
When to Move Off Zapier: Cost, Limits, and Compliance
March 18, 2026 / Bryan Reynolds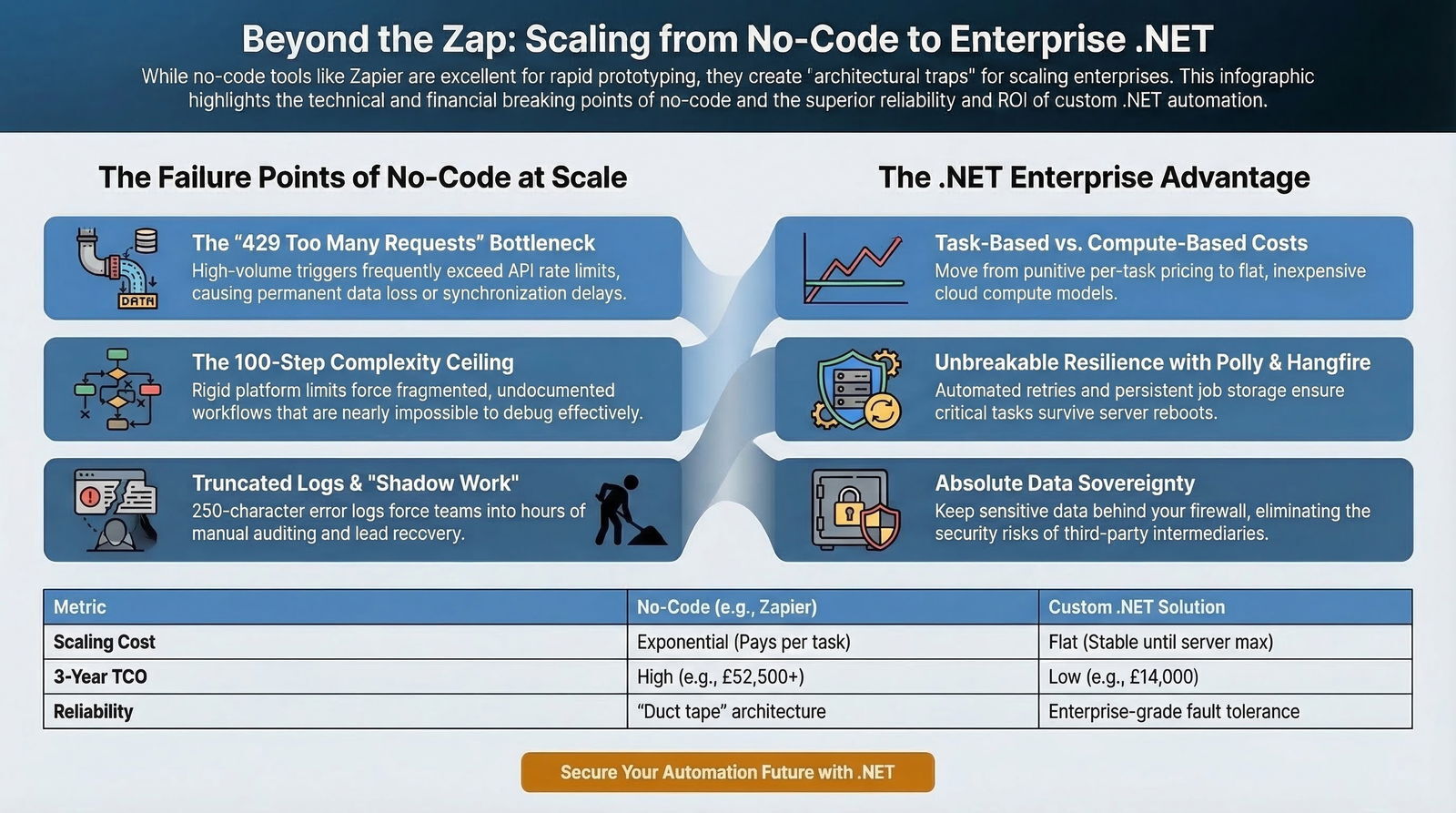
The Adult Solution for Critical Processes: When to Move Off Zapier and Scale with Custom.NET Automation
The modern B2B enterprise operates on a complex, continuously expanding web of interconnected applications. In the relentless pursuit of agility and digital transformation, organizations frequently turn to no-code automation platforms like Zapier, Make.com, or Activepieces to bridge the operational gaps between disparate software systems. These platforms have fundamentally democratized software integration. They are undeniably powerful tools for rapid prototyping, enabling marketing directors to route leads, sales operations teams to sync customer records, and human resources departments to automate onboarding flows without ever waiting for an overburdened IT department to provision resources.
For a fast-growing startup or a mid-market firm taking its first steps into workflow optimization, a visual, drag-and-drop interface feels like magic. It provides the immediate gratification of connecting a Google Form to a Slack channel or migrating basic rows into a Customer Relationship Management (CRM) system within minutes.
However, as organizations scale—particularly B2B firms operating in high-volume, data-intensive industries such as advertising, gaming, real estate, finance, enterprise software, and healthcare—the initial convenience of these no-code solutions often degrades. What begins as a nimble operational shortcut rapidly transforms into a fragile, expensive, and unmanageable web of technical debt.
The critical inquiry emerging from boardrooms and engineering departments alike is precise and urgent: Why are these early, highly celebrated no-code automations suddenly failing under the weight of enterprise scale, and when is the exact right moment to graduate to a robust, custom-coded solution?
For visionary Chief Technology Officers (CTOs) trying to manage technical debt, strategic Chief Financial Officers (CFOs) auditing skyrocketing operational expenses, and operational leaders desperate for data reliability, the answer lies in understanding the architectural boundaries of consumer-grade automation. This exhaustive research report explores the strict operational limits of no-code platforms, unpacks the hidden financial drain of usage-based billing models, and comprehensively details the architectural superiority of hard-coded, enterprise-grade .NET services. By analyzing total cost of ownership (TCO) metrics, scalability thresholds, and modern integration patterns, this analysis provides the definitive roadmap for transitioning from fragile, visual "glue" to robust, autonomous, and mission-critical automation infrastructure.
The Breaking Point: Anatomy of a Failing No-Code Automation
No-code automation platforms are inherently optimized for linear, highly standardized, and relatively low-volume processes. They excel at simple, straightforward triggers and actions, such as capturing an email lead and depositing it into a database.
However, authentic business logic in a mature enterprise is rarely linear. As operational complexity naturally grows, these automations are suddenly forced to handle deeply nested conditional logic, extensive data formatting and parsing, complex array iterations, and synchronized updates across multiple legacy systems.
It is precisely at this intersection of high transaction volume and high logical complexity that platforms like Zapier begin to physically and operationally fracture.
The Illusion of Infinite Scalability and the API Rate Limit Crisis
One of the most critical reasons no-code automations fail at scale is their inherent vulnerability to Application Programming Interface (API) rate limiting. Rate limiting is a standard network security and traffic management technique that controls the flow of requests to an API within specific time windows.
Whether utilizing token buckets, leaky buckets, sliding windows, or fixed windows, APIs cap the number of requests a client can make to prevent resource exhaustion, ensure fair usage among all tenants, and defend against malicious denial-of-service attacks.
When a B2B firm experiences a sudden, massive surge in operational data—for example, a real estate mortgage firm bulk-updating 10,000 property financial records, an advertising agency processing a massive influx of daily campaign conversion metrics, or an educational institution bulk-enrolling students into a Learning Management System—the no-code platform attempts to process these events as rapidly as possible. If the destination application's API possesses strict administrative rate limits, this rapid succession of automated requests will immediately trigger 429 Too Many Requests HTTP status code errors.
In a traditional, custom-coded software environment, experienced developers anticipate 429 errors as a normal cost of doing business and proactively implement sophisticated message queuing and exponential backoff strategies to handle them gracefully. In a platform like Zapier, the handling of these errors is catastrophically rigid. While Zapier imposes its own throttling to try and space out requests, sustained errors have severe consequences. If 95% of a specific Zap's runs encounter an error response status code within a 7-day window, Zapier's internal safeguards will automatically assign a “Stopped / Errored” status to the workflow and turn the Zap off completely.
The automation will not run again until a human operator receives an email alert, manually logs into the platform, troubleshoots the underlying API rejection, and manually re-enables the workflow. For a mission-critical financial transaction pipeline or a healthcare platform synchronizing sensitive patient data, this silent failure and subsequent suspension represent an unacceptable, revenue-threatening operational risk.
The Complexity Ceiling: Step Limits and Fragmented Logic
Beyond network limitations, Zapier imposes strict, hard-coded structural limitations on the workflows themselves. A single Zap is restricted to an absolute maximum of 100 steps, which includes all nested steps within any conditional routing paths.
Furthermore, Zapier permits up to only 10 branches per path and limits overall nesting to three path steps per Zap.
When business logic dictates processing a large array of items—such as iterating through a complex JSON payload of newly enrolled students, evaluating their previous coursework, and assigning distinct, highly customized curriculum paths based on a dozen different business rules—users are frequently forced to string together multiple, fragmented Zaps to bypass the platform's limits. This forced fragmentation completely obscures the overall process flow, making it nearly impossible for engineering teams to visually debug or trace data lineage.
What should have been a unified, cleanly coded business process devolves into a labyrinth of interconnected scripts, artificial delay modules, and convoluted conditional paths. While competing platforms like Make.com offer slightly more visual control and support iteration better than Zapier, they still rely heavily on independent module processing, which scales poorly and becomes visually incomprehensible when handling thousands of concurrent data points across dozens of branches.
The Latency Tax and Real-Time Degradation
Performance latency is a critical operational metric for real-time digital systems, such as programmatic advertising bidding, live financial trading platforms, or rapid-response customer support ticketing. Latency measures the time delay between a network action and the system's actual response, representing the total network travel time and server processing time.
In a no-code ecosystem, data must travel from the origin application's servers, across the internet to Zapier's processing servers, undergo formatting and logic checks, and then be transmitted outward to the destination application.
This introduces multiple, unavoidable network hops. Furthermore, Zapier heavily utilizes polling triggers for many of its integrations. Polling means the platform actively checks the origin app for new data on a fixed schedule—typically every 1 to 15 minutes, depending strictly on the user's paid pricing tier.
This polling mechanism fundamentally negates any true real-time processing capabilities.
While instant triggers—known as webhooks, which push data to a receiving application immediately when an event occurs—reduce this delay and minimize server load, the no-code platform still throttles high-frequency webhooks. If an advertising platform fires 5,000 webhooks in a single minute to a Zapier endpoint, the platform will rate-limit the intake, queuing or dropping payloads, rendering it entirely unsuitable for high-throughput enterprise data pipelines.

The Hidden Financial Drain: Analyzing Total Cost of Ownership (TCO)
The primary argument for adopting no-code automation frequently centers on dramatically lower upfront costs, reduced reliance on expensive engineering talent, and remarkably rapid time-to-market. For prototyping Minimum Viable Products (MVPs) or automating localized departmental tasks, no-code solutions can successfully cut traditional development expenses by 30% to 70% and reduce initial pipeline development time by up to 90%, transforming deployment timelines from months to mere days.
However, a strategic CTO or CFO's fiduciary responsibility extends far beyond the initial, celebratory software build phase. When evaluating enterprise infrastructure, the only valid financial model is Total Cost of Ownership (TCO), which meticulously accounts for all direct licensing, computational, and indirect maintenance costs over a three-to-five-year operational lifecycle. It is within this long-term TCO analysis that the financial viability of no-code platforms at scale completely disintegrates.
The Punishment of Usage-Based Task Pricing
Zapier and many of its direct competitors utilize an execution-based or task-based pricing model. A "task" is actively consumed every single time an action step is successfully performed by a workflow.
The entry-level tiers appear highly accessible: Zapier’s Free plan offers a mere 100 tasks per month, while the Professional plan begins at $29.99 for 750 tasks, and the Team plan costs $103.50 for 2,000 tasks.
At an enterprise scale, these task allotments are practically invisible. Consider a B2B Software-as-a-Service (SaaS) company managing a conservative 100,000 daily user interaction events—such as application logins, user profile updates, and core feature usage. If a marketing automation requires just three logical steps (e.g., catching a webhook, formatting the incoming data payload, and updating a CRM record), processing 100,000 events daily consumes 300,000 tasks per day. This equates to roughly 9 million tasks per month. On Zapier, exceeding 1 million tasks per month pushes an organization deep into opaque Custom Enterprise Pricing tiers, where annual subscription contracts can easily exceed tens of thousands of dollars for simple data routing.
Competing platforms like Make.com utilize pricing models that are similarly deceptive for highly complex workflows. While Make often appears cheaper on its surface, the platform charges computational credits for every single step executed in a workflow scenario, explicitly including data routing paths, iteration loops through arrays, and even scheduled polling operations that return zero new data.
A single, complex data transformation script that iterates through a large JSON dataset can easily consume 12 to 15 internal operations per single execution.
| Cost Factor | No-Code Automation (Zapier/Make) | Custom.NET Automation (Azure/AWS) |
|---|---|---|
| Initial Build Cost | Low (10,000 - 50,000) | High (100,000 - 250,000+) |
| Deployment Speed | Extremely Fast (Days/Weeks) | Moderate (Months) |
| Operational Scaling Cost | Exponential (Priced per logical task/step) | Flat/Linear (Priced purely by raw compute CPU/RAM) |
| Iteration/Looping Cost | High (Every array item processed costs tasks) | Negligible (Standard code execution loops) |
| Polling/Checking Cost | Charged regardless of new data found | Free (Internal server cron jobs/timers) |
| Long-Term TCO (High Volume) | Prohibitively expensive due to task limits | Highly cost-efficient return on investment |
The Economics of Custom Development Compute
Conversely, traditional custom software development requires a significantly higher upfront capital expenditure (CapEx)—typically ranging from $20,000 for simple internal tools to well over $250,000 depending on the architectural scope and integrations required.
However, once deployed, custom software operates on a dramatically lower and highly predictable operational expenditure (OpEx) curve.
Hosting a custom-coded .NET worker service on modern cloud infrastructure is remarkably cost-efficient. The Microsoft Azure App Service, a fully managed Platform as a Service (PaaS), allows developers to build, deploy, and automatically scale .NET web apps, background workers, and APIs without managing underlying operating systems.
A Standard plan, designed specifically for running reliable production workloads on dedicated Virtual Machine instances, costs approximately $73 per month, while a Premium plan for enhanced, high-throughput performance costs roughly $146 per month. Alternative cloud providers like Google Cloud Run or AWS Lambda offer similar, highly optimized pay-per-compute execution models.
In a custom-hosted environment, processing 1 million data tasks per month incurs virtually negligible cloud compute costs. The enterprise pays exactly for the raw processing power utilized—the CPU cycles and RAM footprint—not an arbitrary, vendor-imposed markup attached to every logical step or data transformation.
Real-world financial data consistently confirms this inversion of cost at scale. One documented case study revealed a manufacturing business that was paying a staggering £17,500 annually in subscription fees for a single, high-volume Zapier workflow. A strategic decision to migrate to a custom solution cost £8,000 in upfront development and only £2,000 in yearly cloud maintenance, yielding a massive, immediate long-term ROI.
Another detailed technical analysis revealed that migrating heavily looped data transformation workflows—specifically generating large volumes of emails with AI and pushing them to spreadsheets—from per-task models to execution-based custom compute dropped monthly operational costs from 180 per workflow to just 23. For high-volume, continuously running operations, custom solutions definitively prove substantially cheaper over the three-to-five-year platform lifecycle.
The "Adult" Solution: The Unmatched Benefits of Custom-Coded .NET Automation
When forward-thinking organizations inevitably reach the absolute technical and financial limitations of Zapier and its competitors, the necessary strategic pivot is toward enterprise-grade, custom-coded software. For over two decades, Microsoft's .NET framework—specifically utilizing the C# programming language—has served as the undisputed, rock-solid backbone of secure, scalable, and highly performant enterprise architecture globally. For many firms, this is also when they start thinking seriously about an AI-native SDLC and long-term engineering governance, not just quick fixes.
Building custom .NET services is widely considered the "adult" solution by veteran engineering leaders because it fundamentally shifts the operational paradigm from merely "connecting consumer apps with digital duct tape" to actively engineering resilient, autonomous, and proprietary business systems.
Maximum Control, Bespoke Architecture, and Unfettered Performance
Unlike black-box no-code platforms where the underlying computational mechanics are entirely hidden and unalterable, custom .NET development provides an organization with absolute, maximum control over system architecture, processing performance, user interface design, and deep security.
Developers write highly optimized, compiled code that interacts directly with databases and target APIs, completely eliminating the sluggish middleman overhead inherent to third-party integration platforms. This is especially powerful when paired with a strategic .NET-based AI tech stack that aligns with existing Microsoft infrastructure and security practices.
The extensive Microsoft ecosystem provides native, deeply embedded integrations with enterprise staples such as Active Directory for identity management, robust SQL Server databases, Microsoft 365, and the entire suite of Azure cloud services.
Enterprises already utilizing these technologies do not need to rely on potentially vulnerable third-party adapters or fragile Zapier connections; they can leverage native software development kits (SDKs) that guarantee data integrity, speed, and strict corporate compliance.
Robust Resilience, Fault Handling, and Intelligent Retries
The starkest, most critical contrast between a consumer-grade Zapier workflow and a professional custom .NET application lies in how the respective systems handle inevitable failure. In Zapier, a failed task—due to a temporary network blip or an API timeout—still counts toward the organization's monthly billing quota and frequently results in a completely stalled workflow that demands immediate human attention.
In a properly architected .NET environment, developers actively anticipate network instability and utilize industry-standard resilience libraries to guarantee continuous execution.
Polly for Transient Fault Handling: Polly is an extraordinarily comprehensive fault-handling and resilience library specifically designed for .NET applications.
It allows engineers to elegantly express complex resilience policies such as Retry, Circuit Breaker, Timeout, Bulkhead Isolation, and Fallback in a highly fluent, thread-safe manner.
When a third-party API becomes temporarily unresponsive, a fragile no-code script simply crashes. In contrast, a custom .NET service leveraging Polly intelligently applies the Circuit Breaker pattern. Rather than hammering a failing endpoint and exacerbating a wider system outage, the circuit "breaks," pausing all outgoing requests to allow the external application time to recover. Once stability is mathematically detected, Polly seamlessly resumes operations, utilizing sophisticated exponential backoff—waiting two seconds, then four, then eight—to ensure zero data loss and absolutely no human intervention.
Hangfire for Background Processing: For complex workflows requiring precise scheduling, delayed execution, or heavy background processing, Hangfire stands as the premier .NET library.
It allows enterprise applications to efficiently offload time-consuming, non-blocking tasks to dedicated background processing threads, drastically improving the responsiveness of user-facing applications. Hangfire natively supports recurring jobs, delayed logic, and fire-and-forget tasks, all backed by highly reliable persistent storage (such as SQL Server or Postgres) to guarantee that critical jobs survive unexpected server restarts or deployments.
MassTransit for Distributed Systems: For massive, multi-step workflows spanning several different microservices or applications, MassTransit provides a developer-focused platform that abstracts complex messaging queues (such as RabbitMQ, Azure Service Bus, or Amazon SQS).
Crucially, MassTransit allows developers to implement the sophisticated Saga design pattern for managing distributed transactions.
Instead of relying on a brittle, linear 100-step Zap, a complex workflow is elegantly broken down into independent, event-driven micro-services. If a transaction successfully passes through 46 stages but encounters a failure at step 47, the data payload remains safely preserved in the persistent message queue. When the issue is resolved, the system seamlessly picks up the work at step 47, completely bypassing the need to redundantly restart the entire workflow from step one.
Superior Observability, Logging, and Auditing
When a Zap inevitably fails, operational teams are frequently presented with entirely generic, unhelpful error messages—such as "Provided data is invalid"—leaving engineers to blindly guess the root cause of the data rejection.
Compounding this frustration, Zapier aggressively truncates all error messages returned from third-party integrations at a maximum of 250 characters, severely limiting the debugging context required to fix complex data mapping issues.
Custom .NET applications entirely eliminate this crippling operational blindness. By integrating powerful diagnostic libraries like Serilog for highly structured application logging and Seq for visual, real-time log analysis, engineering teams gain microscopic, surgical visibility into the heartbeat of the system.
Serilog is remarkably efficient, capable of executing over 285,000 discrete logging operations per second—significantly outperforming legacy frameworks.
It captures the exact, pristine state of the application, the full JSON payload, and the complete stack trace of any error. This rich data is automatically fed into centralized observability dashboards, empowering IT operations teams to proactively identify and resolve data anomalies long before they manifest as critical business interruptions.
Engineering Enterprise Automation: The Baytech Consulting Advantage
Transitioning an entire organization's critical operations from a visual no-code environment to a robust, custom-coded infrastructure is not a trivial undertaking; it requires specialized, highly experienced engineering talent. Baytech Consulting specializes specifically in custom software development and comprehensive application management, providing the exact Tailored Tech Advantage necessary to execute this digital transition flawlessly.
Rather than relying on the rigid constraints of consumer-grade visual builders, Baytech leverages highly skilled, enterprise-focused engineers to construct bespoke, data-grade pipelines utilizing a cutting-edge modern tech stack. By rigorously utilizing Azure DevOps On-Prem for strict version control, continuous integration, and continuous deployment (CI/CD) pipelines, Baytech ensures that all proprietary automation code is inherently testable, fully auditable, and easily deployable with zero downtime.
For many clients, this is also the moment to pair modern automation with AI-powered development practices, so they can speed up delivery without sacrificing quality or control.
Furthermore, Baytech’s deep expertise in modern, scalable infrastructure allows for highly resilient enterprise deployments. By containerizing C#.NET worker services with Docker and elegantly orchestrating them via Kubernetes, these custom applications can dynamically and automatically scale compute resources to handle massive, unforeseen data influxes without a corresponding, punitive spike in monthly SaaS billing.
For organizations actively seeking to modernize and simplify their data centers through hyper-converged infrastructure (HCI), Baytech excels at managing these complex workloads utilizing Rancher deployed on Harvester HCI. Harvester, built on open-source cloud-native technology, elegantly consolidates both legacy virtual machines and modern containerized applications into a single, highly efficient management stack.
This approach drastically reduces the physical footprint of data centers, streamlines administrative overhead, and lowers the total cost of ownership, whether deployed on specialized OVHCloud servers or secured behind robust pfSense firewalls. Backed by the unmatched transactional stability of Postgres and Microsoft SQL Server databases, these tailored solutions provide the ultimate, future-proof foundation for reliable, highly performant, data-driven automation.
The Shadow IT Crisis, Security, and Governance
The rapid, unchecked proliferation of no-code tools over the last decade has undeniably democratized software development, empowering "citizen developers"—marketing managers, sales operations specialists, and human resources representatives—to actively build their own digital tools and integrations without knowing a single line of code.
While initially heralded as an empowering shift in corporate agility, this unchecked decentralization inevitably breeds a severe, systemic risk known as "Shadow IT." Shadow IT refers to information technology systems, software, and integrations deployed and actively utilized inside organizations without explicit approval, security review, or ongoing oversight from the central IT department.
When well-meaning business users construct mission-critical revenue workflows in Zapier or Make.com—often utilizing personal or unmonitored departmental accounts—the wider organization completely loses governance over its own data architecture.
This loss of control manifests in several highly destructive ways:
- The Absence of Version Control and Rollbacks: Visual no-code platforms fundamentally lack traditional, robust Git-based version control systems. If an employee accidentally modifies a core routing logic step, deletes a critical data mapping field, or introduces a fatal error into a Zap, rolling the system back to a previous, perfectly functioning state is exceedingly difficult, if not entirely impossible.
- Severe Turnover Risk and Knowledge Silos: If the specific operations manager who meticulously built and maintains the complex, undocumented web of hundreds of interconnected Zaps leaves the company, the organization is abruptly left with an opaque, highly fragile system of logic that no remaining employee understands or knows how to safely modify.
Integration Bloat and Exponential Technical Debt: Because Zapier relies entirely on a vast library of pre-built, third-party connectors, any unexpected updates, deprecations, or version changes to those underlying external APIs can instantly, silently break existing workflows.
The technical debt associated with manually maintaining, monitoring, and constantly troubleshooting hundreds of individual, fragile API connections through a third-party graphical user interface is exponential, creating a massive maintenance burden that drains operational resources.
- Security, Compliance, and Data Sovereignty Risks: In highly regulated industries such as healthcare, financial services, and enterprise software, strict data privacy is paramount. While Zapier works diligently to maintain SOC 2 Type II and GDPR compliance, routing highly sensitive Protected Health Information (PHI), financial ledgers, or Personally Identifiable Information (PII) through a third-party, multi-tenant public automation platform introduces unnecessary, critical attack vectors. It also severely complicates strict corporate data residency and sovereignty requirements.
Custom .NET development provides the ultimate antidote to the Shadow IT crisis. By intentionally consolidating all critical workflows into centralized, professionally engineered custom .NET services, the IT department instantly regains absolute control over the data pipeline. All proprietary code is securely stored in centralized repositories like Azure DevOps, subjected to rigorous mandatory peer review, secured by modern Identity-Centric and Zero-Trust network principles, and deployed systematically through automated pipelines.
Furthermore, custom code ensures that proprietary matching algorithms and sensitive customer data remain strictly within the organization's own highly secure, controlled perimeters, never needlessly exposed to external public integration platforms. This comprehensive governance approach transforms automation from a fragile operational liability into a highly sustainable, auditable, and secure corporate asset. It also sets the stage for safer AI use by aligning with a 90/10 Human-in-the-Loop trust architecture, where humans stay in control of the most sensitive decisions.
The Decision Matrix: When Exactly Should an Organization Move Off Zapier?
Recognizing the exact, optimal moment to deprecate a visual no-code system in favor of investing in custom software development is a critical strategic imperative for technology leaders. Waiting too long results in massive operational failures and runaway subscription costs; moving too early wastes valuable engineering resources on tasks that don't yet require scale.
The empirical data indicates that organizations must decisively initiate the migration to custom .NET services when their operations trigger one or more of the following critical conditions:
| Migration Trigger | Indicator for No-Code (Zapier/Make) | Indicator for Custom.NET Code |
|---|---|---|
| Transaction Volume | Low to Moderate (Under 10,000 tasks/month). | High Frequency (Over 100,000 tasks/month); live streaming data processing. |
| Business Logic Complexity | Linear workflows; simple A-to-B data transfers; basic standard conditional routing. | Complex proprietary algorithms; massive array iterations; distributed saga patterns requiring state management. |
| Data Sensitivity & Privacy | Public information or non-sensitive internal operational routing data. | Highly regulated data (HIPAA, SOC 2, PCI-DSS); strict international data residency and sovereignty needs. |
| Strategic Business Value | Internal operational efficiency improvements (e.g., Slack notifications, PTO tracking). | Core competitive differentiator; directly drives customer experience, product delivery, or revenue generation. |
| System Error Tolerance | Occasional missed records or dropped webhooks are acceptable; manual clean-up is feasible. | Zero-data-loss requirement; automated exponential retry, state recovery, and circuit breaking is absolutely mandatory. |
Ultimately, if an automated workflow directly touches your paying customers, differentiates your core product offering from industry competitors, continuously processes high-frequency real-time events, or securely handles sensitive compliance data, it unequivocally mandates the architectural rigor, security, and absolute reliability of custom code. At that point, layering in action-oriented AI agents on top of stable automation can drive even more value instead of adding chaos.
The Migration Playbook: Transitioning Safely from Zapier to Custom C#
The decision to migrate is only the first step; executing the transition without disrupting active business operations is the true challenge. Migrating deeply entrenched, complex multi-step Zaps to a modern, custom .NET architecture is rarely a straightforward, direct translation. Attempting a literal, one-to-one recreation of a visual Zap into C# code is a profound strategic error that merely ports bad habits into a new environment.
A migration must be viewed as a unique opportunity to fundamentally re-evaluate, aggressively optimize, and permanently fortify the organization's core business logic. The transition process, led by experienced software architects, must follow a rigorous, highly disciplined engineering methodology. Approaching this with mature Agile methodology and clear iteration cycles helps reduce risk and surface issues early.
Phase 1: Exhaustive Audit and Deep Discovery
The critical initial phase involves meticulously documenting every single existing Zap or Make.com scenario currently in production. Engineers must map the exact data flow, identify all hidden API calls, and accurately calculate the true transaction volumes.
Because a single visual, drag-and-drop step in a platform like Zapier often cleverly obscures multiple underlying API polling operations, authentication handshakes, and data parsing steps, software engineers must reverse-engineer and decode the true, raw computational requirement of the workflow before writing a single line of new code.
Phase 2: Architectural Redesign and Modeling
Rather than building fragile, linear scripts that mimic Zapier's constraints, software architects design highly decoupled, event-driven microservices. Utilizing modern C# and .NET Core frameworks, the engineering team explicitly defines the required data models, establishes robust Postgres or SQL Server relational schemas for permanent data storage, and carefully configures the message brokers (e.g., RabbitMQ or Azure Service Bus) that will route information between services.
This is the critical design phase where robust error handling via the Polly library and asynchronous background scheduling via Hangfire are permanently integrated into the foundational system design. It is also where a forward-looking data strategy—like enterprise data readiness for AI—can be baked in, so future AI features have clean, trusted data to work with.
Phase 3: Parallel Development, Integration, and Deployment
To ensure absolutely zero operational downtime during the transition, the new custom .NET services are methodically developed and subsequently deployed completely alongside the existing, legacy no-code workflows. Utilizing modern infrastructure deployment strategies—such as containerizing the applications with Docker and managing them via Kubernetes and Rancher—the new custom application is seamlessly scaled to match the exact requirements of the live production environment.
For many enterprises, this phase is also a good time to explore sidecar patterns that let them wrap legacy systems in new services without risky rewrites, gradually shifting traffic from no-code to robust microservices.
Phase 4: The Parallel Run and Final Cutover
The absolute most critical phase of the entire migration strategy is the "Parallel Run." For a designated testing period of 1 to 2 weeks, both the legacy Zapier workflow and the newly deployed .NET service actively process the exact same live data triggers simultaneously.
The outputs, logs, and performance metrics of the new custom system are meticulously tracked and mathematically compared against the legacy Zapier outputs to identify any minute data discrepancies, unhandled edge cases, or missing logic loops.
Only when the custom-coded system conclusively proves 100% data parity (alongside vastly superior processing performance and error handling) is the Zapier integration permanently, confidently disabled.
Conclusion
No-code platforms like Zapier and Make have permanently, irreversibly altered the landscape of digital business operations. They have accomplished the monumental task of granting non-technical teams the unprecedented power to automate highly routine administrative tasks and rapidly deploy minimum viable products without specialized training. However, despite aggressive marketing claims to the contrary, these visual platforms were never fundamentally designed, nor are they architecturally suited, to serve as the permanent, load-bearing infrastructure for scaling, enterprise-grade businesses.
When daily transaction volumes inevitably spike into the hundreds of thousands, when core business logic demands complex programmatic iteration, and when the escalating financial cost of usage-based task pricing begins to actively erode hard-earned corporate profit margins, clinging to no-code solutions transitions from a savvy operational shortcut into an exercise in severe diminishing returns. The largely invisible tax of compounding technical debt, the recurring operational nightmare of manual error resolution following API timeouts, and the dangerous lack of true version control collectively create an untenable, highly risky operational environment.
Hard-coded, professionally engineered .NET services represent the definitive, "adult" solution for managing an organization's most critical automated processes. By decisively leveraging the unmatched processing power of C#, the boundless scalability of Azure infrastructure, and the battle-tested reliability of enterprise-grade resilience libraries like Polly and Hangfire, organizations can build sovereign, highly observable, and infinitely scalable automation engines. While the initial capital investment in custom software development is undeniably higher than a monthly SaaS subscription, the perfectly flat, predictable operational costs, the ironclad data security, and the complete elimination of "Shadow IT" yield a vastly superior Total Cost of Ownership over the application's entire lifecycle.
For visionary B2B executives actively looking to outpace their competition and permanently future-proof their digital operations, the strategic mandate is exceptionally clear: meticulously identify the automations that represent your core competitive advantage, and definitively migrate them off fragile visual builders and into robust, custom-engineered code. From there, you can safely explore more advanced capabilities—like proactive AI replacing static dashboards or secure AI firewalls that protect your data—on top of a stable foundation.
Next Steps for Enterprise Leaders:
- Conduct an Immediate Automation Audit: Task your operations team with identifying all active workflows currently consuming over 10,000 to 50,000 tasks per month on platforms like Zapier or Make.com. Evaluate these specific workflows for strategic value and data sensitivity.
- Calculate True, Long-Term TCO: Aggressively model and compare your projected 3-to-5-year SaaS automation licensing costs against the CapEx of a one-time custom software build to find your organization's exact financial break-even point.
- Engage Engineering Experts: Partner with a deeply experienced firm like Baytech Consulting to meticulously architect a secure, scalable .NET transition plan that leverages modern container orchestration to permanently eliminate technical debt. If you are also evaluating broader AI and software strategy, their work on security, technical debt, and AI governance and enterprise application architecture can provide an additional layer of strategic clarity.
Further Reading:
- https://www.baytechconsulting.com/blog/strategic-guide-to-low-code-vs-custom-software-2025
- https://4spotconsulting.com/the-true-roi-of-zapier-quantifying-time-cost-and-strategic-value/
- https://medium.com/@bhargavkoya56/exception-handling-and-logging-in-net-a-complete-guide-to-building-resilient-applications-d688aa06215a
Frequently Asked Question
When should I move off Zapier?
You should definitively move off Zapier and aggressively invest in custom-coded .NET automation when your organization encounters any of the following four critical operational triggers:
- Severe Financial Drain: Your daily workflow volume expands, pushing your consumption past 10,000 to 50,000 tasks per month. At this precise scale, Zapier’s usage-based, per-task pricing model becomes exponentially and prohibitively more expensive than the flat, highly predictable operational cost of hosting a custom cloud service on AWS or Azure.
- Hitting Complexity Ceilings: Your core business logic matures and requires advanced programmatic array iterations, extensive data parsing, or deeply nested multi-step branching that vastly exceeds Zapier's strict 100-step limits. Furthermore, you require distributed transactions where a temporary API failure at step 50 doesn't force a complete, redundant restart of steps 1 through 49.
- The Need for Absolute Reliability and Error Handling: You process mission-critical, revenue-generating data that requires a strict zero-data-loss guarantee. Custom .NET code utilizes robust backoff-and-retry libraries (like Polly) to intelligently handle network blips, rather than relying on Zapier's rigid rate-limit handling, which can catastrophically suspend workflows entirely upon repeated API failures.
- Strict Security and Compliance Mandates: You are handling highly sensitive, strictly regulated data (such as HIPAA-compliant healthcare records or strict financial data) that demands absolute data residency. This proprietary data must remain within your secure network perimeter and cannot be safely or legally routed through third-party, multi-tenant public automation platforms.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.