
Transforming Data Entry: How to Eliminate Errors and Maximize Efficiency
June 20, 2025 / Bryan Reynolds
Inefficient data entry processes represent a significant yet often underestimated drain on organizational resources. These inefficiencies manifest not only as direct financial costs but also as operational disruptions, compromised decision-making, reputational damage, and compliance vulnerabilities. Addressing these challenges is paramount for any organization seeking to enhance productivity, ensure data integrity, and maintain a competitive edge. This report provides an expert analysis of how to identify, diagnose, and rectify inefficient data entry processes, offering a structured approach to transforming this critical business function.
I. Understanding and Diagnosing Inefficient Data Entry Processes
Before solutions can be effectively implemented, a thorough understanding of the problem's scope and nature is essential. Inefficient data entry is more than a minor inconvenience; it is a systemic issue with far-reaching consequences. Recognizing its symptoms and diagnosing its root causes are the foundational steps toward meaningful improvement.
A. The Pervasive Costs of Inefficient Data Entry
The ramifications of suboptimal data entry practices extend throughout an organization, creating a cascade of negative impacts. These costs are not always immediately obvious but accumulate to significantly hinder business performance.
- Direct Financial Losses: The most tangible consequence is the direct financial burden. Inefficient data entry inflates operational costs, primarily through increased labor for manual data input, verification, and correction of errors. Industry analyses underscore the severity of this issue, with Gartner estimating that bad data costs organizations an average of $12.9 million annually. These are not abstract figures; they represent real expenditures, such as wasted marketing spend, where advertisers are reported to lose as much as 21% of their media budgets due to poor data quality.
- Operational Disruptions & Lost Productivity: Errors and inefficiencies inherent in flawed data entry processes disrupt the smooth flow of operations. This leads to delays, process bottlenecks, and a considerable amount of employee time being diverted to menial tasks like correcting data errors or reconciling inconsistent entries. Such diversions directly erode productivity, as staff are occupied with rectifying mistakes rather than engaging in activities that add value to the business. For example, manual processes for importing data from PDF documents can consume several hours each day solely for corrections.
- Compromised Decision-Making: Businesses fundamentally rely on accurate data for strategic planning, operational adjustments, and forecasting. When data is "bad"-characterized by inaccuracies, incompleteness, inconsistencies, or irrelevance -it leads to flawed analyses. These flawed analyses, in turn, result in misguided business decisions, erroneous forecasts, and ultimately, missed strategic opportunities.
- Reputational Damage & Reduced Customer Trust: The impact of inaccurate data, particularly concerning customer information, can be severe. Errors can lead to frustrated customers due to misdirected marketing communications, delays in service response, incorrect billing, or flawed product deliveries. These negative experiences steadily erode customer trust and loyalty, potentially culminating in customer attrition. Indeed, reports suggest that nearly 78% of customers might abandon a transaction or relationship due to a poor experience, which is frequently linked back to data errors.
- Compliance Risks: Poor data quality is not just an internal problem; it can lead to non-compliance with crucial data security, privacy, and industry-specific regulations, such as GDPR or HIPAA. Such failures can result in substantial fines and damaging legal repercussions.
In today's interconnected business environments, data rarely stays within a single system. Information flows between Customer Relationship Management (CRM) systems, Enterprise Resource Planning (ERP) platforms, financial software, and various other operational tools. An error introduced during the initial data entry phase in one system typically does not remain isolated. Instead, it propagates through these interconnected pathways, corrupting datasets in downstream systems. For instance, an incorrect customer address entered into a CRM due to a typographical error can trigger a sequence of problems: failed deliveries recorded in the logistics system, incorrect invoices generated by the accounting system, and misdirected campaigns launched from the marketing automation platform. Consequently, the true cost of a single data entry error often far exceeds the immediate expense of its correction. It initiates a cascade of issues requiring rectification efforts across multiple departments and systems, amplifying the overall financial and operational burden. This interconnectedness means that investments aimed at preventing errors at the initial point of entry offer a disproportionately high return, as they preempt these amplified downstream costs and disruptions.
B. Hallmarks of Inefficient Data Entry (Recognizing the Symptoms)

Identifying inefficient data entry often begins with recognizing common error types and the broader symptoms of "bad data" they produce.
- Common Error Types:
- Transcription Errors: These occur when data is typed incorrectly, such as entering "john.doe@gmail.cmo" instead of the correct ".com".
- Transposition Errors: This involves the accidental swapping of characters or numbers, for example, recording a financial transaction as $91 instead of $19.
- Errors of Omission: These happen when data is entirely forgotten or left out, such as failing to record a significant expense like $20,000.
- Errors of Duplication: This refers to the same transaction, record, or piece of information being entered multiple times into the system.
- Inconsistent Formatting/Practices: Data quality suffers when there are varied abbreviations (e.g., "Street" versus "St." or "Str."), inconsistent date formats, or different naming conventions (e.g., "John Smith" in one record and "Smith, John" in another).
- Incomplete Data: Critical pieces of information are often missing, such as customer contact details, transaction records, or essential fields in a database.
- Misinterpretation Errors: These are particularly common with handwritten source documents, where misreading data can lead to skewed database integrity and flawed business intelligence.
- Signs of "Bad Data" Manifesting from Inefficient Entry: The presence of the error types above often leads to broader indicators of systemic data quality issues:
- Missing Important Information: Crucial data points required for operations or analysis are consistently absent from records.
- Excessive Time on Menial Tasks: A significant portion of staff time is consumed by correcting data errors or reconciling inconsistent data entries, reducing overall productivity.
- Lack of Actionable Insights: The quality of the data is so compromised that it becomes impossible to derive meaningful insights for effective decision-making.
- Difficulty in Data Analysis & Frequent Errors: High error rates in data lead to a lack of trust in its reliability and significantly complicate any attempts at data analysis.
- Delayed Insights: Delays in processing data, often due to the need for extensive cleaning and correction, affect the timeliness of insights and strategic planning.
To provide a consolidated diagnostic view, Table 1 outlines common data entry errors, their typical causes, visible characteristics, and resulting business impacts. This can help organizations quickly identify prevalent issues and understand their origins and consequences, paving the way for targeted solutions.
Table 1: Common Causes, Characteristics, and Impacts of Inefficient Data Entry
| Error Type | Typical Causes | Visible Characteristics | Business Impacts |
|---|---|---|---|
| Transcription Errors | Human error (typos), fatigue, unclear source data | Misspellings (e.g., "gmail.cmo"), incorrect numbers | Communication failures, incorrect calculations, operational mistakes |
| Transposition Errors | Careless input, speed pressure, human error | Swapped digits/characters (e.g., $91 vs. $19) | Financial inaccuracies, reporting errors, systemic delays |
| Errors of Omission | Oversight, unclear forms, distraction | Missing fields, incomplete records, gaps in data sequences | Incomplete analysis, understated/overstated accounts, poor decision-making |
| Errors of Duplication | Manual entry mistakes, system glitches, lack of checks | Identical or near-identical records/transactions appearing multiple times | Wasted resources, confusion, inaccurate reporting, inflated storage costs, duplicated efforts |
| Inconsistent Formatting/Practices | Lack of standards, varied training, individual habits | Different abbreviations (St/Str/Street), date formats (MM/DD/YY vs. DD/MM/YYYY), name orders | Difficulty in data aggregation and analysis, inaccurate segmentation, confusion |
| Incomplete Data | Poor form design, user oversight, unclear requirements | Required fields left blank, missing contact details or transaction components | Hindered analysis, inability to complete processes, poor customer service |
| Misinterpretation Errors | Illegible handwriting, ambiguous source documents | Data entered does not match source intent, skewed values | Flawed business intelligence, incorrect decisions, financial or reputational setbacks |
C. Uncovering Root Causes: A Structured Diagnostic Approach
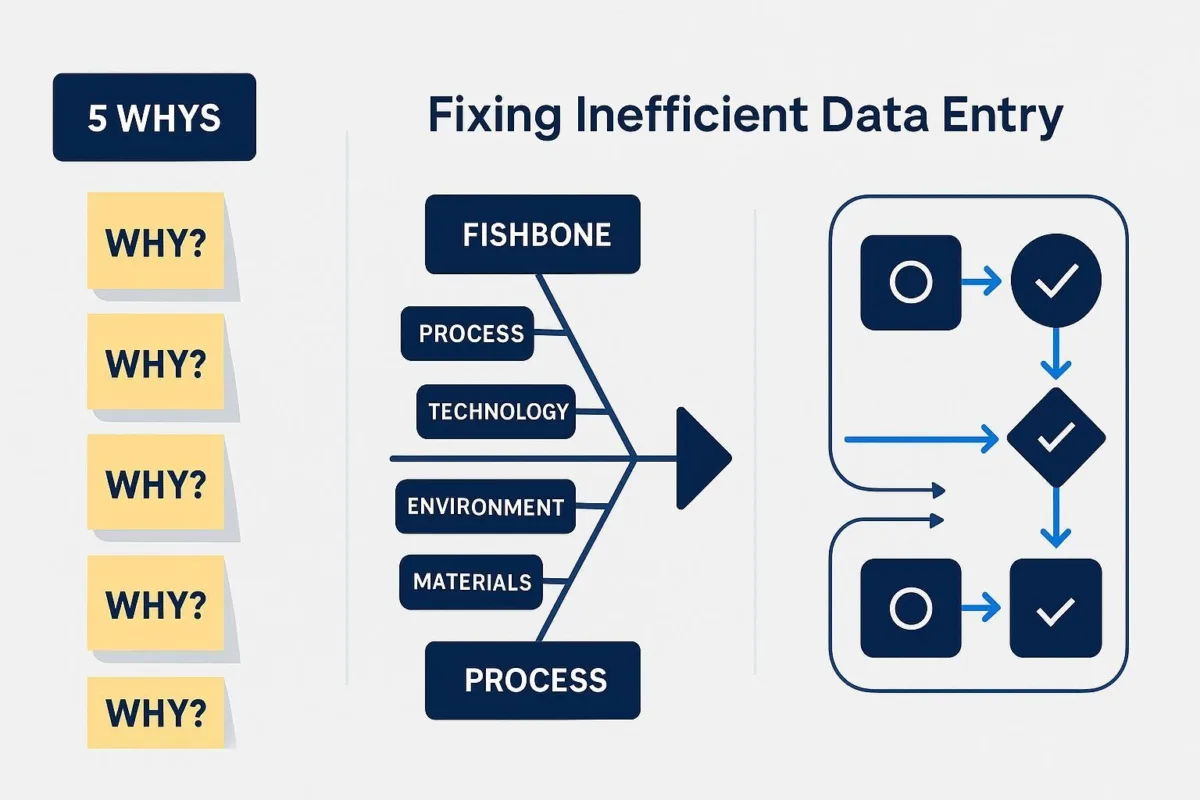
Data entry errors are frequently symptoms of deeper, systemic problems within an organization's processes, technology, or human factor management. To implement lasting fixes, it is crucial to move beyond addressing individual errors and identify these underlying root causes.
- Root Cause Analysis (RCA) Techniques: Several structured techniques can aid in this diagnostic process:
- The "5 Whys": This simple yet powerful iterative technique involves repeatedly asking "Why?" to explore the cause-and-effect relationships behind a problem until the fundamental cause is revealed. For example: Why was the data entered incorrectly? Because the operator was fatigued. Why was the operator fatigued? Because of an excessive workload due to staff shortages. Why were there staff shortages? And so on.
- Fishbone Diagram (Ishikawa Diagram): This visual tool helps in brainstorming and categorizing potential causes of a problem. Causes are typically grouped into main categories such as People (e.g., training, skill), Process (e.g., workflow, standards), Technology (e.g., software, hardware), Environment (e.g., workspace, distractions), and Materials (e.g., source documents), allowing for a comprehensive exploration of contributing factors to data entry errors.
- Process Mapping & Analysis: This involves creating a visual representation (e.g., flowchart) of the current data entry workflow. By mapping out each step, responsibility, and information flow, organizations can identify bottlenecks, redundancies, overly complex segments, or points where errors are likely to occur.
- Data Collection for Diagnosis: A thorough diagnosis relies on gathering relevant information from various sources:
- Analyzing Error Logs: System-generated error logs, if available, can provide valuable data on the types and frequencies of errors, highlighting patterns that may point to specific problematic areas.
- Reviewing Existing Documentation: Examining standard operating procedures (SOPs), training materials, and system manuals can reveal discrepancies between documented processes and actual practices, or identify gaps in guidance.
- Interviewing Staff: Engaging with frontline data entry personnel is critical. These individuals often possess the most practical understanding of daily challenges, system limitations, workflow pain points, and may have valuable suggestions for improvement.
- Direct Observation: Observing the data entry process in action can provide insights that documentation or interviews might miss, such as informal workarounds or environmental factors affecting performance.
- Common Root Cause Categories: Investigations into data entry inefficiencies typically reveal root causes falling into several key categories:
- Human Factors: These are significant contributors and include issues like operator fatigue, insufficient or inadequate training, the cognitive load of multitasking, poor ergonomic setups leading to discomfort, and a general lack of attention to detail. It's reported that human error rates average around 1% even in relatively simple data entry tasks, and can escalate to 5% or significantly higher in more complex scenarios, such as those involving detailed spreadsheet data entry. Repetitive work, a hallmark of many data entry roles, can lead to a "mental drop-off," where concentration wanes and consistency in applying standards diminishes.
- Process Deficiencies: Flaws in the design and management of data entry processes are common culprits. These include the absence of clearly defined and standardized procedures, ambiguous or conflicting guidelines, overly complex or illogical workflows, insufficient data validation steps embedded within the process, and a lack of robust quality control mechanisms to catch errors before they propagate.
- Technological Gaps: The tools used for data entry can themselves be a source of inefficiency. Outdated software with cumbersome interfaces, a lack of automation for highly repetitive tasks, poorly designed user interfaces that are not intuitive, and insufficient error-checking capabilities within existing systems all contribute to lower accuracy and speed.
- Data Source Issues: The quality and format of the source documents from which data is being entered play a crucial role. Illegible source documents, particularly those that are handwritten, and inconsistencies in the format of source materials can significantly increase the likelihood of errors during transcription.
Often, when data entry processes are inefficient or inherently error-prone, and these fundamental issues are not systematically addressed, personnel will develop workarounds and deviations from the prescribed ideal practices. These informal methods are usually adopted to cope with system limitations, unclear procedures, or intense deadline pressures. Over time, if these deviations are not corrected and become widespread, they can become ingrained in the organizational culture and accepted as "the standard way things are done," even if they are demonstrably suboptimal and contribute to a higher error rate. This phenomenon is akin to the "normalization of deviance," a concept observed in high-risk industries where repeated deviations from safety protocols, if they don't immediately result in catastrophe, can become accepted practice.
Therefore, effectively fixing inefficient data entry processes requires more than just correcting individual errors or implementing new software. It often necessitates a cultural shift to actively challenge and dismantle these normalized, suboptimal practices. Diagnostic efforts must diligently seek out these informal workarounds and understand the underlying reasons for their adoption, as these reasons frequently point to deeper systemic flaws in the official process or supporting technology. Simply imposing new rules or tools without addressing the root causes that led to the adoption of these old habits is likely to be met with resistance or result in only superficial compliance, ultimately failing to achieve lasting improvement. Understanding both the documented ("as-is") and the de facto ("actually-is") processes is crucial for successful intervention.
II. Strategic Pillars for Revitalizing Data Entry Operations
Transforming data entry from a liability into an efficient, accurate function requires a multi-faceted strategy. This involves a concerted focus on optimizing underlying processes and workflows, intelligently leveraging technology for automation and enhanced accuracy, and empowering the workforce by addressing critical human factors. Each of these pillars is essential for building a resilient and high-performing data entry operation.

A. Optimizing Processes and Workflows
The foundation of efficient data entry lies in well-designed, standardized, and user-centric processes.
1. Standardizing Data Formats, Input Procedures, and Source Documents
A lack of standardization is a primary driver of inconsistent data, the proliferation of duplicate entries, and an overall increase in errors. Implementing comprehensive standardization is crucial for ensuring that data is uniform and consistent across all systems. This uniformity improves data quality, significantly reduces errors, and enables seamless compatibility and integration between different datasets and applications.
Effective standardization involves several key actions:
- Defining Clear Guidelines and Naming Conventions: Organizations must establish and meticulously document clear, unambiguous, and enforceable rules for data formats. This includes specifying standard date formats (e.g., YYYY-MM-DD), consistent abbreviations (e.g., "St." for "Street," "Ave." for "Avenue"), and uniform naming conventions for files, fields, and data elements (e.g., consistently using snake_case like
customer_idor camelCase likecustomerId). Procedures for data entry and subsequent validation must also be clearly defined, including which fields are mandatory and cannot be left blank. - Standardizing Source Documents: Wherever feasible, standardizing the layout and format of physical source documents, such as intake forms or order sheets, can make the data extraction process significantly easier and more consistent, regardless of whether the extraction is performed manually or by automated tools like OCR. This can include using standardized codes and predefined categories for elements like assets, maintenance types, or product classifications.
- Developing a Data Dictionary: A critical component of standardization is the creation of a centralized data dictionary. This repository serves as the authoritative source defining standard formats, precise naming conventions, acceptable values and ranges for key data elements, and their meanings. It acts as an essential reference guide for all data entry personnel, system developers, and data analysts, ensuring everyone works from a common understanding.
- Implementation Strategy: The path to standardization should begin with mapping and evaluating all existing data entry points to identify current inconsistencies and areas of deviation. It is crucial to clean existing data before applying new standards to avoid perpetuating or legitimizing historical errors. Furthermore, these defined standards must be consistently applied and enforced across all teams, tools, and systems involved in the entire data pipeline to maintain integrity from collection to utilization.
2. Mapping and Re-engineering Data Entry Workflows to Eliminate Bottlenecks
Understanding and optimizing the flow of data entry work is critical to improving efficiency.
- Process Mapping as a Diagnostic Tool: The first step is to visually represent the current data entry workflow. Techniques such as flowcharts or swimlane diagrams are used to document the sequence of tasks, identify who is responsible for each activity, and trace the path of data from its source to its destination in the system. This visual map provides a clear overview of the existing process, making it easier to spot inefficiencies.
- Analyzing the Process Map: Once the map is created, it must be analyzed to pinpoint specific problems. This involves looking for areas where steps take an inordinate amount of time, where tasks tend to accumulate (bottlenecks), where there are an excessive number of approval steps causing delays, or where communication breakdowns occur between different stages or individuals. Gathering input from frontline teams-those directly involved in the workflows-is invaluable during this analysis, as they often have firsthand knowledge of practical issues and chokepoints.
- Applying Business Process Re-engineering (BPR) Principles: For more significant improvements, particularly where existing processes are deeply flawed, principles of BPR can be applied. This approach advocates for radical redesign rather than incremental tweaks, focusing on:
- Organizing work around outcomes rather than individual, fragmented tasks.
- Empowering those who use the output of a process to perform the process itself, where feasible, reducing handoffs.
- Integrating information-processing work directly into the real work that produces the information, rather than treating it as a separate, subsequent step.
- Systematically eliminating redundant steps, automating manual activities where appropriate, and streamlining the overall workflow to reduce complexity and improve speed.
- A Structured Approach to Workflow Re-engineering: A systematic methodology, adapted from established BPR frameworks , includes:
- Identify Processes for Re-engineering: Prioritize data entry workflows that exhibit significant performance gaps, have the greatest negative impact on business outcomes, or offer the highest potential return on investment from improvement.
- Analyze Current Processes: Thoroughly map the current "as-is" process flows and meticulously identify all bottlenecks, inefficiencies, and disconnects.
- Identify Improvement Opportunities: Brainstorm, analyze, and validate potential solutions and improvements to address the identified gaps and root causes. This includes considering automation, task consolidation, or simplification.
- Design Future State Processes: Based on the validated opportunities, create a new, optimized "to-be" workflow map that visualizes the improved process.
- Develop and Implement Changes: Operationalize the new workflows, procedures, and any associated technologies. This step is critical and requires clear communication, comprehensive training, and robust change management to ensure successful adoption.
- Checklist for Workflow Optimization: Key considerations when optimizing data entry workflows include :
- Clearly identifying all current inefficiencies and bottlenecks.
- Rationalizing tasks by consolidating or eliminating unnecessary steps.
- Implementing appropriate technology to automate processes and track progress.
- Measuring performance using defined Key Performance Indicators (KPIs).
- Standardizing processes to ensure consistency and reduce ambiguity.
- Providing regular training to keep staff proficient with new workflows and tools.
- Designing workflows that are flexible and can adapt to changing business requirements.
3. Designing User-Centric Data Entry Forms and Interfaces for Error Reduction

The design of the forms and system interfaces through which data is entered has a profound impact on accuracy and efficiency. Poorly designed interfaces can frustrate users and directly contribute to errors. If you want to create superior digital experiences that help users enter information quickly and accurately, it's essential to invest in user experience (UX) design that is grounded in practical best practices.
- Fundamental User Interface (UI) / User Experience (UX) Principles:
- Simplicity and Clarity: The most effective interfaces are straightforward and intuitive. Designs should avoid overly complex layouts, ambiguous icons, or confusing color schemes that can overwhelm the user. Labels for fields and instructions must be clear, concise, and easily understandable.
- Consistency: Maintaining consistency in design elements-such as colors, typography, button styles, and layout across all forms and screens-helps users learn the system faster, navigate more easily, and reduces cognitive load, leading to fewer errors.
- User-Centered Design: The primary focus of interface design should always be on the needs and preferences of the end-users. The system should be easy to use and navigate, requiring minimal effort to complete tasks correctly.
- Best Practices for Form Design :
- Logical Flow and Grouping: Fields should be arranged in a logical sequence that mirrors natural thought processes or the flow of source documents. Related fields should be visually grouped together using spacing or section dividers. For lengthy forms, consider breaking them down into multiple steps or screens, providing clear progress indicators to keep the user oriented.
- Clear Labeling: Place labels consistently, typically above their respective input fields, to enhance the visual association and improve scannability, especially on mobile devices. Use clear, unambiguous, jargon-free language for all labels and instructions.
- Appropriate Input Field Design: The physical size of an input field should visually suggest the expected length of the input (e.g., a field for a postcode should be shorter than one for a street address). Avoid splitting single pieces of information, like phone numbers or credit card numbers, into multiple separate input fields, as this can cause frustration and errors, especially for users who look at the keyboard while typing.
- Mandatory vs. Optional Fields: Clearly and visually distinguish mandatory fields from optional ones (e.g., using an asterisk or distinct color). Critically evaluate whether each field is truly necessary; removing non-essential fields helps keep forms concise and reduces user burden.
- Use of Appropriate Input Types: Instead of relying solely on free-text entry, utilize constrained input types like dropdown lists for selecting from predefined options, checkboxes for multiple selections, radio buttons for single selections from a mutually exclusive set, and dedicated date pickers. These guide users, reduce typing, and limit entries to valid options. On mobile devices, leverage native operating system features for special inputs like date pickers, as users will be more familiar with them.
- Error-Proofing Mechanisms (Mistake Proofing / Poka-Yoke) : These are design features intended to prevent errors from occurring or to make them immediately obvious:
- Real-Time Validation (Just-in-Time Validation): Provide instant feedback to the user as data is entered, or immediately after they move to the next field. This validation can check for correct format (e.g., email address structure), valid range (e.g., age between 18 and 99), or consistency with other entered data. However, avoid premature inline validation (i.e., showing an error message as soon as the user starts typing in a field), as this can be distracting and confusing.
- Input Masks: For fields requiring a specific format, such as phone numbers (e.g., (XXX) XXX-XXXX), credit card numbers, or postal codes, input masks guide the user and prevent incorrectly formatted entries.
- Dropdown Lists & Predefined Options: As mentioned, these restrict choices to a list of valid entries, eliminating typos and invalid inputs for those fields.
- Auto-Complete and Suggestions: Based on previous inputs or existing data within the system, auto-complete features can suggest or automatically fill in parts of an entry, saving time and preventing common spelling or entry errors.
- Conditional Formatting: Use visual cues like color-coding for dropdown selections or highlighting entries that meet certain criteria. This can aid quick comprehension and flag potential issues or required actions directly on the form.
- Forgiving Formats: For certain types of data where users might naturally use variations (e.g., phone numbers entered with or without spaces/hyphens, different common date separators like '/' or '-'), the system can be designed to accept these variations and normalize them upon submission.
- Pre-populating Fields: Where information is already known or can be reliably inferred (e.g., defaulting the country based on IP address, filling in user details if logged in), pre-populate fields to reduce manual typing and the associated risk of errors.
- Helpful and Clear Error Messages: When an error does occur and is detected, the system must provide meaningful, jargon-free error messages. These messages should clearly explain what has gone wrong and provide specific guidance on how to correct the issue, ideally by visually highlighting the field(s) in error.
The efforts to standardize data and design user-friendly forms are not independent; they are deeply intertwined. Effective form design is heavily reliant on the existence of pre-defined data standards. For instance, to implement a dropdown list effectively-a key form design element for error reduction -an organization must first establish a standardized list of acceptable values for that field. Similarly, applying real-time validation to a date field, which provides immediate feedback to the user , necessitates a clearly defined standard date format (e.g., YYYY-MM-DD, as suggested in ). Input masks, which guide users in entering formatted data like phone numbers , are rendered ineffective if no standard format has been agreed upon.
Consequently, attempting to improve data entry forms without concurrently establishing, or having already established, clear data standards will yield significantly diminished results. The standards provide the fundamental "rules" that the form design then aims to enforce and facilitate for the user. This implies that process optimization initiatives focused on data standardization should ideally precede, or at least be tightly integrated with, any UI/UX redesign projects to achieve maximum impact. A poorly designed form can undermine even the most robust data standards by making it difficult or confusing for users to comply. Conversely, even the most intuitively designed form cannot guarantee data quality if the underlying standards for what constitutes "good data" are ambiguous, inconsistent, or altogether non-existent. Thus, investing in one aspect while neglecting the other leads to a suboptimal outcome, highlighting the necessity of a coordinated approach.
B. Leveraging Technology for Automation and Enhanced Accuracy
Technology offers powerful tools to automate repetitive data entry tasks, extract information from various sources, and enhance the accuracy of captured data. In today's landscape, AI-enabled development is becoming increasingly prominent, transforming how we approach automation and accuracy in data entry.
1. Automated Data Capture: Optical Character Recognition (OCR), Intelligent Character Recognition (ICR), and Barcode/QR Scanners
Automated data capture technologies are pivotal in reducing manual data entry from physical or image-based documents.
- Optical Character Recognition (OCR): OCR technology is designed to convert scanned documents and images containing printed text into machine-readable, editable digital formats. Its primary benefit is the significant reduction in manual typing, which translates directly into time and cost savings for businesses. Modern OCR systems can achieve very high accuracy rates, often between 99.5% and 99.99% for specific, well-defined tasks such as extracting data from bank statements. However, OCR performs best with structured, clean documents that have standard layouts and clear, printed text. Its limitations become apparent when dealing with handwritten text, complex or inconsistent layouts, and documents of poor quality (e.g., faded, skewed, or low-resolution images).
- Intelligent Character Recognition (ICR): ICR represents an advancement over traditional OCR, specifically engineered to recognize and interpret handwritten text. It can identify various handwriting styles and fonts, making it suitable for processing data from handwritten forms and documents. ICR systems typically employ neural networks and machine learning algorithms, enabling them to "learn" from the data they process and improve their recognition accuracy over time. While ICR is significantly more accurate than OCR for handwritten content (achieving up to 97% accuracy in some cases), it generally cannot read cursive handwriting (for which Intelligent Word Recognition, or IWR, is often required). Due to its more advanced capabilities, ICR solutions usually involve a higher implementation cost compared to basic OCR.
- Barcode and QR Code Scanners: These devices provide an extremely fast, highly accurate, and cost-effective method for capturing data from items that are tracked using barcodes or QR codes. They are extensively used across various industries, including retail (for product identification and point-of-sale), logistics (for tracking shipments and inventory), manufacturing (for parts and component tracking), and healthcare (for patient identification and medication administration). The use of scanners dramatically reduces manual entry errors for any data that can be encoded in these formats. Zebra and Cognex are notable providers of such scanning technologies, offering a range of devices from handheld to fixed-mount scanners capable of reading damaged or poorly printed codes.
The overarching benefits of implementing these automated capture technologies include substantially increased speed and operational efficiency, a marked reduction in human error rates, significant cost savings through reduced labor requirements, enhanced data security by minimizing manual handling of sensitive information, and improved scalability to handle growing data volumes.
2. Robotic Process Automation (RPA) in Data Entry
RPA offers a powerful way to automate structured, repetitive data entry tasks that involve interaction with digital systems.
- What is RPA?: Robotic Process Automation utilizes software "robots" or "bots" that are programmed to mimic human actions when interacting with digital systems and software applications. These bots can perform a wide array of repetitive, rule-based office tasks, such as extracting data from one source, filling in electronic forms, moving files between folders or applications, and interacting with existing enterprise applications through their user interfaces (UIs) or Application Programming Interfaces (APIs).
- How RPA Works for Data Entry: In the context of data entry, RPA bots can be configured to perform a sequence of actions that a human operator would typically undertake. This includes logging into various systems, opening emails and their attachments, scraping data from screens or documents (often in conjunction with OCR/ICR technologies for data extraction from images or PDFs), inputting this extracted data into forms, spreadsheets, or databases, validating the entered data against predefined rules or lookup tables, and transferring data between different, often disparate, software systems.
- Use Cases for RPA in Data Entry: RPA is highly versatile and finds application in numerous data entry-intensive processes across various departments and industries. Common use cases include:
- Customer onboarding (automating form filling and system updates).
- Extracting data from PDFs and scanned documents (e.g., invoices, purchase orders).
- Performing routine data updates in CRM or ERP systems.
- Validating data by cross-checking against external public databases or internal master data.
- Automating the preparation and dissemination of periodic reports.
- Streamlining accounts payable and accounts receivable processes (e.g., invoice processing, payment posting).
- Processing insurance claims or healthcare patient records.
- Managing inventory data and updates.
- Benefits of RPA: The implementation of RPA for data entry tasks can yield substantial benefits:
- Significant Time Savings: Tasks that might take humans minutes or even hours can often be completed by bots in seconds, drastically reducing processing times.
- Increased Accuracy: By automating rule-based tasks, RPA minimizes the human errors typically associated with manual data entry, such as typos or omissions.
- 24/7 Operational Feasibility: RPA bots can operate continuously, around the clock, without breaks or fatigue, enabling businesses to process data outside of normal working hours.
- Scalability: RPA solutions can be easily scaled up or down to handle fluctuating data volumes without requiring proportional increases in human staff.
- Improved Employee Morale: Automating tedious and repetitive data entry tasks frees up human employees to focus on more engaging, complex, and higher-value work, which can lead to increased job satisfaction.
- Enhanced Data Security: RPA can be configured to handle sensitive data according to strict protocols, potentially reducing the risks associated with manual data handling.
- RPA in Comparison to Other Automation: It's useful to distinguish RPA from other automation concepts. RPA is primarily process-driven and excels at automating tasks that follow predefined rules and interact with existing system interfaces, making it particularly useful for integrating legacy systems that may lack modern APIs. Artificial Intelligence (AI), on the other hand, is data-driven and involves systems that can learn from data and make more complex decisions. While data entry automation can be a specific component or outcome of an RPA implementation, RPA itself has a broader scope, capable of automating entire end-to-end workflows that may include multiple data entry steps among other actions.
3. AI-Powered Data Extraction, Validation, and Intelligent Automation

Artificial Intelligence (AI) and Machine Learning (ML) are taking data entry automation beyond the capabilities of basic OCR and rule-based RPA, enabling systems to "learn," "understand," and adapt. Businesses who want to stay ahead should get familiar with the AI toolkit landscape and how these technologies are evolving across industries.
- AI Enhancements Beyond Basic Automation:
- Intelligent Document Processing (IDP): IDP solutions represent a significant leap forward from traditional OCR/ICR. They combine these character recognition technologies with AI and ML algorithms to extract data from a wide variety of document types, including complex, unstructured, or semi-structured documents like invoices, contracts, emails, and forms, with much greater accuracy and contextual understanding. IDP systems are adept at handling variations in document layouts and can learn and improve their extraction capabilities over time as they process more documents.
- AI-Powered Data Validation: AI goes beyond simple rule-based validation (e.g., checking if a field is numeric). AI agents can automatically detect a broader range of errors, including subtle inconsistencies, missing values that require contextual understanding, incorrect formats that deviate from learned patterns, and anomalous data points. Some advanced AI systems can even suggest or automatically apply corrections.
- Natural Language Processing (NLP): NLP, a subfield of AI, enables systems to understand the meaning, sentiment, and context of human language, both written and spoken. In data entry, NLP is invaluable for improving the accuracy of data extraction from narrative documents, customer emails, survey responses, or other text-heavy sources where simple keyword spotting is insufficient.
- Predictive Data Entry and Auto-Correction: AI models can be trained on historical data to predict likely entries as a user types or to suggest corrections for common errors based on learned patterns, further speeding up input and improving accuracy.
- AI Data Extraction Platforms: A growing market of sophisticated platforms leverages AI for data extraction and integration. Tools such as Airbyte, Fivetran, Talend, Import.io, Hevo Data, Octoparse, and Infrrd provide capabilities to extract data from diverse sources including APIs, databases, websites, and complex documents. These platforms often employ AI/ML for intelligent data recognition, extraction, transformation, and loading (ETL/ELT) processes. Infrrd, for example, explicitly states its use of NLP, ML, and Generative AI to achieve high precision in extracting data from even challenging sources like complex images and engineering diagrams.
- Benefits of AI-Driven Solutions: The integration of AI into data entry and extraction processes offers several advantages over more basic automation methods:
- Higher Accuracy: AI models, especially those that learn and adapt, can often achieve superior accuracy in data extraction and validation, particularly with complex or variable data.
- Handling Complex and Unstructured Data: AI, particularly IDP and NLP, excels at processing data that does not conform to rigid structures, which is a significant limitation for traditional OCR and rule-based RPA.
- Continuous Improvement: ML-based systems have the inherent ability to learn from new data and user corrections, leading to continuous improvement in their performance over time.
- Improved Overall Data Quality: By catching more errors and extracting data more accurately from a wider range of sources, AI contributes to higher overall data quality within the organization.
- Enhanced Decision-Making: Better quality data, available more quickly, supports more informed and reliable business decisions.
4. Utilizing Specialized Software (e.g., Accounting, Data Validation Tools)
Beyond broad automation platforms, specialized software designed for specific functions or tasks often incorporates features that significantly aid in reducing manual data entry and improving accuracy.
- Accounting Software: Modern accounting systems are increasingly equipped with features aimed at minimizing manual data entry and its associated errors. These can include:
- Automatic Bank Transaction Imports: Directly importing transaction data from bank and credit card feeds eliminates the need to manually key in this information.
- AI-Powered Suggestions: Some systems use AI to analyze imported transactions and suggest appropriate expense accounts or categorizations, reducing guesswork and potential misclassification.
- Streamlined Account Reconciliation: Tools that facilitate the comparison of internal records with bank statements make it easier and faster to identify discrepancies, which can often stem from data entry errors.
- Data Validation Software & Techniques: Ensuring data quality at the point of entry or during processing is critical, and various tools and techniques support this:
- Dedicated Data Validation Tools: A range of commercial and open-source tools specialize in data validation. Examples include Pydantic (for Python-based schema validation), Great Expectations (for data pipeline validation), Deequ (for big data validation on Spark), Informatica Data Quality, and newer AI-driven tools like Numerous.ai (specifically for spreadsheet validation) and ArtificioAI (for data governance and validation). These tools offer capabilities such as:
- Schema validation (ensuring data structure is correct).
- Format checks (e.g., valid email, date format).
- Range checks (e.g., value within a specified minimum and maximum).
- Data type validation (e.g., ensuring a field contains a number, not text).
- Duplicate detection and flagging.
- Automated error correction for common issues.
- Built-in Validation in Applications: Many business applications (CRMs, ERPs, custom-built systems) allow administrators or developers to configure validation rules directly within the application forms or data import processes.
- Validation Techniques: These can be broadly categorized:
- Field-Level Validation: Checks applied to individual data fields (e.g., format, range, type, mandatory field).
- Cross-Field Validation: Checks that ensure consistency between multiple fields within the same record (e.g., ensuring a "date of birth" is before a "date of enrollment").
- Real-Time vs. Batch Validation: Real-time validation checks data as it is being entered, providing immediate feedback. Batch validation processes data in bulk, typically after it has been collected, to identify errors.
- Methodological Validation: Certain accounting practices, like double-entry accounting, inherently serve as a validation method by requiring that debits and credits balance, which can help in spotting certain types of data entry errors.
- Dedicated Data Validation Tools: A range of commercial and open-source tools specialize in data validation. Examples include Pydantic (for Python-based schema validation), Great Expectations (for data pipeline validation), Deequ (for big data validation on Spark), Informatica Data Quality, and newer AI-driven tools like Numerous.ai (specifically for spreadsheet validation) and ArtificioAI (for data governance and validation). These tools offer capabilities such as:
Table 2: Comparative Overview of Data Entry Automation Technologies
| Feature | Manual Entry | OCR (Optical Character Recognition) | ICR (Intelligent Character Recognition) | RPA (Robotic Process Automation) | AI-Powered IDP/Validation |
|---|---|---|---|---|---|
| Primary Use Case | Low-volume, varied tasks; human judgment needed | Digitizing printed, structured documents | Digitizing handwritten, structured forms | Automating repetitive, rule-based digital tasks | Extracting/validating complex, unstructured data |
| Typical Accuracy | Low to Moderate (95-99% before verification, error rate up to 4%) | High for clean printed text (99%+) ; Lower for poor quality/handwriting | Moderate to High for clear handwriting (up to 97%) ; Not for cursive | High for defined rules; dependent on underlying data quality | Very High, improves with learning (99%+) |
| Initial Investment | Low (labor costs are ongoing) | Moderate (software, scanner) | Higher than OCR (specialized software) | Moderate to High (software, development) | High (advanced software, expertise) |
| Implementation Complexity | Low | Low to Moderate | Moderate | Moderate to High | High |
| Scalability | Low (requires more staff) | High | High | Very High | Very High |
| Handles Unstructured Data? | Yes (human interpretation) | Limited (best with structured) | Limited (best with structured forms) | Limited (can interact with systems handling it) | Yes, excels with unstructured/semi-structured |
| Key Benefits | Flexibility, nuanced data capture | Speed, cost reduction for printed docs | Handles handwriting, reduces manual input | Automates cross-system tasks, 24/7 operation | Highest accuracy, handles complexity, learns |
| Key Limitations | Slow, error-prone, high ongoing cost | Poor with handwriting/low quality docs | Higher cost, no cursive, needs clear writing | Requires stable processes, can be brittle to UI changes | Highest cost, requires significant data/expertise |
The journey towards automating data entry processes often follows a progression, reflecting an "automation spectrum." Not every inefficiency demands the immediate deployment of the most sophisticated and potentially costly AI solution. Organizations can strategically begin with simpler, more targeted automation initiatives. For example, implementing OCR for specific, high-volume, structured document types or using RPA for well-defined, stable, and highly repetitive digital tasks can provide quick wins and demonstrate a clear return on investment. This aligns with a phased implementation approach, where solutions are tested on a small scale, refined, and then expanded.
Such initial successes serve multiple purposes: they build internal confidence in automation, generate tangible savings and efficiencies that can fund further initiatives, and allow the organization to develop in-house expertise and experience with automation technologies. As needs evolve and the value of automation becomes more apparent, businesses can then progress towards more intelligent solutions like IDP or comprehensive AI-driven validation for more complex data challenges. This phased approach mitigates the risk of over-investing in highly complex solutions before foundational process issues are adequately addressed or before the organization is culturally and technically ready to absorb them. It transforms data entry automation from a potentially daunting, monolithic project into a manageable and evolving journey along a spectrum of technological sophistication.
C. Empowering the Workforce and Addressing Human Factors
Even with advanced automation, the human element remains crucial in data entry, whether for tasks not yet automated, for managing exceptions, or for overseeing automated systems. Therefore, addressing human factors through training, ergonomic design, and strategies to minimize error is essential.
1. The Critical Role of Comprehensive Training and Skill Development
The proficiency of data entry personnel directly impacts data quality and operational efficiency. A lack of adequate training is a significant and direct contributor to data entry errors. Staff who are not properly trained may not fully understand required data formats, the functionalities of the systems they use, or, critically, the broader business impact of accuracy in their work. For organizations looking to future-proof their teams, investing in AI and digital literacy training can be a game-changer, especially as automation tools and intelligent systems become more integral to daily workflows.
Comprehensive training programs should cover a range of essential areas:
- Basic Data Entry Skills: This includes mastering keyboard shortcuts to improve speed and reduce reliance on mouse-driven navigation, as well as practicing typing techniques designed to enhance both speed and accuracy.
- Understanding Data Standards & Guidelines: Thorough instruction on the organization's established data standards is vital. This encompasses correct data formats for various fields (dates, numbers, codes), lists of acceptable values, defined input procedures, and any specific naming conventions.
- Software Proficiency: Staff must be proficient in using all software relevant to their roles. This includes specific data entry applications, accounting systems, CRM platforms, and any automation tools (like OCR interfaces or RPA dashboards) that they interact with.
- Error Detection & Prevention Techniques: Training should explicitly cover methods for detecting and preventing errors. This includes the importance of double-checking work, techniques for verifying data against source documents, understanding how system validation rules function, and processes for correcting identified errors.
- Importance of Data Quality: A crucial, yet often overlooked, aspect of training is educating staff on the downstream impact of data entry errors on the entire business-from financial reporting to customer satisfaction and strategic decision-making. Understanding this context can significantly increase diligence.
- Industry-Specific Knowledge: Where applicable, training should be tailored to include knowledge of industry-specific data formats, terminologies, and regulatory compliance requirements (e.g., healthcare data privacy, financial reporting standards).
Training should not be a one-time event. Continuous learning and ongoing support are vital for maintaining high levels of accuracy and efficiency. Regular refresher training sessions, workshops on new tools or techniques, and readily available support channels help reinforce best practices and keep staff updated. Furthermore, professional certifications, such as the Certified Data Entry Specialist (CDES) or Microsoft Office Specialist (MOS) in tools like Excel, can provide formal validation of an individual's skills and proficiency. Numerous online courses and training programs are also available to supplement internal efforts.
2. Ergonomic Workstation Design for Peak Performance and Well-being

The physical environment in which data entry is performed significantly influences operator comfort, fatigue levels, and ultimately, their speed and accuracy. Poor ergonomics, characterized by fixed, constrained, or awkward postures, repetitive hand and wrist movements, and a consistently high work pace, are major contributors to musculoskeletal injuries (MSIs), chronic discomfort, fatigue, and a corresponding decline in data entry performance.
Key ergonomic principles for designing data entry workstations include :
- Chair: The chair should be fully adjustable, allowing the user to modify its height so their feet rest comfortably flat on the floor or a footrest. It must provide firm lumbar (lower back) support. Seat pan tilt and backrest angle should also be adjustable. Armrests, if provided, should be height-adjustable or removable to avoid interfering with natural arm movements during typing.
- Keyboard and Mouse Height: The keyboard and mouse should be positioned at a height that allows the user to sit with their shoulders relaxed, elbows bent at approximately a 90-degree angle, and forearms, wrists, and hands kept roughly parallel to the floor. Height-adjustable keyboard trays can be invaluable if the desk height is not optimal.
- Keyboard Angle and Type: The keyboard should be positioned to promote a neutral (flat) wrist posture, avoiding excessive bending up, down, or sideways. Ergonomic keyboards, which may feature a split design (allowing hands to be positioned shoulder-width apart) or tenting (angling the keyboard halves upwards like a tent), can significantly reduce strain by promoting a more natural hand and wrist position.
- Monitor Placement: The top of the computer display screen should be positioned at or slightly below the user's eye level when seated comfortably. For users who wear bifocal glasses, the screen may need to be positioned lower and possibly closer to avoid awkward neck postures.
- Desk Space: The desk should provide sufficient surface area to accommodate all necessary equipment (monitor, keyboard, mouse, document holder, phone) and allow for comfortable movement and changes in posture.
- Lighting: Adequate and appropriate lighting is crucial to avoid eye strain and minimize screen glare. Natural light is ideal, but if unavailable, good quality desk lamps should be used. The monitor should be positioned away from direct light sources (windows, bright overhead lights) to prevent reflections on the screen.
- Essential Accessories: Depending on individual needs and tasks, accessories such as document holders (adjustable to screen height for those typing from hard copies), footrests (if feet don't comfortably reach the floor), padded wrist rests (of the same height as the keyboard home row), and lightweight telephone headsets (for users who frequently use the phone while typing) should be provided.
Implementing good ergonomic practices yields significant benefits, including reduced operator fatigue, improved data entry accuracy, the potential for increased typing speed, and, most importantly, the prevention of debilitating long-term health issues such as carpal tunnel syndrome and other repetitive strain injuries.
3. Strategies to Minimize Human Error and Enhance Focus
Human error remains a persistent challenge in data entry, often stemming from factors like fatigue, pervasive distractions, excessive time pressure, and the inherently repetitive nature of many tasks, which can lead to a "mental drop-off" in concentration. Error rates attributable to human factors can range from 1-4% or even higher, depending on the complexity of the data and the volume of work.
Several strategies can be employed to mitigate these risks and enhance operator focus:
- Implementing Checks and Balances:
- Double-Checking and Proofreading: Encouraging or mandating that operators review their own work before submission is a basic but effective step.
- Double Key Entry Verification (Two-Pass Verification): This more robust method involves having two different individuals enter the same set of data independently. The system then compares the two entries, and any discrepancies are flagged for review and correction. This is particularly effective at catching random keystroke errors.
- Creating an Optimal Work Environment:
- Minimizing Distractions: The physical workspace should be designed to minimize common office distractions. This might involve designated quiet zones for data entry tasks or providing noise-canceling headphones, especially in open-plan offices.
- Managing Workload and Fatigue:
- Regular Breaks: Encouraging employees to take short, regular breaks away from their screens helps to combat fatigue, maintain focus, and reduce the likelihood of errors accumulating over long periods of continuous work. Techniques like the Pomodoro Technique (working in focused intervals separated by short breaks) can be beneficial.
- Task Management Strategies:
- Batching Similar Tasks: Grouping similar data entry tasks together (e.g., entering all customer names, then all addresses) can reduce the mental effort of context switching and improve consistency.
- Breaking Down Large Tasks: Dividing large volumes of data entry into smaller, more manageable segments can make the work feel less overwhelming and help maintain concentration.
- Alternating Task Focus: Where possible, alternating between high-concentration data entry tasks and lower-focus administrative tasks can help prevent mental fatigue and maintain engagement.
- Clear Guidance and Realistic Expectations:
- Providing Clear Instructions: Ensuring that all data entry personnel have access to precise, unambiguous guidelines and procedures for their tasks is fundamental.
- Setting Realistic Goals and Standards: Establishing achievable productivity and accuracy targets, without imposing undue time pressure that encourages rushing, is important for maintaining quality.
The efforts to improve data entry through training, ergonomic enhancements, and automation are not merely additive; they are deeply interdependent in creating a robust system that effectively mitigates human error. For example, comprehensive training on data standards and software use can be significantly undermined if poor ergonomics lead to operator fatigue and discomfort, which in turn increase error rates despite the operator's knowledge. Conversely, an ergonomically perfect workstation might not be utilized to its full potential if staff are not trained on proper posture, optimal keyboard techniques, or the effective use of ergonomic accessories.
Similarly, the introduction of automation tools like OCR or RPA necessitates retraining staff. Their roles may shift from manual data input to managing the automated systems, handling exceptions that the automation cannot process, performing quality control on automated output, and troubleshooting minor issues. Without this specific training, the expensive automation tools may be underutilized, misused, or errors in their output might go undetected, negating the intended benefits. Even with automation reducing the volume of manual typing, any remaining manual tasks, or new tasks involving interaction with automated systems (such as reviewing flagged exceptions or configuring bot parameters), still benefit immensely from good ergonomic design to ensure operator comfort and efficiency during these potentially prolonged periods of monitoring or focused interaction.
Therefore, a holistic strategy to minimize human error and maximize efficiency in data entry operations must address training, ergonomics, and automation in an integrated and coordinated manner. Investing heavily in one area while neglecting the others will likely yield limited or lopsided results. For instance, purchasing sophisticated automation software without adequately retraining staff for their new or modified roles, or without ensuring their workstations are ergonomically suited to these new tasks, will fail to maximize the return on investment or achieve the desired reduction in errors. The most resilient and efficient data entry systems are those that strategically leverage automation for repetitive and high-volume tasks, ensure that the remaining human workforce is exceptionally well-trained for their (potentially evolved) responsibilities, and provide an ergonomically sound and supportive work environment.
III. Evaluating, Implementing, and Justifying Improvement Initiatives
Successfully transforming data entry operations requires a structured approach to selecting appropriate solutions, rigorously evaluating their financial viability, planning for necessary resources, and executing implementation in a controlled manner.
A. A Framework for Selecting the Right Solutions (Process, Technology, People)
Choosing the most effective interventions demands a clear understanding of the specific problems at hand and the desired outcomes.
- Needs Assessment Revisited: The diagnostic findings from Section I are paramount. A clear articulation of the primary pain points (e.g., high error rates, slow processing, compliance issues), the most common error types (e.g., transcription, omission), and their identified root causes (e.g., lack of standards, outdated software, insufficient training) must guide solution selection.
- Prioritization of Issues: Not all inefficiencies carry the same weight. It's crucial to prioritize which problems to tackle first based on their impact on key business metrics such as cost, data quality, processing speed, customer satisfaction, or regulatory compliance. Addressing areas with the highest negative impact or the greatest potential for improvement often yields the most significant returns.
- Matching Solutions to Specific Problems: A tailored approach is more effective than a one-size-fits-all solution:
- If inefficiencies are primarily rooted in process deficiencies (e.g., inconsistent standards, convoluted workflows, poorly designed forms), the initial focus should be on process-oriented solutions like data standardization, workflow re-engineering, and user-centric form redesign.
- For tasks characterized by high volume, high repetition, and clear rules , Robotic Process Automation (RPA) is a strong candidate for automation.
- When data entry involves significant volumes of paper-based documents or images , Optical Character Recognition (OCR) for printed text or Intelligent Character Recognition (ICR) for handwritten text are key enabling technologies.
- If the challenge involves extracting data from complex, variable, or unstructured documents (e.g., contracts, detailed invoices, correspondence), more advanced AI-powered Intelligent Document Processing (IDP) solutions should be considered.
- Persistently high human error rates in manual tasks , despite existing processes, point towards the need for enhanced training programs, significant ergonomic improvements, better form design with embedded validation, and the deployment of specialized data validation tools.
- Considering Business Context:
- Business Size and Data Volume: The scale of the operation matters. Smaller businesses with limited data volumes and budgets may find lightweight, simpler solutions or manual process improvements sufficient, whereas large enterprises processing vast amounts of data will likely require more robust, scalable, and often automated platforms.
- Integration with Existing Systems: Any new technological solution must be evaluated for its ability to seamlessly integrate with the organization's current technology ecosystem, including databases, CRM systems, ERP platforms, and other critical business applications. Poor integration can create new data silos or operational friction.
- Scalability: Solutions should be chosen not only for their ability to handle current data volumes and processing needs but also for their capacity to scale and adapt to anticipated future growth and evolving business requirements.
B. Conducting Cost-Benefit Analysis and Calculating Return on Investment (ROI)
Financial justification is critical for securing approval and resources for any data entry improvement initiative. A thorough cost-benefit analysis (CBA) and Return on Investment (ROI) calculation provide this justification. If you want to dive deeper into ROI frameworks and how CFOs can quantify the impact of technology investments, check out our CFO's guide to calculating ROI for custom software.
- Understanding ROI: ROI is a fundamental financial metric used to evaluate the profitability or cost-effectiveness of an investment. It is calculated by comparing the net financial benefits gained from the investment to the total costs incurred in acquiring, implementing, and maintaining it. A common formula is: RO I = Cost of Investment ( Net Return on Investment − Cost of Investment ) × 100 .
- Identifying and Quantifying Costs : A comprehensive list of potential costs includes:
- Technology Costs: This encompasses software licenses or subscription fees (for OCR, RPA, AI tools, specialized validation software), the purchase of necessary hardware (scanners, upgraded computers, servers), costs associated with system implementation and configuration, and ongoing expenses for cloud storage or data hosting.
- Personnel Costs: These include the costs of hiring new skilled staff if required (e.g., automation specialists, data analysts), the expense of training existing staff on new processes and tools, and fees for external consultants if their expertise is leveraged.
- Maintenance and Support: Ongoing costs for software updates, vendor support contracts, and internal IT effort for maintaining the new systems.
- Change Management Costs: Resources allocated to managing the transition, including communication, stakeholder engagement, and addressing resistance to change.
- Identifying and Quantifying Benefits : Benefits can be both direct (easily quantifiable) and indirect (more strategic, harder to assign a precise dollar value but still critical):
- Direct Cost Savings:
- Reduced Labor Costs: Fewer human hours required for data entry due to automation or increased efficiency, leading to savings on salaries, benefits, and overtime. Some studies suggest RPA can reduce operational costs by as much as 50%.
- Reduced Error Correction Costs: Fewer errors mean less time and resources spent on identifying, investigating, and correcting mistakes, as well as mitigating their downstream consequences.
- Lower Operational Expenses: Streamlined processes can lead to savings in materials, utilities, or other operational overheads.
- Increased Productivity and Efficiency: Time savings from faster data processing due to automation or optimized manual workflows translate directly into increased output per employee or per unit of time.
- Improved Accuracy: A quantifiable reduction in error rates leads to more reliable data, fewer penalties for non-compliance, less rework, and better decision-making. Advanced AI tools, for instance, can achieve accuracy rates exceeding 99%.
- Enhanced Compliance: More accurate and complete data, coupled with better process controls, can help avoid costly fines and penalties associated with regulatory non-compliance.
- Strategic Value (Indirect Benefits):
- Faster Time-to-Market: More efficient data processes can accelerate product development cycles or service delivery.
- Improved Customer Satisfaction and Retention: Accurate data leads to better customer experiences (correct orders, timely service), fostering loyalty.
- Better Decision-Making: Higher quality data enables more informed strategic and operational decisions, potentially leading to new revenue opportunities or market advantages.
- Direct Cost Savings:
- ROI Calculation Methodologies: Beyond the basic ROI formula, other metrics can provide additional perspective:
- Payback Period: This calculates the amount of time it takes for the accumulated financial benefits of the investment to equal its initial cost. A shorter payback period is generally more attractive.
- Net Present Value (NPV): NPV takes into account the time value of money by discounting future cash flows (both costs and benefits) back to their present value. A positive NPV indicates that the investment is expected to be profitable over its lifespan.
- Comparing Manual vs. Automated ROI: Manual data entry is characterized by ongoing, often significant, labor costs and a persistent potential for high error rates. Automation technologies, while typically involving a higher upfront investment, can lead to substantial long-term savings in labor, dramatic reductions in error-related costs, and significant gains in processing speed and efficiency. For example, the annual cost of OCR software can be less than $1,000, whereas the average annual salary for a single data entry professional can exceed $40,000.
- ROI of Training vs. Technology: It's also important to consider the interplay between investments in human capital and technology. Investing in AI and data literacy training for staff can yield significant ROI, primarily measured through productivity improvements over a 12 to 24-month period. Effective upskilling of the workforce is often a key prerequisite for realizing the full ROI from major technology transformations. In some cases, particularly where foundational process issues or skill gaps are severe, investing in improving skills for existing systems or implementing simpler process changes may yield a better immediate ROI than rushing into large-scale technology investments before the organization is prepared.
C. Resource Planning and Managing Implementation Costs
Effective implementation requires careful planning of all necessary resources-human, technological, and financial-and diligent management of associated costs.
- Identifying Resource Needs:
- Human Resources: Depending on the scope and nature of the improvement initiative, various roles may be required. These can include project managers to oversee the initiative, IT specialists for system integration and technical support, data analysts to measure impact and identify further opportunities, trainers to upskill staff, subject matter experts (SMEs) from the business units affected, and data stewards to take ownership of data quality post-implementation. A key decision is whether existing staff can be retrained and redeployed or if new hires or external consultants are necessary.
- Technological Resources: This includes all necessary software (licenses or subscriptions for data entry, management, automation, or validation tools), hardware (new computers, scanners, servers), and any required upgrades to network infrastructure or security systems.
- Financial Resources: A detailed budget must be allocated, covering all cost components identified during the cost-benefit and ROI analysis. This budget needs to be actively managed throughout the project lifecycle.
- Estimating Costs: While specific costs vary greatly depending on the organization and project scope, referencing typical expenses for setting up a data entry operation can provide a baseline (adaptable for internal projects) :
- Computers & Hardware: Potentially $2,000 - $5,000 for desktops, laptops, additional peripherals like monitors, and crucially, ergonomic furniture (chairs, desks) to support operator well-being and productivity.
- Software & Subscriptions: Ranging from $1,500 - $4,000 or more, covering licenses for specialized data entry and management software, AI-driven tools, data validation utilities, and subscriptions for cloud storage and collaboration platforms.
- Hiring & Training: If new staff are hired, this is a significant cost. Training existing staff can range from $500-$1,000 per employee for initial programs, plus ongoing professional development.
- Data Security: Investments of $600 - $1,500 or more for firewalls, VPNs, encryption tools, and security audits to protect sensitive information.
- Consulting Services: If external expertise is engaged for process re-engineering, technology selection, or implementation support, these fees can be substantial, potentially accounting for 10-15% of the total project budget.
- Tips for Managing Implementation Costs :
- Consider Cloud-Based SaaS Solutions: Opting for Software-as-a-Service (SaaS) solutions can often minimize large upfront capital expenditures on hardware and software licenses, shifting costs to more predictable operational subscription fees.
- Thoroughly Compare Vendor Offerings: Carefully evaluate pricing models, ease of implementation, and included features from different vendors.
- Evaluate Total Cost of Ownership (TCO): Look beyond initial purchase or subscription costs to consider the TCO over a realistic period (e.g., three years), factoring in implementation, training, maintenance, support, and potential upgrade costs.
- Phased Implementation: Rolling out changes in stages (see below) can help spread costs over time and allow for learnings from earlier phases to optimize spending in later stages.
D. Developing a Phased Implementation Strategy
A "big bang" approach to implementing significant changes in data entry processes or technologies is often risky and disruptive. A phased implementation strategy is generally more prudent and effective. If you're looking for a real-world framework on how to roll out digital transformation in waves, our article on leveraging custom software for long-term growth offers practical insights on phased adoption and scaling.
- Pilot Projects and Small-Scale Rollouts: Before a full-scale deployment, it is highly advisable to test new processes, software, or automation tools on a limited scale. This could involve a pilot project within a single department, for a specific document type, or with a small group of users. Pilot projects serve several crucial functions:
- They help to identify and mitigate unforeseen risks and challenges in a controlled environment.
- They provide an opportunity to gather valuable feedback from end-users and stakeholders, which can be used to refine the solution before wider rollout.
- They allow for the validation of anticipated benefits and ROI on a smaller scale, building confidence and support for broader implementation.
- Iterative Approach: Rather than attempting to implement all desired changes at once, an iterative approach involves breaking the overall initiative into smaller, manageable stages or sprints. Each stage delivers a specific set of improvements, and the learnings from one stage inform the planning and execution of the next. This allows for flexibility, continuous learning, and the ability to adapt the plan as new information emerges or business priorities shift.
- Robust Change Management: Successfully implementing new data entry solutions, especially those involving new technologies or significant workflow alterations, requires effective change management to ensure user adoption and minimize resistance. Key components include:
- Clear and Consistent Communication: Proactively and transparently communicate the reasons for the changes ("the why"), the expected benefits for both the organization and individual employees, and how the changes will impact daily work.
- Stakeholder Engagement and Participation: Involve all relevant stakeholders, particularly the data entry staff who will be most directly affected, in the planning, design, and testing phases. Their input is invaluable for creating practical solutions, and their participation fosters a sense of ownership and buy-in, reducing resistance to change.
- Comprehensive Training and Ongoing Support: As detailed in Section II.C.1, provide thorough training on any new tools, processes, and standards. Ensure that ongoing support mechanisms are in place to assist users during and after the transition.
- Thorough Documentation: All new processes, data standards, system configurations, user guides, and training materials must be meticulously documented. This documentation is essential for onboarding new staff, for troubleshooting, and for ensuring consistency as the new systems and procedures become embedded in the organization.
The financial returns anticipated from investments in "hard" technologies like RPA, AI, or new data management software are often critically dependent on the success of "soft" investments in areas like employee training and comprehensive change management. If employees are not adequately trained to use new systems effectively, or if they resist changes to their established workflows due to insufficient communication or engagement, the technology will likely be underutilized or even misused. This, in turn, will significantly diminish the potential ROI, regardless of the sophistication or inherent capabilities of the technology itself. Resistance to change is a common challenge in business process re-engineering efforts and requires proactive strategies like clear communication and early stakeholder involvement to overcome.
Therefore, when organizations are calculating the ROI for data entry improvement projects and planning their implementation budgets, it is imperative not to underestimate or underfund these crucial "soft" aspects. Comprehensive training programs and robust change management initiatives should not be viewed as auxiliary or discretionary costs, but rather as essential enabling factors for achieving the projected financial benefits from technological advancements. Failing to invest adequately in the human side of technological change can lead to stalled or failed implementations, or result in a significantly lower-than-expected ROI, thereby undermining the entire improvement effort. These "soft" costs are fundamental to unlocking the "hard" financial returns.
IV. Sustaining Peak Data Entry Performance
Implementing fixes for inefficient data entry is a significant achievement, but the journey doesn't end there. Sustaining peak performance requires ongoing monitoring, regular evaluation, and a deeply embedded culture of continuous improvement. Without these elements, even the best-implemented solutions can degrade over time as business needs evolve, new challenges emerge, or vigilance wanes.
A. Establishing Key Performance Indicators (KPIs) for Ongoing Monitoring
Key Performance Indicators (KPIs) are quantifiable measures used to track the effectiveness and efficiency of data entry processes over time. They provide objective data on performance, help gauge progress towards predefined goals, and act as early warning signals for emerging issues that may require attention. To go deeper into building a data-driven culture and integrating analytics with your business process improvement, explore our insights on enterprise software development strategy and the power of continuous monitoring.
- Key Data Entry Quality & Efficiency KPIs :
- Accuracy Rate: This fundamental KPI measures the percentage of data entries that are free from errors. It is typically calculated as: ( Number of accurate entries / Total number of entries ) × 100 . A common target for high-performing data entry operations is an accuracy rate of 95-98% or higher.
- Error Rate: The inverse of the accuracy rate, this measures the percentage of entries containing errors. The goal is typically to keep this below 3%. Calculated as: ( Number of incorrect entries / Total number of entries ) × 100 .
- Data Completeness Rate: This tracks the percentage of data records that have all required fields filled in. Missing data can render records useless for analysis or operations. A target of 90% or higher is often set.
- Data Consistency: This refers to the uniformity and coherence of data within a single database and across different interconnected systems. It is typically assessed through data profiling and regular audits rather than a single formula.
- Data Timeliness / Data Entry Time: This KPI measures how quickly data is entered into the system after being received or generated. It can be expressed as the percentage of data entered within a defined timeframe (e.g., within 24 hours of collection) or as the average time taken to collect and enter a dataset.
- Data Validity: This assesses the extent to which entered data conforms to predefined business rules, constraints, and formatting requirements. A high adherence rate, such as 98%, is desirable.
- Data Uniqueness (Inverse of Duplication Rate): This measures the proportion of unique records in a dataset, aiming to minimize or eliminate duplicate entries which cause confusion and waste resources.
- Throughput / Processing Speed: This KPI quantifies the volume of data processed per unit of time, such as the number of records entered per hour or documents processed per day. It is a key indicator of operational efficiency.
- Cost per Entry / Transaction: This metric tracks the operational cost associated with processing each individual data unit or transaction, helping to monitor cost-efficiency.
- Time Taken for Corrections: Measuring the amount of time spent by staff on fixing data entry errors provides insight into the impact of poor quality and the effectiveness of error prevention measures.
- KPIs for Measuring Automation Success : When automation solutions are implemented, specific KPIs are needed to track their performance:
- Automation Rate: The percentage of potentially automatable processes or test cases that have actually been automated.
- Reduction in Manual Effort / Time Saved: Quantifies the number of human hours saved due to the automation of tasks.
- Bot Accuracy / Error Rate: Measures the accuracy of the data processed or tasks performed by the automation bots.
- Process Cycle Time Reduction: The improvement in the end-to-end speed of processes that have been automated.
- Return on Investment (ROI) of Automation Initiatives: Tracks the financial benefits of automation against its costs.
- Setting Benchmarks: For each chosen KPI, it is essential to establish clear, measurable, achievable, relevant, and time-bound (SMART) benchmarks or targets. These should be based on initial performance assessments, industry standards (if available), and the desired outcomes of the improvement initiatives.
Table 3: Key Performance Indicators (KPIs) for Data Entry Operations
| KPI Category | KPI Name | Definition | Formula / Calculation Example | Target Example |
|---|---|---|---|---|
| Accuracy | Data Accuracy Rate | Percentage of data entries without errors. | (Accurate Entries / Total Entries) * 100 | >95-98% |
| Error Rate | Percentage of data entries containing errors. | (Incorrect Entries / Total Entries) * 100 | <3% | |
| Quality | Data Completeness Rate | Percentage of records with all required fields filled. | (Complete Records / Total Records) * 100 | >90% |
| Data Validity | Extent data meets specific rules/constraints. | (Valid Entries / Total Entries) * 100 | 98% adherence | |
| Data Uniqueness (No Duplicates) | Percentage of distinct records in a dataset. | (Unique Records / Total Records) * 100 | >99% | |
| Efficiency/ | Throughput / Processing Speed | Volume of data processed per unit of time. | E.g., Records per hour, Documents per day | Increase by X% |
| Speed | Data Timeliness / Entry Time | Percentage of data entered within a defined timeframe from collection/receipt. | E.g., % entered within 24 hours | >95% within 24hrs |
| Time Taken for Corrections | Average time spent fixing data entry errors. | Total correction time / Number of errors corrected | Decrease by Y% | |
| Cost | Cost per Entry/Transaction | Operational cost to process each data unit. | Total data entry cost / Total entries processed | Reduce by Z% |
| Automation | Automation Rate | Percentage of automatable tasks/processes that are automated. | (Automated Tasks / Total Automatable Tasks) * 100 | Target % |
| Impact | Reduction in Manual Effort | Hours of manual work saved due to automation. | Manual hours before - Manual hours after | Specific hour goal |
| Process Cycle Time Reduction (Automation) | Percentage decrease in end-to-end process time due to automation. | ((Old Cycle Time - New Cycle Time) / Old Cycle Time) * 100 | Target % reduction |
B. Conducting Post-Implementation Reviews (PIRs) and Regular Process Audits
Once improvement initiatives are implemented, it's crucial to assess their actual impact and ensure ongoing adherence to new standards and processes. For those leading digital transformation, making post-implementation audits a core part of your DevOps efficiency practices will help keep your improvements on track and sustainable.
Purpose and Process of Post-Implementation Reviews (PIRs): A PIR is a formal evaluation conducted after a project or significant change initiative has been completed and its outputs have been in use for a period. For data entry improvements, this means reviewing the new processes, technologies, or training programs once they have stabilized. The primary goals of a PIR are:
- To determine whether the original objectives of the improvement project were met (e.g., did error rates decrease as planned? Was processing speed enhanced?).
- To assess the actual business impact and benefits realized compared to those anticipated in the initial justification (e.g., cost savings, productivity gains).
- To identify what went well during the implementation and what challenges were encountered.
- To document valuable lessons learned that can inform future projects and continuous improvement efforts.
The PIR process typically involves :
- Define Objectives for the Review: Clearly state what the PIR aims to evaluate, linking back to the original project goals.
- Gather Data: Collect all relevant project documentation (plans, budgets, timelines), performance data (KPI reports before and after implementation), status updates, and feedback from stakeholders.
- Conduct Interviews: Speak with project team members, data entry staff (end-users), managers, and other stakeholders to gather their experiences, perspectives on the changes, challenges faced, and suggestions for improvement. An environment that encourages honest and open feedback is essential.
- Analyze Findings: Review all collected information to identify patterns, key insights, and discrepancies. Compare actual outcomes against planned objectives (gap analysis).
- Document Lessons Learned: Clearly articulate what worked well and should be replicated, what didn't work and should be avoided, and specific, actionable recommendations for future improvements or projects.
- Share and Apply Insights: Distribute the PIR findings to relevant parties across the organization. Crucially, ensure that these lessons learned are actively incorporated into the planning and execution of future initiatives.
- Data Quality and Process Audits: Alongside project-specific PIRs, regular, ongoing audits of data quality and data entry processes are essential for maintaining standards.
- Objective: To systematically and periodically review samples of data and observe data entry processes to ensure ongoing accuracy, completeness, consistency, and compliance with established standards and procedures.
- Process: Audits typically involve:
- Establishing clear audit criteria based on defined data quality metrics and process standards.
- Collecting data samples (e.g., a random selection of recently entered records) and analyzing them for errors or deviations (this may involve data profiling and sampling techniques).
- Observing data entry processes to ensure adherence to documented procedures.
- Identifying and meticulously documenting any data quality issues, process non-conformities, or areas of emerging risk.
- Frequency: Audits should be conducted regularly. The frequency can vary (e.g., weekly, monthly, quarterly) depending on the criticality of the data and the stability of the processes. Audits can be random spot checks or more formally scheduled events covering a representative sample of work.
- Focus Areas: Audits should examine common error types, adherence to data entry procedures, the effectiveness of implemented validation rules, system performance related to data entry, and the correct use of any automation tools.
- Remediation Plan: A key output of any audit is the development and implementation of a remediation plan to address any identified issues or deficiencies promptly. This ensures that problems are not just noted but actively corrected.
C. Fostering a Culture of Continuous Improvement in Data Operations

Sustaining peak data entry performance is not a one-time fix but an ongoing commitment. It requires fostering a culture where continuous improvement (CI) is an integral part of daily operations. If you want to see how continuous improvement principles drive digital transformation at scale, take a look at our coverage of the state of DevOps in 2025 for practical lessons and emerging trends.
- Embracing a Continuous Improvement (CI) Mindset: CI is an organizational philosophy focused on making ongoing, incremental efforts to improve products, services, and processes. This involves proactively identifying inefficiencies, systematically addressing weaknesses, and consistently making modifications to achieve higher levels of performance, quality, and efficiency. In the context of data entry, this means recognizing that data quality is not a static goal to be achieved and then forgotten, but rather an ongoing practice that must be constantly nurtured and refined.
- Methodologies for Continuous Improvement: Several established methodologies can guide CI efforts:
- PDCA Cycle (Plan-Do-Check-Act): This iterative four-step management method is widely used for continuous improvement.
- Plan: Identify an opportunity for improvement (e.g., a recurring error type, a slow process step) and develop a plan to address it.
- Do: Implement the planned change, often on a small scale or as a pilot first.
- Check: Monitor the results of the change (using KPIs) to see if it had the desired effect and to identify any unintended consequences.
- Act: If the change was successful, implement it more broadly and standardize the new process. If not, analyze what went wrong and begin the cycle again with a new plan.
- Kaizen: This Japanese philosophy emphasizes making small, ongoing positive changes that collectively lead to significant improvements over time. It encourages all employees to contribute ideas for improvement.
- Lean Principles: Originating from manufacturing, Lean thinking focuses on maximizing customer value while minimizing waste. Key principles applicable to data entry include defining value from the customer's perspective (users of the data), mapping the value stream (the data entry process), creating a smooth flow of work, establishing a "pull" system (processing data as needed rather than creating large backlogs), and continuously seeking perfection.
- PDCA Cycle (Plan-Do-Check-Act): This iterative four-step management method is widely used for continuous improvement.
- Key Practices for CI in Data Entry Operations :
- Regularly Review KPIs and Audit Findings: Use the data generated from performance monitoring and audits as the primary driver for identifying areas needing improvement and for measuring the success of CI initiatives.
- Actively Gather Feedback: Create channels for ongoing feedback from data entry staff, downstream users of the data, and other relevant stakeholders. Their insights are invaluable for identifying practical improvement opportunities.
- Encourage a Culture of Accuracy and Ownership: Promote a workplace environment where attention to detail is highly valued. Empower staff to identify, report, and even help solve data quality issues. Establishing clear data stewardship roles, where individuals or teams are responsible for the quality of specific datasets, can reinforce this ownership.
- Invest in Ongoing Training and Skill Enhancement: As processes and technologies evolve, ensure that staff skills are continuously updated to maintain high performance levels.
- Iterate on Processes and Technologies: Be prepared to regularly refine workflows, update software configurations, and explore new tools or techniques as business needs change or as new, more effective solutions become available.
- Document and Share Best Practices: When successful improvements are made, document the new best practices and share them across the relevant teams to ensure consistency and widespread adoption.
The relationship between Key Performance Indicators (KPIs), regular audits, and a continuous improvement framework forms a vital, self-reinforcing feedback loop that acts as an engine for sustained efficiency in data entry operations. KPIs provide the ongoing, often near real-time, data on how processes are performing against established targets. When these KPIs flag potential issues-such as a sudden increase in error rates, a decline in processing speed, or a drop in data completeness-they act as triggers. These triggers can then prompt more focused investigations, often in the form of targeted data quality audits or detailed process reviews, to understand the "why" behind the adverse KPI trends.
The findings from these deeper-dive audits and reviews then provide specific, actionable insights. For example, an audit might reveal that a particular step in a newly revised workflow is causing confusion and leading to errors, or that a specific validation rule in the data entry software is not functioning as intended. These concrete findings become direct inputs into the "Plan" and "Do" stages of continuous improvement cycles, such as the PDCA model. A plan is formulated to address the identified root cause, and the corrective action is implemented. Subsequently, the "Check" stage of the PDCA cycle would involve closely monitoring the very same KPIs that initially flagged the problem to determine if the implemented changes have had the desired positive effect and have brought performance back on target.
This creates a dynamic and continuous cycle: Monitor performance using KPIs, Investigate deviations and root causes through audits and reviews, Implement improvements through a CI framework, and then return to Monitoring KPIs to assess the impact. By consciously designing and diligently maintaining this interconnected feedback system, organizations can ensure that improvements to data entry processes are not only made but are also sustained and built upon over time. This transforms the management of data entry operations from a reactive, problem-fixing mode, where issues are addressed only after they cause significant disruption, to a proactive, optimizing one, where the system is constantly being refined for better performance.
V. Conclusion: Transforming Data Entry into a Strategic Asset
Fixing inefficient data entry processes is far more than a mere operational tune-up; it is a strategic imperative that can unlock significant business value. The journey from error-prone, labor-intensive data entry to an optimized, accurate, and efficient operation involves a comprehensive, multi-pronged approach that addresses processes, technology, and people.
The core strategies detailed in this report-optimizing workflows through standardization and re-engineering, leveraging appropriate technologies like OCR, ICR, RPA, and AI for automation and enhanced accuracy, and empowering the workforce through comprehensive training, ergonomic design, and focus-enhancing techniques-are all critical components of this transformation. Each pillar supports the others, and neglecting one can undermine progress in the others.
Ultimately, the goal is to elevate data entry from a perceived cost center to a foundational element of business intelligence and operational excellence. Accurate, timely, and efficiently managed data is the bedrock upon which reliable analytics, informed decision-making, and sustainable competitive advantage are built. When data entry processes are efficient and produce high-quality data, the entire organization benefits-from reduced operational costs and mitigated compliance risks to improved customer satisfaction and enhanced strategic agility.
The transformation of data entry requires commitment, a structured diagnostic approach, careful selection and implementation of solutions, and an unwavering dedication to continuous improvement. By embarking on this optimization journey, organizations can convert a traditionally burdensome function into a streamlined data pipeline that actively supports and drives broader business objectives, turning data entry into a true strategic asset. The path forward involves starting with a thorough diagnosis of current inefficiencies, strategically selecting and justifying improvement initiatives, and fostering a culture where data quality and process efficiency are continuously monitored and enhanced.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.