
Software Maintenance Mastery: Executive Guide to Post-Launch Success
September 14, 2025 / Bryan ReynoldsYour Software is Live, Now What? A Guide to Effective Maintenance & Evolution
The champagne has been popped, the launch-day metrics looked good, and the team took a well-deserved breath. But now, a week later, the real work begins. The question "Now what?" echoes in every strategy meeting, from the CTO's office to the CFO's budget review. The initial victory of a successful launch quickly gives way to the complex, long-term reality of managing a living, breathing software asset. This article is the definitive answer to that question.
The post-launch phase should not be viewed as a dreaded cost center, but as the most critical stage for maximizing your software's long-term value and return on investment (ROI). Launching isn't the finish line; it's the start of a continuous process of refinement, adaptation, and evolution that separates market leaders from the competition. This guide provides a strategic framework for navigating the challenges, managing the costs, and harnessing the technologies that turn a newly launched product into a durable competitive advantage.
Part 1: The Reality Check — Navigating the Critical First 90 Days
The first three months after launch are a crucible where a meticulously planned software product meets the unpredictable reality of the market. This is the transition from a controlled test environment to the dynamic, often chaotic, world of real-world usage. Successfully navigating this period requires anticipating the challenges before they become crises.
From Theory to Traffic: The Performance Gauntlet
The Challenge: Your software, which performed flawlessly in staging environments, now faces the true test: real user traffic. Pre-launch load and stress testing, while essential, are based on assumptions. Real users are unpredictable. They might all log on simultaneously at 9 AM every Monday, creating a "warm-up" period of sluggishness. Or, a small but powerful group of users might become obsessed with a new reporting feature, running complex queries that create database cache inefficiencies your team never anticipated.
The Business Impact: Slow load times and poor performance are not minor annoyances; they are business killers. In a competitive market, user patience is razor-thin. Research shows that 40% of users will uninstall an application due to poor performance, and a staggering 80% will abandon it after just one bad experience. For a B2B platform, this translates directly into failed user adoption, higher customer churn, and a direct hit to projected revenue streams.
The Strategy: Proactive monitoring is non-negotiable. From day one, implement effective, real-time monitoring tools to track both system performance and user behavior. This goes beyond simply watching server load. It means tracking key user experience metrics like bounce rate (how many users leave after viewing only one page), session duration (how long they stay engaged), and page load time to identify bottlenecks before they escalate into widespread problems.
The Inevitable Bug Hunt
The Challenge: No software, no matter how rigorously tested, launches completely bug-free. Despite the best Quality Assurance (QA) efforts, bugs will be discovered in the production environment. These can range from minor user interface (UI) glitches that erode user confidence to critical, system-breaking failures that halt business operations and cause immediate revenue loss. The pressure to identify, prioritize, and resolve these issues is intense and immediate.
The Business Impact: The financial consequences of a bug escalate dramatically the later it is discovered in the software development lifecycle (SDLC). According to research from IBM's Systems Sciences Institute, a bug found in production can cost four to five times more to fix than one caught during design, and up to 100 times more than one identified even earlier. This cost isn't just the developer's time. It's a cascade of expenses, including increased customer support calls, potential service-level agreement (SLA) penalties, brand and reputation damage, and the opportunity cost of pulling developers off planned feature development to fight fires.
The Strategy: A reactive, ad-hoc approach is a recipe for disaster. Establish a dedicated rapid response team empowered to act the moment a critical issue is identified. This team's mandate should include not only fixing the bug but also communicating transparently with users about the problem and the expected resolution time. This transparency fosters trust even during a crisis. A tight, continuous feedback loop where users can easily report issues is essential to pinpoint and crush bugs quickly, turning a potential catastrophe into a demonstration of your company's responsiveness.
Opening the Floodgates: Managing the Initial Wave of User Feedback
The Challenge: A successful launch triggers a deluge of user feedback. This torrent of information contains everything from bug reports and minor complaints to brilliant feature requests and insightful suggestions for improvement. Without a structured system to capture and analyze this input, this treasure trove of market intelligence becomes overwhelming noise, and valuable opportunities are lost.
The Business Impact: Ignoring this initial wave of feedback is a critical strategic error. It leads to user dissatisfaction, a feeling of being unheard, and a product that quickly falls out of alignment with real market needs. Conversely, systematically harnessing this feedback is the cornerstone of agile, customer-centric product development. It allows you to validate your initial assumptions and prioritize a roadmap that delivers genuine value, driving long-term growth and customer loyalty.
The Strategy: Implement a robust, multi-channel feedback system before you launch. This system should make it easy for users to provide input through various means, including in-app feedback forms, targeted surveys, engagement on social media platforms, and even structured customer interviews or focus groups. The goal is not just to collect feedback, but to have a process in place to categorize, analyze, and begin prioritizing this input from the very first day.
These post-launch challenges are not isolated incidents; they are deeply interconnected and can create a vicious cycle. A performance issue, like slow report generation, doesn't just exist in a technical vacuum. It generates a flood of user complaints and support tickets, which must be managed. The development team is then pulled away from planned work on new, value-adding features to firefight the performance bug. This constant reactive state leads to team burnout and makes it difficult to retain the top engineering talent needed to solve the underlying problems. Suddenly, the business faces a cascade of compounding problems: dissatisfied users, a demoralized team, a growing backlog of valuable feature requests, and a product that is stagnating instead of evolving. This demonstrates that a holistic strategy anticipating technical, user, and team challenges is not a luxury; it is essential for surviving and thriving in the first 90 days.
Part 2: A Framework for Control — The Four Pillars of Software Maintenance
To move beyond the reactive firefighting of the initial launch period, businesses need a structured, strategic framework for managing their software asset. This involves understanding that "maintenance" is not a monolithic cost center but a portfolio of distinct activities, each with a specific business purpose. Adopting the four globally recognized types of software maintenance, as defined by standards bodies like the IEEE and ISO/IEC 14764, provides executives with a shared language to discuss, prioritize, and budget for the ongoing health and evolution of their software.
The Four Pillars Explained
This framework categorizes all post-launch work into four distinct pillars, allowing for a more strategic allocation of resources.
- Corrective Maintenance (Reactive): This is the classic "bug fix." It's the reactive process of identifying and correcting defects, faults, and errors after they have been discovered by users or monitoring systems. This is the essential work of keeping the software functional and reliable.
- Example: A defect in your B2B platform's authentication code prevents new users from logging in with their social media credentials. A patch is quickly developed and deployed to correct the faulty code.
- Adaptive Maintenance (Proactive): This involves modifying the software to keep it compatible and performant in a constantly changing technological environment. This could be in response to new operating system versions, changes in hardware, or updates to third-party services your software depends on. It's about ensuring the software doesn't become obsolete.
- Example: A key third-party service, like a social media platform used for logins, updates its API. Your software must be adapted to communicate with the new API to ensure that the login functionality continues to work seamlessly for users.
- Perfective Maintenance (Proactive): This is where true product evolution happens. Perfective maintenance involves implementing new features, enhancing existing ones, and improving the user interface and experience based on user feedback and strategic business goals. This is the largest category of maintenance and the primary driver of increased value.
- Example: After analyzing user feedback, you discover that when users log into your application, the first thing they want to see is a dashboard of their most recent activity, not their static profile page. You modify the software to change the default landing page, perfecting the user journey.
- Preventive Maintenance (Proactive): This is the "future-proofing" pillar. It involves making changes to the software to improve its long-term maintainability and prevent future problems. This includes activities like code refactoring, optimizing database structures, and improving documentation. These changes are often invisible to the end-user but are critical for reducing future costs.
- Example: Your user base is growing rapidly. Anticipating a future surge in traffic that could crash the system, your team proactively adds more server capacity and modifies the software to automatically scale and handle the increased load, preventing a future crisis.
To help executives align these technical activities with business outcomes, the following table provides a strategic view.
| Maintenance Type | Technical Description | B2B Example | Strategic Business Purpose |
|---|---|---|---|
| Corrective | Reactively fixing bugs and defects found in production. | A bug prevents the generation of quarterly financial reports in your B2B SaaS platform. | Ensure Reliability & User Trust: Maintain core functionality and meet service-level agreements (SLAs). |
| Adaptive | Proactively updating software to remain compatible with new platforms, OS versions, third-party APIs, or security standards. | Your CRM must be updated to integrate with the latest version of the Microsoft 356 API. | Maintain Viability & Security: Prevent obsolescence and protect against emerging security vulnerabilities. |
| Perfective | Proactively adding new features, improving UI/UX, and enhancing performance based on user feedback and strategic goals. | Adding a new analytics dashboard to your marketing automation tool based on customer requests. | Increase Value & Competitive Edge: Evolve the product to meet market demands and stay ahead of competitors. |
| Preventive | Proactively refactoring code, optimizing databases, and improving documentation to make future maintenance easier and cheaper. | Rewriting a complex, poorly documented module to reduce technical debt and make it easier for new developers to understand. | Reduce Future Costs & Increase Agility: Lower the total cost of ownership (TCO) and accelerate future feature development. |
The way a company allocates its resources across these four pillars—its "Maintenance Mix"—serves as a powerful leading indicator of its software's health and its overall business agility. Industry benchmarks show that in a healthy, mature product, the largest portion of effort, typically 30-40%, is dedicated to Perfective maintenance—the work that adds new value and enhances competitive positioning. If a company finds that its maintenance budget is overwhelmingly consumed by Corrective maintenance, with developers spending 60-70% of their time just fixing a constant stream of bugs, it's a clear red flag. This imbalance is a symptom of deeper issues, often stemming from accumulated technical debt and a chronic neglect of Preventive maintenance. This state of constant firefighting starves the product of the resources needed for evolution. New features are perpetually delayed, the product stagnates, and competitors who have achieved a healthier maintenance balance will inevitably pull ahead. A strategic CFO or CTO can use this concept as a diagnostic tool. By simply asking, "What percentage of our maintenance budget is spent on fixing versus improving?" they can quickly gauge the health of their software asset and the long-term efficiency of their technology organization. An unhealthy mix is a direct threat to the company's capacity to innovate.
Part 3: The Financial Truth — Understanding the Total Cost of Ownership (TCO)
For strategic executives, particularly the CFO, a clear-eyed understanding of the long-term financial commitment of a software asset is paramount. The conversation must shift from the one-time, upfront development cost to the comprehensive, multi-year Total Cost of Ownership (TCO). This perspective is the only way to budget realistically and make informed decisions about the software's lifecycle.
The 80/20 Rule of Software Costs: The Maintenance Iceberg
The initial development cost is merely the visible tip of a much larger financial iceberg. A wealth of industry research consistently shows that ongoing maintenance accounts for the vast majority of a software's lifetime expense, typically ranging from 50% to 80% of its TCO . Some studies from respected sources like the Standish Group report that post-launch enhancements and modifications can cost three to four times the original development price.
This reality has profound implications for financial planning. A budgeting model that heavily front-loads the development phase while treating maintenance as a minor, secondary expense is fundamentally flawed and destined for failure. To put this in concrete terms, a software project with an initial development cost of $500,000 could easily require a maintenance budget of $1 million to $2 million over its operational lifetime. Therefore, TCO is not just an accounting term; it is the only realistic metric for strategic financial planning and for understanding the true investment required.

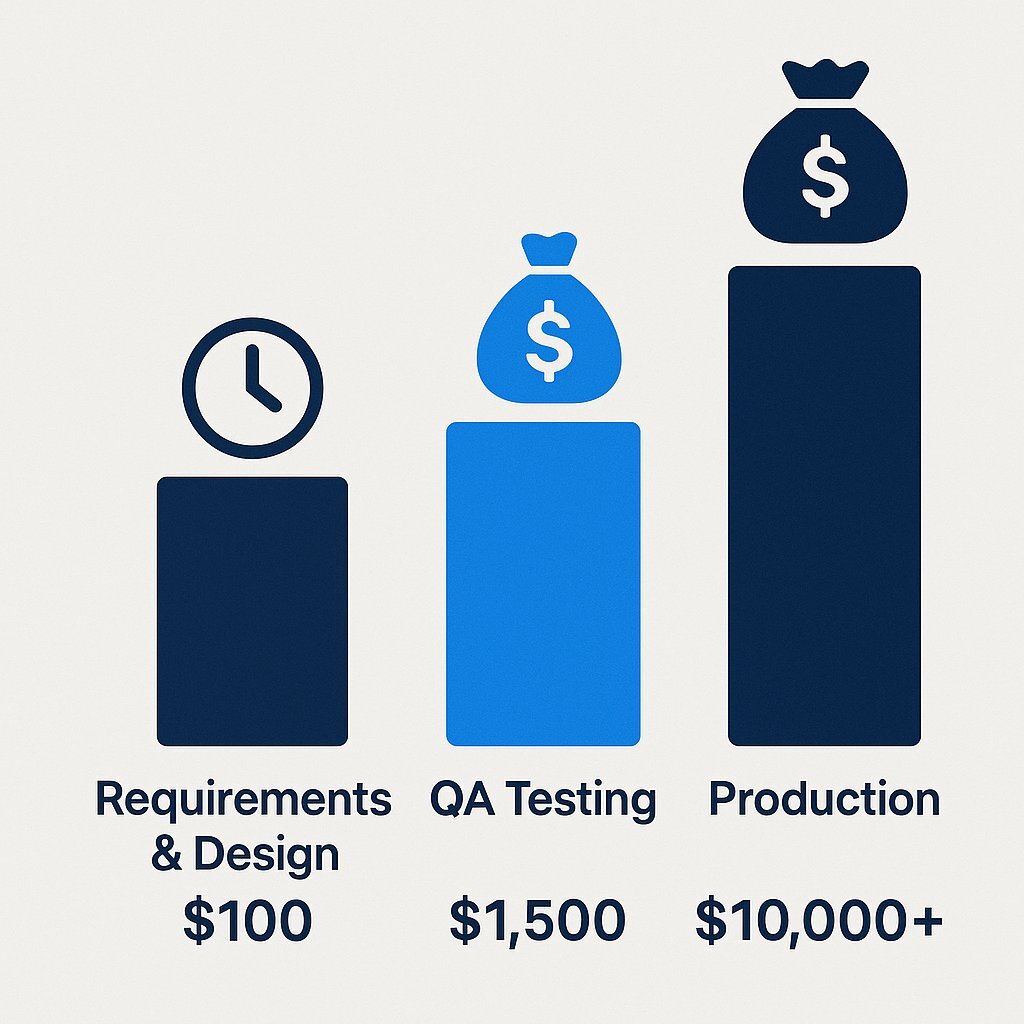
Chart 1: The Exponential Cost of Delay
One of the most significant factors driving up TCO is the delayed discovery of bugs. A visual representation powerfully illustrates why investing in robust QA and testing during the development cycle yields an enormous return.
| SDLC Phase | Relative Cost to Fix a Bug |
|---|---|
| Requirements & Design | $100 |
| QA Testing | $1,500 |
| Production (Post-Launch) | $10,000+ |
| Data based on reports from IBM Systems Sciences Institute and industry analysis. |
As the chart demonstrates, the cost to fix a single bug is not linear; it grows exponentially. A simple logic error that might take an hour to correct during the design phase could require hundreds of hours of developer time, customer support resources, and emergency deployments to fix once it's live in production.
Budgeting for a Living Asset: Industry Benchmarks
Annual maintenance costs are not static; they evolve as the software ages and its environment changes. Research from industry analysts like Gartner reveals a predictable pattern of cost escalation that can be used for more sophisticated, multi-year financial planning.
- Years 1-2 (Early Phase): Budget 10-25% of the initial development cost, annually. This period is often dominated by corrective maintenance (fixing early bugs) and initial perfective maintenance (responding to immediate user feedback).
- Years 3-5 (Mid-life Phase): Budget 15-30% of the initial development cost, annually. As the software stabilizes, costs often increase due to more significant perfective enhancements and growing adaptive maintenance needs to keep pace with technology changes.
- Years 6+ (Mature Phase): Budget 20-40% of the initial development cost, annually. In this phase, adaptive maintenance can become a major cost driver as the underlying technology platforms evolve. Preventive maintenance also becomes critical to manage accumulated complexity and prevent the software from becoming a legacy burden.
This data allows finance and technology leaders to move away from simplistic, flat-line budgeting and create realistic, evolving financial models that avoid surprise shortfalls in later years when the software may be most critical to the business.
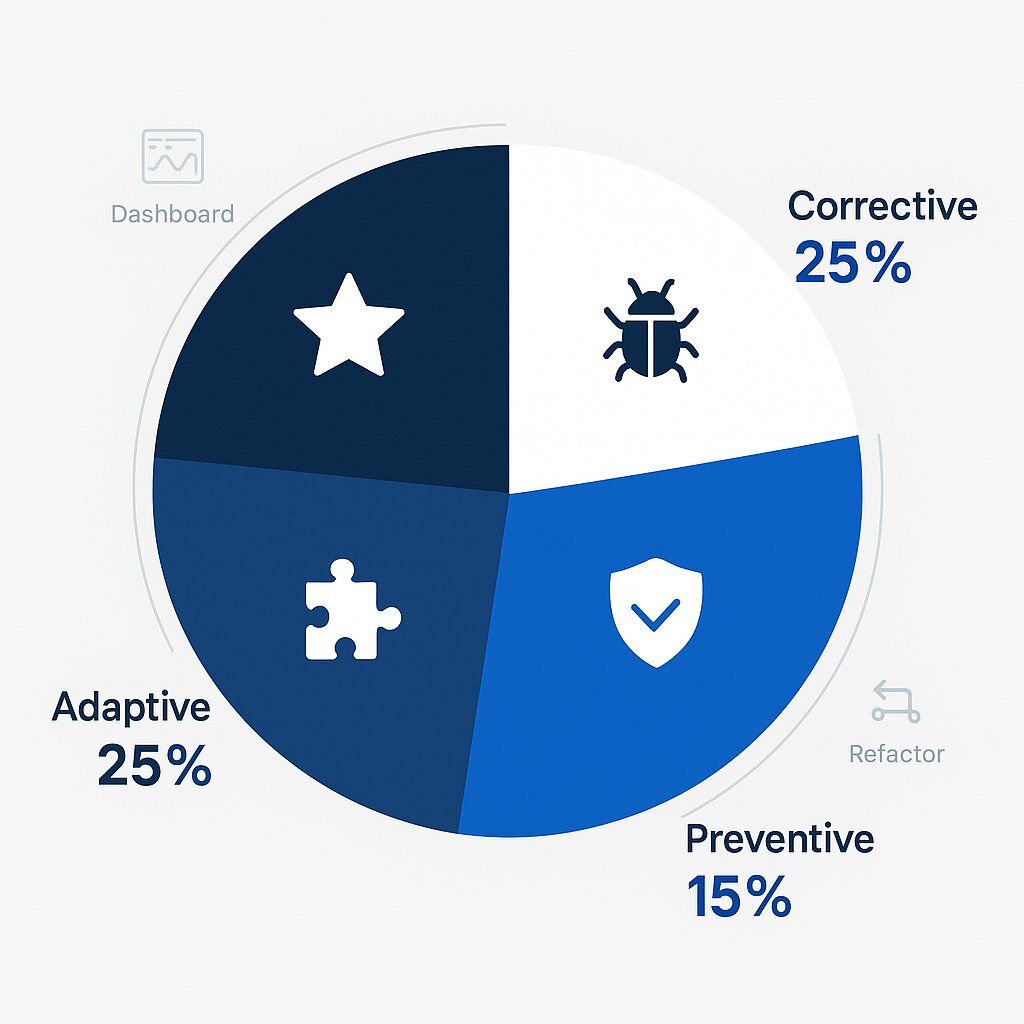
Chart 2: How the Maintenance Budget is Spent
Visualizing the "Maintenance Mix" provides executives with a clear benchmark to compare their own resource allocation against, helping them identify strategic imbalances.
| Maintenance Type | Typical % of Lifetime Effort |
|---|---|
| Perfective Maintenance | 35% |
| Corrective Maintenance | 25% |
| Adaptive Maintenance | 25% |
| Preventive Maintenance | 15% |
| Averaged data from multiple industry reports. |
This typical distribution underscores that a healthy software asset should have the majority of its resources dedicated to proactive, value-adding activities (Perfective and Preventive) rather than reactive fixes.
The concept of TCO transcends being a mere financial metric; it functions as a powerful strategic alignment tool. The realization that maintenance constitutes the largest portion of TCO is the first step. The second is understanding that an abnormally high maintenance cost, particularly a high percentage spent on corrective fixes, is a direct symptom of poor initial architecture, inadequate testing, or excessive technical debt. These technical failings are not contained within the IT department; they have direct, negative business consequences, including slower time-to-market for new features, increased developer frustration and turnover, and reduced system stability that harms customer satisfaction. Consequently, the TCO and its component ratios become lagging indicators of the quality and strategic foresight of the initial technical decisions. A forward-thinking CFO can leverage the TCO ratio to hold the technology organization accountable for long-term value creation, not just short-term launch deadlines. This fosters a crucial, data-driven conversation between finance and technology about the tangible business cost of technical debt and the long-term ROI of investing in quality from day one, aligning the entire C-suite around the principle of software as a long-term, dynamic asset.
Part 4: From Maintenance to Momentum — A Blueprint for Continuous Evolution
Successfully managing post-launch realities and costs is about establishing stability. True market leadership, however, comes from building on that stability to create momentum. This requires shifting the organizational mindset from defense (fixing and maintaining) to offense (innovating and evolving). This section outlines the modern cultural philosophies, practices, and technologies that enable software to become a source of sustained competitive advantage.
The Engine of Evolution: DevOps and Rapid Agile Deployment
The term DevOps is often misunderstood as a job title or a set of tools. In reality, it is a cultural philosophy that fundamentally changes how software is delivered. It is about breaking down the traditional, adversarial silos between development teams (who want to build and ship new things) and operations teams (who want to maintain stability). Under a DevOps model, these teams collaborate closely, often merging into a single unit where engineers share responsibility for the entire application lifecycle, from initial code to production support. This culture of shared ownership and accountability, supercharged by automation, is what enables the high-velocity delivery of reliable software updates.

The core mechanical process that powers this culture is the Continuous Integration/Continuous Deployment (CI/CD) pipeline . In business terms, this is an automated assembly line for software changes. Every time a developer commits a change, a series of automated processes are triggered to build, test, and prepare the code for release. This automation drastically reduces the risk of human error and increases the frequency and pace of releases from months or weeks to days or even hours. This is the engine that drives a "Rapid Agile Deployment" capability, allowing a business to respond to market changes with unprecedented speed. Modern toolchains, such as
Azure DevOps On-Prem , provide the integrated version control, automated build servers, and testing frameworks necessary to make a robust CI/CD pipeline a reality.
Future-Proofing Your Platform with Cloud-Native Technology
To support this rapid pace of evolution, a modern, flexible infrastructure is required. This is where cloud-native technologies like containers and orchestration platforms become essential.
The Foundation (Docker): In simple terms, Docker packages an application and all its dependencies (code, libraries, settings) into a single, standardized, and portable unit called a container. For an executive, the key benefit is
consistency . A Docker container ensures the software runs exactly the same way on a developer's laptop, in a testing environment, and in the production cloud. This eliminates the costly and time-consuming "it worked on my machine" problem that has plagued software development for decades.
The Orchestrator (Kubernetes & Rancher): While Docker creates the containers, Kubernetes acts as the sophisticated "air traffic control" system for them. It is a powerful orchestration platform that automates the deployment, scaling, and management of thousands of containers across a cluster of servers. To make this power more accessible, platforms like
Rancher provide a simplified, user-friendly management layer on top of Kubernetes. This allows enterprise teams to harness the full power of Kubernetes without needing a small army of highly specialized engineers, making it a key component of a "Tailored Tech Advantage".

This modern technology stack delivers three critical business outcomes:
- Scalability: Automatically add or remove application instances to handle traffic spikes without manual intervention, ensuring a smooth customer experience while optimizing costs.
- Resilience (Self-Healing): Automatically detect and restart or replace failed containers, ensuring high availability for critical applications and minimizing the business impact of downtime.
- Efficiency: Densely pack applications onto servers to optimize resource utilization, significantly reducing infrastructure and hosting costs.
Taming Technical Debt: The Hidden Mortgage on Your Agility
Technical debt is a concept every CFO should understand. It is the implied future cost of rework caused by choosing an easy, limited solution now instead of using a better, more sustainable approach that would take longer. It's like taking out a high-interest loan on your codebase: the short-term gain in development speed is paid for with interest in the form of higher maintenance costs, slower feature development, and reduced agility in the future.
While some technical debt is a strategic and acceptable trade-off to meet a critical deadline, unmanaged debt can cripple a product. The strategy is to manage it intentionally:
- Identify and Track: Use static analysis tools like SonarQube or Code Climate to identify "code smells," vulnerabilities, and complexity. Track metrics like the Technical Debt Ratio (TDR)—the cost to fix issues versus the cost to develop the software—to quantify the problem.
- Prioritize and Pay Down: Don't attempt a massive, "boil the ocean" rewrite. Instead, adopt a phased approach. A common best practice is to dedicate a fixed percentage of each development sprint, typically 10-20% , specifically to reducing technical debt. Focus on addressing the high-impact, low-cost issues first to get the best ROI.
- Prevent: The best way to manage debt is to prevent it from accumulating. Institute a strong culture of peer code reviews and implement automated testing within your CI/CD pipeline to enforce quality standards and catch issues before they become part of the codebase.
The Voice of the Customer: Building a Powerful Feedback Loop
A product feedback loop is a systematic, repeatable process to collect, analyze, implement, and follow up on user feedback. It transforms customer interactions from a reactive support function into a proactive, data-driven engine for product development. This ongoing conversation between your team and your users is non-negotiable for building software people actually want and value.
With a potential flood of feedback, however, rigorous prioritization is key. Two simple but powerful frameworks can help executives and product teams make sense of the noise:
- The MoSCoW Method: This is a straightforward technique for categorizing features and requirements to align stakeholders on priorities for a specific release or timebox. It classifies items into four groups: M ust-have (non-negotiable for the release), S hould-have (important but not vital), C ould-have (desirable but can be postponed), and W on't-have (explicitly out of scope for now).
- The Kano Model: This is a more sophisticated model that helps you understand the emotional impact of features on customer satisfaction. It categorizes features into three key types: Basic Needs (expected features that cause dissatisfaction if absent), Performance Needs (features where "more is better," like speed), and Delighters (unexpected, innovative features that create a "wow" factor). Using the Kano model helps you strategically balance meeting core expectations with delivering the innovations that create loyal customers and differentiate your product.
These strategies for continuous evolution are not independent; they are interlocking parts of a single, self-reinforcing system. A strong DevOps culture is what enables the effective implementation of a CI/CD pipeline. That automated pipeline, in turn, provides the technical capability to deploy changes rapidly and reliably. This speed makes it feasible to act on user feedback quickly, which tightens the product feedback loop. A tight feedback loop provides the rich, real-time data needed to make informed strategic decisions about which new features to build (Perfective Maintenance) and which areas of technical debt to address (Preventive Maintenance). Running this entire system on a cloud-native platform like Docker and Kubernetes ensures that these rapid deployments are also scalable and resilient. This creates a powerful flywheel effect: the organization gets progressively faster, smarter, and more responsive to the market with every turn.
Part 5: The Strategic Crossroads — Choosing Your Management Model
The final piece of the post-launch puzzle is a critical strategic decision: who will manage, maintain, and evolve this valuable software asset? This choice between building an in-house team and engaging an expert partner for application management is as important as the initial decision of who builds the software. It has profound implications for cost, agility, access to expertise, and your organization's ability to focus on its core business.
The Core Decision: In-house Team vs. Expert Partner
The global IT outsourcing market is massive and continues to grow, with projections suggesting it will surpass $1 trillion by 2030. However, the most telling trend is the fundamental shift in
why companies choose to outsource. In 2020, 70% of businesses cited cost savings as their primary driver. By 2024, that number had plummeted to just 34%. The top driver for outsourcing today is access to specialized talent (42%) . This seismic shift reframes outsourcing from a simple cost-cutting tactic to a strategic imperative for acquiring critical capabilities that are difficult and expensive to build and retain internally.
Table 2: In-House vs. Outsourced Application Management: A C-Suite Comparison
This table provides a clear, at-a-glance comparison of the two models across the criteria that matter most to executive decision-makers, serving as a strategic evaluation framework.
| Criteria | In-House Team | Outsourced Expert Partner (Application Management) |
|---|---|---|
| Cost & TCO | High fixed overhead (salaries, benefits, training, infrastructure). Can be cost-effective long-term if utilization is consistently high. | Converts fixed costs to variable costs. Economies of scale can lower TCO. Eliminates recruitment and infrastructure expenses. |
| Access to Expertise | Limited to the talent you can hire and retain. Acquiring specialized skills (e.g., Kubernetes, advanced cybersecurity) is difficult and expensive. | Immediate access to a deep bench of specialists across multiple technologies and industries. The partner stays current on cutting-edge tech. |
| Scalability & Flexibility | Scaling up or down is slow and costly, tied to lengthy hiring or painful firing cycles. | Highly flexible. Can scale resources up or down rapidly to meet project demands, handle peak periods, or adapt to changing business needs. |
| Focus on Core Business | The internal IT team can become bogged down in routine maintenance and support, pulling focus away from strategic, revenue-generating initiatives. | Frees up valuable internal resources to focus on core competencies, product innovation, and market strategy. The partner handles the day-to-day management. |
| Control & Alignment | Full, direct control over the team, process, and priorities. The team is deeply integrated with company culture and strategic goals. | Control is managed through robust Service Level Agreements (SLAs) and governance frameworks. A true partner acts as a seamless, strategic extension of your team. |
The Expert Partner Advantage
This is where the value proposition of a specialized firm becomes clear. An expert application management partner doesn't just provide temporary staff; they provide a mature, proven practice. They bring enterprise-grade processes, deep expertise in complex, modern tech stacks—including platforms like Kubernetes, Rancher, and Azure DevOps —and a disciplined focus on efficiency, proactive maintenance, and clear communication. This model allows a business to leverage a "Tailored Tech Advantage" and "Rapid Agile Deployment" capability immediately, without the immense time, cost, and risk of trying to build those world-class capabilities from scratch.
Ultimately, the sourcing decision for application management is a bet on your organization's core competency. The technological landscape is becoming exponentially more complex, with the rise of cloud-native architectures, AI, and sophisticated cybersecurity threats. For most companies in industries like finance, healthcare, or real estate, managing this complex software stack is a critical support function, but it is not their core business. Attempting to build and maintain a world-class in-house application management team for a non-core function represents a massive diversion of capital, resources, and executive focus. It forces a mortgage company, for example, to compete for scarce, expensive tech talent against tech-first giants—a battle they are unlikely to win.
The decision to outsource application management, therefore, is no longer just an IT decision; it is a fundamental business strategy decision. It is an explicit choice to focus your internal resources on what your company does best to win in its market, while entrusting the critical-but-non-core function of application management to a partner whose entire business is that competency. Choosing to keep it in-house is an implicit bet that you can build and run a technology organization better and more efficiently than a company that specializes in it. For many, that is a bet not worth taking.
Conclusion: Your Software Is a Dynamic Asset, Not a Finished Product
The journey of your custom software doesn't end at launch; it begins. The initial deployment is a milestone, not the destination. Long-term success and value are defined not by the launch itself, but by the strategic, ongoing commitment to a disciplined cycle of maintenance and evolution. The most critical shift in mindset is to stop viewing your software as a finished product or a static expense and start treating it as a dynamic, living asset—one that requires continuous investment and strategic management to deliver its full potential and drive lasting business growth.
Actionable Next Steps for Executives
- Calculate Your 5-Year TCO: Move beyond the initial development invoice. Use the industry benchmarks in this guide (e.g., budgeting 15-30% of the initial development cost annually for maintenance) to create a realistic, multi-year financial plan for your software asset.
- Audit Your "Maintenance Mix": Schedule a meeting with your technology lead and ask a simple question: "What percentage of our team's time is spent fixing bugs versus building new features?" Compare your answer to the healthy benchmark of ~35% for perfective (value-add) work. An unhealthy balance is a red flag that requires immediate strategic attention.
- Evaluate Your Management Model: Use the C-Suite Comparison table to conduct an honest, objective assessment of your current application management model. Is it truly aligned with your strategic goals for talent acquisition, scalability, and, most importantly, focus on your core business?
The path from reactive maintenance to proactive evolution is complex, requiring a blend of financial discipline, technical excellence, and strategic foresight. For additional strategies on maximizing the ROI of your technology, explore our guide to software testing and ROI. If you're ready to build a comprehensive plan to maximize the ROI of your software asset, it's time to engage with experts who do this every day.
Further Reading
- https://www.edmunds.com/tco.html
- https://launchdarkly.com/blog/product-feedback-loop/
- Agentic SDLC: The AI-Powered Blueprint Transforming Software Development
- Time & Materials vs. Fixed Price: Which Software Development Contract Model Delivers Better ROI?
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.