
Understanding Event Sourcing: Key Principles and Benefits
August 02, 2025 / Bryan Reynolds
The Foundations of Event Sourcing: A Paradigm Shift in Data Persistence
This section establishes the fundamental principles of Event Sourcing, moving from the high-level conceptual shift away from traditional data management to the concrete mechanics that underpin the pattern. The goal is to build a solid, unambiguous understanding of what Event Sourcing is before analyzing why and when to use it.
Defining Event Sourcing: From Snapshot to Narrative
Event Sourcing is an architectural pattern for data persistence that represents a fundamental paradigm shift. In contrast to traditional persistence models that store only the current state of data—a single snapshot in time—Event Sourcing captures the full history of an application's state as a chronological sequence of immutable events. The central tenet of this approach is that this sequence of events, stored in an append-only log, becomes the single, authoritative source of truth for the system. Any change to the state of an application is captured and stored as an event object, preserving the complete narrative of how the data reached its current disposition.
The most effective analogy for understanding this shift is the accounting ledger. An accountant records transactions (credits and debits) in a ledger. To find the current balance, one sums up all the transactions. Crucially, past entries are never erased or modified; corrections are made by appending new, compensating entries. This provides a complete, auditable history. Traditional state-oriented databases, by contrast, are more akin to a scrapbook that only shows the final picture; when a new picture is added, the old one is discarded, and the context of the change is lost.
This concept, while gaining prominence in modern distributed systems, is not new. It was formally articulated by Martin Fowler in a seminal 2005 essay, grounding the pattern in a long-established history and demonstrating its enduring relevance in software architecture. The core idea is that by storing the sequence of state-changing events, a system can not only be queried for its current state but can also reconstruct any past state, providing a powerful foundation for auditing, debugging, and business analytics.
Core Mechanics and Components: The Machinery of Event Sourcing
To implement the Event Sourcing pattern, several key components and mechanical processes must work in concert. These elements form the machinery that enables the shift from state-based to event-based persistence.
The Event Store
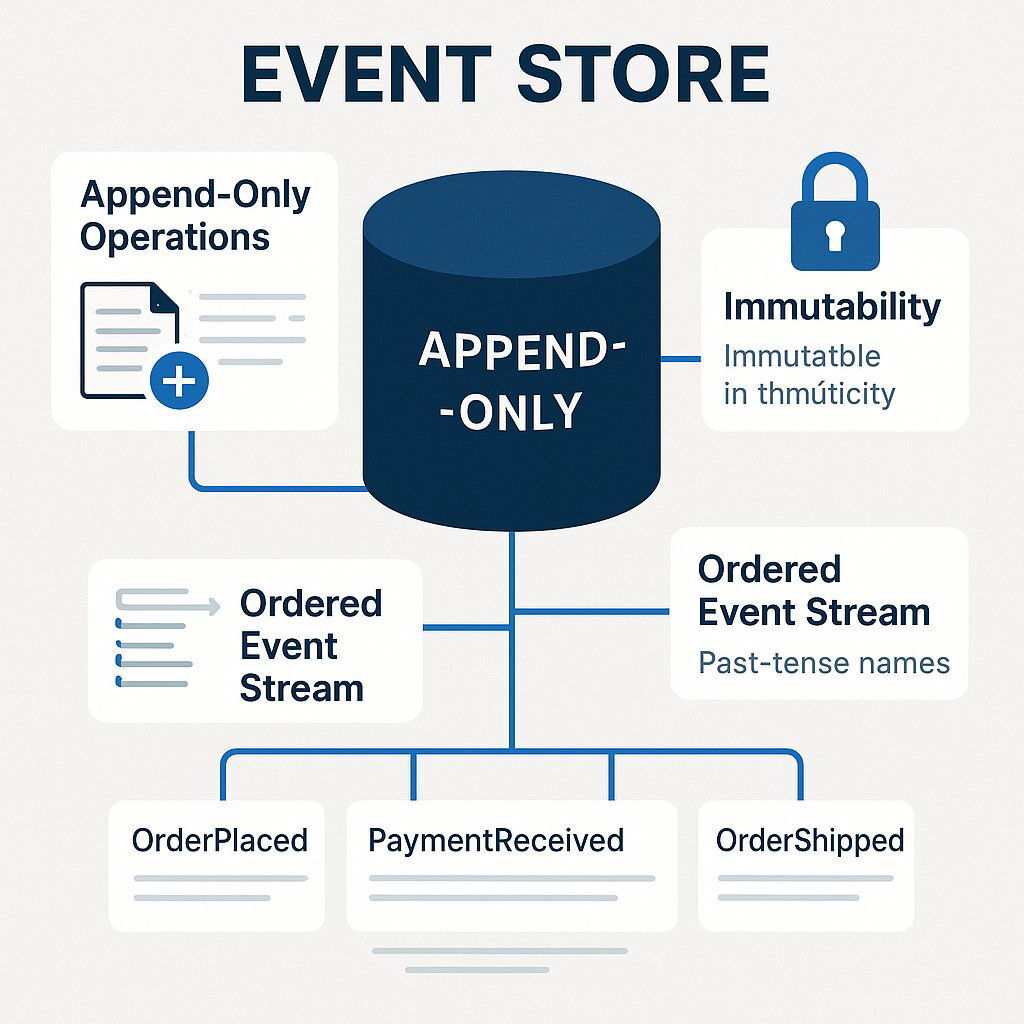
The heart of any event-sourced system is the event store. This is a specialized database or persistence mechanism designed to function as an append-only log. Its primary responsibility is to store sequences of events, often grouped into "streams," where each stream typically corresponds to a single entity instance (e.g., a specific customer order). The defining characteristics of an event store are:
- Append-Only Operations: Events are written to the store but are never modified or deleted. Any correction or reversal of a past action is achieved by appending a new, compensating event.
- Immutability: Once an event is written to the store, it is considered an immutable fact and cannot be changed.
- Ordering Guarantee: Events within a stream are stored and retrieved in the precise chronological order they occurred. This ordering is critical for correctly reconstructing the state of an entity.
While specialized databases like EventStoreDB are built for this purpose, general-purpose databases, particularly NoSQL databases like Azure Cosmos DB, are also frequently used due to their scalability and flexible schemas that accommodate evolving event structures.
Events as First-Class Citizens
In an event-sourced system, events are not merely passive log entries; they are rich, domain-specific objects that are treated as first-class citizens of the domain model. An event represents a significant business fact that has occurred. To be effective, events should be designed with the following principles:
- Named in the Past Tense: Event names should be declarative and use past-tense verbs to signify that the action has already completed (e.g.,
OrderPlaced,ItemAddedToCart,PaymentSubmitted). - Capture Business Intent: A well-designed event captures the intent and context of a change, not just the resulting data. This makes the event log meaningful to domain experts and provides richer data for future analysis. For example, an
AccountClosedevent is more descriptive than a simple state change tostatus: "closed".
Aggregates and State Reconstruction (Rehydration)
The "sourcing" in Event Sourcing refers to the process of deriving an entity's current state from its history of events. The current state is not stored directly. Instead, it is reconstructed on-demand through a process known as rehydration. The typical workflow is as follows:
- When an operation needs to be performed on an entity (often a Domain-Driven Design Aggregate), the system first creates a new, empty instance of that entity.
- It then queries the event store for the complete stream of events associated with that specific entity instance.
- Finally, it applies each event from the stream to the empty instance in chronological order. Each event application modifies the in-memory state of the entity. After the last event is applied, the entity is fully rehydrated to its current state and is ready to process new commands.
Commands vs. Events
A crucial distinction within this architecture is between commands and events.
- Commands are imperative requests to perform an action. They represent an intent to change the state of the system (e.g.,
CreateUserCommand,AddItemToCartCommand). A command can be rejected if it violates business rules. - Events are declarative, immutable records of something that has already happened. They represent a fact and cannot be rejected.
In a typical flow, a command handler receives a command. It loads the relevant aggregate by rehydrating it from its event stream. It then executes the business logic of the command against the aggregate's current state. If the command is valid, the aggregate produces one or more new events. These events are then persisted to the event store, atomically completing the operation.
Projections and Materialized Views
While rehydrating an aggregate from its events is fundamental to the write model, it is highly inefficient for handling queries. Reading the entire event stream for multiple entities just to display a list in a user interface would be prohibitively slow. To solve this, event-sourced systems almost universally employ projections, also known as materialized views.
A projection is a process that consumes the stream of events and builds a separate, optimized read model. This read model is specifically designed for the query needs of the application. For example, as OrderPlaced and OrderItemAdded events occur, a projection might update a denormalized JSON document in a document database or a row in a relational table that represents an "Order Summary" view. Applications then query these materialized views directly, bypassing the event store and the need for rehydration. This approach is so common that it leads directly to the Command Query Responsibility Segregation (CQRS) pattern, discussed later in this report.
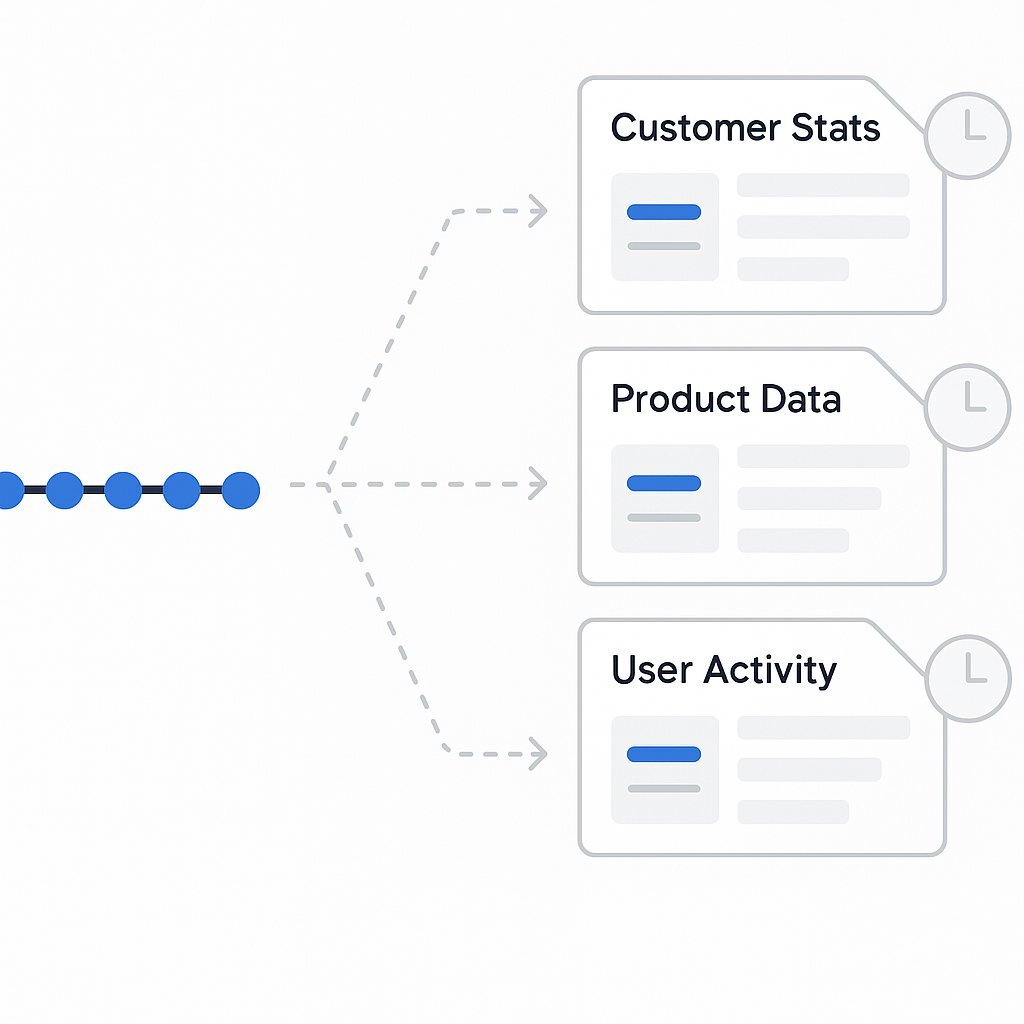
The use of projections and the mechanics of rehydration reveal a deeper architectural characteristic: Event Sourcing is fundamentally a write-side optimization pattern. The core mechanical change it introduces is to transform a potentially contentious and complex UPDATE operation into a simple, non-destructive, and highly performant APPEND operation. This dramatically reduces write contention and simplifies the transactional logic on the write path. The complexity is deliberately shifted to the read path, which is then managed through the creation of these specialized, eventually consistent projections.
The Role of Snapshots: A Critical Performance Optimization
The process of rehydrating an aggregate by replaying its events, while conceptually pure, introduces a significant performance challenge for long-lived entities. An aggregate that has existed for years might have a history of thousands or even millions of events. Replaying this entire stream every time the aggregate is needed would introduce unacceptable latency.
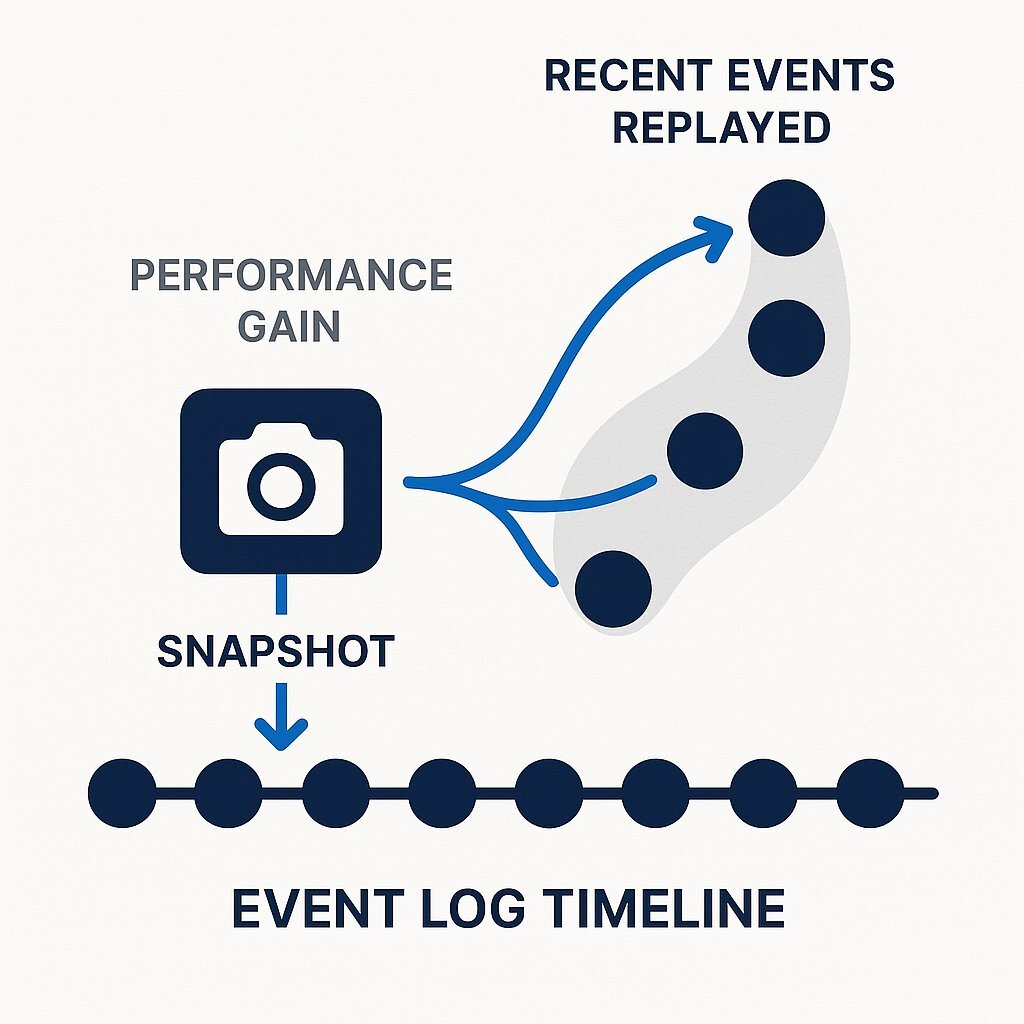
To mitigate this, a critical optimization technique called snapshotting is employed. A snapshot is a persisted, serialized copy of an aggregate's full state at a specific point in time or, more commonly, at a specific version number (e.g., after its 100th event).
When the system needs to rehydrate an aggregate that has snapshots, the process is modified:
- Instead of starting with an empty instance, the system loads the most recent snapshot of the aggregate from storage.
- It then queries the event store only for the events that have occurred after that snapshot was taken.
- It applies this much smaller subset of events to the state loaded from the snapshot.
This drastically reduces the number of events that need to be processed, significantly improving the performance of rehydration for aggregates with long event histories. The strategy for when to create snapshots—for instance, every N events or based on time intervals—is a key design decision that balances write performance (creating snapshots adds overhead) with read performance (frequent snapshots speed up rehydration).
The practical necessity of both projections (for queries) and snapshots (for rehydration) demonstrates that "pure" Event Sourcing is more of a theoretical concept than a practical implementation. Any real-world, production-grade system will almost certainly implement Event Sourcing as part of an integrated trio of patterns: Event Sourcing for the write model's source of truth, Projections for the read models, and Snapshots for write model performance. An architect evaluating this pattern should therefore consider the complexity and benefits of this entire composite pattern, not just Event Sourcing in isolation.
The Strategic Imperative: Benefits and Inherent Challenges
Adopting Event Sourcing is a significant architectural decision with profound consequences. It offers a unique set of powerful benefits that are difficult to achieve with traditional models, but these advantages come with inherent and non-trivial challenges. This section provides a balanced examination of this strategic trade-off.
Key Architectural Benefits
The advantages of Event Sourcing extend beyond simple data persistence, enabling new capabilities related to auditability, business intelligence, and system resilience.
Unerring Auditability and Traceability
Perhaps the most celebrated benefit of Event Sourcing is the creation of a perfect, intrinsic audit log. In traditional systems, auditing is often an add-on, implemented via triggers or application-level logging, with the inherent risk of being incomplete or out of sync. In an event-sourced system, the event log is the system of record. Every single state change is captured as a meaningful, immutable event, providing a 100% accurate and verifiable history of the system's behavior from its inception. This is not just a technical feature; it is a critical business enabler for industries with stringent compliance and regulatory requirements, such as finance and healthcare, and is invaluable for security forensics and root cause analysis of production incidents.
Temporal Capabilities and Business Insight
By preserving the full history of changes, Event Sourcing unlocks powerful temporal capabilities. The ability to query the state of the system at any point in the past, a feature often called "time travel," moves from being a theoretical exercise to a practical tool. This has several profound implications:
- High-Fidelity Debugging: Developers can reproduce bugs with perfect accuracy by replaying the exact sequence of events that led to a failure in a production environment, drastically reducing the time spent on diagnostics.
- Advanced Analytics and Projections: The system can be used for "what-if" analysis by replaying events up to a certain point and then projecting potential future outcomes based on different business rules or inputs.
- Future-Proofing Business Data: The event log captures the rich context and intent behind business operations. Data that may not seem valuable today can be mined in the future to build new features, generate new reports, or train machine learning models. By never discarding data, Event Sourcing creates a valuable asset that can provide a long-term competitive advantage.
Enhanced System Resilience and Fault Tolerance
The separation of the event log (the source of truth) from the read models (projections) creates a highly resilient architecture. Since the state stored in materialized views is derived, it is considered ephemeral. If a read model becomes corrupted, contains a bug, or needs to be changed to support a new feature, it can be safely deleted and completely rebuilt by replaying the event stream from the event store. This makes the read side of the system fault-tolerant and easy to evolve without risking the authoritative data.
Improved Performance and Scalability in High-Contention Systems
As previously noted, Event Sourcing transforms write operations. Instead of performing complex UPDATE statements that may require locking multiple rows or tables, the system executes a simple, atomic append to a log. This operation has extremely low contention, which can vastly improve performance and scalability for applications with high write loads or many concurrent users updating the same data. By decoupling the write operation from the tasks that handle the events (like updating read models), the system can remain highly responsive to user input, as the time-consuming work is handled asynchronously in the background.
Critical Challenges and Mitigation Strategies
The benefits of Event Sourcing are compelling, but they are intrinsically linked to a set of significant challenges. Adopting the pattern means committing to solving these challenges, as they arise directly from the same mechanics that provide the benefits.
Inherent Complexity
The single greatest barrier to adopting Event Sourcing is its complexity. It is not a simple pattern and introduces a steep learning curve and a significant cognitive load for development teams. It permeates the entire architecture, influencing how data is modeled, persisted, queried, and evolved. For simple applications, this complexity is a form of over-engineering and is often cited as a reason to avoid the pattern unless its benefits are strictly required.
- Mitigation: The primary mitigation is to apply the pattern judiciously. Avoid using it as a default for all services. Instead, consider a hybrid approach where Event Sourcing is applied only to the most critical, complex, and auditable bounded contexts of a system, while simpler CRUD models are used elsewhere. Starting with a minimal, well-understood implementation can also help manage the learning curve.
Eventual Consistency
Because read models are typically updated asynchronously from the event stream, a delay exists between when a write occurs and when that change is reflected in query results. This state is known as eventual consistency. For example, a user might submit an order and be redirected to a summary page that does not yet show the new order. This is a fundamental trade-off that the entire application, including the user interface, must be designed to handle gracefully.
- Mitigation: The system must be designed for eventual consistency from the outset. This can involve UI strategies that provide immediate feedback to the user that their action was successful and is being processed (e.g., "Your order has been submitted and will appear shortly"). For scenarios where immediate consistency is required (a "read-your-own-writes" scenario), the system may need to query the write model directly or wait for the specific projection to be updated.
The Event Versioning Problem
Events stored in the event log are immutable and, in theory, live forever. However, business requirements and software evolve, which inevitably leads to changes in the structure or schema of events. For example, a
UserRegistered event might later need to include a new TimeZone field. When replaying the event log, the system must be able to handle both the old and new versions of this event. This is a non-trivial problem that requires a deliberate versioning strategy.
- Mitigation: Several strategies exist to manage event versioning. One common approach is upcasting, where old event versions are transformed into the new format on-the-fly as they are read from the event store. Another is to maintain multiple versions of event handlers in the code, allowing the application to process any historical event format. For major structural changes, it may be necessary to perform an event stream transformation, where the entire event log is replayed and written to a new stream with all events migrated to the latest schema.
Data Management and Compliance
The immutable, append-only nature of the event log introduces unique data management challenges.
- Storage: The event log grows indefinitely, which can lead to significant storage costs and potential performance degradation over time if not managed properly.
- GDPR and the "Right to be Forgotten": The principle of immutability is in direct conflict with data privacy regulations like GDPR, which mandate the right for users to have their personal data erased. Deleting an event from the log would corrupt the history and invalidate the state of all subsequent events in that stream.
- Mitigation: For storage concerns, strategies include aggressive snapshotting to reduce the need to retain all events online, as well as using tiered storage to move older, less-frequently-accessed events to cheaper, archival storage. The GDPR challenge is more complex. Common solutions include cryptographic erasure (encrypting a user's personally identifiable information (PII) with a user-specific key and then deleting the key, rendering the data unreadable) or storing PII in a separate, mutable data store that is referenced by an ID in the event, rather than embedding the PII in the event itself. This allows the reference data to be deleted without altering the immutable event log.
The interconnectedness of these benefits and challenges is fundamental. The very immutability that provides a perfect audit trail is the same characteristic that creates the significant challenge for GDPR compliance. The complete historical record that enables powerful replay capabilities for debugging and resilience is also the source of the event versioning and storage problems. Therefore, an architect cannot simply choose to adopt the benefits of Event Sourcing; they must commit to actively managing the challenges that are causally and inextricably linked to them. The decision to use Event Sourcing is a decision to embrace this entire package of trade-offs.
A Comparative Analysis: Event Sourcing vs. Traditional State-Oriented Persistence
To fully appreciate the architectural implications of Event Sourcing, it is essential to contrast it directly with the industry's default approach to data management: the state-oriented, or CRUD, model. This section provides a structured comparison to highlight the fundamental differences in philosophy, mechanics, and outcomes, equipping architects with a clear framework for evaluating the two paradigms.
The CRUD Paradigm: The World as a Snapshot
The CRUD model, an acronym for Create, Read, Update, and Delete, is the bedrock of most application data persistence. It is centered on the direct manipulation of the
current state of entities. When a user's profile is updated, an UPDATE statement modifies the existing record in the database. When an order is canceled, a DELETE statement removes it. The strength of this model lies in its conceptual simplicity, its ubiquity in frameworks and ORMs, and the straightforward nature of its query model: the data you need is typically stored in a format that is ready to be read.
The core limitation of the CRUD paradigm, however, is that its write operations are destructive. An UPDATE overwrites the previous state, and a DELETE erases it entirely. This process discards invaluable historical context. The system can tell you what the state of an entity is now, but it has lost the information about how or why it arrived at that state.
A Foundational Dichotomy: Storing State vs. Storing History
The choice between CRUD and Event Sourcing is a choice between two fundamentally different philosophies of data. CRUD is concerned with storing the present state, while Event Sourcing is concerned with preserving the past as a series of immutable facts. This leads to profound differences across every aspect of data management.
- Data Model: A CRUD system models data as it exists now . An event-sourced system models data as a sequence of things that have happened.
- Data Fidelity: CRUD is inherently lossy. Every
UPDATEorDELETEoperation discards information. Event Sourcing is lossless; because events are immutable and only ever appended, the full narrative of the system is preserved in perpetuity. - Write Operation: In a CRUD system, writes are destructive and modify existing data. In an event-sourced system, writes are constructive; they are append-only operations that add new information without altering the past.
- Read Operation: Reading data in a CRUD system is typically a direct and simple operation. In an event-sourced system, reading the current state is an indirect and more complex process, requiring either the rehydration of an entity from its event stream or a query against a separate, pre-built projection.
- Business Insight: A CRUD database can answer the question, "What is the customer's current address?". An event-sourced system can answer that question, but it can also answer, "How many times has this customer moved in the last five years, and what were their previous addresses?".
- Complexity: CRUD presents a lower barrier to entry and is generally simpler to implement and reason about initially. Event Sourcing introduces significant conceptual and operational complexity related to event design, versioning, projections, and eventual consistency.
Table: Comparative Analysis of Event Sourcing vs. CRUD
The following table provides a consolidated, at-a-glance comparison of the two persistence models across key architectural dimensions. This serves as a decision-support framework for evaluating which set of trade-offs is better aligned with a specific system's requirements.
| Feature / Dimension | Traditional State-Oriented (CRUD) | Event Sourcing |
|---|---|---|
| Source of Truth | The current state of data in tables/documents. | The chronological, immutable log of events. |
| Data Operation | Destructive writes (UPDATE, DELETE modify/erase data). | Append-only writes (Events are added, never changed or deleted). |
| Data Fidelity | Lossy. Historical states and context are overwritten and lost. | Lossless. The complete history of all changes is preserved. |
| Audit Trail | An afterthought. Must be explicitly built and maintained separately. | Intrinsic. The event log is a perfect, built-in audit trail. |
| Querying for State | Direct and simple (e.g., SELECT * FROM users WHERE id=1). | Indirect and complex. Requires replaying events or querying a pre-built projection. |
| Temporal Queries | Difficult to impossible without complex, custom logging mechanisms. | Natural. The system can be reconstructed to any point in time by replaying events. |
| Complexity | Lower initial conceptual and implementation complexity. | Higher complexity in implementation, event versioning, and data management. |
| Consistency Model | Typically favors strong consistency for both reads and writes. | Write model is strongly consistent, but read models are typically eventually consistent. |
| Business Insight | Answers "What is the state now?" | Answers "How and why did the state get here?" |
| Schema Evolution | Managed via database migrations (e.g., ALTER TABLE). | Managed via event versioning strategies (e.g., upcasting). |
| Fit for... | Simple applications, static data, systems where history is irrelevant. | Complex domains, financial/auditable systems, collaborative platforms, long-running processes. |
The Hybrid Approach: Pragmatism Over Dogma

The decision between Event Sourcing and CRUD is not necessarily a binary, all-or-nothing choice. A highly effective and pragmatic strategy is to adopt a hybrid model within a larger system architecture. This approach recognizes that different parts of an application have different requirements and seeks to apply the appropriate pattern where it delivers the most value.
For example, a system could use Event Sourcing for its core, mission-critical domain where auditability and complex business logic are paramount (e.g., order processing, financial transactions). Simultaneously, it could use a simple CRUD model for less critical, supporting domains where history is irrelevant and simplicity is valued (e.g., managing user preferences, content for a help section). This strategy contains the high complexity of Event Sourcing to the bounded contexts where its benefits justify the cost.
Another common hybrid pattern is "CRUD with Event Logging." In this model, the system remains fundamentally state-oriented, with a traditional database as the source of truth. However, application logic (e.g., an after_update hook in an ORM) is added to generate and persist an event that describes the change. This provides a lightweight audit trail without incurring the full complexity of rehydration and projections. However, it's crucial to recognize that this is not Event Sourcing; the log is a side effect, not the source of truth, and it does not provide the same guarantees of state reconstruction or resilience.
The Architectural Ecosystem: ES, CQRS, DDD, and Microservices
Event Sourcing does not exist in an architectural vacuum. Its practical application and true power are often realized in conjunction with other modern design patterns. This section explores the critical and often symbiotic relationships between Event Sourcing and Command Query Responsibility Segregation (CQRS), Domain-Driven Design (DDD), and microservice architectures. Understanding this ecosystem is key to leveraging Event Sourcing effectively.
The Symbiotic Relationship with CQRS
Command Query Responsibility Segregation (CQRS) is an architectural pattern that mandates a separation between the models used to update information (the "command" side) and the models used to read information (the "query" side). Instead of using a single data model for both writing and reading, CQRS advocates for distinct models optimized for each task.
This separation makes Event Sourcing and CQRS a natural and powerful pairing, often described as a "match made in heaven." The two patterns solve each other's primary weaknesses.
- Event Sourcing Implements the Write Model: Event Sourcing provides a perfect implementation for the command side of a CQRS architecture. The event log serves as the definitive, transactionally-consistent write model. Command handlers operate on aggregates that are rehydrated from this event log, process business logic, and produce new events that are atomically appended to the log.
- Projections Implement the Read Model: The primary drawback of Event Sourcing is its inefficiency for queries. CQRS directly addresses this. The projections or materialized views that are a practical necessity in any event-sourced system are the perfect implementation for the query side. These read models are denormalized and specifically tailored to the needs of the application's queries, providing high-performance reads without impacting the write model.
While it is technically possible to implement Event Sourcing without CQRS (and vice versa), using them together creates a highly coherent and robust architecture. CQRS provides the formal architectural structure for the separation of concerns that a practical Event Sourcing implementation naturally requires to be performant. The event stream becomes the reliable mechanism for synchronizing the write model with the various read models, typically with eventual consistency.
Integration with Domain-Driven Design (DDD)
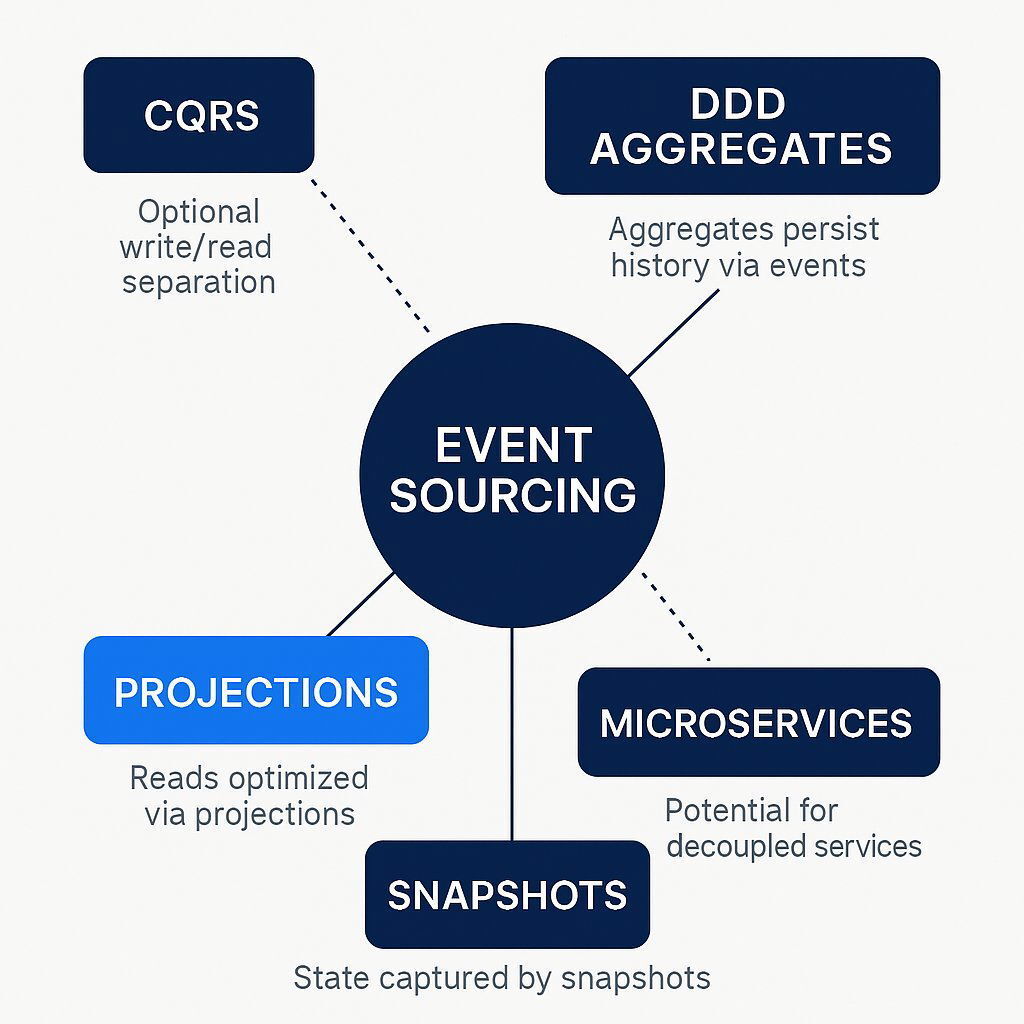
Event Sourcing is often described as a pattern stemming from Domain-Driven Design, and its principles align exceptionally well with DDD's tactical patterns.
- Persisting Aggregates: In DDD, an Aggregate is a cluster of domain objects that is treated as a single unit for the purpose of state changes, forming a transactional consistency boundary. Event Sourcing provides a natural and powerful persistence strategy for Aggregates. The state of an Aggregate at any point in time is the logical result of the sequence of business operations performed on it. These operations map perfectly to a stream of events, allowing the entire lifecycle of an Aggregate to be captured with high fidelity.
The Critical Distinction: Event Sourcing Events vs. Domain Events
A crucial and often misunderstood nuance when combining Event Sourcing and DDD is the distinction between two types of "events."
- Event Sourcing Events (Internal Persistence Events): These are the fine-grained events used for the sole purpose of persisting and reconstructing an Aggregate's internal state. Examples might include
CustomerNameChanged,ShippingAddressLine1Updated, orItemQuantityIncremented. These events are an implementation detail of how the Aggregate is persisted. They are internal to the Aggregate's bounded context and should not be exposed to the outside world. - Domain Events (External Notification Events): These are higher-level, semantically rich events that represent a significant business occurrence that other parts of the system or other Bounded Contexts need to be aware of. Examples include
OrderShipped,CustomerBecamePreferred, orPaymentProcessed. These events are part of the Aggregate's public API and are designed for integration and communication between different parts of the domain.
The pitfall to avoid is conflating these two. Using internal Event Sourcing events as public Domain Events is a serious architectural error. It breaks the encapsulation of the Aggregate by leaking its internal state-change mechanisms to external consumers. This creates a tight coupling where any refactoring of the Aggregate's internal logic could break downstream services that are listening to its low-level persistence events. The correct pattern is for an Aggregate, upon reaching a significant business state (e.g., after processing a command that completes an order), to explicitly generate and publish a distinct, high-level Domain Event that communicates the business fact, not the underlying state change.
Event Sourcing as a Backbone for Microservices
In a microservices architecture, Event Sourcing provides a powerful foundation for enabling service autonomy and resilient communication.
- Enabling Loose Coupling: Instead of services making synchronous, direct calls to each other (which creates temporal coupling and reduces resilience), they can communicate asynchronously through events. A service can publish events representing its state changes to a durable message bus (such as Apache Kafka). Other services can then subscribe to these event streams and react to them, building their own local data projections tailored to their specific needs. This decouples the services, allowing them to be developed, deployed, and scaled independently.
- Improving Resilience and Data Consistency: This event-driven approach enhances system resilience. If a consuming service is offline, it does not cause a failure in the producing service. When the consumer comes back online, it can simply resume processing events from the log where it left off, eventually catching up to the current state. To solve the challenge of ensuring that a database update and an event publication happen atomically (the "dual-write problem"), patterns like the Transactional Outbox are used. This pattern involves writing the event to a dedicated "outbox" table within the same local database transaction as the state change. A separate process then reliably relays events from this outbox to the message broker, guaranteeing that an event is published if and only if the corresponding state change was successfully committed.
The combination of DDD, CQRS, and Event Sourcing is more than just a collection of related patterns; it forms a coherent architectural philosophy for building complex, domain-centric systems. DDD provides the strategic and tactical tools to model the business domain. Event Sourcing offers an ideal mechanism for persisting the history of the domain's Aggregates. CQRS supplies the architectural framework to interact with that persisted history efficiently at scale. When applied correctly, this synergy allows for the creation of systems that are not only scalable and resilient but also deeply aligned with the business processes they are meant to support.
Strategic Application: Use Cases and Decision Framework
Event Sourcing is a powerful but specialized pattern. Its successful application depends on a clear understanding of the problem domains where its benefits outweigh its considerable complexity. This final section provides actionable guidance on ideal use cases, scenarios where it should be avoided, and a strategic framework to aid architects in their decision-making process.
When Event Sourcing Excels: Ideal Use Cases
Event Sourcing is most effective in systems where the history, context, and intent of changes are as important, or even more important, than the current state itself.
- Complex Domains with Long-Lived Processes: The pattern is exceptionally well-suited for modeling complex business workflows that unfold over time. Examples include insurance claims processing, order fulfillment systems, supply chain logistics, and contract negotiation, where understanding the sequence of steps is critical for both operation and analysis.
- Financial and E-commerce Systems: The intrinsic need for a perfect, immutable audit trail makes Event Sourcing a natural choice for banking, trading platforms, and payment processing systems. The classic e-commerce example of tracking the complete lifecycle of an order—from creation, to item addition, to payment, to shipment, to delivery—is a prime use case.
- Compliance-Driven Industries: Any domain with strict regulatory or legal requirements for data traceability benefits immensely from Event Sourcing. This includes healthcare, where maintaining a complete history of patient records is vital, and government applications that require transparent and auditable processes.
- Collaborative and Multi-User Systems: Applications that involve multiple users making concurrent changes to a shared state are fundamentally event-driven. Version control systems like Git are a canonical example of Event Sourcing in practice. Other examples include collaborative document editors, project management tools, and multiplayer games, where tracking and resolving the sequence of user actions is essential.
- Systems Requiring Undo/Redo/Replay Functionality: The event log provides the complete history necessary to implement features like "undo" and "redo" naturally. A state can be rewound by reversing events or replaying the log up to a specific point.
When Event Sourcing is Overkill or an Anti-Pattern
Despite its power, applying Event Sourcing indiscriminately leads to over-engineering and unnecessary complexity. It is an anti-pattern in scenarios where its core benefits provide no tangible value.
- Simple CRUD Applications: For straightforward applications like a basic blog, a personal to-do list, or a simple content management system (CMS), the overhead of implementing Event Sourcing is not justified. A traditional CRUD model is simpler, faster to develop, and perfectly adequate for the task.
- Systems Focused on Static or Reference Data: If the data in a system rarely changes, there is no meaningful history to capture. Using Event Sourcing for a product catalog, a list of countries, or other static reference data would be wasteful and add needless complexity.
- Read-Heavy Analytical Systems (OLAP): While an event stream can be an excellent source for a data warehouse or analytics platform, the event log itself is not an efficient data structure for performing complex, ad-hoc analytical queries (OLAP). These systems perform best when querying against denormalized, pre-aggregated data structures, which can be built as projections from an event stream but should not be the event stream itself.
- Systems Requiring Low-Latency, Strongly Consistent Reads: The Event Sourcing and CQRS patterns typically rely on eventual consistency for read models. If the business requirements strictly forbid any delay between a write and its visibility in all subsequent reads, and the system cannot be designed to accommodate this latency, then the pattern may be unsuitable.
A Decision-Making Framework for Architects
To make a sound architectural decision, the choice to use Event Sourcing should be driven by clear business and technical requirements, not by architectural trends. An architect should consider the following strategic questions:
- Is the history of state changes a first-class business requirement? Is the narrative of "how we got here" as important as the snapshot of "where we are"? If the journey of the data is central to the domain, Event Sourcing is a strong candidate.
- Do you have strict audit or compliance requirements that demand an immutable log of all actions? If the answer is yes, Event Sourcing provides this capability intrinsically, rather than as an add-on.
- Is the domain logic complex, involving long-running business processes, state machines, or collaborative workflows? These are the types of problems that Event Sourcing excels at modeling.
- Can your application, and more importantly, its users, tolerate eventual consistency for read operations? If the system cannot be designed to handle a potential delay between writes and reads, the standard ES/CQRS implementation may not be appropriate.
- Does your development team have the expertise and appetite to manage the significant increase in complexity? Adopting Event Sourcing requires a commitment to managing event versioning, projection logic, and the nuances of a distributed, event-driven architecture.
- Could a simpler hybrid approach satisfy the requirements with less complexity? Before committing to a full Event Sourcing implementation, evaluate whether a simpler pattern, such as a traditional CRUD model with a separate audit log, could meet the core business needs with a lower implementation and maintenance cost.
In conclusion, Event Sourcing is a potent but highly specialized architectural pattern. It should not be a default choice. However, when applied thoughtfully to the right problem domain—one where history, auditability, and complex temporal logic are paramount—it can provide unparalleled benefits in resilience, business insight, and architectural clarity, forming the foundation of a robust and evolvable system that stands ready for the demands of tomorrow’s data-driven world. For more on optimizing event-driven and distributed architectures, explore data engineering and analytics integration strategies with Databricks, which can further empower scalable, real-time decision-making.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.