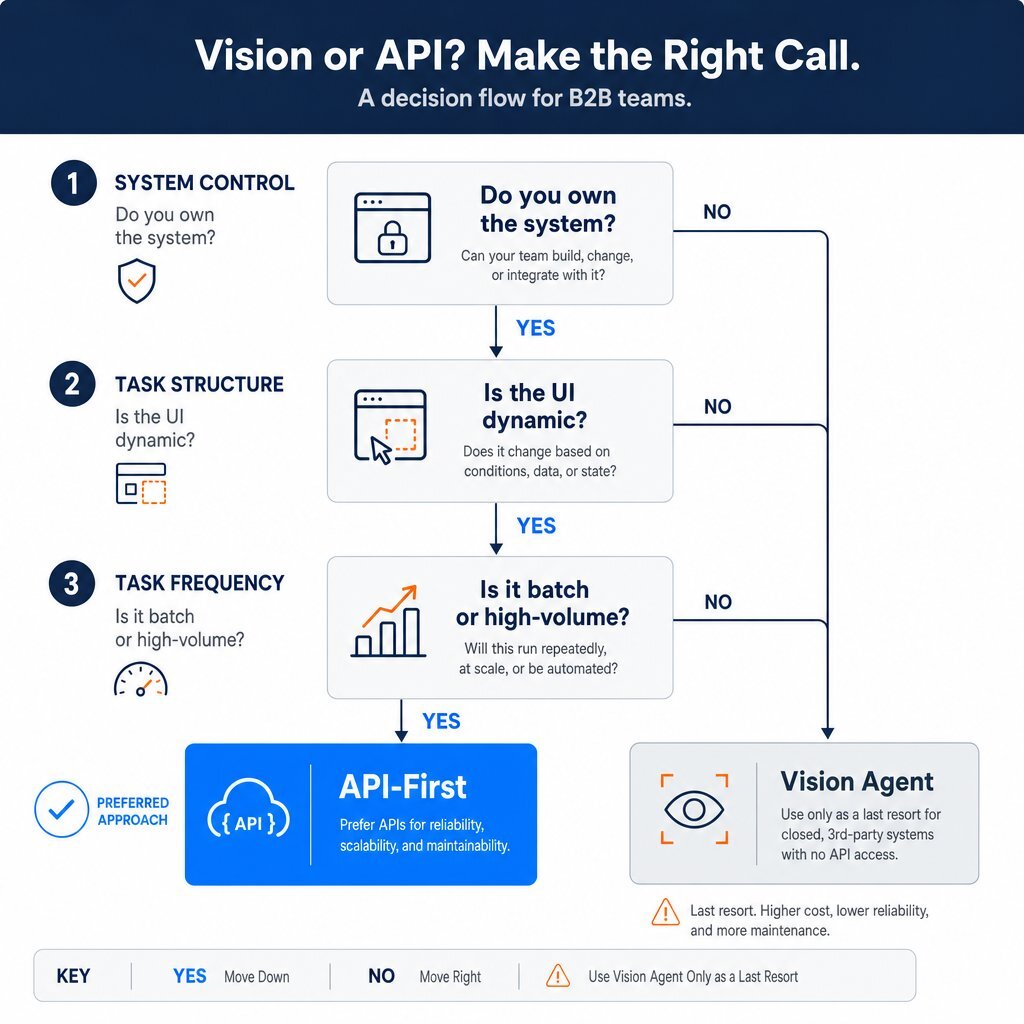
For a B2B product team building their first agentic feature, deciding between an API and a vision architecture is the highest-leverage decision they will make. Following a strict sequence of decisions before writing any agent code prevents the accumulation of unmanageable technical debt.
- Assess System Control: Do you own the target system, or does a compliant partner offer robust APIs?
- If Yes: Proceed strictly to API-First Architecture.
- If No: Proceed to Step 2.
- Assess Task Structure: Is the task highly repetitive, or does it require navigating dynamic, ever-changing DOM structures?
- If Dynamic: Re-evaluate the feature. Vision agents fail reliably on dynamic sites.
- If Repetitive/Static: Proceed to Step 3.
- Evaluate Task Frequency: Will this task be executed dozens of times a day, or is it an infrequent, batch-processed operation?
- If High Volume: The 45× token multiplier will destroy product margins. A hybrid approach utilizing an Agentic Search API (like Firecrawl or Exa AI) to structure the external data is required.
- If Low Volume: Deploy a Computer-Use Vision Agent.
This sort of simple, pragmatic framework also mirrors how leading teams think about where to plug copilots into their products. Instead of bolting a chatbot onto a UI, they design around clear workflows, APIs, and agents—similar to the approach described in From Chat Widgets to Copilots: The SaaS AI Revolution.
Conclusion
The allure of the computer-use vision agent is rooted in the promise of frictionless deployment. The ability to point an LLM at a screen and watch it operate software is an undeniably profound technical achievement. However, as the Reflex benchmark explicitly proves, treating this capability as a default architecture is a financial and operational miscalculation.
Burning 45 times more tokens to force a frontier model to visually parse dropdown menus and paginate through tables is an inefficient use of compute. It inflates operational costs, balloons wall-clock latency to nearly 20 minutes for basic tasks, introduces severe reliability risks through grounding failures, and locks applications out of the economic benefits provided by highly capable tier-3 models.
For modern enterprises, the directive is clear: visual agents are a last resort for systems entirely beyond your control. For every proprietary system, internal dashboard, and partner integration, the future of agentic AI is headless, structured, and API-first. By investing in Model Context Protocol integrations and deterministic endpoints today, organizations can deploy scalable, reliable AI workflows that actually generate, rather than consume, enterprise ROI. For teams ready to design resilient agentic architecture, partnering with experienced development teams like Baytech Consulting—who can also help you decide where to build versus buy AI capabilities—ensures that infrastructure is built correctly the first time, leveraging tailored technology to maximize business value.
Frequently Asked Questions
Will better vision models eventually make API agents obsolete?
No, the cost gap is structural rather than a temporary tuning issue. While future vision models will undoubtedly become more accurate at identifying UI elements and grounding coordinates, the fundamental requirement to convert millions of high-resolution pixels into tokens for every single interaction state will always remain exponentially more compute-intensive than transferring a few kilobytes of structured JSON data through an API. For regulated and security-sensitive environments, that difference also matters for governance and compliance, which is why many organizations pair API-first agents with a structured AI code approval and compliance framework.
Supporting Links
- https://reflex.dev/blog/computer-use-is-45x-more-expensive-than-structured-apis/
- https://www.metacto.com/blogs/anthropic-api-pricing-a-full-breakdown-of-costs-and-integration
Model Context Protocol Introduction
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.