
Building AI Data Infrastructure to Reduce Hallucinations
May 08, 2026 / Bryan Reynolds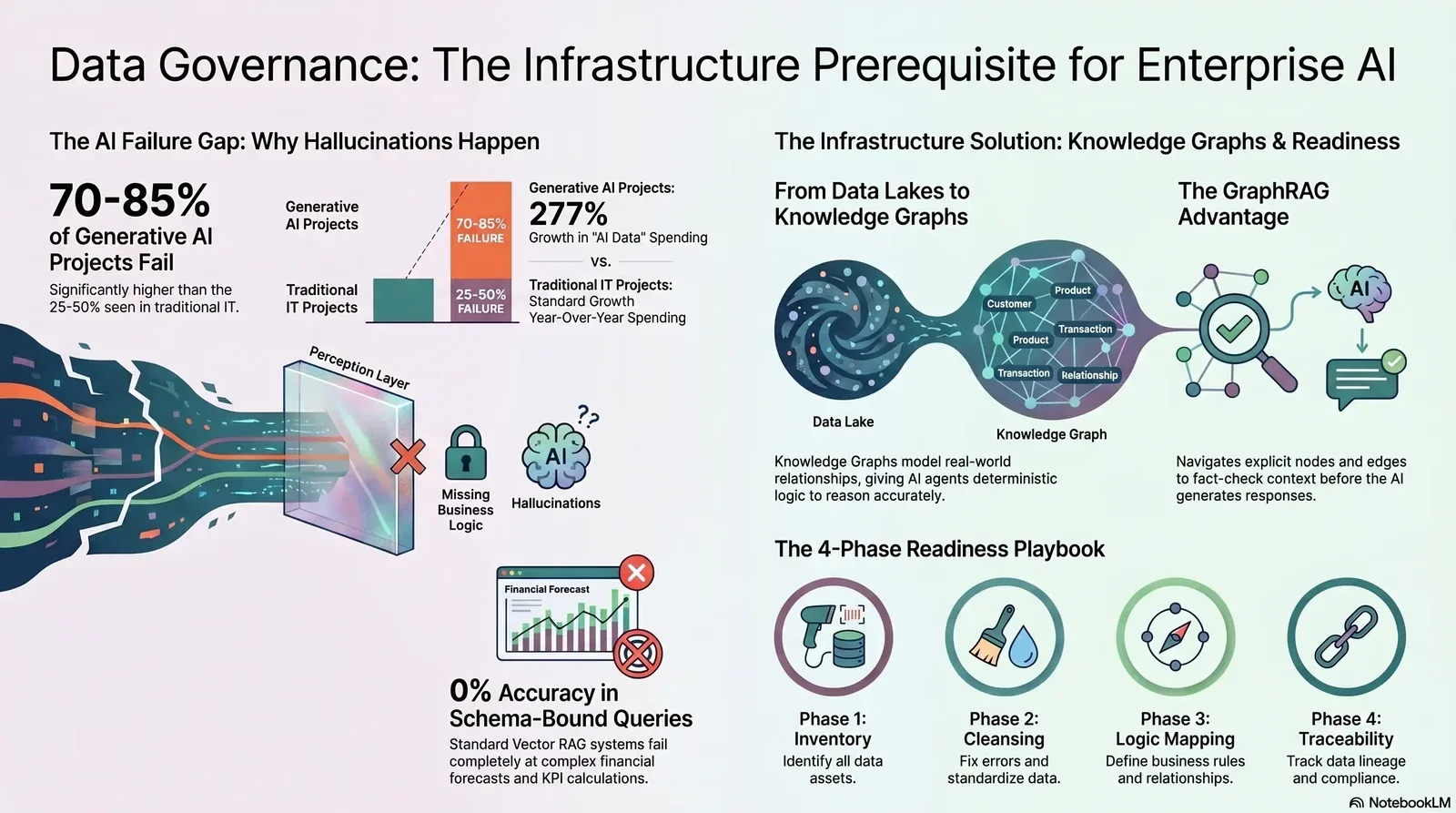
Data Governance as Infrastructure: The Prerequisite for AI
The enterprise pursuit of autonomous operations has reached a critical juncture. Across industries—from telecommunications and real estate to healthcare and decentralized finance—organizations are deploying artificial intelligence (AI) agents with the expectation of achieving unprecedented productivity. Yet the reality frequently contradicts the marketing. The executive boardroom is increasingly echoing a set of urgent, interconnected questions: Why do out-of-the-box AI agents confidently hallucinate when connected to standard ERPs? How does a Knowledge Graph fundamentally improve an AI agent's reasoning capabilities? And what steps must a company take to clean its data before handing the keys to an AI?
The fundamental issue driving these questions is not the capability of the underlying large language models (LLMs). The breakdown occurs at the foundational layer: the data. When autonomous systems are built on top of messy, ungoverned data, they do not simply fail to execute tasks; they confidently fabricate realities to bridge the gaps in their understanding. This phenomenon, widely known as hallucination, represents a critical failure in digital infrastructure.
Addressing this failure requires a paradigm shift. Data governance can no longer be viewed merely as a compliance exercise managed via periodic audits. Instead, it must be treated as a rigorous, non-negotiable infrastructure layer. To transition from isolated generative AI experiments to scalable, agentic AI workflows, organizations must evolve their architectures. This evolution necessitates moving away from stagnant data lakes toward highly structured, semantic knowledge graphs that provide AI agents with the explicit context, relationships, and deterministic constraints required to reason accurately.
The Anatomy of AI Hallucinations in Enterprise Systems
To understand why AI agents fail when integrated with traditional enterprise systems, one must first analyze the mechanical nature of how an LLM processes information. An LLM is, at its core, a probabilistic engine. It predicts the next sequence of tokens based on patterns established during its massive, generalized training phase. When an AI agent is deployed to perform a task—such as analyzing competitor pricing, initiating a supply chain reorder, or validating a mortgage application—it relies on external data sources to ground its probabilistic output in factual, enterprise-specific reality.
When that grounding data is sourced from a standard Enterprise Resource Planning (ERP) system or an unstructured data swamp, the system encounters several catastrophic barriers that directly trigger hallucinations.
The "Perception" Layer and Network Blocks
Before an AI agent can even attempt to process data, it must successfully retrieve it. Many autonomous agents, particularly those tasked with market intelligence or external competitor research, fail at what is known as the "perception" layer. When an agent attempts to access external websites or highly secure internal endpoints via standard IP addresses or automated scrapers, it frequently encounters aggressive anti-bot measures, network blocks, Cloudflare challenges, or 403 Forbidden errors.
Because the agent is programmed with a mandate to fulfill a user prompt, it attempts to "reason" its way out of the blocked access. Without explicit programmatic guardrails to halt the operation when network access is denied, the agent may enter an infinite loop or, more commonly, generate a hallucinatory response based on generalized, outdated training data rather than live information. If the agent is functionally "blind" due to network infrastructure limitations, no amount of sophisticated prompt engineering or model fine-tuning can prevent the resulting data fabrication. Resolving this often requires decoupling the reasoning engine from the execution engine, utilizing ethical residential IP pools to maintain a positive IP reputation and allow the agent to actually view the live Document Object Model (DOM) of target sites.
Business Logic Gaps and Missing Context
Standard ERPs are highly optimized relational databases designed for transaction processing (OLTP). They are structured around rigid tables, columns, and foreign keys. While this architecture is perfect for recording a financial ledger or logging inventory, it is inherently devoid of semantic business context.
An ERP might store a customer's payment history in one table, their active service tier in another, and the corporate policy for refunds in an entirely separate, unstructured PDF document stored on a cloud drive. When an AI agent is queried about a customer's refund eligibility, it lacks the ontological map to connect these disparate data points. Missing this business logic, the model generates an answer that ignores the company's specific compliance requirements, embedded formulas, and operational rules. For instance, a customer service bot might confidently authorize a same-day refund for a client based on generic internet training patterns, entirely bypassing the enterprise's strict 30-day processing policy. In customer experience, where loyalty is fragile, a single hallucination of this nature can trigger customer churn, severe compliance headaches, and massive reputational fallout.
Governance Blocks and Blind Spots
Security architecture often inadvertently causes AI hallucinations. To protect sensitive enterprise data, security teams correctly restrict database access and implement strict role-based access controls (RBAC). However, if an AI agent is not provisioned with the appropriate, secure pipelines to access this data, it operates in a state of partial blindness.
When queried, the agent encounters a governance block. Instead of returning a definitive error message stating it lacks the authorization to view the required data, probabilistic models frequently attempt to construct a plausible-sounding answer using whatever fragmented data they can access. This creates a dangerous scenario where the AI generates highly believable responses that have absolutely no factual basis within the organization's production systems, removing the ability for human operators to cross-check the AI's logic against actual source data.
The Dimensions of Poor Data Quality
The most pervasive trigger for hallucinations is the inherent degradation of the data itself. Data quality is multi-dimensional, and AI systems act as force multipliers for existing flaws. According to extensive analysis, poor data quality is characterized by several specific dimensions:
- Accuracy: Data containing human errors, such as mistyped phone numbers, invalid addresses, or incorrect decimal placements, which propagate downstream and corrupt algorithmic analysis.
- Completeness: Datasets suffering from missing fields or undocumented attributes, leaving the AI to guess the missing variables.
- Consistency: A lack of uniformity across different data sources, leading to contradictory "truths" stored in parallel systems.
- Timeliness: Outdated information that no longer reflects the current operational reality, leading AI agents to make decisions based on obsolete market conditions.
When an AI model ingests inaccurate, incomplete, or outdated data, it undergoes model drift. Its performance degrades steadily as it interacts with flawed information. The resulting data chaos does not merely limit performance; it actively undermines the credibility and trustworthiness of the entire AI initiative.
The Statistical Reality: Why AI Projects Crash and Burn
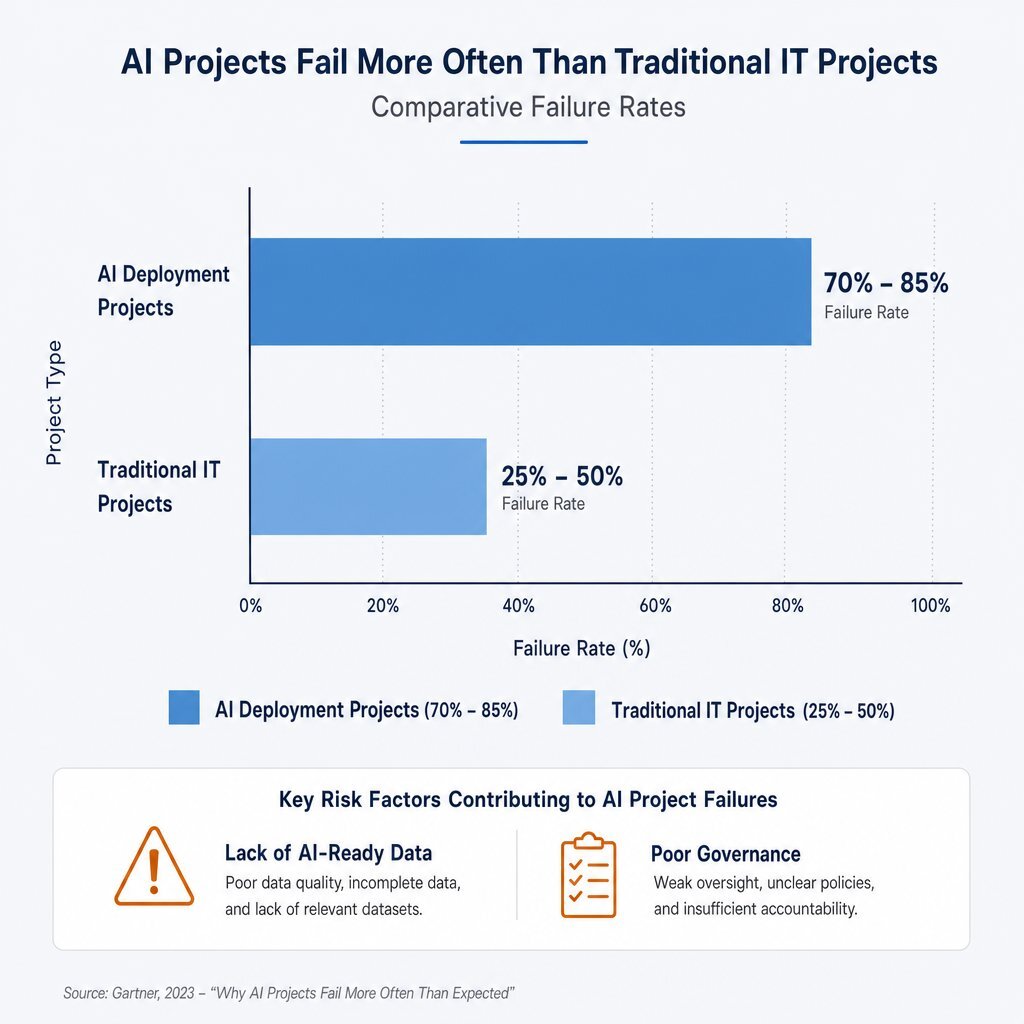
The corporate rush to deploy Generative AI has collided violently with the reality of enterprise data maturity. Industry research reveals the staggering cost of this data chaos. Between 70% and 85% of generative AI deployment efforts fail to meet their desired return on investment (ROI), a figure significantly higher than the standard 25–50% failure rate for traditional IT projects.
The primary root cause of this high failure rate is universally identified as a lack of AI-ready data. Traditional data management paradigms are wholly insufficient for autonomous agents. Data that is considered "high quality" for standard human-read analytics may be entirely unusable for an AI agent if it lacks robust metadata tagging, clear lineage, and explicit semantic relationships.
The illusion of readiness is a trap. Organizations assume that because they possess a massive data lake, they are prepared for agentic AI. This assumption fundamentally misunderstands how AI agents interact with storage architectures. Leaders who want to turn experiments into production should align these efforts with a clear enterprise AI implementation roadmap so projects are scoped, funded, and governed around measurable outcomes instead of hype.
The Intelligence Ceiling: Data Lakes vs. Knowledge Graphs
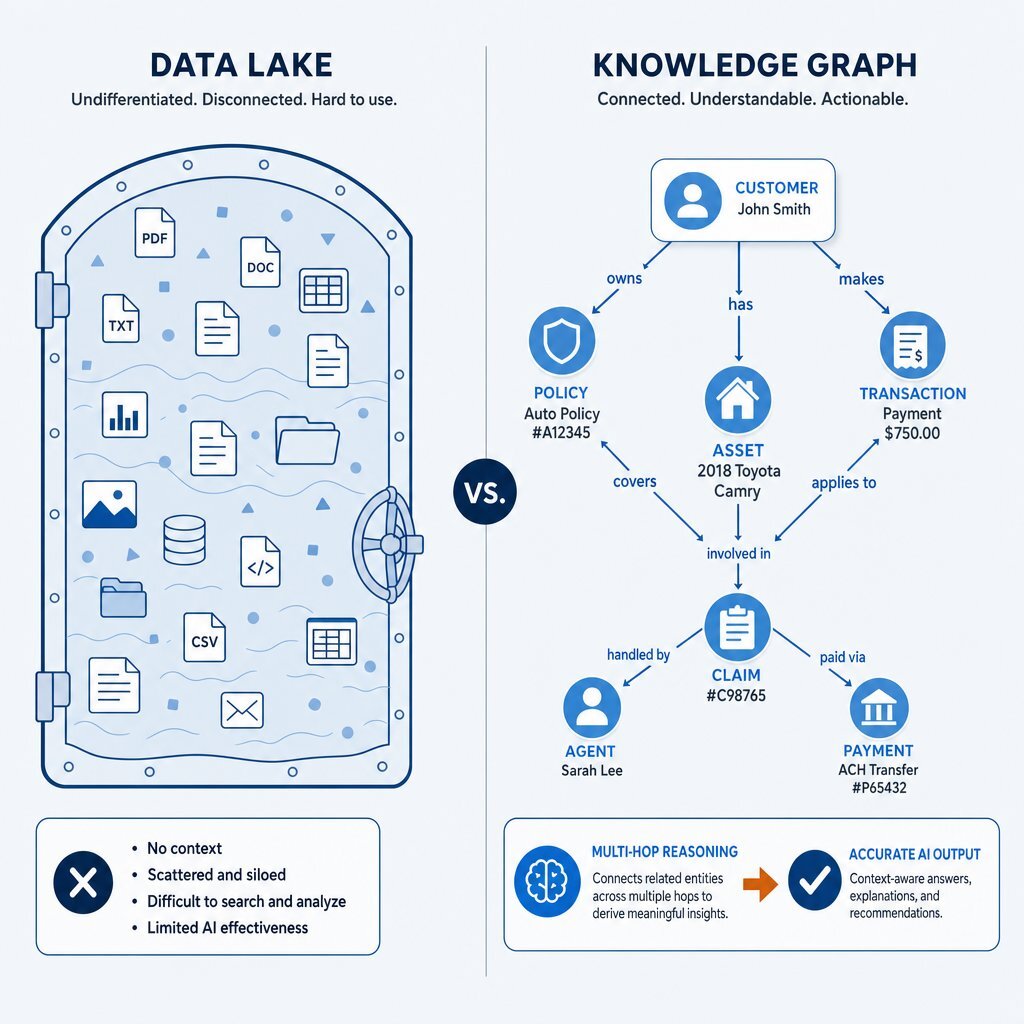
To combat the limitations of raw ERP data, enterprises have historically invested millions of dollars into data lakes. A data lake is a vast, centralized repository designed to store raw structured, semi-structured, and unstructured data at immense scale. The theoretical promise of a data lake was that by colocating all enterprise data in one highly accessible environment, data scientists and machine learning algorithms could seamlessly extract predictive patterns without worrying about rigid schemas.
In practice, this approach has hit an intelligence ceiling.
While data lakes successfully solve the problem of physical data storage, they entirely fail to improve data usability. Centralizing data does not automatically grant it semantic meaning. Without strict, continuous governance, data lakes quickly devolve into "data swamps"—jumbled repositories where the meaning of the data remains locked within the separate applications, isolated processes, and proprietary program logic that originally generated it.
The Mechanics of Knowledge Graphs
A Knowledge Graph (KG), by contrast, fundamentally alters how data is organized, modeled, and accessed. Instead of storing information as isolated rows within tables or flat files floating in a lake, a knowledge graph explicitly models real-world entities (people, products, organizations, events) and the multidimensional relationships between them.
By deploying a knowledge graph as an infrastructure layer, an organization maps its unique business reality into a format that a machine can natively understand. This allows data to be queried not just for what it is, but for what it means. For SaaS and internal platform teams, this same shift underpins the move from simple chat widgets to true AI copilots embedded in products that can navigate complex business logic instead of answering in vague generalities.
The Retrieval Wars: Vector RAG vs. GraphRAG
As enterprises recognize the dangers of feeding raw data directly to LLMs, the industry has widely adopted Retrieval-Augmented Generation (RAG). RAG systems attempt to ground AI responses by retrieving task-relevant data snippets from a proprietary database and injecting them into the LLM's context window just before the generation phase.
The default approach for the past several years has been Vector RAG. While an excellent starting point, Vector RAG frequently breaks down under the weight of enterprise complexity, necessitating the evolution toward GraphRAG.
The Limitations of Vector Semantics
In a standard Vector RAG pipeline, enterprise documents are broken down into smaller, arbitrary "chunks." An embedding model mathematically maps these chunks into high-dimensional vectors. When an AI agent submits a query, the system retrieves the text chunks that are geometrically closest in semantic similarity.
However, Vector RAG inherently fails when confronted with relational complexity. The initial chunking process destroys the structural integrity of the original documents, severing the explicit relationships between entities. Crucially, Vector RAG fails spectacularly at multi-hop reasoning and schema-bound queries. In rigorous industry benchmarks evaluating schema-bound queries like Key Performance Indicators (KPIs) and financial forecasts, Vector RAG scored a catastrophic 0% accuracy rate.
The GraphRAG Advantage
Graph Retrieval-Augmented Generation (GraphRAG) addresses these flaws by integrating structured knowledge graphs directly into the retrieval pipeline. Instead of relying solely on mathematical proximity, GraphRAG extracts entities and relationships from the enterprise corpus, stores them in a graph database, and utilizes explicit graph traversal during the query phase.
This architecture provides a robust computation layer on top of semantic search. GraphRAG navigates explicit edges to group, filter, and accurately count entities across the full dataset before passing the aggregated, fact-checked context to the LLM for final generation.
By deploying GraphRAG, organizations ensure that their AI agents receive deterministic constraints. The inherent transparency of navigating explicit nodes and edges makes it vastly easier for engineers to debug the system and build necessary institutional trust in the AI's output. That level of discipline is also what keeps Shadow AI risks in check, because sanctioned systems can show exactly which governed data a model used to answer a question.
Agentic Knowledge Graphs: Eliminating Semantic Drift
The shift from simple generative chatbots to autonomous, agentic AI introduces a new requirement: continuous, multi-step collaboration. AI agents are increasingly deployed in "multi-agent systems" where specialized bots collaborate to solve complex enterprise problems without human intervention.
Agentic Knowledge Graphs solve standard text-based "semantic drift" by transforming the graph from a static ontology into a living reasoning snapshot. When a Risk Agent detects an anomaly, it generates a context-specific, ephemeral subgraph—a structured mathematical representation of the disruption and affected nodes. Downstream agents receive this explicit structural data, bypass human language interpretation entirely, and instantly attach probability weights directly to the subgraph, turning the knowledge graph into a shared mathematical language.
Industry-Specific AI Agent Transformations
The transformative power of knowledge graph-backed reasoning and stringent data governance is currently reshaping operational realities across numerous B2B sectors. When the data infrastructure is clean and properly mapped, AI agents cease to be mere novelties and become core drivers of business value.
Finance, Real Estate, and Mortgage Operations
The real estate and mortgage finance industries suffer from vast operational bottlenecks due to their heavy reliance on unstructured paperwork. For instance, the Cotality Payoff Analysis Agent acts as an autonomous generative AI assistant designed specifically for mortgage lenders. Grounded by highly structured data extraction algorithms, the agent autonomously identifies and extracts relevant financial data points from spreadsheets, applies modeling assumptions outlined in a plain-language prompt, and computes exact financial metrics to drastically improve customer retention.
Healthcare and Clinical Workflows
Healthcare data is notoriously complex, heavily regulated, and deeply siloed. Supported by rigorous data governance frameworks and knowledge graph overlays that map medical ontologies, healthcare agents can now securely tap into real-time patient data streams. This infrastructure allows providers to autonomously analyze daily lifestyle habits, safely cross-reference contraindications using explicit semantic relationships, and suggest precise dosage adjustments to clinicians while maintaining strict HIPAA compliance.
Telecommunications and High-Tech Advertising
In highly dynamic environments like telecommunications and enterprise advertising, understanding data lineage is critical for both regulatory compliance and operational speed. Companies like Quollio Technologies are utilizing knowledge graphs to model massive enterprise metadata sets as a connected semantic layer. Instead of exposing highly sensitive, raw telecom records directly to an LLM, Quollio's AI agents operate strictly over the metadata graph. This allows business users to autonomously trace data lineage and verify compliance status using natural language without ever breaching security protocols.
The Financial ROI of Governed AI Infrastructure
The business case for treating data governance and knowledge graph construction as core infrastructure is emphatically validated by emerging economic metrics. Organizations with successful AI initiatives invest up to four times more heavily in their underlying data foundations than those that experience poor AI outcomes.
The financial mandate to fix this infrastructure is reflected in global budget shifts. According to Gartner, worldwide AI spending will reach $2.5 trillion by 2026, but the most explosive growth is happening at the foundation: spending specifically on "AI Data" is projected to increase by nearly 277% year-over-year as enterprises scramble to build AI-ready architectures.
These statistics reveal a critical truth: productivity does not rise because employees are working longer hours; it rises because governed AI agents are systematically stripping away the friction of manual data processing. When you stop “renting” generic intelligence and instead invest in data infrastructure built around your own workflows and knowledge graphs, you protect margins and create durable competitive advantage.
The Data Readiness Playbook: Steps to Clean Your Data
Recognizing the need for structured data is only the first step. Executing an enterprise-wide transformation requires a rigorous operational playbook. Before an enterprise can safely hand the keys over to an autonomous AI agent, it must implement a comprehensive data cleansing and readiness strategy.
Implementing these structured layers often requires specialized custom software development and agile application management. Organizations leveraging tailored technological advantages frequently deploy modern infrastructures utilizing Azure DevOps On-Prem for continuous integration, Postgres and SQL Server for robust relational foundations, and Kubernetes and Docker orchestrated via Rancher and Harvester HCI for scalable, containerized microservices.
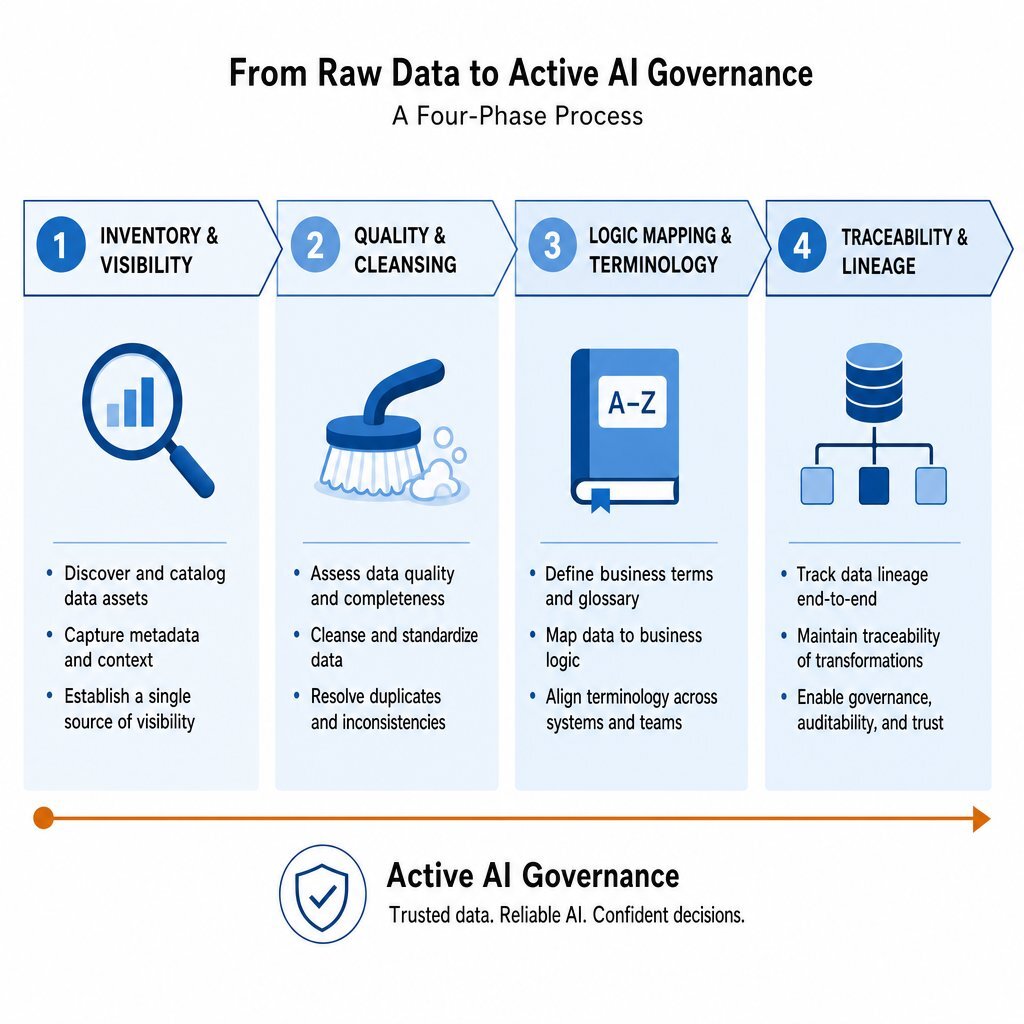
The critical steps for executing data remediation and infrastructure modernization are as follows:
- Phase 1 - Inventory & Visibility: Create an exhaustive catalog of all enterprise data sources, define clear data owners, and write semantic descriptions understandable to both humans and AI.
- Phase 2 - Quality & Cleansing: Execute baseline data cleansing by standardizing universally (e.g., YYYY-MM-DD formats) and implementing programmatic strategies for missing fields.
- Phase 3 - Logic Mapping & Terminology: Create a unified business glossary and translate enterprise logic into the explicit ontological schema that will govern the knowledge graph.
- Phase 4 - Traceability & Lineage: Ensure that metadata tagging and lineage tracking are standard architectural practices to allow continuous output verification.
Many teams pair this with a clear AI readiness checklist so that infrastructure, security, and people practices mature together. A structured CTO AI readiness checklist helps align data work, governance, and deployment plans into a single transformation roadmap instead of scattered one-off projects.
Active AI Governance: The Non-Negotiable Layer
The final and most crucial component of this infrastructure is establishing robust governance. In the era of agentic AI, governance must evolve into an active, centralized infrastructure layer that provides real-time runtime controls and dynamic policy enforcement.
The rapid adoption of predictive and agentic AI has vastly outpaced traditional Governance, Risk, and Compliance (GRC) structures. Because autonomous agents can execute actions and manipulate enterprise data at microsecond speeds, manual human oversight of every transaction is no longer feasible. The emergence of the EU AI Act and other global regulations is expected to drive AI compliance spending toward $1B by 2030, highlighting the financial severity of this requirement.
Leading organizations are aligning their new governance infrastructures with standardized frameworks, such as the NIST AI Risk Management Framework (RMF), which breaks governance down into core actionable pillars: Govern, Map, Measure, and Manage. By shifting to an infrastructure model, AI governance platforms provide the necessary centralized inventory, automated policy enforcement, and evidentiary reporting required to manage AI at enterprise scale. Securing this perimeter requires robust networking and server management, often utilizing tools like pfSense and OVHCloud servers, integrated with seamless collaboration environments like Microsoft 365 and Teams.
In parallel, engineering leaders are rethinking how they approve and monitor AI-generated code inside these governed environments. Adopting a seven-stage AI code approval framework helps regulated enterprises combine NIST-style governance with OWASP-grade security controls so that automation never outpaces safety.
As industry analysts have explicitly warned, without absolute trust in the underlying data, the outputs of the models, and the decision-making logic of the agents, an enterprise will derive zero sustainable value from artificial intelligence.
Conclusion
The deployment of autonomous B2B workflows is not primarily an exercise in adopting the latest, most sophisticated Large Language Model. It is an exercise in profound data discipline. AI agents are highly advanced engines, but they cannot manufacture facts from chaos. When connected to raw data lakes or unstructured ERP systems, models will inevitably succumb to the limitations of semantic ambiguity, resulting in costly, high-risk hallucinations.
By recognizing data governance as a fundamental prerequisite infrastructure layer, enterprises can bridge the wide gap between AI experimentation and scaled, secure production. Transitioning from the stateless, context-blind retrieval of basic Vector RAG systems to the deterministic, multi-hop reasoning capabilities of structured Knowledge Graphs provides AI agents with the explicit logic required to perform complex tasks accurately.
Before handing over the keys to autonomous systems, organizations must ruthlessly inventory their data, enforce rigorous quality standards, explicitly map their business logic, and embed continuous, trust-based governance controls into their workflows. For enterprises lacking the internal bandwidth to execute this overhaul, partnering with specialists in custom software development, DevOps efficiency, and application management—like Baytech Consulting—provides the tailored tech advantage and rapid agile deployment necessary to build a resilient data foundation. Only through this disciplined architectural approach can businesses unlock the exponential productivity, operational efficiency, and massive ROI promised by the AI revolution.
Recommended Reading
- Cost of poor data quality
- https://www.informatica.com/blogs/the-surprising-reason-most-ai-projects-fail-and-how-to-avoid-it-at-your-enterprise.html
- https://www.meilisearch.com/blog/graph-rag-vs-vector-rag
Frequently Asked Questions
Why do out-of-the-box AI agents confidently hallucinate when connected to standard ERPs? AI agents hallucinate when connected to standard ERPs because ERP systems are designed as rigid relational databases optimized for transactional recording, not for semantic reasoning. They lack explicit business context. When an AI accesses this raw data, it encounters missing business logic, unlinked data silos across tables, and security governance blocks (such as restricted database ports or IP blocking). Unable to verify the complete picture or retrieve necessary cross-departmental rules, the probabilistic nature of the LLM forces it to guess and fabricate an answer to fulfill its prompt, resulting in a highly confident hallucination. To prevent this, many enterprises pair ERP integrations with governed agentic workflows that sit on top of richer semantic layers instead of raw tables.
How does a Knowledge Graph fundamentally improve an AI agent's reasoning capabilities? A Knowledge Graph improves reasoning by providing a structured, deterministic computation layer on top of raw enterprise data. Unlike standard vector databases that only search for semantic text chunk similarities (and often destroy document context), knowledge graphs explicitly model real-world entities and the exact relationships between them using nodes and directional edges. This semantic structure allows the AI agent to perform multi-hop reasoning—tracing the logical path from a customer to a policy, to a transaction—and accurately execute schema-bound queries like counting, grouping, and aggregating data before generating a response, thereby drastically reducing hallucinations and eliminating semantic drift. When combined with clear metrics frameworks like those in modern developer productivity measurement, leaders can also see, in hard numbers, how better reasoning translates into real business value.
What steps must a company take to clean its data before handing the keys to an AI? Before deploying AI agents, a company must execute a rigorous data readiness playbook. This begins with Phase 1: Inventory, conducting a full cataloging of data assets to gain visibility into all data sources and assigning clear ownership. Next, Phase 2: Cleansing requires standardizing data formats (e.g., universal date formats), handling missing values, and removing duplicate records. Phase 3: Logic Mapping involves explicitly documenting business terminology so the AI understands internal definitions, translating that logic into a knowledge graph ontology. Finally, Phase 4: Traceability and Governance requires implementing active data governance as an infrastructure layer—establishing continuous monitoring, setting clear data access controls, tracking data lineage for auditability, and assigning explicit accountability for AI risk management using frameworks like the NIST AI RMF. Treating this work as part of a broader technical-debt and AI-risk strategy keeps your new automation from turning into tomorrow’s maintenance time bomb.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.