
Kafka Real-Time Data Processing Guide 2025
December 17, 2025 / Bryan ReynoldsExecutive Summary: The Death of the "Wait" State
In the high-stakes arena of modern digital business, time is no longer just money—it is survival. The architectural paradigms that built the web of the early 2000s, primarily the synchronous Request-Response model, are crumbling under the weight of today’s data demands. Whether it is a financial institution attempting to block a fraudulent transaction before the swipe clears, a telecommunications giant managing the fluctuating load of a 5G network, or a massive multiplayer online game synchronizing the movements of thousands of players, the requirement is absolute: systems must react instantaneously.
At Baytech Consulting, we specialize in navigating these complex technological shifts. Through our work in custom software development and application management, we have observed a distinct migration away from static, monolithic systems toward dynamic, Event-Driven Architectures (EDA). This report serves as a comprehensive, expert-level guide for Lead Architects and Senior Engineers. We will dismantle the "why" and "how" of this transition, providing a deep-dive analysis of Apache Kafka as the central nervous system of the modern enterprise, exploring the operational realities of deployment on Kubernetes (specifically Rancher and RKE), and exposing the hidden economics of streaming data at scale.
1. The Architectural Schism: Request-Response vs. Event-Driven
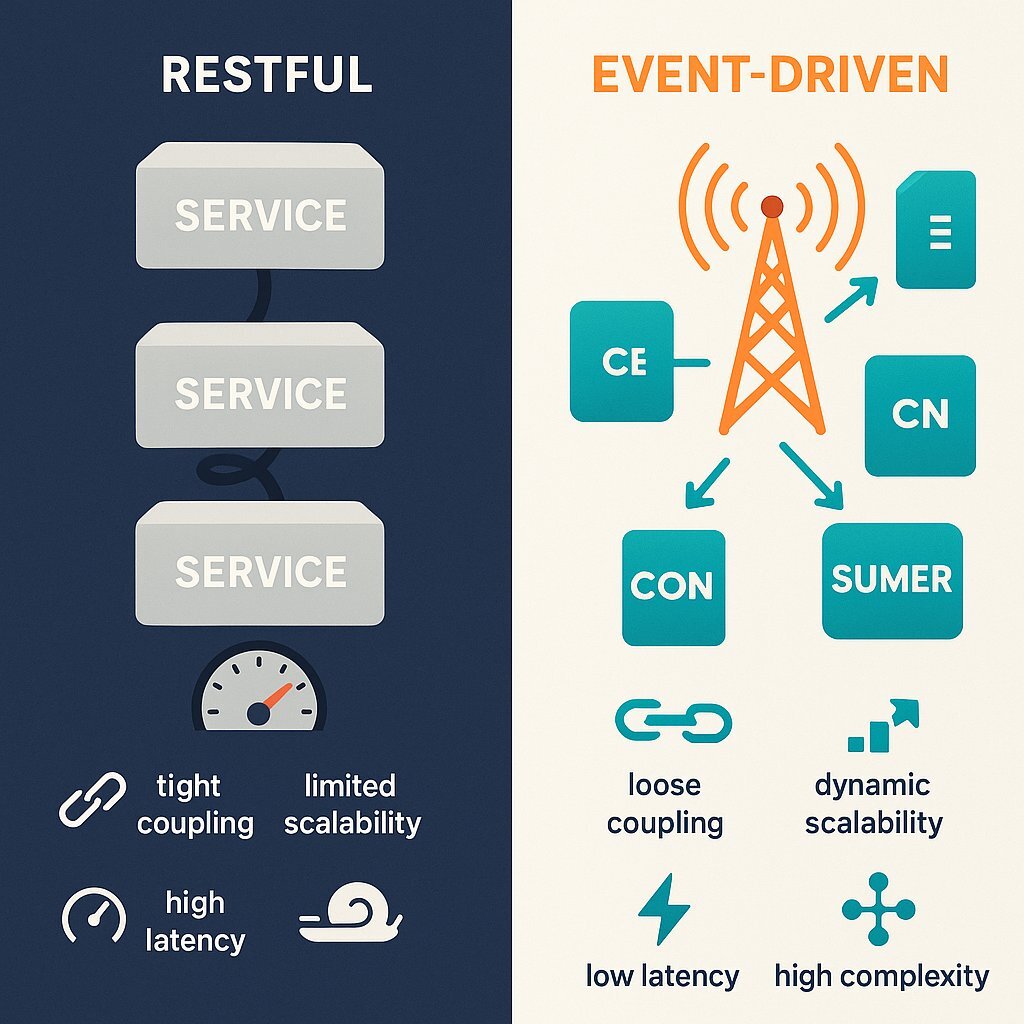
To truly appreciate the necessity of Event-Driven Architecture, we must first scrutinize the limitations of the status quo. For decades, the RESTful API has been the lingua franca of the internet. It operates on a synchronous model akin to a telephone call: the client dials (sends a request), and the server answers (sends a response). This works perfectly for simple interactions, but in complex distributed systems, it introduces fragility.
1.1 The Fragility of Synchronous Coupling
In a microservices environment utilizing REST, services are tightly coupled in time. If Service A calls Service B, and Service B calls Service C, a failure or delay in Service C cascades immediately back to Service A. This phenomenon, known as latency accumulation , means that the performance of your entire system is capped by its slowest component.
Furthermore, synchronous systems struggle with scalability bottlenecks . In a RESTful architecture, handling a spike in traffic often requires scaling every service in the dependency chain simultaneously. If the "Order Service" scales up to handle Black Friday traffic but the "Inventory Service" it calls synchronously cannot keep up, the entire transaction fails. The resources in the Order Service are blocked, waiting for a response that may never come, leading to resource exhaustion.
1.2 The Event-Driven Paradigm Shift
Event-Driven Architecture (EDA) fundamentally alters this relationship. Instead of a telephone call, EDA functions like a radio broadcast. The producer of data (Service A) simply announces "An Order Was Placed" (the event) to a central log or broker, and then immediately returns to its work. It does not know, nor does it care, who listens to that broadcast.
This decoupling is the strategic advantage of EDA. Service B (Inventory), Service C (Fraud Detection), and Service D (Analytics) can all consume that "Order Placed" event at their own pace. If the Inventory Service goes offline for maintenance, the Order Service is unaffected; it continues to accept orders and publish events. When the Inventory Service returns, it simply catches up on the backlog of messages.
This architecture unlocks parallelism that is impossible in synchronous systems. A single event can trigger multiple downstream business processes simultaneously without the producer needing to orchestrate them. For example, a "Payment Received" event can trigger a receipt email, a shipping label generation, and a ledger update all at once, handled by independent consumers scaling horizontally on their own terms.
1.3 Strategic Comparison: The Architect's Decision Matrix
While the benefits of EDA are compelling, it is not a universal replacement for REST. The choice depends on the specific requirements for latency, consistency, and coupling.
| Feature | RESTful Architecture | Event-Driven Architecture (EDA) |
|---|---|---|
| Coupling | Tight : Client and Server must be active simultaneously and aware of each other's endpoints. | Loose : Producers and Consumers are decoupled via a broker; they evolve independently. |
| Latency Profile | Low (Immediate) : Ideal for direct user interactions where an answer is needed instantly (e.g., UI login). | Variable (Asynchronous) : Introduces slight overhead; better for backend processing and eventual consistency. |
| Scalability | Vertical/Linear : Difficult to scale deep dependency chains without cascading resource contention. | Horizontal/Massive : Highly scalable; add consumers to process partitions in parallel. |
| Complexity | Lower : Easier to reason about flow; standard debugging tools apply. | Higher : Requires managing brokers, distributed tracing, and eventual consistency logic. |
Architecture Insight : The industry is converging on a hybrid model, often referred to as the "Mullet Architecture"—business in the front, party in the back. Use synchronous REST APIs for the "edge" where the user interacts (ensuring immediate feedback like "HTTP 202 Accepted"), and use EDA for the "core" backend where heavy processing occurs asynchronously.
2. Apache Kafka: The Backbone of Real-Time Systems
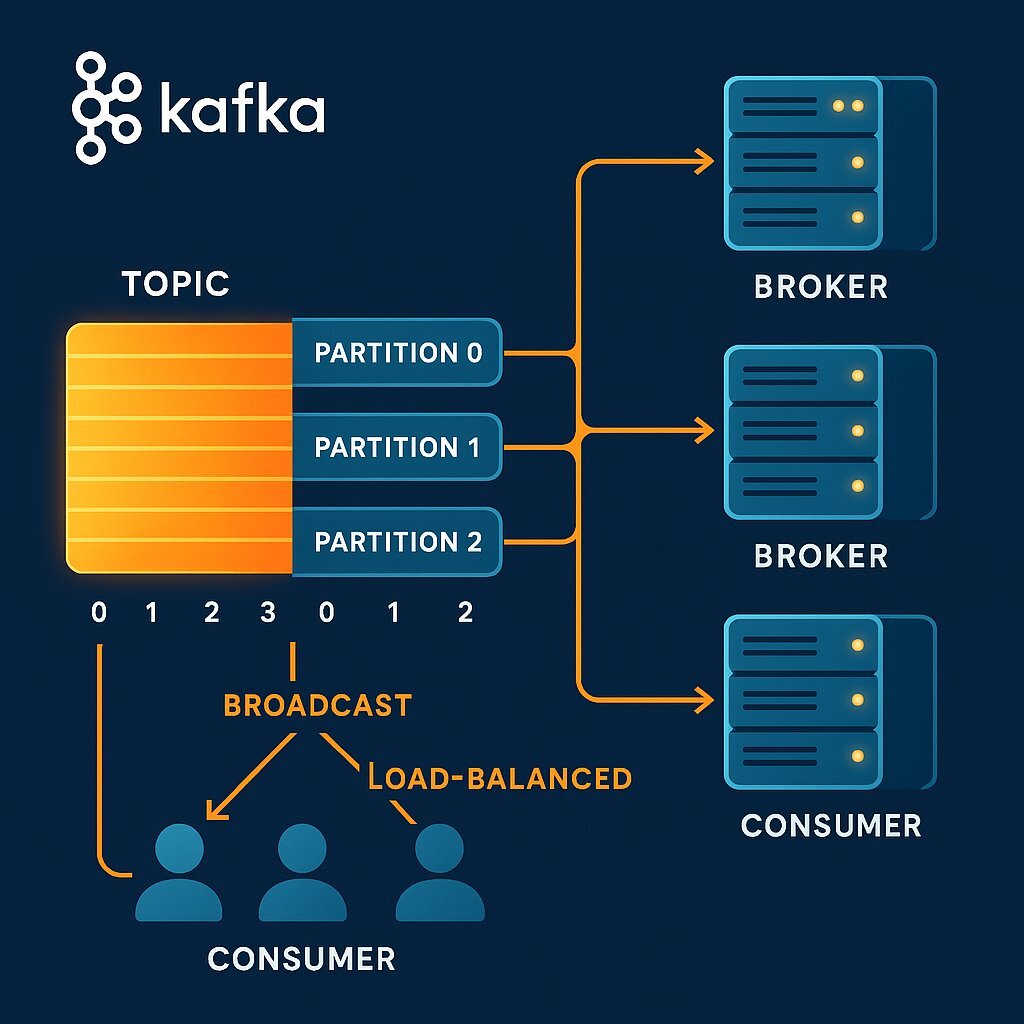
In the realm of EDA, Apache Kafka has emerged as the de facto standard. However, describing Kafka merely as a "message queue" does a disservice to its capabilities. It is more accurately described as a distributed commit log . Unlike traditional queues (like RabbitMQ or ActiveMQ) that delete messages once they are consumed, Kafka stores streams of records durably for a configurable retention period. This persistence allows consumers to "replay" history, enabling time-travel debugging and the reprocessing of data—a capability that transforms how we architect data consistency.
2.1 The Anatomy of the Log: Topics, Partitions, and Offsets
To architect effectively with Kafka, one must understand its internal mechanics.
- Topics : The fundamental unit of organization, analogous to a table in a database. A topic is a named stream of records.
- Partitions : The engine of scalability. Topics are broken down into partitions, which can be distributed across different brokers in a cluster. This allows a single topic to scale beyond the I/O or storage limits of a single server. Crucially, partitions are the unit of parallelism . If a topic has 10 partitions, you can have up to 10 active consumers in a group reading simultaneously.
- Offsets : Within a partition, each message is assigned a unique, sequential ID called an offset. Kafka does not track which messages a consumer has read; the consumer tracks its own offset. This "dumb broker, smart consumer" design relieves the broker of state management metadata, allowing it to handle millions of messages per second with minimal overhead.
- Consumer Groups : This concept allows Kafka to act as both a queue (load balancing) and a topic (broadcast). A Consumer Group is a set of consumers that cooperate to consume a topic. Kafka guarantees that each partition is consumed by exactly one member of the group, ensuring ordering within the partition while balancing load across the group.
2.2 Durability: The acks=all Guarantee
For critical systems—such as the financial transaction platforms we see in the fintech sector—data loss is unacceptable. Kafka achieves durability through replication.
- Replication Factor : This determines how many copies of the partition exist. A factor of 3 is the industry standard.
- ISR (In-Sync Replicas) : The subset of replicas that are currently alive and fully caught up with the leader.
- Producer Configurations : To guarantee zero data loss, the producer must be configured with
acks=all. This setting forces the leader broker to wait until all in-sync replicas have acknowledged the write before confirming success to the client. Combined with the broker-level settingmin.insync.replicas=2(for a cluster of 3), this ensures that data is written to at least two physical disks before it is considered "committed," tolerating the loss of a broker without data loss.
2.3 Evolution: The Rise of KRaft
Historically, Kafka relied on Apache ZooKeeper for cluster coordination. This introduced significant operational complexity—managing two distinct distributed systems. Modern Kafka (version 2.8+) introduces KRaft (Kafka Raft Metadata mode) , which internalizes metadata management into Kafka itself. This removes the ZooKeeper dependency, simplifies deployment, and significantly improves scalability, allowing clusters to support millions of partitions. For any new greenfield deployment, utilizing KRaft is a strategic imperative to future-proof the infrastructure.
3. The Battle of Brokers: Kafka vs. RabbitMQ vs. ActiveMQ
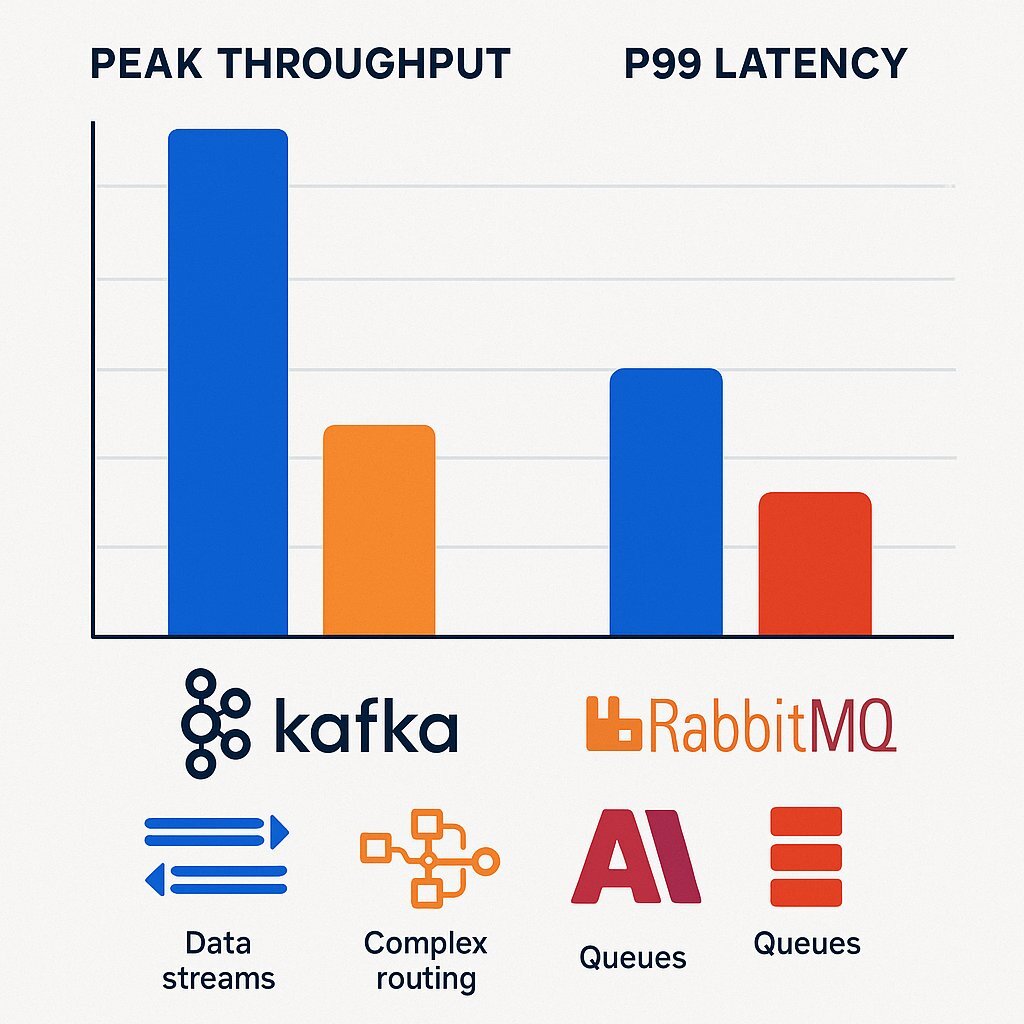
At Baytech Consulting, we often assist clients in selecting the right tool for the job. A common question from CTOs is: "Why introduce the complexity of Kafka if we already have RabbitMQ?" The answer lies in the fundamental trade-off between Throughput and Latency , and the distinction between Stream Processing and Complex Routing .
3.1 Throughput and Latency Benchmarks
Recent benchmarks paint a clear picture of the performance dichotomy between these systems.
| Metric | Apache Kafka | RabbitMQ (Mirrored) | Architectural Implication |
|---|---|---|---|
| Peak Throughput | 605 MB/s | 38 MB/s | Kafka is designed for hyper-scale data ingestion (telemetry, logs). |
| p99 Latency (High Load) | 5 ms (at 200 MB/s) | N/A (Degrades) | Kafka maintains low latency even under massive load. |
| p99 Latency (Low Load) | ~5 ms | 1 ms (at 30 MB/s) | RabbitMQ excels at ultra-low latency for light workloads. |
Analysis : RabbitMQ provides lower latency (sub-millisecond) at low throughputs because it pushes messages directly to consumers. However, its performance degrades significantly under heavy load due to the CPU overhead of managing complex routing logic and queue mirroring. Kafka, by contrast, is optimized for batching and sequential I/O, allowing it to saturate network and disk bandwidths that would choke RabbitMQ.
3.2 The Push vs. Pull Model
- RabbitMQ (Push) : The broker pushes messages to consumers. This allows for near real-time delivery but risks overwhelming consumers if the producer is faster than the consumer. It requires the broker to manage flow control and backpressure, adding complexity to the broker.
- Kafka (Pull) : Consumers poll the broker for data. This puts the control in the hands of the consumer. If a consumer is slow, it simply falls behind (increases lag) without crashing or slowing down the broker. It can catch up later by reading historical data. This makes Kafka inherently more resilient to "bursty" traffic patterns.
3.3 Strategic Selection Guide
- Choose RabbitMQ if : Your primary requirement is complex routing (e.g., routing messages based on header content to different queues), message prioritization, or if you are dealing with low-volume, high-value command messages where sub-millisecond latency is critical (e.g., commanding a robotic arm).
- Choose Kafka if : You need to process massive streams of data (clickstreams, logs, IoT sensors), require data persistence/replayability (Event Sourcing), or need to decouple systems that operate at vastly different speeds.
4. Operational Excellence: Deployment on Kubernetes
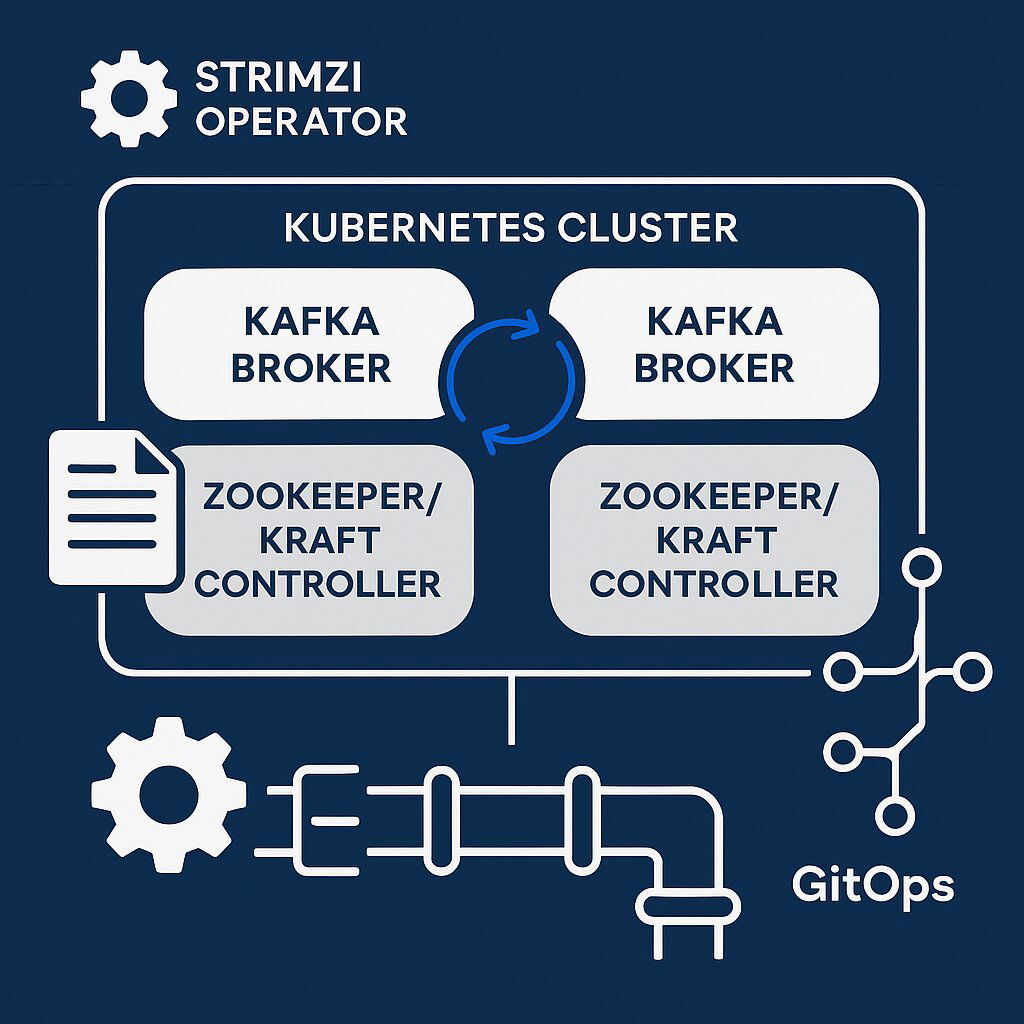
As proponents of Tailored Tech Advantage , we at Baytech heavily utilize containerization and orchestration to deliver robust solutions. Deploying Kafka on Kubernetes has moved from "experimental" to "best practice," largely due to the maturity of the Operator pattern.
4.1 The Strimzi Operator: Automating Intelligence
Running stateful workloads like Kafka on Kubernetes is challenging because pods are ephemeral, but data must be persistent. Strimzi is a CNCF incubating project that simplifies this by codifying the operational knowledge of a Kafka expert into software.
Strimzi manages the entire lifecycle:
- Deployment : It deploys ZooKeeper (or KRaft controllers) and Kafka brokers as StatefulSets.
- Rolling Updates : Strimzi intelligently manages upgrades. It creates a new pod with the updated image, waits for it to join the cluster and catch up with ISRs, and only then moves to the next pod. This ensures zero downtime during upgrades.
- Configuration as Code : With Strimzi, topics and users are defined as Kubernetes Custom Resources (CRDs). You can create a topic by committing a
KafkaTopicYAML file to your Git repository. The operator detects this and issues the necessary commands to the cluster. This enables a true GitOps workflow for Kafka management.
4.2 Best Practices for RKE and Rancher Deployments
Given our experience with Rancher and Harvester HCI, we recommend specific configurations for production readiness:
- Storage Class Performance : Kafka is I/O bound. Never use standard networked storage if latency is a concern. Use a StorageClass backed by local NVMe SSDs or high-performance block storage. Ensure
volumeBindingMode: WaitForFirstConsumeris set so that the Persistent Volume is created in the same zone as the pod. - Anti-Affinity Rules : It is critical to ensure that brokers are distributed across different physical nodes (and ideally different availability zones). Use
podAntiAffinityrules in your Strimzi configuration to force Kubernetes to schedule brokers on separate nodes. If three brokers land on the same physical server and that server fails, you lose the quorum and the cluster goes down. - Resource Isolation : Use Kubernetes Taints and Tolerations to dedicate specific worker nodes solely to Kafka. Taint the nodes
kafka=true:NoScheduleand add the corresponding toleration to the Strimzi deployment. This prevents "noisy neighbor" applications from stealing the CPU cycles or network bandwidth that Kafka desperately needs.
4.3 The Nightmare of Rebalancing Storms
Even with the best tools, operational issues can arise. A Rebalancing Storm is one of the most severe failure modes in Kafka consumers. This occurs when a consumer group enters a loop of constantly reshuffling partition assignments, causing processing to halt completely.
Case Study: The Honeycomb Outage
Honeycomb, an observability platform, experienced a significant outage due to a split-brain scenario triggered by a Zookeeper partition. This led to a state where nodes disagreed on the cluster controller, causing a loop of rebalances and partial data loss. The post-mortem highlighted a critical lesson: Observability is paramount. Teams must monitor consumer_lag and rebalance_rate. If the rebalance rate spikes, it indicates instability.
Mitigation Strategy :
- Static Membership : Kafka 2.3+ introduced the concept of static membership. By assigning a fixed
group.instance.id(e.g., the Kubernetes pod name) to a consumer, the group coordinator recognizes it as a persistent member. If the pod restarts quickly (as in a rolling deployment), the coordinator does not trigger a rebalance, assuming the member will return. This dramatically reduces instability during deployments. - Incremental Cooperative Rebalancing : Ensure your consumer clients are configured to use the
CooperativeStickyAssignor. This protocol allows consumers to continue processing their owned partitions while only the specific partitions being moved are revoked, eliminating the "stop-the-world" pauses associated with older rebalancing strategies.
5. Engineering Real-Time Solutions: Industry Use Cases
The theoretical power of Kafka is best understood through its application in critical industries. We will examine two domains where real-time processing is not a luxury, but a requirement: Financial Fraud Detection and Telecommunications.
5.1 Financial Fraud Detection: The Race Against the Swipe
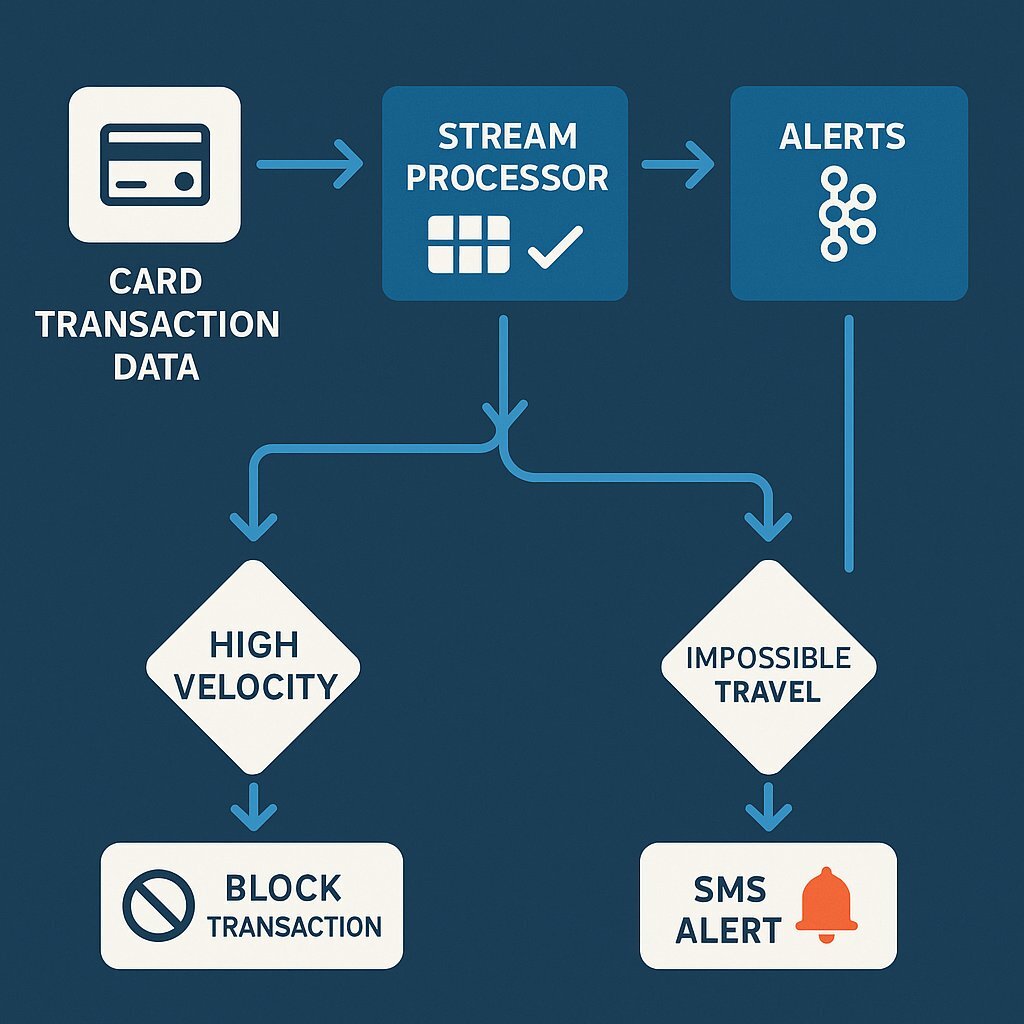
In the banking sector, the window to stop a fraudulent transaction is measured in milliseconds. Traditional batch processing—analyzing logs at the end of the day—is obsolete. The modern approach utilizes Stream Processing to analyze transactions in flight.
Architecture Breakdown :
- Ingestion : Transaction data (POS swipes, online gateways) is published immediately to a Kafka topic (e.g.,
transactions_raw). - Enrichment : A stream processing engine (like Apache Flink or Nussknacker ) consumes this stream. It joins the transaction data with static reference data (e.g., Customer Home Location) loaded into the processor's state.
- Stateful Pattern Matching : The core value lies in Stateful Processing . The engine maintains a "windowed state" in memory (backed by RocksDB). For example, it counts the number of transactions for a specific
ClientIDin the last 5 minutes.- Rule A: If
transaction_count > 5in 5 minutes → Flag as "High Velocity." - Rule B: If
location!=Home_LocationANDprevious_transaction_locationwas > 500 miles away within 1 hour → Flag as "Impossible Travel."
- Rule A: If
- Action : If a rule triggers, a new event is produced to a
fraud_alertstopic. A separate consumer group listens to this topic and triggers immediate blocking via the core banking API or sends an SMS alert to the customer.
Technology Spotlight: Nussknacker
Tools like Nussknacker provide a low-code visual interface on top of Flink and Kafka, allowing risk analysts to define these fraud rules without writing Java code. This democratizes the power of the streaming platform, bridging the gap between engineering and business logic.
5.2 Telecommunications: Taming the Data Firehose
Telecom operators face a unique challenge: volume. A network generates billions of events daily—Call Detail Records (CDRs), GTP-C/U control plane signals, and massive streams of IoT sensor data.
High-Throughput Ingestion Architecture :
- Network Probes : Probes tap directly into the network fiber and generate massive streams of packet data.
- Edge Aggregation (MEC) : In modern Open RAN architectures, lightweight Kafka clusters are deployed at the Multi-Access Edge Computing (MEC) nodes. These clusters aggregate data locally, filtering out noise before transmitting refined streams to the central core. This reduces backhaul bandwidth costs.
- CDR Processing : Instead of batch-loading CDR files via FTP (the legacy method), switches stream CDRs directly to Kafka. This enables Real-Time Billing , allowing operators to update prepaid balances and detect credit limit breaches instantly rather than hours later.
Optimization for Scale:
To handle this scale, standard Kafka configurations are insufficient. Engineers must tune for maximum throughput:
- Batching : Increase
batch.sizeandlinger.mson the producer. Sending fewer, larger batches reduces the network overhead significantly. - Compression : Enable Zstandard (zstd) compression. This offers a high compression ratio with low CPU cost, effectively trading a small amount of compute for massive savings in network bandwidth and storage I/O—often the primary bottlenecks in telco workloads.
- Disk Isolation : Dedicate separate physical disks for the Kafka commit logs to prevent I/O wait times from stalling the broker threads.
6. The Economics of Streaming: Hidden Costs and Governance
While Kafka is open-source, it is not free. The Total Cost of Ownership (TCO) can spiral if not managed with the same rigor as the code itself. If you're looking to maximize ROI and avoid common pitfalls around hidden streaming costs, our guide to software development myths offers practical insights for business and technology leaders.
6.1 The Infrastructure Tax
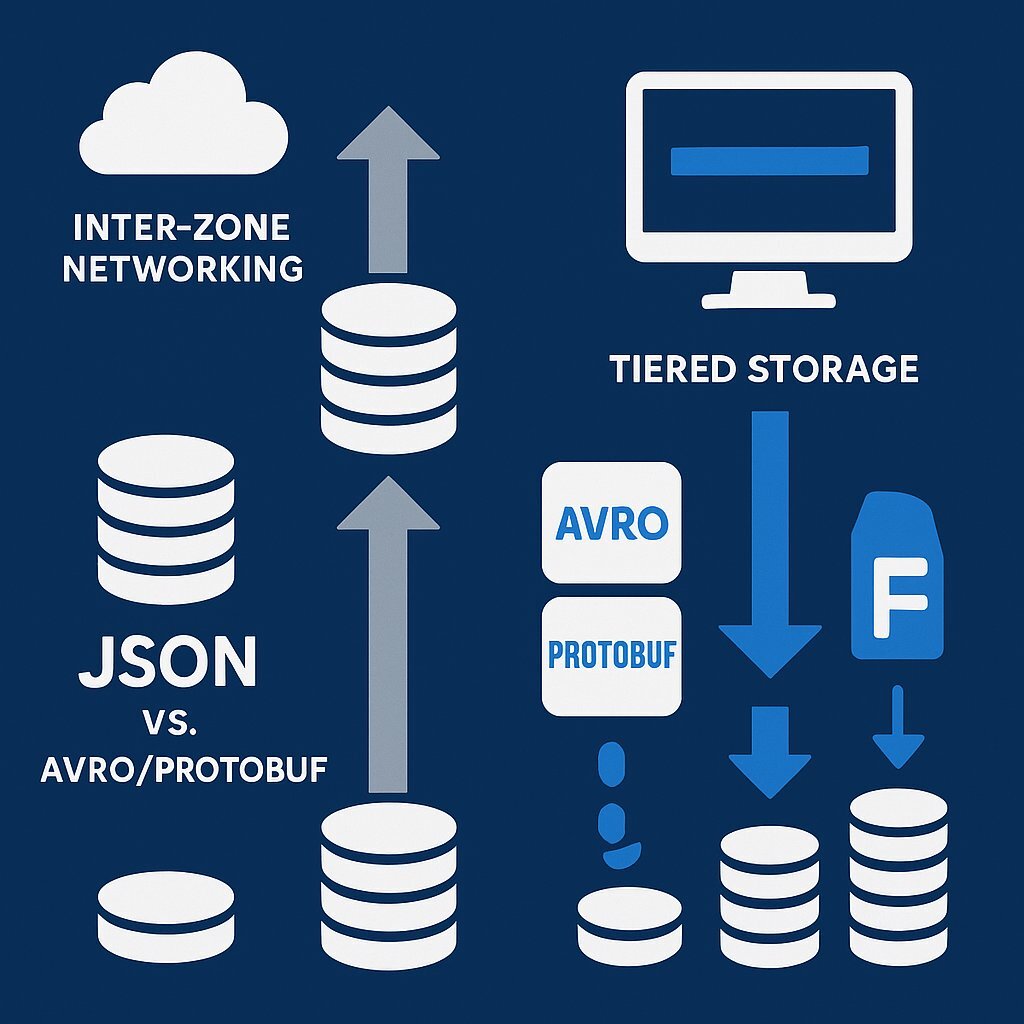
- Inter-Zone Networking Costs : In public clouds (AWS, Azure, Google Cloud), you pay for data transfer between Availability Zones (AZs). High Availability dictates that Kafka must replicate data across AZs (Replication Factor = 3). This means every byte produced is transmitted across the network at least twice. For high-volume clusters, this networking cost often exceeds the cost of the compute instances themselves.
- Storage Overhead : Storing 3 copies of data is expensive. If you are using text-based formats like JSON, you are paying a premium for storing whitespace and repeated field names.
- Mitigation : Switch to binary serialization formats like Avro or Protobuf , which can reduce payload size by 40-60%.
- Tiered Storage : Leverage Kafka's Tiered Storage capability (available in Confluent and newer Kafka versions). This allows you to keep only the "hot" data (e.g., last 4 hours) on expensive NVMe/EBS disks, while offloading older segments to cheap Object Storage (S3/Azure Blob). This can reduce storage costs by up to 80% while keeping data queryable.
6.2 Data Governance: The Schema Registry
In a decoupled architecture, the contract between the Producer and Consumer is the Schema . If a producer changes a data format (e.g., renaming a field) without warning, downstream consumers will crash. This is the "poison pill" problem.
To prevent this, a Schema Registry is essential. It acts as a gatekeeper.
- Validation : When a producer attempts to publish a message, the client checks the schema against the registry. If the schema change violates compatibility rules (e.g., removing a mandatory field), the registry rejects it, and the produce request fails. This protects the consumers from bad data.
- CI/CD Integration : At Baytech, we integrate schema validation into our software project management pipelines. Before code is even merged, the pipeline checks if the proposed schema changes are backward compatible. This "Shift Left" approach catches data governance issues during development, not in production.
7. Conclusion: The Real-Time Imperative
The shift to Real-Time Data Processing is not merely a technological upgrade; it is a fundamental restructuring of how a business perceives and reacts to reality. The "Wait State" is dead. Organizations that continue to rely solely on batch processing and synchronous coupling will find themselves outmaneuvered by competitors who can sense and respond to market stimuli in milliseconds.
For the Lead Architect and Senior Engineer, the path forward is clear but demanding:
- Embrace the Event-Driven Mindset : Decouple your core systems. Use Kafka to create a central nervous system where data is a first-class citizen, accessible to all who need it.
- Architect for Resilience : Use the tools of the trade— Strimzi for Kubernetes orchestration, Schema Registries for governance, and Ack-All configurations for durability.
- Respect the Operational Complexity : Do not underestimate the cost of running distributed systems. Invest heavily in observability, leverage automation (GitOps), and constantly monitor the economics of your infrastructure.
At Baytech Consulting , we understand that this transition is complex. Our "Tailored Tech Advantage" ensures that we don't just implement technology for technology's sake; we craft solutions that fit the specific contour of your business needs, whether that involves deploying high-availability Kafka clusters on Rancher or building sophisticated fraud detection pipelines in Azure. The future belongs to the real-time enterprise—and the time to build that future is now.
Supporting Resources
- https://www.confluent.io/blog/kafka-fastest-messaging-system/
- https://strimzi.io/blog/2025/06/09/taming-the-chaos/
- https://nussknacker.io/blog/real-time-transaction-fraud-detection/
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.