
SaaS Scalability Strategies: Executive Guide for Scaling to 1 Million+ Users
September 16, 2025 / Bryan ReynoldsThe story is a modern business classic. A SaaS company achieves product-market fit, and user growth explodes. In the world of software as a service, this cloud-based delivery model promises rapid growth and global reach. Champagne corks should be popping, but instead, the engineering team is in a crisis. The application, once nimble and responsive, now slows to a crawl under the weight of its own success. Pages time out, databases lock up, and customer complaints flood support channels. This isn’t a failure of the product; it’s a failure of planning.
This scenario highlights a critical truth for any B2B executive: application scalability is not a technical afterthought; it is a core business strategy for mitigating risk and enabling sustainable growth. Scalability is the ability of your system to handle an increasing workload without degrading performance, user experience, or cost-efficiency. Scaling SaaS effectively requires a focus on growth and expansion strategies, leveraging robust technical infrastructure and modular architecture to ensure your product can meet rising demand without sacrificing reliability or customer satisfaction. In the context of SaaS products, scalability refers to increasing capacity and maintaining performance, security, and reliability as user demand grows. In business terms, it translates directly to revenue protection, customer retention, and market competitiveness. SaaS scalability is essential for supporting growth and ensuring long-term business success.
This article serves as a strategic guide for executives, not just engineers. It addresses the tough questions about planning for scale, from architectural choices to financial implications, with a focus on building a scalable system from the start. At Baytech Consulting, we guide our clients through these complex technical decisions to achieve their strategic goals. What follows is the kind of transparent, pragmatic advice we provide—a roadmap to ensure that when your “million-user moment” arrives, it’s a cause for celebration, not a crisis.
The Million-User Question: Are We Planning Too Soon or Too Late?
One of the first and most difficult questions a leadership team faces is, “We’re a startup with limited resources. Do we really need to build for a million users now, or should we just get to market as quickly as possible?” This question reveals a fundamental tension between short-term velocity and long-term viability. Navigating this requires avoiding two dangerous traps. When scaling a SaaS business, making the right decision at this stage is crucial for sustainable growth and future success.
On one hand, over-investing in infrastructure too early can waste precious capital and slow your time to market. On the other, under-investing can lead to painful re-architecture and lost customers when you hit scaling bottlenecks. Each approach carries risks and rewards, and understanding the stages of SaaS growth is essential for planning and resource allocation at every phase.
The key is to manage risk intelligently, balancing speed with the ability to adapt as you grow—while always keeping business health at the forefront of your decision-making.
The Danger of Premature Optimization
The first trap is planning too soon . Premature optimization involves over-engineering a solution for a hypothetical future scale that may never materialize. This is a cash-burning exercise that can delay your time-to-market, introduce unnecessary complexity into your product, and waste precious engineering resources solving problems you don’t have yet. Building a system that can handle a million concurrent users when you only have a hundred is not just inefficient; for a startup, it can be fatal. Similarly, developing an overly complex pricing strategy or creating elaborate pricing packages before truly understanding your customers' needs can lead to confusion, misaligned offerings, and hinder your ability to adapt as your business grows.
Avoiding the extremes: Find the safe path between premature optimization and crippling technical debt.
The Peril of Architectural Dead Ends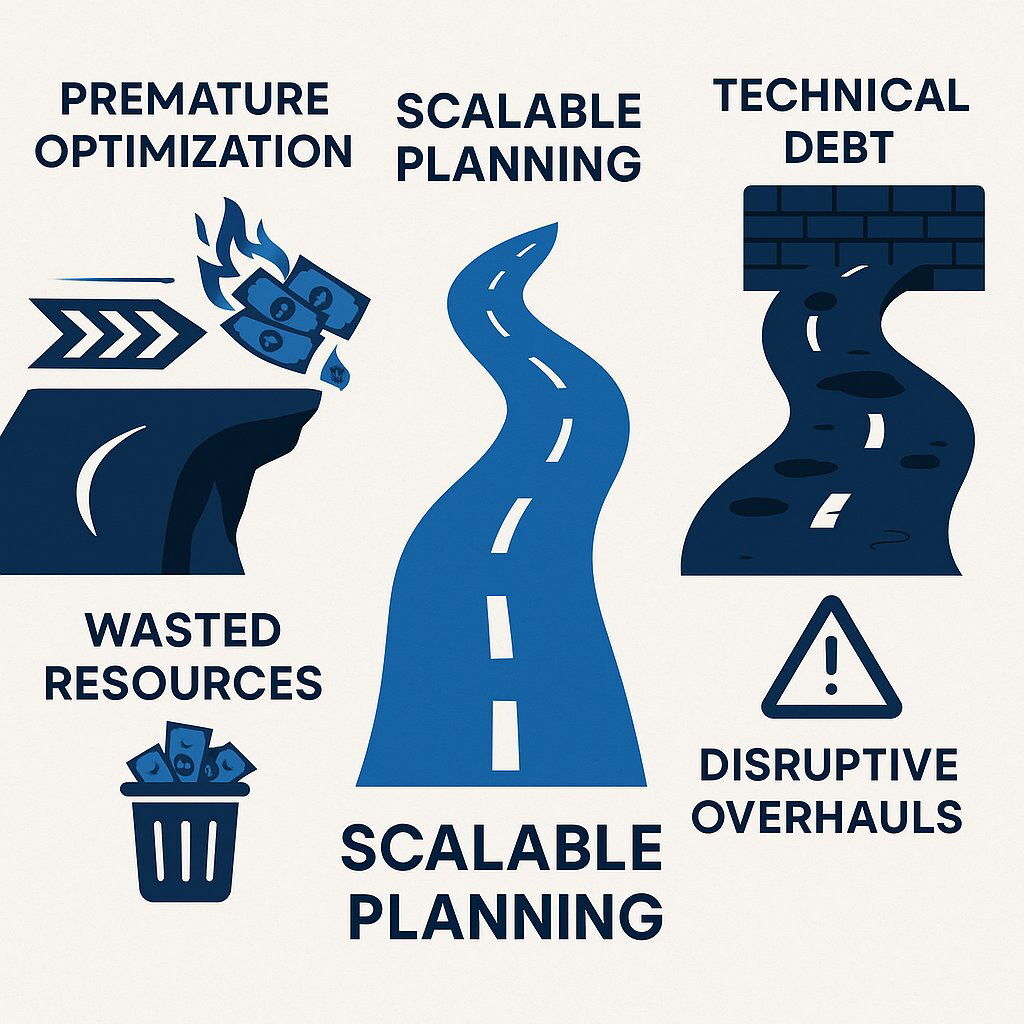
The second, and often more dangerous, trap is planning too late . Ignoring scalability entirely in the rush to build an MVP leads to a “patchy architecture” that accrues crippling technical debt. When rapid growth inevitably arrives, the application hits a wall. The cost, time, and risk required to re-architect a live, mission-critical system can be astronomical, forcing an impossible choice between limping along with a slow, unreliable product or embarking on a massive, business-disrupting overhaul.
The decision of when and how much to invest in scalability is fundamentally a risk management strategy. An unscalable architecture is a direct threat to future revenue. The downtime, poor performance, and eroded brand trust that result from an inability to handle success are not abstract technical problems; they are tangible business liabilities that can cost millions in lost sales and customer churn. Failing to address scalability can also drive up customer acquisition costs and limit the effectiveness of referral programs, as a poor user experience discourages both new signups and loyal customers from recommending your product. The question is not “Can we afford to plan for scale?” but rather “Can we afford the risk of being unprepared for it?”
The Baytech Philosophy: The Scalable Architecture Foundation
The pragmatic path forward is not to build a system for one million users from day one. The goal is to build a system for your first thousand users that can evolve to support one million without a complete rewrite. This is the principle of the “Scalable Foundation.” It involves making deliberate, forward-looking decisions on a few core architectural principles from the very beginning:
- Modularity: Designing the application in distinct, logical components, even if they live in the same codebase initially. Adopting a modular architecture is a best practice, as it enables scalability, flexibility, and easier updates.
- Loose Coupling: Ensuring these components interact through well-defined interfaces, minimizing their dependencies on one another.
- Stateless Design: Architecting application tiers so they don’t retain session-specific data, a critical enabler for seamless scaling.
By embedding these principles from the start, you create an architecture that balances the immediate need for speed with the long-term imperative for growth. Modular architecture allows you to update or scale individual components without disrupting the entire system, making maintenance and expansion much more manageable.
The Blueprint for Growth: Your Core Architectural Decisions
At the heart of a scalable foundation are two pivotal architectural decisions that have profound implications for cost, team structure, and business agility. These are strategic choices that a CTO must make in close consultation with the CEO and CFO. Building a scalable SaaS product requires careful consideration of these architectural decisions to ensure the platform can support future growth and competitiveness.
Making the right choices here lays the groundwork for scaling your SaaS effectively as your user base and feature set expand.
Monolith vs. Microservices: A Strategic Business Choice, Not Just a Technical One
The structure of your application is the single most important factor determining its scalability. The two dominant architectural patterns today are the monolith and microservices.
monolithic architecture is a traditional model where the entire application is built as a single, unified unit. Think of it as a large, all-in-one department store where every function—from sales to inventory to checkout—is under one roof.
A microservices architecture breaks the application down into a collection of small, independent services, each responsible for a single business function. This is akin to a shopping mall with many specialized boutique stores, each operating independently but connected within the larger structure.
The decision between these two is not merely technical; it’s a business trade-off.
The Case for Starting with a Monolith For early-stage companies and new products, a monolithic architecture often offers significant advantages:
- Faster Time-to-Market: With a single codebase and deployment process, development is simpler and faster, which is critical for launching an MVP and validating a business idea. If you’re weighing low-code vs. custom software to boost your speed, this foundational decision really matters.
- Lower Initial Complexity: Small teams can manage a single codebase more easily, reducing cognitive overhead and simplifying testing and debugging.
- Reduced Operational Costs: A monolith requires less initial infrastructure and fewer specialized DevOps skills to deploy and manage.
The Imperative for Microservices As a product matures, a business grows, and teams expand, the limitations of a monolith become apparent. For example, exponential growth in user base or increasing data loads can quickly strain a monolithic system, making it difficult to scale efficiently. This is when a transition to microservices becomes a strategic necessity, driven by business needs such as entering new markets:
- Independent Scalability: This is the primary driver. In an e-commerce application, for example, the product search service might receive 100 times more traffic than the payment service. Microservices allow you to scale only the search service, leading to massive cost and resource efficiency compared to scaling the entire monolithic application.
- Improved Fault Isolation: In a microservices architecture, the failure of one service (like recommendations) doesn’t bring down the entire application (like checkout), dramatically improving overall system reliability.
- Organizational Scaling: Microservices allow you to structure engineering teams around specific business capabilities. Small, autonomous “two-pizza teams” can develop, deploy, and maintain their services independently, enabling parallel development and accelerating feature delivery in a large organization.
The Pragmatic Path: The Modular Monolith The transparent answer is that diving headfirst into microservices from day one is often a mistake. The pattern introduces significant operational complexity, including network latency, distributed data management, and intricate testing scenarios that require a mature DevOps culture and specialized tooling. Recent industry trends have even seen some high-profile companies migrate
back from microservices to monoliths after finding the operational costs and complexity outweighed the benefits for their specific use cases. This is not an indictment of the microservices pattern itself, but a powerful lesson against adopting it based on hype rather than a clear business case.
The expert recommendation is to begin with a modular monolith . This approach involves building a single application but enforcing strict, logical boundaries between its internal components. This gives you the initial development speed of a monolith while making it vastly easier to extract these well-defined modules into independent microservices later, when the need for independent scaling and deployment becomes a clear business priority.
This architectural choice is a direct reflection of your organization’s structure and maturity. A monolithic codebase requires tight coordination, which is natural for a small, centralized team. A microservices architecture, conversely, demands team autonomy and decentralized decision-making to be effective. An attempt to implement microservices without the corresponding organizational structure and DevOps maturity often results in a “distributed monolith”—a system with all the operational complexity of microservices but none of the benefits of true independence. Therefore, when an executive chooses an architecture, they are also making a decision about how to structure their engineering organization.
| Dimension | Monolithic Architecture | Microservices Architecture |
|---|---|---|
| Initial Time-to-Market | Faster. Simpler to build, test, and deploy a single unit. | Slower. Requires significant upfront investment in infrastructure, CI/CD, and service discovery. |
| Scalability | Challenging. The entire application must be scaled as one, even if only one feature is under heavy load. | High. Individual services can be scaled independently, optimizing resource use and cost. |
| Reliability (Fault Isolation) | Low. A failure in one component can bring down the entire application. | High. Failure is isolated to a single service, minimizing impact on the overall system. |
| Team Structure | Ideal for small, co-located teams that can easily coordinate on a single codebase. | Aligns with large, distributed, or autonomous teams organized around business capabilities. |
| Operational Complexity | Low. Managing a single application and database is straightforward. | High. Requires mature DevOps practices for managing distributed systems, networking, and monitoring. |
| Initial Cost | Lower. Less infrastructure and specialized tooling required to get started. | Higher. Requires investment in container orchestration, service mesh, and advanced monitoring tools. |
| Long-Term Cost | Can become high due to inefficient scaling and maintenance challenges as the codebase grows. | Can be more cost-effective at scale due to efficient, granular resource allocation. |
Stateless Architecture: The Unsung Hero of Massive Scalability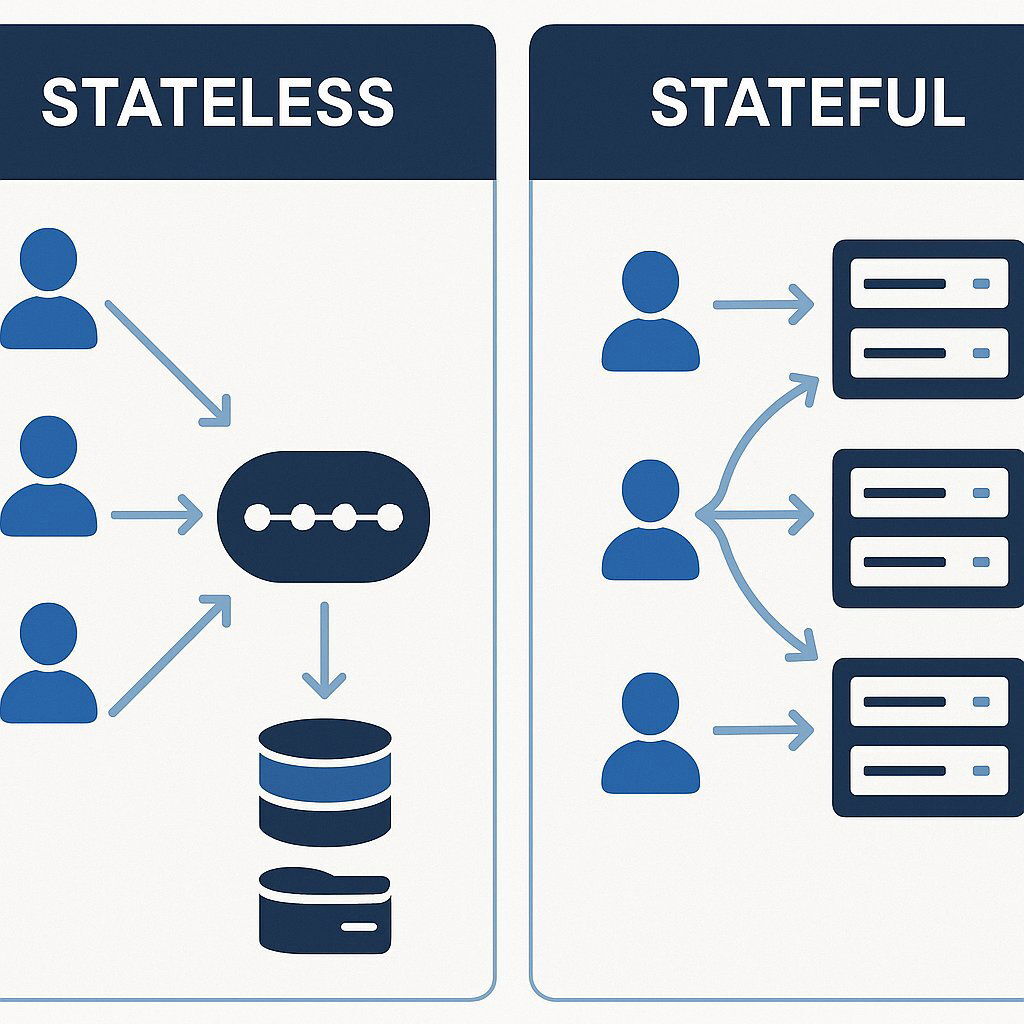
The second foundational decision is designing your application to be stateless . A stateless server treats every request as an independent transaction, without relying on any memory of previous interactions. All information needed to process the request is contained within the request itself. Think of it like a call center agent with no access to past call history; you have to provide your account number and explain your issue every time you call.
Conversely, a stateful server “remembers” past interactions, storing session data like items in a shopping cart or a user’s login status.
Why stateless architecture enables seamless horizontal scaling and reliability.
This distinction is critical for scalability. Because any stateless server can handle any request from any user at any time, it is trivial to add more servers behind a load balancer to handle increased traffic. As user demand grows, stateless architecture ensures your system can easily accommodate more users and higher data loads without major reconfiguration. If one server fails, the traffic is seamlessly rerouted to another healthy server with no loss of user context. This makes the system incredibly resilient and allows for smooth, horizontal scaling—the cornerstone of any application built for massive growth.
Stateful applications are notoriously more difficult to scale horizontally. They often require “sticky sessions,” where a user must be routed back to the same server that holds their session data. This complicates load balancing, creates single points of failure, and makes it difficult to dynamically add or remove servers. While some applications inherently require state, a core principle of scalable design is to push state out of the application tier and into a dedicated, external store (like a database or a distributed cache) whenever possible.
The Scaling Toolkit: Key Technologies and Strategies
With a sound architectural foundation, the next step is to understand the specific tools and techniques used to achieve scalability. These tools are essential to scale your SaaS and scale efficiently, enabling your business to handle increased demand while optimizing resources.
In addition to technical strategies, content marketing is a key approach for attracting potential customers, supporting SEO efforts, and establishing your brand as a thought leader in the industry.
Focusing on operational efficiency is also crucial, as it ensures your scaling efforts are sustainable and attractive to investors.
Scaling Up vs. Horizontal Scaling: Why You Can't Just Buy a Bigger Server
There are two fundamental ways to increase an application’s capacity:
- Vertical Scaling (Scaling Up): This involves adding more power (CPU, RAM) to an existing server. It’s like replacing your delivery van with a larger truck to carry more packages.
- Horizontal Scaling (Scaling Out): This involves adding more servers to distribute the workload. It’s like adding more vans to your delivery fleet.
Why horizontal scaling (scaling out) beats just buying bigger servers (scaling up) for massive growth.
While vertical scaling is simple and can be a quick fix for initial performance issues, it has a hard physical and financial ceiling. You eventually run out of bigger servers to buy, and the cost increases exponentially. More importantly, it creates a single point of failure and typically requires downtime for upgrades.
Horizontal scaling is the key to massive, near-infinite scalability and high availability. It allows for the use of cheaper, commodity hardware, improves system resilience (if one server fails, others take over), and allows for scaling without downtime. In modern cloud-native design, systems can automatically adjust resources to meet demand, scaling up or down as needed without manual intervention. This optimizes both efficiency and cost management.
Taming the Database Bottleneck
In the journey to one million users, the database is almost always the first and most significant bottleneck an application will encounter. A logical, phased approach is crucial for addressing database performance issues without introducing unnecessary complexity. Database scaling is a critical strategy to maintain performance, prevent slowdowns, and ensure security as user demand increases.
Scale your database step-by-step—optimize first, then add caching, replicas, and sharding as needed.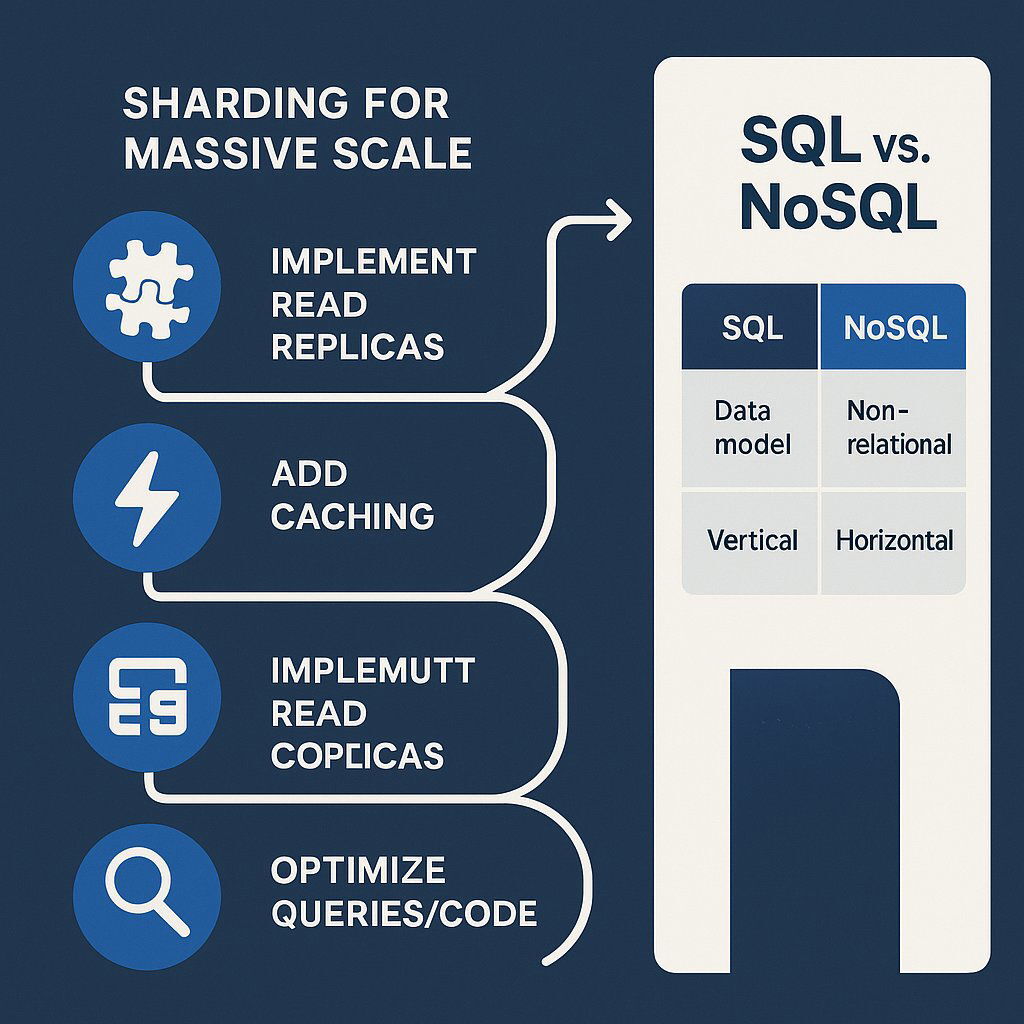
- Optimize First: Before changing any infrastructure, the first step is always to optimize your code and database queries. Inefficient queries, missing indexes, and poor data models are the most common culprits of poor performance. It is always cheaper and more effective to fix inefficient code than to throw more hardware at the problem.
- Implement Caching: Caching is the most powerful and least disruptive architectural change for improving database performance. By storing frequently accessed data in a fast, in-memory cache like Redis or Memcached, you can serve a large percentage of requests without ever touching the database. This dramatically reduces database load and improves response times. A common strategy is
cache-aside (or lazy loading) , where the application first checks the cache for data; if it’s not there (a “cache miss”), it retrieves the data from the database and then populates the cache for subsequent requests. 3. Use Read Replicas: For applications that have many more reads than writes (a common pattern for content sites, e-commerce catalogs, etc.), read replicas are the next logical step. A read replica is a read-only copy of your primary database. By directing all read traffic to one or more replicas, you free up the primary database to focus exclusively on handling write operations, effectively doubling your database capacity for many workloads. 4. Implement Sharding (Partitioning): For applications with massive datasets and extremely high write volumes, sharding becomes necessary. Sharding is the process of horizontally partitioning a database across multiple servers. Each server (or “shard”) holds a subset of the data. For example, users A-M might be on Shard 1, and users N-Z on Shard 2. This allows for near-limitless scaling of write capacity. However, sharding introduces significant complexity. Queries that span multiple shards are more difficult to execute, and managing data consistency and rebalancing shards is a major operational challenge. It should be considered a final step after all other optimization strategies have been exhausted. 5. Choose the Right Database (SQL vs. NoSQL): The type of database itself is a strategic decision.
- SQL (Relational) Databases like PostgreSQL and MySQL are excellent for structured data and enforcing transactional consistency (known as ACID properties). They are the default for many applications, but scaling them horizontally has traditionally been more complex.
- NoSQL (Non-relational) Databases like MongoDB or DynamoDB were designed from the ground up for horizontal scaling and flexible data models. They are ideal for handling large volumes of unstructured data and high-traffic applications but often make trade-offs on transactional consistency.
When optimizing for performance, it is especially important to ensure a seamless experience for paying customers, as their satisfaction directly impacts revenue and retention.
Leveraging Elastic Cloud Infrastructure
Modern cloud platforms like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) are the foundational enablers of scalability, providing the tools to build dynamic, resilient systems.
The essential toolkit for building scalable, cloud-native applications.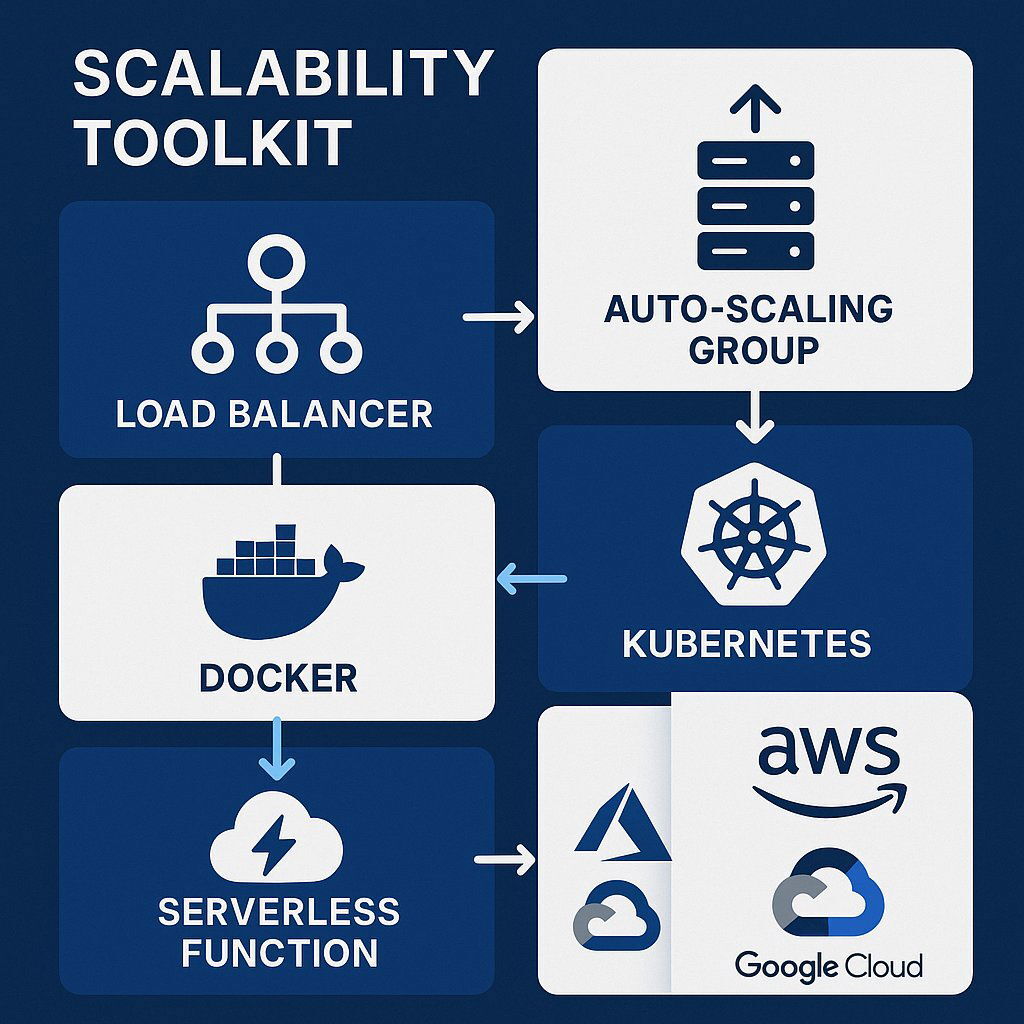
- Load Balancing: A load balancer acts as a “traffic cop,” sitting in front of your application servers and distributing incoming requests evenly across them. This prevents any single server from becoming a bottleneck and is essential for achieving high availability and enabling horizontal scaling.
- Auto-Scaling: This is the feature that makes the cloud “elastic.” Auto-scaling groups automatically add or remove servers based on real-time metrics, such as CPU utilization or the number of requests. During a traffic spike, the system automatically scales out to meet demand, ensuring performance. When traffic subsides, it scales in to reduce costs.
- Content Delivery Networks (CDNs): Content delivery networks distribute static content, such as images and videos, closer to users worldwide. By caching assets at edge locations, CDNs reduce server load, speed up content delivery, and significantly enhance user experience and application performance.
- Containerization (Docker & Kubernetes): Containers, managed by platforms like Docker , package an application and all its dependencies into a standardized, portable unit. This ensures that the application runs consistently across any environment. Kubernetes is a container orchestration platform that automates the deployment, scaling, and management of these containers at scale. It can automatically handle tasks like load balancing, self-healing (restarting failed containers), and scaling, forming the backbone of most modern, scalable microservices architectures.
- Serverless Computing (FaaS): Serverless, or Function-as-a-Service, is the ultimate abstraction of infrastructure. Developers simply write and upload code in the form of functions, and the cloud provider handles everything else—provisioning, managing, and scaling the underlying compute resources. The application scales automatically and infinitely on demand, and billing is based on the number of executions and duration, often measured in milliseconds. This model is incredibly cost-effective for event-driven or unpredictable workloads but can be less suitable for long-running, compute-intensive processes.
The Financial Equation: Scaling Without Spiraling Costs and Managing Customer Acquisition Cost
For a CFO, the promise of infinite scalability comes with a terrifying question: “Will scaling to a million users bankrupt us?” Elastic cloud infrastructure is a double-edged sword; while powerful, its pay-as-you-go nature can lead to runaway costs if not managed proactively and strategically. In addition to cost management, aligning your marketing strategy and broader marketing strategies with your scaling plans is crucial to ensure resources are allocated efficiently and growth is sustainable.
The choice of cloud service model has a profound impact on the Total Cost of Ownership (TCO), which includes not just the direct infrastructure bill but also the indirect operational and personnel costs.
Choosing—and optimizing—the right cloud cost model is essential for sustainable scaling.
- Infrastructure-as-a-Service (IaaS) provides raw building blocks like virtual machines. It offers the most control but carries the highest operational overhead, as your team is responsible for managing everything from the operating system upwards. This requires a larger, more skilled DevOps team.
- Platform-as-a-Service (PaaS) abstracts away the underlying OS and middleware, allowing teams to focus on deploying and managing applications. This reduces the operational burden and can lower TCO, even if the direct platform costs are slightly higher.
- Serverless (FaaS) is the highest level of abstraction, eliminating almost all infrastructure management. This drastically reduces operational staff costs but can become expensive for workloads with constant, high-volume traffic.
- Embracing product led growth can also drive efficient scaling by leveraging user-friendly design and organic adoption, reducing reliance on costly acquisition channels.
An executive decision on a cloud model should always be based on a TCO analysis that balances direct cloud spend with the indirect costs of the engineering talent required to manage it.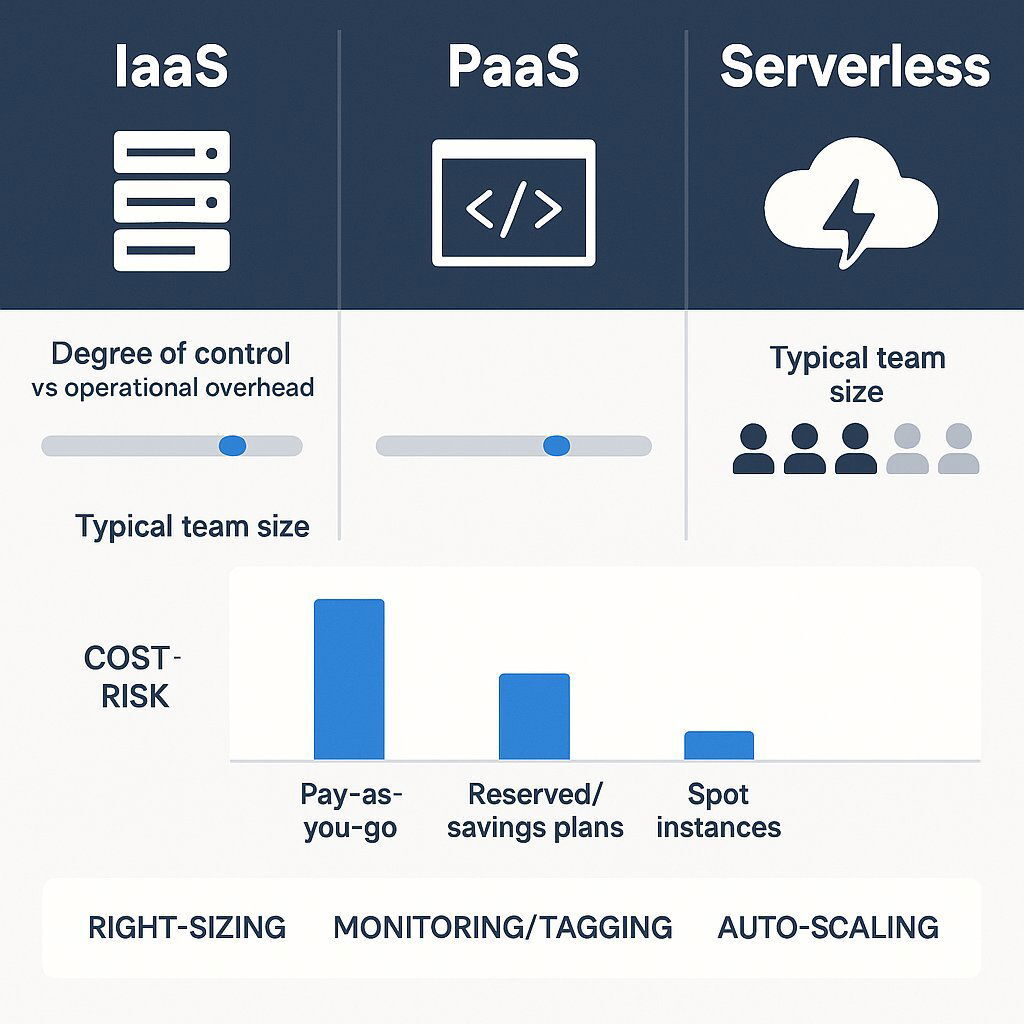
Cloud Cost Optimization 101
Several key strategies are essential for controlling cloud spend:
- Right-Sizing: This is the fundamental practice of continuously analyzing workload performance and adjusting the size and type of cloud resources to match the actual need. Over-provisioning—paying for capacity you don't use—is the single largest source of wasted cloud spend.
- Leveraging Pricing Models: Cloud providers offer different pricing models that create significant opportunities for savings. Understanding these is crucial for financial governance.
- Monitoring and Tagging: You cannot optimize what you cannot measure. Implementing a robust tagging strategy—labeling every cloud resource with metadata like project, team, or feature—is critical. This allows you to attribute costs accurately and identify which parts of the business are driving spend.
| Pricing Model | Best For | Key Benefit | Key Risk |
|---|---|---|---|
| Pay-As-You-Go | Unpredictable workloads, development, and testing environments. | Maximum flexibility; no upfront commitment. | Highest per-hour cost. |
| Reserved Instances / Savings Plans | Stable, predictable workloads with known long-term needs. | Significant discounts (up to 72%) for a 1 or 3-year commitment. | Underutilization if workload decreases, leading to wasted spend. |
| Spot Instances | Fault-tolerant, non-critical workloads like batch processing or data analysis. | Deepest discounts (up to 90%) on spare cloud capacity. | Instances can be terminated by the cloud provider with little notice. |
The Power of Automation for Cost Control
- Auto-Scaling: While primarily a performance tool, auto-scaling is also a powerful cost optimization mechanism. Its ability to automatically scale down resources during off-peak hours ensures you are not paying for idle capacity.
- Serverless Models: With a pay-per-execution model, serverless computing offers the ultimate defense against idle costs. If a function is never called, its cost is zero. This makes it an incredibly efficient choice for applications with intermittent or unpredictable traffic patterns.
- FinOps Culture: Ultimately, cost optimization is not just a tool but a culture. FinOps is an emerging practice that brings together finance, engineering, and business teams to foster a culture of financial accountability for cloud spending. It makes cost a first-class metric, empowering teams to make trade-off decisions that balance performance, features, and cost to maximize business value.
Don't Guess, Test: The Role of Performance Engineering
Architectural plans and scalability strategies are purely theoretical until they are validated under real-world pressure. The mantra of performance engineering is simple: You can’t scale what you don’t measure . Rigorous performance testing is the only way to gain data-driven confidence that your application can handle the load of a million users. During these tests, it is also critical to validate processes like customer onboarding, which directly impact user engagement and retention.
Continuous performance testing and business-focused metrics help ensure readiness for one million users.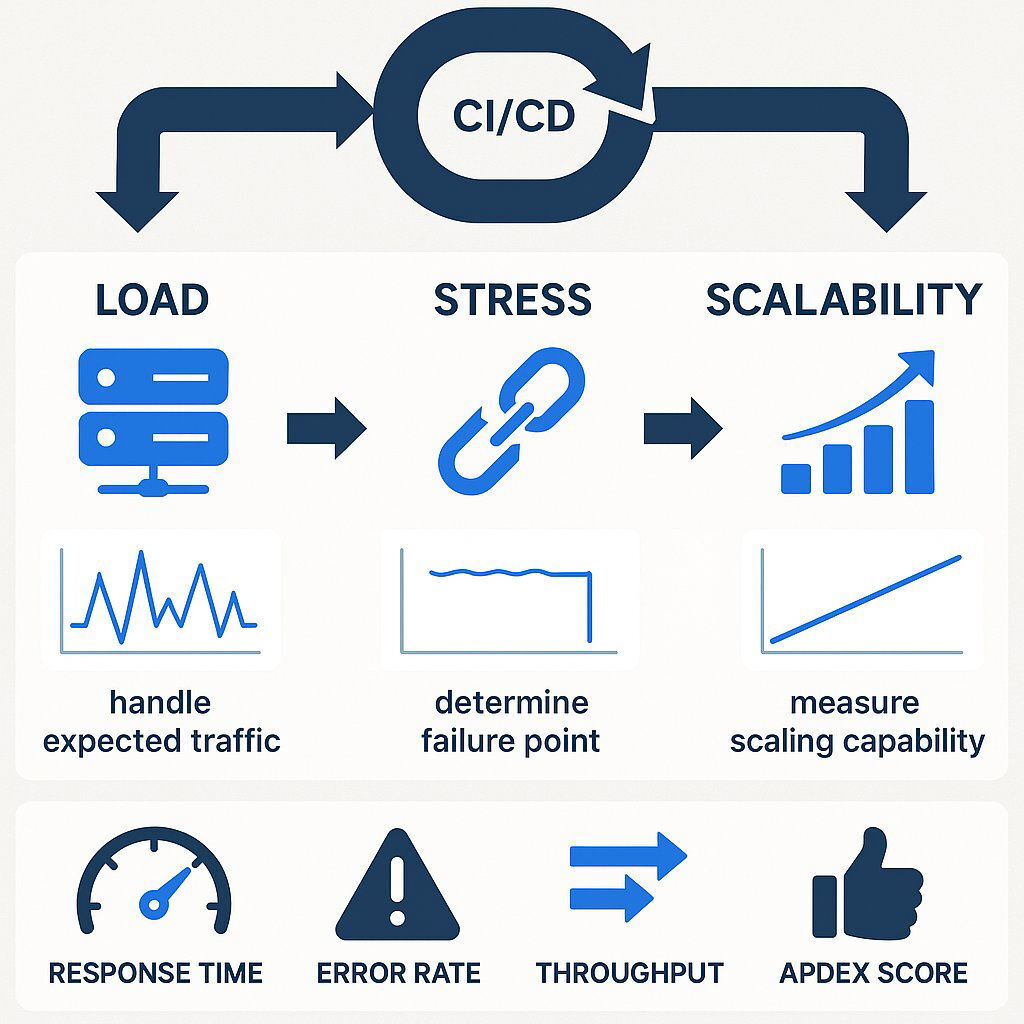
A mature DevOps culture is a prerequisite for, not a result of, effective scalability. The ability to automatically provision test environments, run tests as part of a CI/CD pipeline, and rapidly deploy fixes is foundational. Attempting to scale a complex application with traditional, manual operational processes is a recipe for failure. The budget for scalability must, therefore, include a corresponding investment in the DevOps team, tools, and culture that make it possible. In addition, aligning the sales team and intentionally shaping company culture are essential to support organizational growth and ensure all teams are prepared for scaling efforts.
An Overview of Performance Testing Types
Several types of testing are critical for validating scalability:
- Load Testing: Simulates expected user traffic to measure how the system performs under normal and anticipated peak conditions. This answers the question, "Can our application handle a typical busy Tuesday afternoon?".
- Stress Testing: Pushes the system beyond its designed capacity to find its breaking point. This helps understand failure modes and ensures the system degrades gracefully rather than crashing catastrophically. It answers, "What happens during a Black Friday sales event, and how does the system recover?".
- Scalability Testing: Specifically designed to verify that the architecture scales as expected. The load is gradually increased to confirm that auto-scaling mechanisms trigger correctly, new instances are added seamlessly, and performance remains stable as the system grows. It answers the critical question, "Does our horizontal scaling strategy actually work?".
Performance testing should not be a one-time event before a major launch. It must be integrated into the Continuous Integration/Continuous Deployment (CI/CD) pipeline , allowing teams to automatically run tests with every code change and catch performance regressions early in the development cycle.
Key Metrics That Matter to the Business
While engineers track hundreds of metrics, leadership should focus on a few key performance indicators (KPIs) that directly translate to business outcomes:
- Response Time: The time a user waits for a page to load or an action to complete. This is a primary driver of user satisfaction and conversion rates. Fast response times not only improve retention but also help attract potential customers and new customers, as positive user experiences are crucial for both acquisition and growth.
- Error Rate: The percentage of user requests that result in an error. This is a direct measure of application reliability and a key indicator of user frustration.
- Throughput: Measured in requests per second or transactions per minute, this represents the system’s total capacity. It tells you how much business your application can handle at any given time.
- Apdex (Application Performance Index) Score: A standardized metric that consolidates response time and error rates into a single score from 0 to 1, representing overall user satisfaction. It provides a simple, high-level view of application health that is easy for non-technical stakeholders to understand. Maintaining a high Apdex score is essential for building strong customer relationships, which supports long-term business success.
Customer Success and Retention: The Secret Engine of Sustainable Growth
For SaaS businesses, reaching one million users is only half the battle—the real challenge is keeping them. As your SaaS company grows, customer success and retention become the linchpins of sustainable growth. It’s not enough to simply acquire new users; you must consistently deliver value, exceed customer expectations, and ensure that your platform remains indispensable to both new and existing customers.
A scalable architecture is the foundation that enables SaaS platforms to meet rising user demand without sacrificing service quality. When your systems are built for consistent performance, you can confidently onboard more users, roll out new features, and support diverse customer segments—all while maintaining the high level of customer satisfaction that drives referrals and renewals.
Efficient systems are critical here. They allow your team to respond quickly to customer feedback, resolve issues before they escalate, and personalize the user experience at scale. This operational agility is what transforms a growing user base into a loyal community, reducing churn and maximizing lifetime value.
Customer success isn’t just a department—it’s a company-wide commitment. From product development to support, every function should be aligned around helping customers achieve their goals. Proactive onboarding, clear communication, and robust self-service resources empower users to get the most from your SaaS platform, while data-driven insights help you anticipate needs and address pain points before they impact satisfaction.
Ultimately, the most successful SaaS businesses are those that view customer retention as a strategic priority, not an afterthought. By investing in scalable architecture and efficient systems, your SaaS company can deliver the consistent performance and customer success that fuel sustainable growth—turning one million users into one million advocates.
Market Research and Analysis: Understanding Your Growth Landscape
Scaling a SaaS business to one million users and beyond requires more than just robust technology—it demands a deep understanding of your market, your customers, and the competitive landscape. Market research and analysis are the compass that guides SaaS companies through the complexities of sustainable growth, ensuring every strategic move is grounded in real-world data and evolving customer expectations.
For SaaS businesses, market research is not a one-time exercise but an ongoing process that uncovers critical insights about customer segments, user demand, and emerging trends. By systematically gathering and analyzing data, SaaS companies can identify what drives customer satisfaction, where operational costs can be optimized, and how to refine their marketing strategies for maximum impact. This intelligence is essential for reducing customer acquisition costs, improving conversion rates, and ensuring that your sales team is targeting the right potential customers with the right messaging.
A thorough market analysis also shines a light on the competitive landscape. By evaluating competitors’ offerings, pricing packages, and customer feedback, SaaS businesses can spot gaps in the market and opportunities for differentiation. This enables you to fine-tune your pricing strategy, prioritize the development of new features, and ensure your scalable architecture is designed to support the unique needs of your target audience. Whether you’re entering new markets or focusing on niche markets, these insights help you scale efficiently and maintain a competitive edge.
From a technical perspective, market research informs decisions about scalable infrastructure, horizontal scaling, and database scaling. Understanding projected user demand and customer onboarding patterns allows you to design a scalable system that can handle increasing data loads, multiple servers, and the operational demands of exponential growth. Leveraging cloud providers like Google Cloud, implementing load balancing, and utilizing content delivery networks all become more effective when guided by accurate market data.
Moreover, market research is vital for supporting product-led growth and ensuring your SaaS platform delivers consistent performance as user demand grows. By listening to customer feedback and monitoring user satisfaction, you can iterate quickly, address pain points, and deliver new features that resonate with both existing customers and new users. This continuous feedback loop is key to building strong customer relationships, driving customer retention, and supporting the next growth phase of your SaaS company.
In summary, market research and analysis are indispensable tools for scaling a SaaS business. They empower you to make informed decisions about your pricing model, marketing strategy, and technical roadmap, all while keeping business health and customer success at the forefront. By prioritizing market research, SaaS companies can unlock new opportunities, mitigate risks such as data breaches, and build a scalable SaaS product that stands the test of time. In the fast-paced world of software as a service, those who understand their growth landscape are best positioned to achieve sustainable growth, deliver exceptional user satisfaction, and secure long-term success.
Conclusion: Your Roadmap to 1 Million Users and Beyond
The journey from one user to one million is not a straight line. It is a series of strategic decisions and technical trade-offs that must be navigated with foresight and expertise. Waiting for a growth-induced crisis to think about scalability is a strategy for failure. Planning for it from day one is a strategy for enduring success. In conclusion, scaling requires a deliberate approach to strategic growth, ensuring your business is prepared to attract and retain customers while maintaining robust technical infrastructure.
The core pillars of a scalable application can be summarized as follows:
- Start with a Scalable Foundation: Build your initial product on sound architectural principles like modularity and statelessness. Don’t over-engineer for a hypothetical future, but create a system that is designed to evolve. Looking for even deeper strategies? Explore our guide to software and AI asset management for managing risk and resilience as you scale.
- Make Architecture a Business Decision: Align your technical architecture—whether a monolith, microservices, or a hybrid—with your team structure, budget, and time-to-market requirements. Review how AI-driven SDLC approaches can further future-proof your roadmap.
- Leverage the Cloud Intelligently: Use the powerful, elastic tools of modern cloud platforms like auto-scaling, load balancing, and containerization as strategic assets, not just infrastructure. To dive into best practices for agility and resilience, see our executive blueprint for cloud-native business architecture.
- Manage Costs Proactively: Treat cloud spend as a variable to be actively managed through right-sizing, smart pricing models, and a culture of financial accountability (FinOps).
- Test, Measure, and Iterate: Make scalability an engineering discipline. Use rigorous load, stress, and scalability testing to make data-driven decisions and validate that your system can handle the success you are working to achieve. For more on ensuring ROI and necessary coverage, check our guide to software testing for B2B leaders.
Every SaaS business should proactively plan for scale, ensuring that growth does not compromise performance or customer experience.
Navigating this journey is complex. The right choices depend heavily on your specific business context, product, and team. At Baytech Consulting, we specialize in helping businesses traverse this path. As a next step, we often recommend a Scalability Audit —a comprehensive assessment of your current architecture, processes, and infrastructure to identify potential bottlenecks and create a strategic, actionable roadmap for future-proof growth. SaaS companies can especially benefit from a scalability audit to overcome growth challenges and ensure their technical strategies support expansion. Planning today ensures that when your millionth user signs up, your business is ready.
Supporting Articles:
- Martin Fowler, “Microservices”: https://martinfowler.com/articles/microservices.html
- Microsoft Azure, “Azure Cost Management and Billing best practices”: https://learn.microsoft.com/en-us/azure/cost-management-billing/costs/cost-mgt-best-practices
- ByteByteGo, “0 to 1.5 Billion Guests: Airbnb’s Architectural Evolution”: https://bytebytego.com/guides/real-world-case-studies/
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.