
When Your SIS and LMS Don't Speak: The Sidecar Solution
May 29, 2026 / Bryan Reynolds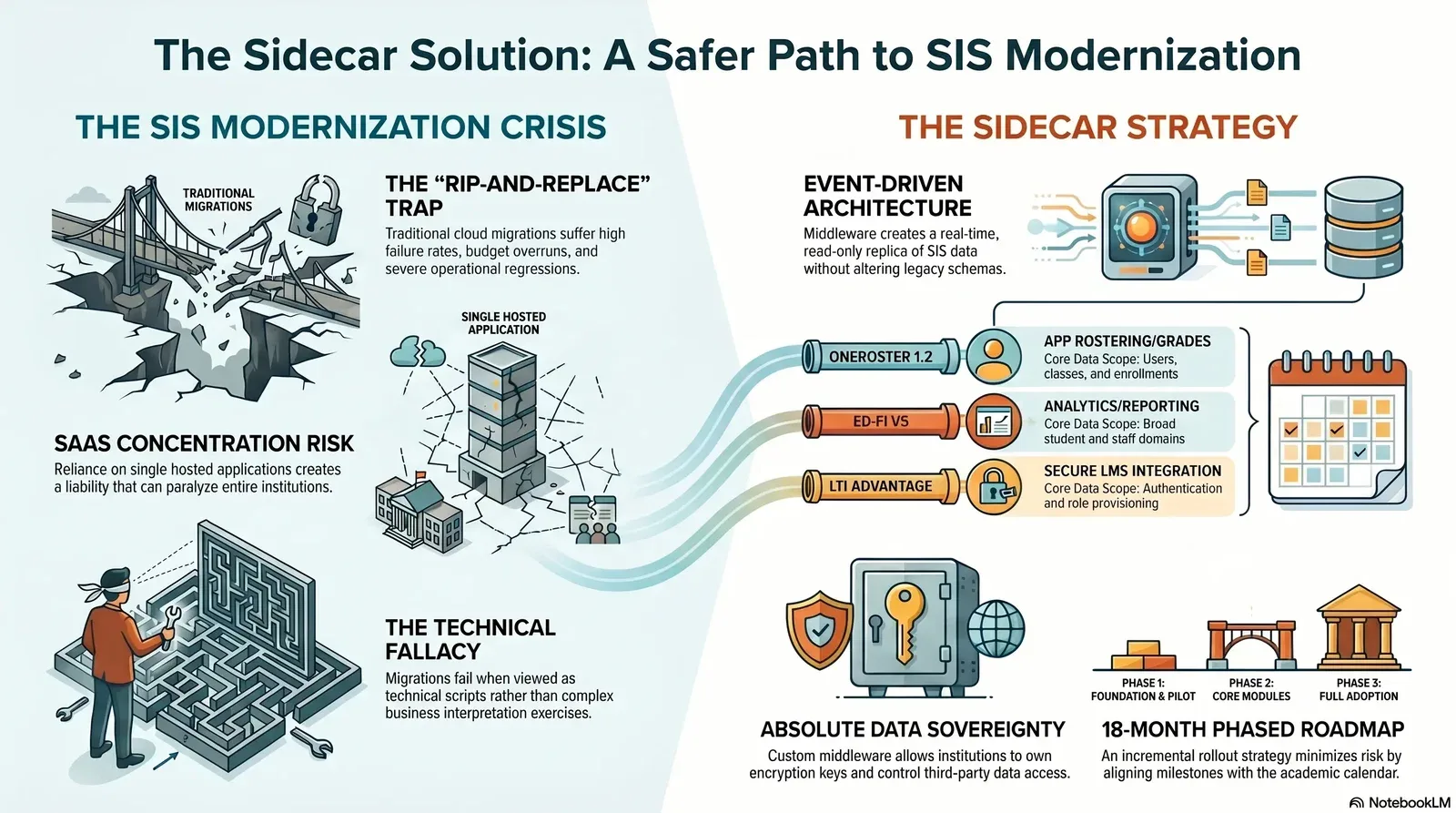
EdTech and the SIS Modernization Problem: When Your Student System Can't Talk to Your LMS
The foundational technology infrastructure at the heart of most higher education institutions and K-12 districts operates on a fractured timeline. The typical Student Information System (SIS) acting as the ultimate system of record was purchased and implemented in 2009. The Learning Management System (LMS) operating alongside it was likely acquired during a secondary procurement cycle around 2017. The enterprise data warehouse powering institutional analytics was built in 2022, and the provost almost certainly just approved an experimental generative artificial intelligence tutoring system that went live last semester.
None of these disparate platforms share a single, unified source of truth regarding the digital identity of a student. The SIS modernization crisis stems from the fact that each of these systems maintains its own isolated definition of enrollment, demographic context, and academic progress. In this fragmented ecosystem, the institutional registrar remains the sole arbiter of data integrity, navigating a labyrinth of undocumented manual processes and fragile point-to-point application programming interfaces (APIs) just to maintain baseline operational continuity.
Modernizing this aging infrastructure traditionally presents chief technology officers (CTOs) and chief financial officers (CFOs) with two equally unappealing options. The first is a high-risk, "rip-and-replace" cloud SIS migration—an endeavor fraught with implementation failures, budget overruns, and severe operational regressions. The second is a superficial integration strategy that quickly collapses under the weight of strict data retention requirements, complex role-based access controls for parents and advisors, and stringent privacy mandates like the Family Educational Rights and Privacy Act (FERPA).
The calculus for institutional technology leadership shifted dramatically in May 2026. A widespread ransomware attack executed by the ShinyHunters threat group forced Instructure to take the Canvas LMS completely offline, disrupting digital learning and administrative access at forty-one percent of North American higher education institutions. This critical incident exposed the systemic vulnerability of centralized Software-as-a-Service (SaaS) dependency. Institutions realized that relying on a single, externally hosted application for core academic operations without decoupled, locally controlled data replication is an architectural liability that can paralyze an entire university system overnight. Leaders now have to think the same way mid-market enterprises are thinking about securing SaaS dependencies against ransomware-scale outages, not just about routine uptime.
This comprehensive analysis proposes an alternative path. By utilizing an incremental, sidecar-led modernization strategy adapted from regulated enterprise sectors—the same approach Baytech Consulting advocates for complex healthcare and finance legacy environments—institutions can modernize their technology stacks without risking the operational stability that thousands of students depend upon. Through the implementation of read-only middleware, the adoption of strict data interoperability standards like OneRoster and Ed-Fi, and a phased rollout structured strictly around the academic calendar, educational institutions can solve the SIS modernization problem without executing a perilous rip-and-replace migration.
Why the SIS is the Third Rail of EdTech Modernization
The Student Information System functions as the central nervous system of an educational institution. It is exclusively responsible for processing course enrollment, managing complex financial aid distributions, storing protected demographic data, tracking degree audits, and finalizing academic transcripts. Because the SIS touches every functional department across a campus—from admissions and advising to athletics and alumni relations—altering its structure inherently impacts the entire institutional ecosystem. It is the hardest enterprise system to modernize in education because its processes dictate the legal and financial compliance of the institution.
When institutions attempt to modernize by executing complete system migrations from legacy, on-premises platforms like Ellucian Banner, Oracle Campus Solutions, or legacy PeopleSoft instances to modern cloud enterprise resource planning (ERP) systems like Workday Student, the failure rates are exceptionally high. These multi-year initiatives routinely arrive at their launch dates entirely exhausted, massively over budget, and carrying critical unresolved errors directly into production environments. Workday implementations in higher education typically stumble not because of inherent software defects within the platform, but due to profound organizational and strategic miscalculations regarding the complexity of higher education operations. These are the same kinds of miscalculations that derail large IT modernization in other sectors, which is why many institutions look to enterprise software development partners that specialize in de-risking modernization.
The primary failure mode in these high-stakes migrations is the technical fallacy. Project management teams frequently approach data conversion as a purely technical script execution, viewing it simply as the automated movement of data from a legacy database into a new cloud architecture. In practice, data conversion is a massive business interpretation and mapping exercise. Legacy student systems house decades of accumulated inconsistencies, unmaintained records, duplicate entries, and non-standard coding structures designed to bypass historic software limitations. Information technology departments cannot unilaterally cleanse this data in a vacuum; they require functional staff from financial aid and the registrar's office to dictate how legacy data translates to new workflows. When institutions fail to prioritize data stewardship at the departmental level, they launch new cloud systems crippled by dirty legacy data.
Furthermore, these migrations suffer from immense change management gaps. Universities operate with distinct levels of departmental autonomy and shared governance, requiring significantly more time to build consensus around standardized processes than typical corporate environments. Consequently, institutions that force a cloud migration without adapting their operational culture experience disastrous post-launch regressions.
Administrators transitioning to major cloud SIS platforms have reported severe functionality losses that paralyze academic administration. Documented failures include cloud systems forcing students to apply for graduation on arbitrary calendar dates rather than designated academic terms, the total inability of registrars to issue registration overrides for time conflicts or repeat limits, broken degree audit modules, and workflows that require a canceled course to be made visible to students before the cancellation can be processed.

The rip-and-replace approach requires absolute technical perfection during a dangerously narrow deployment window, usually relegated to a few weeks in the summer between academic terms. If the data conversion fails during this specific window, the institution cannot process federal financial aid or enroll incoming students, creating an existential fiscal crisis. Treating the SIS migration as an institutional transformation rather than an IT project is the only way to mitigate this risk, but the sheer gravity of the endeavor often leaves CTOs searching for less invasive modernization pathways.
The Integration Problem and the Canvas Ransomware Lesson
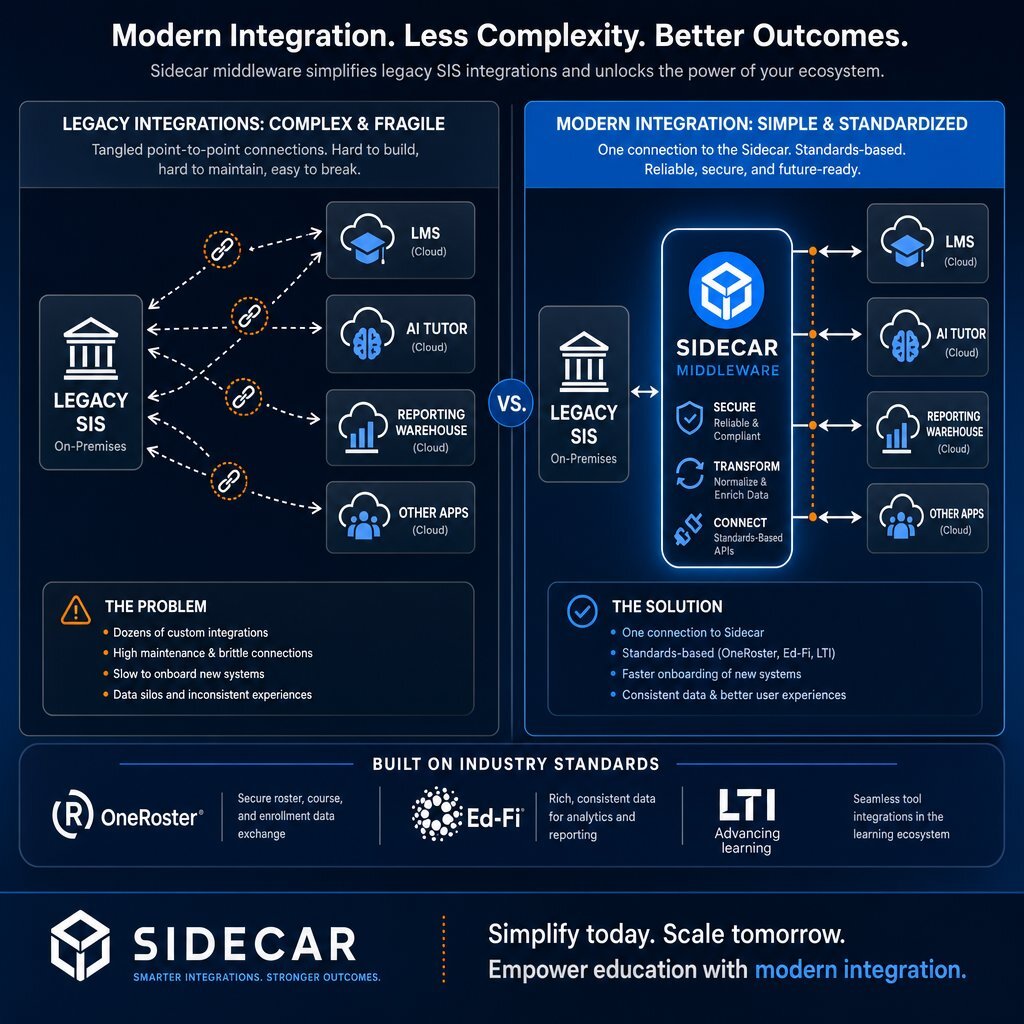
The modern educational technology stack is no longer a monolithic entity; it has evolved into a highly fragmented web of specialized applications. A typical university relies on the legacy SIS for official records, the LMS for daily instructional delivery and grading, a data warehouse for institutional reporting, independent financial aid portals for Title IV compliance, and increasingly, AI-driven applications for personalized tutoring and predictive retention analytics. Each of these independent systems maintains its own isolated database table defining the student entity, leading to severe architectural data drift.
The integration crisis is compounded by the necessity of triangulating data between these disparate nodes at high velocity. When a student interacts with an AI tutor embedded within the LMS, the resulting performance data must eventually inform the early-warning retention systems housed in the data warehouse, while the final summative grade must be passed back accurately to the SIS to finalize the transcript. Traditional point-to-point API connections between these platforms create a fragile, tightly coupled architecture. If the SIS undergoes a scheduled maintenance window, the direct API connections fail, and the AI tutor loses access to the demographic context required to function.
The catastrophic events of May 2026 served as a stark demonstration of why this tight application coupling is fundamentally dangerous for educational institutions. Beginning on April 25, 2026, the ShinyHunters threat group breached Instructure's defenses, navigating through the Canvas infrastructure and ultimately defacing institutional login pages nationwide with ransom demands. In response to the breach and subsequent unauthorized activity, Instructure was forced to take the Canvas platform completely offline on May 7, triggering a nationwide system shutdown that blocked university access entirely.
The fallout was immense. Unconfirmed reports suggested a ten million dollar ransom was ultimately paid to the threat actors, and by May 13, a class-action lawsuit was filed against Instructure in the United States District Court for the Southern District of California regarding the release of personally identifiable information. Even after Instructure claimed the system was safe to use, institutions reported ongoing, cascading access issues, including the inability to render unsupported files or add enrollments to their course catalogs. On May 8, more than nine hundred EDUCAUSE community members convened in an emergency webinar to discuss the campus impacts, raising profound operational questions about third-party risk, data security, and institutional preparedness.
This incident highlighted a critical architectural flaw in higher education IT architecture: the concentration of SaaS dependency. When educational institutions wire all third-party integrations, grading workflows, and AI tutoring data directly into a single hosted LMS, an outage at the LMS provider severs the institution's access to its own instructional data. If the SIS relies on the LMS to push final grades, and the LMS is held ransom, the institution cannot graduate its students. Institutions desperately require an integration layer that isolates external application failures from internal core systems, ensuring that a disruption in a vendor's environment does not result in total institutional paralysis. SaaS concentration is no longer merely an IT infrastructure issue; it is a procurement-level conversation that demands a decentralized architectural response. This mirrors the broader shift in software markets away from brittle, centralized SaaS dependencies toward architectures that protect margins and sovereignty.
The Sidecar Modernization Pattern Applied to Education
To mitigate the existential risks of both rip-and-replace SIS migrations and centralized SaaS dependencies, enterprise IT architects utilize the sidecar modernization pattern, specifically through the creation of an Event-Driven Architecture (EDA). This technical methodology, frequently deployed to modernize legacy mainframes in the healthcare and financial sectors, is highly applicable to the rigid operational constraints of educational technology.
The sidecar pattern involves deploying a read-only middleware layer—often referred to as an Event-Driven Book of Reference—that sits adjacent to the legacy SIS. Rather than attempting to rewrite the ancient, fragile codebase of the legacy student system or subjecting it to millions of daily API calls from external vendors, the custom middleware ingests data events from the system of record and translates them into a modernized, industry-aligned data model for downstream consumption.
Architectural Mechanics and Event-Driven Synchronization
In practice, this architecture utilizes a Change Data Capture (CDC) mechanism or database replication tool to continuously monitor the legacy SIS database for any state changes. When a business event occurs—such as a student registering for a new class, a change in financial aid status, or a grade update—the CDC tool captures this event in real time. These events are streamed into a raw landing zone and subsequently processed into a curated operational data store (ODS) using an append-only, persistent, and immutable log.
This infrastructure creates a warm, read-only replica of the SIS data. The middleware acts as a Strangler Facade, fundamentally decoupling read operations from write operations. When the new AI tutoring system, the LMS, or the enterprise data warehouse needs to query student demographics or validate roster information, they query the modern sidecar database rather than pinging the legacy SIS directly.
This approach yields three profound architectural advantages for educational institutions:
First, it requires zero legacy schema modifications. The legacy SIS remains entirely untouched. The institution does not have to alter the fragile, decades-old database schemas that currently process complex Title IV financial aid distributions and mandatory accreditation reporting.
Second, the sidecar provides infinite scalability and system decoupling. Microservices and modern edtech applications can scale independently and query the sidecar data at extremely high frequencies without degrading the performance of the core SIS. If a sudden spike in traffic occurs during finals week as thousands of students access an AI tool, the compute-intensive workload hits the modern middleware, leaving the legacy SIS completely unaffected.
Third, the architecture ensures absolute vendor agnosticism. Because all external applications connect to the middleware rather than forming direct point-to-point connections with the SIS or the LMS, the institution can swap out a failing vendor without rebuilding dozens of custom integrations. If the LMS suffers a ransomware attack, the middleware retains the most recent state of all student data, allowing the institution to route emergency communications or spin up alternative instructional delivery methods using the preserved sidecar data.
While this architecture introduces eventual consistency—meaning there may be a sub-second delay between an update in the SIS and its reflection in the sidecar—this delay is entirely acceptable for the vast majority of customer-facing educational use cases, such as online learning and analytics. By implementing custom middleware built on robust, enterprise-grade infrastructure—such as PostgreSQL databases orchestrated via Kubernetes, Docker containers, and Rancher on OVHcloud servers—institutions achieve a Tailored Tech Advantage. This ensures that the institution retains absolute sovereignty over its data routing, providing a decoupled safety net that prevents total system failure during vendor outages. It also aligns with how regulated enterprises are already thinking about balancing edge and on-prem AI infrastructure to keep critical systems resilient.
The Interoperability Standards That Actually Matter
Middleware is only effective if it speaks a standardized language that external vendors natively understand. The educational technology sector is governed by a specific set of data standards that dictate how roster information, academic grades, and behavioral analytics are structured and exchanged. Building the sidecar middleware to conform strictly to these standards is the only viable way to ensure future interoperability, eliminate custom API development, and prevent vendor lock-in. The three interoperability standards that define the modern edtech ecosystem are OneRoster, the Ed-Fi Data Standard, and LTI Advantage.
OneRoster versus Ed-Fi: Operational Provisioning versus Analytical Modeling
Institutions frequently confuse the specific use cases for OneRoster and Ed-Fi, assuming they are competing standards fighting for the same architectural territory. In reality, they serve complementary but entirely distinct functions within a district or university's data ecosystem, and a properly modernized sidecar will utilize both.
OneRoster, maintained by the 1EdTech consortium, is a highly focused operational standard optimized specifically for provisioning digital applications and executing grade passback. Its core strength lies in enabling fast onboarding for instructional applications so that class lists stay perfectly aligned and manual grade entry is minimized. OneRoster focuses on a narrow scope of operational classroom entities: users, classes, enrollments, and grades. It functions as the immediate provisioning path that instructional vendors rely upon to ensure that a student dropping a class in the SIS is immediately removed from the corresponding AI application.
The latest iteration, OneRoster 1.2, published in September 2022, supports twenty-two specific CSV files and eighty-one REST API endpoints. Crucially, OneRoster 1.2 supports both bulk data exchanges and delta syncs. Delta feeds transmit only the specific data records that have changed since the previous update, drastically reducing processing overhead compared to nightly full-file dumps.
Conversely, the Ed-Fi Data Standard acts as the comprehensive analytical and reporting backbone for an institution. While OneRoster manages day-to-day application rostering, Ed-Fi is designed to integrate broad domain data from the SIS, human resources platforms, behavioral tracking tools, and state assessment systems into a unified Operational Data Store (ODS). Ed-Fi provides a highly structured relational data model designed for complex reporting, long-term analytics, and Multi-Tiered System of Supports (MTSS) early-warning dashboards.
An Ed-Fi API integration requires strict adherence to resource dependency orders. For example, a source system must transmit data establishing Local Education Agencies (LEAs) before it can transmit data regarding Schools, and both must exist before transmitting student data. The Ed-Fi Student Information Systems API for Data Standard v5 validates that an SIS provider can manage this core set of data using RESTful patterns.
When designing a sidecar architecture, the engineering team should utilize Ed-Fi principles to model the data at rest within the internal ODS, serving as the structured foundation for the data warehouse. Simultaneously, the middleware should expose OneRoster-compliant REST endpoints outward, allowing lightweight classroom applications to connect quickly without needing to comprehend the entire Ed-Fi analytical schema. This is exactly the kind of disciplined data design that underpins trusted AI data infrastructure that reduces hallucinations across analytics and tutoring tools.
LTI Advantage and the Next-Generation Security Overhaul
Learning Tools Interoperability (LTI) is the global standard that governs how external tools and applications launch within a Learning Management System. For years, the industry relied on outdated versions of LTI (such as LTI 1.1) that utilized cumbersome OAuth 1.0 cryptographic signatures, which presented known security vulnerabilities.
LTI Advantage, built exclusively upon the foundation of LTI 1.3, represents a total overhaul of the educational security and integration model. The 1EdTech Security Framework now strictly requires OAuth 2.0 authentication protocols and JSON Web Tokens (JWT) for secure message signing, providing a massive upgrade in data privacy and protection against interception. LTI Advantage introduces three critical feature services that are essential for modernizing the student experience:
The Deep Linking (DL 2.0) service allows instructors and instructional designers to seamlessly embed specific content playlists, external AI tutoring modules, and dynamic HTML content directly into the LMS course structure with a few clicks, bypassing clunky external portal logins.
The Assignment and Grade Services (AGS) service is perhaps the most critical for SIS modernization. It permits third-party tools to dynamically update numeric scores, instructor comments, and multiple assignment attempts directly into the centralized LMS gradebook. This enables a seamless flow where an AI tutor evaluates a student, AGS pushes the score to the LMS, and the sidecar middleware utilizes OneRoster to pull that finalized grade from the LMS back into the SIS system of record.
The Names and Role Provisioning Services (NRPS 2.0) grants external tools secure, real-time access to the roster of users and their specific institutional roles within a given course context. This ensures an AI tool immediately knows whether the user logging in is a student requiring assessment or an instructor requiring an analytics dashboard.
By ensuring that the custom middleware and all procured vendor applications are strictly certified for LTI 1.3 and OneRoster 1.2, institutions force edtech vendors to adhere to standardized, modern security protocols, drastically reducing the attack surface that malicious actors exploit.
| Interoperability Standard | Primary Institutional Use Case | Core Domain Data Scope | Technical Format and Security | Ideal Implementation Scenario |
|---|---|---|---|---|
| OneRoster 1.2 | Application rostering and grade passback | Users, classes, enrollments, grades | REST/JSON APIs, CSV (Bulk & Delta), OAuth 2.0 | Rapidly provisioning a new supplemental reading application and synchronizing its grades with the legacy SIS. |
| Ed-Fi Data Standard v5 | Institutional analytics and reporting | Broad domain: Students, staff, attendance, state assessments | REST/JSON APIs, Bulk ETL | Building a centralized data warehouse hub to power predictive retention and Multi-Tiered System of Supports dashboards. |
| LTI Advantage (1.3) | Secure application launch and deep LMS integration | Authentication, role provisioning, dynamic gradebook updates | OAuth 2.0, JSON Web Tokens (JWT), HTTPS | Embedding an interactive AI tutor directly into an LMS module with seamless single sign-on and automatic grade return. |
Compliance: FERPA, State Laws, and AI-Specific Regulatory Overlays

The technical architecture of an educational integration layer is ultimately subordinated to strict legal and compliance frameworks. Educational data is heavily regulated, and the rapid introduction of artificial intelligence has triggered a wave of new state-level legislation that severely limits how student data can be processed, stored, and evaluated. A modernized SIS architecture must structurally guarantee compliance with these overlapping mandates.
FERPA and the Rigid "School Official" Exception
The Family Educational Rights and Privacy Act (FERPA) serves as the baseline federal privacy law for education, mandating that educational institutions cannot disclose personally identifiable information (PII) from a student's education record without written parental or student consent. To utilize modern third-party cloud computing platforms and edtech vendors without obtaining thousands of individual permission slips for every application, institutions rely heavily on the "school official" exception.
To legally qualify for this exception, the third-party edtech integration must meet three rigorous criteria. First, it must perform an institutional service or function that the school would otherwise use internal employees to execute. Second, the vendor must operate under the direct control of the institution regarding the use and maintenance of those specific education records. Third, the vendor must strictly adhere to FERPA's rules prohibiting the redisclosure or repurposing of that data for unauthorized activities, specifically precluding the use of student data for targeted marketing or unauthorized model training.
When building a sidecar middleware, the architecture must enforce these legal boundaries mathematically. The sidecar ensures that external vendors only pull the specific data fields required for their contractual function—a principle known as least privilege access at the data layer. This architectural chokepoint prevents vendors from passively scraping unrelated student demographic records from the SIS to build proprietary profiles. It is the same mindset used to tame Shadow AI risks when staff use unsanctioned AI tools, by locking down where sensitive records can and cannot go.
New York State Education Law Section 2-d
State privacy laws compound federal requirements, creating strict technical floors for any integration project. New York's Education Law § 2-d represents one of the strictest edtech frameworks in the country, explicitly protecting the PII of students, teachers, and principals shared with third-party vendors.
Under § 2-d, vendors must legally commit to adhering to the NIST Cybersecurity Framework and are bound by strict, rapid breach notification protocols. Critically, the law mandates that all PII must be encrypted both in motion and at rest using industry-standard data encryption technology. Educational institutions must formally appoint a Data Protection Officer (DPO), conduct comprehensive risk assessments on new technologies, and publish a Parents' Bill of Rights detailing exactly how student data is utilized by vendors. Custom middleware provides the centralized encryption, data mapping, and granular auditing capabilities required to prove compliance with § 2-d during a rigorous state audit.
The Colorado AI Act: The Pivot from CAIA to ADMT Accountability
The regulatory landscape regarding artificial intelligence in education experienced a seismic, highly disruptive shift in May 2026, fundamentally altering how institutions must handle algorithmic student data. Initially, Colorado passed the landmark Colorado AI Act (SB 24-205), which broadly categorized educational enrollment, assessment, and financial aid algorithms as "high-risk" systems, mandating extensive impact assessments and risk management programs by June 30, 2026.
However, following extensive industry pushback regarding the law's overly complex and burdensome compliance regime, Colorado Governor Jared Polis signed Senate Bill 26-189 into law on May 14, 2026, fully repealing the original act and replacing it before it ever took effect. The new legislation abandons the broad "high-risk" developer framework in favor of regulating Automated Decision-Making Technology (ADMT) that materially influences consequential decisions, pushing the effective enforcement deadline back to January 1, 2027.
While the new ADMT framework scales back the macro-level systemic reporting requirements, it drastically increases point-of-use accountability and consumer rights. Under SB 26-189, if an AI system materially influences a consequential educational decision—such as denying a student admission, triggering an academic probation alert, or altering financial aid eligibility—the institution deploying the technology must provide a plain-language disclosure to the student explaining the system's role within 30 days of the adverse outcome.
Furthermore, the institution must provide the student with the explicit right to access the underlying personal data used by the AI system, the right to correct inaccurate data, and the right to request meaningful human review and reconsideration of the ADMT-influenced decision. Crucially for procurement officers, the new law voids any vendor contract clauses that attempt to indemnify a party or shift liability for discriminatory ADMT outputs away from the software developer and solely onto the deploying school. While the law does not create a private right of action and includes a 60-day right-to-cure provision valid until 2030, it is enforceable exclusively by the Colorado Attorney General.
For CTOs and CIOs, this means that any AI tutor or predictive analytics engine integrated into the institutional stack must have completely transparent, auditable data pipelines. A black-box AI model connected directly to the SIS via an unmonitored API is a massive legal liability. A sidecar middleware layer solves this by acting as an immutable audit log, tracking every single data interaction. If a student challenges an ADMT decision under Colorado law in 2027, the institution can definitively trace the exact data points the AI model ingested from the sidecar at the specific time of the decision, fulfilling the state's stringent transparency and human-review mandates. This level of traceability is exactly what forward-looking CFOs and CTOs are starting to demand when they justify AI investments and measure real ROI.
| Legal / Compliance Framework | Jurisdiction and Scope | Primary Data Protected | Core Architectural and Operational Requirement |
|---|---|---|---|
| FERPA (School Official Exception) | US Federal (Applies to all federally funded schools) | Student Personally Identifiable Information (PII) | Requires least-privilege API access and enforces strict prohibitions on external data repurposing or marketing. |
| NY Education Law § 2-d | New York State | Student, teacher, and principal performance records | Mandates enforced AES-256 encryption at rest and TLS in transit, aligning with the NIST Cybersecurity Framework. |
| Colorado SB 26-189 (ADMT) | Colorado residents (Effective January 1, 2027) | Personal data driving consequential AI decisions | Demands immutable audit logs mapping exact inputs to AI outputs, supporting 30-day notices and data correction rights. |
An 18-Month Phased Modernization Roadmap
A multi-year, big-bang modernization effort is destined to fail in the education sector due to the inherent, unyielding constraints of the academic calendar. System migrations cannot occur during high-stakes registration periods, end-of-term grading windows, or federal financial aid disbursement cycles. The only viable, realistic path to modernizing the legacy stack is an incremental, 18-month phased roadmap that introduces the sidecar layer systematically, utilizing academic breaks as critical go/no-go delivery gates.
Phase 1: Architectural Assessment and Sidecar Provisioning (Months 1-3, Fall Term)
The objective of the initial phase is establishing the foundational infrastructure without disrupting active classes. The IT department conducts a comprehensive business mapping exercise to catalog existing legacy SIS data structures, avoiding the technical fallacy that plagues traditional migrations. Engineering teams, utilizing Rapid Agile Deployment principles, deploy the custom middleware infrastructure, bringing PostgreSQL operational data stores and Kubernetes clusters online. The Change Data Capture (CDC) pipelines are established to begin silently replicating data from the legacy SIS into the sidecar's read-only repository. No external systems are connected to the sidecar during this period. The primary deliverable is achieving a stable, real-time Event-Driven Book of Reference that accurately mirrors the SIS.
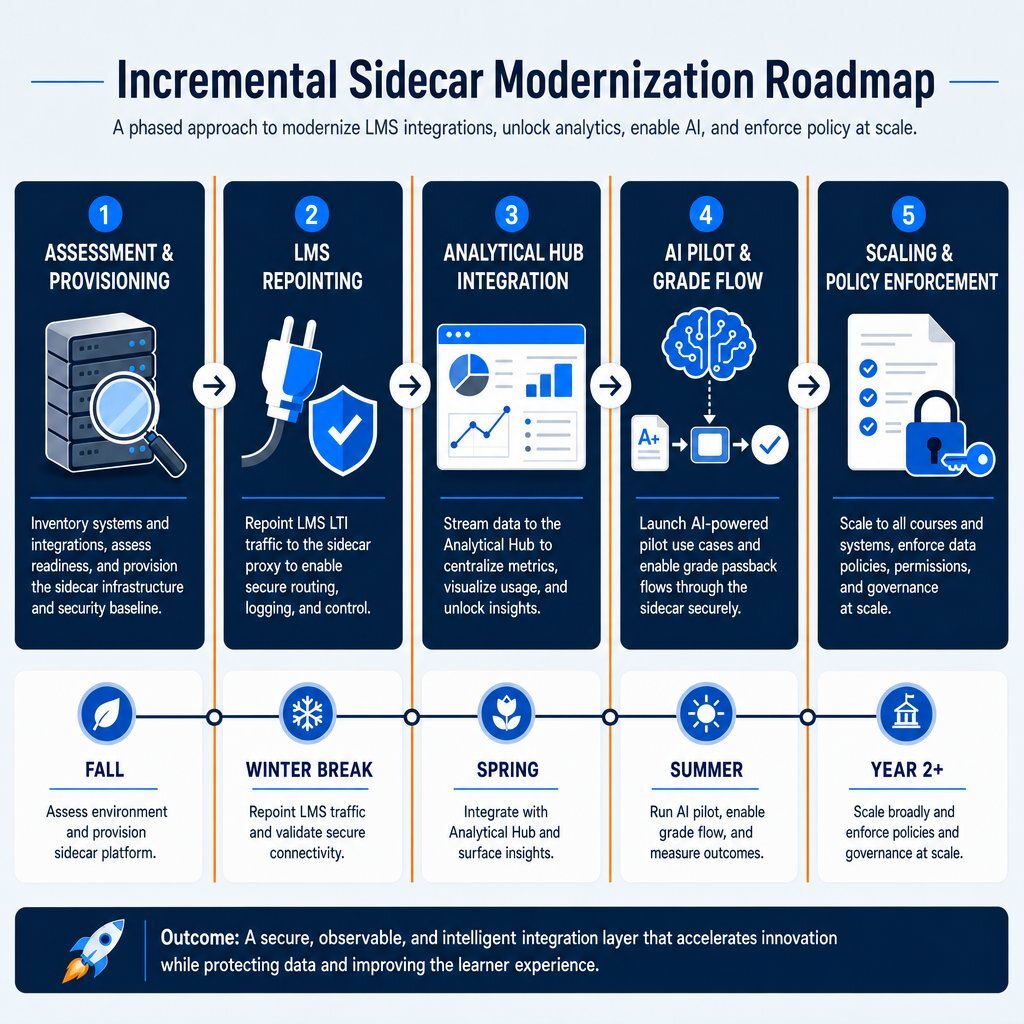
Phase 2: LMS Standards Alignment and Repointing (Months 4-6, Winter Break)
During the low-traffic winter break, the IT team executes the first major system transition, shifting the LMS integration away from the legacy SIS and pointing it toward the new middleware layer. The sidecar is configured to securely expose OneRoster 1.2 REST endpoints. The LMS begins reading user rosters and course enrollments exclusively from the sidecar. Concurrently, LTI Advantage 1.3 security protocols are strictly enforced across all existing LMS tool integrations, establishing the secure foundation for Names and Role Provisioning Services. The deliverable is a modernized LMS connection that no longer burdens the legacy SIS with constant read requests.
Phase 3: Analytical Hub Integration and Data Lakehouse (Months 7-9, Spring Term)
With operational rostering functioning smoothly via OneRoster, focus shifts to broad data analytics. The sidecar data model is expanded to fully encompass the Ed-Fi Data Standard v5. The enterprise data warehouse and MTSS predictive retention dashboards are repointed to ingest data directly from the Ed-Fi ODS layer of the middleware using bulk ETL processes. This unlocks siloed historical data, allowing the institution to run complex predictive algorithms on student retention without impacting the performance of the transactional SIS.
Phase 4: AI Tutor Pilot and Bidirectional Grade Flow (Months 10-12, Summer Term)
The critical summer window provides the operational safety necessary for the introduction of bidirectional data flow and experimental technology. The institution pilots the newly approved AI tutoring system, integrating it via LTI Advantage to ensure secure OAuth 2.0 authentication. The AI application reads student context from the sidecar and utilizes the Assignment and Grade Services (AGS) endpoint to post assessment scores back through the middleware. The middleware safely queues and validates these grade updates before initiating a highly controlled, synchronous write-back sequence to the legacy SIS, ensuring data integrity without exposing the SIS to direct external writes.
Phase 5: Scaling, Policy Enforcement, and Legacy Optimization (Months 13-18, Academic Year 2)
In the final phase, the institution enforces a strict IT governance policy dictating that all new third-party vendor applications must connect exclusively through the standardized middleware. Direct API access to the legacy SIS is formally deprecated. The IT team enters a period of hypercare, closely monitoring the audit logs to ensure total compliance with laws like the upcoming Colorado ADMT regulations. The legacy SIS, now relieved of millions of daily API read requests, functions efficiently purely as the ultimate system of record for financial disbursements and transcript reporting, its lifespan significantly extended.
Custom Software vs. Off-the-Shelf Integration Platforms
When establishing an integration layer to solve the SIS modernization problem, institutions must rigorously evaluate whether to utilize commercial off-the-shelf integration platforms or commission the development of custom middleware. The current market is heavily dominated by centralized SaaS platforms, but their underlying financial models and architectural philosophies pose long-term strategic risks for educational institutions.
The Clever Platform: The Apple App Store of EdTech
Clever operates as the dominant identity and rostering platform in the K-12 market, successfully capturing over half of all United States school districts. It functions effectively as the "Apple App Store for Education," offering a centralized, highly polished portal that makes technology transitions and student access practically seamless.
However, Clever utilizes a brilliant but aggressive economic model: the platform and its integrations are provided completely free of charge to the school districts, but Clever monetizes the ecosystem by charging EdTech developers a substantial tax to access those schools. EdTech developers are typically charged between 1.50 and 5.00 per student annually just to integrate their product via Clever. For an innovative supplemental learning application deployed across thousands of students, these recurring costs rapidly escalate to tens of thousands of dollars a month.
Because Clever hosts over five hundred different learning applications and maintains deep, efficient database connections from district to district, it has established extraordinarily high switching costs. Districts become hesitant to adopt innovative new tools unless they are natively accessible on the Clever platform, effectively forcing smaller vendors to pay the Clever tax or risk total exclusion from the market. This dynamic artificially consolidates market power in a single entity and limits the institution's ability to procure niche, specialized tools.
ClassLink and Edlink: Alternative Centralized Models
ClassLink operates as a primary competitor to Clever, providing similar single sign-on (SSO) and rostering capabilities but utilizing an inverted pricing model. ClassLink charges the school districts directly—typically 1.50 to 3.00 per student annually for their standard tier—while providing the application integrations to vendors for free. While this removes the barrier to entry for software developers, it introduces a significant recurring software licensing cost directly to the institution's IT budget.
Edlink approaches the integration problem from a fundamentally different architectural angle. Rather than providing a visible portal for students and teachers to log into, Edlink operates as an invisible backend middleware facilitator. It offers a unified API that allows EdTech vendors to build a single integration that subsequently connects to dozens of different LMS, SIS, and identity management providers. While Edlink brilliantly reduces the engineering burden for software companies, it remains a third-party SaaS layer inserted directly between the institution and its sensitive data, perpetuating the risks of external SaaS reliance.
The Strategic Value of Custom Middleware
Relying entirely on Clever, ClassLink, or Edlink merely transfers the institution's critical dependency from the legacy SIS vendor to the integration vendor. It exacerbates the exact SaaS concentration risk that led to the devastating Canvas ransomware blackout.
Developing a proprietary, custom middleware sidecar ensures absolute technological sovereignty. Partnering with a specialized application management firm like Baytech Consulting allows institutions to build a localized Event-Driven Book of Reference utilizing robust, enterprise-grade technologies like PostgreSQL databases, Docker containerization, and Kubernetes orchestration. This custom approach embodies Tailored Tech Advantage and Rapid Agile Deployment, allowing the institution to tailor the data structures exactly to its unique edge cases rather than forcing institutional data to conform to a commercial platform's rigid, generic schema. It is also aligned with a broader “stop renting intelligence” strategy, where you build the AI and integration capabilities that truly differentiate your institution instead of depending entirely on vendor roadmaps.
Custom software guarantees that the institution explicitly owns the encryption keys, independently manages the immutable audit logs required by the Colorado AI Act, and controls the exact data fields exposed to third parties to satisfy FERPA's strict "school official" limitations. It transforms the integration layer from a recurring, leased operational expense into a permanent, owned institutional asset that secures the future of the university's digital infrastructure.
Conclusion
The legacy Student Information System cannot simply be ripped out without courting operational disaster, nor can it be safely exposed to the volatile, rapid-iteration ecosystem of modern artificial intelligence tools and cloud learning platforms. Attempting a monolithic cloud migration without proper operational readiness and intensive departmental business mapping guarantees failure, while relying on single point-to-point API connections courts ransomware vulnerability and compliance violations.
The definitive solution lies in architectural decoupling. By implementing an event-driven, read-only sidecar middleware layer, educational institutions can establish a secure, standardized Event-Driven Book of Reference. Enforcing strict interoperability standards like OneRoster 1.2, the Ed-Fi Data Standard v5, and LTI Advantage 1.3 ensures that demographic data and academic grades flow efficiently and securely across the campus ecosystem. Crucially, this advanced architecture provides the precise, mathematically enforced auditability required to navigate emerging legal frameworks, from FERPA's rigid restrictions to the automated decision-making transparency mandated by the newly enacted Colorado SB 26-189.
For institutions looking to permanently resolve their SIS integration bottleneck without risking operational continuity or relying on monopolistic SaaS platforms, commissioning custom middleware is the most strategic path forward. Firms specializing in complex enterprise architecture and custom software engineering provide the precision necessary to execute this transition safely. Institutions must begin planning their Phase 1 sidecar deployments immediately to ensure readiness ahead of the next academic cycle, ideally as part of a broader 90-day AI implementation and modernization roadmap that can be repeated and scaled.
Supporting Links
- https://davidkentconsulting.com/blog/top-workday-implementation-issues-in-higher-education/
- https://er.educause.edu/articles/2026/5/how-higher-education-is-responding-to-the-canvas-lms-incident-and-preparing-for-whats-next
- https://www.finnegan.com/en/insights/articles/colorado-replaces-landmark-ai-act-an-overview-of-the-new-sb-26-189-framework.html
FAQ
How does the Colorado AI Act impact existing educational algorithms?
The original Colorado AI Act (SB 24-205) was fully repealed in May 2026 and replaced by SB 26-189, which shifts the regulatory focus toward Automated Decision-Making Technology (ADMT). Taking effect January 1, 2027, the new law requires institutions to provide plain-language disclosures within 30 days whenever an ADMT materially influences a consequential decision, such as admission or financial aid determinations. Institutions must also maintain detailed, auditable records of the specific data processed to allow students to request meaningful human review and reconsideration of adverse decisions. For many institutions, that will require the kind of auditable, self-hosted agent infrastructure described in frameworks for self-hosting AI agents in regulated environments, adapted carefully to student data.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.