
Scaling Kubernetes in the Enterprise: A Strategic Guide to Cost, Complexity, and Competitive Advantage
July 24, 2025 / Bryan Reynolds0.1 Introduction: From Promise to Production - The Kubernetes Container Orchestration Scaling Imperative

Kubernetes has cemented its position as the de facto standard for container orchestration, a testament to its power, flexibility, and the vibrant open-source community that propels it forward. Recognized as the second-fastest-growing open-source project after Linux, the Kubernetes market is projected to expand at a 23.4% compound annual growth rate, reaching an estimated $9.7 billion by 2031. This widespread adoption is no accident; Kubernetes provides an unparalleled foundation for deploying, scaling, and managing containerized applications with resilience and portability.
However, the journey from a successful pilot project to a sprawling, enterprise-wide implementation reveals a critical paradox. The very strengths that make Kubernetes attractive at a small scale can become significant liabilities when magnified across hundreds of clusters, thousands of nodes, and countless development teams. Without a deliberate and strategic approach, enterprises often find that their Kubernetes environments devolve into a source of spiraling costs, operational fragility, and security vulnerabilities.
This report, prepared by the experts at Baytech Consulting, serves as a strategic guide for enterprise IT leaders navigating this complex landscape. It moves beyond basic technical tutorials to address the core strategic considerations required to master Kubernetes at scale. The objective is to provide a clear framework for transforming Kubernetes from a potential operational burden into a powerful, strategic enabler of business agility and competitive advantage. This journey involves mastering foundational operational disciplines, architecting for future resilience, making informed platform decisions, embedding financial accountability into the fabric of your cloud-native operations, and ensuring effective infrastructure management to support scalable Kubernetes operations.
Section 1: The Scaling Paradox: When Kubernetes's Strength Becomes a Challenge
The initial success of Kubernetes within an organization often masks a set of second-order problems that emerge only at enterprise scale. The management paradigm for a handful of clusters is fundamentally different from that required for a global fleet. At this level, platform teams play a critical role in managing the increased complexity and ensuring operational stability. What begins as a straightforward and powerful tool can, without proactive governance, become a fragile "house of cards," where teams avoid critical updates out of fear of breaking the system. This section dissects the specific, interconnected challenges that define the Kubernetes scaling paradox.
The skills gap becomes more pronounced as organizations attempt to scale, and hiring talent with deep Kubernetes expertise is increasingly difficult. Platform engineers are essential for building and maintaining scalable Kubernetes environments, providing the specialized knowledge needed to avoid operational pitfalls.
1.1 Beyond the Pilot: The New Class of Problems at Enterprise Scale
The transition from small-scale deployments to enterprise-wide adoption fundamentally alters the nature of Kubernetes management. The "set it and forget it" mindset, while tempting, is a direct path to systemic failure. Due to the inherent complexity of the platform, seemingly minor decisions and undocumented fixes made when the infrastructure was small can cascade into brittle, unexpected problems at scale.
This challenge is severely compounded by a persistent and well-documented skills gap. According to The State of Kubernetes survey, the number one challenge when selecting a Kubernetes distribution remains inadequate internal experience and expertise, cited by 51% of respondents. The second most common challenge, noted by 37% of participants, is the difficulty of hiring the necessary talent. This talent shortage creates a difficult reality for many organizations: they are forced to build complex layers of automation simply to hide the underlying complexity of Kubernetes from their internal users and developers. Internal platforms can provide a modern, resilient environment for development teams, helping organizations achieve the speed and reliability needed for effective software delivery.
Building and managing a skilled software team is crucial for overcoming these organizational and technical hurdles. Hiding complexity from internal users and developers also highlights the importance of streamlined developer workflows, which support efficient Kubernetes adoption at scale. This reactive approach to automation, born out of necessity rather than strategy, often contributes to the very fragility it is meant to solve.
1.2 The Four Horsemen of Kubernetes Sprawl: Cost, Complexity, Security, and Drift
As Kubernetes environments grow organically, they often fall prey to four interconnected issues that collectively undermine the platform's value proposition. These are not independent problems but a self-reinforcing cycle of technical debt.
Operational complexity, lack of network visibility, and interoperability challenges can make it difficult to manage and scale Kubernetes clusters effectively. Advanced networking is essential in this context, as it enables Kubernetes to support complex microservices architectures with sophisticated, automated network configurations.
Security, compliance, and upgrade challenges further increase the need for automation and efficiency. Continuous integration and continuous delivery play a crucial role here by streamlining deployment, automating testing and rollbacks, and reducing manual intervention.
Exorbitant Cloud Costs
This is frequently the most visible and painful symptom of improperly scaled Kubernetes. A recent Cloud Native Computing Foundation (CNCF) survey found that 68% of organizations are seeing their Kubernetes costs increase, with half of those experiencing a rise of more than 20% per year. This financial drain is not an inherent flaw of Kubernetes but a result of systemic inefficiencies. Key drivers include overprovisioning resources to avoid performance issues, idle development clusters running after hours, and orphaned storage volumes that continue to incur charges long after they are needed. Research reveals a staggering level of waste: over 65% of Kubernetes workloads use less than half of their requested CPU and memory, primarily because schedulers rely on these requests-not actual usage-for pod placement. This leads to underutilized nodes and a cloud bill that balloons out of control, with one report suggesting teams waste approximately 32% of their total cloud expenditure.
To help budget-conscious teams and startups avoid unnecessary spending, some platforms offer a free tier that supports many early-stage use cases before scaling up.
Operational Complexity and Fragility
At its core, Kubernetes abstracts away infrastructure complexities, allowing developers to focus on applications. However, as deployments grow to include thousands of containers, nodes, and services across multiple teams and environments, managing this "fleet" becomes a daunting task. Container orchestration platforms streamline managing containers by automating deployment, monitoring, and scaling, which reduces the manual workload for development and operations teams and improves overall efficiency. In the absence of a strong governance model, teams often introduce piecemeal solutions and undocumented "late-night fixes" to solve emerging issues. This leads to disjointed, fragile systems that resemble a house of cards, where a single change can have unpredictable and catastrophic consequences. This complexity is significantly amplified in hybrid and multi-cloud deployments, which introduce challenges related to network visibility, interoperability, and maintaining consistency across disparate environments.
Pervasive Security Vulnerabilities
Security consistently ranks as one of the top challenges of running Kubernetes at scale. The distributed and ephemeral nature of cloud-native applications adds layers of complexity to securing the stack. Most security incidents are not the result of sophisticated zero-day exploits but stem from preventable misconfigurations, such as overly permissive network policies, insecure API server configurations, or the use of vulnerable container images. Robust user management is essential for enforcing secure access controls, policy enforcement, and user permissions across multiple clusters and cloud environments, significantly reducing the risk of security incidents. This problem is exacerbated by a phenomenon known as "upgrade paralysis." The fear of breaking a complex and fragile system causes many teams to avoid performing critical upgrades, leaving their clusters several versions behind the latest release. This inaction directly exposes the organization to known vulnerabilities, creating significant security risks and affecting system performance. Real-world security incidents, such as the 2018 Tesla cloud breach caused by an unprotected Kubernetes dashboard, and the more recent "IngressNightmare" vulnerabilities that put nearly half of all cloud environments at risk, underscore the severe consequences of these security lapses.
Configuration Drift
Configuration drift is the inevitable entropy that occurs in any large, dynamic system. It happens when developers or operators, often under pressure to make a quick fix, bypass standard procedures. A developer who SSHs into a node to manually patch a troublesome configuration file is creating a "snowflake" infrastructure. While this may solve an immediate problem, it introduces an undocumented, non-standard state that is invisible to declarative management tools. Troubleshooting a system full of these one-off exceptions is like finding a needle in a haystack and inevitably leads to more workarounds to fix the workarounds. This drift is a primary cause of system fragility and a major contributor to the "upgrade paralysis" mentioned earlier; it is nearly impossible to predict how a standard upgrade will affect a non-standard system. Effective image management plays a crucial role in maintaining consistency across environments and helps reduce configuration drift.
1.3 The Business Impact: How Technical Debt in Kubernetes Stifles Innovation
The technical challenges of scaling Kubernetes do not exist in a vacuum; they translate directly into tangible business consequences that should concern any C-level executive. The connection between these issues forms a vicious cycle: the inherent complexity and the associated skills gap foster a fear of change. This fear leads to upgrade paralysis , which creates massive security holes. To compensate for the resulting fragility and a lack of clear observability, teams are forced to overprovision resources, driving up costs . Meanwhile, ad-hoc fixes create configuration drift , which further increases complexity and makes future upgrades even more daunting.
This cycle has three primary business impacts:
- Direct Financial Waste: As noted, organizations are wasting nearly a third of their cloud spend, often due to Kubernetes-related inefficiencies. This is not merely an IT budget line item; it represents significant capital that could be reinvested in product development, market expansion, or other strategic initiatives. To understand how to analyze software investments for maximum value, see this CFO's guide to ROI in custom software development
- Reduced Developer Velocity and Innovation: When platform engineering teams are trapped in a reactive cycle of firefighting, troubleshooting snowflake systems, and manually managing fragile upgrades, they are not building the tools and platforms that accelerate application delivery. Delayed application deployment is a direct and measurable consequence of security incidents and infrastructure misconfigurations. This operational drag acts as a tax on innovation, slowing the entire organization's ability to respond to market changes.
- Increased Business and Reputational Risk: An unpatched, misconfigured, and drifting Kubernetes environment is a ticking time bomb. It represents a significant and unnecessary risk profile for the business, ranging from data breaches and regulatory compliance failures to production downtime that erodes customer trust and leads to direct revenue loss. In production environments, robust practices are essential to prevent downtime and data breaches, as failures here can have immediate and severe business consequences.
An IT leader cannot solve the cost problem without simultaneously addressing the underlying issues of complexity, security, and drift. They are inextricably linked. A strategy that only targets cost-for example, by purchasing reserved instances-without fixing the root causes of operational fragility is ultimately doomed to fail.
Section 2: Mastering the Foundations: Core Disciplines for Scalable Operations
To break the negative cycle of cost, complexity, and risk, enterprises must establish a set of core operational disciplines. These are not one-time fixes but ongoing practices that create a stable, efficient, and observable foundation for Kubernetes at scale. Effective scaling is not about choosing a single tool but about orchestrating a system of interacting controllers that are informed by a robust observability platform. This journey is evolutionary; an organization might begin with simple CPU-based autoscaling, only to realize the need for custom metrics, then for right-sizing with VPA, and finally for node-level scaling with a Cluster Autoscaler. Planning for this evolution and investing in observability from day one is the key to enabling all subsequent layers of automation.
2.1 The Art of Autoscaling: A Multi-Layered Approach
Dynamic scaling is one of Kubernetes' most powerful features, allowing resources to align with demand in real-time. However, effective autoscaling requires a multi-layered strategy that coordinates scaling at the pod and node levels. Container orchestration tools automate scaling tasks, efficiently adjusting resources and deploying containers as demand fluctuates, which is especially important in large-scale, production environments.
The primary scaling targets in Kubernetes include Pods, Nodes, Deployments, and StatefulSets. A comprehensive strategy must address these layers in concert, using a combination of autoscaling tools:
- Horizontal Pod Autoscaler (HPA): This is the most common form of autoscaling, which automatically adjusts the number of pod replicas in a Deployment or ReplicaSet based on observed metrics. While CPU and memory utilization are the default metrics, a truly effective strategy moves beyond these. Relying solely on infrastructure metrics is a common mistake, as they are often poor proxies for application performance. The real power of HPA is unlocked by using custom metrics-such as requests per second, message queue depth, or API response latency-which are much closer to the actual user experience and business needs.
- Vertical Pod Autoscaler (VPA): Where HPA adjusts the number of pods, VPA adjusts the CPU and memory requests and limits of the containers within the pods themselves. This is a critical tool for right-sizing workloads and eliminating the resource waste caused by overprovisioning. However, it's important to note that VPA and HPA can conflict if not configured correctly, potentially leading to "thrashing," where the system oscillates between adding pods and resizing them. A common best practice is to run VPA in "recommendation" mode initially to gain insights without causing disruption.
- Cluster Autoscaler (CA) and Karpenter: These tools operate at the infrastructure level, scaling the number of nodes in the cluster. The CA is a reactive tool that adds nodes when it detects pods that cannot be scheduled due to resource constraints. A more modern alternative, Karpenter, is a proactive and flexible node provisioner that can launch the most cost-efficient instance types across different purchasing options (like Spot Instances) in real-time, often with lower latency than the traditional CA. A critical failure pattern for organizations new to scaling is implementing HPA without a corresponding node-level autoscaler. When pods attempt to scale up on a full cluster, they will remain in a pending state indefinitely. These layers must work together.
Common pitfalls in autoscaling include oscillating behavior (often caused by scaling thresholds being too close together), slow scaling (due to long pod termination grace periods), and "flapping" (frequent scaling up and down), which can severely impact stateful applications like Kafka by triggering constant, high-overhead rebalancing operations. Tuning parameters like the stabilization window, which controls how long the HPA waits before scaling down, is essential for system stability.

2.2 Resource Management as a Financial Strategy: The Science of Right-Sizing to Minimize Operational Overhead
Proper resource management is arguably the single most impactful strategy for Kubernetes cost optimization. It is a financial discipline as much as a technical one, focused on eliminating waste by precisely aligning resource allocation with application needs. For certain workloads, deploying Kubernetes on bare metal servers can provide additional performance and cost benefits by running containerized workloads directly on physical hardware, bypassing the overhead of virtualization or cloud infrastructure. This involves the careful configuration of resource requests and limits.
- Requests vs. Limits: These two parameters are fundamental to Kubernetes scheduling and resource governance. A container's request specifies the minimum amount of CPU or memory it needs to run, which Kubernetes guarantees and uses to make scheduling decisions. The limit defines the maximum amount of a resource the container is allowed to use, preventing a single runaway application from starving other workloads on the same node. For applications requiring predictable performance, a common best practice is to set memory requests equal to memory limits, which assigns the pod a Guaranteed Quality of Service (QoS) class.
- The Perils of Misconfiguration: Incorrectly setting these values leads to four distinct failure modes:
- Under-provisioning Requests: Setting requests too low can cause the scheduler to place a pod on a node with insufficient resources, leading to CPU throttling and poor performance.
- Over-provisioning Requests: Setting requests too high wastes money. The node will appear full to the scheduler, preventing other pods from being placed, even if the requested resources are not actually being used.
- Under-provisioning Limits: Setting limits too low can cause Kubernetes to throttle or even kill the application when it experiences a legitimate spike in load, leading to instability and crashes.
- Over-provisioning Limits: Setting limits too high allows a single pod to monopolize a node's resources, potentially starving other critical applications.
The process of right-sizing is continuous, not a one-time task. It begins with establishing a baseline by analyzing historical consumption data with monitoring tools like Prometheus and Grafana. From there, tools like the Vertical Pod Autoscaler (VPA) or open-source utilities like Goldilocks can be used to analyze actual usage and recommend optimized request and limit values, which can then be implemented and monitored over time. For organizations seeking even deeper automation and efficiency, exploring AI-powered optimization strategies can unlock further resource savings and insights.
2.3 Observability is Non-Negotiable: Building a Data-Driven Culture

A recurring theme in scaling challenges is a lack of visibility. As one source aptly puts it, "You can't scale what you can't see." Without a comprehensive observability strategy, teams are flying blind, unable to diagnose performance issues, identify waste, or make informed scaling decisions. Platforms that offer built in monitoring features are especially valuable, as they integrate monitoring and governance capabilities directly within the system to ensure compliance and ease management. A mature observability practice is built on three pillars:
- Metrics: This involves collecting quantitative time-series data about the health and performance of the system. Prometheus is the de facto standard in the Kubernetes ecosystem for this purpose. It is essential for tracking not only basic infrastructure metrics like CPU and memory but also custom application-level metrics that drive intelligent autoscaling and provide insight into business key performance indicators (KPIs).
- Logs: Logs provide detailed, event-based records that are critical for debugging and root-cause analysis. While Kubernetes generates logs from various components, challenges remain in aggregation and analysis at scale. A robust logging pipeline, often using tools like Fluent Bit for collection and a centralized backend like Loki or the ELK Stack for storage and querying, is a foundational requirement.
- Traces: In a distributed microservices architecture, a single user request can traverse dozens of services. Distributed tracing, using standards like OpenTelemetry , provides the ability to follow that request through the entire system, making it possible to pinpoint bottlenecks and understand complex service interactions.
For enterprise-scale deployments, simply having these three pillars is often not enough. The sheer volume and complexity of the data generated require more advanced solutions. A modern approach calls for a single, comprehensive platform that provides end-to-end, full-stack visibility-from the underlying infrastructure all the way up to the application components. These platforms often incorporate AI-powered analytics to automatically detect anomalies, correlate events across the stack, and provide actionable root-cause analysis, moving the team from a reactive to a proactive posture.
Section 3: Architecting for the Future: Advanced Patterns for Resilience and Governance
Once the foundational disciplines of autoscaling, resource management, and observability are in place, enterprises can turn their attention to more advanced architectural patterns. Leveraging a distributed systems kernel at this stage allows organizations to abstract and manage resources such as CPU, memory, and storage across clusters, enabling efficient handling of diverse workloads and greater application flexibility in large-scale distributed environments. These strategies are designed to ensure high availability, disaster recovery, and robust security across large, geographically distributed, and often hybrid environments. Making the right architectural choices at this stage is critical for building a Kubernetes platform that is not just scalable, but also resilient and governable.
3.1 From Single Cluster to Global Fleet: Navigating Multiple Kubernetes Clusters and Hybrid Cloud Models
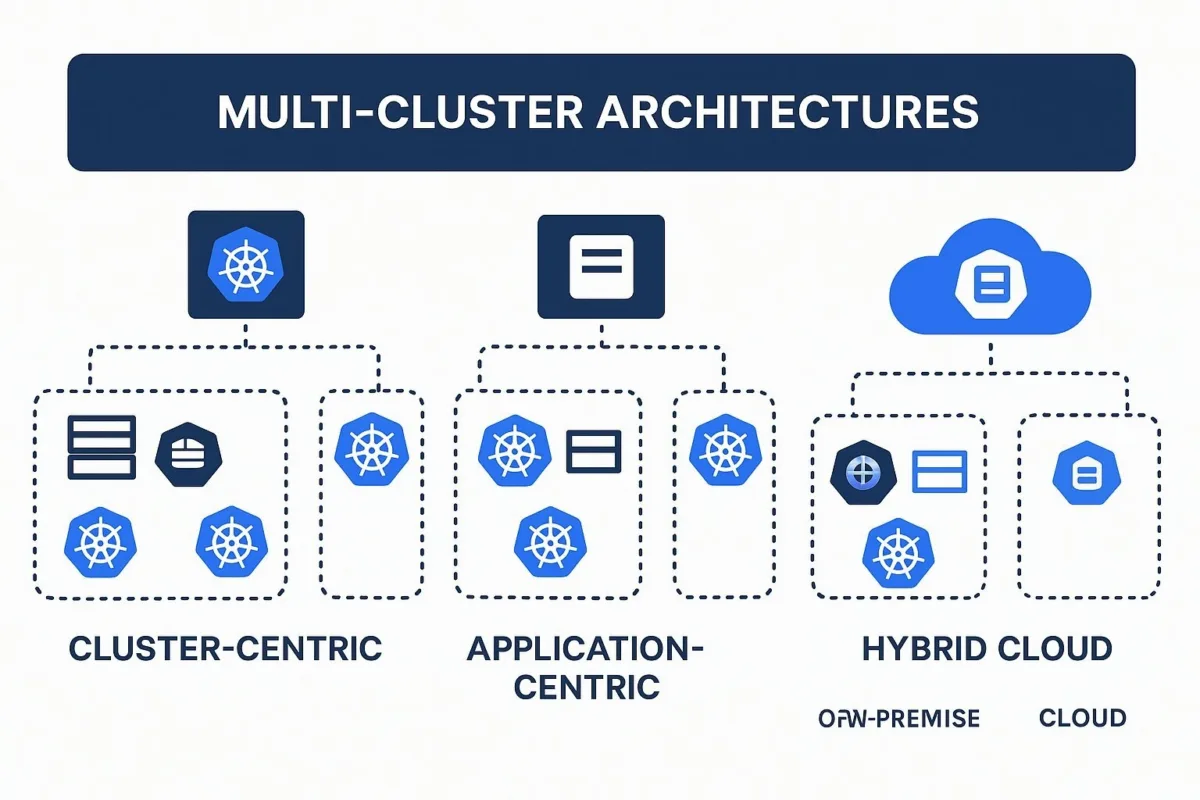
The decision to move beyond a single Kubernetes cluster is driven by several key business and technical requirements, including the need for higher availability, robust disaster recovery, strict tenant or data isolation, compliance with data sovereignty laws, and the strategic desire to avoid vendor lock-in. Managing a fleet of clusters introduces new complexities, particularly around networking, policy enforcement, and centralized monitoring, but several well-defined architectural patterns can help address these challenges. Managing multiple clusters across different environments brings both operational challenges and significant benefits, such as improved fault tolerance and the ability to tailor resources to specific workloads. For mid-sized B2B organizations, custom software solutions can be vital in streamlining these multi-cluster, hybrid environments for greater efficiency.
- Architectural Approaches:
- Cluster-Centric (Federated) Architecture: In this model, multiple distinct Kubernetes clusters are managed as a single logical or "virtual" unit, often through a unified control plane. This approach simplifies application deployment and management, as developers can interact with the fleet as if it were one large cluster. However, its success is heavily dependent on solving the challenge of seamless, high-performance networking and service discovery across all constituent clusters.
- Application-Centric Architecture: This approach treats each Kubernetes cluster as an independent, standalone environment. Applications and workloads can be deployed to, or moved between, these clusters as needed. This architecture offers greater flexibility and stronger isolation, making it particularly well-suited for disaster recovery scenarios (failing over from one independent cluster to another) and for leveraging the unique capabilities of different cloud providers in a multi-cloud setup.
- Implementation Strategies:
- Mirrored Configuration: In this strategy, identical copies of an entire application and its associated Kubernetes resources are deployed to each cluster in the fleet. This is a powerful pattern for achieving high availability and creating "hot spare" clusters for rapid failover. While the configuration is centrally managed, traffic may be distributed globally across all active clusters or directed only to a primary cluster, with the mirrored clusters on standby.
- Targeted Configuration: This is a more granular version of the mirrored strategy. Instead of replicating the entire application, only specific components-such as a single namespace for a particular tenant or a critical microservice-are duplicated across clusters. This approach provides administrators with greater precision and is ideal for enforcing tenant isolation, managing complex data governance requirements, and optimizing costs, as the secondary clusters do not need to be 1:1 replicas of the primary.
- Hybrid Cloud Patterns: Kubernetes is a key enabler of hybrid cloud strategies, allowing for consistent application orchestration across on-premises data centers and public clouds. Common patterns include "cloud bursting," where a primary on-premises cluster scales out to a public cloud to handle peak demand, and using the public cloud for development and testing environments while keeping production workloads on-prem for security or compliance reasons. Lightweight Kubernetes distributions, such as K3s and MicroK8s, are particularly well-suited for edge computing scenarios, enabling containerized applications to run efficiently at edge locations and in resource-constrained environments. For a deeper dive, see this analysis of private vs. public cloud for mid-market companies .
3.2 Beyond Backups: A Pragmatic Guide to Enterprise-Grade Disaster Recovery (DR)

An enterprise-grade disaster recovery strategy for Kubernetes is not just about having backups; it's about having a tested, reliable, and efficient plan to restore business operations in the face of failure. The technical strategy must be driven by clear business requirements, specifically the Recovery Point Objective (RPO) , which defines the maximum acceptable amount of data loss, and the Recovery Time Objective (RTO) , which defines the maximum acceptable duration of downtime. Different applications will have different RTO/RPO requirements, and the chosen DR pattern should reflect this, balancing cost against the need for resilience.
The following table outlines the common DR patterns, providing a strategic framework for aligning business needs with technical solutions.
| DR Pattern | Typical RTO | Typical RPO | Relative Cost | Implementation Complexity | Ideal Use Case |
|---|---|---|---|---|---|
| Backup & Restore | Hours to Days | Minutes to Hours | Low | Low | Non-critical applications, development/test environments, and workloads where some data loss and downtime are acceptable. |
| Pilot Light | Minutes to Hours | Minutes | Low-Medium | Medium | Applications with seasonal or unpredictable demand where essential components can be kept on standby and scaled up quickly when needed. |
| Warm Standby (Active-Passive) | Minutes | Near-Zero to Minutes | Medium-High | High | Critical business applications requiring high availability. A secondary, fully-scaled cluster is kept running with continuous data replication but does not serve live traffic until a failover event. |
| Hot Site / Multi-Site (Active-Active) | Seconds to Minutes | Zero | High | Very High | Mission-critical, global applications that cannot tolerate any downtime. Two or more independent clusters actively serve traffic, managed by a global load balancer. |
Table 1: Kubernetes Disaster Recovery Strategies - A Strategic Comparison
Regardless of the chosen pattern, several best practices are universal. DR plans must be tested regularly and automatically through "fire drills" to ensure they work as expected. Backups, whether etcd snapshots or application-level backups using tools like Velero, should be stored securely off-site and should be immutable to protect against ransomware attacks. It is also important to standardize the operating system environment across clusters to ensure compatibility and reliable recovery during disaster scenarios. Finally, adopting an application-centric backup approach, which captures not just data but also all the Kubernetes configurations and dependencies an application needs to run, is crucial for reliable recovery in complex environments.
3.3 Locking Down the Citadel: A Framework for Security, Governance, and Compliance
Securing Kubernetes at scale requires a defense-in-depth strategy that embeds security into every phase of the application lifecycle and is governed by the foundational Principle of Least Privilege (PoLP) . If you're interested in how real-world organizations tackle security across their DevOps lifecycle, check out the latest trends in DevOps for 2025
- A Lifecycle Approach to Security:
- Build Phase: Security starts in the CI/CD pipeline. This involves using minimal, hardened base images (such as "distroless" images) to reduce the attack surface, and integrating automated vulnerability scanning to prevent images with known CVEs from ever reaching the container registry.
- Deploy Phase: At deployment time, security is enforced through Kubernetes-native controls. This includes using namespaces for logical isolation, enforcing Pod Security Standards to prevent containers from running with excessive privileges, and leveraging admission controllers like Open Policy Agent (OPA) Gatekeeper to enforce custom governance policies before any resource is created in the cluster.
- Run Phase: Once an application is running, the focus shifts to threat detection and response. This requires runtime security monitoring tools (e.g., Falco) to detect anomalous behavior like unexpected process execution or network connections, continuous network traffic monitoring, and frequent, automated rotation of all infrastructure credentials. Automation tools play a crucial role in managing infrastructure by enforcing security policies consistently across environments, reducing manual errors and ensuring compliance.
- Enforcing the Principle of Least Privilege:
- Role-Based Access Control (RBAC): RBAC is the cornerstone of Kubernetes authorization. It must be configured to grant granular, namespace-scoped permissions to users and service accounts. Cluster-wide permissions and the use of wildcards (*) should be strictly avoided. Furthermore, applications should use dedicated service accounts with minimal permissions, and the automatic mounting of the default service account token should be disabled.
- Network Policies: By default, all pods in a Kubernetes cluster can communicate with each other. This flat network is a significant security risk, as it allows for easy lateral movement by an attacker who compromises a single pod. The best practice is to implement a "default-deny" network policy that blocks all traffic and then explicitly create policies to allow only the specific communication paths required for the application to function.
- Secrets Management: Sensitive information like passwords and API tokens should be stored in Kubernetes Secrets. These secrets should be encrypted at rest within the etcd datastore and should be mounted into containers as read-only volumes, rather than being exposed as less secure environment variables.
- Securing the Control Plane: The Kubernetes control plane, especially the API server and the etcd datastore, is the brain of the cluster. Access to it must be tightly controlled. This involves using firewalls to restrict network access to the API server from only trusted sources and ensuring that all communication between control plane components, and between the control plane and worker nodes, is encrypted using TLS.
Section 4: The Enterprise Platform Decision: A Comparative Analysis of Rancher, OpenShift, and Tanzu
Choosing an enterprise Kubernetes platform is one of the most consequential decisions an IT leader will make in their cloud-native journey. It is not merely a choice of technology but a long-term commitment to a specific operational philosophy, ecosystem, and support model. The three leading platforms-SUSE Rancher, Red Hat OpenShift, and VMware Tanzu-each offer a powerful but distinct approach to taming Kubernetes complexity at scale. The OpenShift Container Platform stands out as a comprehensive enterprise solution for deploying, managing, and scaling containerized applications, offering hybrid capabilities and deep integration with Kubernetes and Docker for enterprise environments. This section provides a deep, comparative analysis to help leaders align their strategic goals with the right enterprise platform. The choice of a platform is a proxy for a larger strategic decision about an organization's approach to open-source software, vendor relationships, and internal skill development.
4.1 Introduction: Three Philosophies for Taming Kubernetes
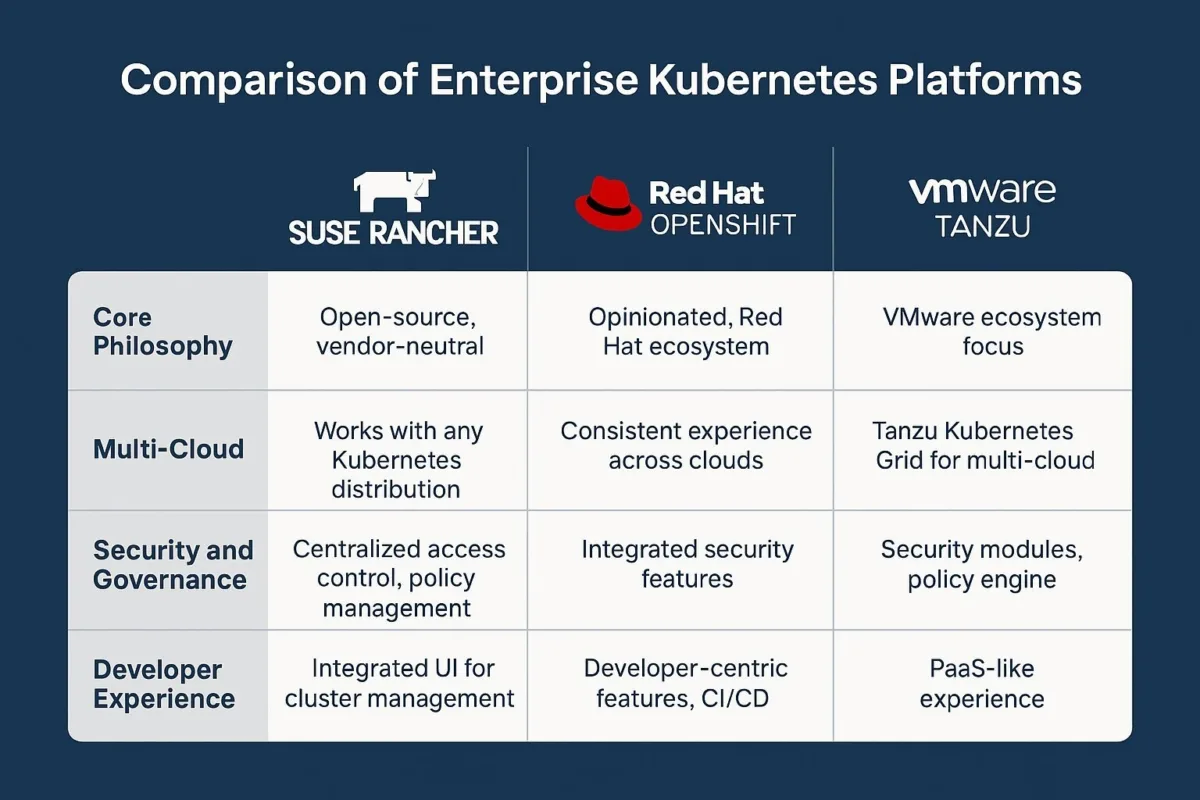
The core difference between these platforms lies in their fundamental design philosophy:
- SUSE Rancher: The Universal Management Plane. Rancher's philosophy is one of ultimate flexibility and abstraction. It is designed to be a single pane of glass for managing any CNCF-compliant Kubernetes cluster, regardless of where it runs-on-premises, in any public cloud, or at the edge. It embraces a "bring your own Kubernetes" model. A vote for Rancher is a vote for open-source integration and internal ownership of the stack.
- Red Hat OpenShift: The Secure, Opinionated Platform. OpenShift's philosophy is one of deep integration and security by default. It is not just a management layer but a complete, enterprise-grade Kubernetes distribution that comes with a full suite of developer-centric tools, stringent security controls, and comprehensive support out-of-the-box. A vote for OpenShift is a vote for a tightly integrated, secure, and fully supported "buy" solution over a "build" approach.
- VMware Tanzu: The vSphere-Native Powerhouse. Tanzu's philosophy is centered on extending the familiar VMware ecosystem into the cloud-native world. It is designed to provide a consistent operational model for managing both virtual machines and containers, leveraging existing investments and skillsets in vSphere, NSX, and vSAN. A vote for Tanzu is a vote to evolve the current data center operating model, prioritizing consistency for teams already deeply invested in VMware.
Some platforms also prioritize simplicity, making them especially appealing to small to medium-sized organizations or teams that need straightforward deployment and management without complex features.
4.2 Deep Dive: SUSE Rancher
- Strengths: Rancher's primary strength is its unparalleled flexibility in managing heterogeneous, multi-cloud, and hybrid-cloud environments. Its ability to seamlessly import and manage existing managed Kubernetes clusters (like Amazon EKS, Azure AKS, and Google GKE) alongside its own RKE2/K3s distributions provides maximum freedom and helps organizations avoid vendor lock-in. The core Rancher management platform is open-source and free to use, making it a highly cost-effective option, with commercial support from SUSE available as an optional subscription. Its centralized user interface is consistently praised for making the complex task of managing a fleet of clusters intuitive and efficient.
- Strategic Considerations: Rancher follows a "bring your own" or "à la carte" model for many of the ancillary services required for a complete platform. While it provides excellent integrations with a wide range of open-source and commercial tools for functions like CI/CD, security scanning, and service mesh (e.g., Istio), the enterprise is ultimately responsible for selecting, integrating, and maintaining this full stack. This approach offers maximum flexibility but may require a more mature and experienced platform engineering team compared to a fully integrated, all-in-one platform.
- Pricing Model: The core software is open-source. Paid offerings are primarily for enterprise support subscriptions, which are typically priced on a per-node or per-core basis. This model can be very cost-effective for organizations with the expertise to self-support the core platform.
4.3 Deep Dive: Red Hat OpenShift
- Strengths: OpenShift's dominant feature is its comprehensive, out-of-the-box approach to security and developer experience. It is a full-fledged Kubernetes distribution built on Red Hat Enterprise Linux CoreOS, with security embedded at every layer. Key security features include Security Context Constraints (SCCs) , which provide granular control over pod permissions, an integrated container registry (Quay) with built-in vulnerability scanning, and the optional Red Hat Advanced Cluster Security (RHACS) for runtime threat detection. For developers, it offers a rich, integrated experience with built-in CI/CD via OpenShift Pipelines (based on Tekton) and a powerful Source-to-Image (S2I) workflow that automates container builds directly from source code. As a fully integrated and commercially supported platform, it reduces the operational burden on internal teams. OpenShift is particularly well-suited for large enterprises that require a fully supported, secure, and integrated container platform, especially those with existing investments in Red Hat technologies.
- Strategic Considerations: The all-in-one nature of OpenShift is also its main strategic trade-off. It is a highly opinionated platform that replaces vanilla Kubernetes with its own distribution. This ensures consistency and reliability but can lead to significant vendor lock-in; migrating applications and operational practices away from the OpenShift ecosystem and its specific tooling can be a complex and costly endeavor. Its subscription-based pricing model is generally considered to be at a higher price point than Rancher's support-only costs.
- Pricing Model: OpenShift is sold via a subscription model, with pricing often based on the number of vCPUs or cores. Red Hat offers various editions, including self-managed options and fully managed cloud services like Red Hat OpenShift Service on AWS (ROSA) and Azure Red Hat OpenShift (ARO).
4.4 Deep Dive: VMware Tanzu
- Strengths: Tanzu's undeniable strength lies in its deep and native integration with the broader VMware software-defined data center (SDDC) stack. For the thousands of enterprises that have built their data centers on VMware vSphere, Tanzu offers a seamless and evolutionary path to modern, containerized applications. It allows IT administrators to manage Kubernetes clusters and namespaces directly from the familiar vSphere client, applying similar concepts like resource quotas and leveraging established technologies like vSAN for storage and NSX for networking and security. Tanzu delivers simplified operations for managing Kubernetes in vSphere environments by streamlining cluster deployment, reducing management complexity, and enabling faster, more efficient orchestration.
Tanzu Mission Control (TMC) provides a powerful centralized management plane for enforcing policies and maintaining visibility across a fleet of clusters, whether on-premises or in the public cloud.
- Strategic Considerations: The value proposition of Tanzu is most compelling for organizations already heavily invested in the VMware ecosystem. For enterprises without a significant VMware footprint, its unique advantages are less pronounced when compared to the multi-cloud flexibility of Rancher or the integrated developer experience of OpenShift. While Tanzu supports multi-cloud deployments, its "center of gravity" and deepest integrations remain with vSphere-powered private and hybrid clouds.
- Pricing Model: Tanzu's pricing is often perceived as complex and can be expensive. It is typically licensed on a per-CPU basis or bundled into various suites and larger enterprise license agreements (ELAs) with VMware. Offerings range from Tanzu Basic for running Kubernetes on vSphere to more advanced editions that include a full suite of developer and platform services.
4.5 Head-to-Head Strategic Comparison
The following table synthesizes the key differences between the three platforms across the strategic dimensions that are most critical for enterprise decision-making. Most teams prioritize ease of use and manageability when selecting an enterprise Kubernetes platform, making these features especially relevant in the comparison below.
| Strategic Dimension | SUSE Rancher | Red Hat OpenShift | VMware Tanzu |
|---|---|---|---|
| Core Philosophy | Universal Management Plane: Provides a single interface to manage any CNCF-compliant cluster, anywhere. Prioritizes flexibility and open-source integration. | Integrated Secure Platform: A complete, opinionated Kubernetes distribution with security and developer tools built-in. Prioritizes consistency and enterprise support. | vSphere-Native Powerhouse: Extends the VMware SDDC to the cloud-native world. Prioritizes a consistent operational model for existing VMware customers. |
| Multi-Cloud/Hybrid Strategy | Best-in-Class: Designed from the ground up to manage heterogeneous clusters across on-prem, edge, and multiple public clouds. Imports existing EKS, AKS, GKE clusters seamlessly. | Consistent Environment: Provides a consistent OpenShift environment across different infrastructures via managed services (ROSA, ARO) or self-managed deployments. Focus is on platform uniformity. | vSphere-Centric Hybrid: Excels at creating a hybrid cloud that bridges on-prem vSphere environments with public clouds. Deepest integration is with the VMware ecosystem. |
| Security & Governance Model | Flexible & Extensible: Provides foundational security (RBAC, Pod Security Standards) and integrates with external tools like OPA Gatekeeper for policy and Falco for runtime security. Requires more configuration. | Integrated & Prescriptive: Strongest out-of-the-box security. Features integrated OAuth, advanced OpenShift RBAC, Security Context Constraints (SCCs), built-in image scanning, and RHACS. | Ecosystem-Integrated: Strong security posture leveraging vSphere permissions, NSX for micro-segmentation, and Tanzu Mission Control for centralized policy management. |
| Developer Experience & CI/CD | Integration-Focused: Provides a clean UI and application catalog but relies on integrating external CI/CD tools like Jenkins or GitLab. Rancher Desktop offers a strong local development experience. | Developer-Centric: Offers a rich, out-of-the-box experience with OpenShift Pipelines (Tekton), Source-to-Image (S2I) builds, and a comprehensive developer console and OperatorHub. | Modernization-Focused: Tanzu Build Service (based on kpack) and Application Catalog streamline modern application delivery. Strong integration with the Spring framework. |
| Storage & Data Management | Open Choice: Includes the open-source Longhorn for distributed block storage and integrates with any standard CSI driver. Backup via Velero integration. | Integrated Solution: Offers OpenShift Data Foundation (based on Ceph and NooBaa) for unified block, file, and object storage. Backup via the OADP operator. | vSphere-Integrated: Natively leverages vSphere storage solutions like vSAN and vSphere File Services via a highly optimized CSI driver. Backup integrates with Velero and Veeam. |
| Ecosystem & Lock-in | Low Lock-in: As a management layer for standard Kubernetes, it offers the easiest path for migration and avoids tying operations to a specific distribution or toolset. | High Lock-in: The highly integrated and opinionated nature of the platform means that its specific tools and CRDs become deeply embedded in operational workflows, making migration difficult. | Ecosystem Lock-in: While it uses upstream Kubernetes, its primary value and deepest integrations are within the VMware ecosystem, creating a strong incentive to remain with VMware. |
| Ideal Enterprise Profile | Enterprises with a diverse, multi-cloud strategy, a strong internal platform engineering team, and a primary focus on flexibility and cost control. | Security-conscious enterprises, particularly those in regulated industries or already invested in the Red Hat ecosystem, who value an all-in-one, fully supported platform. | Enterprises with a significant existing investment in VMware infrastructure who are looking to modernize their applications and create a consistent hybrid cloud operating model. |
Table 2: Strategic Comparison of Enterprise Kubernetes Platforms
Section 5: The Baytech Consulting Perspective: Forging Your Path to Kubernetes at Scale
Successfully scaling Kubernetes is a strategic journey that extends far beyond the choice of a technology platform. It requires a holistic approach that integrates financial discipline, a forward-looking architectural vision, and a commitment to building the right people and processes. This concluding section provides Baytech Consulting's perspective on synthesizing these elements into a cohesive strategy, transforming Kubernetes from a complex operational challenge into a true engine for business innovation.
5.1 The Financial Imperative: Embracing Kubernetes FinOps
The staggering statistics on wasted cloud spend make it clear that cost optimization cannot be an afterthought; it must be a core operational discipline. Embracing a FinOps culture for Kubernetes means making cost a first-class metric, on par with performance and uptime. This involves three key pillars:
- Visibility and Allocation: The first step is to gain granular visibility into where money is being spent. This requires moving beyond high-level cloud bills to implement tools that can allocate costs to specific teams, projects, applications, or even individual features. This drives accountability and empowers teams to make cost-conscious decisions. A common obstacle to accurate allocation is incomplete or inconsistent labeling, making a standardized tagging strategy a critical prerequisite.
- Optimization: This pillar encompasses the technical strategies for reducing waste. It includes the continuous right-sizing of pods and nodes, but also more advanced techniques like leveraging Spot or Preemptible Instances for fault-tolerant workloads, which can offer savings of up to 90% over on-demand prices. It also means actively managing and optimizing network egress fees and storage costs by using appropriate storage tiers and cleaning up orphaned resources.
- Governance: Finally, robust governance automates cost control. This involves implementing policies to automatically shut down idle development and testing clusters after business hours, setting alerts for budget thresholds, and using quotas to prevent runaway resource consumption at the namespace level.
5.2 Synthesizing the Decision: A Framework for Choosing Your Platform
The analysis in Section 4 demonstrates that there is no single "best" Kubernetes platform; there is only the best platform for a specific organization's context, priorities, and culture. To navigate this decision, IT leaders should ask a series of strategic questions:
- Question 1: What is our existing infrastructure and ecosystem? The answer to this question often creates a strong gravitational pull. An enterprise with a massive investment in VMware virtualization and a deep bench of vSphere-skilled administrators will find the most seamless path with Tanzu . An organization that is a long-time Red Hat customer for its operating systems and middleware will see significant ecosystem benefits with OpenShift . An enterprise with a heterogeneous, multi-cloud environment and no single dominant infrastructure vendor will find the universal management capabilities of Rancher most aligned with its reality. Additionally, platforms that integrate seamlessly with other HashiCorp tools, such as Consul and Vault, offer a cohesive ecosystem for managing diverse workloads and simplifying application deployment and security across environments.
- Question 2: What is our primary strategic driver for this platform? If the paramount goal is maximum flexibility, avoiding vendor lock-in, and controlling costs by leveraging open-source software, Rancher is the natural choice. If the top priority is achieving the highest level of security and compliance out-of-the-box and accelerating developer velocity with a fully integrated toolchain, OpenShift presents the most compelling case. If the main driver is to leverage existing operational models and capital investments to create a consistent bridge from the traditional data center to the cloud, Tanzu is the logical path.
- Question 3: What is the maturity and philosophy of our platform engineering team? A highly skilled platform team that is comfortable with integration and wants the freedom to build a best-of-breed stack from various components will thrive with the flexibility of Rancher . A team that needs to deliver a secure, stable, and fully supported platform quickly, and prefers to offload the integration burden to a vendor, will be better served by the all-in-one nature of OpenShift or Tanzu .
5.3 Building a Center of Excellence: People, Process, and Technology
The chosen platform is a powerful tool, but it is only one component of a successful scaling strategy. Long-term success depends on building a Kubernetes Center of Excellence (CoE) that addresses people, process, and technology in a unified manner.
- People: The persistent skills gap is a real and significant threat to any Kubernetes initiative. Organizations must invest heavily in training and upskilling their teams. This also means fostering a collaborative culture where Development, Security, and Operations teams work together with shared goals and responsibilities-the essence of DevSecOps. To see how AI is transforming team roles and work styles, explore AI's impact on software development .
- Process: Technology alone cannot enforce good behavior. Success requires establishing clear, automated processes. Adopting GitOps as the standard for managing all infrastructure and application configurations is critical for ensuring a declarative, version-controlled, and auditable state, effectively combating configuration drift. This must be paired with well-defined governance policies for security, resource usage, and cost management. If you're curious about how organizations implement robust DevOps and GitOps, our DevOps efficiency services can help you get there.
- Technology: The technology choice-the platform and its surrounding ecosystem-should be made to support and enable the people and process strategies. The platform should reduce cognitive load for developers, automate repetitive tasks for operators, and provide the necessary visibility for security and finance teams.
5.4 Conclusion: Kubernetes as a Strategic Enabler
The journey to scaling Kubernetes in the enterprise is undeniably complex, fraught with challenges related to cost, operational fragility, and security. However, these challenges are not insurmountable. They are symptoms of a lack of a cohesive, top-down strategy.
When approached deliberately, Kubernetes transforms from a source of technical debt into a powerful platform for business acceleration. By mastering the foundational disciplines of scaling and resource management, architecting for resilience and security, and making an informed platform choice that aligns with organizational strategy, enterprises can unlock the true promise of cloud-native computing. A well-managed Kubernetes environment reduces risk, controls costs, and, most importantly, empowers development teams to deliver value to the business faster and more reliably. Choosing orchestration platforms that offer tight integration with cloud-native services-such as seamless connections to networking, storage, and security-further enhances deployment speed and reliability, especially for real-time data pipelines. This transformation is not just an IT upgrade; it is a fundamental driver of competitive advantage in the digital economy. Baytech Consulting stands ready to partner with enterprises to navigate this journey, ensuring that their Kubernetes investment yields maximum strategic value.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.