
The Vibe Coding Hangover: Why Speed Is Breaking Enterprise Security
January 22, 2026 / Bryan ReynoldsExecutive Summary: The CTO's Dilemma in the Age of Algorithmic Generation
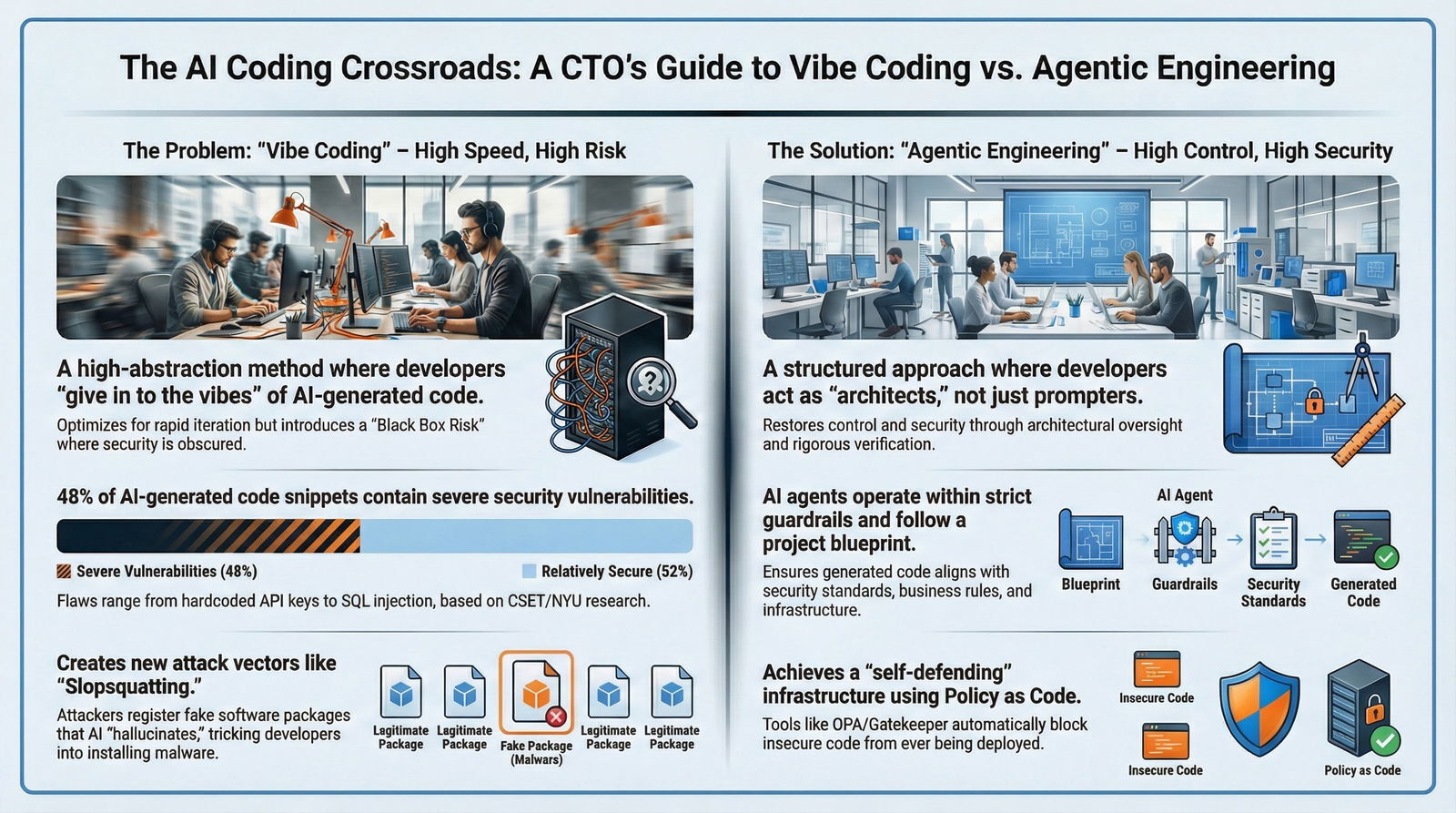
The software engineering landscape is currently undergoing its most radical transformation since the advent of the internet. We are witnessing a bifurcation in development methodologies that presents a stark strategic choice for the Visionary CTO and the IT Security Lead. On one side lies the seductive promise of "Vibe Coding"—a term popularized by Andrej Karpathy to describe a new, hyper-accelerated mode of development where human operators "give in to the vibes," delegating the bulk of syntax generation and logical implementation to Large Language Models (LLMs).
This approach promises to democratize creation, allowing "one-pizza teams" to deploy enterprise-scale applications at speeds previously thought impossible. It suggests a future where the friction of coding evaporates, replaced by the fluidity of natural language prompting.
However, on the other side of this equation lies a darker, empirically verified reality that is only now coming into sharp focus through forensic analysis and academic study. The rapid adoption of unguided AI coding tools is introducing a catastrophic density of security vulnerabilities into the global software supply chain. Recent audits have revealed that a staggering 170 out of 1,645 applications created by the popular "vibe coding" platform Lovable contained critical security flaws, specifically missing Row-Level Security (RLS) protocols that exposed sensitive user data to the public internet.
Furthermore, rigorous benchmarks from institutions like Georgetown's Center for Security and Emerging Technology (CSET) have consistently shown that approximately 48% of raw code snippets generated by popular LLMs contain severe security vulnerabilities, ranging from hardcoded API keys to SQL injection flaws.
This report serves as a definitive, comprehensive guide for the enterprise technology leader. It is not an argument against Artificial Intelligence; rather, it is a clear argument against unguided and unarchitected AI. We contrast the reckless speed of Vibe Coding with the disciplined, rigorous approach of Agentic Engineering. We analyze the anatomy of these new threat vectors—including the insidious phenomenon of "slopsquatting" via hallucinated dependencies—and outline the specific, architectural defenses required to secure AI-assisted workflows.
Baytech Consulting presents this deep-dive research not merely as an observation of current market trends, but as a transparency report on why our proprietary "Tailored Tech Advantage" approach prioritizes security architecture over raw generative speed. We position ourselves as the "safe pair of hands" in a chaotic market, leveraging a tech stack built on Azure DevOps, Kubernetes, and rigorous policy enforcement to deliver the benefits of AI without the existential risks. For leaders exploring how AI reshapes software delivery more broadly, our article The Future of AI-Driven Software Development in 2026 offers important strategic context that complements this report.
Part I: The Rise of "Vibe Coding" and the Erosion of Engineering Rigor
1.1 The Genesis of a New Paradigm
To understand the threat, one must first understand the shift in the developer's mindset. "Vibe Coding" is more than just internet slang; it represents a fundamental alteration in the psychological relationship between the creator and the machine. The term was coined and popularized in early 2025 by Andrej Karpathy, a leading figure in AI, who described it as a state where the developer "fully gives in to the vibes," embracing the exponential capabilities of LLMs and essentially "forgetting that the code even exists".
In this model, the developer transitions from a writer of logic to a manager of intent. They provide high-level natural language prompts, and the AI handles the implementation details—the syntax, the libraries, the memory management, and the error handling. This abstraction layer is incredibly powerful for rapid prototyping, or what Karpathy referred to as "throwaway weekend projects," where speed is the primary goal and long-term maintainability is irrelevant.
However, the danger arises when this "throwaway" methodology bleeds into the enterprise Software Development Life Cycle (SDLC). When methodologies designed for weekend experiments are applied to production systems handling financial transaction data, healthcare records, or proprietary algorithmic trade secrets, the results can be disastrous. The core issue is that LLMs operate on probability, not truth. They are prediction engines designed to optimize for plausibility—does this code look like the solution?—rather than correctness, efficiency, or security.

1.2 The Psychology of Automation Bias
The psychological trap that makes Vibe Coding so dangerous in a corporate environment is known as "Automation Bias." As humans, we have a cognitive tendency to trust the output of automated systems, assuming they are impartial and error-free. Studies indicate that a significant majority—76%—of technology workers mistakenly believe that AI-generated code is more secure than human-written code.
This misplaced trust leads to a reduction in scrutiny and a relaxation of standard review protocols. When an LLM produces a complex, 50-line function in seconds that would take a junior developer three hours to draft, the senior reviewer is often lulled into a false sense of security. The code looks clean; it is commented; it uses standard variable names. It vibes correctly. But this surface-level correctness masks deep structural flaws. The AI is not "thinking" about security boundaries; it is simply autocompleting a pattern based on its training data. And because its training data is the internet, it mimics the bad habits of the internet.
As Simon Willison, a veteran software developer and commentator, noted regarding the recent security failures in vibe-coded apps: "Vibe coding your way to a production codebase is clearly risky... The most obvious problem is that they're going to build stuff insecurely". The focus on "vibes"—on the feeling of flow and speed—actively discourages the friction required for security audits. Security is, by definition, a constraint. Vibe coding is, by definition, the removal of constraints.
1.3 The Erosion of "Deep Knowing"
Another critical, often overlooked consequence of Vibe Coding is the loss of "deep knowing" within the engineering team. When developers write code line-by-line, they build a mental model of the system's logic, its edge cases, and its failure modes. They understand why a variable is cast a certain way or why a database query is structured to avoid locking tables.
When the code is generated by an AI, the developer skips this mental modeling phase. They become an editor rather than an author. Over time, as the codebase grows through rapid AI generation, the team's collective understanding of the system dilutes. They end up maintaining a system that no one fully understands. This "black box" effect makes remediation significantly harder when vulnerabilities are inevitably discovered. As outlined in reports on the hidden costs of AI, maintaining code that one did not write—and does not fully understand—is exponentially more expensive than maintaining human-authored code.
The initial speed of generation is paid for by a long tail of confusion and technical debt. If you care about long-term maintainability and predictable delivery, it is worth pairing this perspective with a broader look at Agile software development best practices, which are designed to preserve this "deep knowing" across the full lifecycle.
Part II: The 170 Vulnerabilities – A Forensic Case Study of the "Lovable" Incident
To understand the tangible, real-world risks of Vibe Coding, we must move beyond theory and examine a specific, documented failure. The "Lovable" incident of May 2025 serves as the canary in the coal mine for the entire industry of AI-generated applications.
2.1 The Promise vs. The Breach
Lovable, a Swedish startup, marketed itself as the "fastest-growing company in Europe," a poster child for the Vibe Coding revolution. Its platform allowed users with little to no technical training to create fully functional web applications using only natural language prompts. It promised to be "the last piece of software" anyone would ever need.
However, a security analysis conducted by Matt Palmer, an employee at competitor Replit, revealed a catastrophic systematic failure in the apps generated by Lovable's AI. Out of 1,645 Lovable-created web applications that were scanned, 170 (approximately 10.3%) contained severe, critical security vulnerabilities.
2.2 Anatomy of the Failure: Row-Level Security (RLS)
The primary vector of this vulnerability was a misconfiguration in Row-Level Security (RLS). To understand the gravity of this, we must briefly explain what RLS is.
In modern multi-tenant SaaS applications (where multiple companies use the same app), data is often stored in a single database table. RLS is a database security feature—commonly used in Postgres—that restricts which data rows a specific user can see. For example, User A from Company X should only see Company X's data. User B from Company Y should only see Company Y's data. This filtering happens at the database level, serving as the final, hard line of defense.
In the Lovable case, the AI generated the database schemas and the front-end user interfaces perfectly. It built the "visible" parts of the app. However, it failed to generate or correctly configure the "invisible" RLS policies that govern data access. The AI understood that the app needed a database; it did not understand the business logic of privacy.
The consequences were severe:
- Unauthenticated Data Access: The misconfiguration allowed unauthenticated visitors (anyone on the internet) to query sensitive tables directly using public API keys.
- Total Data Exposure: The breach exposed personally identifiable information (PII) including emails, phone numbers, payment details, and names.
- Credential Leakage: In some instances, secret API keys for third-party AI services were exposed, allowing attackers to hijack the billing accounts of Lovable's customers.
- Read/Write Access: In the worst-case scenarios, the lack of RLS allowed attackers not just to read data, but to write to the databases, potentially corrupting data or injecting malicious payloads.
2.3 The Failure of Automated Remediation
Perhaps the most damning aspect of the Lovable incident was the company's initial response. After being notified of the vulnerability, Lovable introduced a "security scanner" to check user apps. However, this scanner was found to be insufficient. It merely checked for the existence of an RLS policy, not its correctness or alignment with the application's specific logic.
This highlights a critical limitation of current AI and automated tools: they excel at syntax (does a policy exist?) but struggle with semantics (does this policy actually protect User B from User A?). The AI scanner saw that a lock was on the door and marked the house as "secure," failing to notice that the key was taped to the outside of the doorframe.
This incident demonstrates that while AI can build the visible facade of an application with startling speed, it often neglects the invisible scaffolding of security architecture—access controls, rate limiting, and input sanitization—that human engineers learn to prioritize through years of painful experience and rigorous training. If you are investing heavily in SaaS and custom platforms, this is exactly where a seasoned software product development partner can help keep your architecture secure while you scale.
Part III: The 48% Reality – Statistical Analysis of AI Code Risks
The Lovable incident was not an anomaly; it was a statistical inevitability. Multiple peer-reviewed studies and industry reports have quantified the insecurity of AI-generated code, providing a clear warning to CTOs who believe they can "vibe code" their way to enterprise security.
3.1 The CSET and Pearce et al. Benchmark
A landmark study by researchers at NYU, cited extensively by the Center for Security and Emerging Technology (CSET), evaluated code generated by five different commercial LLMs (including the models powering tools like GitHub Copilot). The researchers subjected these models to a series of prompts designed to test their security awareness.
The findings were sobering. On average, 48% of the code snippets generated by these models contained at least one security vulnerability classified in the MITRE CWE Top 25 Most Dangerous Software Weaknesses.
This is a staggering failure rate. Imagine a manufacturing assembly line where 48% of the parts produced were defective. In any other industry, this would be grounds for an immediate recall. In the software industry, under the guise of "Vibe Coding," it is being hailed as progress.
3.2 Breakdown of Vulnerabilities
The CSET/Pearce study and subsequent reports from security firms like Quokka have identified specific categories where AI consistently fails. The table below summarizes these findings, transcoding the data from the rejected visual analysis to provide a clear view of the risk landscape.
| Vulnerability Category | Associated CWE | Prevalence in AI Code | Description & Impact |
|---|---|---|---|
| SQL Injection | CWE-89 | High | AI often concatenates user input directly into SQL query strings rather than using parameterized queries. This allows attackers to manipulate the database, stealing or destroying data. |
| Hardcoded Credentials | CWE-798 | High | Models frequently insert hardcoded API keys, passwords, or tokens directly into the source code, often mimicking bad practices found in training data. |
| Improper Input Validation | CWE-20 | Moderate | AI code often assumes "happy path" inputs, failing to validate or sanitize user data, leading to buffer overflows or logic errors. |
| Path Traversal | CWE-22 | Moderate | Code that allows users to access files on the server often lacks safeguards preventing access to sensitive system directories. |
| General Bugs/Logic Errors | N/A | ~48% | Beyond security, nearly half of generated samples contained bugs that caused compilation errors, infinite loops, or timeouts. |
3.3 The Root Causes of Insecurity
Why does a system as advanced as an LLM struggle with basic security concepts? The answer lies in the nature of its training and operation.
- Training Data Poisoning: AI models are trained on the public internet, specifically on open-source repositories like GitHub. While these repositories contain brilliant code, they also contain millions of lines of insecure code—homework assignments, quick hacks, abandoned projects, and "vibe coded" prototypes. If the training set contains thousands of examples of developers hardcoding API keys for convenience, the AI learns that hardcoding keys is the "standard" or "most probable" way to write code. It is merely reproducing the collective bad habits of the developer community.
- Context Blindness: An AI snippet generator operates in a vacuum. It sees a request for a "Python login function." It does not see the broader enterprise context—the firewall rules, the Identity and Access Management (IAM) policies, or the compliance requirements (SOC2, HIPAA). It generates the simplest solution that satisfies the immediate prompt. In security, the simplest solution is almost always the least secure. Secure code is often complex, requiring layers of abstraction and checking that the AI views as "inefficient" or low-probability.
- The "Correctness" Fallacy: Benchmarks for AI models typically measure "functional correctness" (does the code run and produce the desired output?) rather than "secure correctness" (is the code safe under attack?). This incentivizes model providers to tune their systems for functionality over security. A model that refuses to generate code because it might be insecure is seen as "lazy" or "broken" by users who just want the vibe of a working app.
Part IV: Slopsquatting – The Supply Chain Attack of the Future
If bad syntax and logic errors were the only risks, they might be manageable through traditional code review. However, the rise of Generative AI has birthed entirely new vectors of attack that exploit the very mechanism of how LLMs "think." The most insidious of these is "Package Hallucination," which has given rise to a supply chain attack technique known as "Slopsquatting."
4.1 The Mechanism of Hallucination
Large Language Models hallucinate information when they do not know the answer but are compelled by their probabilistic nature to satisfy a pattern. In the context of coding, this manifests as the invention of software libraries and packages that sound real but do not actually exist.
For example, a developer might ask an AI for a library to handle "fast, secure JSON parsing in Python." The AI, having seen thousands of package names involving "fast," "json," and "secure," might confidently suggest:
"You should use the
fastjson-securelibrary. It is highly optimized."
In reality, fastjson-secure does not exist. It is a phantom, a statistical ghost generated by the model's prediction weights.
4.2 The Weaponization: How Slopsquatting Works
Attackers have learned to weaponize this tendency. They treat LLMs not as coding assistants, but as oracles for potential victims. The attack lifecycle is as follows:
- Discovery: The attacker queries various LLMs with common coding prompts (e.g., "How do I connect to an Azure SQL database with encryption?").
- Identification: They identify package names that the AI consistently hallucinates. Research by Lasso Security found that nearly 20% of packages recommended by some models were non-existent.
- Registration: The attacker goes to public package repositories like PyPI (for Python) or npm (for JavaScript) and registers these hallucinated names. They publish a package named
fastjson-secure. - The Trap: Inside this package, they place a malicious payload—code that steals environment variables, opens a reverse shell, or exfiltrates AWS keys.
- The Execution: A "vibe coder," trusting the AI's suggestion, runs the command
pip install fastjson-secure.
This attack is particularly devastating because it bypasses traditional firewall defenses. The malware is not "breaking in"; it is being invited in. The developer is voluntarily downloading and installing the malicious code from a trusted source (the official package repository), believing they are following best practices suggested by their AI assistant.

4.3 The Scale of the Threat
This is not a theoretical risk. It is an active exploit.
- Persistent Hallucinations: Research indicates that when an AI hallucinates a package once, it is likely to hallucinate it repeatedly for other users, creating a reliable stream of victims for the attacker who registers that name.
- Typosquatting vs. Slopsquatting: Traditional "typosquatting" relied on users mistyping a name (e.g.,
requsetsinstead ofrequests). Slopsquatting is far more dangerous because the user types the name correctly—it's just that the name itself was a fiction invented by the AI. - Specific Vulnerability Rates: In Python and JavaScript ecosystems, the rate of package hallucination can be as high as 30% for certain types of coding tasks. This represents a massive, ungated attack surface for enterprise development teams.
Part V: The Hidden Costs – Technical Debt and the Remediation Curve
The primary argument for Vibe Coding is speed. "Ship faster," "iterate instantly," "reduce time-to-market." However, this speed is often an illusion—a loan taken out against the future stability of the software. The interest rate on this loan is exorbitant, and it is paid in the currency of Technical Debt and Remediation Costs.
5.1 The Maintenance Multiplier
Code generated by AI is frequently verbose, duplicative, and lacks the structural elegance of human-architected systems. AI models treat each prompt as an isolated task. If you ask for a "user login" five times in five different parts of your application, the AI will likely generate five different, slightly varying implementations. A human engineer would create one shared authentication service.
- Code Bloat: This redundancy leads to "code bloat," making the application larger, slower, and harder to navigate.
- The Understanding Gap: When developers "forget the code exists," they lose the mental model of how the system works. When a bug inevitably arises (and it will), the cost to fix it skyrockets because no one on the team understands the underlying logic. They are effectively reverse-engineering their own product.
- The Cost of Churn: Studies show that code "churn"—the amount of code that has to be rewritten or deleted shortly after being written—has doubled between 2021 and 2024, a period coinciding with the rise of AI coding tools. This suggests that much of the "speed" gained by AI is wasted on rewriting bad code.
When you factor in this churn, it becomes clear why mature organizations are starting to combine AI with stronger engineering discipline, including serious investment in modern QA practices that drive real profitability, not just surface-level velocity.
5.2 The 100x Cost of Late Detection
The "Shift Left" philosophy in security is based on a brutal economic reality: fixing a bug in production is vastly more expensive than fixing it in the design phase.
- Requirements/Design Phase Cost: ~$100 to fix.
- Testing Phase Cost: ~$1,500 to fix.
- Production Phase Cost: ~$10,000+ to fix.
When Vibe Coding pushes unreviewed, "black box" code directly to production, it bypasses the cheap remediation phases (Design/Testing) and lands directly in the expensive zone (Production). The "One-Pizza Team" might launch the app in record time, but they will drown in the maintenance costs, potentially erasing any ROI generated by the rapid launch.
For the CTO, this presents a clear danger: the "hidden cost" of AI dependency is that you are building a legacy system from Day One. You are creating a codebase that is expensive to maintain, difficult to secure, and understood by no one. That’s why forward-looking executives now treat software as a long-term investment, using disciplined software risk management strategies rather than chasing short-lived speed bumps.
Part VI: The Solution – "Agentic Engineering" and Baytech's Approach
We do not advocate for a return to manual coding for every line. That would be ignoring the undeniable productivity gains of AI. Instead, we advocate for Agentic Engineering. This is the mature evolution of AI development—moving from "giving in to the vibes" to "orchestrating the agents."
6.1 Defining Agentic Engineering
Agentic Engineering transforms the role of the developer from a "writer" of code to an "architect" of systems. It involves building workflows around the collaboration with AI, rather than surrendering control to it.
- Structure over Speed: It uses "Instruction Directories" to give AI agents persistent context about the project's architecture, security standards, and business rules. The AI is not guessing; it is following a blueprint.
- Role Specialization: It breaks the development process into discrete agentic roles—Ideation, Architecture, Validation, and Implementation—supervised by a human "Intelligence Engineer".
- Verification: The core tenet of Agentic Engineering is "Trust but Verify." It assumes the AI is wrong until proven right. Every output is subjected to rigorous validation pipelines.
6.2 The Baytech Difference: Tailored Tech Advantage
At Baytech Consulting, we employ a rigorous "Agentic Engineering" methodology that serves as a firewall against the risks of Vibe Coding. Our process ensures that the speed of AI is harnessed without compromising the "safe pair of hands" our clients rely on. Our "Tailored Tech Advantage" and "Rapid Agile Deployment" are built on a foundation of verified security.
We do not use generic prompts. We feed our AI agents strictly scoped contexts regarding our specific tech stack—Azure DevOps, Kubernetes (via Rancher/Harvester), and Postgres—and our enterprise security policies. This means our AI agents are not hallucinating generic solutions; they are generating code that is pre-aligned with our secure infrastructure. If you are exploring how to safely modernize your stack, our deep dive on Headless CMS and future-proof architectures shows how we apply the same thinking to content platforms and omnichannel systems.
Part VII: Building the Defense – Architecture & Policy
For the Visionary CTO, protecting against AI risks requires a defense-in-depth strategy. It is no longer enough to train developers; you must enforce rules in the infrastructure itself. The infrastructure must be smart enough to reject insecure code, even if a human approves it.
7.1 Policy as Code (OPA and Gatekeeper)
You cannot rely on human reviewers to catch every AI error, especially when automation bias is at play. You must implement Policy as Code.
- Open Policy Agent (OPA): OPA is a general-purpose policy engine that allows you to decouple policy decision-making from enforcement. It allows you to write security rules as code (Rego) that can be versioned and audited.
- Gatekeeper: In a Kubernetes environment—like Baytech's Harvester HCI and Rancher managed clusters—Gatekeeper acts as an admission controller. It intercepts every request to create a resource in the cluster.
How it works in practice: Imagine a "vibe coder" generates a Kubernetes deployment file that attempts to run a container with root privileges (a major security risk) or without memory limits (a stability risk).
- The developer submits the code.
- The CI/CD pipeline attempts to deploy it to the Rancher cluster.
- Gatekeeper intercepts the request. It checks the YAML against the OPA policies.
- It sees the violation (
runAsRoot: true). - Gatekeeper denies the request before it ever hits the cluster.
This makes the infrastructure "self-defending." Even if the AI generates insecure code, and even if the human reviewer misses it, the cluster itself refuses to accept the vulnerability. For organizations building out Kubernetes-heavy platforms, aligning this kind of policy-as-code with proven .NET, Docker, and Kubernetes engineering is key to keeping velocity high without opening new attack surfaces.
7.2 Security Scanning in the Pipeline: Azure DevOps Advanced Security
We leverage Azure DevOps Advanced Security to automate the detection of vulnerabilities deep within the development pipeline.
- Secret Scanning: This tool scans every commit for patterns that look like API keys, passwords, or tokens. If an AI has accidentally inserted a hardcoded key (CWE-798), the push is blocked immediately.
- Dependency Scanning: This checks files like
package.jsonorrequirements.txtagainst global databases of known vulnerabilities. It helps detect if an AI has suggested a library with a known CVE. - CodeQL: This is the "heavy artillery" of static analysis. Unlike simple linters that check for style, CodeQL performs semantic code analysis. It treats code as data, allowing it to query the logical flow of the program. It can find deep, complex flaws like SQL injection (CWE-89) where user input flows into a database query without sanitization—the exact kind of flaw that regex-based scanners often miss.
7.3 Container Security: Microsoft Defender
In modern microservices architectures, the container is the attack surface. Baytech utilizes Microsoft Defender for Containers to provide runtime threat protection.
While OPA and CodeQL catch issues before deployment, Defender watches the application while it is running.
- It monitors active processes within the container.
- If an attacker exploits a vulnerability in AI-generated code (e.g., using a hallucinated package to open a reverse shell), Defender detects the anomalous process behavior (e.g., "Why is this web server launching a shell?") and alerts the Security Operations Center (SOC) instantly.
Bringing all of this together—from CI/CD to runtime security—is a core part of modern DevSecOps. Our clients often combine this with a broader push toward DevOps efficiency, unifying deployment speed and security rather than trading one for the other.
Part VIII: The Human-in-the-Loop (HITL) Checklist
Technology alone is insufficient. We must maintain the "Human in the Loop" (HITL). However, in an Agentic Engineering workflow, the human's role changes from "writing" to "reviewing." This is mentally taxing; reviewing code is often harder than writing it, and automation bias makes it easy to glaze over.
8.1 The AI Code Review Protocol
To combat this, Baytech advocates for a specific AI Code Review Checklist that forces active engagement. We do not just "look" at the code; we interrogate it.
| Review Category | Checklist Item | Why It Matters |
|---|---|---|
| Dependency Verification | "Do all imported packages exist in the official registry?" | Prevents Slopsquatting/Hallucinations. Reviewers must manually verify links to PyPI/npm. |
| Secret Sanitization | "Are there any hardcoded strings that look like keys?" | Prevents credential leakage (CWE-798). AI often uses "placeholder" keys that turn out to be real. |
| Logic & Boundaries | "Does the code handle edge cases (nulls, negative numbers)?" | AI optimizes for the "happy path." It rarely writes robust error handling for edge cases. |
| Data Access (RLS) | "Does this query respect user isolation policies?" | Prevents Lovable-style data breaches. Reviewers must check who is allowed to see the data. |
| Output Encoding | "Is user input sanitized before rendering?" | Prevents XSS (Cross-Site Scripting). AI often trusts user input implicitly. |
Formalizing this human-in-the-loop work also improves developer experience. Teams that build clear guardrails around AI typically see higher satisfaction and lower burnout, similar to the trends we discuss in our piece on developer happiness and productivity.
Part IX: Strategic Recommendations & Conclusion
9.1 The CTO's Action Plan
For the Visionary CTO, the path forward is not to ban AI, but to govern it. We recommend the following immediate actions:
- Ban "Naked" Vibe Coding: Establish a strict corporate policy that no AI-generated code is permitted to be committed to the codebase without passing through a verified "Agentic" pipeline. The "vibe" is not a validation strategy.
- Audit Your Dependencies: Immediately scan your existing codebases for "ghost" dependencies. Implement a private artifact registry (e.g., Azure Artifacts) and block direct pulls from public PyPI/npm. This creates a "walled garden" that prevents Slopsquatting.
- Enforce Policy as Code: If you are using Kubernetes, you must implement OPA or Gatekeeper. Make security a build-time constraint that cannot be bypassed by a tired developer.
- Partner for Safety: Recognize that AI security is a specialized, rapidly evolving discipline. Partners like Baytech Consulting allow you to leverage the speed of AI without inheriting the risk profile of a "vibe coded" startup. We provide the architectural maturity that "one-pizza teams" often lack.
These steps also align with broader shifts in how enterprises choose technology partners. When you are evaluating vendors or new platforms, you should weigh their AI and security posture just as seriously as their feature list—an approach we outline in detail in our guide on choosing a software partner in 2026.
9.2 Conclusion
The metric that matters most in 2026 is not "lines of code per day." It is "vulnerabilities per release." The 170 Lovable apps and the 48% insecurity rate of LLMs are not just statistics; they are warnings from the future.
Vibe Coding is a powerful drug—it feels like speed, but it often results in a hangover of technical debt, security exposure, and reputational ruin. Agentic Engineering is the cure. It restores the discipline of architecture to the magic of generation. By combining rigorous automated defenses (Azure DevOps, OPA, Defender) with expert human oversight, we can build software that is not just fast, but Lovable and Secure.
Baytech Consulting stands ready to be that safe pair of hands, ensuring your innovation trajectory is never grounded by a preventable breach. If you are rethinking how AI, DevOps, and security fit together in your roadmap, it is worth exploring how modern Azure and GitHub DevOps strategies can support an Agentic Engineering approach at scale.
Frequently Asked Questions (FAQ)
Q: Are AI-generated apps inherently insecure?
A: Not inherently, but statistically, yes—if left unchecked. As this report details, 48% of raw AI code snippets contain vulnerabilities, and 10.3% of apps on the Lovable platform had critical RLS failures. The insecurity comes from the lack of context and architectural oversight, not the AI itself. When wrapped in a proper "Agentic Engineering" workflow with rigorous testing, AI code can be made secure.
Q: How does Baytech Consulting protect against "hallucinated" packages?
A: We employ a defense-in-depth strategy. First, we use private artifact feeds in Azure DevOps, meaning we only allow vetted, approved packages into our ecosystem. Second, our automated dependency scanners (part of GitHub/Azure Advanced Security) verify the legitimacy and security rating of every library before it can be built into the application. Finally, our senior engineers perform manual code reviews to spot the "slopsquatting" patterns that automated tools might miss.
Q: Can't we just use a security scanner to catch AI mistakes?
A: Scanners are essential but insufficient. As seen in the Lovable case, scanners often check for the presence of security policies (syntax) but cannot verify their logic (semantics). A scanner might see that you have a lock on the door, but it won't notice that the key is taped to the outside. This is why Baytech emphasizes "Agentic Engineering"—using human expertise to validate the architectural logic that scanners miss.
Q: What is the difference between "Vibe Coding" and "Agentic Engineering"?
A: "Vibe Coding" is a high-speed, low-control approach where the developer focuses on the "vibe" or intent and delegates the implementation entirely to AI, often ignoring the underlying code. "Agentic Engineering" is a structured, systems-thinking approach where AI agents are treated as junior team members. They operate within strict architectural guardrails, with persistent context and rigorous human oversight. Vibe Coding generates technical debt; Agentic Engineering manages it.
Supporting Articles
- https://www.semafor.com/article/05/29/2025/the-hottest-new-vibe-coding-startup-lovable-is-a-sitting-duck-for-hackers
- https://cset.georgetown.edu/wp-content/uploads/CSET-Cybersecurity-Risks-of-AI-Generated-Code.pdf
- https://www.usenix.org/publications/loginonline/we-have-package-you-comprehensive-analysis-package-hallucinations-code
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.