
Unlocking Corporate Knowledge: How AI Transforms Document Chaos into Strategic Advantage
July 25, 2025 / Bryan Reynolds
Your Company's Hidden Genius: How AI Unlocks Decades of Knowledge Trapped in Documents
Every organization suffers from a form of corporate amnesia. Within your servers, cloud storage, and email archives lies a vast, invaluable repository of institutional knowledge—decades of project proposals, financial reports, customer feedback, technical specifications, and strategic plans. This is your company's collective genius, the sum of its experience and expertise. Yet, for most businesses, this asset is largely inaccessible, locked away in disconnected systems, forgotten folders, and the minds of former employees. This isn't merely an operational inconvenience; it's a silent and persistent drain on productivity, innovation, and profitability.
The promise of Artificial Intelligence has often been framed around futuristic concepts, but its most immediate and profound impact is far more practical. Modern AI offers a fundamental shift in how businesses can interact with their own accumulated knowledge. It can function as a perfect corporate memory, an intelligence capable of reading, understanding, and synthesizing everything your company has ever known, learned, or documented. This technology can instantly surface the critical data point buried in a five-year-old report, connect a customer complaint from last week to a known bug documented by an engineer three years ago, and provide your teams with the precise information they need, the moment they need it.
This report is designed to answer the most pressing questions executives have about this transformative technology. It will move from the "Why"—exploring the steep and often hidden costs of knowledge chaos—to the "How," demystifying the technology that makes this possible. It will then cover the "What," providing clear, measurable return on investment, and finally, the "Next Steps," offering a practical guide to implementation, security, and governance. This is a roadmap for turning your company's greatest untapped asset into a powerful engine for competitive advantage.
Why Can't We Find Anything? The Hidden Costs of Knowledge Chaos

The frustration of not being able to find a critical piece of information is a universal experience in the modern enterprise. However, for executive leadership, this daily annoyance scales up to a significant strategic liability. The problem manifests differently across departments, but the cumulative effect is a slower, less efficient, and less competitive organization. Validating these frustrations by articulating the specific, cross-departmental pain points is the first step toward understanding the scale of the opportunity.
Your Question (CFO): What is the real financial drain of our scattered data?
For a Chief Financial Officer, knowledge chaos is not a soft problem; it is a hard-line item that directly impacts the bottom line through operational inefficiency, increased risk, and flawed strategic planning. The modern CFO is expected to be a strategic guide for the business, but this role is rendered nearly impossible when critical financial and operational data is fragmented across a multitude of disconnected systems, departments, and spreadsheets. This fragmentation shatters any hope of a single, reliable view of the organization's financial health.
This data disarray is a direct fuel for inefficiency. Finance teams become bogged down in a cycle of manual, error-prone work, such as closing the books with complex spreadsheets or painstakingly reconciling transactions from multiple, inconsistent sources. The poor quality of this data—riddled with inaccuracies, inconsistencies, and outdated information—forces costly and time-consuming data-cleaning efforts that consume valuable resources and delay critical reporting. This is not a one-time cost; it is a recurring operational tax on the finance function.
The strategic impact is even more severe. Without a solid foundation of trustworthy, integrated data, financial forecasting devolves into "guesswork". When flawed data leads to incorrect conclusions, the strategic decisions built upon that analysis are inherently misguided. This directly hinders a CFO's ability to strike the crucial balance between funding growth and maintaining cost discipline, as it becomes impossible to know with certainty where to invest for long-term gains or where to cut costs without compromising performance.

This dynamic creates a vicious cycle of financial inefficiency. It begins with fragmented data from siloed systems like CRMs and ERPs, which leads to unreliable forecasts. The business then makes strategic bets based on this flawed data. When these initiatives underperform, it creates budget pressure. Faced with this pressure, a CFO is understandably hesitant to approve a large capital expenditure for a project like "data infrastructure modernization," as its ROI appears less immediate than that of a new sales campaign. This lack of investment perpetuates the data silos, and the cycle repeats, continuously eroding the company's strategic agility and financial health. This transforms the problem from a simple inefficiency into a form of "strategic debt" that accrues interest over time in the form of missed opportunities and poor decisions.
Finally, this environment of poor data governance and siloed information creates significant and often unquantified compliance risks. Improperly stored or managed customer and financial data can lead to non-compliance with regulations like GDPR, resulting in hefty fines and lasting reputational damage.
Your Question (CTO): Why is our existing tech stack failing to solve this?
For a Chief Technology Officer, the problem of knowledge management is rooted in the architectural limitations of legacy systems and the inherent complexity of enterprise information retrieval—a challenge that most off-the-shelf tools were never designed to handle. The core issue often lies in obsolete technology built on a decentralized architecture, where knowledge becomes trapped in siloed repositories like individual Google Drives, departmental Dropbox accounts, and personal email archives. Over time, each department organically develops its own taxonomy, file-naming conventions, and data-sharing methods, making cross-departmental collaboration and information discovery a technical and cultural nightmare.

This data fragmentation is a systemic barrier to efficiency. Even in companies with modern tools, critical business information exists in dozens of formats—from the structured data in CRMs and ERPs to the vast ocean of unstructured content in PDFs, Word documents, slide decks, and emails. This diversity and volume pose a massive scalability challenge for any single retrieval system. As a result, standard enterprise search is fundamentally broken. It consistently fails to deliver relevant results because it cannot truly understand user intent. A typical search either returns only exact keyword matches, missing the contextual meaning of a query, or it produces a flood of irrelevant information, forcing the user to manually sift through pages of useless results. This poor user experience leads to low adoption rates, widespread frustration, and a return to inefficient, manual methods of finding information.
This technical debt is compounded by the immense pressures on a modern CTO: keeping company data secure, accelerating software development, and managing team productivity, often in an environment of reduced budgets and shifting priorities. Attempting to build a custom solution to the knowledge retrieval problem from scratch is a monumental undertaking that can divert critical engineering resources away from core product innovation and strategic initiatives.
This situation creates an "Integration Paradox" for the CTO. The more best-of-breed, specialized tools the CTO provides to solve specific departmental problems—a new CRM for Sales, a sophisticated project management tool for Engineering—the more severe the enterprise-wide knowledge problem becomes. Each new application creates another data silo, an isolated island of information with its own API, data structure, and access protocols. To create a unified view, the CTO must then fund and oversee a series of complex, expensive, and time-consuming integration projects to connect these disparate systems. As the business grows and adopts more tools, this integration burden compounds exponentially. Consequently, the CTO's budget and their team's time are increasingly consumed by the "undifferentiated heavy lifting" of maintaining these fragile connections, rather than driving the strategic innovation the business needs to compete. The very act of empowering individual teams with better tools inadvertently creates a larger, more expensive strategic problem for the enterprise as a whole.
Your Question (Sales & Marketing): How much opportunity are our teams losing?

For Sales and Marketing leaders, the consequences of poor knowledge management are not abstract; they translate directly into lost revenue, inconsistent brand messaging, and a commercial engine that is slower and less competitive than it should be. The speed at which a commercial team can access and apply relevant knowledge is a direct predictor of its competitive velocity. It is not merely about possessing the knowledge, but about the time-to-application .
For sales teams, the impact is felt daily. Reps are consistently hampered when they cannot find the right information at the right time. This could be the most persuasive case study for a specific prospect's industry, the latest technical specifications for a product, or the company-approved talking points for handling a competitor's claims. Every minute spent searching through outdated shared drives or asking colleagues in a chat channel is a minute not spent selling. This friction slows down the entire sales cycle, from proposal generation to closing, and results in less effective, less confident customer interactions.
For marketing teams, effectiveness is contingent on a deep and current understanding of the market, the audience, and past performance. When competitive intelligence, customer data, and campaign results are locked in separate silos, marketers are forced to operate with blinders on. They cannot easily learn from past successes and failures or react quickly to emerging market trends. This leads to generic, one-size-fits-all messaging, inefficient campaign spending, and a failure to personalize the customer experience.
The disconnect between Sales and Marketing, a classic organizational challenge, is dramatically exacerbated by poor knowledge management. Marketing may invest heavily in creating high-quality content and research, but if the sales team is unaware of these assets or cannot easily find them, the investment is wasted. This lack of coordination leads to a disjointed customer journey where the messaging a prospect receives from marketing is inconsistent with their conversation with a sales rep, eroding trust and losing deals. This breakdown in cooperation has been identified as a primary cause of workplace failure and missed objectives.
Furthermore, the hidden costs of onboarding and turnover are significant. In high-turnover fields like sales and marketing, a lack of accessible, centralized knowledge means it takes far longer for new hires to become fully productive. They struggle to learn the products, understand the market, and absorb the institutional wisdom necessary to succeed, placing a continuous drag on team performance.
How Does AI Actually Read and Understand Our Business?
To appreciate how AI solves the deep-seated problem of knowledge chaos, it is essential to look beyond the hype and understand the core technologies at play. This is not about a magical black box, but rather a combination of powerful, understandable engineering principles that, when applied together, allow a machine to interact with information in a way that mimics human comprehension. This section demystifies the two key concepts that make enterprise-grade AI possible: Retrieval-Augmented Generation (RAG) and Vector Embeddings.
Your Question: What is Retrieval-Augmented Generation (RAG) in plain English?
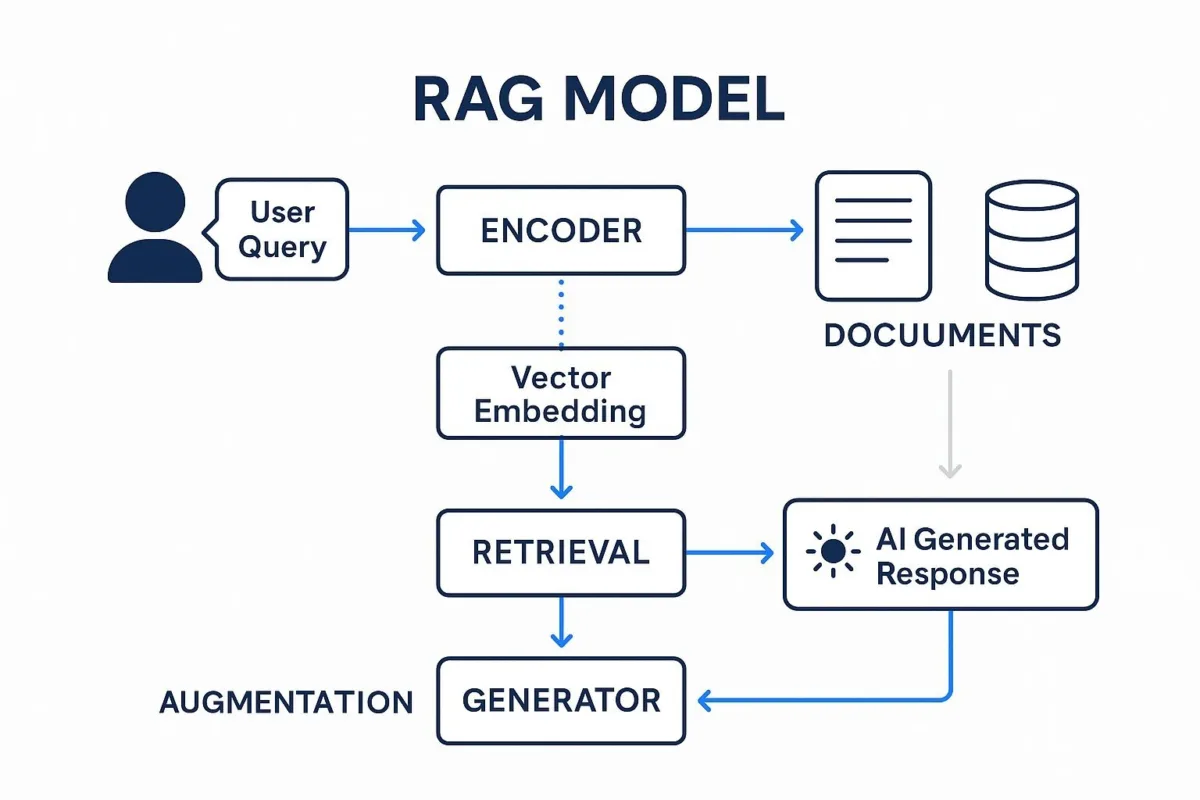
Retrieval-Augmented Generation, or RAG, is the critical architectural framework that makes generative AI safe, reliable, and relevant for business use. It is the fundamental difference between a creative but sometimes unreliable "artist" and a knowledgeable, fact-checking "research assistant." An AI model on its own, like a Large Language Model (LLM), is like a brilliant, well-read intern who has read every book in the public library up to last year. They can write eloquently and reason about general topics, but they have no access to your company's private files, your latest financial reports, or today's news. RAG is the process that gives that intern a security badge, a key to your company's secure internal library, and a real-time news feed. It instructs the intern: "Before you answer any question, go into this library, find these specific, relevant documents, and base your answer only on what you find there."
This process unfolds in a clear, logical sequence:
- Retrieval: When a user asks a question—for example, "What were our sales numbers in the EMEA region for Q3?"—the RAG system does not immediately ask the LLM to answer. Instead, it first performs a highly advanced search across your company's designated knowledge sources (such as documents on a shared drive, data in a CRM, or articles in a knowledge base) to find the most relevant snippets of information.
- Augmentation: The system then takes the retrieved information—perhaps a paragraph from the Q3 financial summary and a data table from a sales report—and "augments" the user's original question with it. The prompt sent to the LLM now effectively says: "Using only the following facts: [insert retrieved text and data], answer the question: What were our sales numbers in the EMEA region for Q3?"
- Generation: The LLM then generates an answer that is grounded in the provided, company-specific facts. This simple but powerful step dramatically reduces the risk of "hallucinations"—the term for when AI models confidently state information that is factually incorrect.
The key business benefit of this framework is profound: it ensures that the AI's outputs are based on your organization's own trusted, secure, and up-to-date information, not just its generic, pre-trained knowledge base. This makes the AI a reliable tool for mission-critical business tasks.
Your Question: How can a computer 'understand' meaning? A non-technical look at Vector Embeddings

While RAG provides the "what," vector embeddings provide the "how." They are the secret sauce that allows the retrieval step in RAG to be so intelligent, enabling the AI to move beyond simple keyword matching to understand the context, nuance, and conceptual relationships within your company's data. Vector embeddings are numerical representations—or mathematical "fingerprints"—of data, whether that data is a word, a sentence, a full document, or even an image. They act as a universal translator, converting complex, human-centric information into a structured language of numbers that machines can efficiently process and compare.
The most effective analogy is to imagine a vast, intelligent library where books are not organized alphabetically by title but by their core concepts. All books about "financial risk management" are clustered in one corner of the room. All books on "brand marketing strategy" are in another, far away. Crucially, books with closely related topics, like "Q3 financial performance" and "quarterly earnings reports," would be placed right next to each other on the same shelf. Vector embeddings create this "semantic map" for all of your company's digital information.
The power of this approach lies in proximity. The key insight is that items with similar meanings will have numerically similar "fingerprints" and will therefore end up close to each other in this multi-dimensional mathematical space. This allows an AI to precisely measure the conceptual similarity between any two pieces of information. This capability is what enables a truly powerful semantic search. A sales manager can search for "ideas for reducing supply chain costs," and the system can instantly find a report titled "Logistics Optimization Initiative Q4," even though the exact search terms are not present in the document's title. The system understands the
intent behind the query, not just the keywords.
This technology can even capture complex, abstract relationships. The classic academic example is that the vector for "King" minus the vector for "Man" plus the vector for "Woman" results in a vector that is extremely close to that of "Queen". In a business context, this same logic could apply: the vector for "Q4 Sales Report" minus the vector for "Sales Data" plus the vector for "Marketing Spend" could point directly to a document analyzing marketing ROI.
It is critical for executives to understand that RAG and vector embeddings are not independent technologies; they are deeply symbiotic. RAG provides the essential framework for building trustworthy, fact-based AI, but vector embeddings provide the intelligent retrieval mechanism that makes the framework truly powerful. One is largely ineffective without the other in a complex corporate knowledge environment. The quality of the "R" (Retrieval) in RAG is entirely dependent on the quality of the vector search. A RAG system that relies on a weak, keyword-based retrieval engine is like a brilliant researcher who is only allowed to use the index at the back of a book instead of being able to read and understand the chapters. Investing in an "AI chatbot" without understanding its underlying retrieval mechanism is a recipe for disappointment. The real magic, and the real business value, lies in the sophisticated combination of these two technologies.
What's the Real ROI? From Cost Center to Profit Driver
Moving beyond the technical underpinnings, the most critical question for any executive is about the return on investment. Investing in AI for knowledge management is not a speculative bet on future technology; it is a proven strategy with a clear, multi-faceted, and measurable return that spans operational efficiency, direct cost savings, new revenue generation, and enhanced employee and customer satisfaction. The value is not abstract; it manifests in daily, tangible improvements for every key department in the organization.
Your Question: What specific, measurable results can we actually expect?
The evidence from companies that have successfully implemented AI to manage their knowledge and customer interactions is compelling and quantifiable. The ROI is not limited to a single metric but is seen across the entire business, from the back office to the front lines. The following table collates specific, measurable results from real-world case studies across various industries, demonstrating the tangible impact of these technologies.
| Category | Metric | Company/Industry Example |
|---|---|---|
| Operational Efficiency & Speed | 70% reduction in drug discovery time | AstraZeneca |
| 60% reduction in time spent on clinical documentation | Mass General | |
| 90% jump in speed of compliance and call reviews | FFAM360 (Finance) | |
| 3x faster customer response and resolution time | H&M | |
| 40% decrease in loan processing time | QuickLoan Financial | |
| Cost Reduction & Savings | 25% reduction in customer service costs | American Express |
| $20M+ savings in transportation costs | General Mills | |
| 12% decrease in production costs | Siemens | |
| 10% reduction in inventory costs | Unilever | |
| 30% reduction in recruitment costs | Eightfold AI Case Study | |
| Revenue Growth & Conversion | 25% increase in conversion rates during chatbot interactions | H&M |
| 5% improvement in sales | PPS (Insurance) | |
| 20% increase in annual returns for clients | CapitalGains Investments | |
| 39% of inquiries turned into leads | INATIGO (Finance) | |
| Employee & Customer Experience | 17% decrease in call center load | Bank of America |
| 10% increase in customer satisfaction | American Express | |
| 70% of customer queries resolved autonomously | H&M | |
| 15% increase in customer retention | Sparex |
Your Question: How will this impact my department's day-to-day work?
The true paradigm shift enabled by this technology is the move from simple "knowledge retrieval" to powerful "knowledge synthesis." The old model of knowledge management is a search bar. A user searches for "Q3 performance" and gets back a list of ten documents: a spreadsheet, a PowerPoint presentation, and eight emails. The user still bears the cognitive load of opening each document, reading it, and mentally synthesizing the disparate pieces of information into a coherent answer. This is basic retrieval.
The new AI-powered model allows a user to ask a direct question: "What were the key drivers of our Q3 performance, and how did it compare to our forecast?" The AI uses its RAG and vector search capabilities to identify the relevant sections within the spreadsheet (the raw numbers), the PowerPoint (the executive summary), and the emails (the contextual discussion). It then generates a new, synthesized paragraph that directly answers the question, citing its sources. For example: "In Q3, performance exceeded forecasts by 7%, primarily driven by a 15% growth in the EMEA region (Source: Q3_Financials.xlsx), though the APAC region saw a 3% decline due to supply chain issues (Source: Q3_Board_Deck.pptx)." This is a fundamentally different and more valuable interaction. It elevates the value proposition from a simple time-saver to a true intelligence-amplifier, with specific applications for each department:
- For Sales: Imagine a sales representative preparing for a crucial call. Instead of spending an hour searching for materials, they can ask their phone, "Give me the top three talking points and the most relevant case study for a prospect in the logistics industry who is concerned about on-time delivery." The system instantly synthesizes this information, pulling key differentiators from the latest marketing materials and surfacing the Siemens case study, which highlights a 99.5% on-time delivery rate achieved through their own operational improvements. This capability accelerates deal cycles, increases rep confidence, and improves win rates.
- For Marketing: A marketing manager planning for the next quarter can ask, "What were the key takeaways from our Q1 campaigns across all channels, and what were the dominant customer feedback trends we saw on social media during that period?" The AI can synthesize performance reports from the analytics platform, budget data from the finance system, and sentiment analysis from social listening tools. This provides a holistic view in minutes that would have taken a team of analysts days to compile manually, enabling faster, more data-driven campaign planning and resource allocation.
- For HR and Onboarding: A new employee can bypass the frustrating and inefficient process of searching through a confusing intranet or asking colleagues basic questions. They can simply ask, "What is our company policy on remote work, and where do I find the sales training deck from Q3?" The AI provides instant, accurate answers with links to the source documents, drastically reducing the time it takes for new hires to become productive and integrated into the company. This directly addresses the significant pain point of onboarding delays and improves the new employee experience.
- For Product & Engineering: A developer working on a complex and recurring bug can ask, "Show me all technical documentation, past support tickets, and internal chat discussions related to the 'session timeout' error in the main application." The system can retrieve this institutional knowledge, which might otherwise have been lost when a senior developer left the company. This prevents the team from "reinventing the wheel" and wasting valuable engineering cycles solving a problem that has already been solved before, a common pitfall detailed in legacy software modernization guides.
How Do We Implement This? The 'Build vs. Buy' Dilemma
Once the strategic value of AI-powered knowledge management is clear, the conversation naturally shifts to implementation. This leads to one of the most critical decisions an organization will make on its AI journey: whether to purchase a pre-built, off-the-shelf tool or to partner with a specialist firm to build a custom solution. This choice involves a careful weighing of trade-offs between speed, cost, flexibility, and long-term competitive advantage.
Your Question: Should we build a custom solution or buy an off-the-shelf tool?
This decision requires a strategic assessment of your organization's unique needs, resources, and long-term goals. There is no single right answer, but a structured comparison can illuminate the best path forward for your company. For a deeper exploration of this choice, see our analysis of custom software vs. commercial off-the-shelf solutions.
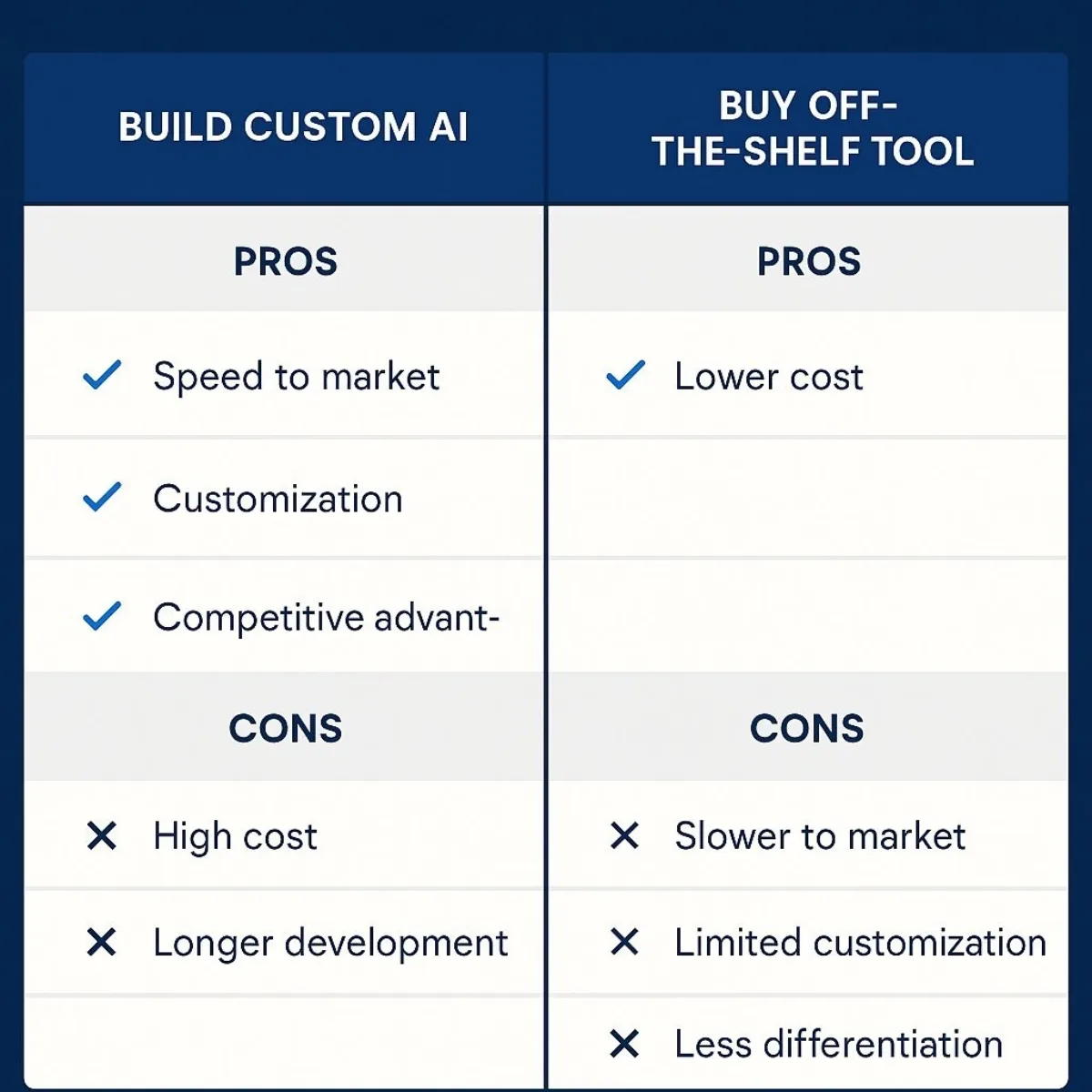
| Factor | Buy (Off-the-Shelf Solution) | Build (Custom Solution with a Partner) |
|---|---|---|
| Speed to Market | Faster. Off-the-shelf tools can often be deployed in a matter of days or weeks, providing a quick way to start addressing immediate pain points. | Slower. A custom build is a more deliberate process, requiring careful planning, development, and testing. A typical pilot project alone can take 2-3 months. |
| Cost | Lower initial cost, but with ongoing subscription fees that can become substantial over time. The ROI can be lower if the tool's generic nature leads to low automation rates. | Higher upfront investment is required for development. However, this can lead to a higher long-term ROI through tailored efficiency gains and the absence of recurring licensing fees. |
| Customization & Integration | Limited. You are fundamentally constrained by the vendor's feature set and roadmap. Integration with unique, proprietary, or legacy systems can be a significant and often insurmountable challenge. | Total Customization. The solution is designed and built to your exact workflows, data sources, and business logic. Deep integration with all existing systems, no matter how unique, is a primary objective. |
| Competitive Advantage | Low. Your competitors have access to the exact same tool. Any advantage gained is purely operational and temporary, not strategic or defensible. | High. A custom solution built around your company's unique data, processes, and expertise becomes a proprietary intellectual asset. It is a defensible competitive advantage that cannot be easily replicated. |
| Maintenance & Governance | Handled entirely by the vendor. Your organization benefits from their continuous improvements but has little to no control over their development roadmap, security protocols, or data governance policies. | Requires a partnership for ongoing maintenance and support. However, it provides your organization with full control over the system's security, governance framework, and future development roadmap. |
| Talent & Resources | Requires less specialized in-house AI talent, as you are effectively leveraging the vendor's expertise. | Requires a strong partnership with a team of external experts, such as data scientists and AI engineers, to design, build, and maintain the solution. |
Your Question: When does a custom solution with a partner like Baytech Consulting make sense?
While off-the-shelf tools can be effective for solving generic, well-defined problems, a custom solution becomes the superior strategic choice when your organization's knowledge is a core component of its competitive edge. This path is for businesses that recognize their data and processes are unique and cannot be shoehorned into a one-size-fits-all product. A custom build is the right decision for organizations that need to integrate deeply with proprietary or legacy systems, have highly specialized workflows, or want to build a long-term, strategic asset that grows with the business.
This is where a partnership with a specialist firm like Baytech Consulting becomes invaluable. A true partner is not just a "builder" or a vendor; they are a strategic guide who helps navigate the complexities of a custom AI implementation from start to finish. They specialize in filling the critical gaps left by generic solutions. Where an off-the-shelf tool fails to integrate with your 20-year-old proprietary ERP system, a partner like Baytech builds the custom bridge that makes the connection seamless. They understand that the ultimate goal is not simply to deploy a piece of technology, but to generate a tangible and rapid return on investment. This approach is designed for companies that view AI not as a cost-saving side quest, but as a central pillar of their digital transformation strategy.
Your Question: What's a safe and effective first step?
Embarking on an AI journey does not require a massive, multi-million dollar commitment from day one. The most successful implementations begin with two smart, manageable, and value-driven steps: a thorough Knowledge Audit and a focused Pilot Project.
Step 1: The Knowledge Audit Before you can effectively manage your knowledge with AI, you must first understand its current state. A knowledge audit is a systematic process designed to answer critical questions: What knowledge does our organization possess? Where does it live? Where are the most significant gaps and bottlenecks? And how does information currently flow—or fail to flow—between teams? This process typically involves creating a comprehensive inventory of all content, interviewing subject matter experts from across the business to capture tacit knowledge, and analyzing usage data from existing systems to identify pain points. The output of a knowledge audit is a clear, actionable map of your organization's knowledge assets and challenges, which forms the concrete business case for your AI pilot project.
Step 2: The Pilot Project An AI pilot project is a small-scale, time-limited experiment designed to test the feasibility, value, and user acceptance of an AI solution in a controlled, real-world environment. It is the best way to de-risk a larger investment and prove the technology's ROI. Best practices for a successful pilot include:
- Define a Specific, High-Impact Problem: Do not try to solve everything at once. Focus on a single, well-defined pain point where improvement can be clearly measured. For example, a strong pilot objective would be: "Reduce the average time our Tier 1 customer support team spends searching for troubleshooting guides by 50% within three months".
- Set Clear, Measurable KPIs: Success must be defined upfront. Use the SMART (Specific, Measurable, Achievable, Relevant, Time-bound) goal framework to establish clear metrics for success.
- Keep it Short and Focused: A pilot should be long enough to generate meaningful data but short enough to maintain momentum and stakeholder interest. A timeline of two to three months is often ideal.
- Start Small and Scale: Begin with a specific department or a limited user group to minimize disruption, gather valuable feedback, and refine the solution before a broader rollout.
A trusted development partner like Baytech Consulting can be instrumental in these initial stages. Their expertise can help you properly scope the knowledge audit, define a pilot project with realistic and impactful KPIs, and ensure that the project delivers a clear ROI analysis that builds the business case for a full-scale, transformative implementation. For organizations considering digital transformation, our AI powered software development services are specifically tailored to support these first steps and beyond.
Is It Secure? Answering Your Top Governance and Data Privacy Questions
For any executive, particularly a CTO or CFO, the promise of AI is invariably met with a critical question of security and governance. This is not just a compliance checkbox; it is one of the biggest and most legitimate barriers to AI adoption. Building trust in these systems requires a transparent acknowledgment of the risks and a clear, robust strategy for mitigating them. An AI knowledge management system must be built on a foundation of security, not have it bolted on as an afterthought.
Your Question: How do we ensure our sensitive company data remains protected?
Ensuring the security of sensitive company data within an AI system is non-negotiable. This requires a multi-layered defense strategy where security and privacy are embedded into the system's architecture from the very beginning.
First, it is important to be transparent about the potential threats. These are not theoretical risks; they are real-world challenges that a well-architected system must address. Key risks include data poisoning , where malicious actors attempt to corrupt the training data to skew the AI's results, and model inversion attacks , where attackers try to reverse-engineer the AI model to expose the sensitive underlying data it was trained on. Perhaps the most common risk is
unintentional data leakage , where an AI-generated summary or answer inadvertently exposes confidential information or Personally Identifiable Information (PII) that was present in the source documents.
The solution to these challenges is a robust, multi-layered defense:
- Privacy by Design: Security cannot be an add-on. It must be a foundational principle of the system's design. This includes standard best practices like encrypting all data, both in transit and at rest, and utilizing data anonymization or pseudonymization techniques wherever feasible to protect sensitive information before it is ever processed by an AI model.
- Enterprise-Grade Access Control: A critical component of a secure system is the ability to enforce strict, role-based access controls (RBAC). This ensures that users can only ask questions of, and receive answers from, the data sets they are explicitly authorized to view. A sales manager, for example, should not be able to query sensitive HR documents. This granular control is a core feature that can be meticulously implemented in a custom-built system, especially when using AI-powered research assistants designed for enterprise use.
- Secure and Hardened Infrastructure: The AI solution must be deployed on a secure and resilient infrastructure. This is an area where a partnership with an expert firm like Baytech Consulting provides significant value. They can leverage their deep expertise in secure cloud deployment, utilizing platforms like Azure Kubernetes Service (AKS) for scalable and secure management of the AI workloads. Furthermore, they can implement and configure robust network security measures, such as a pfSense firewall, to create a hardened perimeter that protects the entire environment from external threats. This approach abstracts the deep technical complexity of infrastructure security away from the client while ensuring a best-in-class security posture.
- Continuous Audits and Monitoring: A secure system is not static. It requires continuous monitoring for anomalous activity and regular, independent security audits to ensure ongoing compliance with evolving data protection regulations like GDPR and CCPA.
Your Question: Who is responsible for the AI's output?
Ultimately, technology is a tool, and humans remain accountable for its use and its output. The goal of a well-designed AI knowledge management system is not to replace human judgment but to augment it by providing better, faster, and more comprehensive information. A clear governance framework is essential to ensure this relationship remains effective and responsible.
Transparency and Traceability are the cornerstones of this framework. A trustworthy AI system must never be a "black box." It must provide clear and direct source attribution for every answer it generates. When the AI synthesizes a response, users should be able to click a link and be taken to the exact source document—and ideally, the specific paragraph or data point—that the AI used. This traceability is a core feature of the RAG architecture and is essential for building user trust and allowing for human verification of the AI's output.
This leads to the adoption of a "Human-in-the-Loop" model for critical decisions. The AI system is best viewed as a "cognitive assistant" or as part of a "centaur" model, where the machine performs the heavy lifting of research, data retrieval, and synthesis, but a human expert makes the final strategic call based on the information provided. If you are interested in best practices for responsible AI adoption and aligning technology with your business, our AI governance insights can help inform your strategy.
To manage this process, a clear governance framework must be established from the outset. This framework should define roles and responsibilities for knowledge ownership, establish review and approval processes for sensitive or regulated content, and create simple feedback loops that allow users to flag incorrect, biased, or outdated outputs. This continuous feedback is crucial for refining the system's accuracy and relevance over time. When you partner with a firm like
Baytech Consulting to build a custom solution, these governance features are not an afterthought; they are built into the system's DNA. They work with your organization to design auditable, traceable systems and to establish the human oversight processes that are essential for responsible and effective AI deployment.
Conclusion & Call to Action
Your company's decades of accumulated knowledge—currently a fragmented, inaccessible, and often costly liability—represent your greatest untapped strategic asset. The daily frustrations of searching for information, the financial drain of inefficiency, and the missed opportunities from a lack of insight are not unavoidable costs of doing business. They are symptoms of an outdated approach to knowledge management. Modern Artificial Intelligence, when implemented strategically and thoughtfully, offers a direct cure. By leveraging technologies like Retrieval-Augmented Generation and vector embeddings, you can transform this institutional chaos into a powerful, centralized intelligence—an engine for enhanced efficiency, accelerated innovation, and sustainable growth.
The journey from knowledge chaos to knowledge clarity is a strategic imperative in today's competitive landscape. While a generic, one-size-fits-all tool might scratch the surface of the problem, it will not understand the unique nuances of your data, your processes, or your people. A custom solution, built around the very things that make your business unique, is what unlocks true, defensible competitive advantage.
Ready to transform your company's knowledge from a cluttered archive into your most powerful strategic asset? A generic tool won't understand your unique business. Contact Baytech Consulting today for an expert consultation. We'll help you conduct a knowledge audit, design a value-driven pilot project, and build a custom AI knowledge solution that delivers a measurable return on your investment.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.