
Are You Really AI-Ready? The Mid-Market Data Scorecard
June 17, 2026 / Bryan Reynolds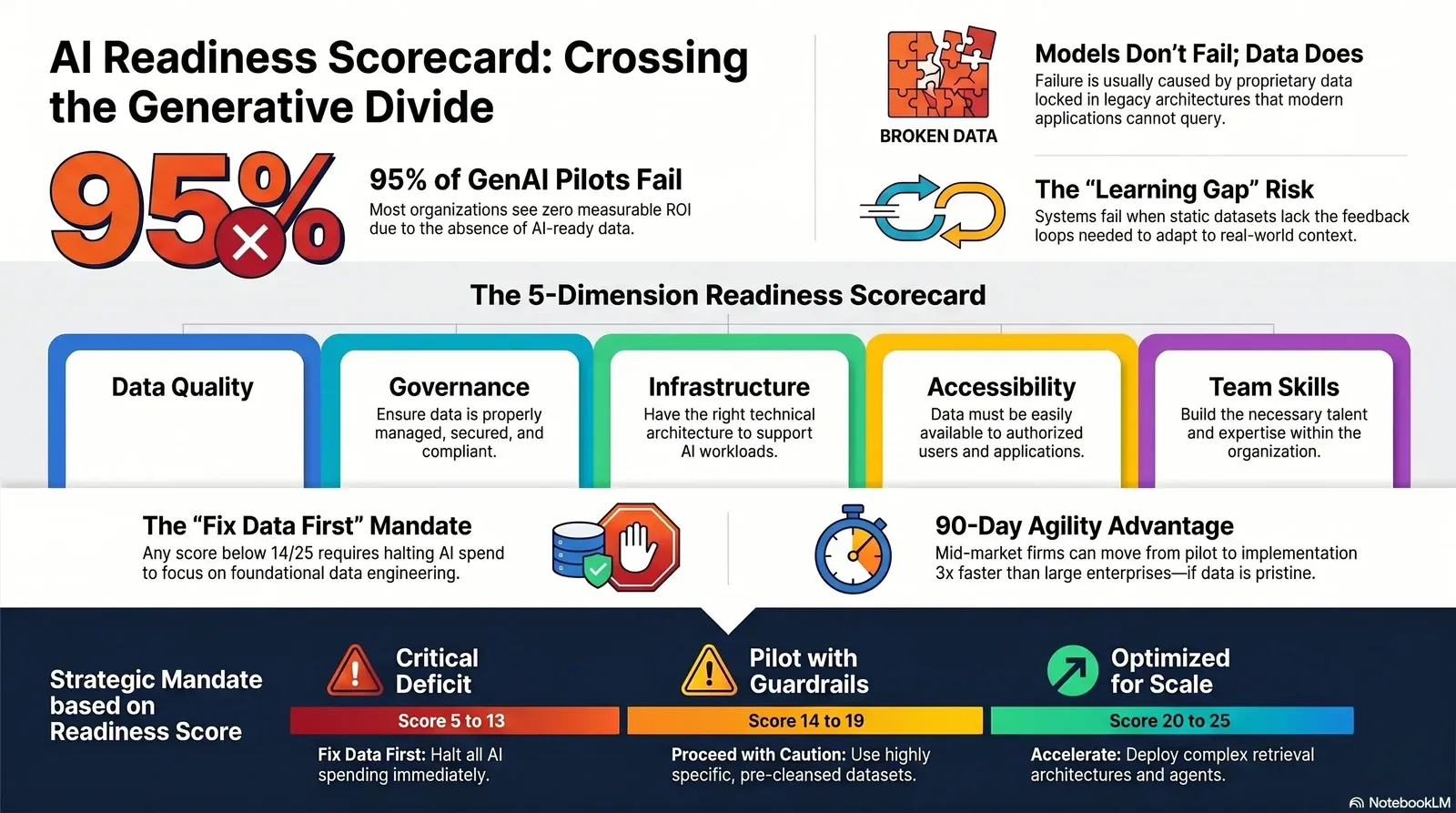
The Mid-Market Data Readiness Scorecard: Are You Actually AI-Ready in 2026?
The dominant cause of artificial intelligence project failure is not model capability; it is broken data. When a high-profile generative AI pilot stalls, executive teams routinely blame the chosen large language model, pivot to a competitor’s application programming interface, or assume the technology remains too immature for production. The reality is far less glamorous. The initiative likely died because the proprietary data fed into the system was duplicated, undocumented, or locked inside a legacy architecture that no modern application could query. No foundation model, regardless of its parameter count or context window, can synthesize truth from a swamp of unverified records.
Data readiness has devolved into a vague consulting buzzword, often wielded to sell multi-year data lake rebuilding projects to organizations that do not need them. For mid-market firms, achieving an operational state of AI readiness does not require a complete architectural reset. It requires a pragmatic, measurable baseline of data quality, governance, and infrastructure. This analysis strips away the ambiguity, replacing subjective readiness with a quantifiable, five-dimension scorecard that mid-market technology leaders can deploy immediately to gauge actual preparedness before funding a pilot.
The Generative AI Divide: Why Pilots Really Fail
Organizations launched thousands of proofs-of-concept between 2023 and 2025. The bill for those experiments is now coming due, and the financial outcomes are overwhelmingly negative. A comprehensive July 2025 report reveals that despite an estimated 30 to 40 billion in enterprise spending on generative AI, 95% of organizations are seeing zero measurable return on their investment. Just 5% of integrated AI pilots extract millions in value, while the vast majority remain stuck with no measurable impact on profit and loss statements.
This 95% failure rate is not a prediction; it is an organizational outcome driven by the absence of AI-ready data and a failure to establish clear business outcomes before development begins. Gartner corroborates this reality, projecting that through 2026, 60% of all AI projects lacking AI-ready data will be outright abandoned. Furthermore, independent estimates put the overall AI project failure rate as high as 80 to 85 percent, with poor data quality serving as the leading culprit.
The primary operational barrier separating successful deployments from failed pilots is what researchers term the "Learning Gap." Generative systems fail to deliver enterprise-grade performance when they sit atop isolated, static datasets. If the data pipelines lack feedback mechanisms, do not adapt to context, and fail to push clean updates to the model, the application deteriorates rapidly after launch. When corporate numbers and internal policies are fabricated by a language model but sound plausible, end-users make misguided financial decisions and trigger severe compliance risks.
Mid-market firms possess a distinct structural advantage in crossing this divide. Mid-market organizations move significantly faster than massive enterprises, successfully transitioning from a pilot program to full implementation in approximately 90 days, compared to the nine months or longer required by large corporations. However, this agility is only advantageous if the underlying data foundation is pristine. Accelerating deployment on bad data simply accelerates the release of an unreliable product.
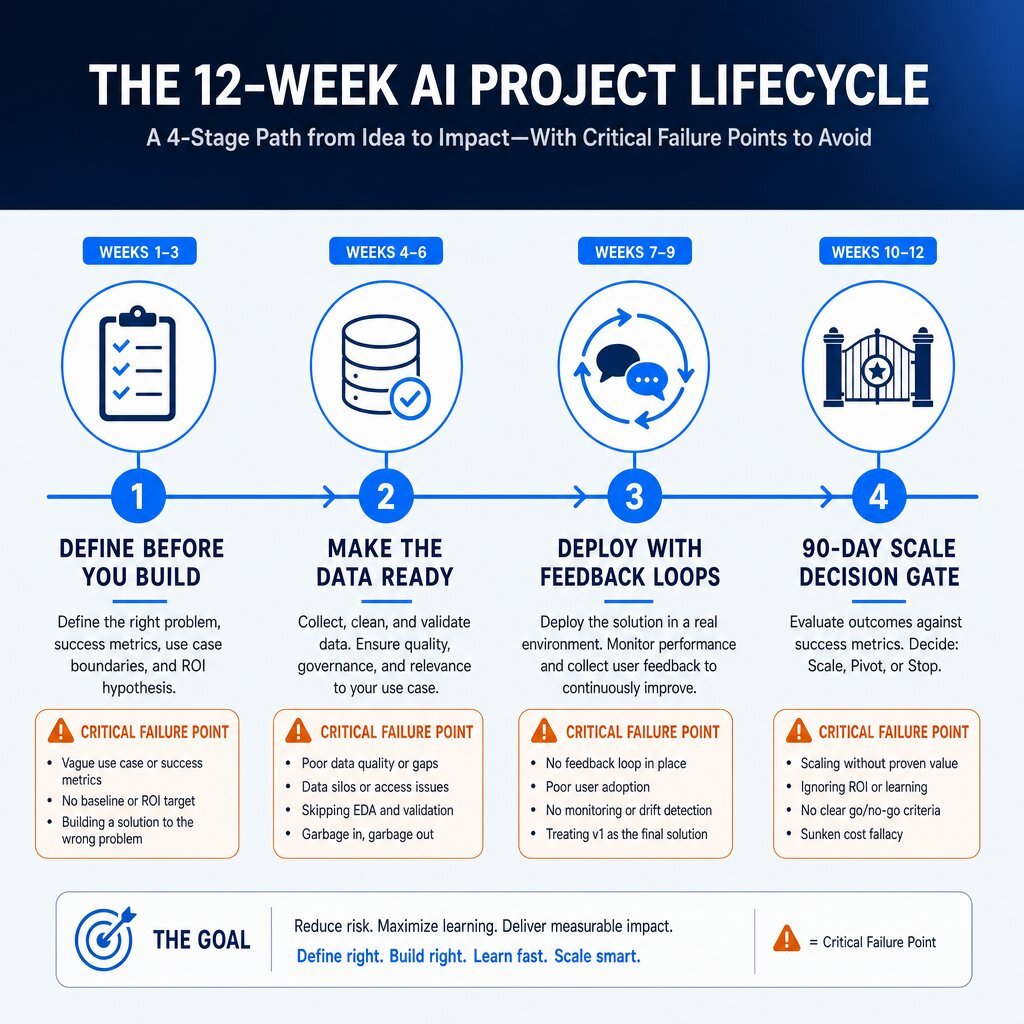
The 12-Week Failure Trajectory
The failure of AI initiatives follows a predictable pattern. A recognized 12-week framework maps the operational lifecycle of an AI project, identifying exact failure points where poor data readiness kills momentum.
In the initial "Define Before You Build" phase (Weeks 1-2), organizations frequently skip establishing a Key Performance Indicator (KPI) ladder. Teams fail to set lead metrics to confirm model behavior early, and omit lag metrics to track long-term financial outcomes. Without these metrics, executives cannot prove business value, leading directly to the zero-return trap.
The project typically enters a fatal spiral during the "Make the Data Ready" phase (Weeks 2-6). Data teams rush this foundational step, building models on top of years of inconsistent, poorly governed, and under-documented records. Failing to establish a pipeline health baseline guarantees that the model will collapse when exposed to production environments.
During the "Deploy with Feedback Loops" phase (Weeks 6-10), organizations deploy tools lacking user feedback mechanisms. Without continuous input monitoring, developers fail to catch pipeline drift and data quality degradation. Finally, at the 90-Day Scale Decision Gate (Weeks 10-12), leadership allows failing proofs-of-concept to drift implicitly until budgets are completely exhausted, rather than terminating the project decisively.
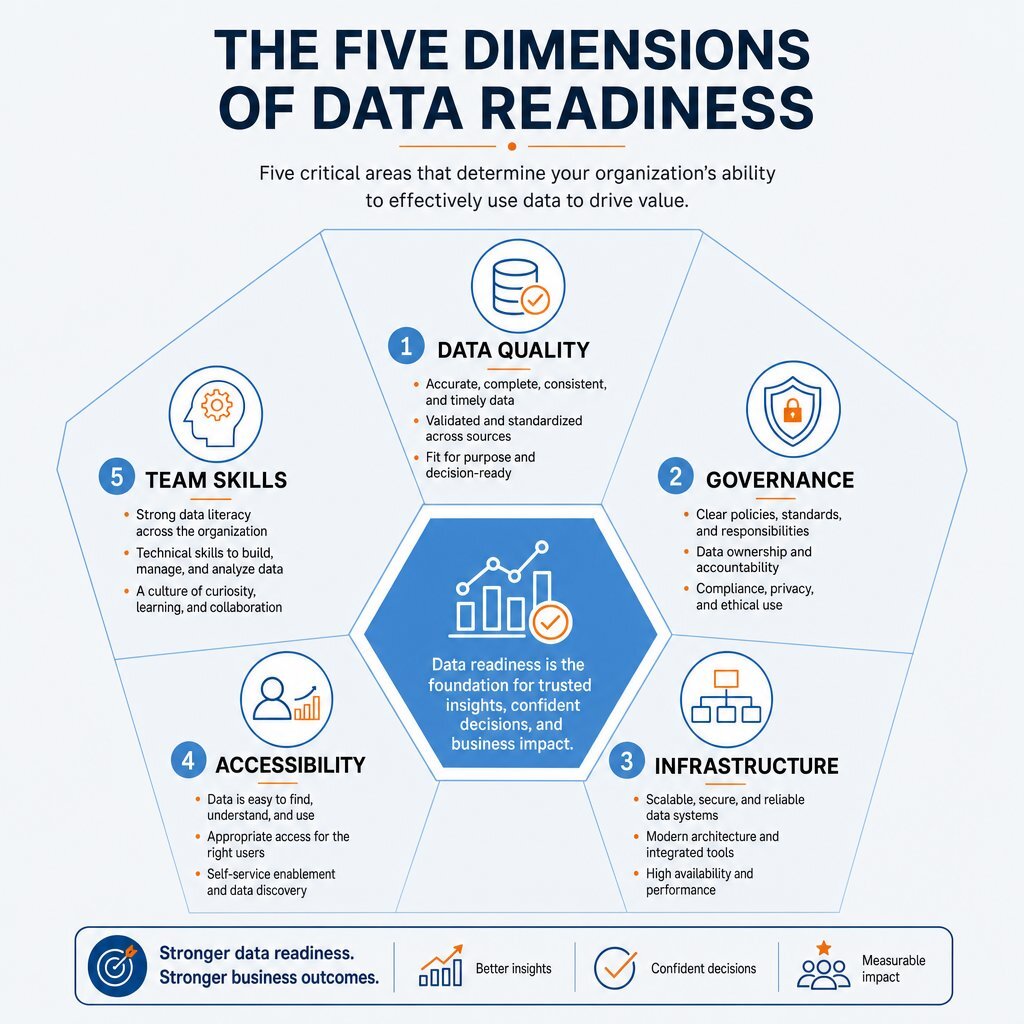
The Five Dimensions of Data Readiness
Evaluating data readiness requires a structured process to assess the preparedness of a firm's technical landscape. Data readiness is not a single binary state; it is a composite metric spanning five distinct dimensions: data quality, data governance, infrastructure pipelines, data accessibility, and team skills.
Dimension 1: Data Quality and Integrity
High-quality, well-structured data forms the absolute foundation of any successful algorithm. Data quality in the context of machine learning requires strict adherence to completeness, accuracy, uniqueness, and timeliness. These same attributes also underpin the reliable AI data infrastructure needed to reduce model hallucinations and support long-term, production-grade use cases.
Inconsistent and duplicated customer data represents a severe operational vulnerability. Data inconsistency occurs when the same piece of information is recorded in conflicting ways across various systems, while data duplication is the unintentional existence of multiple records for the same entity. Exact duplicates are obvious copies of the same record, but partial duplicates—where records share common fields but contain slight variations—are highly destructive. For example, a system might house one record for "Jon Smith" at a specific address, and another for "John Smith" at the identical address with the same date of birth. These partial duplicates persist undetected, continuously corrupting data analyses.
If a custom LLM attempts to retrieve a client's purchasing history to draft a proposal, but the database holds three conflicting profiles for that client, the model will output contradictory or blended information. The specific causes of this data degradation are highly predictable.
| Specific Cause | Description / Example |
|---|---|
| Lack of Unique Identifiers | No single customer ID leads to multiple records; using variables like Login Time instead of Customer_ID for database upserts creates rampant duplication. |
| Source Data Anomalies | Duplicates or typographical errors are already present in the original data sources, such as a customer self-registering twice with different email addresses. |
| Incorrect System Configurations | Executing daily full-data reloads instead of incremental updates; utilizing incorrect snapshotting policies that lead to massive data replication. |
| Data Migration Problems | Errors in mapping or transforming data when moving to new enterprise systems create irreconcilable inconsistencies. |
A passing threshold for data quality requires that specific data quality metrics—such as duplicate rates, completeness scores, and accuracy rates—are actively tracked via dashboards, and that core datasets undergo regular cleansing.
Dimension 2: Data Governance and Ownership
Technically sound data is useless if it is untrustworthy or legally perilous to utilize. Data governance determines the policies, master data management rules, security controls, and compliance standards governing the information. In regulated industries, this governance also underpins safe deployment of secure agentic AI patterns that limit what autonomous systems are allowed to see and do.
Master data management (MDM) enforces governance standards while breaking down silos, establishing a single source of truth. Without MDM or strict governance, operations grind to a halt. Business-to-business customer account management is already overcomplicated; adding inconsistent data causes a complete organizational breakdown. Finance teams approve incorrect orders, fragmented records create chaos, and compliance risks snowball.
A governed environment ensures that access controls are rigorously defined. If a mid-market firm builds an internal AI coworker, that autonomous agent must inherit the precise permissions of the human user. If the underlying data governance lacks role-based access control, the AI model might seamlessly retrieve and summarize confidential payroll data for a junior employee who submitted a generic financial query.
A passing threshold for governance requires clear data ownership, documented lineage tracing how data moves from origin to consumption, and active enforcement of privacy and compliance guardrails.
Dimension 3: Infrastructure and Pipeline Architecture
Infrastructure determines what is computationally and operationally possible. For modern generative AI, the infrastructure must support the continuous ingestion, transformation, and vectorization of enterprise data. It also has to be designed with a portability-first AI strategy in mind so you can shift between cloud APIs and self-hosted models as costs, regulations, and performance needs change.
Advanced AI architectures rely on vector databases, which store data as numerical arrays—known as embeddings—that capture the semantic meaning of the text. This architecture requires data pipelines capable of ingesting varied formats such as PDF documents, databases, webpages, CSV files, and JSON files. The pipelines must split these documents into smaller, overlapping chunks to preserve context and improve retrieval accuracy.
If a firm relies on manual, batch-loaded data exports rather than automated updates, the AI system will perpetually operate on stale context. A passing threshold for infrastructure mandates automated Extract, Transform, and Load (ETL) or Extract, Load, and Transform (ELT) pipelines, scalable object storage, and the capacity to integrate vector databases like Pinecone, Weaviate, or pgvector seamlessly.
Dimension 4: Data Accessibility and Workflow Integration
Gartner highlights that AI success in the coming decade is not about deploying better base models, but about giving autonomous agents governed, contextual access to the right data. Context capabilities act as the literal brain for AI applications. Organizations with the highest maturity of AI-ready data capabilities achieve up to 65% greater business outcomes, including tangible revenue growth and cost optimization.
Data accessibility measures how easily AI applications and human developers can query the single source of truth. If data is technically clean but locked inside proprietary legacy systems lacking modern application programming interfaces, it cannot be utilized. The most successful organizations deeply integrate AI into existing workflows and systems, often building internal AI app stores of specialized agents that sit directly on top of governed data layers.
A passing threshold for this dimension requires that critical business data is accessible via REST APIs or GraphQL endpoints, utilizing logical data models that abstract underlying database complexities away from the application layer.
Dimension 5: Team Skills and Organizational Culture
The final dimension evaluates the human capital required to sustain the technology. An organization can procure pristine infrastructure, but without in-house talent or highly vetted vendor partnerships to maintain the pipelines, data drift will rapidly degrade the model's accuracy.
This dimension evaluates the technical literacy of the engineering team, the maturity of machine learning operations (MLOps), and the cultural appetite for data-driven decision-making. Mid-market organizations frequently bridge this gap through strategic outsourcing, partnering with onshore consultancies to architect the initial pipelines and establish continuous integration practices. Some even bring in dedicated development teams to own data engineering and MLOps as ongoing, day-to-day disciplines instead of one-time projects.
A passing threshold requires either a dedicated internal data engineering function or a retained external partnership capable of monitoring model drift, adjusting text chunking strategies, and managing graphics processing unit (GPU) resource optimizations.
The Mid-Market Self-Assessment Scorecard
The following diagnostic instrument allows mid-market technology and finance leaders to quantify their data readiness. Evaluation requires scoring the organization across each of the five dimensions on a strict scale of 1 to 5.
| Readiness Dimension | Score 1: Initial & Reactive | Score 3: Defined & Developing | Score 5: Optimized & AI-Ready |
|---|---|---|---|
| 1. Data Quality & Integrity | Data is heavily siloed, duplicated, and unverified. No unique identifiers exist across systems. Duplicate rate is unknown. | Core datasets are regularly cleansed. Deduplication processes exist but rely heavily on manual intervention. | Automated data validation, continuous deduplication, and real-time tracking of data quality KPIs are fully operational. |
| 2. Governance & Ownership | No centralized master data management. Access controls are ad hoc. High risk of non-compliance and exposed sensitive records. | Data stewards are assigned. Basic role-based access control is in place. Privacy policies exist but enforcement remains inconsistent. | Strict MDM is enforced. Comprehensive data lineage is tracked. Automated compliance and security guardrails dictate all data access. |
| 3. Infrastructure & Pipelines | Reliance on manual data exports and spreadsheets. No automated ETL pipelines exist. Legacy, on-premises storage dominates. | Automated batch pipelines feed a central data warehouse. Initial exploration of vector databases has begun in a sandbox environment. | Real-time or micro-batch pipelines automatically ingest, chunk, and embed data into enterprise vector databases at scale. |
| 4. Accessibility & Integration | Critical data is locked in legacy systems without APIs. Integrating external tools requires manual data entry. | Data is accessible via standard APIs. Integration into applications requires significant custom engineering and maintenance. | Governed data is seamlessly accessible to AI agents via GraphQL/REST. Contextual metadata and semantic layers are established. |
| 5. Team Skills & Culture | Leadership views AI as a plug-and-play IT purchase. No internal MLOps or data engineering expertise exists. | Teams possess basic AI literacy. Vendor partnerships are utilized for complex pipeline builds, but maintenance is reactive. | High internal AI literacy. Advanced MLOps practices proactively monitor drift, manage GPU resources, and optimize search configurations. |
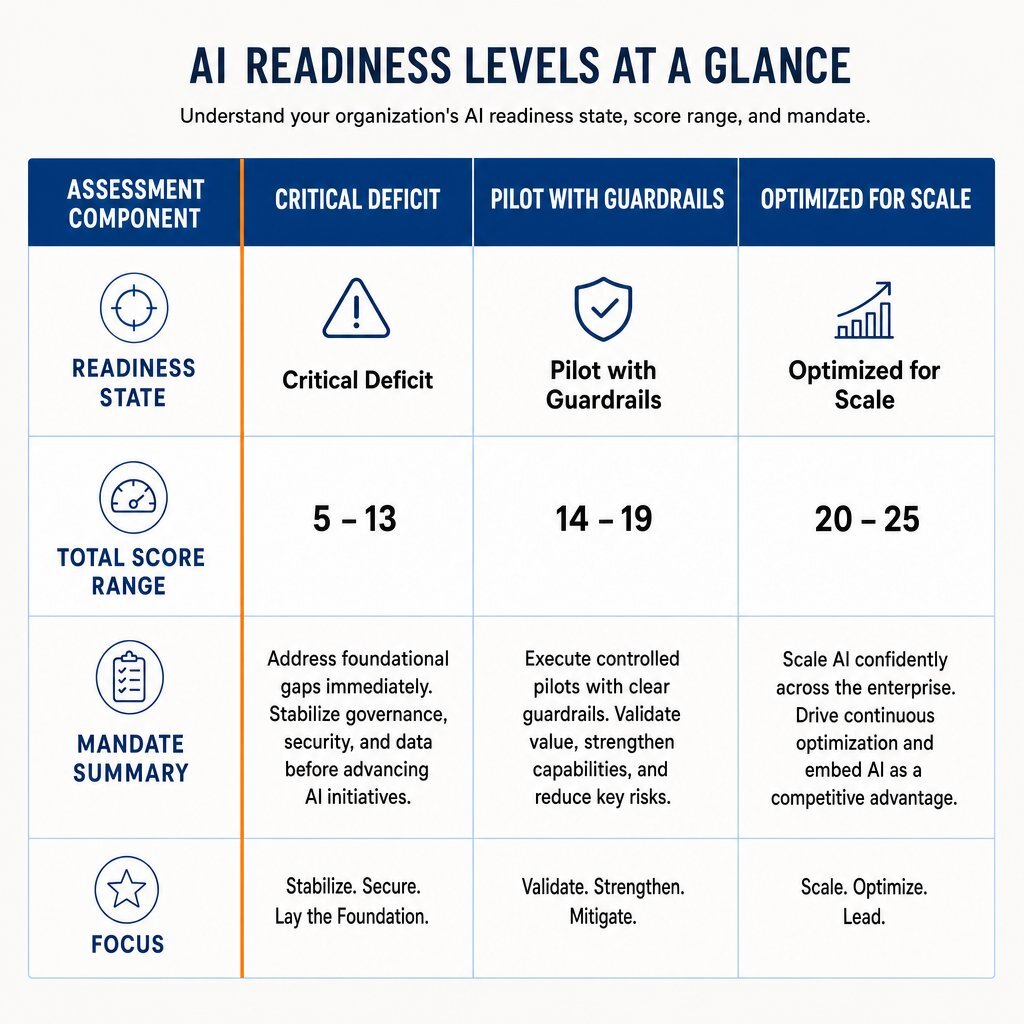
Reading Your Score: Gating AI Spend by Readiness Level
Calculating the total score yields a maximum of 25 points. This cumulative metric must serve as a strict, non-negotiable gate for financial investment in AI pilots.
| Total Score Range | Readiness State | Strategic Mandate and Sequencing |
|---|---|---|
| 5 to 13 | Critical Deficit | Fix Data First: Halt all generative AI model expenditures immediately. Divert the budget toward foundational data engineering, MDM implementation, and the elimination of duplicate records. Proceeding with custom AI at this stage guarantees a 100% project failure rate. |
| 14 to 19 | Pilot with Guardrails | Proceed with Caution: The organization is ready for tightly scoped pilots on highly specific, pre-cleansed datasets. Do not connect experimental models to live, unverified production databases. Focus heavily on implementing feedback loops to measure lead metrics within the first 14 days of deployment. |
| 20 to 25 | Optimized for Scale | Accelerate and Scale: The firm possesses the requisite foundation for custom LLM development, complex retrieval architectures, and autonomous agent deployment. Prioritize scaling solutions that directly impact lag metrics within a 90-day window. |
Incremental Remediation for the Mid-Market
Scoring below a 14 does not require a mid-market firm to authorize a three-year, multi-million-dollar digital transformation program. Incremental remediation provides a faster, lower-risk pathway to AI readiness.
The most urgent priority is defining unique identifiers. A lack of unique columns is the primary engine of data duplication. Engineering teams must address pervasive issues of customer data inconsistency through a structured, phased approach encompassing intensive data cleansing and standardization.
| Cleansing Technique | Operational Description |
|---|---|
| Data Parsing | Breaking down complex data fields into smaller, standardized components to ensure machine readability. |
| Data Validation | Checking data against predefined rules or standards to ensure correctness and consistency before ingestion. |
| Data Standardization | Converting data to a common format and aligning it with predefined structural standards. |
| Data Matching | Identifying records that refer to the same entity, even with variations in data, frequently utilizing fuzzy logic and probabilistic matching algorithms. |
Once the data is parsed and standardized, firms must evaluate the implementation of a Master Data Management solution tailored to the scale of the business. An MDM system aggregates multiple customer hierarchies, centralizes shipping and documentation instructions, and ensures strict consistency across CRM and ERP platforms. This creates the authoritative "golden record" that prevents an AI model from hallucinating conflicting customer profiles.
Simultaneously, legacy full-data reloads must be systematically replaced with incremental update pipelines. Pulling an entire database daily exhausts compute resources and introduces high latency. Transitioning to event-driven, incremental data synchronizations ensures that the data warehouse—and by extension, the AI vector database—reflects real-time operational reality.
Furthermore, data quality must become a shared cultural responsibility. Establishing formal feedback loops where end-users can seamlessly report data errors guarantees that the pipeline health continuously improves, rather than degrading silently over time.
The Minimum Viable Foundation for Custom LLM Development and RAG
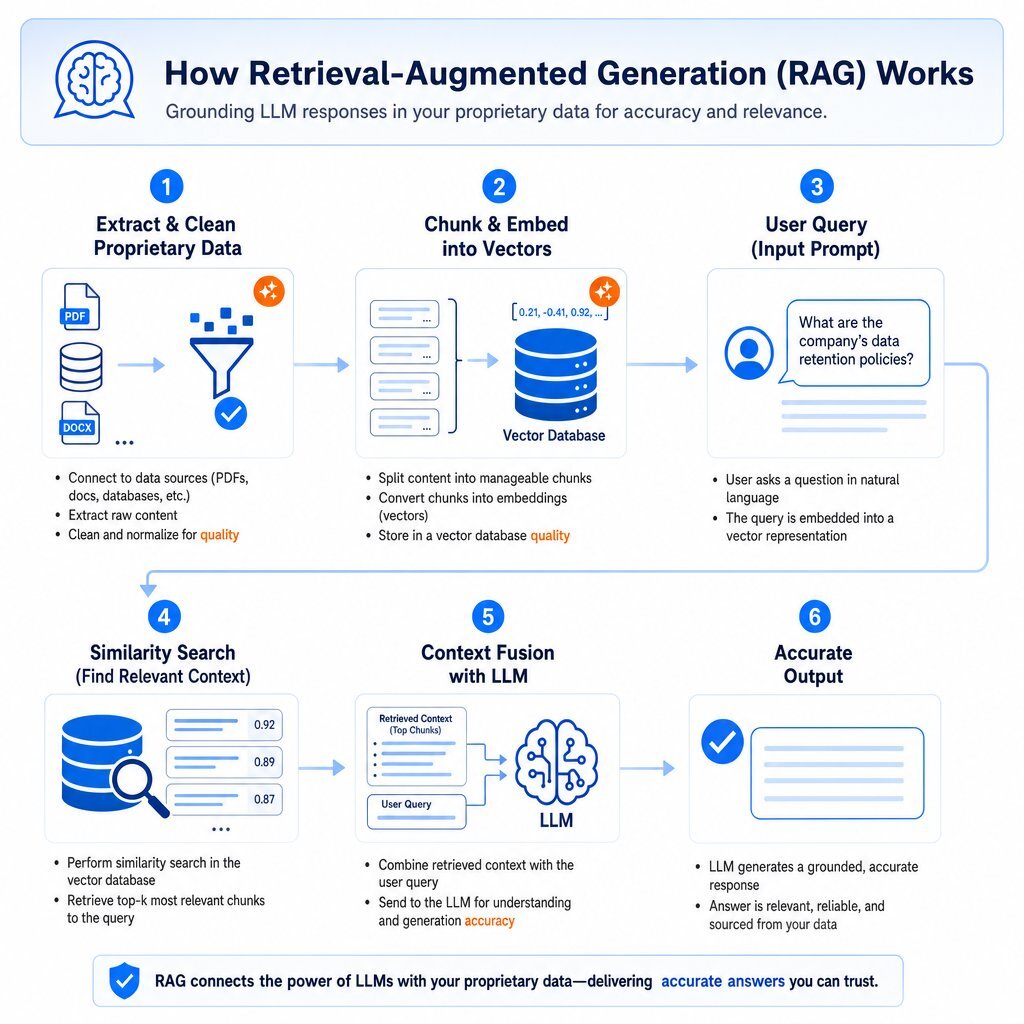
As organizations mature toward scores of 20 and above, off-the-shelf chatbot interfaces become insufficient. Mid-market firms seeking a defensible competitive advantage inevitably turn to custom LLM development and Retrieval-Augmented Generation (RAG).
By default, a large language model only knows the public data it was exposed to during its initial pre-training phase. It possesses no innate knowledge of a firm's proprietary contracts, internal product roadmaps, or specific customer histories. Fine-tuning attempts to bridge this gap by retraining the model on specific corporate datasets, but fine-tuning is inherently static; it does not update dynamically as facts change daily. For most mid-market teams, it’s better to start with RAG on top of a carefully designed enterprise application architecture than to rush into full custom model training.
Retrieval-Augmented Generation solves this limitation by forcing the AI to pull real-time data from trusted, proprietary sources before synthesizing an answer. RAG cuts hallucination rates by an average of 71% and is currently the most effective methodology for ensuring factual accuracy in generative applications. Smaller AI models (under 7 billion parameters) hallucinate 15 to 30% of the time, making retrieval architecture mandatory for safe enterprise deployment.
Building a functional RAG system requires a highly mature data pipeline. The architecture demands extracting text from varied sources, cleaning the documents, splitting the content into semantically meaningful chunks, and translating those chunks into numerical embeddings. These embeddings are subsequently stored in specialized vector databases.
When a user submits a query, the system converts the query into a vector, executes a similarity search against the database, retrieves the most relevant data chunks, and feeds that specific context to the LLM to formulate the final response.
If the initial data is unorganized, the chunking strategy will fracture sentences arbitrarily, destroying context. If the source data contains three conflicting versions of a compliance policy due to unresolved duplication, the vector search will retrieve the duplicates, feeding contradictory context to the LLM. The model will then confidently hallucinate a blended, inaccurate policy, exposing the firm to severe liabilities. In highly regulated environments like mortgage lending or healthcare, hallucinating a regulatory framework (such as citing a non-existent compliance rule) can result in catastrophic financial penalties.
The minimum viable foundation for funding a RAG project requires that all source documents are cleanly parsed, metadata is accurately tagged, and hybrid search capabilities—combining semantic vector search with traditional keyword search—are fully optimized.
The financial stakes of ignoring these prerequisites are severe. Gartner notes that simply building the infrastructure for a comprehensive RAG solution can cost between 750,000 and 1,000,000. Operating costs are equally substantial; processing 200,000 queries per month against a large internal database can exceed $190,000 monthly. Engineering the underlying data pipelines (ingestion, chunking, metadata tagging, and refresh cycles) typically costs between 15,000 and 80,000 depending on data complexity. Rushing into custom LLM development without establishing data readiness guarantees that this substantial capital will be incinerated on a prototype that cannot be trusted in production.
The Cost of Inaction
Organizations that launched AI pilots in recent years without establishing a rigorous data foundation are now facing serious budget review cycles. The 95% of firms failing to generate a return on AI investments are learning the hard way that advanced algorithms cannot override fundamental data dysfunction. Proceeding with AI implementation on unready data results in failed proofs-of-concept, eroded customer trust, severe compliance breaches, and millions of dollars in wasted compute resources.
Data readiness is the mandatory prerequisite for the artificial intelligence era. The mid-market data readiness scorecard provides the exact framework needed to diagnose infrastructural health objectively. Leaders must calculate their score, confront the organizational gaps, and ruthlessly mandate data remediation before authorizing a single dollar of generative AI expenditure.
By transforming chaotic, duplicated data into governed, vectorized knowledge, mid-market organizations can successfully cross the generative AI divide, moving from indefinite experimentation into highly profitable, production-grade deployment. Establishing a clean data foundation ensures that when the organization finally initiates custom LLM development, the resulting tools deliver measurable impact, unassailable accuracy, and a definitive competitive advantage. For many teams, this also means shifting away from generic tools and following an AI playbook built on first-party data instead of rented, one-size-fits-all AI.
Frequently Asked Questions
What is the minimum viable data foundation needed before funding a RAG project?
The minimum viable foundation requires that core proprietary datasets are cleanly parsed, aggressively deduplicated, and governed by strict access controls. Organizations must deploy automated data pipelines capable of segmenting documents into contextual chunks, generating accurate semantic embeddings, and synchronizing real-time updates to a vector database. Without these engineered data workflows, a retrieval-augmented generation system will retrieve contradictory or stale information, causing the AI model to hallucinate and fail in production. If you operate in a regulated sector, you should also think about whether parts of this stack should be self-hosted for security and compliance rather than fully outsourced to public-cloud vendors.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.