
What Is RAG? A Business Guide to Retrieval-Augmented Generation in AI
July 15, 2025 / Bryan Reynolds
What is RAG? Retrieval-Augmented Generation (RAG) is an AI approach that combines two strengths: information retrieval and text generation . In simple terms, a RAG-based system first fetches relevant knowledge (from documents, databases, etc.) and then uses a language model (like GPT) to generate an answer based on that information. This hybrid "open-book" strategy results in responses that are both factually grounded and fluent , addressing a key weakness of standard AI models which otherwise rely only on their fixed training data.
Why it matters: RAG is important because it makes AI more accurate, reliable, and domain-aware . Traditional large language models can be like over-enthusiastic new employees - confident but prone to making things up or using outdated info. RAG fixes this by giving the AI access to your up-to-date, authoritative data when answering questions. The result is higher-quality answers (fewer "hallucinations" or errors), relevant to your business context , and often with the ability to cite sources for transparency. This improves user trust and makes AI solutions far more viable for business-critical applications.
Who should care: For CTOs, CIOs, CFOs, and business unit leaders, RAG opens the door to AI systems that can leverage your organization's knowledge - from internal policy docs to industry databases - without expensive model re-training. It enables smarter chatbots, virtual assistants, and workflow automation tools that speak your industry's language (be it real estate listings, financial regulations, healthcare research, educational content, or telecom manuals) with accuracy. In short, RAG turns AI from a generic content generator into a focused problem-solver grounded in real data , which can drive better decision-making and customer service in your enterprise.
Below, we answer 25 common questions about RAG, organized into five sections: Basic Understanding, How It Works, Functionality & Limits, Trust & Safety, and Comparative Questions . By the end of this guide, you'll understand what RAG is, how it works conceptually, what it can and cannot do, how it ensures more trustworthy AI outputs, and how it compares to other approaches. Let's dive in.
1. Basic Understanding
In this section, we cover fundamental questions to clarify what RAG is and why it's transforming business AI.
Q: What exactly is Retrieval-Augmented Generation (RAG)?
A: RAG is a method for improving AI-generated answers by augmenting a generative model with retrieval of external information . Instead of an AI model working from memory alone, RAG allows it to search a knowledge source (like a database, document repository, or the web) for relevant facts and then use those facts to craft its response. Think of a student taking an open-book exam : the student (AI) can look up answers in a textbook (knowledge base) and then write an answer in their own words. By combining retrieval and generation , RAG systems produce responses that carry the creativity and language fluency of AI plus the factual accuracy of retrieved data. In summary, RAG is an AI architecture - not a single tool - that joins a search engine with a language model to deliver answers that are both knowledgeable and articulate .
Q: Why is RAG important for businesses and AI applications?
A: RAG addresses several pain points that businesses face with standard AI. Firstly, it keeps answers accurate and up-to-date . Traditional AI models have a fixed training knowledge (often months or years old) and may confidently give wrong or outdated information. RAG fixes this by pulling in current, authoritative data on demand. Secondly, RAG tailors AI to your domain without requiring expensive re-training. For example, an AI assistant can retrieve your company's policies or industry-specific data when answering questions, ensuring responses are relevant to your context (real estate, finance, healthcare, etc.) rather than generic. This means better customer support, faster employee onboarding, and more informed decision support. Thirdly, RAG improves user trust . Because the AI bases its answers on known sources, it's less likely to "make things up," reducing the risk of misinformation. It can even cite or reference the source documents, giving decision-makers confidence in the answers. In short, RAG makes AI solutions more factual, reliable, and aligned with business needs , which is why it's seen as a game-changer in enterprise AI.
Q: How is RAG different from a standard chatbot or GPT-style model?
A: The difference is in where the answer's knowledge comes from. A standard GPT-based chatbot (without RAG) is like a closed-book exam - it generates answers purely from the patterns it learned in training data. It cannot learn anything new after training, and if asked about something outside that data, it either fails or hallucinates (invents an answer). RAG, on the other hand, is like an open-book system - before answering, it actively searches for relevant info in external sources. The RAG pipeline has two main parts: a retriever (which finds relevant documents or entries) and a generator (which formulates the answer using those documents). For example, ask a traditional model about the latest tax regulation and it might give a vague or outdated answer. Ask a RAG-enabled model, and it will fetch the latest regulation text from the knowledge base and provide a specific, up-to-date answer. Thus, RAG augments the AI with a real-time research ability , whereas a normal LLM is stuck with static, pre-learned knowledge. The result: RAG answers tend to be more accurate, context-specific, and current compared to a vanilla chatbot.
Q: What challenges with AI does RAG solve?
A: RAG was designed to overcome some well-known issues of standalone AI models. Key challenges it addresses include:
- Hallucinations and False Information: Large language models often present false information when they don't actually know the answer. RAG mitigates this by grounding responses in real data - if the answer comes from your verified knowledge source, there's less room for the AI to fabricate facts. This significantly reduces the incidence of "AI hallucinations" (making up facts) and leads to more factual consistency in responses.
- Out-of-date Knowledge: AI models have a knowledge cutoff - they can't know events or data beyond their last training update. RAG allows dynamic updating because it pulls information from current databases or the internet. The AI can give answers using the latest information (e.g. recent market prices, new regulations) rather than being stuck with year-old data.
- Generic or Irrelevant Answers: Without context, AI may give generic answers not specific to your question or domain. RAG forces the AI to consider contextual documents , yielding responses that are contextually relevant and specific. For example, it will use your company's handbook to answer an HR question, rather than a general answer. This makes interactions far more useful for end-users.
- Lack of Transparency: Pure generative models don't show how they got an answer, which can be a trust issue. RAG systems can surface the sources (documents, URLs) that were used to derive the answer. This transparency lets users verify information and increases confidence in the system.
- Inflexibility to New Data: In traditional AI, adding new knowledge means retraining the model (costly and slow). RAG solves this by simply updating the knowledge base. If there's new data (say new product specs or a revised policy), you index it for retrieval and the AI can instantly use it in answers - no retraining required. This makes RAG-driven solutions agile and easy to keep current .
By addressing these challenges, RAG enables AI applications that are far more reliable and business-friendly than their predecessors.

Q: What are some real-world applications of RAG (in industries like real estate, finance, healthcare, etc.)?
A: RAG can be applied anywhere you need AI to provide informed, context-specific answers or content . Here are a few industry-relevant examples:
- Real Estate: Imagine a real estate chatbot for clients. Using RAG, it can pull details from listing databases, market reports, or legal documents. If a buyer asks, "What are the school ratings in this neighborhood?" the bot retrieves school data and generates a clear answer. It can also draft property descriptions or investment analyses by pulling in recent sales comps and neighborhood stats, giving agents and clients trustworthy insights.
- Finance: RAG-powered assistants in finance can access up-to-the-minute financial data or internal policy manuals. For instance, a bank's internal helpdesk bot could retrieve relevant compliance rules and client data to answer a question like "Can we approve this loan under policy X?" with specifics. In wealth management, an advisory tool might fetch the latest market research to generate a tailored report for an investor, ensuring recommendations are backed by current data.
- Healthcare: In healthcare, accuracy is paramount. A RAG-based medical assistant can search medical literature and patient records simultaneously. If a doctor asks, "What are the latest treatment guidelines for [a condition]?" the system can retrieve the newest research papers or guidelines and then summarize them in plain language. Similarly, patients could query a symptom checker that pulls from verified health databases to give informed advice (with disclaimers), rather than generic answers.
- Education: RAG can power intelligent tutoring systems or campus info bots. A student might ask, "Explain Newton's second law in simple terms," and the system retrieves the relevant textbook section or lecture notes, then generates an easy-to-understand explanation. Or a university's Q&A bot could draw from school policy documents to answer, "How do I appeal a grade?" - providing the exact steps and references.
- Telecommunications: Telecom companies deal with complex tech and large customer bases. A RAG-enabled support agent can instantly pull troubleshooting steps from internal knowledge bases and combine it with customer-specific data. For example, when a customer asks, "Why is my internet speed slow?", the bot can check network status reports, the customer's modem logs, and relevant troubleshooting guides to give a personalized answer (or next steps) rather than a generic script. Internally, network engineers could use a RAG system to query equipment manuals and past incident reports to solve technical problems faster.
These examples scratch the surface. Any industry that has a body of knowledge (documents, data) can leverage RAG to make AI assistants and tools that are domain-expert . Baytech's clients, ranging from real estate firms to healthcare providers, are exploring RAG to build everything from smarter customer service bots to internal knowledge assistants. The common theme is that RAG empowers AI to deliver useful, context-rich output that aligns with specific business needs , rather than one-size-fits-all answers.
2. How It Works (Conceptually)
Now that we know what RAG is and why it's useful, let's demystify how it functions behind the scenes. This section explains the RAG process in approachable terms, often with analogies to everyday concepts.
Q: How does a RAG system work at a high level? What's the process?
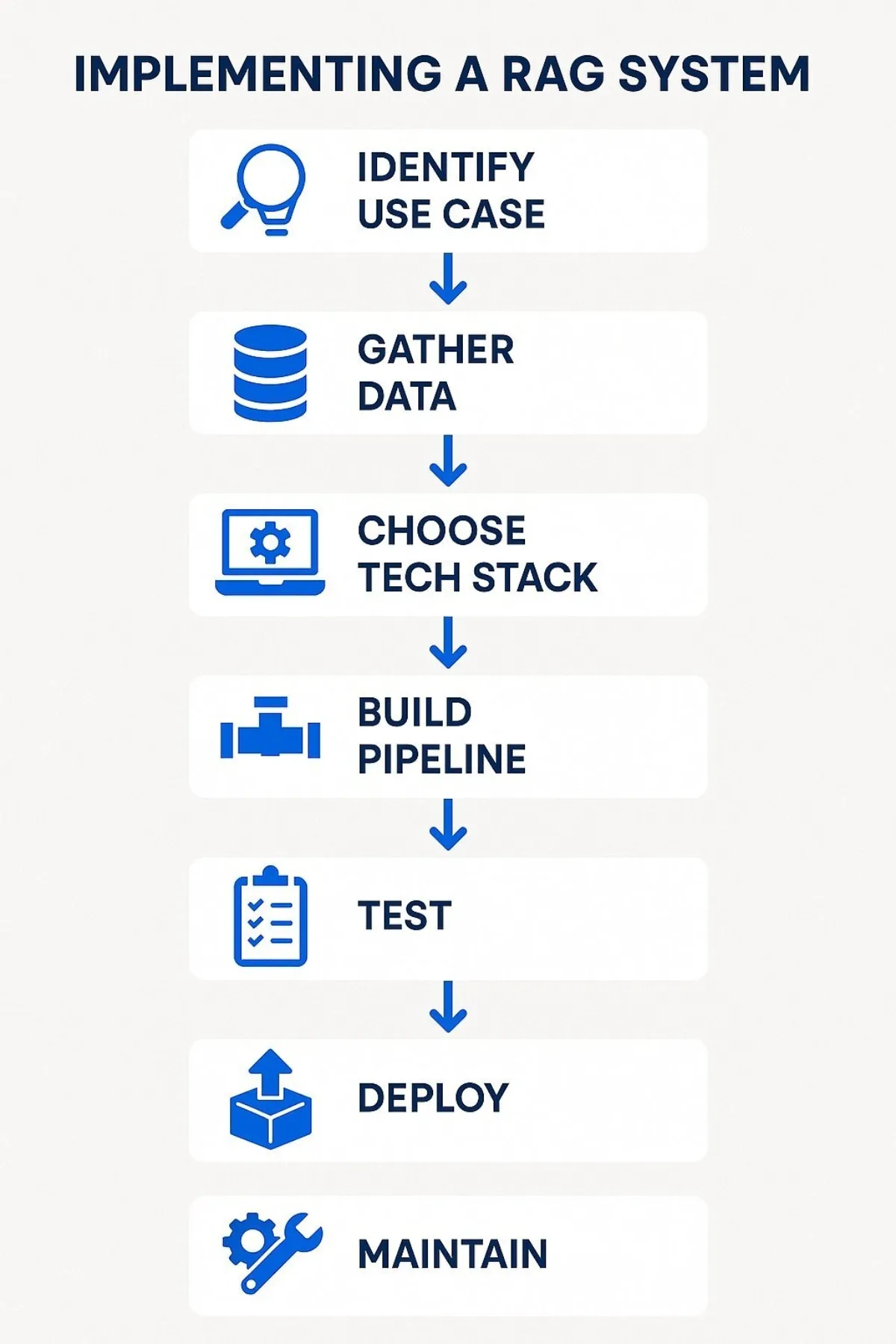
A: At its core, a RAG system works in a two-step loop: retrieve, then generate . Here's the conceptual flow:
Conceptual flow of a Retrieval-Augmented Generation system. The AI first searches a knowledge source for relevant information, then uses that information to produce a context-informed answer.
- User Query: Everything starts when a user asks a question or makes a request (this is the prompt or query). For example, "How do I reset my router?"
- Retrieval Step: The RAG system sends this query to a retriever component , which searches through the designated knowledge sources for relevant information. It's like doing a focused Google search across your company's documents or databases. In our example, the retriever might look into a telecom company's support knowledge base and find a troubleshooting guide or FAQ about router resets.
- Relevant Info Returned: The retriever returns the most relevant snippets or documents - say, the exact steps from the router manual and perhaps a note about what not to do. This retrieved content serves as context for the AI.
- Generation Step: Now the query plus the retrieved context are fed into the generative model (an LLM). The model sees something like: "User asks: How to reset router? + [Insert relevant text from the manual] ." With this enhanced prompt (question + supporting text), the LLM formulates a complete answer. It might write out: "To reset your router, locate the reset button on the back, press and hold it for 10 seconds, then wait for the lights…," incorporating details from the retrieved guide.
- Response: The system delivers the generated answer to the user. Ideally, it's a fluent, helpful answer that directly addresses the query, grounded by the factual info fetched in step 3. In many implementations, the system might also offer references (like "according to the ACME Router Model X Manual") to bolster trust.
This all happens behind the scenes in seconds. The user just sees a helpful answer that feels both intelligent and correct. In summary, RAG systems retrieve first, then respond , ensuring the answer is backed by data rather than guesswork. This conceptual pipeline is analogous to an assistant that first quickly researches your question and then provides a nicely worded answer.
Q: What are the main components of a RAG system?
A: A RAG system is essentially composed of two pillars working together:
- The Retriever (Knowledge Retriever): This part is responsible for searching and fetching relevant information . Think of it as the AI's research department. It could be as simple as keyword search or as advanced as a vector similarity search (where both query and documents are encoded into embeddings for semantic match). The retriever works against a knowledge source - which might be a set of documents, a wiki, a database, or even an API. In many modern RAG setups, this is implemented via a vector database that can quickly find text chunks related in meaning to the query. For example, if the query is "latest IRS tax bracket for 2025", the retriever might use an index of financial documents to find the exact snippet from the 2025 tax code. The effectiveness of RAG heavily relies on this component: if the retriever finds good info, the final answer will likely be good.
- The Generator (Language Model): This is the AI text generation engine (often a large language model like GPT-3, GPT-4, etc.). Once the relevant info is retrieved, it's passed to the generator along with the original question. The generator's job is to synthesize a coherent, natural-language answer that uses the retrieved facts. It's trained to take the context into account, meaning it will try to incorporate that external knowledge into the response. This component gives the answer a fluent, conversational quality and can fill in connective text or explanations that make the raw facts more understandable. In essence, the generator turns raw data into a helpful narrative or answer.
Additionally, there's often some integration logic around these components to coordinate the steps (feeding query to retriever, feeding results to model, etc.). Sometimes, there's a ranking step (if multiple pieces of text are retrieved, the system may rank or filter them) and possibly a post-processing step (to ensure the answer is well-formed or within guidelines). But at a high level, RAG = Retriever + Generator . The retriever brings knowledge in, the generator produces the output. Both are needed - without a retriever, the model might lack facts; without a generator, you'd just get a list of docs rather than a synthesized answer.
Q: Where does the "knowledge" in RAG come from? Do we need a special database?
A: The knowledge in a RAG system comes from whatever data sources you choose to connect . This is highly flexible. Common knowledge sources include:
- Company Documents and Files: PDFs, Word docs, presentations, emails - any text content. For example, your company's policy manuals, product specs, or research reports can be loaded as the knowledge base. The RAG system will then retrieve from these when users ask relevant questions.
- Internal Databases: Structured data like databases or spreadsheets can also be tapped. For instance, an inventory database or a CRM could be connected so that the AI can retrieve specific figures ("current stock level of item X") and include them in its answer. In practice, this might involve an additional step of formatting the data for the LLM.
- Web and External Sources: RAG isn't limited to internal content. It can also use external APIs or the web. Some implementations retrieve from the public internet (like how some search engine chatbots work) for the latest news or information. You might configure a RAG system to hit a specific API - for example, a live exchange rate feed if you need financial answers with current prices.
- Wikis or Knowledge Graphs: If you have a curated knowledge base (like an internal wiki or even a knowledge graph), RAG can retrieve from that. In fact, RAG and knowledge graphs can complement each other - the knowledge graph provides a structured way to find entities/relations, which the retriever can use to gather data. However, you don't necessarily need a fancy knowledge graph to start; even a collection of unstructured documents can work with modern retrievers.
- Vector Database / Index: Behind the scenes, it's common to use a vector database or search index to make retrieval fast and semantic. This isn't something end-users see, but as a business you'd set up a system (using tools like FAISS, Pinecone, Elastic, etc.) that holds embeddings of your text data. This essentially allows the RAG system to "remember" your documents in a mathematical form and quickly find which ones relate to a new query . So yes, typically RAG involves building an index (kind of like a specialized search engine for your data). But many off-the-shelf solutions and cloud services are available to handle this part, so you don't have to build it from scratch.
In summary, the knowledge can come from anywhere you have useful information . The key preparation work for RAG is often gathering and organizing your data into a retrievable form (e.g. chunking documents into passages, indexing them). Once that's done, the RAG system will handle querying it. One of the benefits of RAG is you maintain direct control over this knowledge source - you can update it with new documents, remove outdated ones, and the system's answers will adjust accordingly. It's very much your knowledge powering the AI.
Q: Do we need to train new AI models to use RAG, or can we use existing models?
A: One attractive aspect of RAG is that it often does not require training a new model from scratch . RAG is more of an architecture or system design than a single model. In practice, you usually use a pre-trained language model (like OpenAI's GPT series, or open-source models) as the generator, and you use existing algorithms or tools for retrieval.
Here's how it typically works:
- You take a powerful pre-trained LLM that understands language out-of-the-box (for example, GPT-4 or an enterprise model from Azure/AWS). This model already has general language capability.
- You connect it with a retrieval mechanism on your data (using libraries such as LangChain or others that support this pipeline). The retriever might be configured but not "trained" in the neural sense; it uses embeddings or search indexes built from your data.
- When deployed, the system orchestrates calls: first a search step, then feeding the found text into the LLM to get the answer.
Because the language model is pre-trained on broad text corpora, it's very adept at phrasing answers. You usually don't have to fine-tune the LLM just to make RAG work. The beauty of RAG is that the knowledge injection happens through retrieval, not through weight updates of the model. That said, there are cases where a bit of fine-tuning or prompt tuning can help - for instance, if you want the model to adopt a certain formal tone or to better handle the style of your documents. But this is optional.
Compared to alternatives (like fully training a custom model on all your documents), RAG is faster and cheaper to implement . You leverage existing AI models and just give them the right data at the right time. In summary, you reuse existing AI building blocks - a pre-trained brain and a search tool - and you engineer them together (with code/configuration) rather than training a new brain from scratch. This is why many organizations find RAG a practical way to get domain-specific AI capabilities without a huge ML R&D investment.
Q: How can a business implement RAG in practice? What does it take to set it up?
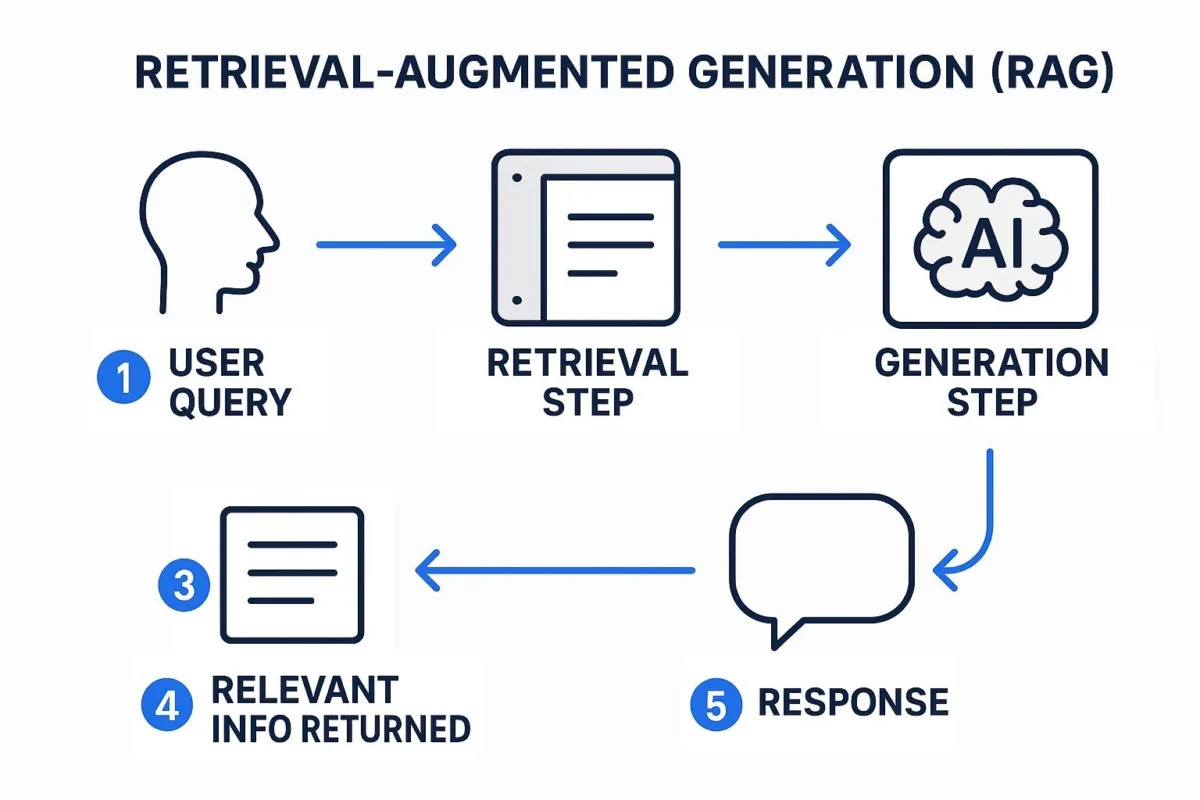
A: Implementing RAG in your business involves a few concrete steps, but it's quite achievable with modern tools (and partners like Baytech can help streamline the process). Here's a simplified roadmap:
- Identify the Use Case: First, be clear on what you want to achieve. For example, "We want a customer support chatbot that can answer questions using our product manuals and FAQ documents," or "We need an internal tool for salespeople to query our pricing and product info." Having a focused use case helps target the right data and design the conversation flow.
- Gather and Prepare Data: Collect the knowledge sources that the AI should draw from. This could be company documents, knowledge base articles, SharePoint files, etc. You might need to clean or organize this data - for instance, splitting large documents into smaller sections (since retrieval works better on reasonably sized chunks). There are tools to help "ingest" documents and create an index. Ensure the data is up-to-date and representative of what questions users will ask.
- Choose a Tech Stack: Decide on the tools/platform. Many options exist: you can use open-source libraries like LangChain or LlamaIndex which are designed to create RAG pipelines, or cloud services (AWS, Azure, GCP have offerings for building chatbots with retrieval). For the language model, you might use a cloud API (such as OpenAI's GPT) or a self-hosted model if data privacy is a concern. For the retriever, choose a solution to index and search your data (e.g., ElasticSearch, Pinecone, or built-in tools with the libraries mentioned).
- Build the RAG Pipeline: This is where a developer (or Baytech's team) sets up the system to do the retrieval-then-generation dance. Using the chosen tools, they will: connect the data to a vector store or search index, write the code that takes a user query to query that store, then passes results to the LLM along with the query. It often only takes a few hundred lines of code or less using high-level frameworks. You'll also configure things like how many documents to retrieve, how to format the prompt given to the LLM (prompt engineering), and what to do if nothing relevant is found.
- Test and Iterate: Once set up, test the system with real sample questions. You'll want to fine-tune the retrieval parameters (maybe you need to index differently or add keywords) and prompt format. For example, you might instruct the model in the prompt: "Use the information below to answer. If the question is unrelated to the info, say you don't know." This helps with quality and safety. You iterate until the answers are accurate and well-phrased.
- Deployment and Integration: Finally, integrate this RAG system into your user interface or workflow. That could mean a chat UI on your website, a Slack bot for employees, or an API endpoint that your applications call. Ensure you have proper access controls if the data is sensitive (only authorized users can query certain info, etc.). Fortunately, RAG systems can incorporate such controls - e.g., using user identity to filter search results.
- Maintenance: Plan to update the knowledge base periodically. Whenever you have new documents or data, add them to the index. Retire outdated info to avoid confusion. The AI will always reflect the latest indexed data. Also monitor usage: see what people ask and how the system responds, so you can refine it or expand the data if needed.
The good news is you don't have to start from scratch - there are established platforms and best practices for each step, and consulting experts can accelerate the process. Many companies start with a pilot project (e.g., a limited chatbot for a specific set of documents) and then expand once they see the value. Baytech Consulting, for instance, often helps clients by handling the technical heavy lifting: setting up the pipeline, ensuring data security, and integrating the solution seamlessly into the client's product or internal systems. The result is a custom AI solution powered by RAG that feels tailor-made for your business's knowledge and needs.
3. Functionality & Limits
No technology is magic. In this section, we discuss what RAG-enabled AI can do, its limitations, and practical considerations like accuracy, speed, and maintenance. This will help set the right expectations about RAG's performance and requirements.
Q: Does using RAG mean the AI will always give correct answers?
A: Not always, but it will significantly improve accuracy. RAG greatly reduces random gibberish or unfounded answers by grounding the AI in actual data, but it's not a 100% guarantee of correctness. Here's why:
- If the information in your knowledge source is accurate and relevant to the question , a RAG system will likely produce a correct answer based on that info. It's leveraging facts, not just predictive text. For example, if the company handbook says the office closes on holidays and a user asks about office hours on July 4th, the RAG system will pull that rule and answer correctly.
- However, if the knowledge base lacks the answer or has outdated/wrong info, the AI might still stumble. In cases where nothing relevant is found, some RAG setups will have the AI say, "I'm sorry, I don't have that information." But others might have the model try to answer from general knowledge, which could reintroduce the risk of error. Properly designed systems can minimize this by instructing the AI to admit when it doesn't have a source.
- The AI's generation component might occasionally misuse the retrieved info . For instance, it might slightly misinterpret a technical detail even if it had the source (though this is rarer and usually far less severe than a hallucinating model without RAG).
- In sum, RAG is not infallible, but it's a big step up in reliability . Think of it as moving from a student who guesses answers to one who opens the textbook - the student can still err but is far more likely to be right. Empirically, organizations find that responses from RAG feel "more precise and contextually appropriate" than those from an unaugmented model. The factual accuracy goes up, though critical applications should always include a human verification loop if absolute correctness is needed.
Q: What are the known limitations or drawbacks of RAG?
A: While RAG is powerful, it does come with some limitations and trade-offs:
- Complexity & Overhead: A RAG pipeline is more complex than using a single AI model. There's an extra retrieval step, which means additional infrastructure (e.g., maintaining a document index) and slightly longer processing time per query. The two-step process can be computationally heavier, potentially increasing latency (the AI has to search and then generate). For most applications this is still fast (often responses in a couple of seconds), but real-time systems need to optimize carefully.
- Dependency on Data Quality: RAG is only as good as the information it can retrieve. If your data is incomplete, outdated, or irrelevant, the answers will suffer. For example, if a knowledge base has a wrong price for a product, the RAG system will faithfully use that wrong price in its answer. So, there's an onus on curating and updating the knowledge source. Garbage in, garbage out.
- Scalability Challenges: Managing a large and growing corpus of documents can be challenging. Indexing tens of thousands of documents and keeping them updated is doable, but requires planning (storage, update processes, etc.). Also, if you want the system to handle very broad queries, you might need to index a huge variety of content which could bloat the system. Organizations often need to scope the domain or use clever indexing (sharding by topic, etc.) to keep retrieval efficient.
- Still Requires Expertise to Tune: While you don't have to train big models, implementing RAG effectively does require some expertise. Tuning the retrieval to get the right documents, formatting prompts correctly, and adding guardrails are all part of the development cycle. This is where working with experienced teams (like Baytech) or leveraging proven frameworks helps, but it's not entirely plug-and-play magic - some iteration is needed to get top results.
- Residual Risks: RAG can mitigate biases and misinformation by drawing from vetted sources, but if those sources have bias, the output can still reflect it. Also, if the retriever pulls unrelated content by mistake, the model might produce a confusing answer (though such cases can be reduced with good testing). Additionally, multi-hop reasoning (questions that require piecing together info from multiple places) can be tricky - RAG can handle it via iterative retrieval, but it's an advanced setup.
It's worth noting that many of these limitations are active areas of improvement in the AI community. For instance, new indexing techniques and faster vector databases are emerging to tackle scalability and speed, and research into better prompt engineering and model tuning is making RAG systems more robust. Despite limitations, the consensus is that the benefits (accuracy, relevance) far outweigh the downsides for most use cases , especially when the system is well-designed.
Q: What happens if the information needed isn't in the RAG system's knowledge base?
A: If the answer to a user's question isn't in the documents or data you've provided, the RAG system will have one of a few outcomes:
- No Answer / Uncertainty: Ideally, the system should recognize the info is not found and respond accordingly. For example, it might say, "I'm sorry, I don't have information on that," or it might give a gentle refusal or redirect ("I can't assist with that topic"). This kind of behavior can be implemented by checking the retriever's confidence or simply instructing the AI to not answer beyond the given context.
- Partial Answer: In some cases, the system might retrieve something tangentially related and the model will attempt an answer. This can lead to an incomplete or not entirely satisfying answer . For instance, if asked about a very new event not in the data, the system might pull an older related event and the answer will be somewhat off-mark. Users might notice it's not exactly what they wanted. This is where monitoring queries and expanding the knowledge base continuously is important - you'll discover content gaps and can fill them.
- Fallback to Base Knowledge (if allowed): If not constrained, the LLM might try to answer from its own training knowledge. This is not always desirable because that's when it can introduce hallucinations or outdated info again. Many RAG implementations prevent this by designing the prompt such that the model is only supposed to use provided context. Some frameworks even override the language model's answer if no documents were found (to avoid a guess).
- Escalation: In a customer service setting, if the RAG bot can't find an answer, it might escalate to a human agent. Or in an internal tool, it might raise a flag that the question couldn't be answered. These are design decisions beyond RAG itself, but worth planning for.
In practice, a well-maintained RAG system will be continually updated to minimize these scenarios. Regularly update your knowledge base to include new or frequently sought information. Also, analyze the questions coming in: if many people ask for something you don't have data on, that's a signal to add that content. The goal is to keep the "answerability" of questions high by proactively curating content. But no matter what, it's good to have a graceful failure mode (like a polite apology or escalation) for those rare cases something isn't covered.
Q: Is RAG slower than using a single AI model? What about performance and scalability?
A: There is a bit of added latency with RAG, but it can be managed . The retrieval step does introduce overhead: the system might spend, say, 100ms to a few hundred milliseconds searching the index before it even calls the language model. And the language model then processes a prompt that includes the retrieved text (which might be longer than the original question). All this can make RAG responses slightly slower than a vanilla model response. In many business applications, though, this difference is negligible - users won't mind waiting 2 seconds for a correct answer versus 1 second for a wrong one. Still, for high-throughput or real-time scenarios, performance tuning is key:
- Optimizing Retrieval: Modern vector databases are fast, and with proper indexing, search can be very quick (sub-second even for millions of documents). Caching can also help - if many users ask similar questions, the system can cache those retrieval results.
- Model Size vs. Speed: Using a somewhat smaller but still capable LLM can reduce latency. In RAG, the heavy lifting of factual accuracy comes from the data, so you might not need the absolutely largest model for great results. Companies have found that a fine-tuned medium-sized model with RAG can outperform a larger model without RAG, in both accuracy and speed.
- Streaming Responses: One trick to hide latency is to stream the answer as it's generated (word by word), which gives the user the impression of immediacy - they see the answer starting to appear in under a second, even if the full answer takes a couple seconds to complete.
- Scalability: RAG systems can scale horizontally. The vector search can be distributed across servers if needed, and you can run multiple instances of the language model in parallel to handle concurrent queries. Cloud providers and platforms are already offering managed services for this. So, if your usage grows (say your bot gets 10x more queries), you can scale up by allocating more resources or instances. Just like scaling a search engine or a web service, it's a solvable engineering task.
- Infrastructure Consideration: There is a cost to maintaining the knowledge index (storage, memory) and possibly running the model (if self-hosted, you need GPU servers or use API credits if using an external service). But these costs are often far lower than what it would take to train and keep retraining a custom model on all your data.
In summary, yes, RAG adds some complexity and slight delay, but with optimization the user experience can still be very fast and the system can handle large workloads. Many enterprise deployments of RAG report that users are happy with the response times, especially given the answers are more useful. The trade-off in speed is usually worth the dramatic gains in accuracy and relevance. With good engineering (like using efficient retrievers and possibly smaller specialized models), RAG systems can feel snappy and scale to enterprise needs.
Q: How do we keep a RAG system's knowledge up-to-date? Is it hard to maintain?
A: Keeping a RAG system updated is generally simpler than retraining AI models from scratch, but it does require a maintenance workflow:
- Regular Data Updates: The primary task is to feed new or updated content into the knowledge index. For example, if you have new product releases, new documentation, or a policy change, you add those documents to the corpus and index them. Many RAG setups allow incremental indexing , meaning you can update the index without rebuilding everything from zero. You might set up a schedule (say, crawl the intranet for new docs every night) or event-driven updates (whenever a document is added to SharePoint, update the index).
- Pruning Outdated Info: Likewise, you'll want to remove or archive information that is no longer valid to avoid confusion. For instance, if an old policy is replaced by a new one, you'd take the old one out of the active index or mark it as superseded so the retriever favors the new info.
- Versioning and Source Control: In industries like finance or healthcare, you might need to maintain historical info (for legal reasons) but not present it unless asked specifically. Some advanced RAG systems tag documents by date or version, enabling queries like "latest version" to retrieve current info. It's a good practice to keep track of data versions.
- Security and Access Updates: If your data has permissions (say certain documents should only be seen by managers), maintaining the access control rules in the RAG system is important. This can be done by filtering retrieval results based on user identity/roles. As personnel or role definitions change, those rules may need updates too.
- Monitoring & Feedback: Maintain a log of queries and which sources were used to answer them. This helps in two ways: (1) If the system gave an incorrect answer, you can trace which document misled it or if it didn't find the right doc. (2) You might discover frequent queries that aren't well answered due to missing info - that's a cue to add that info. Essentially, user interactions provide a feedback loop to improve the knowledge base.
- Retraining (Minimal): You typically don't need to retrain the language model as long as it's handling the domain well. However, if you significantly expand into new types of queries or a new language, you might consider fine-tuning or swapping out for a model that better fits the new domain. But again, that's optional and often avoidable.
Maintenance isn't burdensome if baked into your content management practices. Many companies find it akin to maintaining a search engine or an intranet knowledge base - you regularly add/remove content as the business evolves. The difference is that any update immediately makes the AI smarter and more relevant, which is satisfying to see. With RAG, staying up-to-date is straightforward: update your data, and the AI's knowledge updates with it. This agility is a major advantage over traditional AI models that would need a whole new training cycle to incorporate new information.
4. Trust & Safety
RAG aims to make AI more trustworthy and safe by grounding it in real data. In this section, we address how RAG affects the trustworthiness of AI outputs, how to ensure the system is used safely, and ethical considerations. These answers will cover issues like hallucinations, bias, privacy, and content moderation.
Q: Does RAG really reduce AI "hallucinations" and misinformation?
A: Yes - substantially, though not absolutely . Hallucinations (AI making up facts) are significantly curbed by RAG because the AI isn't operating in a vacuum; it has retrieved facts to reference. When an AI has concrete source text about a topic, it doesn't need to invent details - it can draw from the source. Users of RAG-based systems generally observe far more factual consistency . In fact, one of the big selling points of RAG is that it "increases user trust, improves user experience, and reduces hallucinations."
However, the caveat is that the system can only be as truthful as the sources you provide. If your knowledge base somehow contains misinformation, the AI might echo that. So ensuring high-quality, credible sources is step one (for instance, using documents that come from expert or verified origins). The good news is that in a business context, you often have control over the repository (it could be your company's own manuals, reputable industry data, etc.), which means you can vet what the AI will use.
Additionally, because RAG systems can cite or show the sources they used, it's easier to verify the answer's correctness . If a RAG-powered assistant tells a customer, "According to the policy document updated in March, you are eligible for a full refund," it can also present a snippet or reference to that policy. The customer (or an auditor) can check that source. This transparency provides an extra check against hallucinations - any fabrication would be obvious if it cites a source unrelated to the answer. Designing your RAG application to include references or make source content easily inspectable is a great way to enhance trust.
In summary, while no AI is 100% immune to error, RAG greatly reduces the frequency of incorrect or made-up answers by always trying to ground responses in reality . It moves the AI from a "best guess" approach to a "look it up" approach, which naturally yields more reliable information.
Q: How can we ensure the information RAG uses (and outputs) is trustworthy and unbiased?
A: Ensuring trustworthiness in RAG involves careful curation and system design :
- Curate Quality Sources: Be intentional about what data you feed into the system. Use authoritative and up-to-date sources. If you're building a health chatbot, for example, you might include medical guidelines, vetted articles, and exclude random forum posts. If you're building an internal knowledge assistant, load it with official company documents, not rumor mill emails. By filtering input data, you inherently bias the system towards trustworthy info. In technical terms, you can configure the retriever to prioritize credible sources - for instance, tag certain documents as higher priority or use a ranking model that scores source reliability.
- Bias Mitigation: Every dataset has biases. To mitigate this, include diverse perspectives in your knowledge base if applicable, and use content from unbiased sources for factual queries. For social or policy topics, maybe include an FAQ or guidance that explicitly addresses known biases or ethical stances of the company. Also, monitor the outputs: if you see any consistently biased or skewed responses, that's a signal to adjust your sources or add clarifying content.
- AI Validation and Cross-Checking: One interesting approach is that the generative model can be prompted to double-check retrieved info. For example, the prompt might instruct: "Use the info below. If you are not sure the info answers the question, state that you are unsure." This makes the AI less likely to confidently push a dubious claim. Some systems run multiple passes (e.g., have the AI explain why the info is relevant) to catch mismatches.
- Human in the Loop: For high-stakes usage, keep a human reviewer in the loop initially. For instance, an AI drafting content for the public might have a human editor approve it. Over time as trust builds, you can automate more.
- Transparency: As mentioned, surfacing sources is key. This allows users to judge for themselves. It's like giving citations for facts - it inherently increases credibility. Users knowing where the answer came from often makes them more comfortable trusting it.
- Continuous Updates: Ensure the data is not stale - outdated info can mislead. If your business stance or factual reality changes (e.g., nutritional guidelines update, a law changes), update the content promptly so the AI doesn't keep serving old truth as new truth.
- Ethical Guidelines and Testing: Before deployment, test your RAG system with a set of queries that probe potential sensitive areas. See if any biased language or problematic content surfaces. If it does, refine the data or add AI guardrails.
By taking these steps, you essentially shape the "knowledge diet" of the AI to be healthy and balanced. Remember, RAG doesn't magically know what's true or fair - it inherits that from your chosen sources. But since you have control over those sources in a RAG setup, you have a powerful lever to ensure trustworthiness. This is a major improvement over opaque AI models trained on random internet data; with RAG you're effectively curating the training data on the fly for each query, which is a very effective way to maintain quality and impartiality.
Q: What about privacy and security? If our RAG uses internal data, how do we keep it safe?
A: Privacy and security are crucial, especially when RAG is applied to proprietary or sensitive data. Here's how they're handled:
- Data Remains Internal: One big advantage of many RAG setups is that you can keep the whole pipeline within your secure environment. For instance, if you're concerned about sending data to external APIs, you can use open-source models deployed on-premises and a self-hosted vector database. That way, queries and documents never leave your network. If you do use a third-party model API, techniques like encryption or redaction can be applied to the prompt (though that's advanced and often not needed if using trusted cloud with proper agreements).
- Access Control: You can enforce user permissions in the RAG retrieval step. Say your company has documents where some are HR-only, some are finance-only. When a user query comes in, the system can be aware of who is asking (via an authentication token) and filter the search results to only include documents that user is allowed to see. This way, the AI will never retrieve and thus never reveal content beyond the user's clearance. It's similar to how a normal intranet search might hide results the user shouldn't access.
- Prompt and Output Logging: For security audits, you can log all inputs and outputs (with proper access control to these logs). This helps in tracing any unusual behavior. But be mindful: these logs could contain sensitive info that was in a query or answer, so they should be protected just like the data itself.
- On-device Processing: In cases with extremely sensitive data (e.g., medical or legal), organizations sometimes choose smaller local models to ensure data never leaves their servers. RAG can work with such models too - even if the model isn't state-of-the-art, the fact it's boosted by retrieval can still yield very good results.
- Data Encryption: The databases storing your documents or vector embeddings can be encrypted at rest. Communication between components (like between the app and the database or the LLM API) should ideally be encrypted in transit (TLS). These are standard IT security practices and can be applied to the RAG infrastructure.
- Removing PII or Sensitive Info: If your knowledge base contains personal identifiable information (PII) or other confidential fields that aren't necessary for Q&A, you might preprocess the data to mask or exclude those parts from indexing. For example, you might strip social security numbers or personal addresses if they're not needed in answers, so even if a user asks, the system truly doesn't have that data available.
- Emergency Off-Switch and Monitoring: Implement usage monitoring to detect any unusual spikes or content in queries (this can catch, say, an internal user trying to abuse the system to get confidential info). If something looks off, the system can flag it or temporarily lock down. In an extreme case, maintain a "kill switch" to disable the AI's response if a serious policy violation is detected, just until you investigate. Tools like NVIDIA's NeMo Guardrails can set rules for allowable topics or detect sensitive content in inputs/outputs.
Overall, RAG doesn't introduce new security issues beyond what any data system has - you still enforce who can query what. In some ways, it can improve security because the AI will only answer based on documents the user is permitted to access, which reduces the chance of accidentally leaking something (contrast this with a general AI that might accidentally speak about internal info because it was in training data - with RAG, if the retriever doesn't surface it due to permissions, the AI won't mention it). By designing the system with enterprise-grade security principles - identity authentication, role-based access, encryption, and audit logging - you can safely deploy RAG on even sensitive data.
Q: Can RAG provide source citations for its answers?
A: Absolutely, and this is a best practice for building user trust. Because RAG fetches actual documents or snippets to inform an answer, it's straightforward to show the user which document or source was used. Many RAG-based applications will include footnotes or links in the AI's response pointing to the source material. For example, an answer might end with " (Source: Company Handbook, 2023 Edition) " or have a tooltip the user can click to read the original paragraph from the document.
Providing citations offers several benefits:
- Transparency: Users can verify the information. If the AI says "According to research, 60% of customers prefer X," a citation lets them know which research report that came from. This transparency is reassuring and also academically honest in a sense.
- Credit: It gives credit to the source content (important if using external content like a snippet from a public website - you'd want to cite the website).
- Debugging and Improvement: Internally, seeing which source was used for an answer helps developers fine-tune the system. If the answer was off, maybe it cited a wrong or less relevant doc, indicating a retriever issue or a need to improve that source.
- User Education: Sometimes users learn where information resides. For instance, an employee might not have known the answer was in the "IT Policy Doc"; seeing the citation can point them to useful resources.
From an implementation perspective, since the retriever identifies the document and even the passage, it's relatively easy to carry that metadata through and attach it to the model's answer (some prompt engineering might be used to have the model format an answer with citations). In fact, NVIDIA's example RAG chatbot workflow shows linking back to source documents as a feature.
One thing to note: the way the AI generates text, it doesn't automatically cite unless asked, so you typically instruct it via the system prompt to include references. Or the application layer maps the retrieved snippet to a known document ID and appends a citation. Either way, it's doable and encouraged . Many enterprise users have indicated that seeing sources increases their trust in the AI's output - it feels less like a black box and more like an answer with evidence.
Q: Are there any ethical considerations when implementing RAG systems?
A: Yes, several, though many ethical issues of AI are eased by RAG, some new ones also come into play. Key considerations include:
- Bias and Fairness: We touched on this - the system will reflect the biases of its sources. Ethically, you should ensure your knowledge base is not skewed in a way that could lead to unfair or discriminatory responses. For example, if building a recruitment assistant, make sure the documents and policies it draws on align with diversity and inclusion goals (so it doesn't, say, downgrade candidates from certain schools unfairly because historical data did). Actively mitigate bias by curating diverse sources and possibly adding rules or checks for sensitive outputs.
- Accountability: Who is responsible if the AI gives a harmful or wrong answer? With RAG, it's easier to trace why an answer was given (the source and the model), but you still need an accountability framework. Make it clear to users that it's an AI system and provide a channel for feedback or corrections. Internally, have someone (or a team) responsible for the content it uses and the supervision of its behavior.
- Transparency: Ethically, it's good to disclose that a user is interacting with an AI and that the answers are generated from retrieved content. RAG systems often produce very authoritative sounding answers; users might assume it's a person or completely accurate. Being transparent that "this is an AI assistant that provides answers from our knowledge base" helps set correct expectations and respects the user's right to know.
- Privacy: As discussed, ensure the system respects privacy. Ethically, if the AI has access to personal data, you should have consent or a legitimate need to use it in answers. Also, guard against the AI inadvertently exposing someone's private info to another user (hence the importance of access controls and perhaps content filters for certain data fields).
- Misuse: Could someone misuse the RAG system? For example, an internal user might try to get the AI to reveal confidential strategies by phrasing a clever query. Or an external user might try to get the chatbot to say something offensive by manipulating input. You should consider these and implement guardrails. Tools like content moderation and guardrail scripts can intercept disallowed queries or sanitizing outputs if they accidentally include something sensitive. It's an ethical duty to prevent the AI from being used to spread disinformation or harmful content.
- Accuracy and Reliability: There's an ethical aspect to deploying any AI - ensure it's sufficiently accurate for its intended use, so as not to mislead. For example, if using it for medical info, it should come with disclaimers and extremely careful sourcing (because giving wrong medical advice is high stakes). With RAG you can mitigate this by using highly reliable medical sources and possibly having a doctor review the system's responses initially. Ethical design might mean intentionally not answering certain questions if the confidence is low or if it's outside the system's scope (better to refuse than to mislead).
- User Autonomy and Consent: Especially internally, consider if users can opt-out of being tracked when they ask the AI something. You might anonymize logs to protect user privacy. Also, respect any legal requirements like GDPR when handling user queries (which might contain personal data).
In summary, treat the RAG system with the same seriousness as any knowledge system. RAG's strength is that it can be made more transparent and controllable than end-to-end AI , so use that to your advantage ethically. By documenting how it works, keeping humans in the loop for oversight, and regularly auditing its outputs, you can address the ethical challenges responsibly.
5. Comparative Questions
Finally, let's compare RAG with other approaches and answer some strategic questions. Many decision-makers wonder when to use RAG versus fine-tuning models or traditional search, and whether RAG is just a passing trend. This section puts RAG in context against other solutions.
Q: How is RAG different from (or better than) fine-tuning a model on our data?
A: Fine-tuning means taking a pre-trained AI model and further training it on your specific dataset so it "absorbs" that knowledge. RAG means leaving the model as-is, but giving it your data at query time via retrieval. Here's how they stack up:
- Effort and Cost: Fine-tuning a large model on company data can be expensive (you need computing power, ML expertise, and time for training runs). And you might have to redo it whenever your data updates. RAG largely avoids that - you don't alter the model's parameters at all, which saves a lot of cost and allows you to update knowledge by just adding documents. RAG is generally more cost-effective and faster to implement for incorporating new information.
- Knowledge Access: A fine-tuned model has the knowledge baked into its weights , meaning it's static and only as good as the training data you gave it. It can't learn anything new until you fine-tune again. RAG gives the model dynamic access to external knowledge . It can answer questions about anything in the indexed data, even if those topics weren't prominent in the original model's training. It's like the difference between a student who memorized a textbook vs. a student who knows how to quickly look up the reference book when needed.
- Model Size and Domain Specificity: Fine-tuning can make a model very specialized. That's good if you have a specific task (like diagnosing diseases from symptoms). However, it might lose some generality or even degrade performance if not done carefully. RAG keeps the model general-purpose but augments it with specifics as needed, which can be more flexible if you have multiple domains of questions. Also, sometimes fine-tuning is not possible (e.g., if using a closed API model like OpenAI's latest GPT, you might not have the option to fine-tune it on large documents, whereas RAG you can do with the API by prepending context).
- Accuracy: Fine-tuned models can be very accurate for the exact task they're tuned on, and they might be faster at inference (no need for retrieval). But they can still hallucinate or err on details outside their training scope. RAG tends to improve accuracy on knowledge-intensive queries since it pulls the exact facts when needed. There is a hybrid approach: you could fine-tune a model to better handle the style of using retrieved evidence (but that's like an enhancement to RAG, not an alternative).
- Maintenance: With fine-tuning, if your data changes, you have to re-fine-tune (and ensure you have the new data labeled or formatted properly for training). With RAG, maintenance is just adding/removing documents as discussed. No need to touch the model.
- Combining Approaches: It's not necessarily either/or. You might fine-tune a model on your data and use RAG to handle any query that goes beyond that data or to provide citations. For instance, fine-tune for tone and certain formats, use RAG for facts. However, many find that RAG alone often suffices.
In summary, fine-tuning is like editing the brain of the AI, whereas RAG is like giving the AI access to an external library. The latter is generally more agile and cost-efficient for keeping up with new knowledge. Unless you have a very narrow and unchanging dataset that you need the AI to master, RAG is often the better first approach. It delivers quick wins - you see the AI using your data right away - and avoids the heavy lifting of model retraining.
Q: Why use RAG at all if large models like GPT-4 already know so much?
A: It's true that state-of-the-art models come pre-trained on vast amounts of information. However, even the most powerful models have limitations:
- Knowledge Cutoff: They have a training cutoff date. For example, a model might not know events or facts beyond 2021. If you need answers about 2023 or live data, that model alone can't help. RAG can pull in up-to-date info, solving the cutoff issue.
- Specificity to Your Data: GPT-4 might "know" general medical facts or coding patterns, but it certainly doesn't have your company's internal memos, proprietary research, or customer data. That information is private to you, and without RAG, the model can't incorporate it. RAG empowers the model to use proprietary and niche data that would never appear in public training sets.
- Accuracy & Hallucination: Even big models can be confidently wrong. They might approximate an answer that sounds plausible but is off. With RAG, even a slightly smaller model can surpass a bigger one on factual QA because it doesn't rely on its parametric memory - it sources the truth externally.
- Cost and Efficiency: Using a massive model for every query can be expensive (in API credits or compute). If you integrate RAG, you might be able to use a smaller model since the retrieval provides the needed knowledge. Or you might reduce tokens (context length) needed from the big model by focusing it on relevant text. Also, RAG can sometimes find an answer from, say, a short document, which the model can then summarize in one sentence - whereas the big model alone might generate several paragraphs of fluff hoping to hit the point.
- Control: With RAG, you have more control over what the model references. If GPT-4 sometimes says something that doesn't align with your policies, you can ensure the RAG system guides it with the right policy document. Essentially, you steer the model's outputs with your data. Without RAG, you're at the mercy of whatever the model "believes" from its training, which could be incorrect or not aligned with your perspective.
- Traceability: As discussed, RAG allows you to trace answers back to sources, which large models alone can't provide. This is often crucial for verification and compliance.
- Adaptability: No matter how large a model is, the world produces new information every day (new laws, new scientific findings, etc.). RAG-equipped systems can adapt on the fly by ingesting that new info. Waiting for the next GPT model or fine-tuning an existing one will always lag behind.
To give a concrete example: Bing's AI search (based on GPT) uses a form of RAG - it retrieves live web results and then answers. Without that, even GPT-4 wouldn't be able to tell you current news or the latest stock price. Similarly, a corporate RAG bot can answer "What's our latest quarterly revenue?" by fetching the number from a database; GPT-4 alone would just guess or say it doesn't know.
In essence, RAG extends and grounds even the most powerful models, making them more reliable and domain-aware . It's like even a genius sometimes needs to check a reference book for the exact detail - RAG provides that reference check.
Q: How does RAG compare to a normal search engine? Isn't this just search plus summary?
A: RAG does involve search and summarization, but it's more advanced and seamless in experience than a traditional search engine workflow:
- Integrated Answer vs. List of Links: A normal enterprise search engine (or Google, for that matter) returns a list of documents or results. The user then has to click, read, and extract the answer themselves. RAG automates that last mile - it reads the documents for you and gives a synthesized answer. This saves time and also allows the system to combine information from multiple sources. For example, a search engine might give you two manuals; the RAG system can take a relevant paragraph from each and then produce a single, coherent answer that covers both.
- Understanding Context and Language: RAG uses a powerful language model, so it can understand nuanced questions better than keyword search. It can handle natural language queries ("How do I…", "What is the procedure for…") and find relevant info even if not phrased in the exact keywords. It also can resolve pronouns, context from conversation, etc. Traditional search is improving (with semantic search engines), but RAG's use of an LLM means it's at the cutting edge of understanding intent.
- Dynamic Summarization: With RAG, the summary or answer is tailored to the query every time. It's not like you wrote a bunch of FAQ answers in advance - the system truly generates a custom answer. This is powerful when questions are slightly novel or when the combination of facts needed is unique. A search engine can't spontaneously generate a tailored explanation; it can only show what's stored. RAG's generation can translate a technical answer into layman's terms on the fly, or vice versa, depending on what's asked.
- Conversational Ability: Because RAG often powers chatbots, it can have a back-and-forth conversation. After giving an answer, the user might ask a follow-up, and the system can handle that by retrieving more info if needed and remembering the context. A static search engine doesn't do conversational context (though some newer AI-powered search interfaces are bridging that gap - which essentially means they're doing RAG under the hood).
- Scope of Data: You might already have a search tool for your intranet. RAG can actually leverage that same data but make it more accessible. In fact, to implement RAG, you often end up indexing your data similar to search. The difference is in interface and capability: RAG gives a Q&A interface that feels like asking an expert, versus you manually sifting through search results. It's a more user-friendly experience , especially for non-technical users or customers who just want an answer, not homework.
- Accuracy of Extraction: Search engines might surface a document that has the info, but not pinpoint where in the doc the answer is. RAG retrieval often works at the snippet level (bringing back just the relevant paragraph). And the LLM can pick the precise piece of info from that snippet to highlight in the answer. It tends to be more pinpointed. For example, search might return a 100-page PDF for a policy question; the RAG system will quote the specific policy clause that answers the question, which is obviously a better UX.
So while conceptually you can say RAG = search + AI summary, the net effect is transformative: users get direct answers rather than doing the hunting themselves. It's the difference between a librarian handing you a stack of books (search) vs. the librarian having already read them and giving you the answer (RAG). That said, implementing RAG might even utilize your existing search tech for the retrieval part - it's just leveraging it in a smarter way.
Q: Can RAG and other AI techniques (like prompt engineering or knowledge graphs) work together?
A: Definitely. RAG is often part of a broader AI solution and can complement other techniques:
- Prompt Engineering: Even with RAG, how you prompt the language model matters. You'll craft the prompt to include the retrieved text and perhaps instructions like "Use the information above to answer the question. If irrelevant, say you don't know." This is prompt engineering in service of RAG. Outside of that, you might still use prompt tricks to improve the conversation (for example, giving the model a persona or format to follow). So prompt engineering and RAG go hand-in-hand - RAG supplies facts, prompts shape how those facts are used.
- Knowledge Graphs/Symbolic Systems: As mentioned earlier, a knowledge graph can bolster RAG's retrieval. You could navigate the graph to find a relevant subset of documents to feed into the retriever, especially for complex queries needing multi-hop reasoning. Conversely, if you have a knowledge graph that can answer some things directly with a query (like "what's the relationship between X and Y"), you might integrate that with your chatbot. Essentially, RAG could try the knowledge graph first for structured queries and fall back to unstructured RAG for others. They are not mutually exclusive; they are tools in the toolbox. IBM's and other companies' architectures often blend these: use symbolic logic where it excels (consistency, structured queries) and use RAG where unstructured knowledge is needed.
- Agentic AI or Tools Use: RAG can be one of the "tools" an AI agent uses. For instance, an AI agent might have the ability to call a search (retriever) and then use the result to answer, which is exactly RAG. If you think of frameworks like OpenAI's function calling or LangChain's agents, RAG is essentially an agent action (search the docs) followed by using the info. If needed, an agent can use other tools too (like a calculator for math, or an API to perform an action) alongside RAG. So in a complex workflow, RAG might handle the knowledge lookup part.
- Fine-tuning in Combination: Some advanced setups fine-tune the language model to better take advantage of retrieved evidence (for example, fine-tuning on a corpus that includes retrieval context so the model learns how to not ignore provided info). This is a fusion of techniques and can boost performance, though it requires more effort. It's an option if the off-the-shelf model isn't optimally utilizing the retrieved data format.
- Content Generation and RAG: If you're doing lengthy content creation (like writing a report or article), RAG can fetch relevant points and then the model can elaborate. You might incorporate other AI techniques like summarization (generate summaries of long docs to feed in as context) or translation (if sources are multilingual) - basically using RAG as part of a pipeline of tasks.
- Human Feedback (Reinforcement Learning): Over time, you can gather feedback on RAG answers and potentially refine the system with RLHF (Reinforcement Learning from Human Feedback) or just manual adjustments. That's not specific to RAG, but it's another technique to improve the AI's helpfulness and harmlessness. RAG provides a solid starting point (good factual basis), and human feedback can further tune style and correctness.
So, far from being isolated, RAG often plays nicely with other methods. Think of RAG as the information retrieval module in a larger intelligent system. It ensures the AI has the right info, while other techniques ensure the AI uses it correctly, follows instructions, and integrates with business logic. In practice, implementing a real-world AI assistant involves mixing these approaches to get the best of all worlds.

Q: Is RAG a passing trend or is it becoming a standard for AI applications?
A: While we can't predict the future with certainty, RAG appears to be emerging as a standard approach for many AI applications, especially enterprise and knowledge-intensive ones. Here's why:
- Addresses Real Problems: RAG directly tackles the widely recognized issues of hallucination and stale knowledge in AI. As long as those issues exist, RAG (or something with the same effect) is needed. It's not a gimmick; it's solving fundamental reliability problems, which suggests it has staying power.
- Industry Adoption: We're already seeing major players adopt RAG-like solutions. Search engines (Bing, Google's Bard) use retrieval with LLMs for live info. Enterprise software companies are integrating RAG to build smarter assistants (for instance, various SaaS tools now have "AI assistants" that can use your data). NVIDIA, Microsoft, AWS, and others have published guides and tools specifically for RAG. This momentum means a robust ecosystem is forming - which usually indicates the method is becoming a norm.
- Future AI Models: It's likely that future large models will still use something akin to RAG. Some research is going into models that can read from databases or APIs as part of their architecture (sometimes called "modular" or "retriever-augmented" models natively). Even if architectures evolve, the concept of not storing all knowledge in the model and instead fetching it as needed is logically sound and likely to persist. It's how humans work too - we don't memorize entire textbooks verbatim; we recall key points and look up details when needed.
- Efficiency and Practicality: As discussed, RAG is computationally efficient in the sense of not needing constant retraining for new data. This aligns with business needs to reduce cost and deploy quickly. Unless an unforeseen new method arises that can do the same (e.g., some continual learning mechanism that has no catastrophic forgetting, etc.), RAG is a very practical solution available now.
- Versatility: RAG isn't tied to a specific model or vendor - it can augment small open-source models or giant closed models, it can work with text, and it's expanding to multi-modal (imagine retrieving an image or a diagram for a question in addition to text). Its versatility means it's more of a paradigm shift in how we build AI systems than a fad.
- Success Stories: We're already seeing positive reports where RAG significantly improved application performance. For example, users often prefer a chatbot that can cite sources (which is RAG) over one that cannot, because it feels more trustworthy. Companies using RAG for internal knowledge report higher employee satisfaction (they get answers quicker and with evidence). As more success stories accumulate, it reinforces the method's value.
Of course, the field of AI is fast-moving. But even if models get bigger or new techniques emerge, the core idea of grounding AI in external knowledge is likely to remain relevant. In fact, many experts see retrieval-augmented techniques as a key part of the future of trustworthy AI . So investing in RAG now is not just riding a hype wave; it's building on a foundational approach that is poised to be integral to AI systems going forward.
In sum, RAG is here to stay and will probably become as standard as having a database for an application. It's a natural evolution in making AI more usable in real-world, ever-changing information landscapes.
Conclusion & Next Steps
Retrieval-Augmented Generation is revolutionizing how businesses deploy AI solutions by making them more accurate, context-aware, and trustworthy . By allowing AI models to tap into up-to-date knowledge bases, RAG bridges the gap between raw AI capability and real-world business needs. We've seen that RAG-powered systems can act as knowledgeable assistants across industries - from guiding a customer on real estate investments with the latest market data, to helping a doctor recall specialized medical research on the fly, to enabling a telecom support bot to diagnose network issues using internal logs. The possibilities are vast, and the technology is maturing rapidly.
If you're thinking about enhancing your applications with AI that truly knows your domain , now is a great time to explore RAG. The benefits (better performance, happier users, improved trust) are tangible, and the implementation barriers are lower than ever, thanks to advanced frameworks and cloud services. However, success with RAG requires careful integration of data, AI models, and business logic - which is where having an experienced partner can make all the difference.
Baytech Consulting is here to help you harness RAG for your organization's specific needs. With our deep expertise in custom software and AI integration, we can design and implement a RAG-powered solution that leverages your proprietary data safely and effectively. Whether you need a smart internal knowledge base assistant, a customer-facing chatbot that delivers expert answers, or workflow automation that infuses AI with real-time information, our team will tailor the technology to meet your goals. We understand the importance of accuracy, security, and ROI in AI projects for CTOs, CFOs, and department heads alike.
As you plan your next steps, you may find it helpful to understand how AI is transforming the entire software development lifecycle—from code creation to deployment. If you're curious how retrieval-augmented generation fits into the bigger picture of business AI adoption and strategy, our additional guides break down the types of AI models, real-world applications, and best practices for aligning technology with business goals.
Ready to unlock the power of Retrieval-Augmented Generation in your business? Reach out to Baytech Consulting for a consultation. We'll walk you through potential use cases, outline an implementation roadmap, and address any questions about data preparation, costs, or deployment. Don't let your AI operate in the dark - let it tap into the wealth of information you already have and turn it into intelligent action. Contact Baytech today to start the journey toward smarter, more reliable AI solutions that give your business a competitive edge. To explore further, see our deep dive on the current state of artificial intelligence and how these technologies are shaping the future of enterprise solutions.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.