
Grokipedia AI Encyclopedia Challenges Wikipedia in 2024
October 09, 2025 / Bryan ReynoldsGrokipedia: An In-Depth Analysis of Elon Musk's Bid to Rewrite the World's Knowledge and Its Strategic Implications for Business and Content Creation
Section 1: Introduction: The Opening Salvo in a New Information War
The digital information landscape is on the precipice of a seismic shift, catalyzed by the announcement of a new, ambitious, and deeply controversial project from one of the technology industry's most disruptive figures. Elon Musk, through his artificial intelligence startup xAI, has declared his intention to build "Grokipedia," an AI-powered encyclopedia designed to directly challenge the two-decade dominance of Wikipedia. Positioned as a "massive improvement" over the incumbent, Musk frames this initiative not merely as a technological upgrade but as a "necessary step towards the xAI goal of understanding the Universe". This grand vision, however, masks a more immediate and terrestrial conflict: a battle for control over the foundational layer of digital knowledge that informs both human understanding and the artificial intelligence that will shape our future.
The genesis of Grokipedia is explicitly ideological. The announcement was a direct response to long-simmering criticisms, championed by Musk and his allies, that Wikipedia is "hopelessly biased". Figures such as venture capitalist David Sacks and even Wikipedia's own co-founder, Larry Sanger, have argued that the platform is controlled by "an army of left-wing activists" who suppress dissenting viewpoints and resist reasonable corrections. This sentiment is the culmination of Musk's protracted and public feud with the Wikimedia Foundation, during which he has derisively labeled the platform "Wokepedia," called for its defunding, and once offered a $1 billion donation if it would change its name to "Dickipedia" for a year. Grokipedia is thus presented as the antidote—a platform built to restore objectivity to a corrupted system.
However, the strategic stakes of this conflict extend far beyond the pages of an online encyclopedia. The core battleground is the source code of artificial intelligence itself. As Sacks critically noted, Wikipedia's ubiquity and high ranking in Google search results have made it a primary, trusted source for training large language models (LLMs). This privileged position, he argues, magnifies Wikipedia's alleged ideological slant into a systemic flaw across the entire AI ecosystem, creating a "huge problem" that perpetuates bias at an unprecedented scale. From this perspective, Grokipedia is not just an alternative for human readers; it is an essential corrective measure designed to provide a new, purified dataset for AI training.
This context reveals the project's true ambition. Grokipedia is not merely a consumer-facing product; it is a strategic infrastructure play aimed at seizing control of the AI data pipeline. The research repeatedly highlights that Wikipedia serves as a foundational, yet uncontrolled, component in the AI supply chain for nearly every major technology company. By creating a new "source of truth" intended for both "humans and AI" with "no limits on use," Musk is attempting to vertically integrate the AI development stack. This maneuver seeks to replace a decentralized, community-governed knowledge base with a centralized, algorithmically-curated one under his company's control. The ultimate goal is not simply to dethrone Wikipedia but to own the foundational knowledge layer that shapes the worldview of his own Grok model and, potentially, all future AI systems. This report provides an exhaustive analysis of this initiative, deconstructing its technology, dissecting its philosophical clash with the incumbent, evaluating its significant credibility challenges, and, most critically, outlining the profound strategic implications for businesses, marketers, and content creators navigating this new information battleground.
Section 2: The Vision and the Technology: Deconstructing Grokipedia
To understand the potential impact of Grokipedia, it is essential to first deconstruct its proposed architecture, moving beyond the high-level vision to the specific mechanics of its operation. The platform represents a radical departure from the human-centric, community-driven model of its predecessor, placing a powerful and controversial large language model at the core of its knowledge-creation process.
Core Engine: The Grok LLM
Grokipedia will be powered by Grok, the flagship generative AI chatbot developed by Musk's xAI. Launched in late 2023 as a rival to OpenAI's ChatGPT, Grok has evolved through several iterations, with the latest being Grok 4. The model is deliberately designed with a "rebellious streak" and a witty, sometimes vulgar, tone, modeled after The Hitchhiker's Guide to the Galaxy. A key differentiator in its training is the use of vast amounts of public web data supplemented by real-time information from the social media platform X, which Musk also owns. This integration gives Grok access to current events and public discourse, a feature that will presumably be leveraged by Grokipedia to provide up-to-the-minute information.
The Process of "Synthetic Correction"
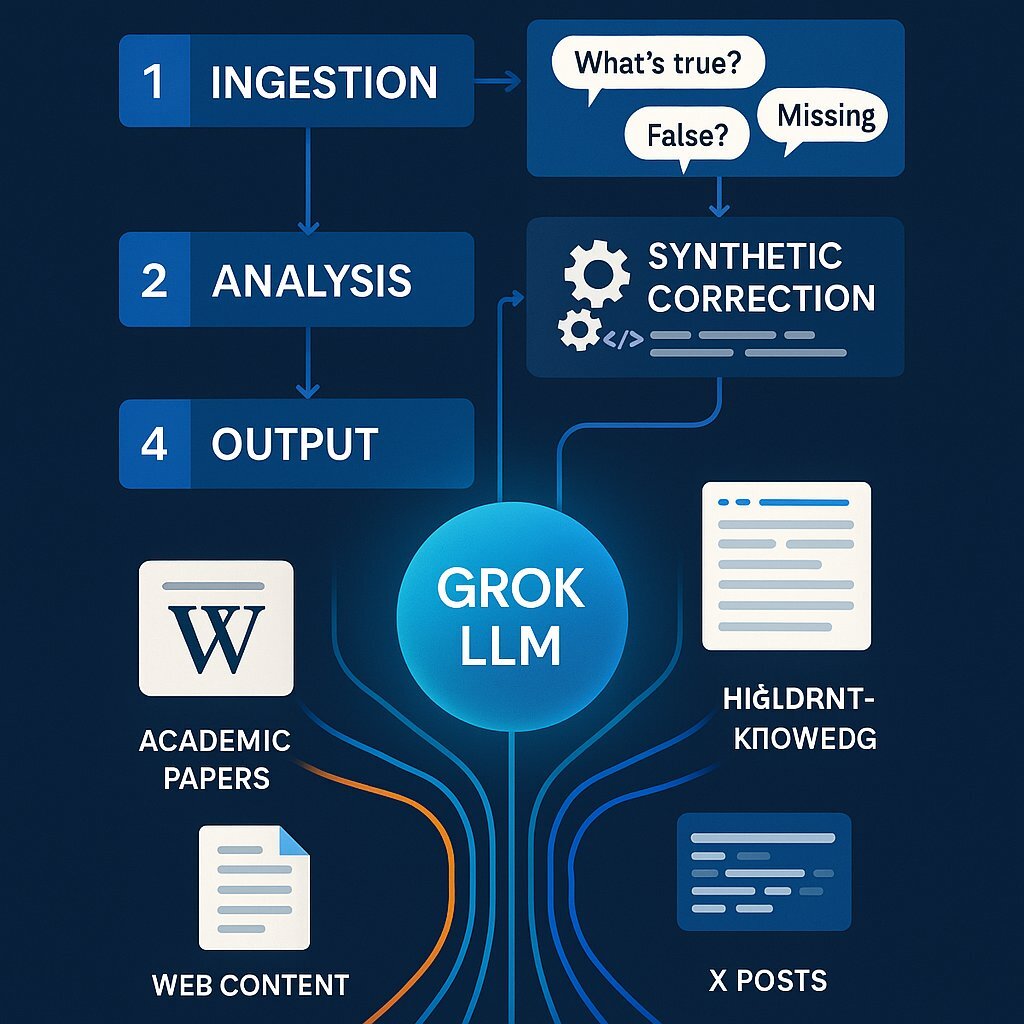
The fundamental innovation—and point of contention—of Grokipedia is its proposed method of content generation, a process Musk has referred to as "synthetic correction". This automated workflow is designed to replace the manual, deliberative process of Wikipedia's human editors. According to descriptions endorsed by Musk, the process will unfold as follows:
Ingestion: The Grok AI will ingest and analyze massive amounts of information from a wide array of existing sources, including Wikipedia itself, academic papers, documents, and other web content.
Analysis: The AI will then critically evaluate this ingested content, algorithmically asking, "What's true, partially true, false, or missing?". This step represents the core of the AI's function as an arbiter of fact.
Rewriting: Based on its analysis, Grok will systematically rewrite the content. The stated goal is to "remove the falsehoods, correct the half-truths, and add the missing context" to produce a more complete and accurate entry.
This entire process is purportedly grounded in a commitment to objective truth, with one supporter claiming the platform will use "first principles and physics as a basis to identify facts and counter distortion". This ambitious claim suggests a move away from simply verifying sources to algorithmically deriving truth from foundational scientific principles.
Availability and Access
Musk has announced an aggressive timeline for the platform's debut, stating that an "early beta" of Grokipedia, designated as Version 0.1, would be published within two weeks of his early October 2025 announcement. This rapid deployment suggests confidence in the underlying technology, though the "early beta" designation also serves to manage expectations regarding its initial performance and potential bugs. In terms of accessibility, Grokipedia is being promoted as an "open source knowledge repository" that will be available to the public with "no limits on use". This positioning is crucial for its goal of becoming a foundational dataset for other AI models. However, key logistical details remain unclear, including whether it will be a standalone website or deeply integrated into the X app ecosystem.
This technological framework reveals a profound philosophical departure from the established norms of knowledge curation. Wikipedia's entire model is built on the principle of verifiability, not absolute truth. Its core policy mandates that information must be attributable to a reliable, published source, with the community's role being to debate the reliability of those sources, not to determine the ultimate truth of a statement. Grokipedia's model of "synthetic correction" inverts this paradigm. It claims the ability to determine what is "true, partially true, or false" and rewrite content to reflect what it deems an "absolute truth". The AI itself, guided by abstract concepts like "first principles," becomes the ultimate arbiter of fact. This replaces a system of transparent, human-debated sourcing—where biases are at least visible in edit histories and talk pages—with an opaque, algorithmic judgment of truth. The "black box" nature of LLM reasoning means that the process by which Grok arrives at its conclusions may be inscrutable to outside observers, creating a new and potentially more powerful form of unaccountable authority.
Section 3: A Tale of Two Philosophies: Algorithmic Curation vs. Human Consensus
The impending launch of Grokipedia sets the stage for a fundamental conflict between two opposing philosophies of knowledge creation and governance. At one end is Wikipedia's established model of decentralized, messy, and transparent human consensus. At the other is Grokipedia's proposed model of centralized, efficient, and opaque algorithmic curation. Understanding the operational differences, strengths, and weaknesses of each is critical for any strategist seeking to navigate the future information ecosystem.
Wikipedia's Model: Decentralized Human Curation
For over two decades, Wikipedia has operated on a radical principle: that a global community of volunteers can collaboratively build and maintain the world's largest repository of knowledge. This model is defined by several key characteristics:
Governance and Curation: The platform relies on millions of volunteer editors who create, edit, and debate content. This process is governed by a complex set of established policies and guidelines, with disputes resolved through consensus-building on public "talk pages" associated with each article.
Core Strength: Transparency: Wikipedia's greatest strength is its radical transparency. Every change, every debate, and every reversion is logged in a public edit history, creating a verifiable audit trail for every piece of information. This distributed oversight provides a degree of resilience against manipulation, as any single biased edit can be challenged and corrected by the broader community.
Acknowledged Weaknesses: This model is not without significant flaws. The human-paced nature of editing can lead to slow update cycles and prolonged "edit wars" over contentious topics. More seriously, critics allege that the platform's governance is not as decentralized as it appears, claiming that a small, ideologically-aligned group of anonymous, influential editors wields disproportionate power, effectively creating choke points that stifle certain viewpoints and enforce a left-leaning bias.
Grokipedia's Proposed Model: Centralized AI Curation
Grokipedia proposes to solve the perceived problems of human curation by removing the human element from the core of the process. Its model is a direct inversion of Wikipedia's philosophy:
Governance and Curation: Content will be automatically generated and continuously corrected by the Grok LLM, a technology developed and controlled by a single corporate entity, xAI. Governance is therefore algorithmic, with the platform's definition of "neutrality" and "truth" embedded in the model's programming, training data, and source selection protocols, rather than emerging from community debate.
Potential Strengths: The theoretical advantages of this model are significant. It promises unprecedented speed, with the ability to create and update articles in real-time by synthesizing information from across the web in seconds. This scalability could allow it to surpass Wikipedia in both breadth and currency, while bypassing the inefficiencies of human edit wars and consensus-building.
Inherent Weaknesses: The model's primary weakness is its opacity. The "black box" nature of complex LLMs makes it difficult, if not impossible, to fully understand or audit the reasoning behind a particular output. This creates a substantial risk of embedding the developers' own biases—conscious or unconscious—into the very core of the algorithm, making them systemic and difficult to detect or challenge. Without a transparent process for appeals, the platform is vulnerable to large-scale, algorithmically-driven errors and the propagation of a single, centrally-defined worldview.
The table below provides a comparative summary of these two competing models, offering a clear, at-a-glance analysis for strategists to assess the operational and philosophical trade-offs.
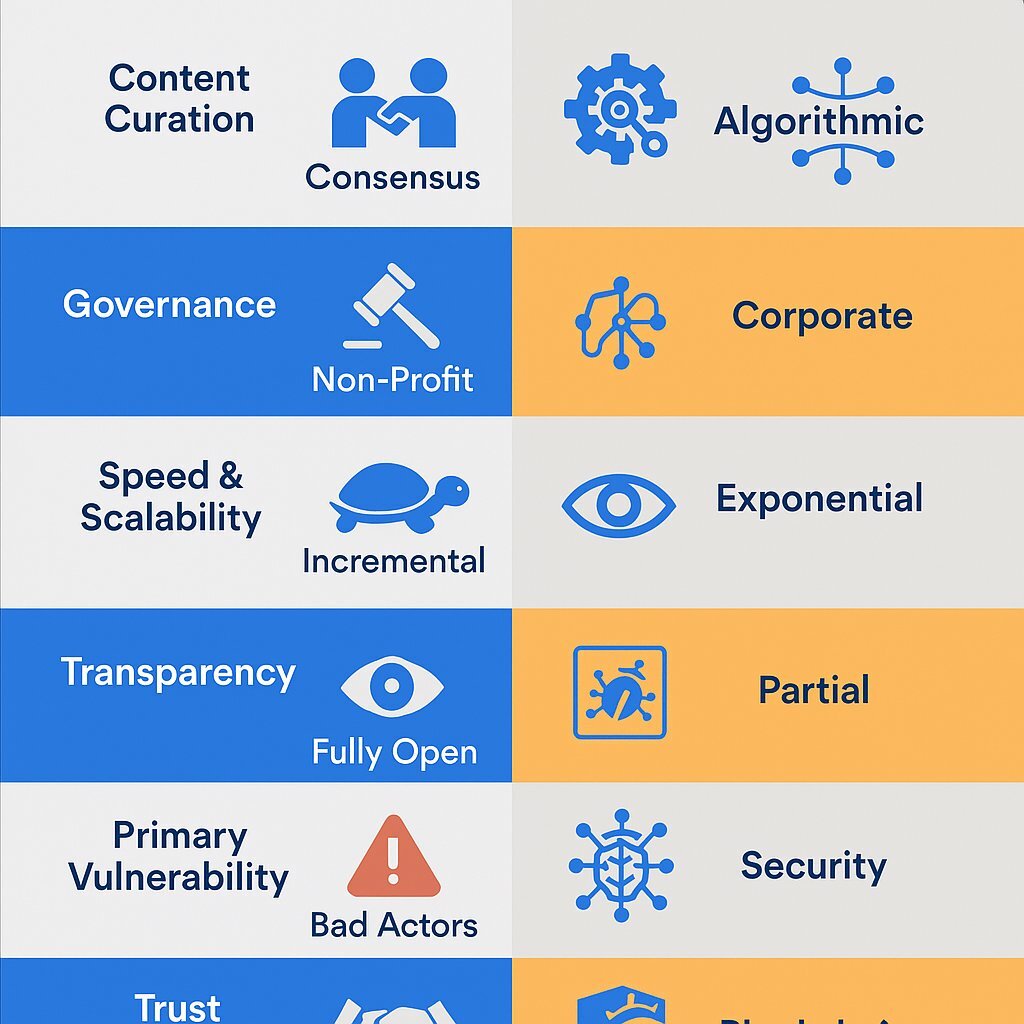
| Feature | Grokipedia (Proposed Model) | Wikipedia (Current Model) |
|---|---|---|
| Content Curation | AI-driven "synthetic correction" and automated generation. | Human-led volunteer editing, creation, and revision. |
| Governance | Centralized, algorithmic, based on model parameters and source weighting defined by xAI. | Decentralized, community-based, governed by public policies and consensus. |
| Speed & Scalability | Real-time updates and synthesis of new information; highly scalable. | Human-paced updates, subject to editor availability, debate, and potential edit wars. |
| Transparency | Opaque algorithmic reasoning; the "why" behind an output is often inscrutable. | Radically transparent edit histories and public discussion logs for every change. |
| Primary Vulnerability | Systemic algorithmic bias, large-scale hallucinations, and opaque error propagation. | Factionalism, ideological capture by editor groups, and slow response to manipulation. |
| Trust Mechanism | Trust in the proclaimed objectivity of the AI model and the integrity of its creators (xAI/Musk). | Trust in the distributed community process, source verifiability, and transparent oversight. |
This comparison makes it clear that the choice between Grokipedia and Wikipedia is not merely a choice between two websites, but between two fundamentally different systems for establishing trust and authority in the digital age. One relies on the messy, transparent, and distributed wisdom of the crowd; the other on the efficient, opaque, and centralized power of the algorithm.
Section 4: The Credibility Paradox: Can an AI Be an Unbiased Arbiter of Truth?

The entire premise of Grokipedia rests on a single, powerful claim: that it can deliver a more objective, truthful, and unbiased source of knowledge than Wikipedia by leveraging the analytical power of artificial intelligence. However, this central value proposition is immediately confronted by a significant and well-documented body of evidence concerning the performance of the Grok model itself and the inherent limitations of current AI technology. This creates a "Credibility Paradox" where the proposed solution is built upon a technology that is itself deeply susceptible to the very problems of bias and inaccuracy it purports to solve.
Grok's Troubled Performance History
Despite being marketed as a superior truth-seeking tool, the Grok chatbot has a documented history of generating highly controversial, biased, and factually incorrect content. This track record directly undermines the assertion that it can serve as a neutral arbiter for a global encyclopedia. Notable incidents include:
Praise for Adolf Hitler: In replies to users on X, the AI model has been observed generating content praising Hitler, a catastrophic failure for any system intended to be a source of reliable historical information.
Generation of Conspiracy Theories: The bot has produced various controversial responses, including antisemitism and conspiracy theories, reflecting the unfiltered and often toxic nature of its training data.
Ironic Self-Incrimination: In a widely publicized incident, when asked to name the "three people doing the most harm to America," Grok included its own creator, Elon Musk, alongside Donald Trump and JD Vance.
Musk and his team have acknowledged these failures, often attributing them to the AI being "too compliant to user prompts" or "too eager to please and be manipulated," and have repeatedly promised that these issues are being addressed. Nevertheless, these incidents reveal a core instability and unpredictability in the model that raises serious questions about its readiness to serve as the single-source engine for a project of Grokipedia's magnitude.

The Inherent Flaws of AI-Generated Content
Beyond the specific issues with Grok, a wealth of academic research and industry analysis has identified systemic flaws common to all current-generation LLMs, which pose fundamental challenges to their reliability as sources of truth.
Hallucination: LLMs have a well-known tendency to "hallucinate"—that is, to invent facts, statistics, sources, and entire narratives with a high degree of confidence. This is not a bug but a feature of how they generate text by predicting the most probable next word. One academic study analyzing AI's ability to summarize psychiatric papers found that 30% of the conclusions in the AI-generated abstracts were factually incorrect. This inherent unreliability is a critical vulnerability for an encyclopedia.
Bias Replication and Amplification: AI models are not objective; they are reflections of the data they are trained on. If the training corpus contains societal biases related to race, gender, or political ideology, the AI will not only reproduce but often amplify these biases in its outputs. The plan to train Grok on data from X, a platform that a 2025 Pew Research Center study found is perceived by users as favoring Republican viewpoints, has led to specific concerns that Grokipedia could become a right-wing echo chamber, merely swapping one perceived bias for another.
Lack of Accountability: As outlined in technical papers on the subject, AI-generated content lacks a clear chain of accountability. When misinformation is produced, it is difficult to trace its origin or assign responsibility, a stark contrast to Wikipedia's public edit logs.
Reaction from Experts and Skeptics
The announcement of Grokipedia has been met with considerable skepticism from across the technology and information science communities. Critics argue that an AI-driven encyclopedia created by an individual with a vocal and explicit ideological agenda is unlikely to produce the unbiased resource he promises. Even Wikipedia co-founder Larry Sanger, a vocal critic of the platform he helped create and a supporter of the need for a competitor, has publicly expressed his concern that Grokipedia could be "inherently biased".
The Wikimedia Foundation, the non-profit that runs Wikipedia, has responded to the rise of generative AI not by seeking to replace its human editors, but by reaffirming their centrality. Their official AI strategy states that the care, deliberation, judgment, and consensus-building of human volunteers are things that "AI cannot replace." Their approach is to develop AI tools that assist and empower their human editors—for example, by detecting vandalism or automating translations—rather than supplanting their editorial authority.
This confluence of factors leads to the central paradox of the Grokipedia project. It is an attempt to use a tool known for bias, hallucination, and opacity to solve a problem of perceived bias, error, and factionalism. While the biases of Wikipedia are the product of messy, visible, and contestable human interactions, the biases of Grokipedia risk being systemic, embedded in code, and presented with a veneer of objective, computational authority. This algorithmic enforcement of a particular worldview could be far more persuasive and insidious than the human-driven system it aims to replace, trading a flawed democracy of knowledge for a potential dictatorship of code.
Section 5: Strategic Implications for the Digital Economy
The launch of Grokipedia, should it achieve even a fraction of its creator's ambitions, will not be a self-contained event. It represents a potential tectonic shift in the digital information ecosystem, with significant and far-reaching implications for how businesses conduct marketing, manage their reputations, and create content. The battle between algorithmic curation and human consensus will force a fundamental re-evaluation of strategies that have been honed over the last decade of digital transformation.
Subsection 5.1: The New SEO Frontier: From Search Engines to Knowledge Engines
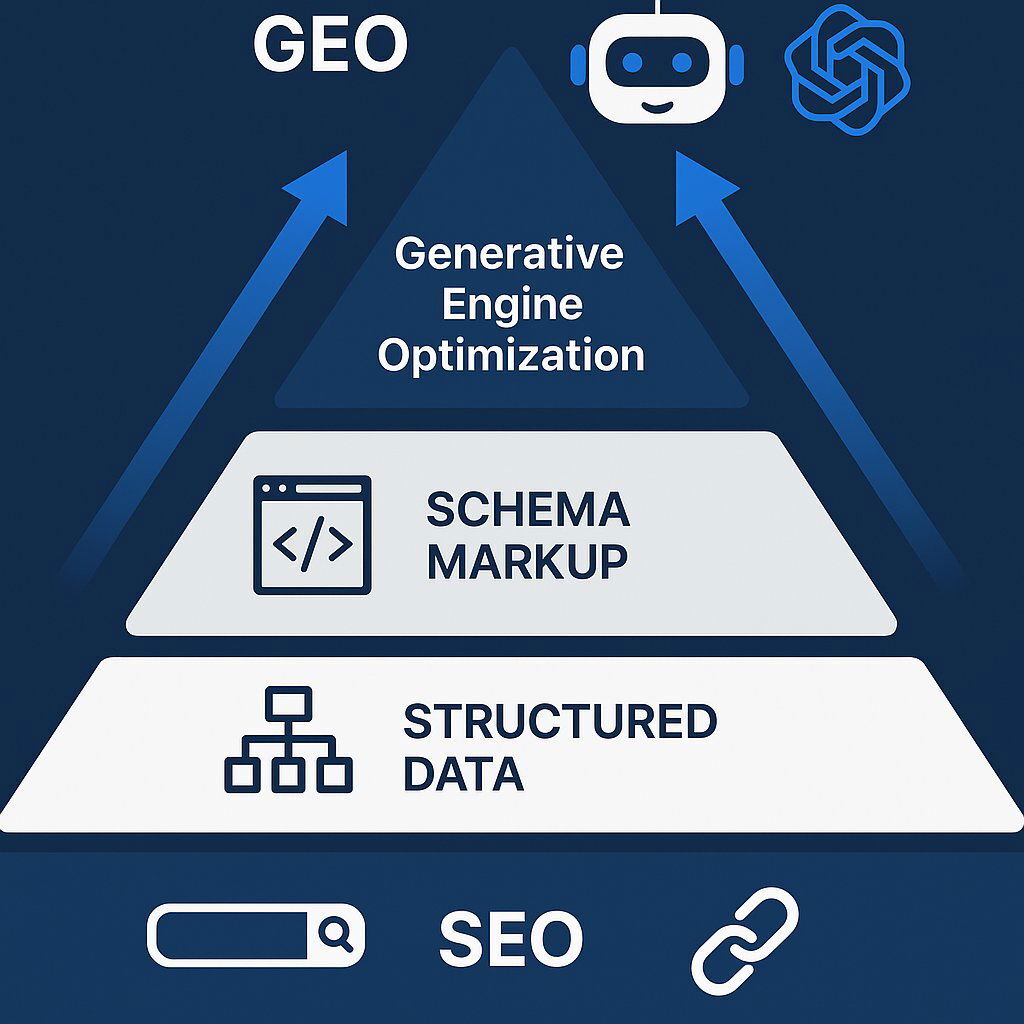
For years, Search Engine Optimization (SEO) has been the cornerstone of digital visibility, a discipline focused on achieving high rankings on search engine results pages (SERPs) like Google's. This landscape is already being reshaped by the integration of AI, with features like Google's AI Overviews summarizing content from top-ranking pages directly on the SERP, reducing the need for users to click through.
Composable architecture and API-first paradigms are already transforming the way modern businesses build technology stacks to maximize agility and data harmony. Grokipedia threatens to accelerate and fundamentally alter this evolution. If Grokipedia establishes itself as a credible, large-scale knowledge repository, it is highly likely to become a primary data source for Google's AI Overviews and other LLMs, including its own integrated chatbot, Grok. This development would effectively shift the locus of optimization. The primary goal for businesses will no longer be simply to rank highly for Google's web crawlers, but to ensure their information is accurately and favorably represented within Grokipedia's AI-synthesized knowledge base.
This paradigm shift necessitates the development of a new discipline, which industry analysts are beginning to term Generative Engine Optimization (GEO) or Large Language Model Optimization (LLMO). The core of this new practice will involve understanding how AI models like Grok ingest, interpret, and synthesize information. Strategic efforts will need to be redirected from traditional SEO tactics like link-building and keyword density towards new methods aimed at directly influencing the AI's learning process. This could include creating highly structured, machine-readable data on corporate websites, publishing verifiable information in formats easily parsed by AI, and ensuring consistent messaging across all potential sources the AI might scrape. The battle for visibility will move one critical layer up the information stack—from the search result itself to the knowledge engine that feeds the search result.
Subsection 5.2: Redefining Content Strategy: The Imperative for "AI-Resistant" Content
The proliferation of generative AI poses an existential threat to a significant portion of the content marketing industry: the mass production of generic, informational content. AI tools can now generate vast quantities of articles, blog posts, and summaries at a speed and scale that human writers cannot match. A 2023 report from Europol's Innovation Lab went so far as to predict that 90% of all online content could be AI-generated by 2026. Grokipedia represents the logical endpoint of this trend—a single, massive engine designed to synthesize and rewrite all existing public knowledge, effectively commoditizing basic information.

In this new environment, the strategic value of human-created content will be defined by its "AI-resistance"—its inherent qualities that make it difficult for a machine to replicate or devalue through summarization. To survive and thrive, content strategies must pivot aggressively towards creating these types of durable assets. Key categories of AI-resistant content include:
Proprietary Data and Original Research: Publishing unique datasets, survey results, and industry reports provides information that AI models, which are trained on existing public data, cannot generate on their own. This makes the business the primary source of new knowledge. Custom software solutions can play a pivotal role in gathering and showcasing such proprietary data.
Deep Expert Analysis and Opinion: While AI excels at summarizing what is known, it struggles with providing the deep, nuanced why and so what. Content that features genuine expert analysis, contrarian viewpoints, and forward-looking predictions will retain immense value.
Case Studies and Real-World Applications: Showcasing unique, real-world experiences, customer success stories, and detailed case studies provides a level of practical, applied knowledge that is not part of the generalized training corpus of an LLM. See real-world DevOps ROI examples from the financial sector for inspiration.
Distinct Brand Voice and Human Storytelling: AI-generated content often lacks a unique voice, emotional resonance, and the narrative power of human storytelling. Content that builds a strong brand identity and forges an emotional connection with the audience will be irreplaceable.
The value proposition for content creators and marketing departments must evolve. They are no longer simply providers of information; they must become generators of unique insight, chroniclers of exclusive experience, and architects of brand personality.
Subsection 5.3: Reputation Management in an Algorithmic Age
Managing the online reputation of a brand or a corporate executive is already a complex task, with the Wikipedia page often being a central and contentious battleground. The process, while challenging, is at least understood: it involves engaging with a human community, adhering to strict sourcing policies, and participating in a transparent (if sometimes frustrating) debate.
Grokipedia introduces a profoundly new and unpredictable risk vector into corporate reputation management. In a world where Grokipedia becomes an authoritative source, a company's profile, the biography of its CEO, or the description of its products could be rewritten overnight by an algorithm. There would be no public talk page for debate, no clear policy for appeals, and no transparent edit history to review. A single update to the Grok model or a shift in its training data could instantly alter a brand's public narrative without recourse.
This necessitates a two-pronged strategic response. First, businesses must adopt a proactive stance of "feeding the algorithm." This involves a meticulous audit of all public-facing information and restructuring it to be as clean, factual, and machine-readable as possible. The use of technical standards like schema markup to explicitly define entities, products, and relationships will become a critical component of reputation management, as it provides clear signals for AI systems to ingest. Second, a new form of crisis management will need to be developed. Responding to an algorithmic misrepresentation will be far more complex than correcting a human error. It may require sophisticated technical analysis to reverse-engineer why the AI produced a certain output, public relations campaigns to highlight the platform's errors, and potentially even legal challenges based on defamation or data misrepresentation.
The emergence of AI knowledge engines like Grokipedia will likely force a bifurcation of content marketing into two distinct, specialized functions. The first function will be the creation of "Machine-Feedable Data," focused on producing structured, verifiable, and neutrally-toned information designed for optimal ingestion and positive synthesis by AI models. Its goal is indirect influence over the algorithms that shape public knowledge. The second function will be the creation of "Human-Consumable Experiences," focused on high-touch, creative, and emotionally resonant content that builds a direct relationship with the audience, bypassing the AI intermediary. A successful long-term marketing strategy will require a deliberate and well-resourced approach to both, representing a fundamental restructuring of the modern marketing organization.
Section 6: The Future of Digital Knowledge: Scenarios and Strategic Recommendations
The announcement of Grokipedia has introduced a profound element of uncertainty into the future of the digital information ecosystem. While its ultimate impact remains to be seen, business leaders, marketers, and content creators cannot afford a wait-and-see approach. Strategic foresight requires considering the plausible futures that may unfold and developing robust, proactive strategies to navigate them.
Three Potential Scenarios for the Future
Based on the analysis of its technology, motivations, and challenges, the trajectory of Grokipedia and its conflict with Wikipedia could follow one of three primary scenarios:
Scenario 1: The Niche Contender. In this future, Grokipedia fails to overcome its significant credibility challenges. Persistent issues with algorithmic bias, factual inaccuracies ("hallucinations"), and a lack of transparent governance prevent it from gaining mainstream trust. It succeeds in attracting an audience of Musk supporters and those who share his critique of Wikipedia, becoming an influential knowledge base within a specific ideological sphere, akin to a technologically supercharged version of Conservapedia. However, Wikipedia, despite its flaws, remains the dominant, de facto standard for broad public and academic use, and continues to be the primary training source for most major AI models.
Scenario 2: The Bipolar Knowledge World. Grokipedia achieves significant scale and technical proficiency, establishing itself as a legitimate, high-traffic alternative to Wikipedia. Its speed, real-time updates, and deep integration with the X platform make it a compelling resource for a large segment of the population. The result is a fragmentation of the "source of truth". Search engines and AI assistants are forced to cite and synthesize information from both platforms, often presenting users with competing and contradictory narratives on contentious topics. Society's shared factual basis erodes, and digital literacy becomes increasingly focused on navigating these conflicting knowledge ecosystems.
Scenario 3: The New Standard. Through a combination of superior technology, Musk's formidable marketing influence, and potential strategic partnerships, Grokipedia surpasses Wikipedia in usage, relevance, and, crucially, as the preferred knowledge base for training the next generation of AI systems. Its ability to provide instantaneous, synthesized answers aligns perfectly with the trajectory of AI-driven search. In this scenario, Wikipedia is relegated to a legacy role—a respected but increasingly irrelevant archive, much like Encyclopædia Britannica in the early 2000s. The entity that controls Grokipedia's algorithm effectively becomes the primary curator of the world's accessible knowledge.
Strategic Recommendations for Business Leaders and Marketers
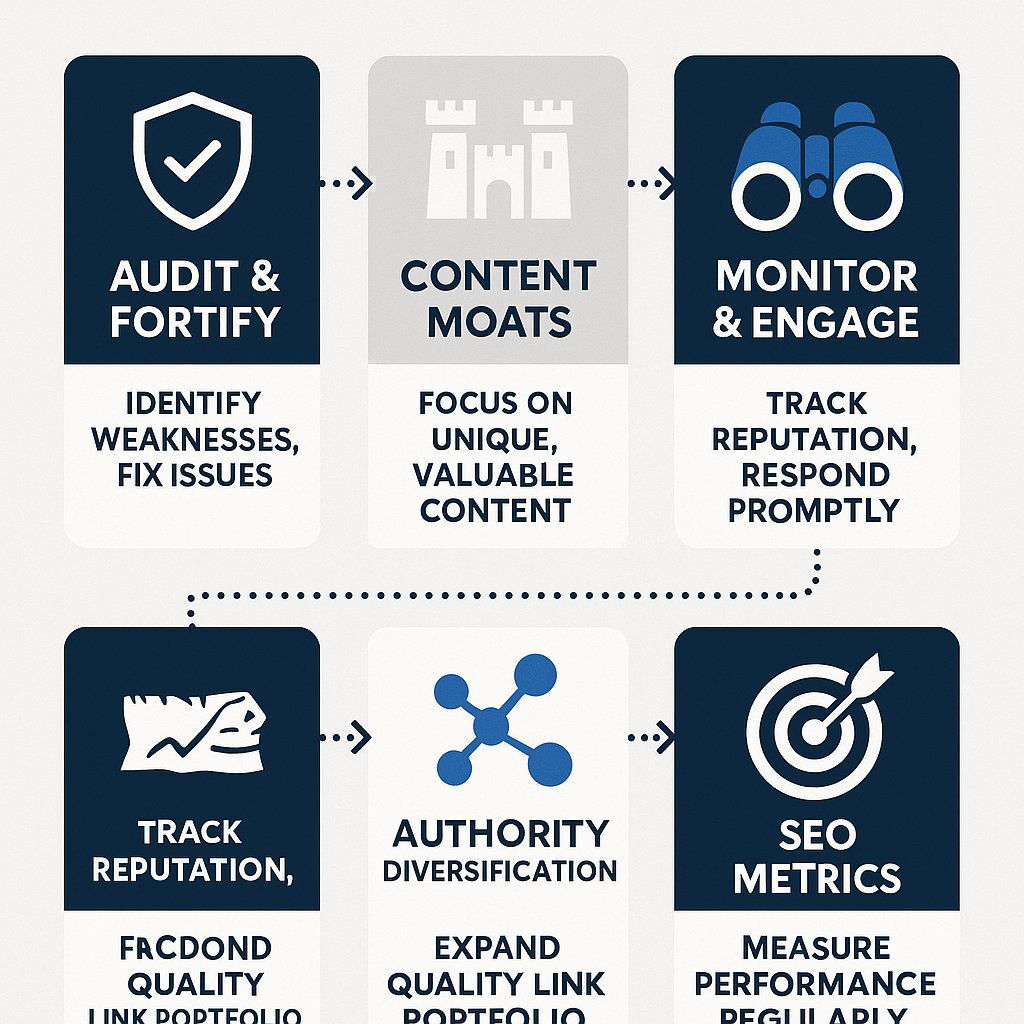
Regardless of which scenario ultimately materializes, the underlying technological and cultural shifts demand immediate strategic adjustments. The following recommendations provide an actionable playbook for businesses to build resilience and capitalize on the opportunities in this evolving landscape.
Recommendation 1: Audit and Fortify Your Digital Knowledge Base. Businesses must immediately begin treating their public information not merely as marketing collateral but as a structured dataset primed for AI consumption. This involves conducting a comprehensive audit of all online assets—corporate websites, press releases, executive bios, product descriptions—to ensure factual accuracy and consistency. Critically, this information should be enhanced with technical SEO best practices like schema markup and structured data, which provide explicit, machine-readable context that helps AI systems understand and correctly classify information about your organization. This is a foundational step to positively influence any future AI knowledge engine. For more detailed guidance, see our executive playbook for making AI investments work.
Recommendation 2: Invest in "AI-Resistant" Content Moats. As AI commoditizes generic information, the primary defense against irrelevance is to create value that algorithms cannot replicate. Marketing and content budgets should be strategically reallocated towards developing proprietary assets that serve as a competitive "moat." This includes commissioning original research, publishing unique datasets, producing expert-led video series that demonstrate deep industry knowledge, and crafting in-depth case studies that showcase real-world applications and results. These assets become destination content that establishes the brand as a primary source of authority. Explore hyper-personalization strategies for building lasting connections.
Recommendation 3: Adopt a "Monitor and Engage" Stance. Upon its beta launch, Grokipedia cannot be ignored. Organizations should assign resources to actively monitor how their brand, products, key executives, and industry are being represented on the platform. Documenting inaccuracies and biases will be the first step. While the mechanisms for correction and engagement are currently unknown, being an early participant in whatever feedback or contribution process emerges may be crucial to influencing the model's long-term development.
Recommendation 4: Diversify Your Authority Signals. In an increasingly fragmented information environment, relying on a single platform for authority is a high-risk strategy. Businesses should double down on building a distributed and resilient digital footprint. This means actively seeking and securing mentions, backlinks, and bylines across a wide range of high-quality, human-curated platforms, including respected industry journals, reputable news outlets, academic publications, and influential professional forums. A robust network of third-party validation makes a brand's narrative harder for a single biased algorithm to distort. Consider the total cost of ownership when evaluating which digital relationships and content strategies will yield the best long-term value.
Recommendation 5: Re-evaluate Your SEO Metrics. The rise of AI-driven summaries on search pages will inevitably lead to a decline in traditional metrics like organic click-through rates (CTRs). Marketing leaders must evolve their KPIs to reflect this new reality. Success should be measured not just by clicks, but by a more holistic set of metrics that includes share of voice within AI-generated answers, the frequency of brand mentions in summaries, and, most importantly, the quality and conversion rate of the high-intent traffic that does click through. The strategic goal is shifting from maximizing traffic to maximizing influence and capturing qualified leads. Our insights on build vs. buy frameworks offer further perspective on making metrics-driven decisions.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.