
Stop Renting Personalization: AI Playbook for Marketing
May 28, 2026 / Bryan Reynolds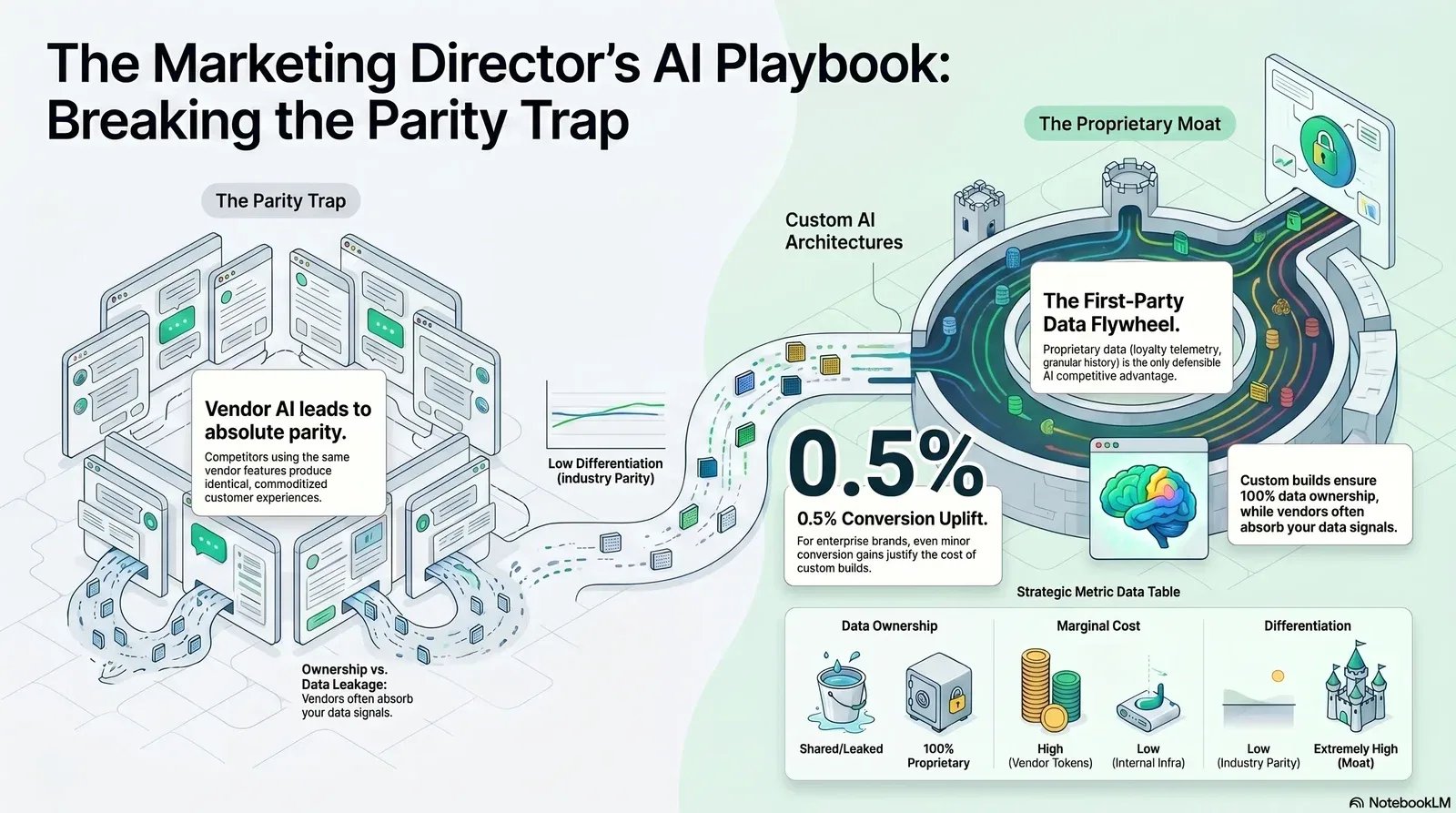
The Marketing Director's Custom AI Playbook: When to Stop Renting Personalization
If your AI-powered email subject lines, content recommendations, and audience segments are running on the exact same model your three closest competitors use, the only thing left to compete on is data — and you are leaking that to a vendor with every personalization call.
The marketing function has been told for a decade that custom software is for engineering teams, not marketing teams. That assumption is now extraordinarily expensive. In 2026, the platforms that own customer journeys—Salesforce, HubSpot, Adobe, Klaviyo, and Braze—all run roughly the same foundation models behind their proprietary personalization features. A marketing director's competitive advantage decays to absolute parity the moment a competitor switches on the same vendor feature.
Marketing leaders who control unique first-party signals, such as loyalty program telemetry, granular purchase histories, customer support interactions, and bespoke app behaviors, must treat custom AI personalization as a core software engineering problem rather than a standard software-as-a-service (SaaS) subscription. This analysis applies the same “Bounded Buy” logic Baytech Consulting leverages for engineering teams, recast for the marketing executive whose primary performance indicator is revenue per visitor, not infrastructure hosting costs. To decide where your AI should live and how portable it needs to be across vendors and infrastructure, it helps to think in terms of a portability-first AI strategy that keeps your most valuable marketing intelligence under your control.
The Parity Trap: Why Platform AI Features Make Competitors Look Identical
Every major B2B and B2C enterprise faces immense pressure to deploy AI, but the default approach of switching on native CRM features fundamentally limits differentiation. Marketing budgets remain functionally flat, rising only slightly to an average of 7.8% of company revenue in 2026, forcing executives to seek operational efficiencies through technology, according to Gartner. Consequently, AI agents and automated workflows have flooded the martech ecosystem. Marketing functions are allocating over 15% of their total budgets directly to AI initiatives, attempting to compensate for stagnant headcount and rising media costs, as reported by MediaPost.
The structural issue with this spending allocation is that generic AI personalization features create parity by design. When a marketing team utilizes Salesforce Agentforce, HubSpot Breeze, or Klaviyo AI to optimize a campaign, those systems rely entirely on standard, commoditized data schemas. If an enterprise CRM only registers that a lead opened an email and clicked a pricing page, the embedded AI can only generate variations of standard follow-up sequences. It cannot synthesize external signals, unstructured behavioral data, or proprietary industry context unless that data is explicitly engineered into the vendor's walled garden, a process that often carries prohibitive integration costs and API limits, as noted by Autobound. In many cases, it’s more effective to treat those platforms as channels and build your own intelligence layer on top, similar to how leading enterprises now rethink SaaS in the age of AI.
The actual financial cost of this parity is deceptively high. The foundational economics of artificial intelligence differ drastically from traditional SaaS. Serving an additional customer in classic SaaS costs virtually nothing, yielding 80% to 90% gross margins for the vendor. Conversely, AI inference requires massive computational power for every query, dropping vendor margins to 50% or 60%. To offset these infrastructure costs, martech vendors charge a premium for AI usage. Salesforce Agentforce can cost $2 per conversation, while other platforms utilize opaque credit systems that deplete rapidly at scale. Marketing organizations are essentially financing their vendor's compute costs while receiving a commoditized output that their direct competitors can duplicate with a single click.
What You Actually Own: Auditing the First-Party Data Flywheel
The true competitive moat in 2026 is the proprietary first-party data flywheel. Foundational language models are increasingly becoming commodities, driving down the intrinsic value of the reasoning engine itself. The enterprise value now resides entirely in the unique data used to contextualize those models. When a brand builds custom AI personalization, it retains full ownership of its behavioral data and the synthesized intelligence generated from it. That same discipline—treating data governance as infrastructure rather than an afterthought—is at the heart of building AI data infrastructure that reduces hallucinations and keeps your personalization accurate and trustworthy.
Leading brands demonstrate that true 1:1 personalization at scale requires unified first-party data feeding into bespoke machine learning systems, rather than generic segment-based targeting.
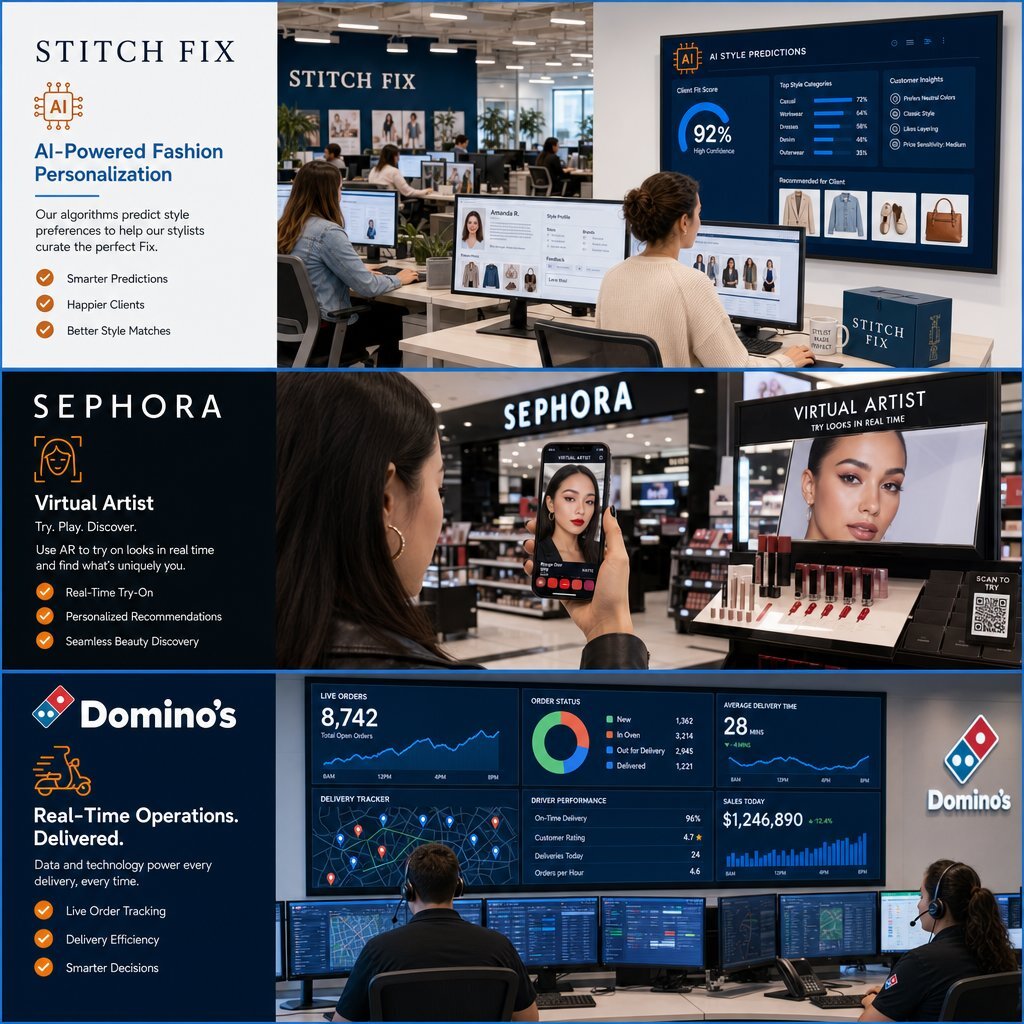
Stitch Fix: Personalization as the Core Value Proposition
Stitch Fix engineered a business model where custom AI personalization is the product itself. Rather than purchasing a generic retail recommendation engine, the company built a proprietary machine learning architecture that pairs algorithmic prediction with human curation. Customers provide extensive zero-party data by completing an 80-question onboarding survey that maps their exact style preferences.
As Stitch Fix tracks which items users keep and which they return, the custom algorithms continuously learn the highly specific nuances of individual client preferences. This custom architecture directly impacts the bottom line; improvements to their client experience and recommendation flexibility generated 10% year-over-year average order value growth, according to third-quarter 2025 earnings. A vendor-supplied AI trained on generalized retail trends could never replicate the precision of this proprietary feedback loop.
Sephora: Deep Digital and Physical Integration
Sephora utilizes custom AI to dominate the omnichannel beauty market. The retailer aggregates rich customer data across mobile app usage, quizzes, purchase history, and in-store behaviors to build comprehensive identity profiles. This data fuels personalized digital experiences, such as the "Virtual Artist" augmented reality tool, which allows customers to virtually try on makeup, as outlined by Cognitute.
Sephora's deployment relies on computer vision and deep learning technologies to cater to complex customer preferences. Crucially, the brand utilizes this intelligence not merely to push immediate sales, but to model demographic trend diffusion and localize physical assortments, an operational capability beyond the scope of a standard marketing cloud.
Domino's: Predictive Operational Intelligence
Domino's Pizza bridges the gap between marketing personalization and operational execution through DomOS, its proprietary technology framework. The company utilizes custom machine learning models to predict precisely when individual customers are most likely to order, often targeting offers down to the specific hour of peak intent.
This personalization extends to the logistical experience. Domino's updated its famous tracking application with a custom AI engine that analyzes multiple real-time inputs—from kitchen preparation data to localized traffic patterns—to generate highly accurate delivery estimates. Feeding this massive volume of disparate information into a central data warehouse requires sophisticated Master Data Management infrastructure, a feat analyzed by Profisee. A rented marketing agent cannot optimize delivery logistics; only a custom-built, deeply integrated AI architecture can achieve this level of cross-functional intelligence.
The Build-vs-Buy Decision for Marketing AI
Marketing leaders must rigorously quantify the cost of AI parity. If a custom build is not justified by the data or the economics, buying and consolidating is the correct strategic move. A proven four-question diagnostic, adapted from Baytech Consulting's enterprise engineering frameworks, clarifies this decision and mirrors broader guidance on when to stop renting intelligence and build AI that protects your edge.
Are your first-party data signals completely unique to your enterprise?
If your personalization relies on standard digital events—page views, email opens, and basic form submissions—buy the vendor feature. If it relies on proprietary product telemetry, localized inventory constraints, or deep loyalty program interactions, build a custom solution.
Does the specific marketing workflow differentiate your brand?
Automating the drafting of social media posts or summarizing sales calls reduces operational drag but does not differentiate the brand. Buy tools for these tasks. However, if the workflow dictates the core customer experience—such as dynamic pricing engines or predictive product configuration—you must own the underlying intellectual property.
Does your query volume justify fixed infrastructure costs over variable token fees?
Enterprise marketing platforms frequently charge usage-based fees for AI execution. For millions of daily personalization calls, variable token costs rapidly outpace the fixed infrastructure costs of hosting a proprietary model.
Does your organization have the engineering bandwidth to govern the system?
Custom AI requires continuous model monitoring, data pipeline maintenance, and stringent compliance auditing. Marketing cannot operate in isolation. If the CTO cannot commit dedicated engineering resources to manage the infrastructure securely, you must buy. When you do decide to build, you’ll need a cross-functional team comfortable with DevOps practices so changes ship quickly without sacrificing safety.
The Actual ROI Math
The financial delta between building and buying is substantial. An organization can license a vendor AI platform for a predictable annual cost, deploying simple workflows in a matter of days. Conversely, a custom build requires extensive upfront capital and dedicated engineering resources, carrying a significantly longer payback period.
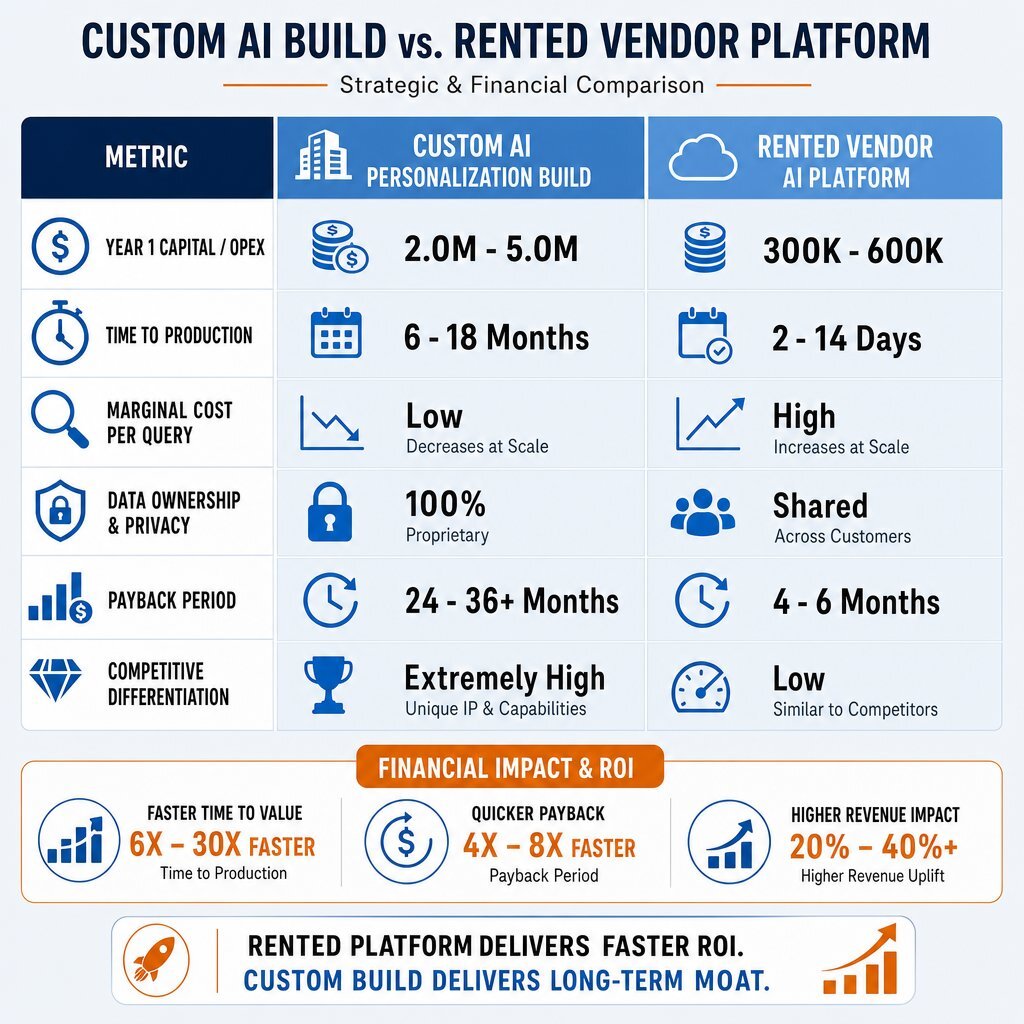
| Strategic Metric | Custom AI Personalization Build | Rented Vendor AI Platform |
|---|---|---|
| Year 1 Capital/Opex | 2.0M - 5.0M | 300K - 600K |
| Time to Production | 6 - 18 Months | 2 - 14 Days |
| Marginal Cost per Query | Low (Internal Infrastructure) | High (Vendor Markup/Tokens) |
| Data Ownership & Privacy | 100% Proprietary and Contained | Shared or Leaked to Vendor Ecosystem |
| Payback Period (ROI) | 24 - 36+ Months | 4 - 6 Months |
| Competitive Differentiation | Extremely High (Defensible Moat) | Low (Industry Parity) |
Table 1: Strategic and Financial Comparison of Build vs. Buy for Enterprise AI Personalization, based on baseline industry modeling.
The data dictates that mid-market companies with limited engineering budgets should default to vendor solutions for 90% of their workflows. However, enterprise brands where a 0.5% uplift in conversion or retention equals tens of millions of dollars in net new revenue must absorb the initial engineering cost of a custom build to secure a defensible long-term moat. Finance leaders will want to see this framed in familiar language—tying payback periods, TCO, and profit impact together, as outlined in our guide to reframing AI ROI for CFOs.
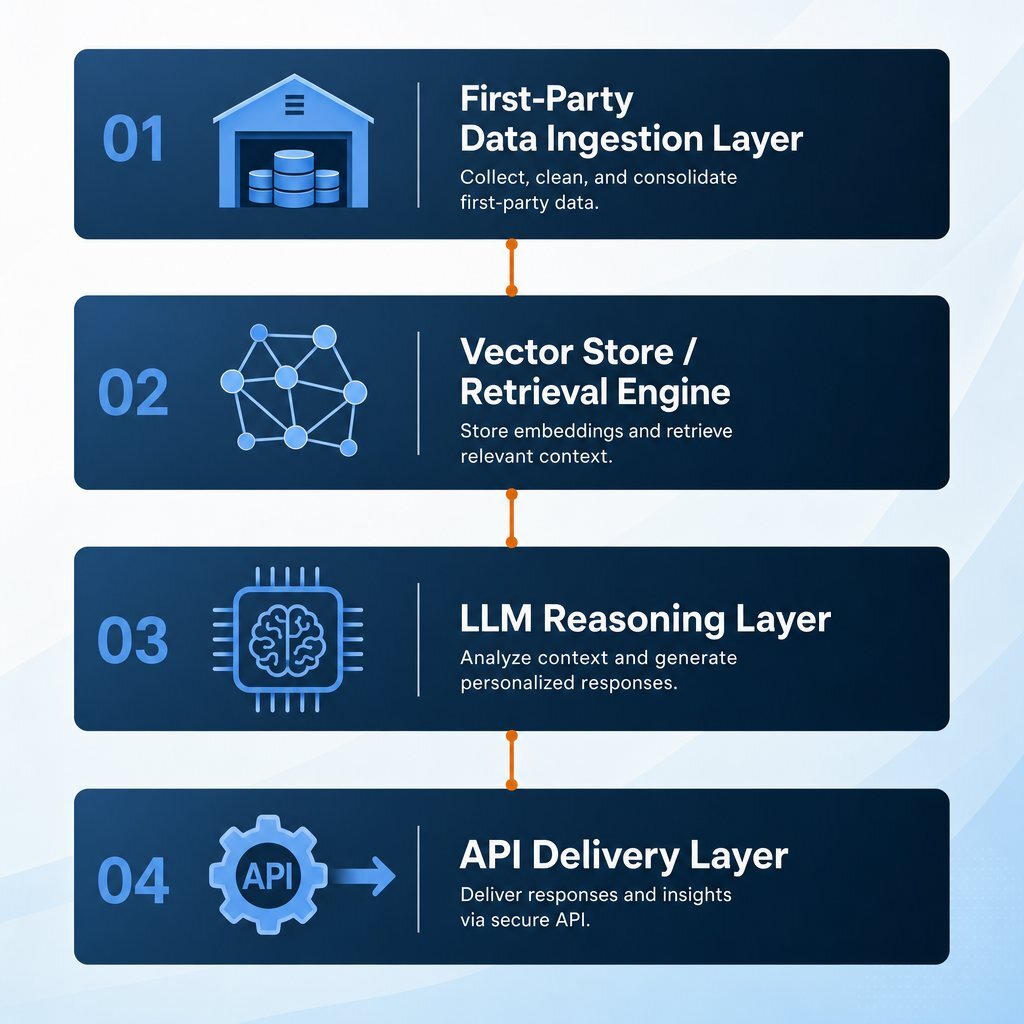
Architecting a Minimum-Viable Custom Personalization Stack
Marketing directors do not need to understand the minutiae of neural network weights, but they must understand the architecture of modern AI to have productive conversations with their engineering counterparts. The barrier to building custom AI has collapsed due to the rise of Retrieval-Augmented Generation (RAG). Organizations no longer need to spend millions training a foundation model from scratch; they simply need to ground an existing model in their proprietary data.
A minimum-viable custom personalization stack consists of four distinct layers:
- The First-Party Data Ingestion Layer: This is the enterprise data warehouse where all behavioral analytics, CRM profiles, and purchase histories reside. If the data is siloed, the AI will fail. Many organizations use this moment to standardize their stack on robust platforms and modern enterprise application architecture so marketing, product, and operations all pull from the same source of truth.
- The Vector Store and Retrieval Engine: AI models cannot natively read relational databases. Unstructured text and categorical data must be converted into high-dimensional mathematical vectors. When a customer triggers a workflow, the system executes a semantic search against this vector store to retrieve the most relevant historical data. Modern platforms natively handle this; for example, Snowflake Cortex Search executes low-latency hybrid searches (combining vector embeddings with traditional keyword matching) directly over enterprise data without requiring separate external infrastructure.
- The LLM Reasoning Layer: The retrieved proprietary data is dynamically injected into a prompt and routed to a Large Language Model. Because the model receives exact, unique context about the specific user, it generates a hyper-personalized output strictly constrained by enterprise facts, virtually eliminating hallucinations.
- The API Delivery Layer: The generated output is routed back to the customer edge via existing mechanisms, such as an email service provider API, a headless content management system, or a dynamic pricing widget on an eCommerce storefront. In practice, this is where you’ll lean on technologies like .NET, Docker, and Kubernetes to package and scale your personalization services reliably across channels.
Compliance Traps: Navigating the 2026 and 2027 Regulatory Minefields
"Shadow martech" is the marketing equivalent of shadow IT, and deploying unvetted AI tools via credit card carries existential regulatory risks. The legal frameworks governing automated profiling and decision-making are undergoing radical transformations across the United States and the European Union. Marketing workflows that process personal data to automate decisions must comply with complex, overlapping jurisdictional mandates. Rather than fighting this trend, many brands are consolidating AI use into vetted internal platforms and adopting private, governed AI to cut down on risky one-off tools.
The Accountability Shift in Colorado
Colorado enacted the nation's first comprehensive state AI law, originally slated for enforcement in June 2026. However, the legislature repealed the initial framework, replacing it with Senate Bill 26-189, which takes effect on January 1, 2027, as detailed by Finnegan.
The new law discards broad "high-risk" system classifications in favor of a targeted accountability model focused on Automated Decision-Making Technology (ADMT) that materially influences a "consequential decision" across domains like financial services, insurance, healthcare, housing, and employment. If a marketing function utilizes custom AI to generate personalized credit offers or segment users for health-related services, it acts as a "deployer."

Deployers must meet rigid consumer rights obligations. They must provide clear, conspicuous pre-use notices informing consumers that ADMT is actively evaluating them. Critically, if the AI personalization results in an adverse outcome—such as a user being excluded from a specific financial product—the enterprise must deliver a plain-language explanation within 30 days detailing the exact inputs the AI used to make the decision. Consumers also possess the right to demand meaningful human review of the automated outcome, forcing organizations to maintain meticulous logs for a minimum of three years.
California's ADMT and Profiling Enforcement
The California Privacy Protection Agency (CPPA) finalized stringent regulations under the California Consumer Privacy Act (CCPA) governing the use of ADMT. These regulations begin taking effect on January 1, 2026, with mandatory compliance enforcing consumer rights beginning April 1, 2027.
California's framework mandates frictionless opt-out procedures. Businesses must provide consumers with clear methods to opt out of the processing, and the interface design must ensure that opting out is just as easy as opting in. Furthermore, enterprises must conduct formal risk assessments before initiating any processing activity that poses a significant risk to consumer privacy, including widespread behavioral profiling. Businesses must eventually submit summary information of these assessments to the state regulatory body.
The European Union AI Act
For multinational enterprises, the EU AI Act imposes the most severe penalties for non-compliance. The critical enforcement deadline affecting high-risk profiling systems is August 2, 2026, as analyzed by HK Law.
While basic marketing automation is not blanketly prohibited, Annex III of the Act classifies specific profiling systems as high-risk, particularly those utilized in employment, candidate filtering, and access to essential services. If a U.S. brand deploys a high-risk AI system where the output affects an EU citizen, the company must complete a formal conformity assessment, maintain detailed technical documentation regarding the model's performance metrics, and register the system in a public EU database. Violations of these high-risk obligations carry devastating fines scaling up to €15 million or 3% of total worldwide annual turnover, whichever is higher.
The 90-Day Custom Personalization Pilot
Given the engineering and regulatory complexity, marketing directors must never attempt a holistic replacement of their existing martech stack. Instead, partner with the CTO to execute a tightly scoped, 90-day pilot focusing on a single, high-impact channel. If your organization doesn’t yet have a clear path to execute that pilot, you can borrow from a structured 90-day enterprise AI implementation roadmap and adapt it to marketing goals.
Weeks 1 to 4: Alignment and Legal Clearance
Define a specific, measurable use case, such as increasing conversion rates on complex B2B product configuration emails. Establish historical performance baselines using existing vendor tools. The engineering team evaluates the first-party data within the enterprise data warehouse, ensuring it is clean and devoid of restricted personal information that could trigger compliance breaches. Legal audits the proposed data pipeline against impending CCPA and Colorado SB 26-189 requirements. A formal C-suite review gate validates the business case before engineering resources are committed.
Weeks 5 to 8: Engineering the Architecture
The proprietary data is embedded and indexed within a vector database. Engineering connects the LLM API to this vector store, while marketing operations specialists rigorously test and refine system prompts to ensure brand voice adherence. Middleware is constructed to connect the custom AI engine to the delivery API. The system undergoes intense internal "red teaming" to ensure safety guardrails hold firm and the model does not hallucinate false product features. This is also the stage where you align deployment and monitoring with your existing AI-powered software practices so the pilot can grow into a production system without a full rebuild.
Weeks 9 to 12: Deployment and ROI Analysis
The system enters shadow testing, generating personalized outputs that are logged but not exposed to customers, verifying latency at scale. Following success, an A/B test deploys the custom AI to a statistically significant cohort (e.g., 10% of traffic), while the remaining 90% receive the standard vendor treatment. The marketing team monitors conversion metrics, while engineering tracks API latency and inference costs. The final executive review compares the precise performance uplift against the engineering expenditures. If the math clears the hurdle rate, the enterprise possesses a validated, compliant custom personalization engine ready for broader channel integration. From there, you can fold it into a broader internal ecosystem of governed agents—similar in spirit to an internal AI app store—so marketing isn’t the only team benefiting from the new platform.
Conclusion and Next Steps
The marketing function must shed the assumption that proprietary software development is the exclusive domain of product engineering. As the AI features natively embedded within major martech platforms commoditize the ability to generate copy, segment audiences, and recommend products, standard vendor tools will yield nothing more than competitive parity. The definitive advantage in modern enterprise marketing is a bespoke AI architecture grounded entirely in unique, first-party data.
While the initial capital expenditures and regulatory compliance burdens—particularly navigating the EU AI Act and Colorado's new accountability mandates—are substantial, the resulting infrastructure creates a compounding, revenue-generating moat. By ruthlessly applying build-versus-buy logic, consolidating generic workflows onto vendor platforms, and building custom engines solely for differentiating customer experiences, marketing leaders can secure highly defensible ROI.
Translating these strategic imperatives into production-grade architecture requires expert engineering execution. Baytech Consulting specializes in custom software development and application management, delivering Tailored Tech Advantage for complex enterprise challenges. With deep expertise across robust infrastructure environments, including PostgreSQL, Kubernetes, and Azure DevOps On-Prem, our engineering teams ensure that custom AI deployments are secure, performant, and perfectly aligned with your strategic revenue goals.
FAQ
How do we protect our proprietary marketing data when sending it to an LLM via API in a custom build?
To protect proprietary data, enterprises must utilize "Zero Data Retention" agreements with commercial LLM providers, ensuring that data passed through the API is not stored or utilized to train the provider's underlying foundational models. Alternatively, organizations can host open-weight models entirely within their own secure cloud infrastructure, guaranteeing that sensitive customer profiles and behavioral telemetry never traverse the public internet or interact with a third-party server. For regulated or highly sensitive environments, this often means self-hosting AI agents and keeping both code and data inside your own perimeter.
Supporting Links
- https://www.snowflake.com/en/blog/cortex-search-ai-hybrid-search/
- https://www.bvp.com/atlas/the-ai-pricing-and-monetization-playbook
https://www.walnut.io/blog/walnut-news/build-vs-buy-in-the-age-of-ai/
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.