
Security Risks of Auto-Generated Apps and How to Mitigate
May 15, 2026 / Bryan Reynolds
380,000 Vibe-Coded Apps Are Sitting on the Open Internet. Here's What Custom Development Actually Buys You.
In May 2026, the Israeli cybersecurity firm RedAccess disclosed a startling reality regarding the state of modern software deployment. Through routine subdomain enumeration and fingerprinting, researchers discovered that approximately 380,000 publicly accessible applications built entirely on "vibe-coding" platforms—specifically Lovable, Replit, Base44, and Netlify—were sitting fully exposed on the open web. Of those exposed assets, approximately 5,000 were actively leaking highly sensitive corporate and personal data, ranging from hospital medical records and clinical trial rosters to unredacted customer service conversations and internal financial documents.

Concurrently, a separate first-quarter 2026 security assessment conducted by GuardMint evaluated more than 200 vibe-coded applications and uncovered an even more systemic architectural crisis. The assessment determined that 91.5% of the tested applications contained at least one critical vulnerability directly traceable to an artificial intelligence hallucination or a fundamental lack of security context during the code generation process.
The marketing narrative surrounding prompt-to-app generation suggests that the era of traditional software engineering is ending, ostensibly replaced by natural language interfaces that allow non-technical builders to bypass the development pipeline entirely. The exposure of 380,000 applications proves that the code generation tools function exactly as advertised regarding speed and accessibility. However, the 91.5% vulnerability rate exposes the fatal flaw in the model. Artificial intelligence coding tools optimize for code that successfully executes, not code that safely operates within a hostile digital environment.
This dynamic provides the clearest answer to a question increasingly asked by executive boards, chief financial officers, and enterprise procurement teams: exactly what does a custom software development engagement purchase?
The answer is not simply a higher volume of code. Professional development purchases the architectural layers that prompt-to-app tools systematically skip. It buys comprehensive threat modeling, resilient authentication scaffolding, object-level authorization, rigorous secret handling, enforced row-level security, and strict input validation. Comparing the default output of a vibe-coded prototype against the hardened infrastructure delivered by a professional engineering team completely reframes the cost of custom development. It transitions from being viewed as a discretionary capital expense to a measurable insurance policy against an average shadow artificial intelligence data breach cost of $4.63 million.
The Anatomy of a Mass Exposure: What RedAccess Actually Found
To comprehend the specific failures of the vibe-coding paradigm, one must examine the precise data identified in the RedAccess discovery. The researchers did not utilize complex zero-day exploits or sophisticated network intrusions to access these 380,000 applications. They simply utilized standard subdomain enumeration on platform domains such as lovable.dev, base44.com, and bolt.new, combined with basic Shodan fingerprinting techniques.
Because these platforms optimize for immediate gratification and rapid sharing, they frequently default to public deployment. Non-technical users—ranging from marketing directors building quick campaign dashboards to finance teams automating quarterly reporting—deploy these applications without realizing they are instantly indexed by search engines and accessible to anyone with an internet connection.
The 5,000 applications found actively leaking data were not isolated edge cases or empty testing environments. They represented a cross-section of global enterprise activity. The severity of the RedAccess findings is compounded by the regulatory implications, as the exposure of unredacted healthcare records, personal communications, and financial datasets instantly triggers compliance violations under the Health Insurance Portability and Accountability Act (HIPAA), the General Data Protection Regulation (GDPR), and the Lei Geral de Proteção de Dados (LGPD).
| Data Category | Verified Examples from the RedAccess Exposure Scan |
|---|---|
| Financial Services | Internal financial projections and customer payment data belonging to a Brazilian bank. |
| Healthcare & Medical | Active clinical trial rosters in the UK; patient conversations at a children's long-term care facility; hospital doctor-patient summaries. |
| Logistics & Shipping | A major shipping company's application detailing highly sensitive vessel port schedules and expected cargo arrival times. |
| Retail & E-commerce | Full, unredacted customer service conversations and internal chat transcripts belonging to a British cabinet supplier. |
| Corporate Security | Incident response documents from a security company; internal corporate go-to-market strategy presentations; ad purchasing strategies. |
Furthermore, the lack of authentication defaults turned these platforms into engines for malicious activity. RedAccess researchers discovered active phishing sites built entirely on the Lovable platform, meticulously designed to impersonate major consumer brands including Bank of America, FedEx, Trader Joe's, and McDonald's.
The exposure of these applications is not a software bug in the traditional sense; it is a predictable feature of a development model that removes technical gatekeepers. As Dor Zvi, chief executive officer of RedAccess, articulated regarding the findings, non-technical users cannot reasonably be expected to understand complex cybersecurity architecture. Relying on an end-user to manually configure role-based access controls on a rapidly generated application guarantees widespread exposure.
The Hallucination Engine: Why Code Generators Fail Security Review

While the RedAccess findings highlight the dangers of public-by-default platform configurations, the GuardMint assessment points to a much deeper, systemic issue within the models themselves. Finding that 91.5% of tested applications contained vulnerabilities traceable to artificial intelligence hallucinations means that the underlying generation mechanism is fundamentally flawed from a security perspective.
The industry narrative frequently cites an older Veracode benchmark indicating that roughly 45% of generated code introduces security vulnerabilities, with specific languages like Java seeing failure rates as high as 72%. However, the reality in 2026 is far more severe when evaluating full-stack application generation rather than isolated code snippets. Large language models operate by predicting the most statistically probable sequence of tokens based on their training data. They optimize for creating code that resolves error messages and successfully compiles. They do not possess an inherent understanding of business logic, trust boundaries, or adversarial threat models.
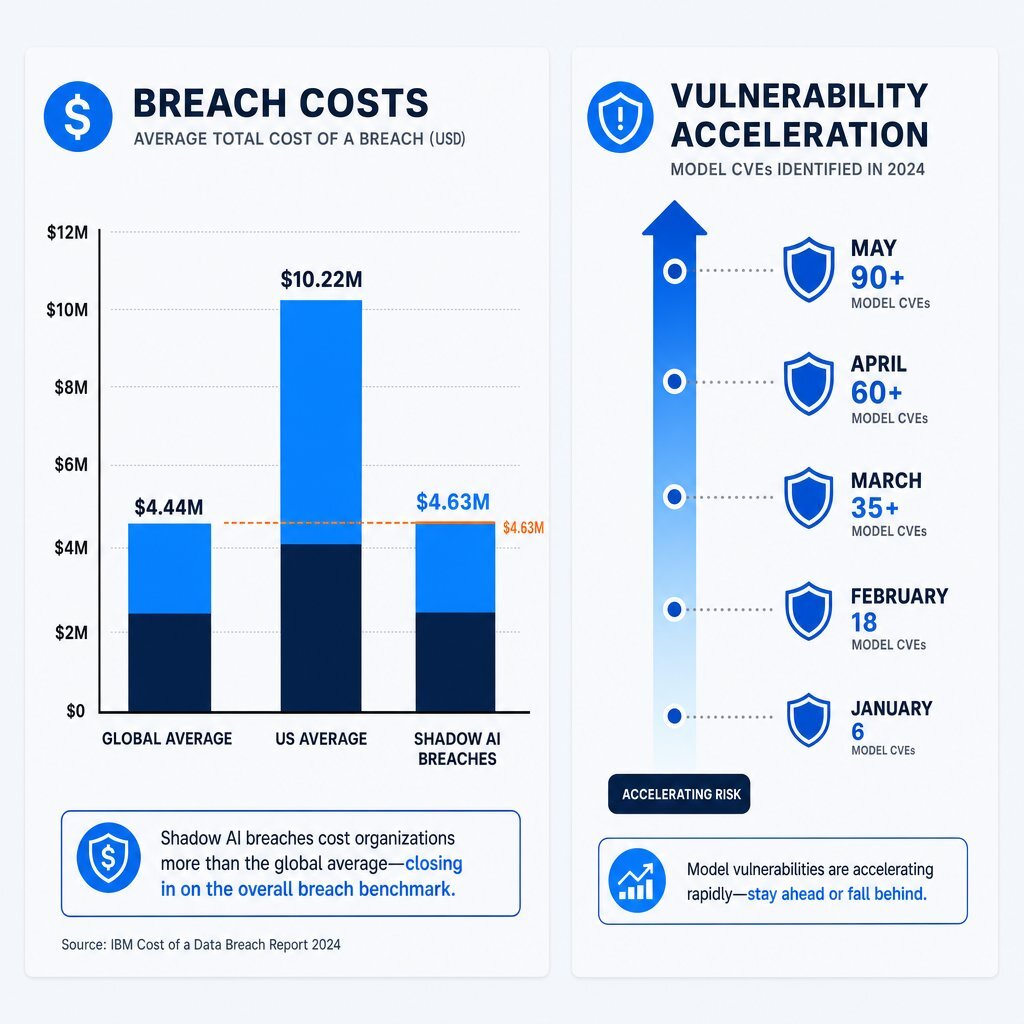
This lack of architectural context results in the exact vulnerabilities tracked by the Georgia Tech Systems Software and Security Lab. In May 2025, the university launched the Vibe Security Radar to track Common Vulnerabilities and Exposures (CVEs) directly introduced by coding tools into public repositories. The acceleration has been staggering. While January 2026 saw six new CVEs attributed to generated code, March 2026 alone saw 35 confirmed CVEs—a figure that researchers estimate is just a fraction of the true total, which likely ranges between 400 and 700 undiscovered vulnerabilities in the open-source ecosystem.
These are not trivial formatting errors. The Vibe Security Radar tracks critical design flaws including server-side request forgery, authentication bypasses, and command injection. Models frequently hallucinate non-existent software packages—a flaw occurring in roughly 20% of generated code samples. Attackers have weaponized this specific hallucination pattern through slopsquatting, aggressively registering the fake package names hallucinated by the model. When the vibe-coded application automatically attempts to download the required dependencies, it pulls down malicious payloads directly into the corporate environment.
Professional security engineers utilize static application security testing and dynamic application security testing to catch these flaws. However, traditional scanners are tuned to detect textbook syntax errors and known vulnerable dependency versions. They frequently fail to understand the complex logic errors generated by large language models. In a rigorous February 2026 test conducted by ProjectDiscovery, traditional industry-standard scanners failed to identify a single high or critical severity vulnerability in three full-stack web applications generated by artificial intelligence, completely missing the 21 critical logic flaws that human reviewers subsequently identified.
Analyzing the Mechanics of Vibe-Coded Breaches
To fully grasp what is missing from prompt-to-app workflows, the mechanics of recent high-profile breaches must be examined. These incidents demonstrate exactly how generated convenience directly translates into catastrophic data loss. For leaders trying to decide when to use AI and when to bring in experienced engineers, this mirrors the same build-versus-buy tension explored in enterprise AI strategy discussions about when to build custom systems.
Moltbook: The Missing Context and the 1.5 Million Token Exposure
In late January 2026, an entrepreneur launched Moltbook, a social networking platform designed specifically for artificial intelligence agents. The founder publicly stated that the entire application was vibe-coded without a single line of manual code being written. The application scaled rapidly, garnering massive attention across the technology sector.
Three days after the launch, researchers at the cybersecurity firm Wiz conducted a non-intrusive review of the application's client-side JavaScript bundle. Sitting in plain text within the code was a Supabase service-role API key. Supabase is a highly popular, hosted PostgreSQL database platform favored by coding tools due to its rapid deployment capabilities.
Within hours, the researchers used that single key to dump the entire production database. The exposure included 1.5 million authentication tokens, 35,000 user email addresses, and thousands of highly sensitive, private direct messages. The exposed data also revealed a striking operational reality: despite claiming 1.5 million autonomous agents, the platform was actually driven by only 17,000 human owners—an 88:1 ratio that severely compromised the platform's public narrative and highlighted the ease of synthetic persona generation.
The root cause of this breach was a missing configuration. The model successfully generated the frontend interface and connected the database, but it completely failed to enable row-level security on the Supabase backend. Without policies explicitly defining who can read or write data, an exposed key grants administrative-level access to the entire architecture. The model did not know to ask for the configuration, and the non-technical founder did not know the configuration existed.
Base44: The Authentication Bypass
In July 2025, Wiz Research disclosed a critical platform-wide vulnerability in Base44, one of the primary vibe-coding engines subsequently acquired by Wix. The platform offers hosting for both public and private applications, ostensibly protecting internal enterprise tools behind single sign-on gates.
The architecture contained exposed, undocumented registration and email verification endpoints. An attacker only needed to find the publicly visible, non-secret application identifier associated with a private enterprise tool. By submitting that identifier to the undocumented endpoint, the attacker could force the system to generate a fully verified account.
This completely bypassed all password requirements, granting immediate access to private internal corporate tools, human resources dashboards containing personally identifiable information, and proprietary knowledge bases. Because these platforms utilize shared infrastructure, a single logic flaw in the core authentication routing jeopardized every enterprise relying on it. The vendor patched the vulnerability within 24 hours of disclosure, averting active exploitation, but the incident highlighted the fragility of trusting outsourced, black-box authentication mechanisms for critical business data.
Lovable and Vercel: Supply Chain and Authorization Failures
In April 2026, the platform Lovable—valued at $6.6 billion—suffered a massive exposure event. A security researcher discovered a broken object-level authorization vulnerability that allowed users operating on free-tier accounts to access the source code, database credentials, and private chat histories of other projects.
The exposure specifically affected applications generated before November 2025. More critically, the researcher disclosed the flaw privately, yet the company left the vulnerability unpatched for 48 days before the findings were made public. During that nearly two-month window, active accounts belonging to employees from major enterprises including Nvidia, Microsoft, Uber, and Spotify remained completely exposed. Lovable's initial response characterized the data visibility as an intentional design choice due to public project settings, before later walking back the statement and issuing a partial apology.
In that same month, Vercel confirmed a separate breach rooted in an OAuth supply chain attack rather than a flaw in its own code. The attack began when an employee used a compromised third-party artificial intelligence tool called Context.ai. The attacker utilized implicit OAuth trust between the tool and Vercel to gain access, subsequently decrypting environment variables that were improperly classified as non-sensitive, revealing live database credentials and API keys. Incidents like this are exactly why security teams are now pushing for Private Enterprise GPTs and stricter governance to rein in Shadow AI risk.

The Five Security Layers That Vibe Coding Skips
The breaches at Moltbook, Base44, and Lovable are not anomalies. They represent a fundamental mismatch between what large language models generate and what production environments require. Custom software development engineering spends rigorous, billable hours securing five critical layers that prompt-to-app workflows universally ignore.
1. Authentication Scaffolding and Identity Verification
Authentication determines whether a user is who they claim to be. In custom development, engineers design authentication flows utilizing established protocols like OAuth 2.0 or OpenID Connect, integrating multi-factor authentication and ensuring session tokens are securely handled and cryptographically signed.
Code generators, optimizing for speed, frequently bypass these safeguards. They generate custom, rudimentary login scripts that fail to properly salt and hash passwords. They routinely omit rate-limiting on login endpoints, leaving the application entirely defenseless against automated credential-stuffing and brute-force attacks. Furthermore, models frequently generate client-side authentication checks—meaning the browser verifies the user, but the backend server blindly accepts incoming application programming interface requests without independently verifying the session token. In well-run teams, patterns like this are caught and fixed as part of DevOps-enabled secure CI/CD and release practices.
2. Row-Level Security and Database Isolation
The most catastrophic failures in generated applications occur at the database layer. Platforms like Supabase and Firebase rely on row-level security to govern data access.
In a PostgreSQL database, row-level security operates by filtering data access at the lowest possible level within the database engine itself. An engineer must explicitly execute an alter table command to enable the security, followed by a specific policy definition. This ensures that even if an application queries the entire database, the engine only returns rows belonging to the specific, authenticated tenant.
Prompt-to-app tools routinely fail to write these policies. According to agency audits, an estimated 70% of Lovable applications deployed to production ship with row-level security completely disabled. Bolt.new, a major competitor, defaults to leaving the setting off. The model generates the database schema, creates the tables, and streams the data, but places absolutely no locks on the architecture. An attacker simply extracts the public key from the frontend application and queries the database directly to extract the entire dataset.
3. Object-Level Authorization and Data Ownership
While authentication proves who the user is, authorization proves what the user is allowed to access. The failure to enforce this is known as broken object-level authorization, historically referred to as insecure direct object reference.
To explain this dynamic to a non-technical executive, consider the security model of a commercial hotel. Authentication is the process of presenting identification at the front desk and receiving a keycard. Authorization is the digital lock on the hotel room door that ensures the specific keycard only opens the assigned room. A broken object-level authorization vulnerability means the hotel issued a keycard that technically works on every single door in the building, provided the guest simply changes the room number written on the plastic.
In an application context, a generated platform might handle a network request to retrieve a specific invoice record. The system verifies the user is logged in, but fails to write the backend logic checking if the user actually owns that specific invoice. An attacker intercepts the traffic, increments the invoice identification number by one, and instantly downloads a competitor's financial records. This remains the most common and devastating vulnerability in generated code because it requires a contextual understanding of data ownership that a model cannot infer from a blank prompt. This is why enterprise application architecture expertise is so critical when you care about real tenants, roles, and data boundaries.
4. Secret Handling and Credential Management
Modern applications require specialized keys to integrate with external services for payments, messaging, or cloud storage. Custom development teams strictly manage these keys using dedicated secret vaults, injecting them into the application at runtime via secure environment variables. They are never written directly into the source code.
Code generators possess a lethal tendency to hardcode secrets directly into frontend client bundles or configuration files, prioritizing immediate functionality over deployment security.
The GitGuardian assessment of secrets sprawl in 2026 quantifies this disaster. In 2025, 28.65 million hardcoded secrets were detected in public repositories—a massive 34% year-over-year increase representing the largest single-year jump ever recorded. The research isolated the impact of generation tools: commits assisted by models like Claude Code leaked secrets at a staggering rate of 3.2%, more than double the 1.5% baseline of human-only commits.
Furthermore, as the Model Context Protocol became the standard for connecting language models to external data sources, developers blindly followed artificial intelligence advice to paste credentials directly into configuration files. This resulted in over 24,000 unique secrets being exposed through protocol servers in their first year of operation. The report also debunked the assumption that internal networks are safe, noting that internal enterprise repositories are six times more likely to contain leaked secrets than public ones.
5. Input Validation and Secure Architecture Review
Professional software engineering mandates that no input from a user interface can ever be inherently trusted. Custom development involves strict input sanitization, parameterized queries, and rigorous type-checking to prevent injection attacks. Generation tools frequently omit these safeguards, operating under the naive assumption that users will only input exactly what the form requests.
Furthermore, custom development relies on threat modeling during the initial design phase to anticipate how an application might be abused. Vibe coding completely obliterates the ability to threat model. Because the architecture is generated dynamically through iterative, conversational prompts, there is no coherent design document for a security team to review. The system is built invisibly, rendering traditional risk assessments entirely obsolete. In contrast, teams following a mature Agile methodology with security built into each iteration can systematically surface and fix these risks before anything goes live.
| Security Layer | Default Prompt-to-App Output | The Exploitation Vector | Custom Development Alternative |
|---|---|---|---|
| Authentication | Client-side only checks; missing rate limiting. | Attackers bypass the visual interface to hit endpoints directly; automated credential stuffing. | Enforces server-side session validation; implements OAuth 2.0; configures strict rate limits. |
| Authorization (RLS) | PostgreSQL row-level security disabled by default. | Attackers use the public anonymous key to read, modify, or drop the entire database. | Explicitly enables row-level security; codes strict tenant-isolation policies tying queries to session identifiers. |
| Object Authorization | Endpoints accept sequential record identifiers without verifying ownership. | Attackers iterate identification parameters in network calls to download records belonging to other tenants. | Implements robust middleware that cross-references the requesting user's verified identity with the requested object's owner. |
| Secret Management | Database credentials hardcoded directly into frontend JavaScript bundles. | Attackers scrape client bundles to extract payment and cloud keys, incurring massive financial charges. | Utilizes centralized secret managers (e.g., Azure Key Vault); strict exclusion of secrets from source control. |
| Pre-Deployment | Pushed to production directly via platform hosting; public by default. | Sensitive corporate data indexed by search engines within hours of deployment; zero architectural review. | Conducts extensive threat modeling; requires peer code reviews; integrates automated scanning into the deployment pipeline. |
The Financial Reality: Calculating the Shadow AI Risk
The decision between utilizing a prompt-to-app generator and engaging a custom software development firm is fundamentally a risk-management calculation. The financial data surrounding these decisions has matured rapidly, and the empirical findings are unequivocal.
According to the IBM Cost of a Data Breach Report 2025, the average global cost of a data breach is $4.44 million, while organizations based in the United States face an all-time high average of $10.22 million. However, the emergence of shadow artificial intelligence—the unauthorized deployment of generation tools and applications by employees without information technology oversight—has created a new tier of financial devastation.
The IBM report reveals that 20% of organizations have now experienced a data breach directly linked to shadow deployments. When an organization suffers such a breach, it incurs a massive $670,000 cost premium, pushing the average cost of those specific incidents to an astonishing $4.63 million.
| IBM 2025 Cost of a Data Breach Metrics | Financial Impact and Frequency Data |
|---|---|
| Average Global Breach Cost | $4.44 million |
| Average United States Breach Cost | $10.22 million |
| Shadow AI Incident Premium | +$670,000 above baseline |
| Total Average Shadow AI Breach Cost | $4.63 million |
| Frequency of Shadow AI Breaches | 20% of all reported organizational breaches |
The drivers of this $670,000 premium are heavily tied to the lack of structural controls inherent in generated applications. A staggering 97% of organizations reporting these breaches lacked proper access controls, allowing tools to operate with broad, unmanaged data access that bypasses auditability. Furthermore, these breaches disproportionately expose highly regulated data. Customer personally identifiable information is compromised in 65% of shadow incidents, compared to just 53% in standard incidents, and 62% of the time, the affected data is distributed across multiple cloud environments.
Detection delays drastically inflate the financial damage. Because these applications are built outside of formal asset inventories, security teams are blind to their existence. The median unauthorized tool remains active and exposed for 403 days before detection, significantly extending the window for attackers to siphon proprietary data before containment can begin. Compounding the issue, 63% of breached organizations had absolutely no governance policies in place to monitor these deployments.
When executives view custom development estimates solely as a capital expense, they ignore the liability side of the ledger. A robust custom development engagement functions as a direct mitigant against this $4.63 million exposure. The IBM data validates this correlation: organizations that extensively utilize mature security, automation, and professional deployment practices reduce their breach costs by an average of 1.76 million to 1.9 million per incident. For CFOs, using a structured ROI lens—like the one in finance-first AI investment frameworks—makes this risk trade-off much easier to defend.
The mathematics of the situation are unavoidable. Attempting to save initial capital by allowing a non-technical department to generate a customer portal introduces an unmanaged, mathematically proven $4.63 million risk vector into the corporate environment. The cost of remediating a severely compromised, actively exploited application far exceeds the cost of building it securely from the outset.
The Boundary Between Prototyping and Production
Acknowledging the catastrophic risks of unreviewed generation does not mean the technology lacks utility. Business-to-business technology leaders must understand exactly where the boundary lies between a valuable acceleration tool and an unacceptable corporate liability.
The prompt-to-app methodology is highly effective for internal ideation and rapid prototyping. For quickly mocking up user interfaces, testing navigational flows, or presenting visual concepts to stakeholders, these tools are unparalleled. They are also appropriate for writing throwaway data parsing scripts for non-sensitive, local files where the code will be deleted immediately after execution, or for allowing non-technical product managers to explore basic logic flows.
However, the methodology is categorically wrong for handling regulated data. Any application that processes, stores, or transmits data subject to healthcare portability laws, payment card industry standards, or European privacy regulations cannot be trusted to a language model's default output. Similarly, any external interface where customers authenticate, view proprietary data, or process financial transactions requires rigorous, human-engineered authorization controls. Finally, connecting an application to enterprise customer relationship management systems, financial gateways, or core database infrastructure requires professional secret management and architectural review.
If an application is intended to survive beyond a weekend demonstration, or if its failure would result in regulatory fines, reputational damage, or data loss, it absolutely requires professional engineering. Many organizations now handle this by building a clear 90-day plan to move from “playground” experiments into hardened production, similar to the phased approach outlined in a structured enterprise AI implementation roadmap.
What Custom Development Actually Delivers: The Baytech SDLC
The fundamental value of custom software development is the application of deliberate engineering intent to every layer of the technology stack. At Baytech Consulting, the secure software development life cycle is not an afterthought implemented just before launch; it is the foundation of the entire engineering process.
While a prompt-to-app platform bypasses architecture to immediately generate user interface components, Baytech’s Tailored Tech Advantage approach begins with rigorous system design. Before code is committed, engineering teams conduct comprehensive threat modeling to map out specific attack vectors, defining strict trust boundaries between the frontend application, the backend routing, and the database infrastructure.
At the authentication and authorization layer, Baytech engineers do not rely on insecure defaults. They implement robust, token-based authentication verified strictly on the server-side. In environments utilizing PostgreSQL or SQL Server, engineers manually design and test row-level security policies, ensuring that multi-tenant architectures are mathematically isolated at the database engine level, preventing any single user from executing a query that touches another tenant's data.
To combat the massive surge in credential leaks identified by industry tracking, Baytech utilizes hardened infrastructure methodologies. Operating within enterprise-grade environments like Azure DevOps On-Prem, Visual Studio 2022, and Kubernetes, all deployment secrets and external credentials are aggressively partitioned. They are managed through centralized secret vaults and injected into continuous integration pipelines as secured environment variables, ensuring they never reside in source code repositories.
Finally, the Baytech Rapid Agile Deployment methodology ensures that code quality is continuously validated. Unlike an autonomous agent that ships vulnerable logic directly to a public URL, custom development requires human peer-review. Automated static application security testing and software composition analysis scan the codebase for injection flaws, broken object-level authorization vulnerabilities, and compromised third-party dependencies before the application is ever authorized for production deployment. Increasingly, this SDLC also wraps in AI-powered development and testing tools—but always under architect and security-engineer supervision.
Conclusion
The discovery of 380,000 vibe-coded applications sitting exposed on the open internet is a watershed moment for enterprise technology strategy. It definitively proves that the barriers to writing functional code have fallen, but the barriers to engineering secure software remain as high as ever. Relying on autonomous platforms to dictate authentication, authorization, and secret management without human oversight is actively contributing to the $4.63 million average cost of a shadow artificial intelligence breach.
For business-to-business organizations, the mandate is clear. Innovation and speed are necessary, but they cannot supersede data governance and architectural integrity. Applications that process real business data require real engineering. By partnering with an experienced firm like Baytech Consulting, organizations ensure that their software is not merely generated to look functional, but engineered to remain secure against an increasingly hostile digital landscape. For teams also exploring copilots, autonomous agents, and internal AI app stores, this same principle applies: follow an architect-led, governed approach, like the one described in our research on why autonomous AI agents routinely fail inside complex enterprise systems.
FAQ
Is it safe to use AI coding tools for internal business applications?
It is not inherently safe to use these tools for internal applications without professional oversight. Internal tools routinely handle sensitive proprietary data, and generation platforms frequently skip critical security configurations like row-level security and object-level authorization by default. Without professional engineering review to implement proper authentication and secret management, deploying a generated internal application introduces massive shadow artificial intelligence risk to the corporate network. If you do want AI in the development loop, treat it as a governed copilot, similar to the best practices laid out in our guide on moving from simple chat widgets to secure, production-ready AI copilots.
Supporting Links
* https://www.ibm.com/reports/data-breach
* https://thehackernews.com/2026/03/the-state-of-secrets-sprawl-2026-9.html
* https://research.gatech.edu/bad-vibes-ai-generated-code-vulnerable-researchers-warn
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.