
How Artificial Intelligence Legal Discovery is Revolutionizing Overcoming Information Overload for Law Firms
August 17, 2025 / Bryan ReynoldsIntroduction to Artificial Intelligence in Law
Artificial intelligence is rapidly reshaping the legal profession, offering legal professionals and law firms a powerful set of tools to streamline their work and deliver superior legal services. As the legal industry faces mounting pressure from increasing data volumes and client expectations, AI technology is emerging as a critical differentiator. Today's law firms and legal teams are leveraging artificial intelligence not only to automate repetitive tasks but also to tackle complex legal research, accelerate document review, and unlock predictive analytics that inform case strategy.
By integrating AI into their daily workflows, legal professionals can analyze vast amounts of legal documents and case law with unmatched speed and accuracy. This enables them to focus on more strategic aspects of legal practice, such as crafting arguments and advising clients, rather than being bogged down by time-consuming manual review. As the legal industry continues to evolve, embracing AI technology is no longer optional-it's essential for law firms and legal teams that want to stay ahead of the competition and deliver meaningful insights to their clients. Understanding both the opportunities and challenges of AI in law is now a fundamental part of modern legal practice.
Drowning in Legal Documents: How AI Solves the Legal Industry's Billion-Dollar Information Problem
In a world with over 1.3 million lawyers in the United States and a single lawsuit capable of generating millions of documents, how can legal teams possibly find the one critical fact they need to win a case? For decades, the answer has been a combination of brute force and staggering expense. The discovery phase of litigation, where parties exchange information, can easily cost millions of dollars, with teams of attorneys spending thousands of hours manually sifting through digital mountains of data. This isn't just inefficient; it's a high-stakes gamble where a missed email or a forgotten precedent can mean the difference between victory and defeat.
The legal industry is facing a crisis of information overload. The sheer volume of Electronically Stored Information (ESI) has rendered traditional methods of search and analysis obsolete, creating massive operational bottlenecks, spiraling costs, and unacceptable levels of risk.
Artificial Intelligence (AI) has emerged as a transformative solution, a smart magnet capable of finding the needle in a digital haystack. But not all AI is created equal. The very same technology that promises to revolutionize legal research can also, if implemented carelessly, invent case law out of thin air, a phenomenon known as "hallucination". The real solution lies not in off-the-shelf chatbots but in sophisticated, purpose-built AI systems designed for the high-stakes, high-scrutiny environment of the legal profession. Understanding this distinction is the first step toward turning an information crisis into a competitive advantage .
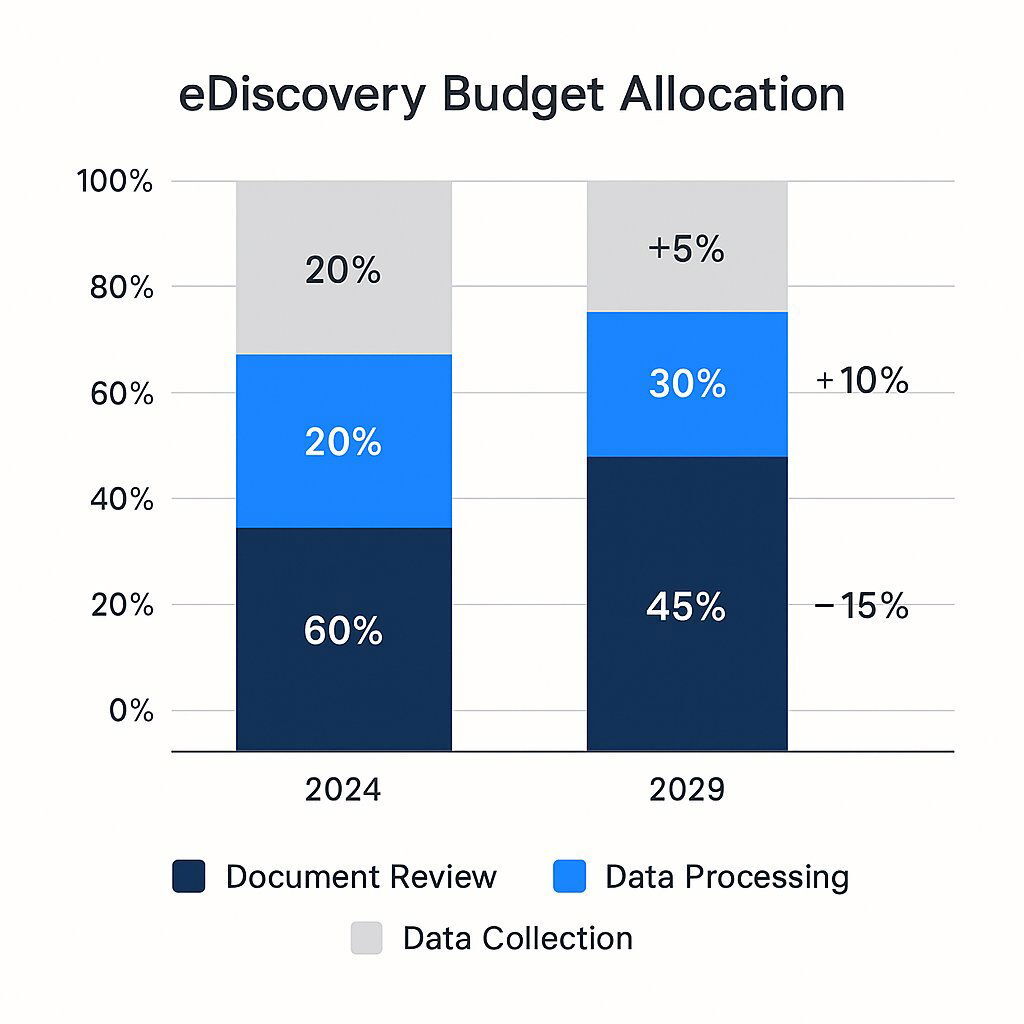
eDiscovery budgets shift from human review to technology-driven processing and collection. E-discovery, or electronic discovery, refers to the process of identifying, collecting, and producing electronically stored information for use as evidence in legal cases. Its significance in the legal industry continues to grow as technological advancements, such as predictive coding and AI-driven tools, reshape how law firms manage data and comply with regulatory and ethical standards.
As law firms make this strategic shift and invest in advanced technology, they are increasingly leveraging AI to transform the discovery process, enhance efficiency, and gain a competitive edge.
The Data Deluge: Quantifying the Legal Information Crisis
To grasp the magnitude of the challenge, one must first understand the scale. The U.S. legal market is a colossal ecosystem, comprising 1.32 million active lawyers and over 463,000 law firms as of 2024. This vast professional network is grappling with a fundamental shift in how information is created and stored. Today, over 90% of all information is born digital. The abrupt pivot to remote work during the pandemic only cemented this reality, catapulting Electronically Stored Information (ESI) from a secondary concern to the primary source of evidence in nearly every legal matter.
This digital explosion has made eDiscovery-the process of identifying, collecting, and producing ESI-the single largest cost component in litigation. The data confirms the strain this puts on legal teams. A 2024 survey of litigation support directors revealed that 93% have seen the volume of data for an average dispute increase, and 60% consider this growth a significant challenge for their teams.
This pressure is forcing a fundamental rethinking of how money is spent. The industry is undergoing a quiet but profound strategic shift away from a model of reactive, manual labor toward one of proactive, technology-driven intelligence. In 2012, the manual review of documents consumed an estimated 73% of all eDiscovery costs. By 2024, that figure had fallen to 64%, and it is projected to shrink further to just 52% by 2029.
A key driver of this shift is the adoption of machine learning algorithms within AI-powered eDiscovery tools. These algorithms are used to analyze and categorize large volumes of legal data, improving efficiency and accuracy by detecting patterns, inconsistencies, and enabling advanced data extraction.
This isn't happening because the total amount of money being spent is decreasing. On the contrary, the overall eDiscovery market is projected to swell from $16.89 billion in 2024 to $25.11 billion by 2029. The change lies in where the money is going. While the percentage spent on manual review declines, spending on the upstream tasks of data collection and processing is expected to climb from a combined 36% of the budget in 2024 to 48% by 2029.
This reallocation of capital tells a clear story. The most forward-thinking firms recognize that paying armies of lawyers for manual review is a losing battle against exponential data growth. It is far more cost-effective and strategically sound to invest in intelligent AI tools at the beginning of the process. By using AI to automatically cull, organize, and analyze data during the processing stage, they can drastically reduce the volume of information that ever needs to reach an expensive human reviewer. This represents a critical evolution from treating discovery as a purely operational expense to leveraging technology as a strategic investment to control costs and mitigate risk.
| eDiscovery Spending Distribution by Task (2024 vs. 2029 Projection) |
|---|
| eDiscovery Task |
| Document Review |
| Data Processing |
| Data Collection |
| Data derived from Complex Discovery market analysis. |
The Old Guard: Why Traditional Search Is No Longer Tenable

Traditional search creates both information overload and dangerous blind spots.
For decades, legal research has been dominated by powerful platforms like Westlaw and LexisNexis. These tools, built on the foundation of keyword and Boolean search, were revolutionary in their time, but their core technology is now a critical vulnerability in the face of modern data volumes.
The fundamental flaw of keyword search is that it is literal, not conceptual. It excels at matching the exact words or phrases a lawyer types into the search bar, but it has zero understanding of the query's intent, context, or meaning. This limitation creates a dangerous gap between what a lawyer is looking for and what the system can find. For example, a meticulously crafted search for "breach of contract" could completely miss a pivotal document that uses the legally synonymous phrase "failure to perform" or "non-compliance with terms". Likewise, a search for "damages" might fail to surface related concepts like "compensation" or "reparation" that are essential to the case.
This technological shortcoming exposes legal teams to two distinct but equally damaging perils:
- False Positives (The Noise): Keyword searches often return a flood of irrelevant documents that happen to contain a search term but in a completely unrelated context. A search for "AIDS" might pull up documents about "hearing aids," forcing lawyers to waste countless billable hours sifting through useless information to find the relevant material. This creates enormous inefficiency and drives up costs.
- False Negatives (The Risk): Far more dangerous is the information the search misses entirely. Because it cannot recognize synonyms or conceptual relationships, keyword search can easily overlook critical documents. This risk is not theoretical. A landmark study cited by FTI Consulting found that experienced attorneys using keyword search believed they had located over 75% of the relevant documents in a dataset. A more detailed analysis revealed they had actually found only 20%.
To overcome these limitations, adopting advanced ai software is essential for legal teams seeking to streamline pretrial discovery, contract analysis, and legal document drafting with greater efficiency and accuracy.
The inadequacy of this core technology creates a direct and quantifiable business liability. The time wasted on reviewing irrelevant results translates directly into higher project costs, a primary concern for any CFO. More importantly, missing a "smoking gun" document or a controlling legal precedent can lead to a lost case, a failed negotiation, or a costly compliance breach. This elevates the problem from a simple IT issue to a foundational business risk. The limitations of the search tool become a strategic vulnerability that impacts profitability , client outcomes, and legal exposure, making the case for a technological upgrade an exercise in risk management.
| Keyword Search vs. AI-Powered Semantic Search |
|---|
| Aspect |
| Methodology |
| Query Style |
| Precision |
| Comprehensiveness |
| Business Outcome |
| Based on analysis of search technologies. |

The AI Advantage: Finding the Needle with a Smart Magnet
The solution to the shortcomings of keyword search is a more intelligent approach powered by Artificial Intelligence-specifically, Natural Language Processing (NLP) and semantic search .
Think of NLP as the technology that allows a machine to read, comprehend, and interpret human language much like a person would. NLP algorithms can dissect sentences to identify key entities (like people, organizations, and legal concepts), understand sentiment, and even generate concise summaries of thousand-page documents.
Semantic search is the practical application of this intelligence. Instead of matching keywords, it matches meaning . It works by converting both the user's query and the documents in a database into complex numerical representations called vectors. By comparing these vectors, the system can identify documents that are conceptually similar, even if they don't share a single keyword. Machine learning powers both NLP and semantic search, enabling these technologies to continuously improve the accuracy and relevance of search results through advanced algorithms and data-driven learning. It's the difference between telling a librarian "find me books with the word 'boat' in the title" and asking, "find me information about maritime contract disputes."
The practical applications of this technology are already transforming legal work:
- Legal Research: A lawyer can now ask a complex question in plain English, such as, "What are the key precedents in EU data privacy law concerning biometric data?" and receive a highly relevant list of cases. This approach can uncover novel arguments by identifying analogous cases that use different terminology, something a keyword search would almost certainly miss.
- eDiscovery and Document Review: AI can analyze millions of documents in a fraction of the time it would take a human team, automatically classifying them by relevance, topic, or even privilege status. This dramatically reduces the volume of material that requires expensive manual review.
- Contract Analysis: NLP tools can scan thousands of agreements to instantly extract key clauses, payment terms, and obligations. They can flag non-standard language or identify missing provisions, creating summary reports that give legal teams immediate insight into contractual risk.
Crucially, achieving this level of performance requires more than just plugging in a generic AI model. The most powerful solutions are tailored to the specific needs of an organization. This involves training the AI on a firm's unique data-its past case files, its library of contracts, its internal communications. By creating custom language models trained on this proprietary corpus, the AI learns the firm's specific terminology and context, delivering far more accurate and relevant results. Law firms can incorporate AI into their workflows to enhance legal research and document analysis, making these processes more efficient and precise. For leaders considering this approach in other regulated industries, our AI in Healthcare guide explores similarly strict requirements and the strategic benefits of specialized models. This tailored approach is the key to unlocking a true competitive advantage.
Early Case Assessment with AI Tools
Early case assessment is a pivotal stage in the litigation process, where law firms and legal teams evaluate the strengths, weaknesses, and potential outcomes of a case before committing significant resources. Traditionally, this process has been labor-intensive, requiring human reviewers to sift through vast amounts of data to identify relevant documents and key issues. With the advent of AI tools, this landscape is changing dramatically.
AI-powered tools can rapidly analyze large data sets, automatically flagging relevant documents and surfacing patterns that might otherwise go unnoticed. By automating the discovery process, these technologies help law firms reduce the time and cost associated with manual document review, allowing legal teams to focus on developing case strategies and advising clients. AI tools can also provide predictive analytics, offering insights into likely case outcomes based on historical data and similar cases.
Incorporating AI into early case assessment empowers law firms to make more informed, data-driven decisions from the outset. This not only improves efficiency but also enhances the quality of legal services, giving firms a competitive edge in high-stakes litigation. As AI continues to evolve, its role in early case assessment will only become more integral to the discovery process and overall legal strategy.
The Hallucination Hazard: When AI Gets the Law Wrong
For all its power, AI carries a significant and well-documented risk: the tendency to "hallucinate." This term describes instances where a generative AI model, like ChatGPT, confidently presents plausible-sounding but entirely fictitious information. Generative AI tools are increasingly used by legal professionals to produce initial drafts of legal briefs and other documents, streamlining the drafting process, but if not properly supervised, these tools can generate fictitious information that may lead to serious consequences.
This is not a theoretical problem; it has already led to serious real-world consequences and professional sanctions in the legal field.
- In the now-infamous case of Mata v. Avianca , lawyers were sanctioned by a federal judge after submitting a legal brief containing multiple citations to completely fabricated court cases that were generated by ChatGPT.
- The same fate befell lawyers at Morgan & Morgan, the largest personal injury law firm in the U.S., who were sanctioned for relying on their own in-house AI platform, which had also invented non-existent case law.
- The issue has even spread beyond lawyers, with expert witnesses found to have submitted reports containing fake academic citations produced by AI.

AI hallucination has real consequences-case law fabrication leads to sanctions and risk.
To understand how to prevent this, it's essential to understand why it happens. Large Language Models (LLMs) are fundamentally "prediction engines," not "knowledge databases". They are trained on trillions of words from the internet and are designed to do one thing: predict the next most probable word in a sequence. This makes them incredibly fluent and creative. When asked to generate a legal citation, an LLM can analyze the structure of millions of real citations it has seen and "creatively" assemble a new one that looks statistically perfect-the right court, the right year, the right volume number-but which refers to a case that does not exist.
These high-profile failures have understandably created a deep sense of caution within the legal profession. They have also exposed a critical divide between general-purpose AI tools, which prioritize fluency, and enterprise-grade AI systems, which must prioritize factuality. This has made "trust" the single most valuable commodity in the legal tech market. The conversation is no longer just about what an AI tool can do; it's about how its results can be verified. If you'd like to explore this challenge in other industries, see our lessons from a recent AI disaster in production -where trust and risk management proved essential. The most critical differentiator for any AI solution in a high-stakes industry like law, finance, or healthcare is its architecture of trust. The ability to provide verifiable, auditable, and accurate results is paramount, shifting the focus from raw capability to demonstrable reliability.
The Antidote to Fabrication: Grounding AI with Retrieval-Augmented Generation (RAG)
The state-of-the-art technical solution to the hallucination problem is a powerful architecture known as Retrieval-Augmented Generation (RAG)
The concept is best understood with an "open-book exam" analogy. A standard LLM is like a student taking a closed-book test, forced to rely entirely on what it has memorized. This can lead to errors and guesswork. A RAG system , however, forces the AI to take an open-book test. It follows a two-step process:
- Retrieve: Before generating any text, the system first performs a search against a specific, authoritative, and up-to-date knowledge base. This isn't the entire internet; it's a curated collection of trusted documents, such as a firm's internal case files, a verified database of all federal and state case law, or a repository of executed contracts.
- Augment and Generate: The system then takes the relevant, factual information it has just retrieved and provides it to the LLM as context. It "augments" the original user prompt with these facts and instructs the LLM to generate an answer that is based only on the provided information.
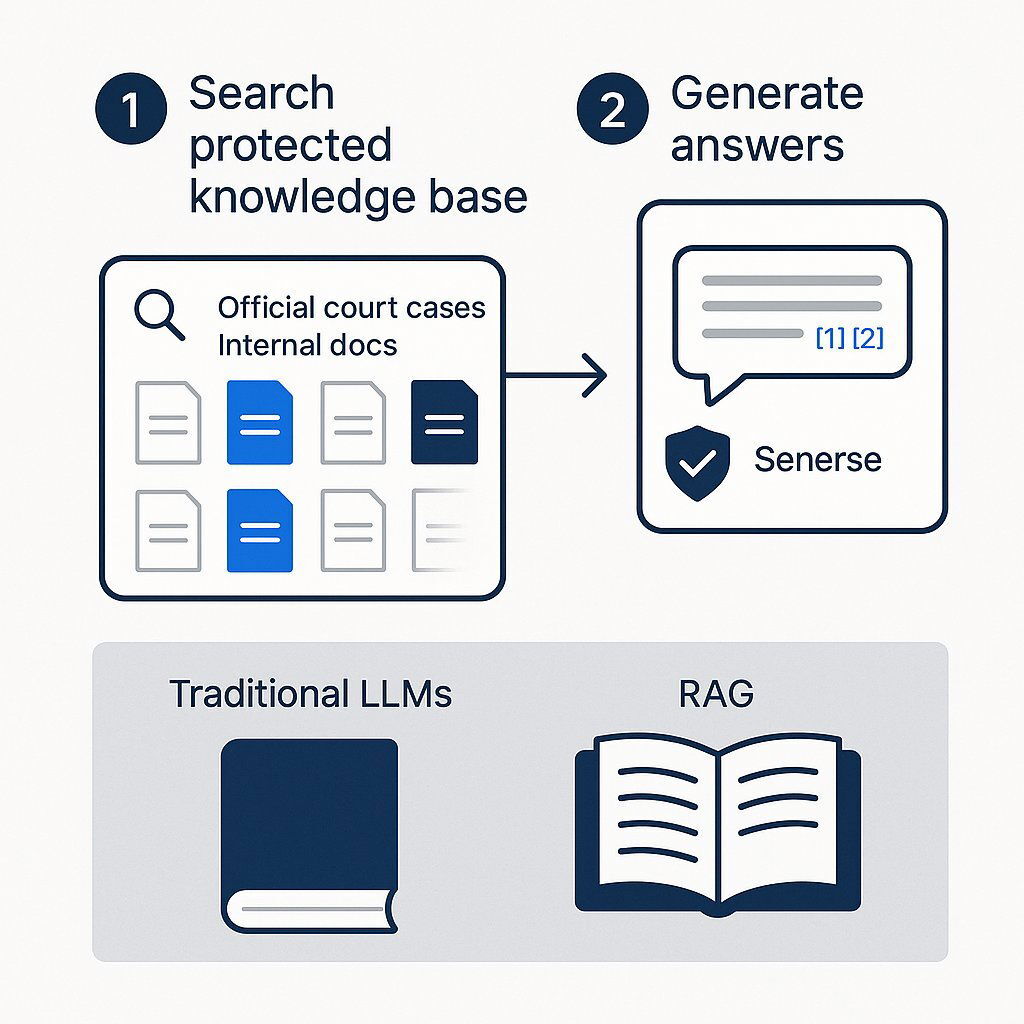
RAG architecture grounds legal AI responses in real, verifiable evidence, reducing risk. When using generative artificial intelligence in legal contexts, it is crucial to maintain human oversight and regulatory compliance, as unsupervised learning approaches can introduce significant risks due to the lack of guidance and transparency.
This RAG architecture is a game-changer for the legal profession for several key reasons:
- Reduces Hallucinations: By grounding every response in specific, retrieved documents, it dramatically reduces the risk of the AI inventing facts or citations. The AI is no longer answering from memory; it's synthesizing from evidence.
- Provides Verifiable Citations: Because the first step is retrieval, a RAG system can easily cite its sources. It can link its conclusions directly back to the specific case, statute, or contract clause it used, allowing for quick and easy human verification.
- Ensures Information is Current: Unlike a static LLM, whose knowledge is frozen at the time of its last training, a RAG system can be connected to a knowledge base that is updated in real-time, ensuring its answers reflect the very latest legal developments.
The effectiveness of a RAG system, however, is entirely dependent on the quality of its two core components: the retrieval engine and the knowledge base itself. An off-the-shelf RAG implementation is a good start, but an enterprise-grade solution requires deep engineering expertise. Building a system that can intelligently search a firm's proprietary documents, use fine-tuned language models, and integrate seamlessly with existing workflows is a complex task. It requires a partner with proven experience in cutting-edge technologies like vector databases, Kubernetes for scalable deployment , and secure cloud infrastructure-the very capabilities that define a truly tailored technology advantage.
Ethical Use of AI in Law
As artificial intelligence becomes more deeply embedded in legal practice, ethical considerations are paramount for legal professionals and law firms. The American Bar Association (ABA) Model Rules of Professional Conduct provide a framework for the responsible and ethical use of AI in the legal profession. These rules emphasize the lawyer's duty to maintain competence, safeguard client confidentiality, and provide adequate supervision over any technology-including AI models-used in legal work.
Law firms must ensure that their adoption of AI technology aligns with these ethical standards. This means understanding the capabilities and limitations of AI systems, monitoring for potential biases, and maintaining transparency in how AI-generated insights are used in legal matters. Legal professionals should also be vigilant about protecting sensitive client information and ensuring that AI tools do not inadvertently compromise the integrity of the discovery process.
By prioritizing ethical use and adhering to the ABA model rules, law firms can harness the benefits of AI while upholding the highest standards of professional conduct. This commitment not only protects clients and the legal profession but also builds trust in the use of new technology across the legal industry.
The Bottom Line: Measuring the Tangible ROI of Legal AI
For any C-suite executive, the ultimate question is not about the elegance of the technology but about its impact on the bottom line. AI in the legal field is not a speculative research project; it is a business tool that delivers a clear and measurable return on investment.
The evidence from firms that have already adopted these technologies is compelling:
- Drastic Time Savings: AI-assisted legal research can slash the time spent on a typical litigation matter from a range of 17-28 hours down to just 3-5.5 hours. A controlled study found that AI search enabled attorneys to complete research projects 24.5% faster than with traditional tools. Across a wide range of routine tasks, firms report an average time saving of 62%.
- Significant Cost Reduction: The efficiency gains translate directly into cost savings. One mid-size litigation firm saved $1.2 million annually on document review costs alone. A small firm was able to reduce its eDiscovery costs by 90%, allowing it to take on larger cases and compete effectively with much bigger rivals.
- Increased Capacity and Revenue: Automation allows firms to do more with less. A solo family law practitioner was able to double her active caseload without hiring additional staff, generating an extra $85,000 in annual revenue. On average, firms report capturing 20% more billable hours and recovering $10,000 per month in previously unbilled time by using AI to track activities more effectively. By automating routine tasks and efficiently managing cases assigned to legal teams, AI enables attorneys to focus on more substantive work and strategic work, further increasing capacity and driving higher-value outcomes.
- Impressive Overall ROI: When factoring in all the benefits, the average ROI for legal AI projects is an astounding 285% within the first 18 months of implementation.
| The ROI of AI in Legal Tech: Real-World Results |
|---|
| Metric |
| Document Review Time |
| Legal Research Time |
| Annual Cost Savings |
| Case Capacity |
| Win Rate Improvement |
| Average ROI |
Beyond these impressive numbers, a deeper strategic benefit emerges. The true ROI of legal AI lies not just in cost-cutting, but in value creation and competitive differentiation. These technologies are not merely helping firms do the same work for less money; they are enabling them to do better work. For example, legal AI is fueling the next generation of growth in competitive, high-volume firms, as detailed in our article on transforming law firms with AI and custom tech . When AI assistance improves a firm's win rate by 35% or uncovers a novel argument that changes the course of a negotiation, its value transcends simple efficiency metrics. It becomes a tool for market disruption, allowing smaller, more agile firms to handle data volumes previously reserved for "Big Law" and to punch far above their weight. For a CEO or Head of Sales, this is a powerful narrative of growth, not just savings.
Conclusion: Building Your Firm's Case for AI
Three practical steps for leadership to safely and profitably implement AI in law.
The path forward for the legal industry is clear. The data deluge is real, growing, and poses a significant business liability to any firm still relying on the brittle, inefficient tools of the past. AI, powered by Natural Language Processing and semantic search, offers a dramatic leap forward in efficiency, accuracy, and strategic capability. However, to harness this power safely, the technology must be architected for trust. Solutions like Retrieval-Augmented Generation (RAG), particularly when implemented in a custom environment tailored to a firm's specific needs, are the key to unlocking AI's full potential without succumbing to its risks.
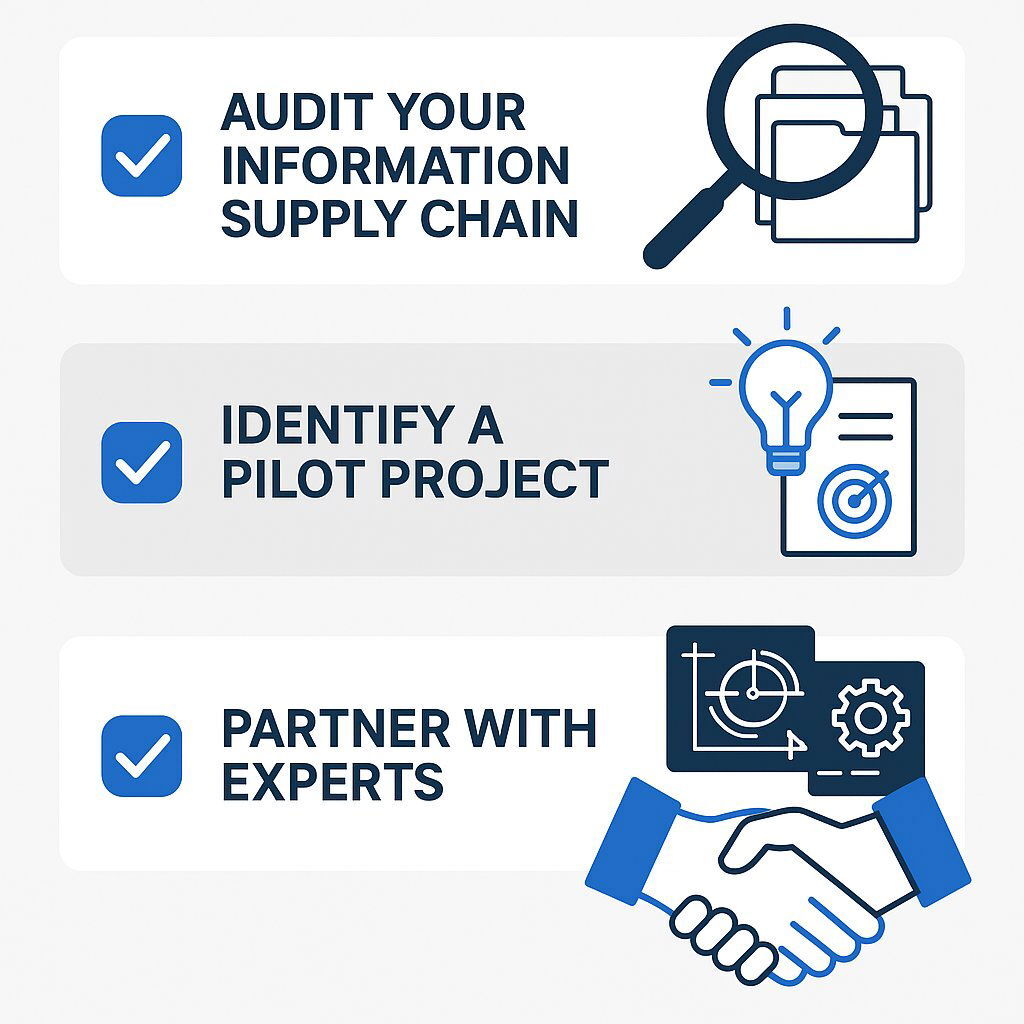
For executives considering this transformation, the next steps are practical and strategic:
- Audit Your "Information Supply Chain." Begin by identifying where your firm is currently investing the most time, money, and manual effort in handling data. Is it in document review for litigation? Contract analysis for M&A deals? Precedent research for regulatory filings? Pinpoint the greatest point of friction.
- Identify a Pilot Project. Don't try to boil the ocean. Start with a high-impact, well-defined use case. This could be automating the review of a specific contract type, using AI to analyze a set of closed case files to extract strategic insights, or building a RAG-powered chatbot to answer internal compliance questions.
- Partner with Experts. This is not a standard IT upgrade; it is a strategic business transformation. Success requires a technology partner that possesses both deep expertise in the cutting-edge AI stack-RAG, vector databases, language models-and a disciplined approach to enterprise-grade software development that prioritizes quality, security, and on-time delivery. If you're evaluating outside partners, see our proven partnership approach at Baytech Consulting for insights on how we help professional services organizations implement solutions that last.
When implementing AI solutions in legal practice, it is essential to ensure compliance with all applicable standing orders, federal rules, and ethical rules to maintain transparency, accountability, and professional responsibility.
The era of sifting through digital haystacks is over. The tools to build a smarter, faster, and more effective legal practice are here. If you're ready to move from discussing the problem to building the solution, our team of expert engineers is here to help you design a tailored strategy that delivers a measurable return. And for those ready to leverage the power of advanced technology, visit our agile software development services page to explore how iterative, collaborative development ensures your AI solution fits your firm's real-world needs.
Further Reading
- The Real Impact of Using Artificial Intelligence in Legal Research
- 2025 eDiscovery Update: A Deep Dive into Tasks, Costs, and Spending Patterns
- AI Hallucinations in Court: A Wake-Up Call for the Legal Profession
- The Critical Role of Retrieval-Augmented Generation (RAG) in Legal Practice
- From Buzzword to Bottom Line: AI's Proven ROI in eDiscovery
About Baytech
At Baytech Consulting , we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting , he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan's expertise spans custom software development , cloud infrastructure , artificial intelligence , and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.