
A Deep Dive into Snowflake 2025
July 04, 2025 / Bryan ReynoldsSnowflake has emerged as a prominent player in the data management landscape, fundamentally reshaping how organizations approach data warehousing and analytics. Understanding its core concepts, architectural underpinnings, and market positioning is crucial for anyone navigating the modern data ecosystem.
1.1. What is Snowflake? A High-Level Overview
At its core, Snowflake is a data warehouse solution meticulously built upon cloud infrastructure, leveraging platforms such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). This cloud-native design immediately distinguishes it from traditional, on-premises data warehousing systems, allowing it to harness the inherent scalability, flexibility, and global reach of the cloud. The platform is engineered to mobilize an organization's data, power its applications, and facilitate artificial intelligence initiatives. It operates as a fully managed service, designed to securely connect businesses globally, regardless of the type or scale of their data.
The fundamental purpose of a Snowflake database is to serve as a centralized repository for an organization's structured and semi-structured data sets, making them readily available for processing and in-depth analysis. This capability allows businesses to consolidate diverse information streams into a single source of truth, paving the way for more informed decision-making.
The evolution of data management from simple storage to a comprehensive ecosystem for insight generation is reflected in Snowflake's self-perception. Its "AI Data Cloud" branding and its comprehensive suite of tools for diverse data workloads signify a deliberate strategy to be more than just an efficient data repository. This ambition aims to position Snowflake as the central nervous system for all data-driven activities within an enterprise, encompassing advanced analytics, AI model development, and data-intensive application hosting. This strategic direction has profound implications for its feature development roadmap, the markets it targets, and the competitive pressures it faces, particularly from platforms with strong AI/ML pedigrees like Databricks.
1.2. Core Concept: The AI Data Cloud and Its Significance
Snowflake strategically positions itself as an "AI Data Cloud" platform. This concept extends beyond traditional data warehousing, envisioning a comprehensive ecosystem that provides several key capabilities:
- Interoperable Storage: Offering unsiloed access to nearly infinite scales of data, including information residing outside Snowflake itself.
- Elastic Compute: Delivering high performance for any number of users, data volumes, and workloads through a single, scalable engine.
- Cortex AI: Accelerating enterprise AI by providing secure access to leading Large Language Models (LLMs) and enabling users to interact with their data using AI services.
- Cloud Services: Ensuring smooth operation through automations that minimize complex and costly resource investments.
- Snowgrid: Enabling global connectivity to data and applications across different regions and clouds with a consistent experience.
- Snowflake Horizon: A built-in governance solution for managing security, compliance, privacy, interoperability, and access.
- Snowflake Marketplace: Allowing users to discover and access critical data and applications, fostering collaboration within the AI Data Cloud network.
- Snowflake Partner Network: Providing partner services, tools, and integrations to assist with migration, optimization, and insight generation.
The platform is constructed upon a cloud-native architecture, deliberately unconstrained by the limitations of legacy technologies. This design enables a wide variety of workloads to operate seamlessly across different public clouds and geographic regions, handling near-unlimited amounts and types of data with low latency. The term "cloud-native" is significant; it implies that Snowflake was engineered from the ground up to capitalize on the inherent advantages of cloud computing, such as elasticity and distributed processing, unlike older systems that may have been retrofitted for cloud environments. This architectural choice is fundamental to its scalability and performance claims.
1.3. Snowflake as a Fully Managed SaaS Platform
Snowflake operates as a fully managed Software as a Service (SaaS) platform. In this model, Snowflake assumes responsibility for all aspects of software and hardware management, including updates, maintenance, security patching, and infrastructure upkeep. Users are thereby abstracted from the complexities of underlying system administration.
This SaaS delivery model is integral to Snowflake's value proposition of "near-zero management". Organizations are freed from the need to select, install, configure, or manage hardware or software. This significantly reduces the administrative overhead traditionally associated with data platforms, allowing technical teams to concentrate on extracting value from their data rather than on infrastructure maintenance. This approach not only lowers the barrier to entry for sophisticated data analytics but also contributes to a reduction in the total cost of ownership (TCO). The resources, both human and financial, that would have been allocated to platform upkeep can instead be directed towards innovation and business-impacting analyses. Consequently, powerful data capabilities become accessible to a broader spectrum of organizations, not just those with large, specialized IT departments.
Furthermore, the SaaS model provides a single, unified platform for a diverse range of data-related activities. These include traditional data warehousing, building data lakes, complex data engineering pipelines, advanced data science, the development of data-intensive applications, and the secure sharing and consumption of real-time or shared data. This versatility underscores Snowflake's ambition to serve as a comprehensive hub for all data operations within an enterprise.
2. Deconstructing Snowflake: Architecture and Core Components
Snowflake's innovative architecture is a key differentiator, enabling its core capabilities of scalability, performance, and ease of use. Understanding its layered design and the principles behind it is essential to grasping how Snowflake delivers its value proposition.

2.1. The Foundational Layers: Storage, Compute, and Cloud Services
Snowflake's architecture is uniquely structured into three distinct, independently scalable layers: Database Storage, Query Processing (Compute), and Cloud Services.
- Database Storage Layer: This layer is responsible for the persistent and efficient management of all data loaded into Snowflake. It is designed to be highly elastic, utilizing cloud-based object storage services provided by the underlying cloud platform (e.g., Amazon S3, Azure Blob Storage, Google Cloud Storage). Data within this layer is automatically organized into optimized, compressed, and encrypted micro-partitions, which are columnar in format. A critical aspect of this layer is its support for diverse data types, including structured (e.g., tables from relational databases), semi-structured (e.g., JSON, Avro, Parquet, XML), and increasingly, unstructured data. The use of cloud object storage ensures high durability, availability, and virtually limitless scalability for storage capacity. Micro-partitioning, along with the metadata collected about them, is a fundamental optimization that allows Snowflake to prune unnecessary data during query execution, significantly enhancing performance.
- Query Processing (Compute) Layer: This layer handles all data processing tasks and query execution. It consists of one or more "virtual warehouses," which are essentially Massively Parallel Processing (MPP) compute clusters. Each virtual warehouse operates independently, meaning it does not share its compute resources with other virtual warehouses. This isolation is crucial for preventing resource contention ("noisy neighbor" problems) and ensuring consistent performance for different workloads or user groups. Users can create multiple virtual warehouses of varying sizes (e.g., X-Small, Small, Large) and dedicate them to specific tasks, such as data loading, business intelligence queries, or data science workloads. The MPP architecture within each warehouse allows queries to be processed in parallel across multiple nodes, delivering high performance for complex analytical tasks.
- Cloud Services Layer: Often described as the "brain" or control plane of Snowflake, this layer coordinates and manages all activities across the platform. Its responsibilities are comprehensive and include:
- Metadata Management: Storing and managing all metadata about schemas, tables, micro-partitions, access control, and transaction logs.
- Security and Authentication: Enforcing security policies, managing user authentication, and controlling access to data and objects.
- Query Optimization and Compilation: Parsing SQL queries, generating optimal execution plans, and distributing tasks to the compute layer.
- Infrastructure Management: Managing the underlying virtual warehouses, coordinating storage operations, and ensuring the overall health and availability of the service.
- Transaction Management: Ensuring ACID properties for database transactions. This layer makes Snowflake a cohesive, fully managed service, abstracting away many of the complex administrative tasks that users would traditionally have to perform.
The three-layer architecture, and particularly the decoupling of these layers, is not merely a technical design choice but the foundational element that enables Snowflake's primary benefits. Traditional database architectures often bundled storage and compute, leading to inefficiencies: scaling compute resources meant also scaling, and paying for, potentially unneeded storage, or vice versa. Snowflake's design allows organizations to independently size and scale each dimension. If more storage capacity is needed due to data growth, the storage layer can expand without affecting compute costs. Conversely, if more processing power is required for intensive analytical queries, virtual warehouses in the compute layer can be scaled up, resized, or multiplied without altering the underlying storage or incurring additional storage costs beyond what is actually stored. This directly translates into significant cost savings, as users only pay for the resources they consume in each dimension, and it enhances performance by allowing dedicated compute resources to be allocated to specific workloads, thereby preventing interference and ensuring predictable query execution times. The Cloud Services layer further enhances this model by automating many management tasks, reducing the operational burden on users and contributing to the platform's overall ease of use.
2.2. Key Architectural Differentiator: Separation of Storage and Compute

The complete separation of storage and compute resources is arguably Snowflake's most significant architectural innovation and a cornerstone of its design philosophy. As outlined above, this decoupling means that the physical storage of data and the computational resources used to process that data are not inherently tied together.
This separation empowers organizations with unprecedented flexibility and cost-efficiency. They can scale their storage capacity up or down based on data volume growth or retention policies, without any direct impact on their compute resources or costs. Similarly, they can scale their compute power-by resizing existing virtual warehouses, adding more warehouses, or utilizing multi-cluster warehouses-to handle fluctuating query loads or concurrent user demands, without altering the amount of data stored or paying for idle compute when demand is low. For instance, a company might require massive compute power for a few hours during month-end reporting but minimal compute for the rest of the time; Snowflake's architecture accommodates this variability efficiently. This ability to independently manage and pay for storage and compute eliminates the common problem of over-provisioning resources, which is often a necessity in tightly coupled systems to handle peak loads.
2.3. Hybrid Approach: Shared-Disk and Shared-Nothing Principles
Snowflake's architecture cleverly combines elements from two traditional database architectural paradigms: shared-disk and shared-nothing systems.
- In a shared-disk architecture, all compute nodes or processors have access to a single, centralized data repository. Snowflake mirrors this by having all its virtual warehouses (compute clusters) access data from the central Database Storage Layer. This simplifies data management, as there's a single source of truth, and data doesn't need to be redistributed or partitioned across compute nodes permanently.
- In a shared-nothing architecture, each node has its own private memory and disk, and data is partitioned across these nodes. Queries are processed in parallel by nodes working on their local portion of the data. Snowflake incorporates this principle in its Query Processing Layer. When a query is executed, each node within a virtual warehouse processes a portion of the required data (which it fetches from the central storage layer as needed and may cache locally). This MPP approach enables high levels of parallelism and scalability for query execution.
This hybrid design aims to capture the "best of both worlds": the data management simplicity and consistency of a shared-disk system, combined with the performance, scalability, and fault tolerance benefits of a shared-nothing system.
2.4. Snowgrid: Enabling Cross-Cloud and Cross-Region Capabilities
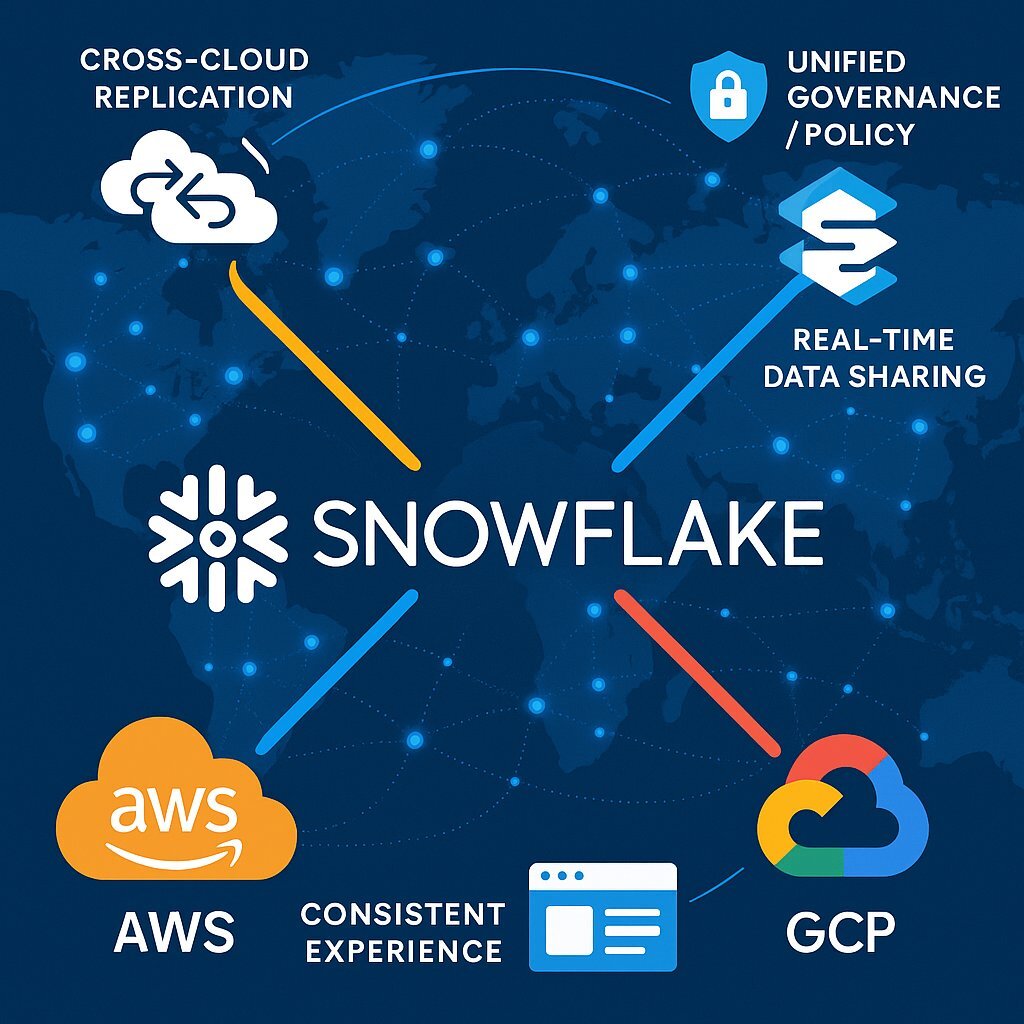
Snowgrid is Snowflake's underlying technology layer designed to provide a seamless and consistent experience for data and applications across different public cloud providers (AWS, Azure, GCP) and various geographic regions. It is the fabric that enables Snowflake's multi-cloud and cross-cloud vision.
Snowgrid facilitates several critical functionalities:
- Cross-Cloud Data Replication: Allows organizations to replicate data between Snowflake accounts running on different cloud providers or in different regions for disaster recovery, business continuity, or data locality purposes.
- Global Data Sharing and Collaboration: Enables secure data sharing and collaboration across cloud and regional boundaries.
- Workload Portability: Allows workloads to be run consistently, irrespective of the underlying cloud or region.
- Unified Governance: Helps maintain consistent governance and security policies across a distributed data landscape.
The introduction and evolution of Snowgrid represent a significant strategic capability for Snowflake, elevating it from a single-instance data warehouse solution to a potentially globally distributed data platform. This is particularly crucial for large multinational enterprises that often operate in multiple geographic regions and may employ multi-cloud strategies due to regulatory requirements, a desire to leverage best-of-breed services from different cloud providers, or as a result of mergers and acquisitions. Managing data consistently, securely, and efficiently across such distributed and heterogeneous environments is a major challenge. Snowgrid aims to address this by providing a unified technological layer that simplifies data replication, ensures consistent governance, and enables workload mobility across various clouds and regions. This makes Snowflake a more compelling and viable option for complex enterprise deployments and aligns strategically with the growing industry trend towards multi-cloud architectures, positioning Snowflake as a potential central data fabric that can span an organization's entire cloud footprint.
The synergy between intelligent data organization in the storage layer and parallel execution in the compute layer is fundamental to Snowflake's ability to deliver fast query speeds, particularly for the complex analytical workloads prevalent in modern data-driven organizations. Micro-partitioning, a feature of Snowflake's storage layer, automatically divides table data into small, immutable, and compressed columnar blocks. Extensive metadata is stored for each micro-partition, including the range of values for each column within that partition. During query processing, Snowflake's optimizer uses this metadata to perform "pruning," effectively identifying and scanning only the micro-partitions relevant to the query, thereby drastically reducing the amount of data that needs to be read from storage and processed. This significantly cuts down on I/O operations. Concurrently, the Massively Parallel Processing (MPP) architecture of the virtual warehouses in the compute layer distributes the execution of the query across multiple compute nodes. Each node works on a subset of the relevant micro-partitions in parallel. This combination of minimizing data scanned (via micro-partition pruning) and maximizing parallel processing (via MPP) is what enables Snowflake to achieve high performance on large datasets and complex analytical queries.
3. Snowflake in Action: Key Features and Functionalities
Snowflake's architecture translates into a rich set of features and functionalities designed to address the diverse needs of modern data operations, from ensuring high performance and scalability to simplifying data management and enabling advanced analytics.
3.1. Scalability and Elasticity: On-Demand Resource Allocation
A hallmark of Snowflake is its ability to provide near-limitless compute resources that are available on demand, coupled with automatic scaling capabilities that adjust resources up or down based on actual usage. This elasticity means the platform can dynamically adapt to fluctuating workloads. For instance, if there's a sudden surge in query volume or data processing needs, Snowflake can automatically allocate more compute resources to maintain performance. Conversely, when demand subsides, these resources can be scaled down or suspended to conserve costs. The platform's single-engine design also aims to eliminate concurrency issues, allowing many users and queries to run simultaneously without degrading performance.
Virtual warehouses, the compute clusters within Snowflake, are central to this scalability. They can be resized on-the-fly—for example, changing from a 'Small' to a 'Large' warehouse to accelerate a complex query—often without interrupting ongoing operations. Furthermore, virtual warehouses can be configured to auto-scale, where Snowflake automatically adds or removes compute clusters within a warehouse based on the query load and concurrency. This provides granular control, allowing organizations to precisely match compute power (and thus cost) to the specific demands of different workloads, ensuring optimal performance when needed and cost savings during periods of lower activity.
3.2. Data Handling: Support for Structured, Semi-Structured, and Unstructured Data
Snowflake exhibits significant versatility in its ability to store and process a wide range of data types. This includes:
- Structured Data: Traditional relational data organized into tables with predefined schemas, such as data from transactional systems or relational databases.
- Semi-Structured Data: Data that does not conform to a rigid relational schema but has some organizational properties, such as JSON, XML, Avro, Parquet, and ORC files. Snowflake provides native support for ingesting, storing, and querying these formats directly using SQL extensions.
- Unstructured Data: Data that lacks a predefined format, such as images, videos, audio files, and PDFs. While direct querying of unstructured data content has limitations, Snowflake is enhancing its capabilities in this area, for example, by allowing processing of such data using external functions or through features like Snowpark Container Services, which enable custom code execution within the Snowflake environment.
This ability to handle diverse data formats within a single platform is crucial for modern data strategies. It allows organizations to consolidate data from various sources, breaking down silos that often exist between systems handling different data types. This unified approach enables more comprehensive analytics and a holistic view of business operations. Snowflake's strong native support for semi-structured data, in particular, has been a key differentiator, simplifying the process of working with modern data sources like IoT devices, weblogs, and mobile applications.
3.3. Powerful Data Management
Snowflake incorporates several powerful data management features that enhance data protection, operational efficiency, and collaboration.
3.3.1. Time Travel and Fail-Safe: Data Recovery and Historical Access
- Time Travel: This feature allows users to access historical versions of data within tables, schemas, or entire databases that may have been modified or deleted. The retention period for Time Travel is configurable, ranging from 1 day (Standard Edition) up to 90 days (Enterprise Edition and above). This capability is invaluable for several scenarios:
- Recovering from accidental data modifications or deletions (e.g., an erroneous
UPDATEorDELETEstatement) without resorting to traditional, often slow, backup and restore procedures. - Auditing data changes over time to understand how data has evolved.
- Analyzing historical trends or comparing data snapshots from different points in time.
- Recovering from accidental data modifications or deletions (e.g., an erroneous
- Fail-Safe: Complementing Time Travel, Fail-Safe provides an additional, non-configurable 7-day period during which historical data may be recoverable by Snowflake support in the event of critical operational failures, such as hardware failures or other systemic issues. This acts as a final safety net for disaster recovery, ensuring that data is not permanently lost even after the configured Time Travel window has expired.
These features, particularly Time Travel and Zero-Copy Cloning, are more than mere conveniences; they serve as significant operational accelerators. In traditional data environments, recovering from accidental data corruption or deletion can be a complex and time-consuming process, often involving database administrators restoring from backups, which can lead to significant downtime and data loss. Snowflake's Time Travel allows users (with appropriate permissions) to query or restore previous states of data almost instantaneously using simple SQL commands, drastically reducing recovery time and mitigating the impact of such incidents. Similarly, setting up development, testing, or quality assurance environments in traditional systems often requires physically copying large datasets, a process that is both time-intensive and consumes considerable storage resources. Snowflake's Zero-Copy Cloning enables the creation of full, writable copies of databases, schemas, or tables in seconds, with minimal initial storage overhead because the clone initially shares the underlying storage with the original and only stores the differences as changes are made. This means developers can iterate more rapidly, testers have immediate access to fresh, production-like data, and data engineers can experiment with transformations or new pipelines without impacting production systems. Collectively, these capabilities lead to faster innovation, reduced operational friction, and lower risk.

3.3.2. Zero-Copy Cloning: Instantaneous Data Duplication
Zero-Copy Cloning allows for the creation of nearly instantaneous copies (clones) of tables, schemas, or even entire databases without physically duplicating the underlying data at the time of creation. When a clone is made, it is essentially a logical copy that shares the same underlying micro-partitions as the original object. The clone only incurs storage costs for new or modified data; unchanged data continues to be referenced from the original source. This process is exceptionally fast and storage-efficient.
This feature is extremely beneficial for:
- Development and Testing: Quickly provisioning isolated development or test environments with production-like data.
- Data Analysis and Experimentation: Allowing data scientists or analysts to work on a snapshot of data without impacting the production environment.
- Backup and Archival (Short-Term): Creating quick snapshots before major data transformations.
3.3.3. Secure Data Sharing: Collaboration Without Data Movement
Secure Data Sharing is a flagship feature of Snowflake, enabling organizations to share live, read-only data with other Snowflake accounts, both internally within the organization and externally with partners, customers, or data providers, without the need to create copies or move data. The sharing mechanism is managed through Snowflake's Cloud Services layer and its metadata store. Data providers maintain full control over their data, granting specific privileges to consumers. Consumers, in turn, can query the shared data as if it resided in their own account, and they only pay for the compute resources (virtual warehouse usage) consumed while querying the shared data; the storage costs remain with the data provider.
This capability represents a paradigm shift for data monetization and collaboration. Traditional methods of sharing data, such as ETL processes, API integrations, or FTP transfers, invariably involve creating multiple copies of data. This not only increases storage costs but also introduces data latency, security risks, and significant governance challenges in keeping these disparate copies synchronized and secure. Snowflake's Secure Data Sharing model bypasses these issues by allowing data providers to share live, governed data directly from their own accounts. Consumers access this data in real-time, ensuring they are always working with the most up-to-date information. This has paved the way for new business models, such as data providers offering datasets for sale or subscription via the Snowflake Marketplace. It also enables seamless collaboration between business partners on joint datasets and allows organizations to easily enrich their internal data with third-party sources. This fosters a powerful network effect: the more organizations and datasets participate in the Snowflake Data Cloud, the more valuable the ecosystem becomes for all its members.
3.4. Security and Governance: A Multi-Layered Approach
Snowflake places a strong emphasis on security and governance, implementing a multi-layered approach to protect data and ensure compliance. Key security features include:
- Authentication: Support for various authentication methods, including standard username/password credentials, Multi-Factor Authentication (MFA), federated authentication with Single Sign-On (SSO) through identity providers like Okta or Azure AD, OAuth for application integration, and key-pair authentication for programmatic access.
- Access Control: Granular access control is enforced through a Role-Based Access Control (RBAC) model. Permissions can be granted on various database objects (databases, schemas, tables, views, warehouses, etc.) to roles, which are then assigned to users.
- Encryption: All data stored in Snowflake is automatically encrypted at rest using strong encryption algorithms (e.g., AES-256). Data is also encrypted in transit using TLS. Higher editions (Business Critical and VPS) offer customer-managed encryption keys (e.g., via AWS Key Management Service, Azure Key Vault, Google Cloud KMS) for enhanced control.
- Network Security: Options for network policies to restrict access based on IP addresses, and support for private connectivity (e.g., AWS PrivateLink, Azure Private Link, Google Cloud Private Service Connect) to isolate traffic from the public internet, available in higher editions.
- Compliance Certifications: Snowflake maintains various industry-standard compliance certifications, such as SOC 2 Type II, and depending on the edition and region, can support compliance with regulations like HIPAA (for healthcare data) and PCI DSS (for payment card information).
- Snowflake Horizon (features in preview): This is Snowflake's integrated governance solution, designed to provide a unified set of capabilities for managing data compliance, security posture, data privacy, interoperability across data assets, and fine-grained access controls within the Data Cloud.
This comprehensive security framework is designed to address a wide range of threat vectors and meet the stringent data protection and compliance requirements of modern enterprises, thereby building trust and enabling organizations to confidently store and process sensitive information within the platform. The development of Snowflake Horizon signals a deeper commitment to providing robust, built-in governance tools, which are increasingly critical as data volumes and regulatory scrutiny grow.
3.5. Extensibility: SQL Support, Snowpark, Cortex AI, Connectors

Snowflake offers multiple avenues for extending its functionality and integrating with broader data ecosystems:
- Standard and Extended SQL Support: Snowflake provides comprehensive support for ANSI SQL, including most Data Definition Language (DDL) and Data Manipulation Language (DML) operations defined in SQL:1999. It also supports advanced DML (e.g., multi-table
INSERT,MERGE), transactions, materialized views, User-Defined Functions (UDFs), stored procedures (via Snowflake Scripting), and native support for geospatial data types and functions. This strong SQL foundation makes the platform readily accessible to a vast pool of data professionals familiar with SQL. - Snowpark: This is a developer framework that allows data engineers, data scientists, and application developers to write data processing logic in familiar programming languages like Python, Java, and Scala. This code executes directly within Snowflake's processing engine, running on the same virtual warehouses used for SQL queries. Snowpark enables more complex data transformations, feature engineering for machine learning, and the development of data-intensive applications that can leverage Snowflake's scalability and performance without moving data out of the platform.
- Snowflake Cortex (features in preview): This is an intelligent, fully managed service integrated into Snowflake, designed to provide users with easy access to industry-leading Large Language Models (LLMs) and vector functions. It aims to enable users to quickly and securely analyze data and build AI-powered applications directly on their data within Snowflake.
- Connectors and Drivers: Snowflake provides an extensive set of client connectors and drivers for popular programming languages and development environments, including Python, Spark, Node.js, Go,.NET, JDBC, and ODBC. This facilitates integration with a wide array of business intelligence (BI) tools, ETL/ELT platforms, data science frameworks, and custom applications. Snowflake also boasts a broad ecosystem of third-party partner technologies that integrate with its platform.
- Snowpark Container Services (features in preview): This offering allows users to deploy, manage, and scale containerized applications (e.g., Docker containers) natively within the Snowflake environment. This significantly expands Snowflake's extensibility, enabling almost any custom code, pre-packaged software, or specialized application to run securely alongside the data in Snowflake, further reducing data movement and simplifying architectures.
The introduction and ongoing development of Snowpark and Snowflake Cortex represent a clear strategic direction for Snowflake. These initiatives aim to move the platform beyond its traditional strengths in SQL-based data warehousing and establish it as a central hub for a much broader range of data science and AI/ML workloads. As the value derived from data is increasingly unlocked through sophisticated AI and machine learning techniques, platforms that only store and query data risk being commoditized if the computationally intensive AI/ML tasks must occur elsewhere. By enabling code in languages like Python, Java, and Scala (via Snowpark) and providing direct access to LLMs and AI functionalities (via Cortex AI) to operate directly on data residing within Snowflake, the company seeks to capture these high-value workloads. This not only enhances the platform's capabilities but also positions Snowflake to compete more directly with platforms like Databricks, which have strong roots in the AI/ML space. For users, this means the potential to unify their data analytics and AI initiatives on a single platform, simplifying data pipelines and accelerating the path from data to insight to AI-driven action. This also addresses a historical limitation where complex non-SQL transformations or machine learning model training often had to be performed outside of Snowflake, requiring data movement and additional infrastructure.
4. Understanding Snowflake's Value Proposition
Snowflake's rapid adoption across various sectors can be attributed to its ability to solve critical data challenges and deliver tangible business value. Its platform is designed to cater to a diverse range of users and use cases, from traditional analytics to modern AI-powered applications.
4.1. Who Uses Snowflake? Target Industries and Departments
Snowflake's flexible architecture and comprehensive feature set have led to its adoption across a wide spectrum of industries. These include, but are not limited to:
- Advertising, Media & Entertainment
- Financial Services
- Healthcare & Life Sciences
- Manufacturing
- Public Sector
- Retail & Consumer Packaged Goods (CPG)
- Technology
- Telecommunications.
This broad applicability stems from its core capabilities: handling massive data volumes efficiently, supporting diverse data types (structured, semi-structured, and increasingly unstructured), and providing highly scalable compute resources that can be tailored to specific workload demands.
Within organizations, Snowflake offers solutions that address the specific needs of various departments. For example:
- Marketing departments leverage Snowflake for use cases such as building comprehensive Customer 360 views, modernizing Customer Data Platforms (CDPs), enabling campaign intelligence, and performing audience targeting by segmenting consumers based on behavioral and demographic data.
- IT departments utilize Snowflake for data consolidation, infrastructure modernization, and simplifying data management.
- Finance departments use it for financial analytics, reporting, and risk management.
- Cybersecurity teams can employ Snowflake for analyzing security logs and threat detection.
The platform is designed to be accessible and valuable to a range of technical roles, including data engineers who build and maintain data pipelines, data scientists who develop machine learning models and perform advanced analytics, business analysts who rely on SQL for querying and reporting, and application developers who build data-intensive applications. The versatility in handling diverse data types and supporting various workloads is a direct consequence of its flexible architecture. This allows Snowflake to target a large addressable market, as its foundational capabilities can be adapted to solve specific problems across many different business contexts.
4.2. Common Use Cases: From Analytics to AI-Powered Applications
Snowflake supports a multitude of use cases that span the entire data lifecycle:
- Analytics: This remains a core use case, with Snowflake enabling faster and more efficient data analytics. Its architecture is optimized for analytical queries, and its "near-zero maintenance" aspect reduces the operational burden associated with traditional data warehouses.
- Artificial Intelligence and Machine Learning (AI/ML): Snowflake is increasingly being used for AI/ML workloads. Features like Snowpark and the upcoming Snowflake Cortex allow organizations to securely build, train, and deploy LLMs and other machine learning models, often customized with their own proprietary data, directly within the platform.
- Data Engineering: The platform facilitates the construction of reliable, scalable, and continuous data pipelines. Data engineers can use SQL or other programming languages like Python, Java, or Scala (via Snowpark) to ingest, transform, and prepare data for various downstream uses.
- Applications & Collaboration: Snowflake enables the development, distribution, and scaling of data-intensive applications. Its secure data sharing capabilities also allow organizations to share live data across different clouds and with external partners or customers, fostering collaboration and new business opportunities.
- Customer 360: A prominent use case involves creating a unified, 360-degree view of the customer. This typically includes unifying disparate business and customer data from various sources (CRMs, transactional systems, websites, etc.), enriching customer profiles with first-party and third-party data (often sourced from Snowflake Marketplace), resolving customer identities across different touchpoints, and managing data consent to enhance customer experiences and comply with privacy regulations.
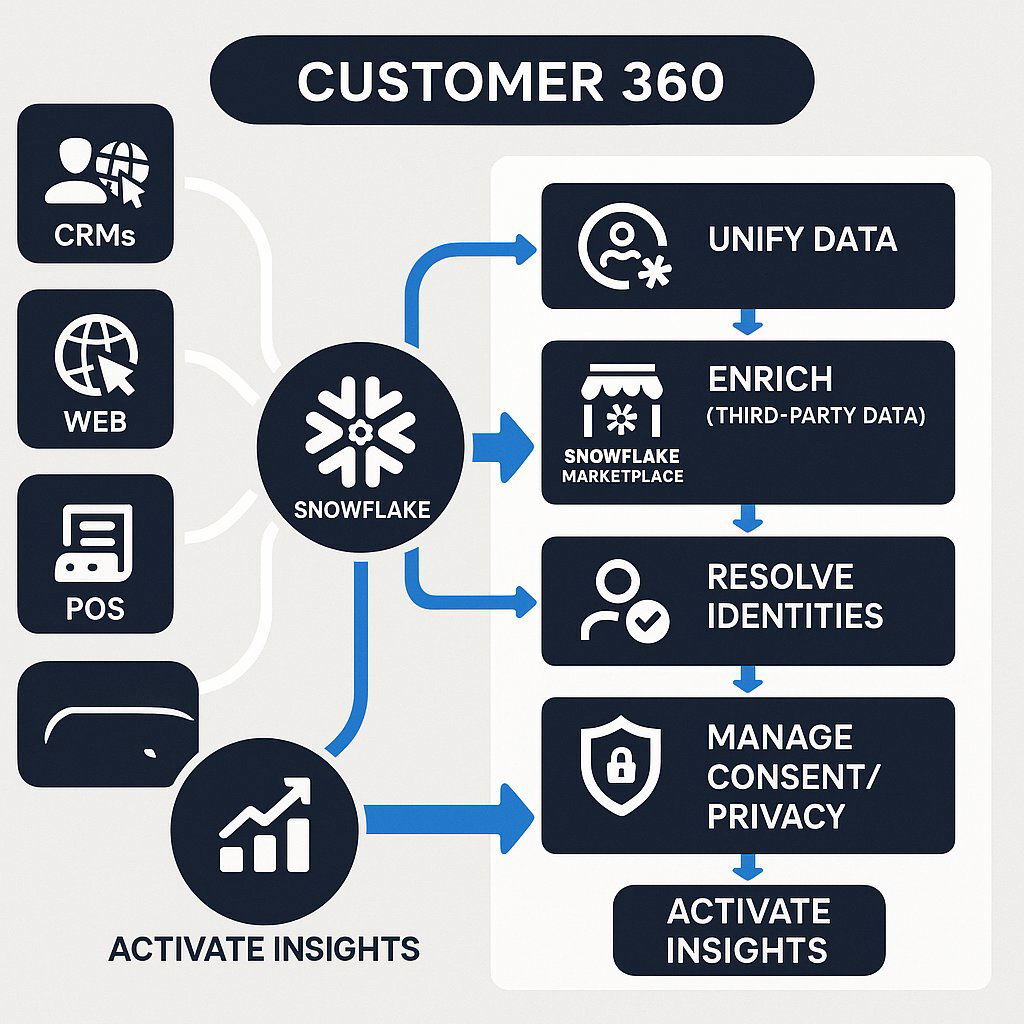
These diverse use cases demonstrate how Snowflake's features translate into tangible business value, supporting everything from traditional business intelligence and reporting to the development of cutting-edge AI applications and participation in collaborative data ecosystems. The "Customer 360" use case is a particularly strong example of how multiple Snowflake capabilities converge to address a complex business requirement. Building such a holistic customer view necessitates ingesting data from a multitude of systems, a task facilitated by Snowflake's support for diverse data types and its rich set of connectors. Enriching these customer profiles often involves leveraging third-party datasets, which can be seamlessly accessed via the Snowflake Marketplace. Resolving customer identities across various interactions and platforms, a critical step, can be accomplished using native applications or partner tools operating within the Snowflake environment. Crucially, managing customer consent and adhering to privacy regulations like GDPR is paramount, and Snowflake's governance features are designed to support these requirements. Finally, activating these comprehensive customer insights often involves sharing data with marketing automation platforms or sales systems, a process streamlined by Snowflake's secure data sharing capabilities. Thus, delivering a Customer 360 solution is not reliant on a single feature but is rather an outcome of the synergistic combination of many of Snowflake's core strengths, underscoring its power as an integrated data platform.
4.3. Business Problems Solved by Snowflake
Snowflake's market appeal lies in its ability to address common and often critical challenges faced by organizations striving to become more data-driven:
- Eliminating Data Silos: Traditional IT environments often suffer from data silos, where information is locked within disparate systems, making comprehensive analysis difficult. Snowflake helps break down these silos by supporting a wide variety of data types and providing a unified platform for data consolidation and integration.
- Addressing Scalability Issues: Many legacy systems struggle to cope with growing data volumes and increasing query complexity, leading to performance bottlenecks. Snowflake's architecture, with its independent scaling of storage and compute, offers "flawless scalability" to adapt to these demands. Its auto-scaling capabilities ensure that resources can dynamically adjust to fluctuating workloads without manual intervention.
- Improving Performance: Slow query performance and delayed results can hinder timely decision-making. Snowflake's Massively Parallel Processing (MPP) architecture is designed to deliver speed and high performance, even for complex queries executed on very large datasets.
- Enhancing Data Security and Compliance: In an era of increasing cyber threats and stringent data privacy regulations, robust security is paramount. Snowflake provides advanced data security features, including end-to-end encryption, role-based access control (RBAC), multi-factor authentication (MFA), and network policies. It also supports compliance with various industry standards such as HIPAA, GDPR, and SOC 2, helping businesses manage sensitive data securely.
- Simplifying Data Integration: Integrating data from diverse sources can be a complex and time-consuming task. Snowflake's ability to seamlessly integrate with numerous third-party tools, cloud storage services, and business applications, along with its support for various structured and semi-structured data formats (e.g., JSON, Avro, Parquet), simplifies the process of ingesting data into a unified platform. This facilitates real-time data sharing and collaboration across different departments.
- Optimizing Cost Efficiency: Traditional on-premises data management solutions often require significant upfront investments in hardware and software, coupled with ongoing maintenance costs. Snowflake's cloud-native design eliminates the need for such costly on-premises infrastructure. Its pay-for-use pricing model, where organizations are charged only for the storage capacity and compute resources they actually consume, can lead to a significant reduction in operational expenses compared to traditional systems.
While Snowflake's primary value proposition centers on solving these fundamental data challenges, its usage-based pricing model, though offering flexibility, also places the responsibility of cost control squarely on the user. The ease with which resources can be provisioned and complex queries executed can, if not managed diligently, lead to unexpectedly high operational costs. This underscores the importance for organizations to implement robust governance and monitoring practices to ensure that the economic benefits of Snowflake's model are fully realized. This dynamic also fosters an ecosystem for third-party cost optimization tools and services designed to help Snowflake customers manage their expenditures more effectively.
5. Navigating Snowflake's Commercial Landscape: Editions and Pricing
Understanding Snowflake's various product editions and its nuanced pricing model is crucial for organizations evaluating the platform. The choice of edition impacts available features and cost, while the pricing model dictates how expenses are incurred based on resource consumption.

5.1. Snowflake Editions: Standard, Enterprise, Business Critical, and VPS
Snowflake offers four primary commercial editions, each tailored to meet different organizational requirements in terms of functionality, security, compliance, and, consequently, price. These editions represent a tiered approach, allowing customers to select the offering that best aligns with their specific needs and budget.
- Standard Edition: This is Snowflake's entry-level offering. It provides access to all core Snowflake features, including its unique architecture, support for various data types, standard SQL capabilities, and data sharing. A key feature at this level is Time Travel for up to 1 day, allowing recovery of data from accidental modifications or deletions within that window. This edition is generally suitable for smaller businesses or organizations with moderate data warehousing needs and without stringent, advanced security or compliance mandates.
- Enterprise Edition: Building upon the Standard Edition, the Enterprise Edition introduces features designed for larger-scale enterprises and more complex data governance requirements. Notable additions include:
- Multi-cluster Warehouses: Enables automatic scaling of compute resources to handle high concurrency and fluctuating query loads.
- Extended Time Travel: Increases the data retention period for Time Travel up to 90 days.
- Materialized Views: Pre-computed views that can improve query performance for common and complex queries.
- Enhanced Security: Features like column-level security (dynamic data masking) and row-level security (row access policies) for more granular data access control.
- Business Critical Edition: This edition is specifically designed for organizations that handle highly sensitive data and require advanced data protection and compliance capabilities. It includes all features of the Enterprise Edition, plus:
- Enhanced Security and Compliance: Support for customer-managed encryption keys (Tri-Secret Secure), options for private connectivity to the Snowflake service (e.g., AWS PrivateLink, Azure Private Link, Google Cloud Private Service Connect), and features to help meet compliance standards such as HIPAA (for healthcare data), PCI DSS (for financial data), and FedRAMP (for public sector workloads).
- Database Failover and Failback: Provides enhanced business continuity and disaster recovery by allowing replication and failover of databases across different regions or cloud providers.
- Virtual Private Snowflake (VPS): This is the premium edition, offering the highest level of security and data isolation. VPS provides a completely separate Snowflake environment, including dedicated metadata storage and compute resources, isolated from all other Snowflake accounts. This edition is typically chosen by organizations with the most stringent security and regulatory requirements, such as large financial institutions or government agencies, where complete data isolation is paramount.
5.2. The Snowflake Pricing Model Explained

Snowflake employs a granular, usage-based pricing model, where customers are billed per second for the resources they consume. The costs are primarily broken down into three main components: compute, storage, and cloud services.
5.2.1. Compute Costs (Virtual Warehouses and Credits)
Compute resources in Snowflake are provisioned through "virtual warehouses." The consumption of these compute resources is measured in "Snowflake Credits".
- A virtual warehouse only consumes credits when it is actively running and processing queries or performing other tasks (e.g., data loading). When a warehouse is suspended or idle, it does not incur compute charges.
- The number of credits consumed per hour is directly proportional to the "size" of the virtual warehouse. Snowflake offers various T-shirt sizes for warehouses (e.g., X-Small, Small, Medium, Large, X-Large, up to 6XL), with each successively larger size typically doubling the compute power and the credits consumed per hour. For example, an X-Small warehouse might consume 1 credit per hour, a Small 2 credits, a Medium 4 credits, and so on.
- Billing for compute is done on a per-second basis. However, there is a minimum charge of 60 seconds' worth of credits each time a virtual warehouse is started, resumed from a suspended state, or resized. After this initial minute, subsequent usage is billed per second as long as the warehouse runs continuously.
- The actual monetary cost of a Snowflake Credit is not fixed; it varies depending on several factors: the chosen Snowflake Edition (Standard, Enterprise, etc., with higher editions generally having a higher per-credit cost), the cloud provider (AWS, Azure, or GCP), the geographic region where the Snowflake account is hosted, and the pricing plan (On-Demand vs. Pre-Purchased Capacity, where pre-purchasing capacity often comes with discounted credit rates). For instance, on-demand credit prices can range from $2.00-$3.10 for Standard Edition to $6.00-$9.30 for VPS, with variations based on region.
Compute costs are typically the largest component of a Snowflake bill, often accounting for around 80% of the total. Therefore, understanding and optimizing virtual warehouse usage—such as choosing appropriate sizes, implementing auto-suspend policies for idle warehouses, and efficient query writing—is critical for effective cost management.
5.2.2. Storage Costs
Snowflake charges for data storage based on the average daily volume of compressed data (measured in terabytes, TB) stored within the platform. This includes data in database tables, as well as historical data retained for Time Travel and Fail-Safe purposes. Snowflake automatically compresses all data, and the storage charges are calculated based on this compressed file size.
The monthly charge for storage is typically a flat rate per TB. However, this rate can vary based on:
- Account Type: On-Demand storage is generally more expensive than storage under a Pre-Purchased Capacity plan.
- Cloud Provider and Region: The specific cloud provider (AWS, Azure, GCP) and the geographic region where the data is stored influence the per-TB rate. For example, storage in AWS US regions might be around $23 per TB per month, while other regions or providers could have different rates.
While storage costs are generally more predictable than compute costs, they can accumulate significantly with very large data volumes, long data retention policies for Time Travel, and extensive use of features like Zero-Copy Cloning if clones diverge substantially from their originals over time.
5.2.3. Cloud Services and Serverless Feature Costs
The Cloud Services layer of Snowflake—which handles tasks like metadata management, query optimization, security enforcement, and transaction coordination—also consumes underlying compute resources and, therefore, can incur credit charges.
However, Snowflake has a notable policy regarding Cloud Services costs: customers are generally only billed for Cloud Services usage if it exceeds 10% of their daily compute credit usage (from virtual warehouses). If the Cloud Services consumption is within this 10% threshold, it is typically not charged separately. Most customers may not incur direct charges for Cloud Services due to this policy, unless their workloads consist of a very large number of small, quick queries, which can have a higher ratio of Cloud Services overhead relative to virtual warehouse compute time.
Several "serverless" features in Snowflake also consume credits. These features operate on Snowflake-managed compute resources rather than user-managed virtual warehouses. Examples include:
- Snowpipe: For continuous micro-batch data ingestion.
- Automatic Clustering: For maintaining optimal clustering of data in large tables.
- Materialized Views (maintenance): For automatically refreshing materialized views.
- Search Optimization Service: For accelerating point lookup queries.
- Serverless Tasks: For scheduled SQL execution. These serverless features consume credits based on their actual compute utilization, often with specific multipliers applied to the standard credit rate. For example, the Search Optimization Service and Materialized View maintenance might incur a 2x credit multiplier, while Snowpipe Streaming might be at 1x.
5.2.4. Data Transfer Costs
Data transfer costs in Snowflake depend on the direction of data movement, the cloud provider, and the geographic regions involved.
- Data Ingress: Generally, there is no charge for ingesting data into Snowflake from cloud storage services (like Amazon S3, Azure Blob Storage, Google Cloud Storage) located in the same cloud region as the Snowflake account.
- Data Egress: Transferring data out of Snowflake incurs costs. This includes:
- Unloading data to cloud storage in a different region or to a different cloud provider.
- Transferring data to the internet (e.g., downloading query results to a local machine).
- Using external functions that send data out of Snowflake. These egress costs vary by region and cloud provider. For example, transfers to a different region within the same cloud might cost between $20 per TB (US) and $140 per TB (Asia Pacific Sydney). Transfers from an AWS US East region to the internet could be around $90 per TB, while from an Azure US East region it might be $87.50 per TB, and from a Google Cloud US East region $120-$190 per TB.
- Data Replication: Replicating data between Snowflake accounts in different regions or on different cloud platforms (e.g., for business continuity or data sharing) will also incur data transfer charges.
Data egress is a common cost component across most cloud services, and organizations using Snowflake need to be mindful of these charges, especially if they involve frequent large-scale data exports or extensive cross-region/cross-cloud data replication.
Snowflake's granular, usage-based pricing model presents both significant advantages and potential challenges. The primary benefit is flexibility: organizations can dynamically scale resources up or down, paying only for what they consume, which contrasts sharply with the often large upfront investments and fixed costs associated with traditional on-premises data warehousing systems. This model can lead to substantial cost savings by eliminating payment for idle resources and avoiding over-provisioning. However, this same granularity and flexibility can also introduce cost unpredictability if usage is not carefully managed. Inefficiently written queries, inappropriately sized virtual warehouses left running, or a lack of adherence to auto-suspend policies can lead to rapid credit consumption and unexpectedly high bills. This necessitates a shift in operational mindset for users, moving from traditional capacity planning to active consumption management, continuous monitoring, and query optimization. This dynamic also creates an opportunity and a need for third-party cost management and optimization tools designed to help Snowflake customers gain better visibility and control over their spending. Furthermore, while compute and storage are the most prominent cost drivers, organizations must also account for potentially significant costs arising from the use of serverless features, data transfer (particularly data egress), and, in some specific workload scenarios, the Cloud Services layer if its usage exceeds the 10% daily compute credit threshold. A comprehensive understanding and diligent tracking of all these cost components are essential to accurately predict and manage the total cost of ownership for Snowflake.
6. The Competitive Arena: Snowflake vs. Key Market Players
Snowflake operates within a dynamic and highly competitive cloud data warehouse market. Understanding its position relative to other major players is key to appreciating its strengths, weaknesses, and strategic direction.
6.1. Overview of the Cloud Data Warehouse Market
The global market for cloud data warehousing is substantial and experiencing robust growth. Projections vary, but the trend is clearly upward; one source estimates growth from $36.31 billion in 2025 to $155.66 billion by 2034, representing a compound annual growth rate (CAGR) of 17.55%. Another report valued the market at $6.71 billion in 2023, expecting it to reach $43.57 billion by 2032, with a CAGR of 23.18%. While the exact figures differ, both underscore a vibrant and rapidly expanding market, attracting significant investment and fostering intense competition among providers.
The leading vendors in this space include Amazon Web Services (with its Redshift platform), Snowflake itself, Google Cloud (with BigQuery), Microsoft (with Azure Synapse Analytics), and increasingly, Databricks, which champions a "lakehouse" architecture.
In terms of market share, AWS has historically held a leading position. By 2023, Snowflake and AWS together accounted for over 20% of the global market. Snowflake reported a $3.8 billion revenue run rate in 2024, demonstrating a strong 27% year-over-year growth. Databricks, while often categorized slightly differently due to its lakehouse focus, is showing even faster growth, with a reported 57% year-over-year increase and $2.6 billion in revenue in 2024.
Several key trends are shaping the cloud data warehouse market. Multi-cloud strategies are becoming more prevalent, influencing organizations' choices of data infrastructure to avoid vendor lock-in and leverage best-of-breed services. AI-driven analytics is another major driver, pushing platforms to integrate more advanced analytical and machine learning capabilities. From an offering perspective, Data Warehouse as a Service (DWaaS) is the dominant model, valued for its cost savings, scalability, and ease of use. Key industry verticals driving adoption include healthcare, which contributed approximately 28% of revenue in 2023, and Banking, Financial Services, and Insurance (BFSI), which is projected for the fastest CAGR. Large enterprises currently account for the majority of market revenue (around 65% in 2023), and public cloud deployments are the most common deployment model (around 64% in 2023). North America has been a leading region in terms of market share, driven by the strong presence of major cloud providers and early adoption of advanced analytics.
6.2. In-Depth Competitor Analysis
A direct comparison with its main competitors highlights Snowflake's unique attributes and its competitive standing.
The following table provides a high-level comparative summary:
| Feature | Snowflake | Amazon Redshift | Google BigQuery | Microsoft Azure Synapse | Databricks |
|---|---|---|---|---|---|
| Core Architecture | Separated Storage/Compute, Multi-Cloud, Cloud Data Warehouse (evolving to AI Data Cloud) | AWS-native, Traditionally Coupled (RA3 separate), Data Warehouse | GCP-native, Serverless, Separated Storage/Compute (Dremel/Colossus), Data Warehouse | Azure-native, Separated Storage/Compute, Integrated Analytics Platform (Warehouse + Spark) | Multi-Cloud, Lakehouse (Data Lake + Warehouse capabilities), Spark-based |
| Primary Strengths | Multi-cloud flexibility, Ease of use/Near-zero admin, Secure data sharing | Deep AWS integration, Cost-effective for reserved capacity, Mature ecosystem | Serverless, High-speed queries, Integrated BigQuery ML, Strong GCP integration | Unified analytics (SQL & Spark), Deep Azure integration, Hybrid potential | Unified platform for Data Engineering/Science/ML, Open-source foundation (Spark, Delta Lake), Handles all data types |
| Pricing Model | Credit-based (compute), Per-TB (storage) | Instance-based (on-demand/reserved), Serverless option, Per-TB (storage) | Query-based (data scanned) or Slot-based (capacity), Per-TB (storage) | DTU/vCore-based (SQL pools), Pay-per-query (serverless), Per-TB (storage) | DBU-based (workload type), Cloud provider storage costs separate |
| Ideal Use Cases | Multi-cloud deployments, Variable workloads, Data collaboration/monetization | AWS-centric organizations, Predictable workloads, Cost optimization via RIs | GCP-centric orgs, Real-time analytics, Ad-hoc querying, SQL-based ML | Azure-centric orgs, Unified big data & warehousing, Integrated BI/ML on Azure | Heavy data engineering/ETL, Advanced ML/AI on raw data, Streaming analytics, Organizations wanting open formats |

6.2.1. Snowflake vs. Amazon Redshift
Amazon Redshift is AWS's established cloud data warehouse service.
- Architecture: Snowflake boasts a multi-cloud architecture with complete separation of storage and compute, operating in a serverless fashion for the user. Redshift is native to AWS. While traditionally its storage and compute were coupled, newer RA3 instances and Redshift Serverless now offer separation. However, Redshift often requires more configuration and setup of nodes and instance types compared to Snowflake's more abstracted model.
- Scalability: Snowflake offers rapid, elastic scaling, often completing in seconds, with robust auto-scaling capabilities. Redshift scaling typically involves adding more nodes to an existing cluster or resizing, which can take minutes. Redshift also offers concurrency scaling, but this can incur extra costs beyond a daily allocated amount.
- UDF Support: Snowflake supports UDFs in Java, Python, JavaScript, and SQL. Redshift supports SQL and Python UDFs and can leverage AWS Lambda functions for UDFs, offering broader language flexibility through Lambda.
- Maintenance: Snowflake is designed for near-zero maintenance, with many tasks automated. Redshift traditionally requires manual
VACUUMoperations to maintain query performance, although some automation has been introduced. - Pricing: Snowflake uses a credit-based system for compute and separate charges for storage, with costs varying by edition and region. Redshift pricing can be bundled (for older instance types) or separate (for RA3/Serverless). It offers on-demand and reserved instance pricing, with potential for significant discounts on long-term commitments. Redshift Spectrum allows querying data in S3, charged by bytes scanned. Redshift is often perceived as more cost-effective for predictable, long-term deployments, especially within the AWS ecosystem where reserved instances can be leveraged.
- Security: Both platforms offer robust security. Snowflake's specific options often vary by edition. Redshift integrates deeply with AWS security services like IAM, CloudTrail, and VPCs.
- Ideal Use Cases: Snowflake excels in scenarios requiring multi-cloud flexibility, handling variable workloads, and leveraging its unique data sharing capabilities. Redshift is a strong choice for organizations heavily invested in the AWS ecosystem, especially those with predictable workloads that can benefit from reserved instance pricing.
6.2.2. Snowflake vs. Google BigQuery
Google BigQuery is Google Cloud's fully managed, serverless data warehouse.
- Architecture: Snowflake employs a multi-cluster, shared data architecture with separated storage and compute, available across multiple clouds. BigQuery is exclusive to Google Cloud Platform (GCP), featuring a serverless architecture powered by Google's Dremel query engine and Colossus distributed file system for columnar storage.
- Pricing: Snowflake's pricing is based on compute credits (per-second billing for virtual warehouses) and storage consumed. BigQuery primarily charges for the amount of data scanned by queries (on-demand pricing) or for reserved compute capacity (slots) under its flat-rate pricing model. Storage is charged separately.
- Data Sharing: Snowflake offers advanced "Secure Data Sharing," allowing live data sharing across accounts without data movement or duplication. BigQuery relies on Google Cloud's Identity and Access Management (IAM) for dataset sharing, primarily within the GCP ecosystem.
- Performance & Scalability: BigQuery is renowned for its high performance on large datasets and its automatic, per-query scaling capabilities, abstracting resource management from the user. Snowflake also offers very fast performance and allows users to manually scale virtual warehouses to balance performance and cost, providing more direct control.
- ML Capabilities: BigQuery features BigQuery ML, which allows users to create and run machine learning models directly within the data warehouse using SQL. Snowflake is rapidly advancing its ML capabilities with Snowpark (for Python, Java, Scala development) and Snowflake Cortex (for LLM access and AI services), alongside integrations with external ML tools.
- Flexibility/Ecosystem: Snowflake's key advantage is its multi-cloud support (AWS, Azure, GCP). BigQuery offers deep and seamless integration with the broader Google Cloud Platform ecosystem, including services like Google Analytics, Google Ads, and Vertex AI.
6.2.3. Snowflake vs. Microsoft Azure Synapse Analytics
Azure Synapse Analytics is Microsoft's integrated analytics service that brings together enterprise data warehousing and Big Data analytics.
- Architecture: Snowflake is a multi-cloud SaaS offering with its own custom SQL query engine and separated storage/compute. Azure Synapse is a PaaS offering native to the Azure cloud. It also separates storage and compute and integrates different analytical engines, including dedicated SQL pools (for traditional data warehousing), serverless SQL pools (for querying data lakes), and Apache Spark pools (for big data processing).
- Supported Environments: Snowflake is cloud-only, running on AWS, Azure, and GCP. Azure Synapse is primarily an Azure cloud service but can connect to on-premises data sources and supports some hybrid scenarios.
- Performance & Scalability: Both platforms allow independent scaling of compute and storage. Snowflake's virtual warehouses can typically scale up or down in seconds due to their pre-warmed nature. Azure Synapse scaling operations for dedicated SQL pools might take 1-5 minutes. Synapse offers both dedicated resource models (for consistent performance) and serverless models (for unpredictable workloads).
- Data Management: Snowflake fully manages all aspects of data storage and underlying infrastructure from the user's perspective. Azure Synapse, while a managed service, leverages Azure's PaaS and IaaS infrastructure, potentially offering users slightly more control over some data processing aspects compared to Snowflake's more abstracted SaaS model.
- Integrations: Snowflake has a broad ecosystem of connectors and partners. Azure Synapse offers deep and native integration with other Microsoft Azure services, such as Azure Data Lake Storage, Azure Machine Learning, Power BI, and Azure Data Factory.
- XML Support: Snowflake provides native support for XML data. Azure Synapse does not support XML natively, though workarounds might be possible.
6.2.4. Snowflake vs. Databricks
Databricks, built by the creators of Apache Spark, offers a unified analytics platform often described as a "lakehouse," which aims to combine the benefits of data lakes and data warehouses.
- Core Offering: Snowflake originated as a cloud data warehouse and is evolving into an "AI Data Cloud," strengthening its capabilities beyond traditional SQL analytics. Databricks is fundamentally a lakehouse platform built on Apache Spark, designed for large-scale data engineering, data science, and machine learning, with growing SQL analytics capabilities via Databricks SQL.
- Data Types: Snowflake has strong support for structured and semi-structured data and is enhancing its capabilities for unstructured data. Databricks excels at handling all data types, including raw, unstructured data (images, video, text), making it highly suitable for data science and ML workloads that often start with diverse data formats.
- Performance: Snowflake is highly optimized for interactive BI and SQL queries on structured and semi-structured data. Databricks, leveraging Apache Spark, offers high performance for large-scale batch and real-time data processing, complex ETL/ELT operations, and streaming analytics.
- ML Capabilities: Databricks has a mature and deeply integrated machine learning ecosystem, including MLflow for MLOps, optimized Spark ML libraries, and support for various deep learning frameworks. Snowflake is rapidly developing its ML story with Snowpark (allowing Python, Java, and Scala code execution), Snowflake Cortex (for LLM access), and integrations with third-party ML tools.
- Ease of Use/Administration: Snowflake is generally considered easier to use and administer, with its "near-zero management" SaaS approach. Databricks often has a steeper learning curve and may require more administration, configuration, and optimization expertise, especially for fine-tuning Spark jobs.
- Pricing: Snowflake uses a credit-based model for compute and separate charges for storage. Databricks pricing is based on Databricks Units (DBUs), which vary depending on the workload type (e.g., Workflows, Delta Live Tables, Databricks SQL, Interactive Workloads) and the underlying cloud provider VM instances. Storage costs are separate and are incurred directly from the cloud provider (AWS S3, Azure Blob Storage, GCS). A general comparison suggests Databricks might average around $99/month and Snowflake $40/month for some typical business user scenarios, but this is highly variable and depends heavily on the specific workload, usage patterns, and chosen configurations.
- SQL Analytics: Snowflake is a longtime leader in cloud data warehousing and SQL analytics. Databricks SQL is a newer offering designed to provide competitive data warehousing performance on the lakehouse.
The competitive landscape clearly indicates that there is no universally "best" cloud data platform. The optimal choice is highly contingent upon an organization's specific circumstances, including its existing cloud infrastructure allegiances (e.g., being heavily invested in AWS, GCP, or Azure), the technical skillsets available within its teams, the primary nature of its data workloads (ranging from traditional business intelligence to advanced machine learning or complex data engineering), its strategic approach to multi-cloud adoption, and its budgetary constraints. For instance, an organization deeply embedded within the AWS ecosystem with predictable, stable workloads might find Amazon Redshift, particularly with reserved instances, to be a cost-effective solution. Conversely, a company prioritizing a fully serverless experience, requiring cutting-edge machine learning capabilities tightly integrated within the Google Cloud Platform, would likely find Google BigQuery highly compelling. Enterprises centered on the Azure cloud and seeking an integrated suite for analytics and data management might gravitate towards Azure Synapse Analytics. For those with intensive data science requirements, a need to process raw or unstructured data at scale, and a preference for a lakehouse architecture built on open-source foundations, Databricks presents a strong case. Snowflake carves out its unique value proposition through its multi-cloud capabilities, renowned ease of use, and innovative data sharing features, appealing to organizations that prioritize operational simplicity, flexibility across cloud environments, and the ability to collaborate on data without complex data movement.
A key strategic differentiator for Snowflake, particularly when compared against the offerings from major cloud hyperscalers (Amazon Redshift, Google BigQuery, Microsoft Azure Synapse), is its multi-cloud agnosticism. While the hyperscalers naturally design their data warehouse services to integrate deeply within their respective cloud ecosystems, thereby encouraging customer retention, Snowflake provides a consistent data platform experience across AWS, Azure, and GCP. This is a powerful advantage for many enterprises that are increasingly adopting multi-cloud strategies to avoid vendor lock-in, leverage best-of-breed services from different providers, ensure business continuity, or comply with data sovereignty regulations. Snowflake's ability to serve as a uniform data layer, regardless of the underlying cloud infrastructure used for other applications and services, offers significant flexibility and portability.
The rivalry between Snowflake and Databricks is particularly noteworthy as it represents a more fundamental divergence in architectural philosophy—the evolution of the cloud data warehouse versus the rise of the data lakehouse—though the lines between these two paradigms are increasingly blurring. Snowflake, having established itself as a leader in cloud data warehousing with exceptional performance for BI and SQL analytics, is now strategically expanding its capabilities into data science, machine learning, and application development with offerings like Snowpark and Snowflake Cortex, aiming to become a comprehensive "AI Data Cloud". Conversely, Databricks, with its origins in Apache Spark and strong footing in big data processing, ETL, and ML on data lakes, has been enhancing its platform with data warehousing features (e.g., ACID transactions via Delta Lake, improved Databricks SQL performance) to realize the lakehouse vision of a single platform for all data workloads. This convergence means that the decision between Snowflake and Databricks is becoming less about choosing a "warehouse or a lake" and more about which platform's foundational architecture, evolving ecosystem, and specific strengths best align with an organization's overall data strategy, particularly concerning the balance and integration of business intelligence, data engineering, and advanced AI/ML initiatives. The choice is increasingly nuanced, requiring a careful evaluation of both current needs and future aspirations.
7. Synthesizing the Deep Dive: Snowflake's Strengths, Weaknesses, and Future Outlook
Snowflake has undeniably carved out a significant position in the data management landscape, driven by its innovative approach to cloud data warehousing and its continuous evolution. A comprehensive analysis reveals a platform with compelling advantages, some potential limitations, and a clear trajectory aimed at addressing the future needs of data-driven organizations.
7.1. Key Advantages of Snowflake (Recap and Synthesis)
Snowflake's success is built upon several core strengths that differentiate it in the market:
- Innovative Architecture: The foundational separation of storage and compute is a paradigm shift from traditional data warehouse designs. This architecture provides unparalleled elasticity, allowing independent scaling of resources, which translates to optimized performance for diverse workloads and significant cost-efficiencies by paying only for what is used. The multi-cluster shared data approach further enhances concurrency and workload isolation.
- Multi-Cloud and Cross-Cloud Capabilities (Snowgrid): Snowflake's ability to run consistently across major cloud providers (AWS, Azure, GCP) and facilitate cross-cloud operations via Snowgrid offers organizations immense flexibility, helps avoid vendor lock-in, and supports global data strategies, including disaster recovery and data sovereignty compliance.
- Ease of Use and Near-Zero Management: As a fully managed SaaS platform, Snowflake significantly reduces the administrative burden associated with traditional data platforms. Automation of tasks like tuning, maintenance, and infrastructure management lowers the total cost of ownership and allows technical teams to focus on deriving value from data rather than managing infrastructure.
- Powerful and Secure Data Sharing: This is a standout feature, enabling organizations to share live, governed data with internal and external parties without the need for data copying or complex ETL processes. This fosters collaboration, enables new data monetization opportunities (e.g., via Snowflake Marketplace), and creates a powerful network effect.
- Versatile Data Handling: Native support for structured and semi-structured data (JSON, Avro, Parquet, XML, etc.) allows organizations to consolidate diverse datasets into a single platform. Capabilities for handling unstructured data are also evolving, particularly with Snowpark and Snowpark Container Services.
- Rich and Evolving Feature Set: Core features like Time Travel (for data recovery and historical querying) and Zero-Copy Cloning (for instant data environment provisioning) provide significant operational benefits. Robust security features across multiple layers, coupled with the extensibility offered by Snowpark (for Python, Java, Scala development) and emerging AI/ML capabilities like Snowflake Cortex, demonstrate a commitment to continuous innovation.
7.2. Potential Limitations and Areas for Improvement
Despite its many strengths, Snowflake is not without potential limitations or areas where further development could enhance its offering:
- Cost Management Complexity: While the usage-based pricing model offers flexibility, it can also lead to unpredictable costs if not diligently monitored and governed. The ease of scaling compute resources means that inefficient queries or poorly managed virtual warehouses can result in unexpectedly high bills. Organizations must adopt robust cost management practices to fully realize the economic benefits.
- Niche Workloads and Specialized Data Types: While Snowflake is highly versatile, for extremely specialized workloads, such as ultra-low-latency online transaction processing (OLTP) systems or the direct, intensive processing of massive archives of certain unstructured data types (e.g., complex video analysis at scale), purpose-built systems might still offer advantages. Its strength lies primarily in analytical workloads.
- Performance for Highly Complex Stored Procedures: Compared to some traditional relational database systems that are highly optimized for complex, procedural SQL logic executed within stored procedures, Snowflake's performance for such specific tasks might occasionally present bottlenecks, though its Snowflake Scripting capabilities are continually improving.
- Pricing Tiers for Advanced Security Features: Some of the most advanced security and compliance features, such as customer-managed encryption keys or private connectivity options, are typically available only in the higher-cost editions (Business Critical or VPS). This could be a consideration for smaller organizations that have significant security needs but may find the higher editions cost-prohibitive.
- Maturity of Native Advanced Analytics and Machine Learning Ecosystem: While Snowpark and Snowflake Cortex represent significant strides in bringing advanced analytics and ML capabilities directly onto the platform, the native ecosystem for these workloads is still maturing compared to more specialized platforms like Databricks, which have a longer history and deeper integration in these areas. However, Snowflake's pace of innovation here is rapid.
7.3. Concluding Thoughts: Snowflake's Role in the Evolving Data Landscape
Snowflake has fundamentally disrupted the data warehousing market with its cloud-native architecture, innovative features, and focus on ease of use. It has successfully addressed many of the pain points associated with legacy data platforms, offering a scalable, flexible, and powerful solution for modern data analytics.
The strategic evolution towards an "AI Data Cloud" is a clear indication of Snowflake's ambition to be more than just a data warehouse. By integrating capabilities for data engineering (Snowpark), AI and machine learning (Cortex AI), application development (Snowpark Container Services, Native Applications), and global data collaboration (Snowgrid, Data Sharing, Marketplace), Snowflake aims to become a central, unified platform for a much broader spectrum of data-driven activities. This expansion is not merely a marketing endeavor but a necessary strategic response to a market where the value of data is increasingly unlocked through AI and sophisticated applications. Remaining solely a data storage and querying layer would risk commoditization as higher-value processing shifts to other specialized platforms. Thus, this evolution is crucial for Snowflake's long-term growth and its aspiration to maintain a leadership position in the comprehensive data platform market.
Snowflake's success has been built on technological innovation and a keen understanding of customer needs for simplicity and scalability. However, as the platform matures and its adoption widens, a key challenge and opportunity lie in balancing continued innovation with the imperative to provide customers with robust tools and transparent mechanisms for managing and optimizing their costs. The usage-based model, while a core tenet of its flexibility, necessitates a partnership with users to ensure that value realization is not overshadowed by cost concerns.
Furthermore, the strength and vibrancy of Snowflake's ecosystem—comprising technology partners, system integrators, data providers on the Marketplace, and a growing community of developers—will be a critical lever for its continued growth and differentiation. No single platform can cater to every conceivable need. A thriving ecosystem extends Snowflake's capabilities, facilitates easier integration into diverse customer environments, and fosters network effects where the platform becomes more valuable as more participants contribute data, applications, and services.
For organizations evaluating or using Snowflake, the platform offers immense potential. Realizing this potential requires a thorough understanding of its unique architecture, a strategic approach to leveraging its rich feature set, and a diligent focus on governance and cost management. As the data landscape continues to evolve at a rapid pace, Snowflake's ability to adapt, innovate, and effectively address the complex interplay of data, analytics, and artificial intelligence will ultimately define its enduring impact.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.