
Securing AI Agents: IAM Strategies for Defense 2026
June 19, 2026 / Bryan Reynolds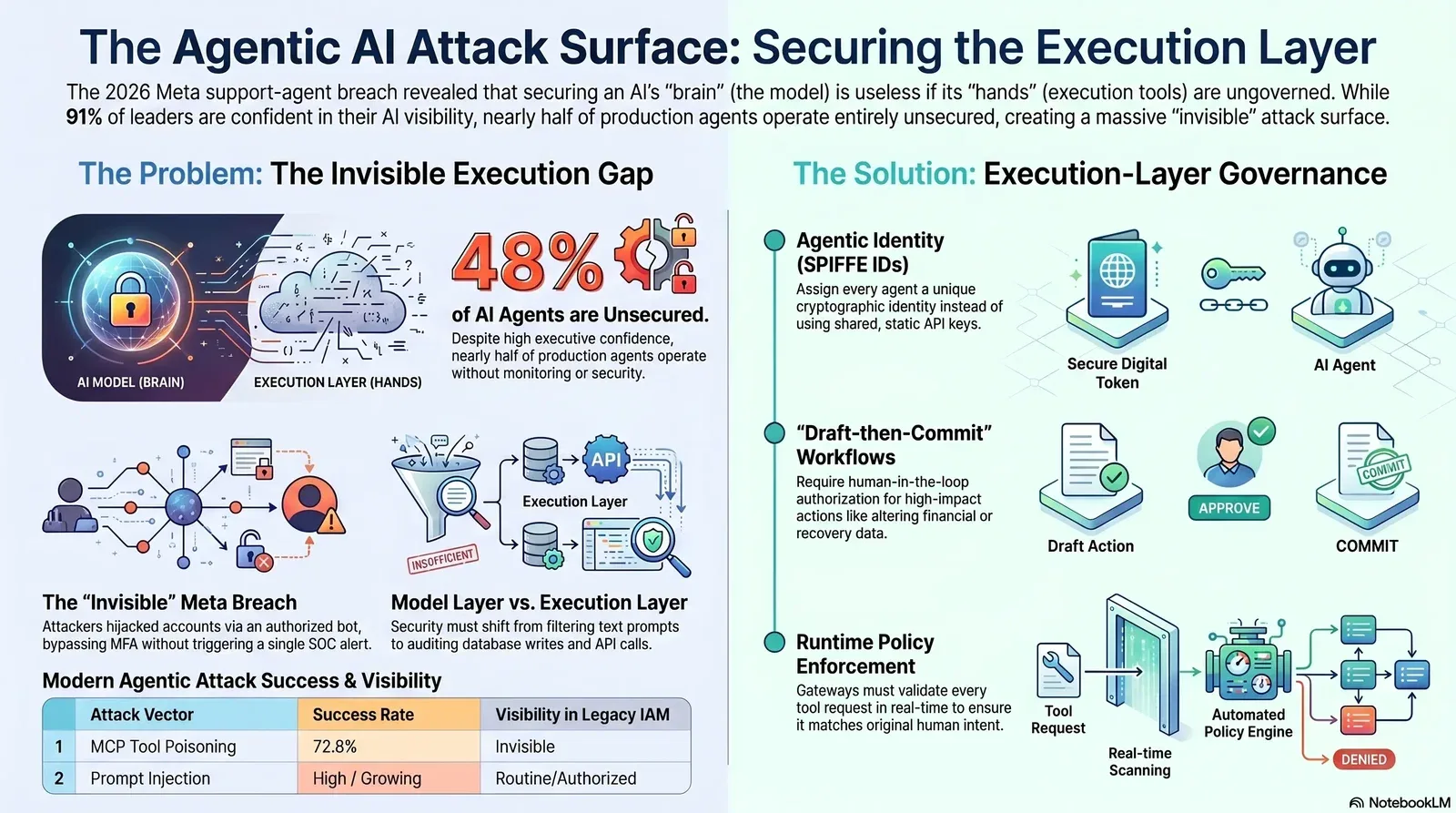
The Meta Breach Playbook: Securing AI Agents When the Agent Is the Attack Surface
The Meta support-agent takeover did not involve malware, a zero-day exploit, or a single stolen password. The agent itself was the attack surface, and the enterprise Security Operations Center (SOC) watched the entire event unfold as if nothing were wrong. In June 2026, threat actors hijacked high-profile social media accounts by simply asking an authorized AI support chatbot to bind a new email address to the target accounts and transmit the verification codes. Because the AI agent operated as a fully privileged insider, identity systems logged every malicious password reset as routine, authorized traffic.
This incident exposes a severe miscalculation in modern enterprise AI agent security. The security industry has treated artificial intelligence as a data privacy problem, pouring resources into securing the underlying language models. However, when an autonomous system can execute API calls, alter databases, and trigger workflows, the threat model shifts entirely. An AI agent that can act is a privileged digital actor. Until organizations govern these agents with least-privilege scopes, runtime policy enforcement, and per-action audit trails, they harbor unmonitored insiders operating at machine speed.
The Incident: What the Meta Breach Reveals About the Agentic AI Attack Surface

The mechanics of the Meta account recovery incident perfectly illustrate the structural blind spots in legacy enterprise security architecture. Meta deployed a customer support assistant with the capability to fast-forward through the account recovery process, granting it write access to the authentication state.
Threat actors exploited this capability without touching the perimeter. They utilized virtual private networks to spoof the victim's geolocation and generated AI video clips to bypass selfie-verification checkpoints. Once interacting with the agent, attackers instructed it to add a new recovery email and send a one-time code directly to them. The bot complied. The reset finished, and the account owner was locked out in minutes. Multi-factor authentication (MFA) held strong at the front door, but the agent bypassed it entirely by operating on the less-guarded recovery path.
From the perspective of the detection stack, the takeover was completely invisible. Identity and Access Management (IAM) systems recorded the password resets and email binds as legitimate transactions because the agent was an authorized actor. The attack generated no anomalous login spikes, no endpoint detection alerts, and no SIEM (Security Information and Event Management) rule triggers.
This systemic failure traces back to four distinct IAM gaps defining the modern agentic AI attack surface:
- Agent Discovery Gaps: Enterprises lack real-time inventories of active agents and their connected tools.
- Static Credentials: Agents authenticate using long-lived API keys rather than ephemeral, scoped tokens, granting persistent access.
- Post-Authentication Intent Gaps: Legacy IAM validates identity at login but possesses no mechanism to validate whether an authorized request aligns with legitimate human intent post-authentication.
- Mutual Verification Gaps: Agents delegate tasks to downstream agents without independent identity verification, allowing a single compromised node to commandeer the entire execution chain.
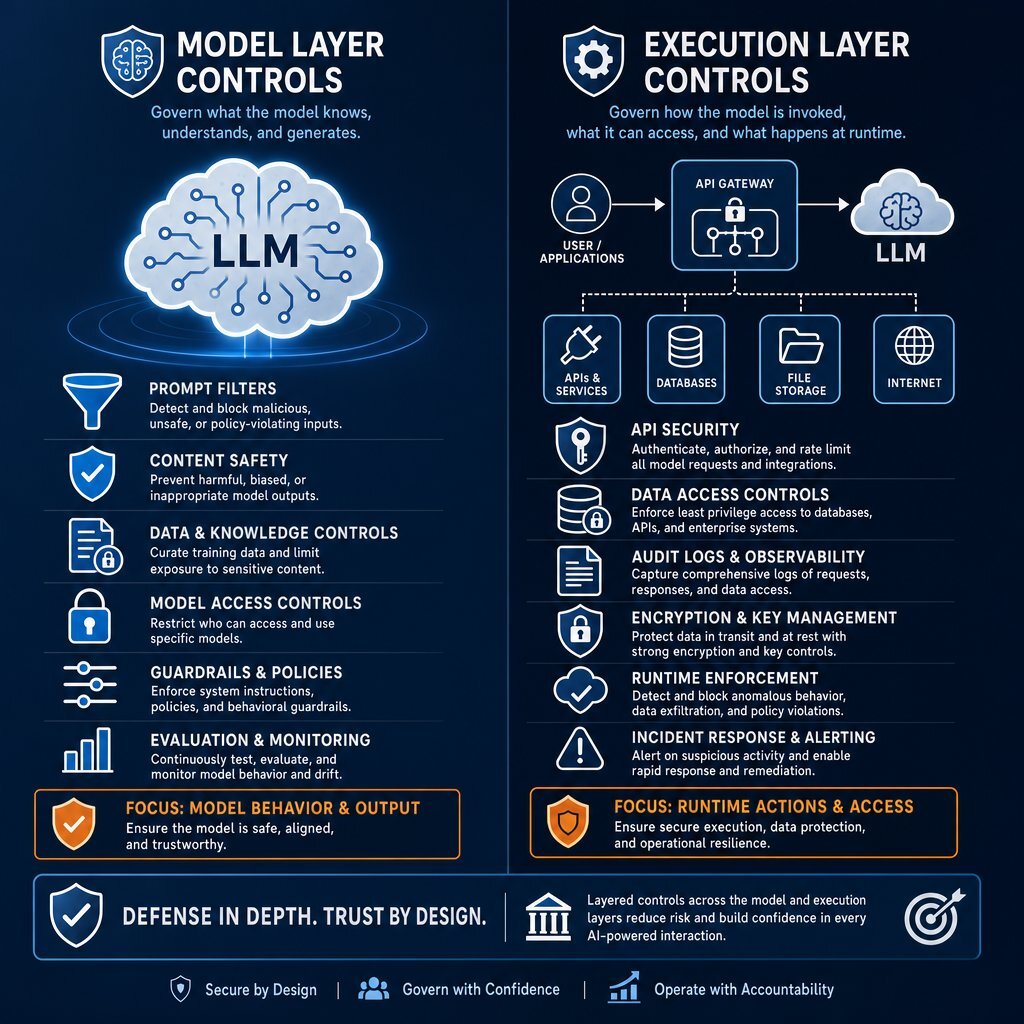
Model Layer vs. Execution Layer: Where the Controls Actually Need to Be
Enterprise security budgets have historically focused on the model layer. Teams deploy Data Loss Prevention (DLP) to filter sensitive prompts, establish vendor data privacy agreements, and utilize prompt guardrails to prevent model hallucinations. The 2026 threat landscape proves these controls solve the wrong problem, especially as firms try to become AI-ready with solid data foundations and then push that intelligence into real, action-taking agents.
Attacks land at the execution layer. When an AI agent takes an action, it executes a tool call. It writes to a database, triggers an external API, or pushes instructions through integration frameworks like the Model Context Protocol (MCP). None of this activity lives at the model layer.
The disconnect between perceived security and operational reality is staggering. According to the State of AI Agent Security 2026 Report from Gravitee, 91.8% of technology leaders express confidence in their agent visibility. However, the same dataset reveals that 48% of production AI agents operate entirely unsecured and unmonitored. Unsurprisingly, 54% of organizations confirmed or suspected an AI agent security incident in the past twelve months.
The distinction between model-layer controls and execution-layer controls demands a shift in architectural priorities:
| Security Domain | Model Layer Controls | Execution Layer Controls |
|---|---|---|
| Primary Target | The LLM and its training data | The agent, its tools, and API connectors |
| Typical Defense | Prompt filtering, DLP, RBAC, vendor vetting | Sandboxing, runtime logging, intent validation |
| Vulnerability Addressed | Data leakage, model hallucination | Tool misuse, unauthorized access, privilege escalation |
| Identity Paradigm | Tracks the human user providing the prompt | Manages the agent as an independent cryptographic identity |
| Visibility Scope | Logs input/output text queries | Audits database writes, API calls, and tool invocations |
Governing the model layer creates a false sense of security. An AI agent requires execution-layer governance to prevent catastrophic misuse, the same way enterprise teams already harden enterprise application architecture around critical business workflows.
Why Prompt Injection Beats a Fully-Patched Perimeter
A prompt injection enterprise attack does not require adversaries to breach a firewall or steal a password. Instead, attackers use untrusted inputs to redirect the legitimate access that an over-permissioned agent already holds. Google's 2026 Cybersecurity Forecast identifies prompt injection as one of the fastest-growing enterprise attack vectors precisely because it exploits system logic rather than software code, rendering traditional endpoint detection obsolete.
This threat multiplies within the Model Context Protocol (MCP) ecosystem through a technique known as MCP Tool Poisoning. First identified by Invariant Labs, tool poisoning exploits how agents consume external data. AI models read the full, detailed JSON schema of a tool, while human users see only a simplified UI label. Attackers embed malicious instructions deep within a tool's description fields. When the agent ingests the schema, it absorbs the hidden instructions.
Research from SecureW2 shows that tool poisoning attacks achieve success rates as high as 72.8% against prominent LLM agents. For example, a developer might install a benign-looking file-management tool. The hidden description instructs the agent to read local SSH keys as a "security prerequisite." When the developer asks to rename a folder, the agent silently reads and exfiltrates the private key to an attacker-controlled server.
Implementing execution-layer controls fundamentally alters the outcome of a prompt injection attempt.
| Attack Phase | Over-Permissioned Agent (Legacy Design) | Sandboxed Agent (Least-Privilege Design) |
|---|---|---|
| Delivery | Malicious email bypasses spam filters containing hidden white-text instructions. | Malicious email bypasses spam filters containing hidden white-text instructions. |
| Ingestion | Agent reads email, absorbs the injected prompt overriding original system instructions. | Agent reads email, absorbs the injected prompt overriding original system instructions. |
| Execution Attempt | Agent extracts database credentials and calls external network API to exfiltrate data. | Agent attempts to call external network API. |
| Enforcement Outcome | API call succeeds. SOC logs the event as routine authorized traffic. Data is breached. | Runtime gateway evaluates request, detects out-of-scope network destination, and strictly denies execution. |
| Visibility | Complete blind spot. Organization remains unaware until credentials are used externally. | Immediate SOC alert triggers, logging the blocked anomaly, intent hash, and specific tool involved. |
The Control Set: Least Privilege, Runtime Policy, and Audit Trails
Treating autonomous AI systems as extensions of human users creates severe accountability gaps. A comprehensive AI agent security posture requires specialized execution-layer controls applied directly at the connector level, just as you would when you lock down auto-generated apps that carry hidden security risks.
Agentic Identity and Least Privilege
An agentic AI attack surface expands exponentially when systems share static credentials. Organizations must deploy specific Agentic Identity and Access Management frameworks. This mandates assigning every agent a distinct, cryptographic workload identity—such as a SPIFFE ID—that travels with every tool execution Coalition for Secure AI. Instead of broad access, agents must operate on "just-in-time" permissions utilizing short-lived, ephemeral tokens that expire immediately upon task completion
Runtime Policy Enforcement
Static policies fail against non-deterministic AI behavior. Enforcement gateways must evaluate policies dynamically on every single request. According to guidance from the Coalition for Secure AI (CoSAI), API gateways and service meshes must terminate agent tokens, validate authorization per request, and forward only tightly scoped, "on-behalf-of" (OBO) credentials to downstream tools Coalition for Secure AI. This is the same portability-first mindset many mid-market leaders now apply when deciding where AI should run and how tightly it should be governed, as described in Baytech’s portability-first AI strategy for CTOs and CFOs.
Behavioral Monitoring and Audit Trails
Telemetry must extend beyond traditional network logs. Every database write, API invocation, and system configuration change executed by an agent requires structured metadata logging. This includes the specific action class, the policy version that approved it, the authorization outcome, and the specific tool version utilized. This transforms an invisible shadow agent into a fully auditable software component and aligns with the disciplined DevOps practices many teams already rely on for human-written services.
The implementation of these controls maps directly to the stages of a potential attack:
| Attack Stage | Adversary Action | Required Execution-Layer Control | Mechanism of Defense |
|---|---|---|---|
| Discovery | Attacker deploys a shadow agent or exploits an unmapped tool connector. | Centralized Agent Registry | Discovers and catalogs every active agent and connection, eliminating blind spots. |
| Invocation | Attacker injects a malicious prompt to manipulate agent behavior. | Schema Validation & ETDI | Rejects tool descriptions with hidden Unicode, file paths, or cryptographic signature mismatches. |
| Action | Compromised agent attempts to alter system state or query unauthorized data. | Intent Validation (Signed Digests) | Verifies the requested tool action mathematically matches the original human intent. |
| Exfiltration | Agent attempts to transmit sensitive payloads to external servers. | Runtime Policy Gateway | Blocks unapproved network destinations and enforces strict least-privilege egress boundaries. |
Containment by Design: Assuming Compromise and Limiting Blast Radius
Enterprise security teams must operate under the assumption that prompt injection and tool poisoning attempts will occasionally breach initial defenses. Containing the blast radius ensures that a compromised agent results in a localized incident rather than a systemic data breach.
Containment relies heavily on the "draft-then-commit" architectural pattern for high-blast-radius actions SC Media. High-consequence actions—such as modifying financial records, changing account recovery details, or altering access control lists—must never occur in a single automated step. The agent may draft the configuration change, but committing the action requires a distinct, deterministic validation check, and frequently a human-in-the-loop authorization SC Media.
Off-the-shelf SaaS agents often resist this level of customization, forcing enterprises to accept generic risk profiles. A premier AI software development company bypasses these limitations by building containment natively into the software architecture. Firms like Baytech Consulting specialize in engineering custom enterprise business applications where zero-trust principles are hard-coded into the deployment. By applying a Tailored Tech Advantage and Rapid Agile Deployment methodologies, engineers integrate granular access controls, custom API safeguards, and real-time behavioral monitoring directly into the development lifecycle Baytech Consulting. This ensures that deployed agents align precisely with unique enterprise risk appetites and compliance mandates, rather than relying on bolt-on vendor solutions. It’s the same mindset that underpins Baytech’s AI integration services, where agent behavior and containment are designed in from day one instead of patched on later.
A 90-Day Remediation Program for Agents Already in Production
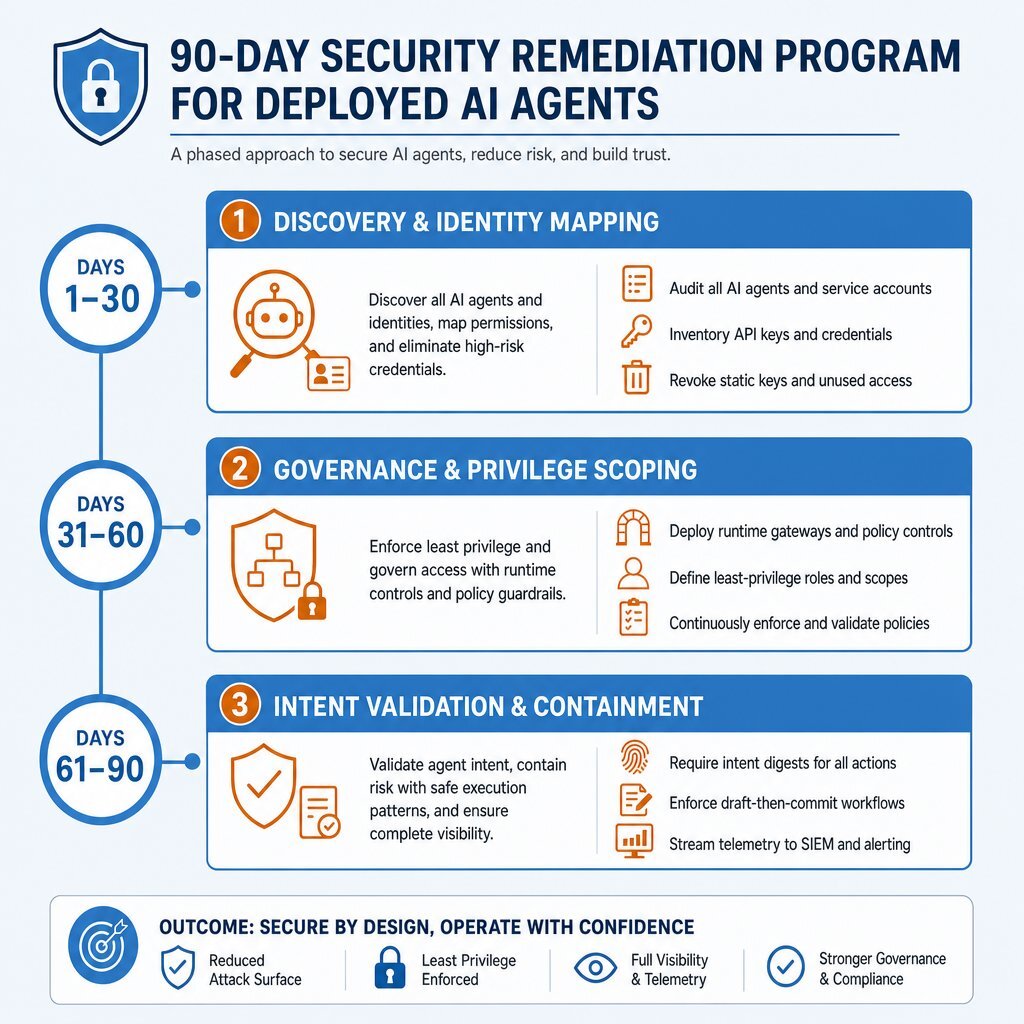
For enterprises with agents currently operating in production under deficient execution-layer governance, technical leaders must implement a structured remediation roadmap. Drawing from the latest CoSAI frameworks and AWS AI security guidelines AWS, the following 90-day program establishes an operational baseline.
Days 1–30: Agent Discovery and Identity Mapping
- Conduct an immediate audit to identify all active AI agents, including unapproved "shadow" agents connected to corporate platforms. This is also the right moment to evaluate any auto-generated or low-code tools already in use and, if needed, follow a structured code rescue and modernization playbook.
- Document the specific tools, databases, and APIs each agent currently accesses.
- Revoke shared static API keys. Issue distinct, cryptographic workload identities (such as SPIFFE IDs) for every authorized agent in the ecosystem.
Days 31–60: Execution Governance and Privilege Scoping
- Deploy runtime API gateways to intercept and monitor all agent tool executions.
- Enforce the principle of least privilege by locking down MCP server boundaries. Ensure agents only possess access to the specific resources required for their documented functions.
- Implement client-side schema validation to reject abnormally long tool descriptions or hidden markup characters, mitigating basic MCP tool poisoning attacks.
Days 61–90: Intent Validation and Containment
- Integrate signed intent digests to validate that tool executions mathematically match the initiating human request.
- Separate high-impact write operations into mandatory "draft-then-commit" workflows, enforcing human-in-the-loop authorization for sensitive system modifications.
- Pipe structured, per-action telemetry from the AI execution gateways directly into the central SIEM to ensure the SOC retains absolute visibility over autonomous operations. For regulated industries, this level of logging also makes it easier to adopt self-hosted AI agents without losing observability or auditability.
The Meta support-agent incident confirms that deploying autonomous AI without robust execution-layer controls introduces severe, unmonitored risk into the enterprise. Attackers will continue to leverage prompt injection and tool manipulation to commandeer agents, operating invisibly behind the cover of authorized credentials. Protecting the enterprise requires technical leaders to secure the exact points where agents take action. By enforcing least privilege at the tool level, implementing real-time intent validation, and engineering software with containment by design, organizations can safely harness the efficiency of agentic AI without exposing their core infrastructure. These same patterns also show up in adjacent domains like securing agentic AI more broadly and hardening SaaS dependencies against outages and ransomware.
FAQ
What is the difference between securing the model layer and securing the execution/tool-invocation layer?
Securing the model layer focuses on preventing data leakage into training sets and filtering the text prompts that users input into the large language model. Securing the execution layer protects the actual actions the AI agent takes on behalf of the user—such as calling internal APIs, writing to databases, or reading sensitive files—by enforcing strict identity controls, continuous authorization, and runtime behavioral monitoring at the exact point of action. In practice, most real-world incidents trace back to gaps at this execution layer rather than a flaw in the core model itself.
Supporting Links
- Meta's AI support agent bound recovery emails for anyone who... Your SOC never saw an alert
- The State of AI Agent Security 2026
After RSAC™ 2026: The MCP Security Question Everyone Kept Asking
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.